
2025 年机器学习工具箱:面向从业者的顶级库和工具
作者 | Ideogram 提供图片
2024 年是机器学习(ML)和人工智能(AI)走向主流的一年,以人们前所未有的方式影响着人们的生活。随着近年来 ChatGPT 等大型语言模型(LLM)产品的推出,企业正竞相将 ML、AI 和 LLM 的力量应用于其业务。
2025 年,机器学习领域的许多新兴趋势将继续在许多业务运营中占据主导地位。代理、生成式 AI、可解释性等趋势将继续塑造我们的未来。这意味着我们应该能够跟上这些趋势。
本文将探讨 2025 年从业者的顶级机器学习库和工具。本文概述的工具箱将成为您应对新兴趋势的基线。
LangChain
2025 年你需要了解的第一个库是 LangChain,包括其扩展产品家族。
在 LLM 应用时代,快速构建和部署应用的能力变得比以往任何时候都更加重要。作为一个库,LangChain 提供了一个框架来简化 LLM 驱动应用的开发,使过程更高效、更具可扩展性。
LangChain 提供了许多工具,通过链、提示模板等各种组件简化了 LLM 应用开发过程。该框架还支持与 OpenAI、Gemini 和 Hugging Face 等各种 LLM 提供商集成。
然而,采用 LangChain 更重要的原因在于其活跃的开发和强大的开源社区。有了这种支持,LangChain 可以成为构建 LLM 应用的完美工具。
LangChain 之所以脱颖而出,还因为它家族中的工具,即 LangGraph 和 LangSmith。LangGraph 构建在 LangChain 之上,使用基于图的方法管理代理工作流。同时,LangSmith 通过提供应用程序生命周期(如监控、测试和优化)的工具来补充 LangChain 和 LangGraph。
让我们试用一下 LangChain 库。首先,我们将安装该库。
|
1 |
pip install langchain langchain-google-gen |
我们还将使用 Gemini 模型 作为 LLM 引擎,因此您需要获取一个 API 密钥。接下来,我们为我们的应用程序设置库和 LLM。
|
1 2 3 4 5 6 7 8 9 |
from langchain_google_genai import ChatGoogleGenerativeAI from langchain.prompts import PromptTemplate from langchain_core.output_parsers import StrOutputParser llm = ChatGoogleGenerativeAI( model="gemini-1.5-flash", temperature=0.7, google_api_key='YOUR-API-KEY' ) |
最后,我们设置提示模板和序列以提供 LLM 的响应。
|
1 2 3 4 |
