Transformer 是一种流行的自然语言处理(NLP)深度学习架构。它是一种旨在处理文本等序列数据的神经网络。在本文中,我们将探讨注意力机制和 Transformer 架构的概念。具体来说,您将了解:
- Transformer 模型解决什么问题
- 注意力机制与 Transformer 模型的关系
- Transformer 模型有哪些不同的变体
让我们开始吧!

注意力机制和 Transformer 模型简介
照片作者:Andre Benz。部分权利保留。
概述
这篇博文分为三部分;它们是:
- Transformer 模型起源
- Transformer 架构
- Transformer 架构的变体
Transformer 模型起源
Transformer 架构起源于 Vaswani 等人于 2017 年发表的论文“Attention Is All You Need”。它与传统神经网络的不同之处在于,它使用自注意力机制来处理输入数据。自注意力机制允许模型根据任务需求,关注输入数据的不同部分。
Transformer 架构解决了循环神经网络 (RNN) 的局限性。RNN 被期望处理输入序列,例如向量序列。相同的网络架构被反复用于处理序列的每个元素。在网络内部,使用了一些记忆机制。记忆会随着每一步的更新,代表迄今为止看到的序列。
RNN 在 NLP 任务中很有用,例如 seq2seq 架构,用于翻译自然语言。然而,由于 RNN 一次处理一个元素,当处理序列的最后一个元素时,网络很难记住第一个元素传递的信息,特别是当序列任意长时。
Transformer 架构中的解决方案是使用自注意力机制一次性处理整个序列。序列的每个元素都可以“看到”序列中的所有元素,模型可以从中提取上下文信息。因此,Transformer 架构可以表现得更好。此外,注意力机制的性质使得计算更具并行性,因为与 RNN 不同,序列的一个元素对应的输出不依赖于序列其他元素对应的输出。
Transformer 架构
原始的 Transformer 架构由编码器和解码器组成。其布局如下图所示。
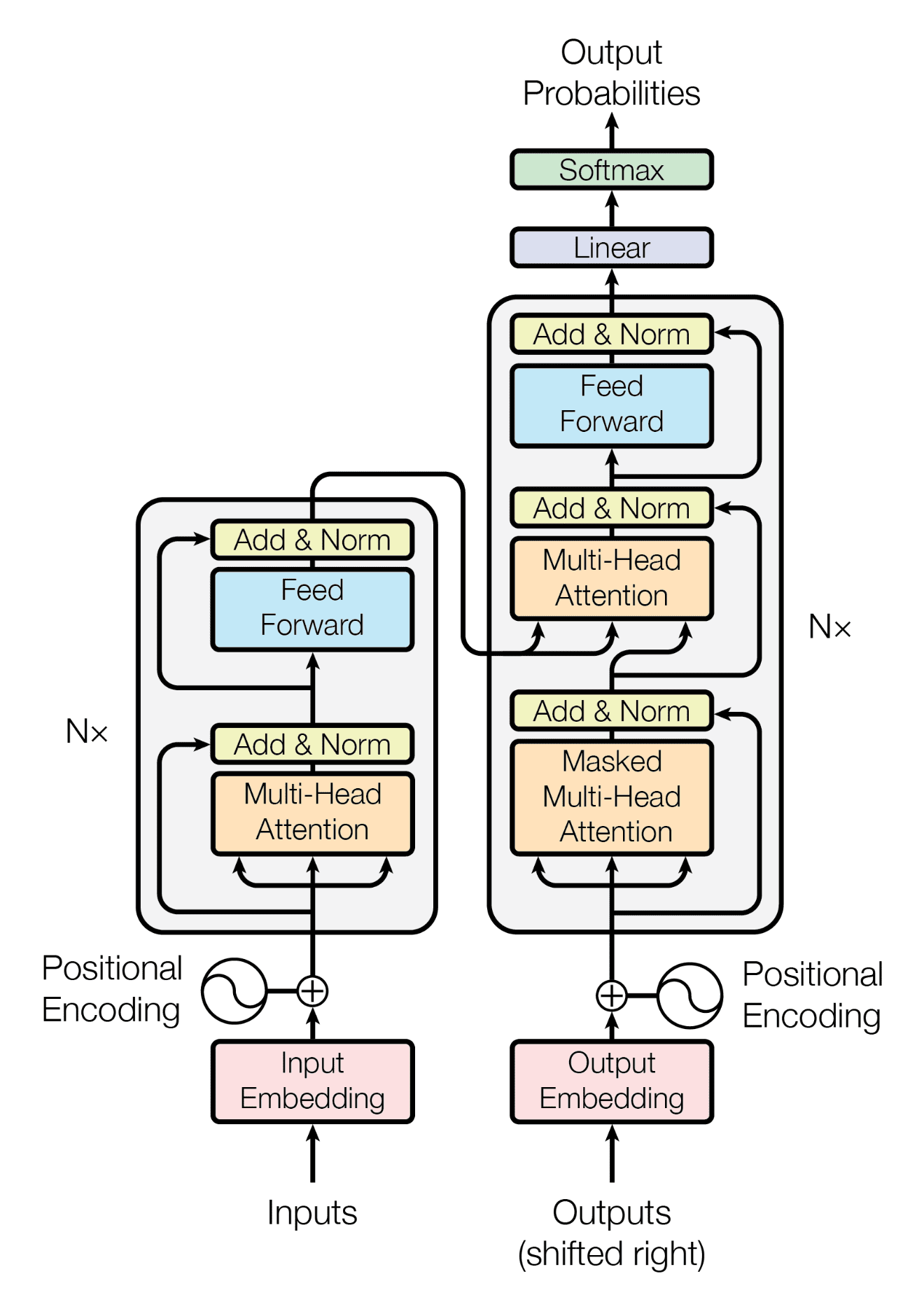
回想一下,Transformer 模型是为了翻译任务而开发的,取代了通常与 RNN 一起使用的 seq2seq 架构。因此,它借鉴了编码器-解码器架构。
编码器的作用是编码输入数据,即源语言的句子。编码器输出一个上下文表示,该表示应能捕获句子的含义。
解码器的作用是产生输出,即生成目标语言的句子,捕获与源语言句子相同的含义。因此,解码器将来自编码器的上下文表示作为输入之一。解码器一次生成一个目标句子中的单词(技术上称为 token)。它需要知道到目前为止已生成的内容,才能确定下一步要生成什么。因此,到目前为止生成的局部序列被作为另一个输入馈送回解码器。
通常,Transformer 模型中的编码器和解码器由一系列相同的层组成。编码器和解码器中的每一层都是一个注意力子层,后面跟着一个前馈子层。
注意力子层通过“关注”序列中的每个其他元素来逐个元素地转换输入序列。它像一个查找表一样工作,以找到最合适的输出。它本质上是一种线性变换,输出的长度与输入相同。然而,前馈子层是一种非线性变换。它是一个具有激活函数的多层感知器,应用于序列的每个元素。
本质上,注意力层允许序列的每个元素从序列中的所有其他元素学习,然后前馈层进一步转换每个元素。
Transformer 架构中使用的现代注意力机制称为缩放点积注意力。它接收三个输入序列:查询 (query)、键 (key) 和值 (value)。查询和键计算注意力权重,然后使用这些权重计算值 (value) 的加权和作为输出。
通常,编码器层中使用的注意力是自注意力,这意味着相同的输入序列用于导出查询、键和值序列。然而,在解码器层中,同时使用自注意力和交叉注意力。解码器中的交叉注意力使用部分生成的序列作为查询,并使用来自编码器的上下文表示作为键和值。
Transformer 架构的变体
我们来看看 Transformer 架构中的编码器层是如何实现的。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
