
学习率调度器的温和介绍
图片作者 | ChatGPT
您是否曾想过为什么您的神经网络在训练过程中似乎会陷入停滞,或者为什么它一开始表现强劲,却未能达到其全部潜力?罪魁祸首可能是您的学习率——这可以说是机器学习中最关键的超参数之一。虽然固定的学习率可能有效,但它通常会导致次优的结果。学习率调度器通过在训练过程中自动调整学习率,提供了一种更动态的方法。
在本文中,您将通过清晰的可视化和实践示例,了解五种流行的学习率调度器。您将学习何时使用每种调度器,查看它们的行为模式,并了解它们如何提高模型的性能。我们将从基础开始,探讨 sklearn 的方法与深度学习的要求,然后使用 MNIST 数据集进行实际实现。
到最后,您将同时掌握理论知识和实用代码,可以开始在您自己的项目中使用学习率调度器了。
学习率基础
想象一下,您正在浓雾中徒步下山,试图到达山谷。学习率就像您的步长——步子太大,您可能会越过山谷,或者在山坡上来回弹跳。步子太小,您会前进得极其缓慢,甚至可能在到达底部之前就卡在某个凸缘上。
在机器学习中,学习率控制着我们在每次训练步骤后调整模型权重的幅度。它决定了我们在尝试最小化损失函数时所做更新的大小。
如果您以前使用过 **sklearn**,您一定在像 GradientBoostingClassifier 或 SGDClassifier 这样的算法中遇到过学习率。这些算法通常在整个训练过程中使用固定的学习率。这种方法对于更简单的模型来说效果相当不错,因为它们的优化表面通常不那么复杂。
然而,深度神经网络带来了更具挑战性的优化问题,包括多个局部最小值和鞍点,在训练的不同阶段需要不同的最优学习率,以及在模型接近收敛时需要进行微调。
固定的学习率会产生几个问题
- 学习率过高:模型在最优点附近振荡,无法稳定地进入最小值。
- 学习率过低:训练进展极其缓慢,浪费计算资源,并可能陷入糟糕的局部最小值。
- 不适应:无法适应训练的不同阶段。
学习率调度器通过根据训练进度或性能指标动态调整学习率来解决这些问题。
什么是学习率调度器?
学习率调度器是在训练过程中自动调整模型学习率的算法。这些调度器不是从头到尾都使用相同的学习率,而是根据预定义的规则或训练性能来更改它。
调度器的妙处在于它们能够优化训练的不同阶段。在训练早期,权重远离最优值时,较高的学习率有助于快速进展。当模型接近收敛时,较低的学习率可以进行微调,防止越过最小值。
与固定的学习率相比,这种自适应方法通常能带来更好的最终性能、更快的收敛速度和更稳定的训练。
五种必备学习率调度器
StepLR - 步长衰减
StepLR 在固定间隔内按固定因子降低学习率。在我们的可视化中,它从 0.1 开始,每 20 个 epoch 将学习率减半,从而产生您看到的独特阶梯状模式。
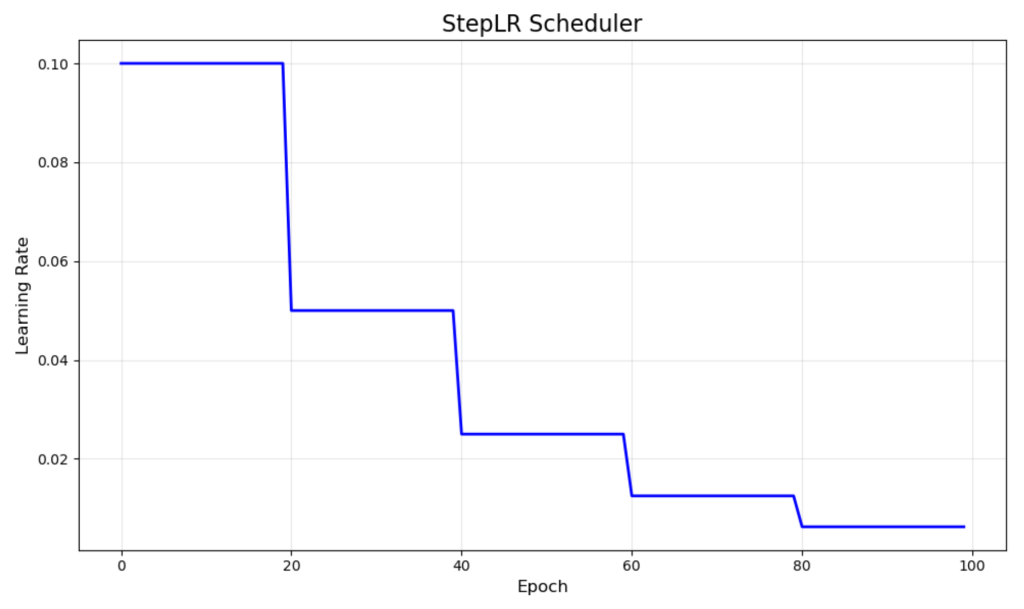