prompt = PromptTemplate(input_variables=["topic"], template="Write a short story about {topic}.") runnable_sequence = prompt | llm | StrOutputParser() response = runnable_sequence.invoke({"topic": "a brave knight"}) print(response) |
我们只需几行代码就设置好了 LLM 应用程序。当然,这个实现仍然非常简单,需要更多的考虑和额外的调整才能在生产环境中稳定运行,但它应该能展示 LangChain 仅用几行代码就能实现的强大功能。
JAX
如果您是数据科学家或以前用 Python 开发过机器学习模型,您可能熟悉 NumPy 库。JAX 是一个 Python 库,提供类似于 NumPy 的数值计算,但具有强大的机器学习研究和实现功能。
JAX 由谷歌团队开发,旨在实现高性能计算并提供自动微分、向量化或即时 (JIT) 编译等功能。这些功能旨在轻松实现密集计算。JAX 已用于许多机器学习应用程序。该模块提供了许多适用于高性能模拟和实验的 API。
让我们用以下代码检查 JAX。首先,我们安装。
|
1 |
pip install jax |
现在我们可以尝试 JAX 计算函数。例如,我们将计算给定函数的梯度。
|
1 2 3 4 5 6 7 8 |
import jax.numpy as jnp from jax import grad, jit, vmap def f(x): return jnp.sin(x) * jnp.cos(x) df = grad(f) print(df(0.5)) |
上述代码的输出将是
|
1 |
0.5403023 |
我们还可以对函数进行向量化并将其应用于数组。
|
1 2 |
f_vmap = vmap(f) print(f_vmap(jnp.array([0.1, 0.2, 0.3]))) |
以及输出
|
1 |
[0.09933467 0.19470917 0.28232124] |
您可以查阅文档以了解更多关于该库的信息。它提供了丰富的材料,您可以探索以了解其工作原理。
Fastai
下一个工具是 Fastai,它提供了深度学习技术和辅助功能的快速实现。该库旨在通过高级组件简化神经网络训练,使从业者能够以最少的代码获得出色的结果。
Fastai 库构建在 PyTorch 库之上,因此 PyTorch 的大部分功能和灵活性都可以从 Fastai 内部获得。然而,Fastai 为用户提供了更简单的方法来构建模型,因为该库将许多复杂的代码抽象为简单的 API。尽管如此,Fastai 仍然可以用于创建自定义模型,因为该库也提供了低级组件。
Fastai 支持许多任务,例如计算机视觉、表格数据、自然语言处理等。根据您的需求,您可以原样使用代码,或者根据需要逐步增加复杂性。
