传统的用于机器翻译的编码器-解码器架构将每个源句子编码成一个固定长度的向量,而不管其长度如何,然后解码器再从中生成翻译。这使得神经网络难以处理长句子,实际上导致了性能瓶颈。
Bahdanau注意力机制是为了解决传统编码器-解码器架构的性能瓶颈而提出的,它在传统方法上取得了显著的改进。
在本教程中,您将了解用于神经机器翻译的Bahdanau注意力机制。
完成本教程后,您将了解:
- Bahdanau注意力机制得名的由来以及它解决的挑战
- 构成Bahdanau编码器-解码器架构的各个组件的作用
- Bahdanau注意力算法执行的操作
立即开始您的项目,阅读我的书 《使用注意力机制构建Transformer模型》。它提供了自学教程和工作代码,指导您构建一个功能齐全的Transformer模型,可以
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...
让我们开始吧。

Bahdanau 注意力机制
照片作者:Sean Oulashin,部分权利保留。
教程概述
本教程分为两部分;它们是
- Bahdanau注意力机制简介
- Bahdanau架构
- 编码器
- 解码器
- Bahdanau注意力算法
先决条件
本教程假设您已熟悉以下内容:
Bahdanau注意力机制简介
Bahdanau注意力机制继承了其发表论文的第一作者的名字。
它遵循 Cho等人 (2014) 和 Sutskever等人 (2014) 的工作,他们也采用RNN编码器-解码器框架进行神经机器翻译,特别是将一个可变长度的源句子编码成一个固定长度的向量。后者随后被解码成一个可变长度的目标句子。
Bahdanau等人 (2014) 认为,将可变长度的输入编码成一个固定长度的向量会“压缩”源句子的信息,而不管其长度如何,导致基本编码器-解码器模型的性能随着输入句子长度的增加而迅速下降。他们提出的方法是用一个可变长度的向量替换固定长度的向量,以提高基本编码器-解码器模型的翻译性能。
该方法与基本编码器-解码器最显著的区别在于,它不试图将整个输入句子编码成一个单一的固定长度向量。相反,它将输入句子编码成一系列向量,并在解码翻译时自适应地选择这些向量的子集。
– 神经机器翻译的联合学习对齐和翻译, 2014。
想开始构建带有注意力的 Transformer 模型吗?
立即参加我的免费12天电子邮件速成课程(含示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
Bahdanau架构
Bahdanau编码器-解码器架构使用的主要组成部分如下
- $\mathbf{s}_{t-1}$ 是前一个时间步 $t-1$ 的解码器隐藏状态。
- $\mathbf{c}_t$ 是时间步 $t$ 的上下文向量。它在每个解码器步骤中唯一生成,以生成目标词 $y_t$。
- $\mathbf{h}_i$ 是一个注释,它捕捉了构成整个输入句子 $\{ x_1, x_2, \dots, x_T \}$ 的单词所包含的信息,并重点关注 $T$ 个单词中的第 $i$ 个单词。
- $\alpha_{t,i}$ 是在当前时间步 $t$ 分配给每个注释 $\mathbf{h}_i$ 的权重值。
- $e_{t,i}$ 是由对齐模型 $a(.)$ 生成的注意力得分,该模型对 $\mathbf{s}_{t-1}$ 和 $\mathbf{h}_i$ 的匹配程度进行评分。
这些组件在Bahdanau架构的不同阶段得到应用,该架构在编码器和解码器之间使用了一个双向RNN作为编码器和一个RNN解码器,并在两者之间使用了注意力机制。
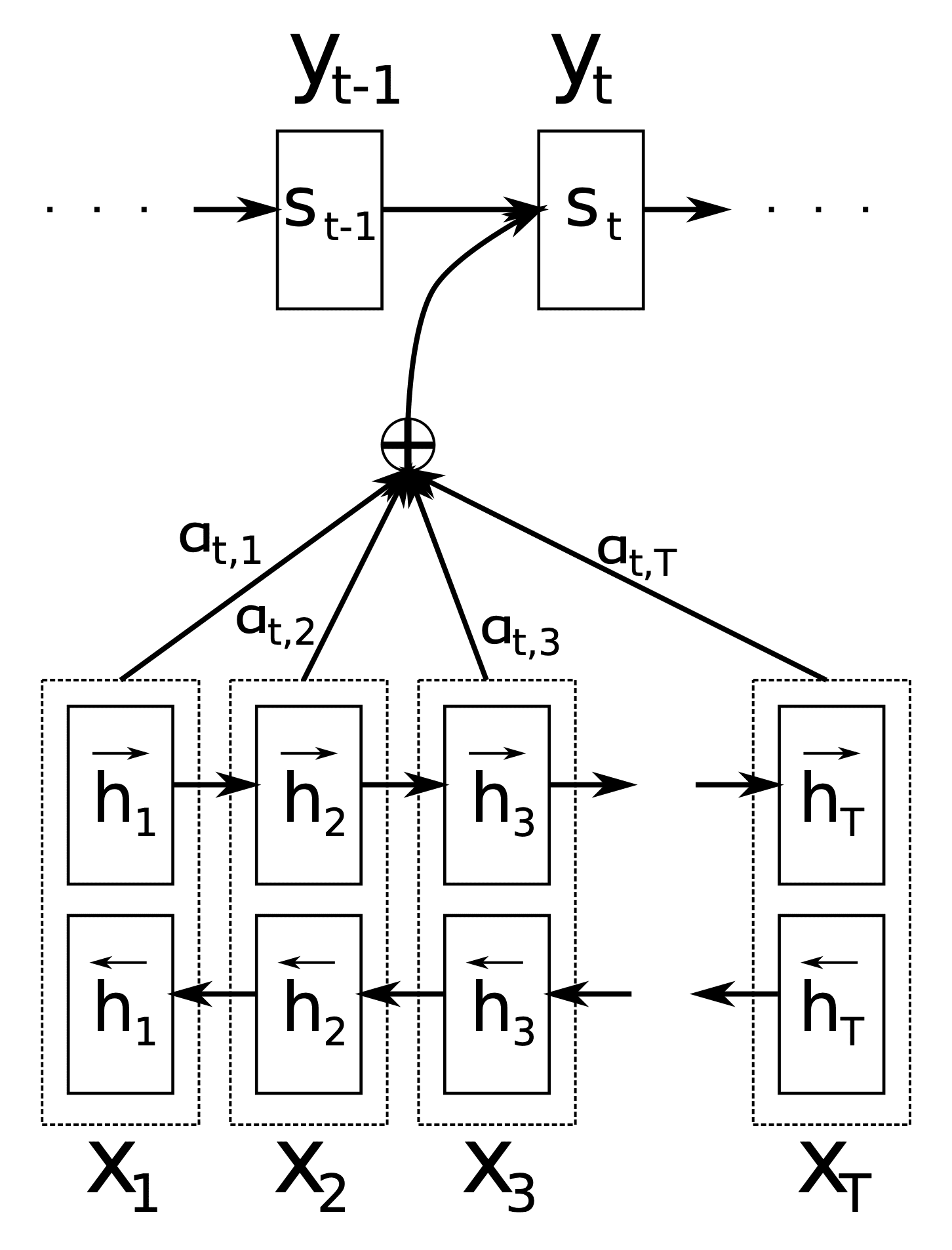
