在编写代码时,无论我们是否知道,我们经常会遇到装饰器设计模式。这是一种在不修改类或函数的情况下扩展其功能的编程技术。装饰器设计模式允许我们轻松地混合和匹配扩展。Python 中的装饰器语法植根于装饰器设计模式。了解如何制作和使用装饰器可以帮助您编写更强大的代码。
在这篇文章中,您将了解装饰器模式和 Python 的函数装饰器。
完成本教程后,您将学习到:
- 什么是装饰器模式,它为什么有用
- Python 的函数装饰器以及如何使用它们
通过我的新书 Python for Machine Learning 启动您的项目,其中包括逐步教程和所有示例的 Python 源代码文件。
让我们开始吧!
Python 装饰器简明介绍
图片来源:Olya Kobruseva。保留部分权利。
概述
本教程分为四个部分
- 什么是装饰器模式,它为什么有用?
- Python 中的函数装饰器
- 装饰器的用例
- 装饰器的一些实用示例
什么是装饰器模式,它为什么有用?
装饰器模式是一种软件设计模式,它允许我们动态地向类添加功能,而无需创建子类并影响同一类的其他对象的行为。通过使用装饰器模式,我们可以轻松地生成我们可能想要的不同功能组合,而无需创建呈指数级增长的子类数量,从而使我们的代码变得越来越复杂和臃肿。
装饰器通常作为我们想要实现的主接口的子接口实现,并存储主接口类型的对象。然后,它将通过覆盖原始接口中的方法并调用存储对象中的方法来修改它想要添加某些功能的方法。
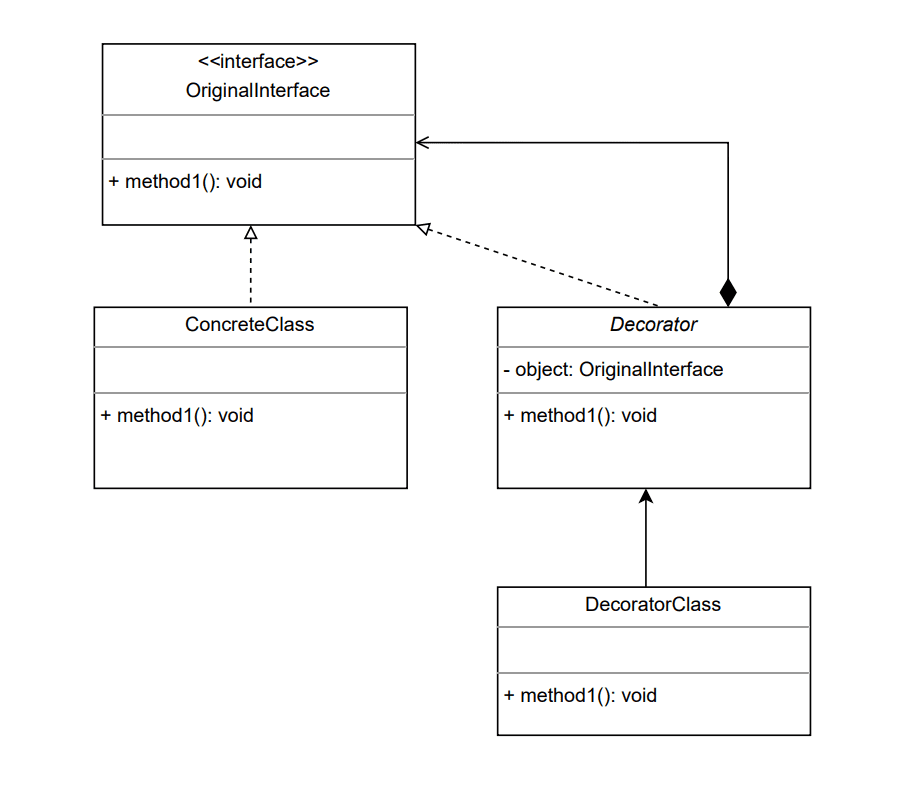
装饰器模式的 UML 类图
上面是装饰器设计模式的 UML 类图。装饰器抽象类包含一个 `OriginalInterface` 类型的对象;这是装饰器将要修改其功能的那个对象。为了实例化我们的具体 `DecoratorClass`,我们需要传入一个实现 `OriginalInterface` 的具体类,然后当我们调用 `DecoratorClass.method1()` 时,我们的 `DecoratorClass` 应该修改该对象的 `method1()` 的输出。
然而,在 Python 中,由于动态类型以及函数和类都是一流对象,我们能够简化许多这些设计模式。虽然在不改变实现的情况下修改类或函数仍然是装饰器的关键思想,但我们将在下文中探讨 Python 的装饰器语法。
Python 中的函数装饰器
函数装饰器是 Python 中一个极其有用的特性。它建立在函数和类在 Python 中是一流对象的思想之上。
让我们考虑一个简单的例子,即调用一个函数两次。由于 Python 函数是一个对象,我们可以将一个函数作为参数传递给另一个函数,这个任务可以如下完成
|
1 2 3 4 5 6 7 8 |
def repeat(fn): fn() fn() def hello_world(): print("Hello world!") repeat(hello_world) |
同样,由于 Python 函数是一个对象,我们可以让一个函数返回另一个函数,即执行另一个函数两次。这可以通过以下方式完成
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
def repeat_decorator(fn): def decorated_fn(): fn() fn() # 返回一个函数 return decorated_fn def hello_world(): print ("Hello world!") hello_world_twice = repeat_decorator(hello_world) # 调用该函数 hello_world_twice() |
上面 `repeat_decorator()` 返回的函数是在被调用时创建的,因为它依赖于提供的参数。在上面,我们将 `hello_world` 函数作为参数传递给 `repeat_decorator()` 函数,它返回 `decorated_fn` 函数,该函数被赋值给 `hello_world_twice`。之后,由于 `hello_world_twice` 现在是一个函数,我们可以调用它。
装饰器模式的思想适用于此。但我们不需要显式地定义接口和子类。事实上,`hello_world` 在上面的例子中被定义为一个函数。没有任何东西阻止我们将这个名字重新定义为其他东西。因此我们也可以这样做
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
def repeat_decorator(fn): def decorated_fn(): fn() fn() # 返回一个函数 return decorated_fn def hello_world(): print ("Hello world!") hello_world = repeat_decorator(hello_world) # 调用该函数 hello_world() |
也就是说,我们不是将新创建的函数赋值给 `hello_world_twice`,而是覆盖 `hello_world`。虽然 `hello_world` 的名称被重新分配给另一个函数,但之前的函数仍然存在,只是没有暴露给我们。
实际上,上面的代码与下面的代码功能上等效