让我们尝试使用该库来更好地理解它。
首先,我们需要安装 Fastai 库。我推荐使用 Miniconda,但您也可以使用其他安装方法。PyTorch 库也很重要,因为它是先决条件。
您可以使用以下代码通过 pip 安装该库
|
1 |
pip install fastai |
安装 Fastai 库后,我们可以使用它来为自己构建一个深度学习模型。例如,我们将使用来自 Kaggle 的数据创建一个情感文本分类器模型。
让我们为本教程准备文本数据和所有必需的库。
|
1 2 3 4 5 6 7 8 9 |
from fastai.text.all import * import pandas as pd from sklearn.model_selection import train_test_split df = pd.read_csv('Corona_NLP_test.csv') df.head() df = df[['OriginalTweet', 'Sentiment']] train_df, valid_df = train_test_split(df, test_size=0.2, random_state=42) |
接下来,我们将使用 Fastai 执行模型微调。在构建模型分类器之前,让我们看看该库如何帮助完成微调任务。
我们必须使用以下代码以 Fastai 可以使用的格式准备数据集。
|
1 2 3 4 5 6 7 |
dls = TextDataLoaders.from_df(pd.concat([train_df, valid_df]), text_col='OriginalTweet', label_col='Sentiment', valid_pct=0.2, seed=42, text_vocab=None, is_lm=True) |
本教程将使用并微调 AWD-LSTM 架构,如下面的代码所示。您还可以根据需要调整学习率和 epoch 数量。
|
1 2 3 |
learn = language_model_learner(dls, AWD_LSTM, drop_mult=0.5, metrics=[accuracy, Perplexity()]) learn.fine_tune(10, 2e-3) learn.save_encoder('fine_tuned_encoder') |
上述代码将微调语言模型对象,并导致模型对象保存到您的目录中。您现在拥有了自己的基本语言模型。让我们看看如何为文本分类器微调预训练语言模型。
我们将再次准备数据集,但这次会进行一些调整。
|
1 2 3 4 5 6 7 8 9 |
dls_clas = TextDataLoaders.from_df( pd.concat([train_df, valid_df]), text_col='OriginalTweet', label_col='Sentiment', valid_pct=0.2, seed=42, text_vocab=dls.vocab, is_lm=False ) |
