粒子群优化(PSO)是一种受生物启发而来的算法,它是一种在解空间中搜索最优解的简单算法。它与其他优化算法的不同之处在于,只需要目标函数,而不依赖于目标函数的梯度或任何微分形式。它还具有很少的超参数。
在本教程中,您将了解 PSO 的基本原理及其算法,并通过一个示例。完成本教程后,您将了解
- 什么是粒子群以及它们在 PSO 算法下的行为
- PSO 可以解决哪些类型的优化问题
- 如何使用粒子群优化解决问题
- PSO 算法有哪些变体
开始您的项目,阅读我的新书《机器学习优化》,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。粒子群
粒子群优化由 Kennedy 和 Eberhart 于 1995 年提出。正如原始论文中所述,社会生物学家认为一群鱼或一群鸟类协同行动“可以从所有其他成员的经验中获益”。换句话说,例如,一只鸟在随机飞行和觅食时,群体中的所有鸟都可以分享它们的发现,并帮助整个群体获得最佳的捕猎成果。

粒子群优化。
照片由 Don DeBold 提供,部分权利保留。
虽然我们可以模拟鸟群的运动,但我们也可以想象每只鸟都在帮助我们在高维解空间中寻找最优解,而鸟群找到的最佳解就是该空间中的最佳解。这是一种启发式解决方案,因为我们永远无法证明能找到真正的全局最优解,而且通常也找不到。然而,我们经常发现 PSO 找到的解非常接近全局最优解。
示例优化问题
PSO 最适合用于寻找定义在多维向量空间上的函数的最大值或最小值。假设我们有一个函数 $f(X)$,它从向量参数 $X$(例如平面上的坐标 $(x,y)$)产生一个实数值,并且 $X$ 可以取空间中的几乎任何值(例如,$f(X)$ 是海拔高度,我们可以在平面上的任何点找到一个值),那么我们就可以应用 PSO。PSO 算法将返回它找到的产生最小 $f(X)$ 的参数 $X$。
让我们从以下函数开始
$$
f(x,y) = (x-3.14)^2 + (y-2.72)^2 + \sin(3x+1.41) + \sin(4y-1.73)
$$

f(x,y) 的绘图
正如我们在上面的图中所看到的,这个函数看起来像一个弯曲的蛋盒。它不是一个凸函数,因此很难找到它的最小值,因为找到的局部最小值不一定是全局最小值。
那么,我们如何找到这个函数中的最小点呢?当然,我们可以采用穷举搜索:如果我们检查平面上每个点的 $f(x,y)$ 值,就可以找到最小点。或者,如果我们认为搜索每个点成本太高,我们可以随机在平面上找一些样本点,看看哪个点在 $f(x,y)$ 上给出的值最低。然而,我们还注意到从 $f(x,y)$ 的形状来看,如果我们找到一个 $f(x,y)$ 值较小的点,那么在其附近更容易找到一个更小的值。
粒子群优化就是这样做的。与寻找食物的鸟群类似,我们从平面上的若干个随机点(称为粒子)开始,让它们以随机方向寻找最小点。在每一步,每个粒子都应该在其找到的最小点附近以及整个粒子群找到的最小点附近进行搜索。经过一定的迭代后,我们将函数的最小点视为该粒子群探索过的最小点。
想要开始学习优化算法吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
算法细节
假设我们有 $P$ 个粒子,并将粒子 $i$ 在迭代 $t$ 的位置表示为 $X^i(t)$。在上面的例子中,我们将其表示为坐标 $X^i(t) = (x^i(t), y^i(t))$。除了位置之外,我们还为每个粒子定义了一个速度,表示为 $V^i(t)=(v_x^i(t), v_y^i(t))$。在下一次迭代中,每个粒子的位置将按以下规则更新:
$$
X^i(t+1) = X^i(t)+V^i(t+1)
$$
或者,等效地:
$$
\begin{aligned}
x^i(t+1) &= x^i(t) + v_x^i(t+1) \\
y^i(t+1) &= y^i(t) + v_y^i(t+1)
\end{aligned}
$$
同时,速度也将根据以下规则更新:
$$
V^i(t+1) =
w V^i(t) + c_1r_1(pbest^i – X^i(t)) + c_2r_2(gbest – X^i(t))
$$
其中 $r_1$ 和 $r_2$ 是介于 0 和 1 之间的随机数,$w$、$c_1$ 和 $c_2$ 是 PSO 算法的参数,而 $pbest^i$ 是粒子 $i$ 迄今为止探索到的使 $f(X)$ 值达到最佳的位置,而 $gbest$ 是整个粒子群迄今为止探索到的使 $f(X)$ 值达到最佳的位置。
请注意,$pbest^i$ 和 $X^i(t)$ 是两个位置向量,差值 $pbest^i – X^i(t)$ 是向量减法。将此差值加到原始速度 $V^i(t)$ 上是为了将粒子带回到 $pbest^i$ 的位置。对于差值 $gbest – X^i(t)$ 也是类似的。

