使用 Keras 在 Python 中创建和评估深度学习神经网络非常容易,但您必须遵循严格的模型生命周期。
在这篇文章中,您将了解在 Keras 中创建、训练和评估深度学习神经网络的逐步生命周期,以及如何使用训练好的模型进行预测。
阅读本文后,您将了解
- 如何在 Keras 中定义、编译、拟合和评估深度学习神经网络。
- 如何为回归和分类预测建模问题选择标准默认值。
- 如何将所有这些结合起来,在 Keras 中开发和运行您的第一个多层感知器网络。
使用我的新书《使用 Python 进行深度学习》启动您的项目,包括分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- 2017 年 3 月更新:针对 Keras 2.0.2、TensorFlow 1.0.1 和 Theano 0.9.0 更新了示例。
- **2018 年 3 月更新**:添加了下载数据集的备用链接,因为原始链接似乎已被删除。

Keras 中的深度学习神经网络生命周期
图片由 Martin Stitchener 拍摄,保留部分权利。
概述
下面是我们将在 Keras 中查看的神经网络模型生命周期中的 5 个步骤的概述。
- 定义网络。
- 编译网络。
- 拟合网络。
- 评估网络。
- 进行预测。
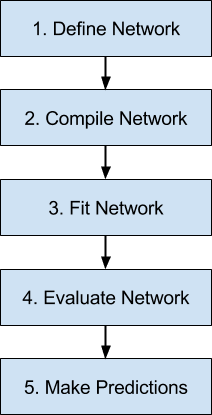
Keras 中神经网络模型的 5 步生命周期
Python 深度学习需要帮助吗?
参加我的免费为期两周的电子邮件课程,发现 MLP、CNN 和 LSTM(附代码)。
立即点击注册,还将免费获得本课程的 PDF 电子书版本。
步骤 1. 定义网络
第一步是定义您的神经网络。
在 Keras 中,神经网络被定义为一系列层。这些层的容器是 Sequential 类。
第一步是创建 Sequential 类的一个实例。然后您可以创建您的层并按照它们应该连接的顺序添加它们。
例如,我们可以分两步完成
|
1 2 |
model = Sequential() model.add(Dense(2)) |
但是我们也可以通过创建层数组并将其传递给 Sequential 的构造函数来一步完成。
|
1 2 |
layers = [Dense(2)] model = Sequential(layers) |
网络中的第一层必须定义预期的输入数量。指定方式可能因网络类型而异,但对于多层感知器模型,这由 input_dim 属性指定。
例如,一个小的多层感知器模型,在可见层有 2 个输入,在隐藏层有 5 个神经元,在输出层有 1 个神经元,可以定义为
|
1 2 3 |
model = Sequential() model.add(Dense(5, input_dim=2)) model.add(Dense(1)) |
可以将 Sequential 模型看作是一个管道,原始数据从底部输入,预测结果从顶部输出。
这在 Keras 中是一个有用的概念,因为传统上与层相关的关注点也可以分离出来并作为单独的层添加,清晰地显示它们在数据从输入到预测的转换中的作用。例如,转换层中每个神经元的求和信号的激活函数可以提取出来,并作为一个名为 Activation 的类似层对象添加到 Sequential 中。
|
1 2 3 4 5 |
model = Sequential() model.add(Dense(5, input_dim=2)) model.add(Activation('relu')) model.add(Dense(1)) model.add(Activation('sigmoid')) |
激活函数的选择对输出层最重要,因为它将定义预测的格式。
例如,下面是一些常见的预测建模问题类型及其在输出层中可以使用的结构和标准激活函数
- 回归:线性激活函数或“linear”,神经元数量与输出数量匹配。
- 二元分类(2 类):逻辑激活函数或“sigmoid”,输出层有一个神经元。
- 多类分类(>2 类):Softmax 激活函数或“softmax”,每个类别值一个输出神经元,假设采用独热编码的输出模式。
步骤 2. 编译网络
一旦我们定义了网络,就必须编译它。
编译是一个效率步骤。它将我们定义的简单层序列转换为一系列高效的矩阵变换,格式旨在根据 Keras 的配置在您的 GPU 或 CPU 上执行。
将编译视为网络的预计算步骤。
定义模型后始终需要编译。这包括使用优化方案进行训练之前以及从保存文件中加载一组预训练权重。原因是编译步骤会准备网络的有效表示,这对于在您的硬件上进行预测也是必需的。
编译需要指定许多参数,这些参数专门用于训练您的网络。特别是用于训练网络的优化算法和用于评估网络(由优化算法最小化)的损失函数。
例如,下面是一个编译已定义模型并指定随机梯度下降(sgd)优化算法和均方误差(mse)损失函数(适用于回归类型问题)的案例。
|
1 |
model.compile(optimizer='sgd', loss='mse') |
预测建模问题的类型对可以使用的损失函数类型施加了限制。
例如,下面是一些针对不同预测模型类型的标准损失函数
- 回归:均方误差或“mse”。
- 二元分类(2 类):对数损失,也称为交叉熵或“binary_crossentropy”。