您可以看到,我使用用于微调的数据集的词汇表设置了 text_vocab 参数以保持一致性,并将 is_lm 设置为 False 以确保模型知道它将用于分类任务。
然后,我们使用以下代码训练分类器。
|
1 2 3 |
learn_clas = text_classifier_learner(dls_clas, AWD_LSTM, drop_mult=0.5, metrics=accuracy) learn_clas = learn_clas.load_encoder('fine_tuned_encoder') learn_clas.fine_tune(10, 2e-3) |
我们现在已经完成了模型分类器的开发并获得了模型。我们可以使用下面的代码查看模型在测试数据集上的表现。
|
1 |
learn_clas.show_results() |
您还可以使用以下代码测试分类器模型。
|
1 2 3 |
test_text = "It's a nice tweet" prediction = learn_clas.predict(test_text) prediction[0] |
输出
|
1 |
Positive |
这就是使用 Fastai 训练模型的简易程度。您可以查阅文档以探索其他用例。
IntepretML
随着可解释性和道德在 2025 年变得越来越突出,我们需要了解为什么我们的机器学习模型会产生它们所产生的输出。这就是为什么 IntepretML 应该在您的机器学习工具箱中。
InterpretML 是微软开发的一个 Python 库,它使用户能够训练可解释的机器学习模型,例如可解释增强机 (EBM),并使用 SHAP 和 LIME 等技术解释黑盒模型。此外,它还提供了一个交互式可视化仪表板,用于深入探索模型解释。
让我们通过 notebook 示例看看它是如何工作的。首先,我们需要安装 IntepretML 库。
|
1 |
pip install interpret |
接下来,我们将通过预处理样本数据集并使用 EBM 模型训练分类器来准备样本数据集。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import pandas as pd import seaborn as sns from sklearn.model_selection import train_test_split from interpret.glassbox import ExplainableBoostingClassifier from interpret import show titanic = sns.load_dataset('titanic') titanic = titanic[['pclass', 'age', 'sibsp', 'parch', 'fare', 