注意力是一个跨多个学科科学研究的概念,包括心理学、神经科学以及最近的机器学习。虽然所有学科可能都有自己对注意力的定义,但它们都认可的一个核心品质是,注意力是使生物和人工神经系统更灵活的机制。
在本教程中,您将发现注意力研究进展的概述。
完成本教程后,您将了解:
- 对不同科学学科具有重要意义的注意力概念
- 注意力如何彻底改变机器学习,特别是在自然语言处理和计算机视觉领域
通过我的书籍《使用注意力构建 Transformer 模型》启动您的项目。它提供了自学教程和可运行代码,指导您构建一个可以
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...
让我们开始吧。

注意力研究概览
图片由 Chris Lawton 拍摄,保留部分权利。
教程概述
本教程分为两部分;它们是
- 注意力的概念
- 机器学习中的注意力
- 自然语言处理中的注意力
- 计算机视觉中的注意力
注意力的概念
注意力研究起源于心理学领域。
注意力的科学研究始于心理学,通过细致的行为实验,可以精确地展示注意力在不同环境下的倾向和能力。
– 《心理学、神经科学和机器学习中的注意力》, 2020。
从这些研究中得出的观察结果可以帮助研究人员推断这些行为模式背后的心理过程。
尽管心理学、神经科学以及最近的机器学习等不同领域都提出了自己对注意力的定义,但有一个核心品质对所有这些领域都具有重要意义
注意力是对有限计算资源的灵活控制。
– 《心理学、神经科学和机器学习中的注意力》, 2020。
考虑到这一点,以下部分将回顾注意力在彻底改变机器学习领域方面的作用。
机器学习中的注意力
机器学习中的注意力概念是受到人脑中注意力的心理机制“非常”松散的启发。
在人工神经网络中使用注意力机制——就像大脑中对注意力的明显需求一样——是为了使神经系统更具灵活性。
– 《心理学、神经科学和机器学习中的注意力》, 2020。
其思想是能够使用一种人工神经网络,该网络能够很好地执行输入可能具有可变长度、大小或结构,甚至处理多种不同任务的任务。正是本着这种精神,机器学习中的注意力机制被认为是从心理学中汲取灵感,而不是因为它们复制了人脑的生物学结构。
在最初为人工神经网络开发的注意力形式中,注意力机制在编码器-解码器框架内和序列模型的背景下工作……
– 《心理学、神经科学和机器学习中的注意力》, 2020。
编码器的任务是生成输入的向量表示,而解码器的任务是将此向量表示转换为输出。注意力机制将两者连接起来。
已经有不同的神经网络架构方案实现了注意力机制,这些方案也与它们所使用的特定应用紧密相关。自然语言处理(NLP)和计算机视觉是其中最受欢迎的应用。