- 多类分类(>2 类):多类对数损失或“categorical_crossentropy”。
您可以查看 Keras 支持的损失函数套件。
最常见的优化算法是随机梯度下降,但 Keras 还支持一系列其他最先进的优化算法。
或许最常用的优化算法因其普遍较好的性能而包括
- 随机梯度下降或“sgd”,需要调整学习率和动量。
- ADAM 或“adam”,需要调整学习率。
- RMSprop 或“rmsprop”,需要调整学习率。
最后,除了损失函数之外,您还可以指定在拟合模型时要收集的指标。通常,对于分类问题,最有用的附加指标是准确性。要收集的指标在数组中按名称指定。
例如:
|
1 |
model.compile(optimizer='sgd', loss='mse', metrics=['accuracy']) |
步骤 3. 拟合网络
网络编译完成后,就可以进行拟合,这意味着根据训练数据集调整权重。
拟合网络需要指定训练数据,包括输入模式矩阵 X 和匹配输出模式数组 y。
网络使用反向传播算法进行训练,并根据编译模型时指定的优化算法和损失函数进行优化。
反向传播算法要求网络训练指定的 epoch 次数,或者暴露给训练数据集的次数。
每个 epoch 可以分成输入-输出模式对组,称为批次。这定义了在一个 epoch 内更新权重之前网络所接触的模式数量。这也是一种效率优化,确保一次加载到内存中的输入模式不会太多。
拟合网络的最简单示例如下
|
1 |
history = model.fit(X, y, batch_size=10, epochs=100) |
一旦拟合,将返回一个 history 对象,它提供了模型在训练期间性能的摘要。这包括每个 epoch 记录的损失以及编译模型时指定的任何附加指标。
步骤 4. 评估网络
网络训练完成后,即可进行评估。
网络可以在训练数据上进行评估,但这无法提供网络作为预测模型性能的有用指示,因为它之前已经看到了所有这些数据。
我们可以评估网络在单独数据集上的性能,该数据集在测试期间是未见的。这将提供网络在未来对未见数据进行预测的性能估计。
模型评估所有测试模式的损失,以及编译模型时指定的任何其他指标,如分类准确性。将返回评估指标列表。
例如,对于使用准确率指标编译的模型,我们可以按如下方式在新数据集上对其进行评估
|
1 |
loss, accuracy = model.evaluate(X, y) |
步骤 5. 进行预测
最后,一旦我们对拟合模型的性能满意,我们就可以使用它对新数据进行预测。
这就像在模型上调用 predict() 函数并传入一个新输入模式数组一样简单。
例如:
|
1 |
predictions = model.predict(x) |
预测将以网络输出层提供的格式返回。
在回归问题中,这些预测可以直接以问题的格式给出,由线性激活函数提供。
对于二元分类问题,预测可能是一个第一类概率数组,可以通过四舍五入转换为 1 或 0。
对于多类分类问题,结果可能以概率数组的形式出现(假设是独热编码的输出变量),可能需要使用 argmax 函数将其转换为单个类别输出预测。
端到端工作示例
让我们将所有这些与一个小的工作示例结合起来。
此示例将使用皮马印第安人糖尿病发病二元分类问题。
下载数据集并将其保存到您的当前工作目录。
该问题有 8 个输入变量和一个输出类变量,整数值为 0 和 1。
我们将构建一个多层感知器神经网络,在可见层有 8 个输入,在隐藏层有 12 个神经元,使用整流器激活函数,在输出层有 1 个神经元,使用 sigmoid 激活函数。
我们将使用 ADAM 优化算法和对数损失函数对网络进行 100 个 epoch 的训练,批处理大小为 10。
拟合后,我们将在训练数据上评估模型,然后对训练数据进行独立预测。这是为了简洁起见,通常我们会在单独的测试数据集上评估模型并对新数据进行预测。
完整的代码列表如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# Keras 中的多层感知器神经网络示例 from keras.models import Sequential from keras.layers import Dense import numpy # 加载和准备数据集 dataset = numpy.loadtxt("pima-indians-diabetes.csv", delimiter=",") X = dataset[:,0:8] Y = dataset[:,8] # 1. 定义网络 model = Sequential() model.add(Dense(12, input_dim=8, activation='relu')) model.add(Dense(1, activation='sigmoid')) # 2. 编译网络 model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 3. 拟合网络 history = model.fit(X, Y, epochs=100, batch_size=10) # 4. 评估网络 loss, accuracy = model.evaluate(X, Y) print("\nLoss: %.2f, Accuracy: %.2f%%" % (loss, accuracy*100)) # 5. 进行预测 probabilities = model.predict(X) predictions = [float(round(x)) for x inprobabilities] accuracy = numpy.mean(predictions == Y) print("Prediction Accuracy: %.2f%%" % (accuracy*100)) |