import torch import torch.nn as nn class TransformerEncoderLayer(nn.Module): def __init__(self, d_model, d_ff, num_heads): super().__init__() self.attention = nn.MultiheadAttention(d_model, num_heads, batch_first=True) self.ff_proj = nn.Linear(d_model, d_ff) self.output_proj = nn.Linear(d_ff, d_model) self.norm1 = nn.LayerNorm(d_model) self.norm2 = nn.LayerNorm(d_model) self.act = nn.ReLU() def forward(self, x): """处理输入序列 x 参数 x (torch.Tensor): 输入序列,形状为 (batch_size, seq_len, d_model)。 Returns torch.Tensor: 处理后的序列,形状为 (batch_size, seq_len, d_model)。 """ # 自注意力子层 residual = x x = self.attention(x, x, x) x = self.norm1(x[0] + residual) # 前馈子层 residual = x x = self.act(self.ff_proj(x)) x = self.act(self.output_proj(x)) x = self.norm2(x + residual) return x seq = torch.randn(3, 7, 16) layer = TransformerEncoderLayer(16, 32, 4) out_seq = layer(seq) print({name: weight.shape for name, weight in layer.state_dict().items()}) print(out_seq.shape) |
这是一个简化的实现,其中省略了许多细节和错误处理。本质上,输入序列是形状为 (batch_size, seq_len, d_model) 的张量,其中 d_model 是模型的维度或序列中每个向量元素的大小。输出序列的形状相同,因此您可以再次用另一个编码器层对其进行处理。因此,您可以轻松地堆叠多个层来形成编码器。
MultiheadAttention 层会产生一个 Python 元组。第一个元素是注意力输出,第二个是注意力权重,在此实现中未对其进行使用。然后,将输出加回到原始输入,并应用层归一化。将输出加回到输入称为残差连接。这是深度学习中常见的做法,有助于模型更好地学习。
在注意力子层之后,输出序列被传递到前馈子层。前馈子层是一个具有 ReLU 激活函数的多层感知器,用于单独处理每个元素。输出的形状仍然与输入序列相同,尽管中间层通常会使用更大的维度。
来自前馈子层的输出将具有另一个残差连接和归一化。然后,这就是编码器层的输出。
上面的代码说明了后归一化架构。这是原始 Transformer 论文提出的架构,但后来发现前归一化架构更容易训练。前归一化版本如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
import torch import torch.nn as nn class TransformerEncoderLayer(nn.Module): def __init__(self, d_model, d_ff, num_heads): super().__init__() self.attention = nn.MultiheadAttention(d_model, num_heads, batch_first=True) self.ff_proj = nn.Linear(d_model, d_ff) self.output_proj = nn.Linear(d_ff, d_model) self.norm1 = nn.LayerNorm(d_model) self.norm2 = nn.LayerNorm(d_model) self.act = nn.ReLU() def forward(self, x): """处理输入序列 x 参数 x (torch.Tensor): 输入序列,形状为 (batch_size, seq_len, d_model)。 Returns torch.Tensor: 处理后的序列,形状为 (batch_size, seq_len, d_model)。 """ # 自注意力子层 residual = x x = self.norm1(x) x = self.attention(x, x, x) x = x[0] + residual # 前馈子层 residual = x x = self.norm2(x) x = self.act(self.ff_proj(x)) x = self.act(self.output_proj(x)) x = x + residual return x seq = torch.randn(3, 7, 16) layer = TransformerEncoderLayer(16, 32, 4) out_seq = layer(seq) print({name: weight.shape for name, weight in layer.state_dict().items()}) print(out_seq.shape) |