'survived']].dropna() X_train, X_test,y_train, y_test = train_test_split(titanic.drop('survived', axis =1), titanic['survived'], test_size=0.20, random_state=42) ebm = ExplainableBoostingClassifier() ebm.fit(X_train, y_train) |
模型准备好后,我们可以检查库的可解释性。我们将检查全局可解释性,即模型的整体可解释性。
|
1 2 |
ebm_global = ebm.explain_global() show(ebm_global) |
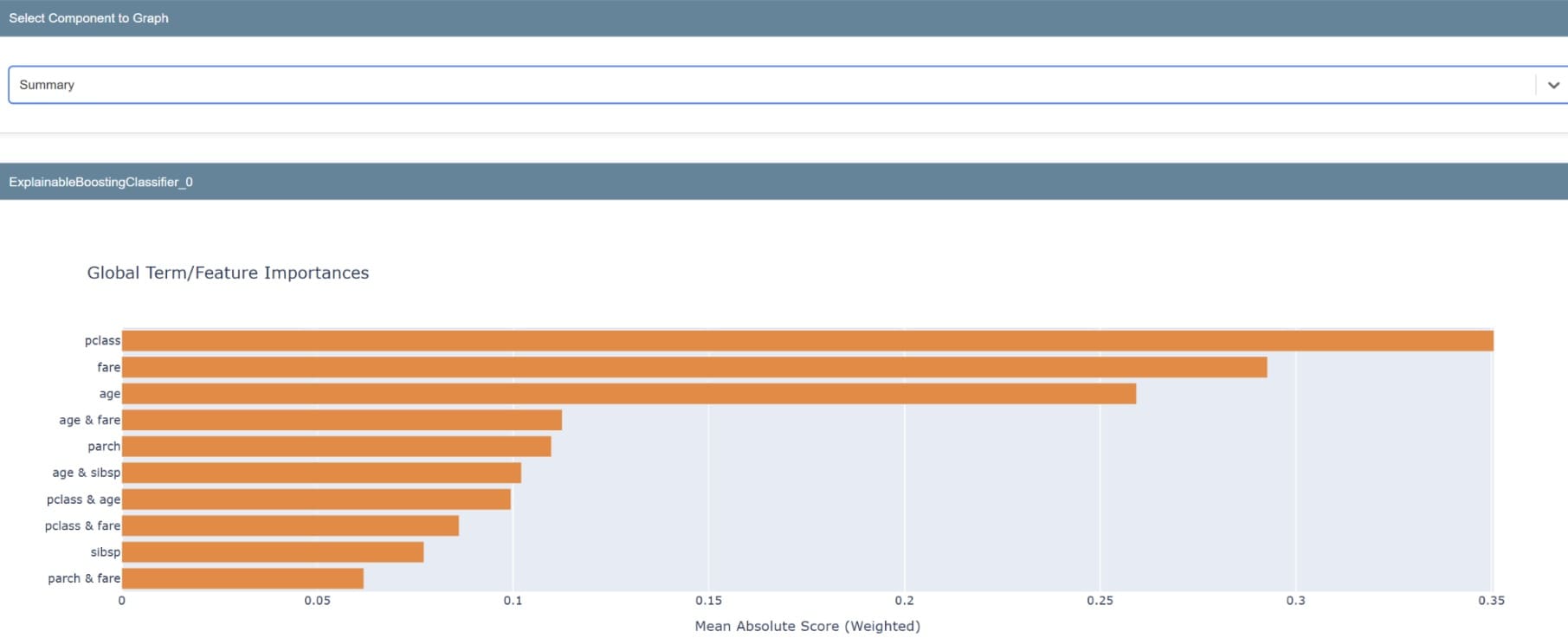
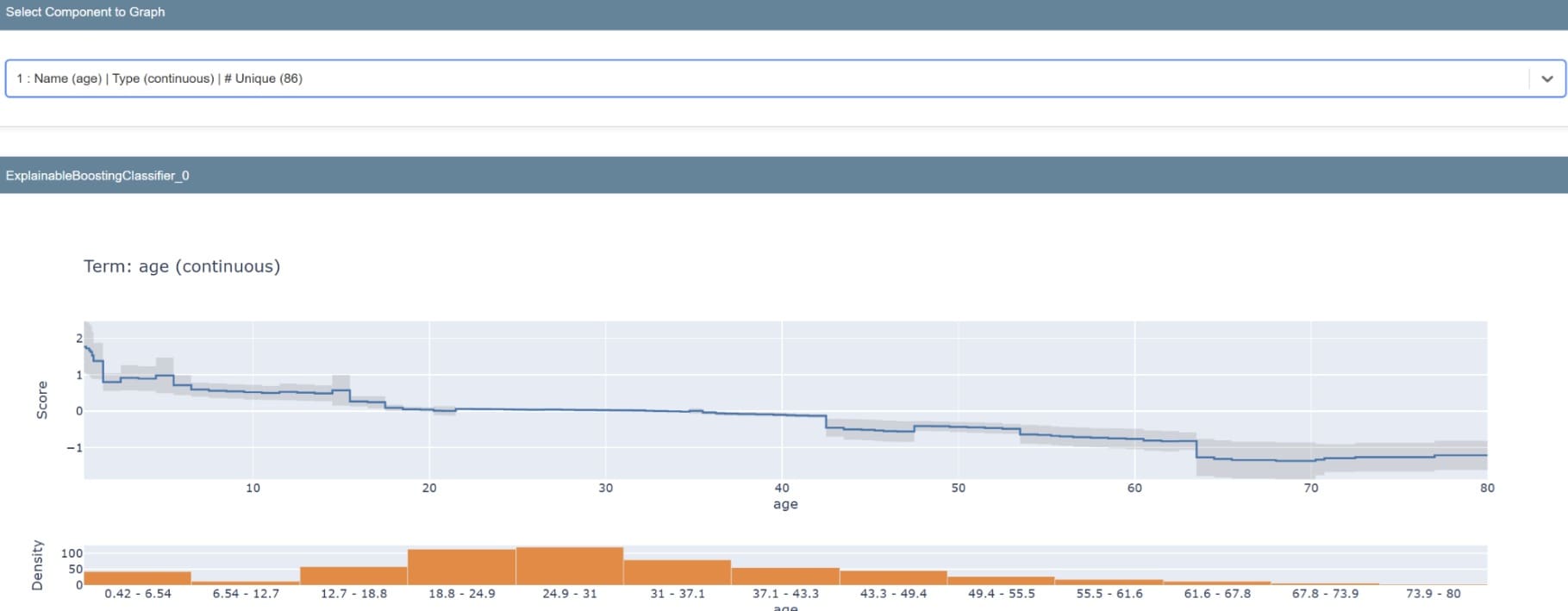
摘要将生成一个图表,显示模型特征的重要性。还可以检查单个特征以了解其预测分布。
如果我们要查看模型如何预测单个数据,以下代码允许我们这样做。
|
1 2 3 |
sample = X_test.iloc[0:1] ebm_local = ebm.explain_local(sample) show(ebm_local) |
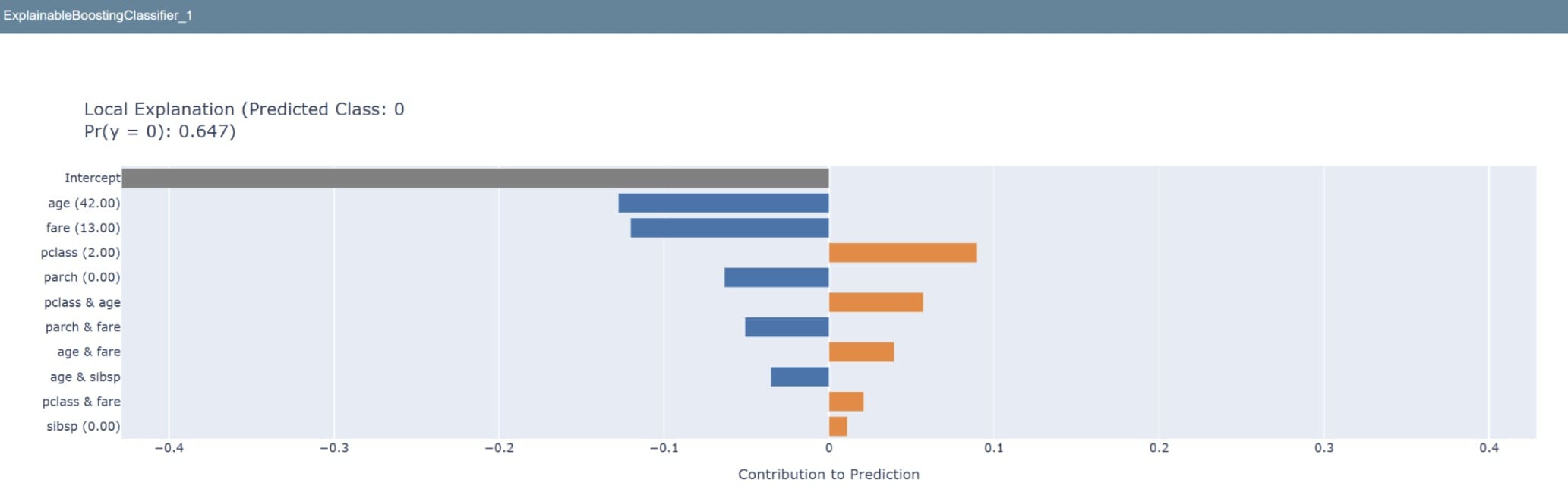
尝试使用这个库来帮助获得利益相关者的信任。可解释性是非技术人员理解模型内部发生情况的方式。
TokenSHAP
SHAP 是一种技术,我们用它来通过 Shapley 值从模型中获得全局和局部级别的可解释性。TokenSHAP 使用 SHAP 技术,通过蒙特卡洛 Shapley 值估计技术来解释 LLM。该库将估计单个 token 的 Shapley 值,并解释每个 token 如何对模型决策做出贡献。
让我们通过先安装它来试用该库。
|
1 |
pip install tokenshap |
然后,我们将使用 TokenSHAP 来了解提示如何影响 Gemini 模型结果。为此,我们将开发一个 TokenSHAP 可以处理的自定义类。
|
1 2 3 4 5 6 7 8 9 10 11 |
from token_shap import * import google.generativeai as genai genai.configure(api_key='YOUR-API-KEY') class GeminiModel(Model): def __init__(self, model_name): self.model = genai.GenerativeModel(model_name) def generate(self, prompt): response = self.model.generate_content(prompt) return response.text |