自然语言处理中的注意力
注意力在自然语言处理中的一个早期应用是机器翻译,目标是将源语言的输入句子翻译成目标语言的输出句子。在此背景下,编码器将生成一组*上下文*向量,源句子中的每个单词对应一个。另一方面,解码器将读取上下文向量,每次生成目标语言中的一个单词。
在传统的没有注意力的编码器-解码器框架中,编码器产生一个固定长度的向量,该向量独立于输入的长度或特征,并且在解码过程中是静态的。
– 《心理学、神经科学和机器学习中的注意力》, 2020。
用固定长度向量表示输入对于长序列或结构复杂的序列来说尤其成问题,因为它们的表示维度被迫与更短或更简单的序列相同。
例如,在某些语言(如日语)中,最后一个单词对于预测第一个单词可能非常重要,而将英语翻译成法语可能更容易,因为句子的顺序(句子的组织方式)彼此更相似。
– 《心理学、神经科学和机器学习中的注意力》, 2020。
这造成了一个瓶颈,即解码器对输入信息(固定长度编码向量中可用的信息)的访问受限。另一方面,在编码过程中保留输入序列的长度可以使解码器以灵活的方式利用其最相关的部分。
后者是注意力机制的运作方式。
注意力有助于确定应使用这些向量中的哪些来生成输出。由于输出序列是每次动态生成一个元素的,因此注意力可以在每个时间点动态地突出显示不同的编码向量。这使得解码器能够灵活地利用输入序列中最相关的部分。
– 第186页,《深度学习要点》,2018年。
机器翻译中最早解决固定长度向量瓶颈问题的工作之一是 Bahdanau 等人 (2014)。在他们的工作中,Bahdanau 等人将循环神经网络 (RNN) 用于编码和解码任务:编码器使用双向 RNN 生成一系列*注释*,每个注释都包含前一个和后一个单词的摘要,这些摘要可以通过加权和映射到*上下文*向量中;然后解码器根据这些注释和另一个 RNN 的隐藏状态生成输出。由于上下文向量是通过注释的加权和计算的,因此 Bahdanau 等人的注意力机制是*软注意力*的一个例子。
另一项早期工作是 Sutskever 等人 (2014)。他们转而使用多层长短期记忆 (LSTM) 来编码表示输入序列的向量,并使用另一个 LSTM 将该向量解码为目标序列。
Luong 等人 (2015) 引入了*全局*注意力与*局部*注意力的概念。在他们的工作中,他们将全局注意力模型描述为在推导上下文向量时考虑编码器所有隐藏状态的模型。因此,全局上下文向量的计算基于源序列中*所有*单词的加权平均值。Luong 等人提到,这在计算上是昂贵的,并且可能使全局注意力难以应用于长序列。为了解决这个问题,他们提出了局部注意力,通过每个目标单词专注于源序列中较小的单词子集。Luong 等人解释说,局部注意力在 Xu 等人 (2016) 的*软*注意力和*硬*注意力模型之间做出了权衡(我们将在下一节再次提到这篇论文),它在计算上比软注意力更便宜,但比硬注意力更容易训练。