运行此示例会产生以下输出
注意:由于算法或评估过程的随机性,或数值精度差异,您的结果可能会有所不同。请考虑多次运行示例并比较平均结果。
|
1 2 3 4 5 6 7 8 9 |
... 768/768 [==============================] - 0s - loss: 0.5219 - acc: 0.7591 Epoch 99/100 768/768 [==============================] - 0s - loss: 0.5250 - acc: 0.7474 Epoch 100/100 768/768 [==============================] - 0s - loss: 0.5416 - acc: 0.7331 32/768 [>.............................] - ETA: 0s 损失:0.51,准确率:74.87% 预测准确率:74.87% |
总结
在这篇文章中,您发现了使用 Keras 库的深度学习神经网络的 5 步生命周期。
具体来说,你学到了:
- 如何在 Keras 中定义、编译、拟合、评估和进行神经网络预测。
- 如何为分类和回归问题选择激活函数和输出层配置。
- 如何在 Keras 中开发和运行您的第一个多层感知器模型。
您对 Keras 中的神经网络模型或本文有任何疑问吗?请在评论中提出您的问题,我将尽力回答。


")


")
predictions = [float(round(x)) for x in probabilities]
代码抛出错误,
类型 numpy.ndarray 未定义 __round__ 方法
然后我将其更改为
predictions = [float(round(x[0])) for x in probabilities]
然后它就工作了!
看来 round() 对 numpy 不起作用。
https://mail.scipy.org/pipermail/numpy-discussion/2010-March/049584.html
谢谢 Ming,这可能是 Python 3 的问题,在我的 py27 环境中执行正常。
在 Python 2 和 3 版本中都可用的最简单解决方案是
在“round”前面加上“numpy.”。
即
predictions = [float(numpy.round(x)) for x in probabilities]
感谢您的本教程!
谢谢 Eric。
使用
rounded = [ ‘%.2f’ % x for x in predictions ]
感谢您对 Keras 的精彩介绍。我想将我的回归问题中的预测限制在特定范围内。Keras 有没有办法实现这一点?
是的,您可以在输出层使用自定义激活函数,或者解释模型中的预测。
感谢您的快速回复。为了强制输出在特定区间(例如 [0 5]),我尝试了 Keras lambda 层 keras.layers.Lambda(function, output_shape=None, mask=None, arguments=None) 并将 Keras 概率分布作为函数 (https://tensorflowcn.cn/probability)。但是,这种方法不起作用。您有什么提示可以实现这一点吗?
最简单的方法是使用线性输出,然后用函数对预测进行后处理。
一旦成功,就使用 lambda 层调用你的自定义函数。
嗨,Jason!
很棒的帖子!
我正计划在内存非常有限的设备上尝试 Keras。有没有一种干净的方法进行在线训练,即从文件中读取 x 行,然后进行训练,直到处理完大数据集?
谢谢
此致
Magnus
对于有限的内存和 CPU,我建议您自己实现,也许从更简单的方法开始。
我建议 Python 栈过于庞大/资源密集。
嗨,又一个问题。你一开始提到的“反向传播算法”在哪里?我们是否明确地做一些事情来正向迭代,计算误差,反向传播误差,然后更新权重?还是当我们使用特定的 LOSS 和 OPTIMIZER 时,反向传播就神奇地发生了?我有一个带有 'mse' 和 'sgd' 的前馈网络,谢谢
使用 Keras 的好处在于它为您实现了算法。您只需选择损失函数和优化算法,然后调用 fit() 即可。
我们能看到
X = 训练数据集
y = 测试数据集
这里?
训练和测试数据都必须包含 X 和 y 组件。
我尝试修改上述示例并收到以下错误消息
ValueError:检查模型输入时出错:预期 dense_1_input 的形状为 (None, 2),但得到形状为 (29, 1) 的数组
我的原始数据有一个日期列和一个整数列。
有什么想法吗?