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 调用函数两次的函数装饰器 def repeat_decorator(fn): def decorated_fn(): fn() fn() # 返回一个函数 return decorated_fn # 对 hello_world 函数使用装饰器 @repeat_decorator def hello_world(): print ("Hello world!") # 调用该函数 hello_world() |
在上面的代码中,函数定义前的 `@repeat_decorator` 意味着将该函数传入 `repeat_decorator()` 并将其名称重新赋值为输出。也就是说,它的意思是 `hello_world = repeat_decorator(hello_world)`。`@` 行是 Python 中的装饰器语法。
注意:`@` 语法也用于 Java,但含义不同,在 Java 中它是一个注解,本质上是元数据而不是装饰器。
我们还可以实现带参数的装饰器,但这会稍微复杂一些,因为我们需要多一层嵌套。如果我们扩展上面的例子来定义函数调用的重复次数
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
def repeat_decorator(num_repeats = 2): # repeat_decorator 应该返回一个装饰器函数 def inner_decorator(fn): def decorated_fn(): for i in range(num_repeats): fn() # 返回新函数 return decorated_fn # 返回实际将函数作为输入的装饰器 return inner_decorator # 使用装饰器,将 num_repeats 参数设置为 5,以重复调用函数 5 次 @repeat_decorator(5) def hello_world(): print("Hello world!") # 调用该函数 hello_world() |
`repeat_decorator()` 接受一个参数并返回一个函数,该函数是 `hello_world` 函数的实际装饰器(即,调用 `repeat_decorator(5)` 返回 `inner_decorator`,其中局部变量 `num_repeats = 5` 已设置)。上面的代码将打印以下内容
|
1 2 3 4 5 |
Hello world! Hello world! Hello world! Hello world! Hello world! |
在本节结束之前,我们应该记住,装饰器除了可以应用于函数之外,还可以应用于类。由于 Python 中的类也是一个对象,我们可以以类似的方式重新定义一个类。
想开始学习机器学习 Python 吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
装饰器的用例
Python 中的装饰器语法使得装饰器的使用变得更容易。我们使用装饰器的原因有很多。最常见的用例之一是隐式转换数据。例如,我们可以定义一个函数,该函数假定所有操作都基于 numpy 数组,然后制作一个装饰器,通过修改输入来确保这一点。
|
1 2 3 4 5 6 7 8 |
# 确保 numpy 输入的函数装饰器 def ensure_numpy(fn): def decorated_function(data): # 将输入转换为 numpy 数组 array = np.asarray(data) # 在输入的 numpy 数组上调用 fn return fn(array) return decorated_function |
我们可以通过修改函数的输出,例如四舍五入浮点值,进一步完善我们的装饰器
|
1 2 3 4 5 6 7 8 |
# 确保 numpy 输入的函数装饰器 # 并将输出四舍五入到小数点后 4 位 def ensure_numpy(fn): def decorated_function(data): array = np.asarray(data) output = fn(array) return np.around(output, 4) return decorated_function |
让我们考虑一个计算数组元素之和的例子。NumPy 数组内置了 `sum()` 函数,Pandas DataFrame 也有。但后者是对列求和,而不是对所有元素求和。因此,NumPy 数组会求和为一个浮点值,而 DataFrame 会求和为一个值向量。但有了上面的装饰器,我们可以编写一个函数,在两种情况下都能给出一致的输出
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
import numpy as np import pandas as pd # 确保 numpy 输入的函数装饰器 # 并将输出四舍五入到小数点后 4 位 def ensure_numpy(fn): def decorated_function(data): array = np.asarray(data) output = fn(array) return np.around(output, 4) return decorated_function @ensure_numpy def numpysum(array): return array.sum() x = np.random.randn(10,3) y = pd.DataFrame(x, columns=["A", "B", "C"]) # numpy .sum() 函数的输出 print("x.sum():", x.sum()) print() # pandas .sum() 函数的输出 print("y.sum():", y.sum()) print(y.sum()) print() # 调用装饰后的 numpysum 函数 print("numpysum(x):", numpysum(x)) print("numpysum(y):", numpysum(y)) |