Bahdanau架构
摘自“神经机器翻译的联合学习对齐和翻译”
编码器
编码器的作用是为输入句子中的每个单词 $x_i$ 生成一个注释 $\mathbf{h}_i$(句子长度为 $T$ 个单词)。
为此,Bahdanau等人采用了一个双向RNN,它向前读取输入句子以产生前向隐藏状态 $\overrightarrow{\mathbf{h}_i$,然后向后读取输入句子以产生后向隐藏状态 $\overleftarrow{\mathbf{h}_i$。某个特定单词 $x_i$ 的注释将这两个状态连接起来。
$$\mathbf{h}_i = \left[ \overrightarrow{\mathbf{h}_i^T} \; ; \; \overleftarrow{\mathbf{h}_i^T} \right]^T$$
以这种方式生成每个注释的目的是捕捉前一个和后一个单词的摘要。
这样,注释 $\mathbf{h}_i$ 就包含了前面单词和后面单词的摘要。
– 神经机器翻译的联合学习对齐和翻译, 2014。
然后将生成的注释传递给解码器以生成上下文向量。
解码器
解码器的作用是通过关注源句子中最相关的信息来生成目标单词。为此,它利用了注意力机制。
每次模型生成翻译中的一个单词时,它都会(软)搜索源句子中的一组位置,这些位置集中了最相关的信息。然后,模型根据与这些源位置相关的上下文向量和所有先前生成的目标单词来预测目标单词。
– 神经机器翻译的联合学习对齐和翻译, 2014。
解码器将每个注释馈送到对齐模型 $a(.)$,并结合前一个解码器隐藏状态 $\mathbf{s}_{t-1}$。这会生成一个注意力得分
$$e_{t,i} = a(\mathbf{s}_{t-1}, \mathbf{h}_i)$$
此处对齐模型实现的函数通过加法操作组合了 $\mathbf{s}_{t-1}$ 和 $\mathbf{h}_i$。因此,Bahdanau等人实现的注意力机制被称为加性注意力。
这可以通过两种方式实现:(1) 通过对连接的向量 $\mathbf{s}_{t-1}$ 和 $\mathbf{h}_i$ 应用权重矩阵 $\mathbf{W}$,或者 (2) 通过分别将权重矩阵 $\mathbf{W}_1$ 和 $\mathbf{W}_2$ 应用于 $\mathbf{s}_{t-1}$ 和 $\mathbf{h}_i$。
- $$a(\mathbf{s}_{t-1}, \mathbf{h}_i) = \mathbf{v}^T \tanh(\mathbf{W}[\mathbf{h}_i \; ; \; \mathbf{s}_{t-1}])$$
- $$a(\mathbf{s}_{t-1}, \mathbf{h}_i) = \mathbf{v}^T \tanh(\mathbf{W}_1 \mathbf{h}_i + \mathbf{W}_2 \mathbf{s}_{t-1})$$
此处 $\mathbf{v}$ 是一个权重向量。
对齐模型被参数化为一个前馈神经网络,并与其余系统组件一起联合训练。
随后,将softmax函数应用于每个注意力得分,以获得相应的权重值
$$\alpha_{t,i} = \text{softmax}(e_{t,i})$$
softmax函数的应用基本上将注释值归一化到0到1的范围内;因此,得到的权重可以被视为概率值。每个概率(或权重)值反映了 $\mathbf{h}_i$ 和 $\mathbf{s}_{t-1}$ 在生成下一个状态 $\mathbf{s}_t$ 和下一个输出 $y_t$ 中的重要性。