当您了解您的训练过程并能预见到模型何时应该专注于微调时,这种调度器效果很好。它对于图像分类任务尤其有用,您可能希望在模型学习了基本特征后降低学习率。
主要优点是其简单性和可预测性。然而,衰减的时间是固定的,不考虑实际训练进度,这可能并不总是最优的。
ExponentialLR - 指数衰减
ExponentialLR 通过每个 epoch 将学习率乘以衰减因子来平滑地降低学习率。我们的示例使用 0.95 的乘数,生成了从 0.1 开始并逐渐接近零的平滑红色曲线。
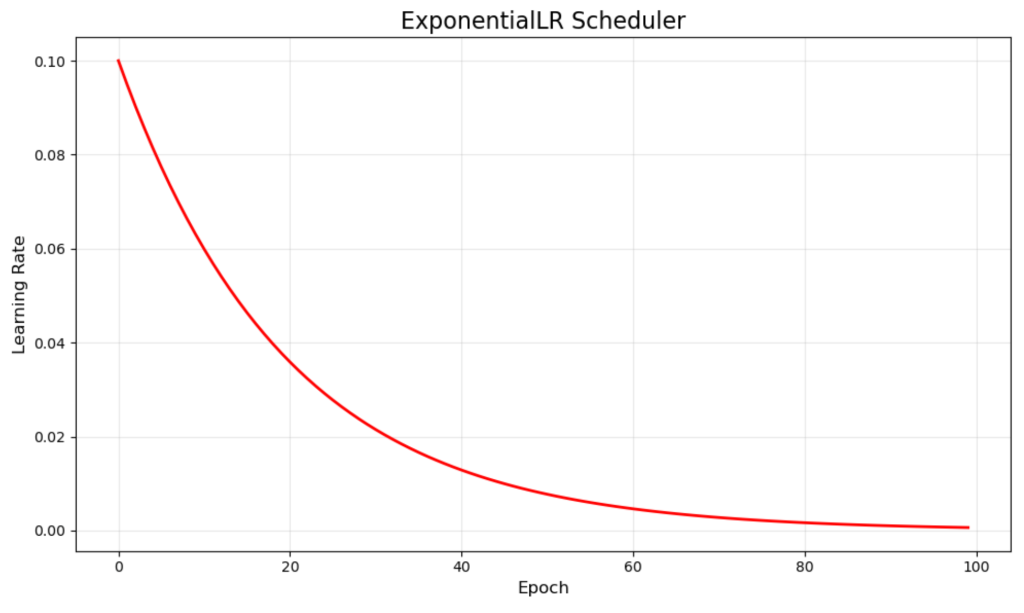
这种连续衰减确保模型在训练过程中始终做出越来越小的更新。它对于您希望渐进式改进而不发生可能干扰训练动量的急剧过渡的问题特别有效。
指数衰减的平滑性质通常会导致稳定的收敛,但需要仔细调整衰减率,以避免学习率衰减过快或过慢。
CosineAnnealingLR - 余弦退火
CosineAnnealingLR 遵循余弦曲线,从高值开始平滑地下降到最小值。绿色曲线显示了这种优美的数学进程,它在接近最小值时自然地减缓了变化率。
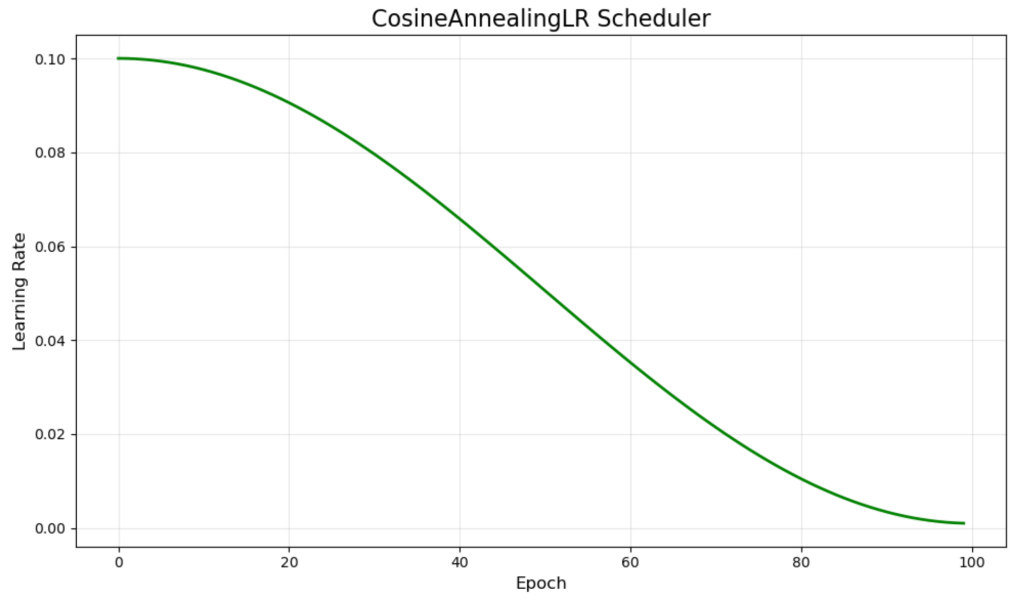
这种调度器受到模拟退火的启发,并在现代深度学习中越来越受欢迎。余弦形状在早期提供了更多的训练时间,以较高的学习率进行训练,然后逐渐过渡到微调阶段。
研究表明,余弦退火可以帮助模型逃离局部最小值,并且在复杂的优化景观中通常能比线性衰减调度器获得更好的最终性能。
ReduceLROnPlateau - 自适应平台衰减
ReduceLROnPlateau 采用不同的方法,通过监控验证指标并在改进停滞时才降低学习率。紫色的可视化显示了典型的行为,衰减大约在 epoch 25、50 和 75 时发生。
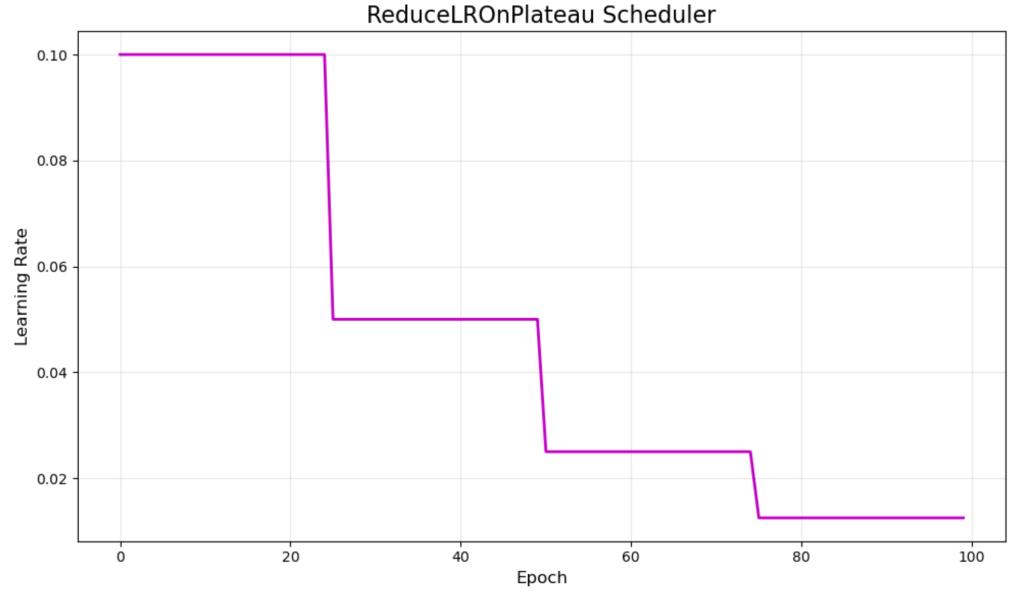
这种自适应调度器响应实际的训练进度,而不是遵循预定的计划。当验证损失在指定数量的 epoch(耐心参数)内停止改进时,它会降低学习率。
主要优点是它对训练动态的响应能力,使其成为您不确定最优调度时的绝佳选择。但是,它需要监控验证指标,并且可能对必要的调整反应缓慢。
CyclicalLR - 周期性学习率
CyclicalLR 在最小和最大学习率之间以三角形模式振荡。我们的橙色可视化显示了这些周期,在 40 个 epoch 的周期内,学习率从 0.001 上升到 0.1 然后再下降。
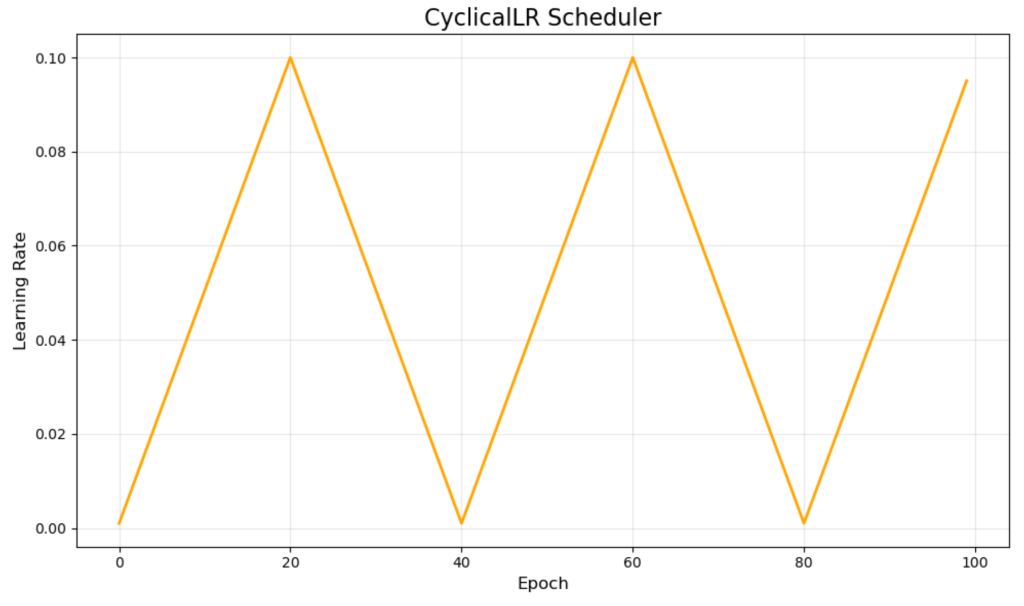
这种方法由 Leslie Smith 开创,挑战了仅降低学习率的传统观念。理论认为,周期性的增加有助于模型逃离糟糕的局部最小值,更有效地探索损失表面。
虽然周期性学习率可以取得令人印象深刻的结果,并且通常比传统方法训练得更快,但它们需要仔细调整最小、最大和周期长度参数才能有效工作。
实践实现:MNIST 示例