运行上述代码会得到以下输出
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
x.sum(): 0.3948331694737762 y.sum(): A -1.175484 B 2.496056 C -0.925739 dtype: float64 A -1.175484 B 2.496056 C -0.925739 dtype: float64 numpysum(x): 0.3948 numpysum(y): 0.3948 |
这是一个简单的例子。但是想象一下,如果我们定义一个新函数来计算数组中元素的标准差。我们可以简单地使用相同的装饰器,然后该函数也将接受 Pandas DataFrame。因此,所有用于修饰输入的代码都通过将它们放入装饰器中而从这些函数中删除。这就是我们如何高效地重用代码。
装饰器的一些实用示例
既然我们已经学习了 Python 中的装饰器语法,那么让我们看看它能做些什么!
记忆化
我们有一些重复调用的函数,但这些函数的值很少(如果有的话)会改变。这可能是对数据相对静态的服务器的调用,或者是动态规划算法或计算密集型数学函数的一部分。我们可能希望对这些函数调用进行记忆化,即将其输出值存储在虚拟备忘录中以备后用。
装饰器是实现记忆化函数的最佳方式。我们只需要记住函数的输入和输出,但保持函数的行为不变。下面是一个示例
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
import pickle import hashlib MEMO = {} # 用于记忆函数输入和输出 def memoize(fn): def _deco(*args, **kwargs): # 序列化函数参数并获取哈希值作为存储键 key = (fn.__name__, hashlib.md5(pickle.dumps((args, kwargs), 4)).hexdigest()) # 检查键是否存在 if key in MEMO: ret = pickle.loads(MEMO[key]) else: ret = fn(*args, **kwargs) MEMO[key] = pickle.dumps(ret) return ret return _deco @memoize def fibonacci(n): if n in [0, 1]: return n else: return fibonacci(n-1) + fibonacci(n-2) print(fibonacci(40)) print(MEMO) |
在这个例子中,我们实现了 `memoize()` 来使用一个全局字典 `MEMO`,其中函数名和参数作为键,函数的返回值作为值。当函数被调用时,装饰器会检查 `MEMO` 中是否存在相应的键,如果存在,则返回存储的值。否则,实际的函数被调用,其返回值被添加到字典中。
我们使用 `pickle` 来序列化输入和输出,并使用 `hashlib` 来创建输入的哈希值,因为并非所有东西都可以作为 Python 字典的键(例如,`list` 是一种不可哈希类型;因此它不能作为键)。将任何任意结构序列化为字符串可以克服这个问题,并保证返回数据是不可变的。此外,哈希函数参数将避免在字典中存储异常长的键(例如,当我们向函数传递一个巨大的 numpy 数组时)。
上面的例子使用 `fibonacci()` 来演示记忆化的强大功能。调用 `fibonacci(n)` 将产生第 n 个斐波那契数。运行上面的例子将产生以下输出,其中我们可以看到第 40 个斐波那契数是 102334155,以及字典 `MEMO` 是如何用于存储对函数的不同调用的。
|
1 2 3 4 5 6 7 8 |
102334155 {('fibonacci', '635f1664f168e2a15b8e43f20d45154b'): b'\x80\x04K\x01.', ('fibonacci', 'd238998870ae18a399d03477dad0c0a8'): b'\x80\x04K\x00.', ('fibonacci', 'dbed6abf8fcf4beec7fc97f3170de3cc'): b'\x80\x04K\x01.', ... ('fibonacci', 'b9954ff996a4cd0e36fffb09f982b08e'): b'\x80\x04\x95\x06\x00\x00\x00\x00\x00\x00\x00J)pT\x02.', ('fibonacci', '8c7aba62def8063cf5afe85f42372f0d'): b'\x80\x04\x95\x06\x00\x00\x00\x00\x00\x00\x00J\xa2\x0e\xc5\x03.', ('fibonacci', '6de8535f23d756de26959b4d6e1f66f6'): b'\x80\x04\x95\x06\x00\x00\x00\x00\x00\x00\x00J\xcb~\x19\x06.'} |