模型准备好后,我们将使用它对 LLM 进行 SHAP 分析。
|
1 2 3 4 5 6 7 8 9 |
gemini_model = GeminiModel("gemini-1.5-flash") splitter = StringSplitter() token_shap = TokenSHAP(gemini_model, splitter, debug=False) prompt = "Why is the sun hot?" df = token_shap.analyze(prompt, sampling_ratio=0.3, print_highlight_text=True) token_shap.plot_colored_text() |
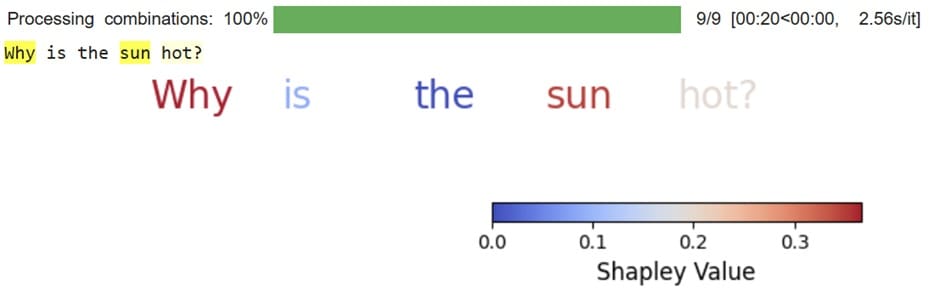
结果是单个 token 根据其 Shapley 值着色。Shapley 值越高,该 token 对模型响应的影响越大。例如,在提供输出时,单词 why 和 sun 比单词 the 重要得多。
使用以下代码,您还可以获取每个 token 的精确 Shapley 值。
|
1 |
token_shap.shapley_values |
输出
|
1 2 3 4 5 |
{'Why_1': 0.3667134604734776, 'is_2': 0.08749906167069088, 'the_3': 0.0, 'sun_4': 0.35029929597949777, 'hot?_5': 0.1954881818763337} |
尝试利用 TokenSHAP 来理解你的 LLM 为何会提供某些输出,以及哪些 token 在此过程中发挥了更大的作用。
结论
本文探讨了一系列将在 2025 年塑造机器学习的强大工具——从 LangChain 家族支持的快速应用开发,到 JAX 的高性能数值计算能力。我们还深入研究了 Fastai 精简的深度学习框架、InterpretML 提供的可解释性优势,以及 TokenSHAP 提供的 token 级洞察。这些库不仅展示了生成式 AI 和增强模型可解释性等新兴趋势,而且还为你提供了实用的动手方法,以应对当今数据驱动环境中复杂的挑战。
展望未来,掌握这些工具将使你能够构建健壮、可扩展和透明的机器学习解决方案。拥抱这些创新,以改进你的工作流程并推动有影响力的成果,确信你已为引领机器学习和人工智能不断发展的世界做好了充分准备。
希望这对您有所帮助!






看到一份聚焦 2025 年的总结真的很有帮助——机器学习工具发展得太快了,很容易错过新出现的流行库。好奇今年 TensorFlow 和 PyTorch 之间是否有任何明显的偏好转变?
不客气!没有注意到明显的转变……它们都很好,而且都很重要!
非常感谢对支持实验和部署的工具的关注——这些仍然是我合作过的许多团队的最大瓶颈。令人鼓舞的是,在 2025 年,工作流程的这一部分受到了更多关注。