最近,Vaswani 等人 (2017) 提出了一种完全不同的架构,将机器翻译领域引向了一个新方向。他们的架构被称为“Transformer”,它完全摒弃了循环和卷积,但实现了*自注意力*机制。源序列中的单词首先并行编码以生成键、查询和值表示。键和查询结合起来生成注意力权重,这些权重捕捉了序列中每个单词与其他单词的关系。然后,这些注意力权重用于缩放值,以便将焦点保留在重要单词上,并消除不相关的单词。
输出被计算为值的加权和,其中分配给每个值的权重由查询与相应键的兼容性函数计算。
– 《注意力就是你所需要的一切》,2017。
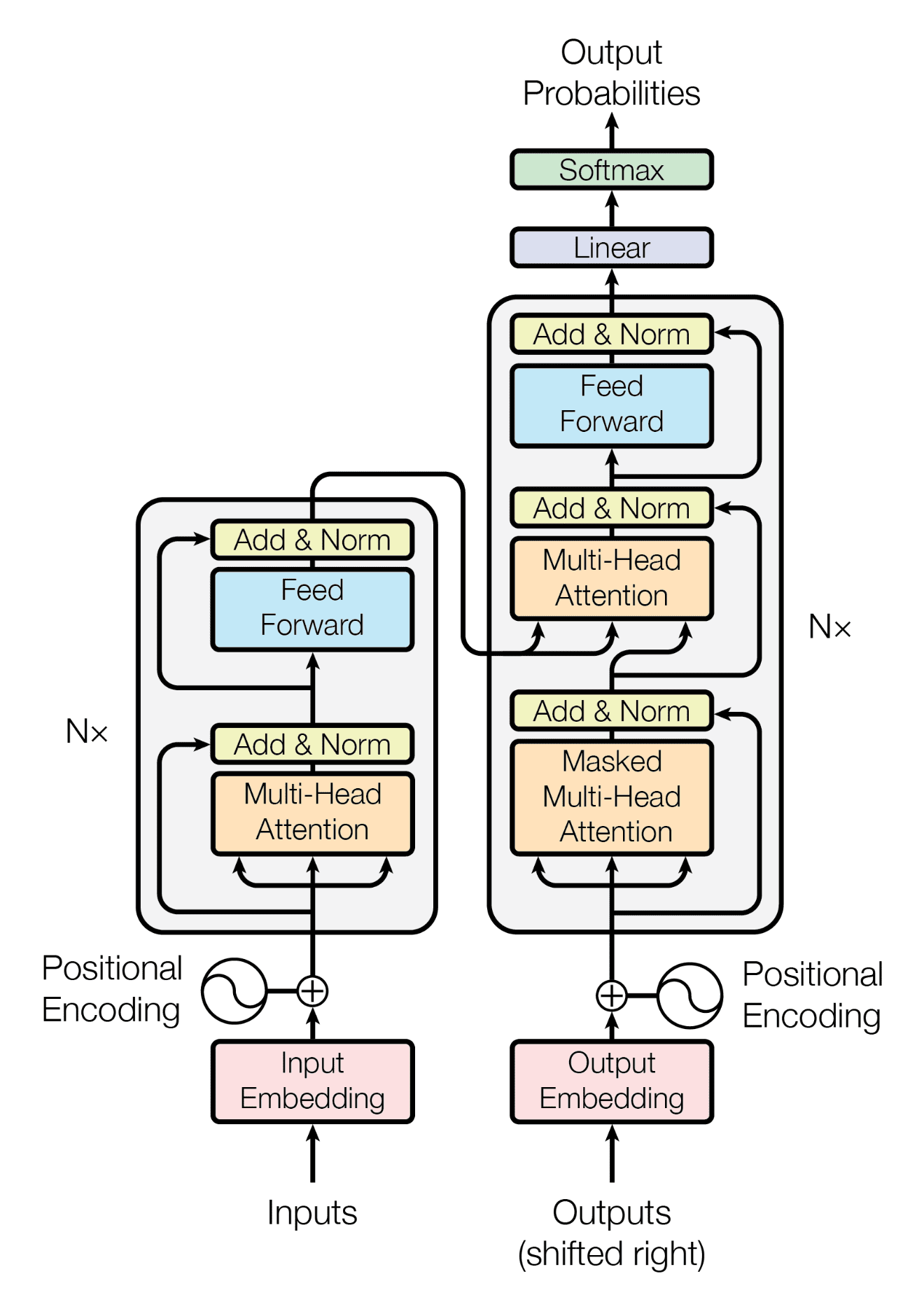
Transformer 架构
摘自《注意力就是你所需要的一切》
当时,提出的 Transformer 架构为英语到德语和英语到法语的翻译任务建立了新的最先进流程。据报道,它的训练速度也比基于循环或卷积层的架构更快。随后,Devlin 等人 (2019) 提出的名为 BERT 的方法在 Vaswani 等人的工作基础上,提出了一种多层双向架构。
正如我们很快将看到的,Transformer 架构不仅在自然语言处理领域得到迅速采用,在计算机视觉领域也同样如此。
计算机视觉中的注意力
在计算机视觉中,注意力已应用于多个领域,例如图像分类、图像分割和图像字幕生成。
例如,如果我们将编码器-解码器模型重新定义为图像字幕任务,那么编码器可以是一个卷积神经网络 (CNN),它将图像中显著的视觉线索捕获为向量表示。而解码器可以是一个 RNN 或 LSTM,将向量表示转换为输出。
此外,与神经科学文献中一样,这些注意力过程可以分为空间注意力和基于特征的注意力。
– 《心理学、神经科学和机器学习中的注意力》, 2020。
在*空间*注意力中,不同的空间位置被赋予不同的权重。然而,这些相同的权重在不同空间位置的所有特征通道中都得到保留。
Xu 等人 (2016) 提出了一种利用空间注意力的图像字幕生成基础方法。他们的模型包含一个 CNN 作为编码器,该编码器提取一组特征向量(或*注释*向量),每个向量对应图像的不同部分,以便解码器能够选择性地关注特定的图像部分。解码器是一个 LSTM,它根据上下文向量、先前的隐藏状态和先前生成的单词来生成字幕。Xu 等人研究了在计算上下文向量时使用*硬注意力*作为软注意力的替代方案。这里,软注意力*柔和地*将权重放置在源图像的所有补丁上,而硬注意力只关注单个补丁,而忽略其余部分。他们报告说,在他们的工作中,硬注意力表现更好。