现在让我们看看这些调度器是如何工作的。我们将在一份 MNIST 数字分类数据集上训练一个简单的神经网络,以比较不同的调度器如何影响训练性能。
设置和数据准备
我们首先导入必要的库并准备我们的数据。MNIST 数据集包含手写数字(0-9),我们将使用一个基本的三层神经网络对其进行分类。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 学习率调度器 - 简洁的 MNIST 演示 import numpy as np import matplotlib.pyplot as plt import tensorflow as tf from tensorflow.keras import layers, callbacks from tensorflow.keras.optimizers import Adam import warnings warnings.filterwarnings('ignore') # Data preparation (x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 x_train = x_train.reshape(-1, 784)[:10000] y_train = tf.keras.utils.to_categorical(y_train, 10)[:10000] # 简单的模型 def create_model(): return tf.keras.Sequential([ layers.Dense(128, activation='relu', input_shape=(784,)), layers.Dense(10, activation='softmax') ]) |
我们的模型特意设计得很简单——一个具有 128 个神经元的隐藏层。我们只使用了 10,000 个训练样本来加快实验速度,但仍然能够展示调度器的行为。
调度器实现
接下来,我们实现每种调度器。大多数调度器都可以实现为简单的函数,这些函数接受当前的 epoch 和学习率,然后返回新的学习率。但是,ReduceLROnPlateau 的工作方式不同,因为它需要监控验证指标,因此我们将在训练部分单独处理它。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 学习率调度器(与可视化参数匹配) def step_lr(epoch, lr): # StepLR: step_size=20, gamma=0.5 (来自可视化) return lr * 0.5 if epoch % 20 == 0 and epoch > 0 else lr def exp_lr(epoch, lr): # ExponentialLR: gamma=0.95 (来自可视化) return lr * 0.95 def cosine_lr(epoch, lr): # CosineAnnealingLR: lr_min=0.001, lr_max=0.1, max_epochs=100 (来自可视化) lr_min, lr_max = 0.001, 0.1 max_epochs = 100 return lr_min + 0.5 * (lr_max - lr_min) * (1 + np.cos(epoch * np.pi / max_epochs)) def cyclical_lr(epoch, lr): # CyclicalLR: base_lr=0.001, max_lr=0.1, step_size=20 (来自可视化) base_lr = 0.001 max_lr = 0.1 step_size = 20 cycle = np.floor(1 + epoch / (2 * step_size)) x = np.abs(epoch / step_size - 2 * cycle + 1) return base_lr + (max_lr - base_lr) * max(0, (1 - x)) |
请注意,每个函数都实现了我们之前可视化中显示的完全相同的行为。参数的选择经过精心设计,以匹配这些模式。ReduceLROnPlateau 需要特殊处理,因为它会在训练期间监控验证损失,这将在下一节中设置为回调函数时看到。
训练与比较
然后,我们创建一个可以利用这些调度器中的任何一个的训练函数,并为每种调度器运行实验。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# 训练函数 def train_scheduler(schedule_name, schedule_fn=None, callback=None): model = create_model() model.compile(optimizer=Adam(0.1), loss='categorical_crossentropy', metrics=['accuracy']) # 以 0.1 开始以匹配可视化 if schedule_fn: callback = callbacks.LearningRateScheduler(schedule_fn) elif callback is None: callback = [] history = model.fit(x_train, y_train, epochs=100, validation_split=0.2, callbacks=[callback] if callback else [], verbose=0) return history # 运行实验 results = {} schedulers = { 'StepLR': (step_lr, None), 'ExponentialLR': (exp_lr, None), 