您可以尝试删除上面代码中的 `@memoize` 行。您会发现程序运行时间显著增加(因为每次函数调用都会再调用两个函数;因此它的运行时间是 O(2^n) 而不是记忆化情况下的 O(n)),或者您甚至可能内存不足。
记忆化对于输出不经常变化的昂贵函数非常有用,例如以下从 Internet 读取一些股票市场数据的函数
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
... import pandas_datareader as pdr @memoize def get_stock_data(ticker): # 从 stooq 拉取数据 df = pdr.stooq.StooqDailyReader(symbols=ticker, start="1/1/00", end="31/12/21").read() return df # 测试函数调用 import cProfile as profile import pstats for i in range(1, 3): print(f"Run {i}") run_profile = profile.Profile() run_profile.enable() get_stock_data("^DJI") run_profile.disable() pstats.Stats(run_profile).print_stats(0) |
如果实现正确,对 `get_stock_data()` 的第一次调用应该更昂贵,随后的调用则便宜得多。上面代码片段的输出给我们
|
1 2 3 4 5 |
运行 1 17492 次函数调用 (17051 次原始调用) 耗时 1.452 秒 运行 2 221 次函数调用 (218 次原始调用) 耗时 0.001 秒 |
如果你正在使用 Jupyter Notebook,这尤其有用。如果你需要下载一些数据,将其封装在一个 memoize 装饰器中。由于开发机器学习项目意味着需要多次迭代地修改代码以查看结果是否有所改善,一个带有记忆功能的下载函数可以为你节省大量不必要的等待时间。
你可以通过将数据保存在数据库中(例如,像 GNU dbm 这样的键值存储或像 memcached 或 Redis 这样的内存数据库)来创建一个更强大的记忆化装饰器。但是,如果你只需要上述功能,Python 3.2 或更高版本已为你提供了内置库 functools 中的装饰器 lru_cache,因此你无需自己编写。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import functools import pandas_datareader as pdr # 使用 lru_cache 进行记忆化 @functools.lru_cache def get_stock_data(ticker): # 从 stooq 拉取数据 df = pdr.stooq.StooqDailyReader(symbols=ticker, start="1/1/00", end="31/12/21").read() return df # 测试函数调用 import cProfile as profile import pstats for i in range(1, 3): print(f"Run {i}") run_profile = profile.Profile() run_profile.enable() get_stock_data("^DJI") run_profile.disable() pstats.Stats(run_profile).print_stats(0) |
注意:lru_cache 实现了 LRU 缓存,将其大小限制为函数最近的调用(默认为 128)。在 Python 3.9 中,还有一个 @functools.cache,其大小无限制,没有 LRU 清除功能。
函数目录
我们可能需要考虑使用函数装饰器的另一个例子是将函数注册到目录中。它允许我们将函数与字符串关联起来,并将字符串作为其他函数的参数传递。这是构建一个支持用户提供插件的系统的开始。让我们用一个例子来说明这一点。下面是一个装饰器和一个函数 activate(),我们稍后将使用它们。假设以下代码保存在文件 activation.py 中。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# activation.py ACTIVATION = {} def register(name): def decorator(fn): # 将 fn 赋值给 ACTIVATION 中以 "name" 为键的条目 ACTIVATION[name] =fn # 不修改地返回 fn return fn return decorator def activate(x, kind): try: fn = ACTIVATION[kind] return fn(x) except KeyError: print("激活函数 %s 未定义" % kind) |