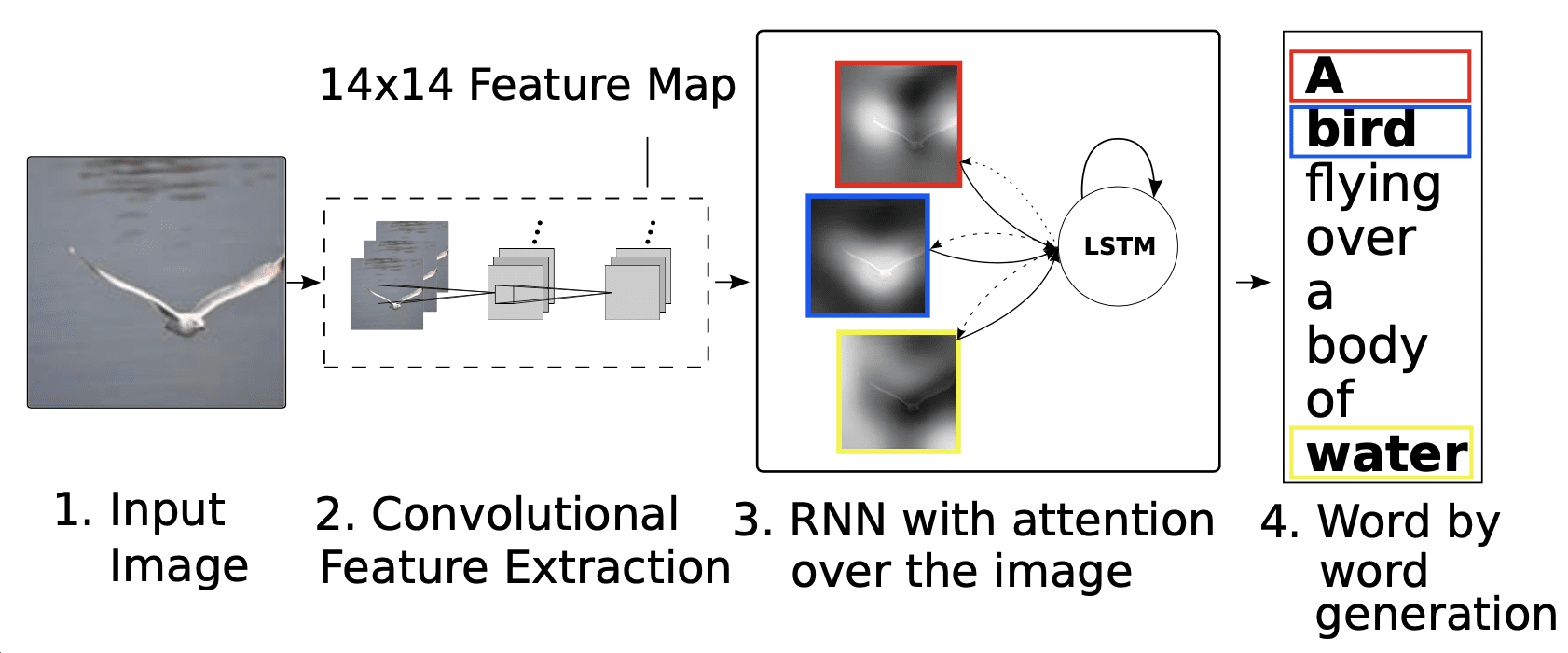
图像字幕生成模型
摘自《展示、关注与讲述:基于视觉注意力的神经图像字幕生成》
相比之下,*特征*注意力允许每个特征图被赋予自己的权重值。一个应用于图像字幕的例子是 Chen 等人 (2018) 的编码器-解码器框架,它在同一个 CNN 中结合了空间和通道注意力。
与 Transformer 迅速成为自然语言处理任务的标准架构类似,它最近也已被计算机视觉社区采纳和改编。
最早这样做的研究是由 Dosovitskiy 等人 (2020) 提出的,他们将自己的*视觉 Transformer* (ViT) 应用于图像分类任务。他们认为,长期以来对 CNN 进行图像分类的依赖并非必要,同样的任务可以通过纯 Transformer 完成。Dosovitskiy 等人将输入图像重新塑形为一系列扁平化的 2D 图像块,然后通过可训练的线性投影进行嵌入,以生成*块嵌入*。这些块嵌入,连同其*位置嵌入*(用于保留位置信息),被馈送到 Transformer 架构的编码器部分,其输出随后被馈送到多层感知器 (MLP) 进行分类。

视觉 Transformer 架构
摘自《图像价值16×16个词:用于大规模图像识别的 Transformer》
受 ViT 的启发,以及基于注意力的架构是建模视频中长程上下文关系的直观选择这一事实,我们开发了几种基于 Transformer 的视频分类模型。
– 《ViViT:视频视觉 Transformer》,2021年。
Arnab 等人 (2021) 随后将 ViT 模型扩展到 ViViT,该模型利用视频中包含的时空信息进行视频分类任务。他们的方法探索了提取时空数据的不同方法,例如通过独立采样和嵌入每一帧,或通过提取不重叠的管状体(一种跨越多个图像帧的图像块,形成一个*管*)并依次嵌入每个管状体。他们还研究了不同的方法来分解输入视频的空间和时间维度,以提高效率和可扩展性。

视频视觉 Transformer 架构
摘自《ViViT:视频视觉 Transformer》
正确性 · 重
在图像分类的首次应用中,视觉 Transformer 已经应用于多个其他计算机视觉领域,例如动作定位、凝视估计和图像生成。计算机视觉从业者对此的兴趣激增预示着一个激动人心的近期未来,我们将看到更多 Transformer 架构的改编和应用。
想开始构建带有注意力的 Transformer 模型吗?
