正如我们学习了 Transformer 模型是什么 以及如何 训练 Transformer 模型,我们注意到它是一个让计算机理解人类语言的强大工具。然而,Transformer 最初被设计为一种将一种语言翻译成另一种语言的模型。如果我们将其用于不同的任务,可能需要从头开始重新训练整个模型。考虑到训练 Transformer 模型所需的时间非常巨大,我们希望有一个解决方案能够让我们为许多不同的任务轻松复用已训练好的 Transformer。BERT 就是这样一个模型。它是 Transformer 的编码器部分的扩展。
在本教程中,您将了解 BERT 是什么,并发现它能做什么。
完成本教程后,您将了解:
- 什么是 Transformer 的双向编码器表示 (BERT)
- BERT 模型如何能为不同目的而复用
- 如何使用预训练的 BERT 模型
通过我的书《构建带有注意力机制的 Transformer 模型》,快速启动您的项目。它提供了自学教程和可运行的代码,指导您构建一个功能齐全的 Transformer 模型,该模型可以
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...
让我们开始吧。

BERT 简介
照片由 Samet Erköseoğlu 拍摄,部分权利保留。
教程概述
本教程分为四个部分;它们是
- 从 Transformer 模型到 BERT
- BERT 能做什么?
- 使用预训练的 BERT 模型进行文本摘要
- 使用预训练的 BERT 模型进行问答
先决条件
本教程假设您已熟悉以下内容:
从 Transformer 模型到 BERT