您总是在注意力或前馈子层之后具有残差连接。但在前归一化架构中,层归一化是在子层开始时而不是结束时应用的。
在上面的两个示例代码中,输出始终是以下内容:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
{'attention.in_proj_bias': torch.Size([48]), 'attention.in_proj_weight': torch.Size([48, 16]), 'attention.out_proj.bias': torch.Size([16]), 'attention.out_proj.weight': torch.Size([16, 16]), 'ff_proj.bias': torch.Size([32]), 'ff_proj.weight': torch.Size([32, 16]), 'norm1.bias': torch.Size([16]), 'norm1.weight': torch.Size([16]), 'norm2.bias': torch.Size([16]), 'norm2.weight': torch.Size([16]), 'output_proj.bias': torch.Size([16]), 'output_proj.weight': torch.Size([16, 32])} torch.Size([3, 7, 16]) |
很容易识别出两个线性层和两个归一化层的权重。注意力层的权重分为两部分:输入投影和输出投影。输入投影的形状为 $48\times 16$,输出投影的形状为 $16\times 16$。48 的原因是输入到注意力层的查询、键和值序列的连接,每个序列的形状都是 batch_size, seq_len, d_model,其中 d_model=16。因此 $16\times 3=48$。
您无法在权重中看到 num_heads=4 的影响,因为当您设置 d_model 时,每个头的维度是 d_model/num_heads。因此,在这种情况下,每个注意力头只处理 4 个维度的切片。每个头处理投影输入的某个切片,然后沿着嵌入维度连接以形成最终输出。
这些示例中的前馈层使用 ReLU 作为激活函数。您可以使用其他激活函数,例如 GELU 或 SwiGLU。事实上,现代 Transformer 模型更不可能使用 ReLU。
这些示例中应用了层归一化。有些模型会改用 RMS 范数。
解码器层的实现类似。不同之处在于您需要添加一个交叉注意力层并以不同的方式调用它。
|
1 |
x = self.attention(x, y, y) |
其中 y 是来自编码器输出的序列,它的长度可能不同。完整代码如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
import torch import torch.nn as nn class TransformerDecoderLayer(nn.Module): def __init__(self, d_model, d_ff, num_heads): super().__init__() self.attention = nn.MultiheadAttention(d_model, num_heads, batch_first=True) self.xattention = nn.MultiheadAttention(d_model, num_heads, batch_first=True) self.ff_proj = nn.Linear(d_model, d_ff) self.output_proj = nn.Linear(d_ff, d_model) self.norm1 = nn.LayerNorm(d_model) self.norm2 = nn.LayerNorm(d_model) self.norm3 = nn.LayerNorm(d_model) self.act = nn.ReLU() def forward(self, x, y): """使用解码器输入 y 处理输入序列 x 参数 x (torch.Tensor): 输入序列,形状为 (batch_size, seq_len, d_model)。 y (torch.Tensor): 来自编码器的输出序列,形状为 (batch_size, seq_len, d_model)。 