代码
def parser(x)
返回 datetime.strptime(x, ‘%Y-%m-%d’)
# 加载数据集
series = read_csv(‘./data/myData.csv’, header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)
values = series.values
X, Y = values[0:-6], values[-6:]
model = Sequential()
model.add(Dense(5, input_dim=2, activation=’relu’))
model.add(Dense(1, activation=’sigmoid’))
model.compile(optimizer=’sgd’, loss=’mse’)
history = model.fit(X, Y, epochs=1, batch_size=1)
有关如何将 MLP 与时间序列数据一起使用的示例,请参阅此帖子
https://machinelearning.org.cn/time-series-prediction-with-deep-learning-in-python-with-keras/
除了不错的 Keras 概念和教程,你还分享了不错的照片,Jason :)
谢谢,
你的书是 Kindle 和电子书吗?还是在亚马逊上??
祝贺。
Jose Miguel
谢谢 Jose。
我的培训材料是仅在我的网站上提供的 PDF 电子书
https://machinelearning.org.cn/products
为什么隐藏层有 12 个神经元?
反复试验。
这帮不了学习者——你如何决定从何开始?
很好的问题。
一个好的起点是复制文献中应用于类似问题的另一个神经网络。
您可以尝试将隐藏层中的神经元数量等于输入数量。
这些都只是启发式方法,当您测试一系列不同的配置并查看哪种配置最适合您的问题时,才会获得最佳结果。
嗨,Jason,
非常好的文章和简单的教程。谢谢您!
我是 Keras 的新手,我想知道 fit() 函数是否执行一对多训练和评估,还是仅仅在 X 中的所有数据上进行训练并在相同数据上进行评估?
谢谢,
fit() 函数使用提供的数据更新模型。它不评估模型。
非常感谢这个有用的教程,
我正在询问如何将生物特征数据集提供给神经网络进行验证?因为这些数据集由单独的个体(真实和伪造)组成
我应该将数据集分成小块,每个个体一个,并分别测量每个个体的准确性。在这种情况下,我有多个二元分类(2 类)问题,还是应该将所有个体的数据集全部提供给网络?但是如何做呢?
很好的问题。
我的建议是集思广益,为您的问题设计一套不同的框架,然后测试每个框架,看看哪种方法能为您的特定数据集带来最佳的模型技能。
嗨,Jason,感谢您的本教程。
我实现了代码,看到准确率约为 76%。如果我增加层数和/或 epoch 数,它会上升到约 79%。
既然我们在同一数据集上进行训练和评估,难道不应该期望接近 90% 的准确率吗?
损失在哪里?
模型的技能特定于给定的数据集。模型的性能好坏取决于特定建模问题的难度和所选择的建模算法。
嗨,Jason!
我想知道打印的准确度是训练准确度还是验证准确度。我猜是训练准确度,因为我没有看到您分割数据集或进行交叉验证。我如何检查验证准确度?
祝好,
Jenny
您可以将数据拆分为训练/测试集,并在调用 evaluate() 时使用测试数据。
有关如何有效评估深度学习模型的更多信息,请参阅
https://machinelearning.org.cn/evaluate-skill-deep-learning-models/
嘿,谢谢你的这个教程,但我不知道为什么我无法使用上面提到的代码加载 PIMA 数据集。
它抛出错误“OSError: pima-indians-diabetes.csv not found”。
有什么线索为什么会这样吗?
提前感谢您的帮助。
您需要下载数据集并将其放置在与您的代码文件相同的目录中。
你好,
我成功构建、编译并拟合了一个模型,验证误差为 0.15。但是当我预测 x_test 时,它对所有输入都给出了一个恒定值。我尝试了许多变体,例如更改学习率的许多值,但对预测结果没有影响。
你能告诉我为什么 Keras 中会发生这种情况吗?
听起来模型对您的问题欠拟合。
也许可以尝试其他模型配置?
嗨,我有一个疑问。当我用 matlab 训练时,我必须定义训练算法。例如,使用列文伯格-马夸特算法计算梯度。在这种情况下,Keras 如何计算梯度?它使用哪种训练算法?
谢谢。
该算法通过“optimizer”参数指定。仅支持 SGD 的变体。
嗨,Jason,
首先,很喜欢这个教程。
您在这里说,对于回归问题,神经元数量等于输出数量。在您的 Keras 回归教程中,您只用一个神经元解决了具有 13 个输出的回归问题。您是想说神经元应该等于每个训练示例的输出数量吗?
我之所以问,是因为当我将总输出数量作为最后一层神经元数量时,Keras 会抛出错误。错误提示
检查目标时出错:dense_18 预期形状为 (199605,),但得到形状为 (1,) 的数组
谢谢!