在 Transformer 模型中,编码器和解码器连接起来构成一个 seq2seq 模型,以便您执行翻译,例如从英语到德语,如您之前所见。回想一下,注意力方程是这样说的:
$$\text{attention}(Q,K,V) = \text{softmax}\Big(\frac{QK^\top}{\sqrt{d_k}}\Big)V$$
但上面的每个 Q、K 和 V 都是通过 Transformer 模型中的权重矩阵转换的嵌入向量。训练 Transformer 模型意味着找到这些权重矩阵。一旦权重矩阵被学习,Transformer 就成为一个语言模型,这意味着它代表了一种理解您用来训练它的语言的方式。
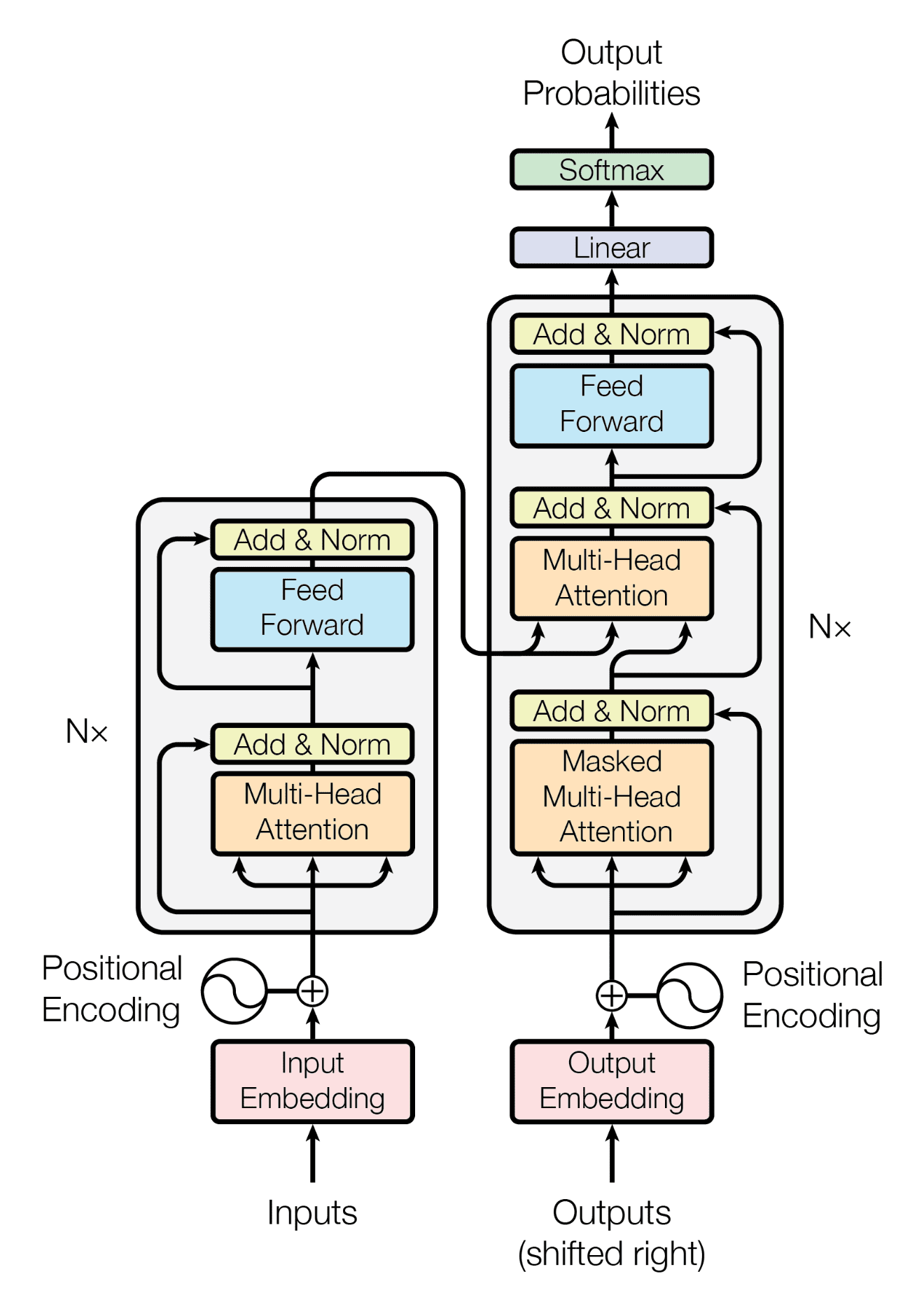
Transformer 架构的编码器-解码器结构
摘自“Attention Is All You Need”
Transformer 具有编码器和解码器部分。顾名思义,编码器将句子和段落转换为内部格式(数字矩阵),该格式能够理解上下文;而解码器则执行相反的操作。结合编码器和解码器可以使 Transformer 执行 seq2seq 任务,例如翻译。如果您去掉 Transformer 的编码器部分,它可以告诉您一些关于上下文的信息,这可以做一些有趣的事情。
Transformer 的双向编码器表示 (BERT) 利用注意力模型来更深入地理解语言上下文。BERT 是许多编码器块的堆栈。输入文本被分成 token,与 Transformer 模型中的一样,每个 token 在 BERT 输出时都会被转换为一个向量。
BERT 能做什么?