'CosineAnnealingLR': (cosine_lr, None), 'ReduceLROnPlateau': (None, callbacks.ReduceLROnPlateau(factor=0.5, patience=3)), 'CyclicalLR': (cyclical_lr, None) } for name, (schedule, callback) in schedulers.items(): results[name] = train_scheduler(name, schedule, callback) |
可视化训练过程
训练损失曲线揭示了有趣的模式。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 简单的可视化 - 仅训练损失 plt.figure(figsize=(10, 6)) plt.title('训练损失') for name, history in results.items(): plt.plot(history.history['loss'], label=name, linewidth=2) plt.xlabel('Epoch') plt.ylabel('损失') plt.legend() plt.grid(True, alpha=0.3) plt.tight_layout() plt.show() |
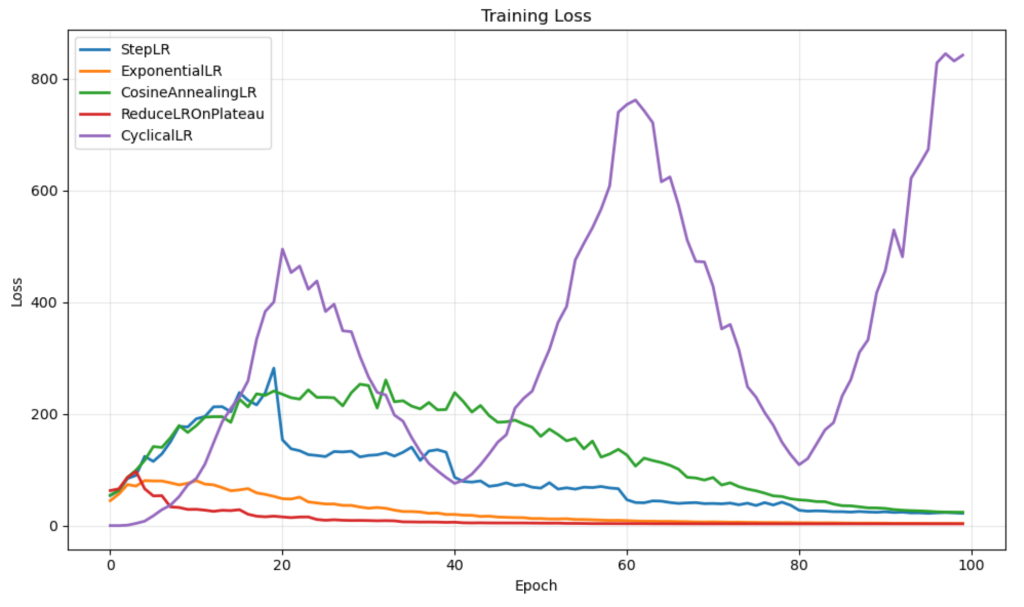
可视化显示了不同的行为。StepLR 和 ReduceLROnPlateau 实现了平滑、稳定的收敛。ExponentialLR 在整个训练过程中保持一致的进展。CosineAnnealingLR 显示出波动期然后改进。CyclicalLR 表现出最不稳定的行为,其急剧的峰值对应于其学习率的增加。
性能比较
最终结果显示了哪种调度器在此任务上表现最佳。
|
1 2 3 4 5 6 7 |
# 最终结果 print("\n最终结果:") print("-" * 50) for name, history in results.items(): val_acc = history.history['val_accuracy'][-1] val_loss = history.history['val_loss'][-1] print(f"{name:<18} | Val Acc: {val_acc:.3f} | Val Loss: {val_loss:.3f}") |
结果
|
1 2 3 4 5 6 7 |
最终 结果: -------------------------------------------------- StepLR | Val Acc: 0.889 | Val Loss: 235.125 ExponentialLR | Val Acc: 0.883 | Val Loss: 71.269 CosineAnnealingLR | Val Acc: 0.883 | Val Loss: 445.005 ReduceLROnPlateau | Val Acc: 0.890 | Val Loss: 31.791 CyclicalLR | Val Acc: 0.859 | Val Loss: 2304.819 |