如果你想预测 13 个值,你的输出层必须有 13 个节点,并且你的数据必须匹配。
嗨,Jason,感谢您的精彩文章。在 model.fit 方法中,当我们不提供任何 split_validation 参数或 validation_data 时,模型如何验证模型?
好问题。
我们可以在拟合后使用 model.evaluate() 函数评估模型的性能。
嗨,Jason,
与“使用 Keras 分步在 Python 中开发您的第一个神经网络”中的示例相比,为什么这里没有隐藏层:model.add(Dense(8, activation=’relu’))。对于一般的 ANN,这也好吗?
祝好,
克里斯
我们确实有一个隐藏层,也许这会使事情更清楚
https://machinelearning.org.cn/faq/single-faq/how-do-you-define-the-input-layer-in-keras
theano 或 tensoeflow 在 keras 中为 BP 或 adam 进行自动微分吗?怎么做?
Adam 只是一种优化算法。
自动微分用于计算导数,而无需指定如何计算它们,这非常酷。
反向传播是在优化过程中使用自动微分计算的梯度更新模型权重的算法。
.
谢谢你的回复 Jason
从你的回复中我了解到,Keras 的特性是进行自动微分。
我的问题是,我们如何查看或者 Keras 如何进行自动微分以及何时进行?是否有任何链接可以帮助我查看?
Keras 使用 TensorFlow 来执行这些操作。
Keras 和 TensorFlow 的源代码都在 GitHub 上,如果您想逐步查看,可以查阅。
非常感谢您的回复
能给我 github 链接吗?
还有一件事,请澄清一下,Keras 会进行自动微分,BP 在优化过程中使用它来更新权重,我明白了。我的问题是,我们是否仍然需要在代码中使用 BP,还是 Keras 为我们做这件事,并且 Keras 使用框架进行 BP?因为我读过许多其他评论和您的评论都说 Keras 使用 BP 来更新权重,
Keras:https://github.com/keras-team/keras
TF:https://github.com/tensorflow/tensorflow
是的,反向传播用于更新模型权重。
Keras/TF 为您全权处理。
我是说我们不需要在 Keras 中为 BP 编写代码吗?TensorFlow 会做吗
不,这一切都已处理好。
非常感谢您的回复和帮助,
不客气。
嗨,Jason。
感谢您的教程,您的所有内容都非常有帮助。我无法用言语表达我的感谢。
我有一个问题。
我使用 tensorflow 在训练数据(例如 X)上训练了一个深度学习(前馈神经网络)模型,即
model = tf.keras.models.Sequential([……])
现在我想在独立数据集上进行预测?为此我写道
dt = pd.read_csv(‘IndependentData.csv’)
dt=dt.drop([‘Col1’],axis=1)
dt=dt.drop([‘Col2’],axis=1)
X1 = dt.values
predictions=model.predict(X1).round()
#Col1 和 Col2 唯一标识行
但这没有给我预期的输出。(我写的这个对吗?)我想计算混淆矩阵并绘制 AuROC 和 AUPR。如何做到这一点?另外,我想确定独立数据中的哪些行被预测为 TP、TN、FP 和 FN(我不想删除 Col1 和 Col2)。您能帮我如何实现吗?
谢谢。
不客气。
也许这会有帮助。
https://machinelearning.org.cn/how-to-calculate-precision-recall-f1-and-more-for-deep-learning-models/
嗨,Jason。我使用本教程训练了自己的网络,并且对准确率很满意。我正计划使用 Arduino 实现它。我的 Arduino 草图需要训练好的权重来进行前馈传播以进行预测。如何从我的 Keras 训练网络中获取权重?
谢谢
您可以使用 Keras API 保存它们,这里有一个示例
https://machinelearning.org.cn/save-load-keras-deep-learning-models/
谢谢,Jason。我是神经网络的新手,你的博客非常棒。
谢谢!
你好 Jason,
感谢您的帖子。
我想知道偏置单元的问题,Keras 是否理解存在一个偏置单元,或者一个额外的“一”列代表这个偏置。
例如,如果我们有 10 个特征,那么我们的输入维度应该是 10 + 1 (11),还是我们应该保持数组的维度为 input_dim = 10 ( len ( array.shape[1] ) )
偏置输入是每个节点内部的,无需添加任何东西。
最后我得到了这个。这是什么意思?
TypeError: type numpy.ndarray doesn’t define __round__ method
也许您需要更新您的 Python 库版本。
我如何为神经网络使用管道?
感谢您的指导。
我不建议这样做,但您可以将管道与 keras 封装器对象一起使用。
非常重要且有用的信息的简单教程
你的方式非常有帮助
谢谢你