Returns torch.Tensor: 处理后的序列,形状为 (batch_size, seq_len, d_model)。 """ # 自注意力子层 residual = x x = self.norm1(x) x = self.attention(x, x, x) x = x[0] + residual # 交叉注意力子层 residual = x x = self.norm2(x) x = self.xattention(x, y, y) x = x[0] + residual # 前馈子层 residual = x x = self.norm3(x) x = self.act(self.ff_proj(x)) x = self.act(self.output_proj(x)) x = x + residual return x dec_seq = torch.randn(3, 7, 16) enc_seq = torch.randn(3, 11, 16) layer = TransformerDecoderLayer(16, 32, 4) out_seq = layer(dec_seq, enc_seq) print({name: weight.shape for name, weight in layer.state_dict().items()}) print(out_seq.shape) |
进一步阅读
以下是一些您可能会觉得有用的论文。
总结
在本文中,您了解了 Transformer 架构和注意力机制。您还看到了如何在 PyTorch 中实现编码器和解码器层。特别是,您了解了:
- Transformer 架构是一种旨在处理文本等序列数据的神经网络。
- Transformer 模型的一个标志是使用注意力机制来处理输入序列。
- Transformer 架构由编码器和解码器组成。每个都由一系列相同的层组成。
- 通过类似的架构,Transformer 模型可以在前归一化或后归一化、不同的归一化方法和不同的激活函数方面有所不同。






您好,文章写得很好!您能否分享一个如何使用 Transformer 模型进行时间序列预测的例子,以及如何跟踪模型的训练性能,以及如何可视化模型的输出与实际测试集的对比?
这确实是一个入门介绍……当我读那本书时,我的眼睛会流血 😂
您好,我想知道为什么在最后一个代码块的第 35 行,您输入的参数是 (x,y,y)?xattention 使用 Pytorch 的 MultiheadAttention 块,它接受的顺序是 Query、Key、Value,这意味着 Query=x、Key=y、Value=y。
然而,在原始 Transformer 论文中,编码器的输出不是作为 Query 和 Key 输入的吗?而解码器自注意力的输出不是作为 Value 输入的吗?那么参数输入应该是 (y,y,x) 吗?
我很想听听您的见解!
Chad,您对 MultiheadAttention 调用中的输入顺序提出疑问是完全正确的,尤其是在 Transformer 架构的交叉注意力方面。
在 PyTorch 的 MultiheadAttention 模块中,forward 方法按此顺序接收三个参数:query、key、value。所以当你看到一行像
attention_output = attention(x, y, y)
这意味着:
* Query 是 x
* Key 是 y
* Value 是 y
这表明 x 在关注 y。换句话说,表示 x 正在尝试从 y 收集上下文。
现在,根据原始 Transformer 论文,在解码器的交叉注意力阶段:
* 解码器的隐藏状态(自注意力之后)用作查询
* 编码器的输出同时用作键和值
所以,标准的编码器-解码器交叉注意力的正确用法应该是:
attention_output = attention(y, x, x)
也就是说:
* Query 是解码器的隐藏状态 (y)
* Key 是编码器的输出 (x)
* Value 也是编码器的输出 (x)
如果您正在查看的代码使用了 (x, y, y),那么有几种可能性:
1. 变量名 x 和 y 可能与标准的命名约定颠倒了。
2. 计算的注意力可能不是交叉注意力;它可能是一些自定义或对称操作。
3. 这可能是代码中的一个错误或简化。
为了确认,您可以检查 x 和 y 的形状和含义。通常:
* 解码器隐藏状态(查询)的形状为 \[目标序列长度, batch size, 嵌入大小]
* 编码器输出(键和值)的形状为 \[源序列长度, batch size, 嵌入大小]
如果 x 与解码器隐藏状态的形状匹配,y 与编码器输出的形状匹配,那么 (x, y, y) 的用法与 Transformer 设计一致。