BERT 模型通过掩码语言模型 (MLM) 和下一句预测 (NSP) 同时进行训练。
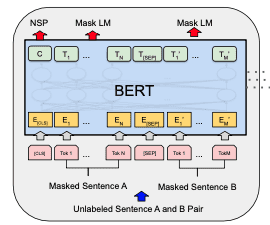
BERT 模型
BERT 的每个训练样本都是来自文档的一对句子。这两个句子可以在文档中是连续的,也可以不是。在第一个句子前会加上一个 [CLS] token(代表类别),并在每个句子后加上一个 [SEP] token(作为分隔符)。然后,这两个句子将被连接成一个 token 序列,成为一个训练样本。训练样本中的一小部分 token 会被一个特殊的 token [MASK]掩盖,或者被替换成一个随机 token。
在输入 BERT 模型之前,训练样本中的 token 将被转换为嵌入向量,并添加位置编码,特别的是,BERT 还添加了句子嵌入,以标记 token 是来自第一个还是第二个句子。
BERT 模型的每个输入 token 都会产生一个输出向量。在一个训练良好的 BERT 模型中,我们期望:
- 与掩盖 token 对应的输出可以揭示原始 token 是什么
- 与开头
[CLS]token 对应的输出可以揭示这两个句子在文档中是否连续
那么,BERT 模型中训练的权重就能很好地理解语言上下文。
一旦有了这样的 BERT 模型,您就可以将其用于许多下游任务。例如,在编码器顶部添加一个合适的分类层,而不是输入一对句子,只输入一个句子到模型,您就可以将类别 token [CLS] 作为输入进行情感分类。这是有效的,因为类别 token 的输出被训练成聚合整个输入的注意力。
另一个例子是将一个问题作为第一个句子,将文本(例如段落)作为第二个句子,然后第二个句子中的输出 token 可以标记答案在文本中出现的位置。这是有效的,因为每个 token 的输出都揭示了关于该 token 在整个输入上下文中的一些信息。
使用预训练的 BERT 模型进行文本摘要
Transformer 模型从头开始训练需要很长时间。BERT 模型需要的时间更长。但 BERT 的目的是创建一个可以为许多不同任务复用的模型。
有一些可以立即使用的预训练 BERT 模型。下面您将看到一些用例。以下示例中使用的文本来自
理论上,BERT 模型是一个编码器,它将每个输入 token 映射到一个输出向量,该向量可以扩展到无限长度的 token 序列。实际上,其他组件的实现会施加限制,限制输入大小。通常,几百个 token 应该就可以了,因为并非所有实现都可以一次处理数千个 token。您可以将整篇文章保存在 article.txt(副本可在 此处获取)。如果您的模型需要较短的文本,您可以使用其中的几段。
首先,让我们探索文本摘要任务。使用 BERT,想法是从原始文本中提取几个代表整个文本的句子。您可以看到此任务类似于下一句预测,其中给定一个句子和一段文本,您想分类它们是否相关。
为此,您需要使用 Python 模块 bert-extractive-summarizer
|
1 |
pip install bert-extractive-summarizer |
它是 Hugging Face 模型的一个包装器,提供摘要任务的流水线。Hugging Face 是一个允许您发布机器学习模型(主要针对 NLP 任务)的平台。
安装 bert-extractive-summarizer 后,生成摘要只需几行代码
|
1 2 3 4 5 |
from summarizer import Summarizer text = open("article.txt").read() model = Summarizer('distilbert-base-uncased') result = model(text, num_sentences=3) print(result) |
输出如下:
|
1 2 3 4 5 6 7 8 |
在英国首相莉兹·特拉斯任期短暂的政府的政治动荡中,英格兰银行发现自己处于财政金融的十字路口。无论下一个政府是谁,英国央行吸取正确的教训至关重要。根据英国央行金融稳定部副行长乔恩·坎利夫的声明,货币政策委员会(MPC)只是“获悉了国债市场的相关问题,并在行动前得到简报,包括其金融稳定理由以及购买的暂时性和针对性”。 简短的政府,英格兰银行发现自己身处财政金融的交叉火力之中。无论哪个政府接任,英国央行吸取教训至关重要。根据英格兰银行金融稳定部副行长乔恩·坎利夫的声明,货币政策委员会(MPC)只是“获悉了国债市场的相关问题,并在行动前得到简报,包括其金融稳定理由以及购买的暂时性和针对性”。 无论哪个政府接任,英国央行吸取教训至关重要。根据英国央行金融稳定部副行长乔恩·坎利夫的声明,货币政策委员会(MPC)只是“获悉了国债市场的相关问题,并在行动前得到简报,包括其金融稳定理由以及购买的暂时性和针对性”。 根据英国央行金融稳定部副行长乔恩·坎利夫的声明,货币政策委员会(MPC)只是“获悉了国债市场的相关问题,并在行动前得到简报,包括其金融稳定理由以及购买的暂时性和针对性”。 国债市场的相关问题,并在行动前得到简报,包括其金融稳定理由以及购买的暂时性和针对性”。 包括其金融稳定理由以及购买的暂时性和针对性”。 购买的暂时性和针对性”。 针对性”。 |
这就是全部代码!在后台,spaCy 用于一些预处理,Hugging Face 用于启动模型。使用的模型名为 distilbert-base-uncased。DistilBERT 是一个简化的 BERT 模型,可以运行得更快,占用内存更少。该模型是“不区分大小写”的,这意味着一旦输入文本被转换为嵌入向量,其大小写将被视为相同。
摘要器模型的输出是一个字符串。由于在调用模型时指定了 num_sentences=3,因此摘要是文本中选取的三个句子。这种方法称为抽取式摘要。另一种方法是生成式摘要,即摘要是生成的,而不是从文本中提取的。这需要一个不同于 BERT 的模型。
想开始构建带有注意力的 Transformer 模型吗?