在上述代码中定义了 register 装饰器之后,我们现在可以使用它来注册函数并将字符串与它们关联起来。让我们将文件 funcs.py 设置如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# funcs.py from activation import register import numpy as np @register("relu") def relu(x): return np.where(x>0, x, 0) @register("sigmoid") def sigm(x): return 1/(1+np.exp(-x)) @register("tanh") def tanh(x): return np.tanh(x) |
我们通过在 ACTIVATION 字典中建立关联,将“relu”、“sigmoid”和“tanh”函数注册到各自的字符串中。
现在,让我们看看如何使用我们新注册的函数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import numpy as np from activation import activate # 创建一个随机矩阵 x = np.random.randn(5,3) print(x) # 尝试对矩阵进行 ReLU 激活 relu_x = activate(x, "relu") print(relu_x) # 加载函数,并再次调用 ReLU 激活 import funcs relu_x = activate(x, "relu") print(relu_x) |
这将给我们输出:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
[[-0.81549502 -0.81352867 1.41539545] [-0.28782853 -1.59323543 -0.19824959] [ 0.06724466 -0.26622761 -0.41893662] [ 0.47927331 -1.84055276 -0.23147207] [-0.18005588 -1.20837815 -1.34768876]] 激活函数 relu 未定义 无 [[0. 0. 1.41539545] [0. 0. 0. ] [0.06724466 0. 0. ] [0.47927331 0. 0. ] [0. 0. 0. ]] |
请注意,在我们到达 import func 行之前,ReLU 激活函数并不存在。因此,调用该函数会打印错误消息,结果是 None。然后,在我们运行 import 行之后,我们加载了那些像插件模块一样定义的函数。然后,相同的函数调用给了我们预期的结果。
请注意,我们从未显式调用模块 func 中的任何内容,也没有修改对 activate() 的调用中的任何内容。仅仅导入 func 就导致这些新函数注册并扩展了 activate() 的功能。使用这种技术,我们可以在一次只关注一个小的部分来开发一个非常大的系统,而不必担心其他部分的互操作性。如果没有注册装饰器和函数目录,添加一个新的激活函数将需要修改使用激活的**所有**函数。
如果你熟悉 Keras,你应该能理解上面的内容与以下语法相似:
|
1 2 3 4 5 |
layer = keras.layers.Dense(128, activation="relu") model.compile(loss="sparse_categorical_crossentropy", optimizer="adam", metrics=["sparse_categorical_accuracy"]) |
Keras 使用类似性质的装饰器定义了几乎所有组件。因此,我们可以通过名称来引用构建块。如果没有这种机制,我们必须一直使用以下语法,这给我们带来了记住许多组件位置的负担:
|
1 2 3 4 5 |
layer = keras.layers.Dense(128, activation=keras.activations.relu) model.compile(loss=keras.losses.SparseCategoricalCrossentropy(), optimizer=keras.optimizers.Adam(), metrics=[keras.metrics.SparseCategoricalAccuracy()]) |
延伸阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
文章
- 装饰器模式
- Python 语言参考,第 8.7 节,函数定义
- PEP 318 – 函数和方法的装饰器
书籍
- 流畅的 Python,第 2 版,Luciano Ramalho 著
API
- Python 标准库中的functools 模块
总结
在这篇文章中,你了解了装饰器设计模式和 Python 的装饰器语法。你还看到了一些装饰器的特定用例,它们可以帮助你的 Python 程序运行得更快或更容易扩展。
具体来说,你学到了:
- 装饰器模式的思想和 Python 中的装饰器语法
- 如何在 Python 中实现一个装饰器以与装饰器语法一起使用
- 装饰器用于调整函数输入和输出、进行记忆化以及在目录中注册函数的用途
掌握机器学习 Python!

更自信地用 Python 编写代码
...从学习实用的 Python 技巧开始
在我的新电子书中探索如何实现
用于机器学习的 Python
它提供自学教程和数百个可运行的代码,为您提供包括以下技能:
调试、性能分析、鸭子类型、装饰器、部署等等...






暂无评论。