ReduceLROnPlateau 以 89.0% 的验证准确率和最低的损失取得了最佳性能。StepLR 以 88.9% 的准确率非常接近。CyclicalLR 在本次实验中表现不佳,可能是因为学习率范围对于这个简单问题来说过于激进。
这些结果表明,调度器的选择会对模型的性能产生重大影响,并且不同的调度器对不同的问题效果更好。ReduceLROnPlateau 的自适应特性使其在此特别有效,因为它能够响应训练动态,而不是遵循预定的计划。
选择合适的调度器
选择合适的调度器取决于您的问题特性和训练要求。这是一个实用的决策框架:
当您了解训练阶段时 → StepLR
如果您了解模型何时应从探索阶段过渡到微调阶段,StepLR 将为您提供对这些阶段的明确控制。
当您想要平滑、可预测的衰减时 → ExponentialLR
用于稳定、连续的衰减,没有可能干扰训练动量的突然变化。
当您想逃离局部最小值时 → CosineAnnealingLR
余弦模式提供了自然的探索阶段,可以帮助模型找到更好的解决方案。
当您不确定调度时 → ReduceLROnPlateau
这种自适应方法可以响应实际的训练进度,使其成为您不确定最佳时机的绝佳选择。
用于高级优化技术 → CyclicalLR
当您想尝试更复杂的方法来挑战传统的学习率假设时。
对于大多数问题,可以从 ReduceLROnPlateau 开始,然后根据您的具体需求尝试其他调度器。
超越基础
学习率调度器的范围远远超出了这五种调度器。现代变体包括用于多个衰减点的 MultiStepLR、用于超收敛的 OneCycleLR、用于自定义衰减曲线的 PolynomialLR、用于任意函数的 LambdaLR 和用于简单线性变化的 LinearLR。
当前研究探索了预热调度、学习率范围测试以及针对不同架构的专用调度器。如需更深入的探索,请查阅 TensorFlow 和 PyTorch 文档、关于优化方法的最新论文以及从业人员的实践指南。
结论与后续步骤
学习率调度器可以显著提高模型的训练效率和最终性能。调度器的选择通常与模型架构本身一样重要。
开始在您自己的项目中试验这些学习率调度器。首先尝试ReduceLROnPlateau,因为它具有自适应性,然后根据您的具体需求探索其他调度器。关键在于密切监控训练过程,并根据您的观察进行调整。
您模型的注意投入在这方面(一个经常被忽视但至关重要的训练方面)会让它们受益匪浅。






我更关心验证损失的最小值,而不是最后一个值。
您好…请详细说明您模型的目标,我们可以帮助您进行指导。