直观地说,这在解码器中实现了一个注意力机制。解码器决定了源句子中需要关注的部分。通过让解码器拥有一个注意力机制,我们减轻了编码器必须将源句子中的所有信息编码成固定长度向量的负担。
– 神经机器翻译的联合学习对齐和翻译, 2014。
最后,通过计算注释的加权和来计算上下文向量
$$\mathbf{c}_t = \sum^T_{i=1} \alpha_{t,i} \mathbf{h}_i$$
Bahdanau注意力算法
总而言之,Bahdanau等人提出的注意力算法执行以下操作
- 编码器从输入句子生成一组注释 $\mathbf{h}_i$。
- 这些注释被馈送到对齐模型和前一个解码器隐藏状态。对齐模型利用这些信息生成注意力得分 $e_{t,i}$。
- 将softmax函数应用于注意力得分,有效地将其归一化为0到1之间的权重值 $\alpha_{t,i}$。
- 这些权重与先前计算的注释一起,通过注释的加权和用于生成上下文向量 $\mathbf{c}_t$。
- 上下文向量与前一个解码器隐藏状态和前一个输出一起被馈送到解码器,以计算最终输出 $y_t$。
- 步骤2-6重复执行,直到序列结束。
Bahdanau等人将他们的架构应用于英译法任务。他们报告说,无论句子长度如何,他们的模型都显著优于传统的编码器-解码器模型。
Bahdanau注意力机制已经提出了几项改进,例如 Luong等人 (2015) 的改进,我们将在另一篇教程中回顾。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
- 使用 Python 进行高级深度学习, 2019.
论文
- 通过联合学习对齐和翻译的神经机器翻译, 2014.
总结
在本教程中,您了解了用于神经机器翻译的Bahdanau注意力机制。
具体来说,你学到了:
- Bahdanau注意力机制得名的由来以及它解决的挑战。
- 构成Bahdanau编码器-解码器架构的各个组件的作用
- Bahdanau注意力算法执行的操作
你有什么问题吗?
在下面的评论中提出您的问题,我将尽力回答。
学习 Transformer 和注意力!

教您的深度学习模型阅读句子
...使用带有注意力的 Transformer 模型
在我的新电子书中探索如何实现
使用注意力机制构建 Transformer 模型
它提供了自学教程和可运行代码,指导您构建一个可以
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...






非常感谢machinelearningmastery。一切都经过了充分的研究和解释。我一直都在搜索你的文章,因为它们能清除所有疑问,而且信息很容易掌握。再次感谢!!!!!!!!!! 🙂
谢谢。很高兴你喜欢。
感谢您的帖子。您能否提供一个使用带Bahdanau注意力机制的编码器-解码器进行时间序列预测的示例代码?谢谢。
你好Binata…以下资源可能会让你感兴趣
https://www.kaggle.com/code/kmkarakaya/encoder-decoder-with-bahdanau-luong-attention
什么都看不懂,反而更糊涂了!!
你好Partha…这是一个具有挑战性的话题!坚持下去,继续学习。以下资源有很好的例子,你可以从中学习以获得更好的理解
https://machinelearning.org.cn/transformer-models-with-attention/
这是一个很好的解释,但是得分计算中的v是什么?它的作用从未被解释过。它似乎没有必要,也没有提供解释。奇怪的是,我在大多数在线注意力教程中也看不到对它的很多解释。它总是神奇地出现,并被手挥得像一个学到的权重。但是为什么呢?权重不是已经由W处理了吗?它似乎是多余的。