立即参加我的免费12天电子邮件速成课程(含示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
- 深度学习要点, 2018.
论文
- 心理学、神经科学和机器学习中的注意力, 2020.
- 通过联合学习对齐和翻译的神经机器翻译, 2014.
- 使用神经网络进行序列到序列学习, 2014.
- 基于注意力的神经机器翻译的有效方法, 2015.
- 注意力就是你所需要的一切, 2017.
- BERT:用于语言理解的深度双向 Transformer 预训练, 2019.
- 展示、关注和讲述:带视觉注意力的神经图像标题生成, 2016.
- SCA-CNN:用于图像字幕生成的卷积网络中的空间和通道注意力, 2018.
- 图像价值16×16个词:用于大规模图像识别的 Transformer, 2020.
- ViViT:视频视觉 Transformer, 2021.
应用示例
- 时空动作定位中的关系建模, 2021.
- 使用 Transformer 进行凝视估计, 2021.
- ViTGAN:使用视觉 Transformer 训练 GAN, 2021.
总结
在本教程中,您了解了注意力研究进展的概述。
具体来说,你学到了:
- 对不同科学学科具有重要意义的注意力概念
- 注意力如何彻底改变机器学习,特别是在自然语言处理和计算机视觉领域
你有什么问题吗?
在下面的评论中提出您的问题,我将尽力回答。
学习 Transformer 和注意力!

教您的深度学习模型阅读句子
...使用带有注意力的 Transformer 模型
在我的新电子书中探索如何实现
使用注意力机制构建 Transformer 模型
它提供了自学教程和可运行代码,指导您构建一个可以
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...






写得非常好!
谢谢你
精彩又令人兴奋的撰写。谢谢!
几个问题
是否有 –
1) Python 中用于 NLP 目的的 Transformer 库,我们可以在哪里找到它们?
2) 目前最先进的 NLP Transformer 是什么?
3) 我们如何在 Python 中从头开始学习构建 Transformer(用于 NLP 目的)?
祝好,
注意力最早是由 Google 的一篇论文提出的。因此我相信您可以查阅一些 TensorFlow 库。希望有所帮助!
您还应该包括注意力机制在时间序列预测中的应用。
感谢您这篇精彩的博客。
感谢您的建议!
先生,
您的 Transformer 书什么时候出版?
尚未确定日期。我们将在未来公布!