立即参加我的免费12天电子邮件速成课程(含示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
使用预训练的 BERT 模型进行问答
BERT 的另一个示例是匹配问题和答案。您将问题和文本都提供给模型,并查看文本中答案开头和结尾的输出。
一个简单的例子只需几行代码,使用与上一个示例相同的示例文本
|
1 2 3 4 5 6 7 |
from transformers import pipeline text = open("article.txt").read() question = "What is BOE doing?" answering = pipeline("question-answering", model='distilbert-base-uncased-distilled-squad') result = answering(question=question, context=text) print(result) |
这里直接使用了 Hugging Face。如果您安装了上一个示例中使用的模块,那么 Hugging Face Python 模块是您已经安装的依赖项。否则,您可能需要使用 pip 进行安装:
|
1 |
pip install transformers |
并且要实际使用 Hugging Face 模型,您还需要同时安装 PyTorch 和 TensorFlow
|
1 |
pip install torch tensorflow |
上面的代码输出是一个 Python 字典,如下所示:
|
1 2 3 4 |
{'score': 0.42369240522384644, 'start': 1261, 'end': 1344, 'answer': 'to maintain or restore market liquidity in systemically important\nfinancial markets'} |
这是您找到答案(它是输入文本中的一个句子)以及答案在 token 顺序中的起始和结束位置的地方。分数可以被认为是模型对答案是否符合问题的置信度分数。
在幕后,模型所做的是为回答问题的最佳起始位置生成一个概率分数,以及最佳结束位置的文本。然后,通过查找最高概率的位置来提取答案。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- 注意力就是你所需要的一切, 2017
- BERT:面向语言理解的深度双向 Transformer 的预训练, 2019
- DistilBERT,BERT 的蒸馏版本:更小、更快、更便宜、更轻巧, 2019
总结
在本教程中,您了解了 BERT 是什么以及如何使用预训练的 BERT 模型。
具体来说,你学到了:
- BERT 如何作为 Transformer 模型的扩展而创建
- 如何使用预训练的 BERT 模型进行抽取式文本摘要和问答
学习 Transformer 和注意力!

教您的深度学习模型阅读句子
...使用带有注意力的 Transformer 模型
在我的新电子书中探索如何实现
使用注意力机制构建 Transformer 模型
它提供了自学教程和可运行代码,指导您构建一个可以
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...



 with a BERT Model")


感谢分享这篇帖子。帖子中的大部分内容我都能理解,特别是演示部分让我印象深刻。不过我也有一个问题。如果我没记错的话,Transformer 机制通过对从现有文本解码出的 QKV 向量进行操作来执行自注意力。注意力是 QKV 操作高值的聚合结果。然后,我遇到了一个问题:
“例如,在编码器顶部添加一个合适的分类层,并将单个句子作为输入提供给模型,而不是一对句子,您就可以将类别 token [CLS] 作为输入进行情感分类。这是有效的,因为类别 token 的输出被训练成聚合整个输入的注意力。”
我猜测类别 token 的输出会生成 QKV 向量,使其能够从 attention(Q, K, V) 操作中获得最高值。如果真是这样,那么这些与其它 token 高度亲和的类别 token 的存在,是否会破坏文本生成过程?因为这些类别 token 与其它 token 高度亲和,它们在 BERT 输出中的出现频率会很高。