向量减法。
图由 Benjamin D. Esham 提供,属于公共领域。
我们将参数 $w$ 称为惯性权重常数。它介于 0 和 1 之间,决定了粒子应该在多大程度上保持其先前的速度(即搜索的速度和方向)。参数 $c_1$ 和 $c_2$ 分别称为认知和群体系数。它们控制了粒子自身搜索结果的细化程度与群体搜索结果的识别程度之间的权重。我们可以认为这些参数控制了探索和利用之间的权衡。
在每次迭代中,位置 $pbest^i$ 和 $gbest$ 都会更新,以反映迄今为止找到的最佳位置。
该算法与其它优化算法不同的一点是,它不依赖于目标函数的梯度。例如,在梯度下降法中,我们通过将 $X$ 向 $-\nabla f(X)$ 的方向移动来寻找函数 $f(X)$ 的最小值,因为那是函数下降最快的方向。对于当前位置为 $X$ 的任何粒子,其移动方式不取决于“下坡”的方向,而仅取决于 $pbest$ 和 $gbest$ 的位置。这使得 PSO 特别适合于区分 $f(X)$ 困难的情况。
PSO 的另一个特点是它易于并行化。由于我们操纵多个粒子来寻找最优解,每个粒子都可以并行更新,我们只需要每迭代一次收集一次 $gbest$ 的更新值。这使得 map-reduce 架构成为实现 PSO 的理想选择。
实现
在这里,我们展示了如何实现 PSO 来寻找最优解。
对于上面展示的相同函数,我们可以先将其定义为一个 Python 函数,并在等高线图中显示它。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import numpy as np import matplotlib.pyplot as plt def f(x,y): "目标函数" return (x-3.14)**2 + (y-2.72)**2 + np.sin(3*x+1.41) + np.sin(4*y-1.73) # 等高线图:全局最小值显示为图上的“X” x, y = np.array(np.meshgrid(np.linspace(0,5,100), np.linspace(0,5,100))) z = f(x, y) x_min = x.ravel()[z.argmin()] y_min = y.ravel()[z.argmin()] plt.figure(figsize=(8,6)) plt.imshow(z, extent=[0, 5, 0, 5], origin='lower', cmap='viridis', alpha=0.5) plt.colorbar() plt.plot([x_min], [y_min], marker='x', markersize=5, color="white") contours = plt.contour(x, y, z, 10, colors='black', alpha=0.4) plt.clabel(contours, inline=True, fontsize=8, fmt="%.0f") plt.show() |
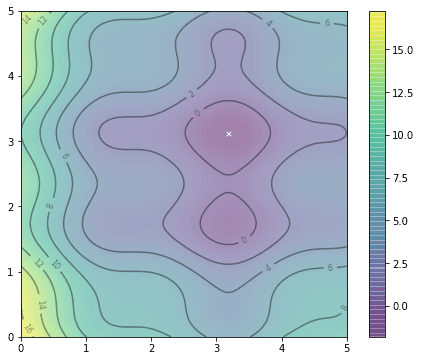
f(x,y) 的等高线图
我们在区域 $0\le x,y\le 5$ 内绘制了函数 $f(x,y)$。我们可以创建 20 个粒子,在区域内随机位置生成,并设置均值为 0、标准差为 0.1 的正态分布采样的随机速度,如下所示:
|
1 2 3 |
n_particles = 20 X = np.random.rand(2, n_particles) * 5 V = np.random.randn(2, n_particles) * 0.1 |
我们可以将它们的位置显示在同一张等高线图上。
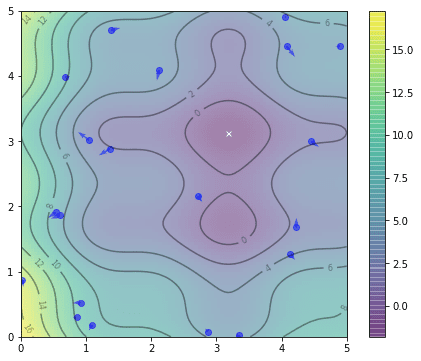
粒子的初始位置
由此,我们已经可以找到 $gbest$ 作为所有粒子迄今为止找到的最佳位置。由于粒子还没有进行任何探索,它们当前的位置也是它们的 $pbest^i$。
|
1 2 3 4 |
pbest = X pbest_obj = f(X[0], X[1]) gbest = pbest[:, pbest_obj.argmin()] gbest_obj = pbest_obj.min() |
向量 `pbest_obj` 是每个粒子找到的目标函数值的最佳值。类似地,`gbest_obj` 是整个粒子群迄今为止找到的目标函数值的最佳标量值。由于我们将其设置为一个最小化问题,因此我们在此使用了 `min()` 和 `argmin()` 函数。下面用星号标记了 `gbest` 的位置。
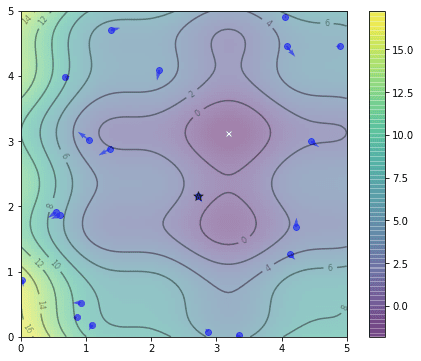
gbest 的位置用星号标记
让我们设置 $c_1=c_2=0.1$ 和 $w=0.8$。然后,我们可以根据上面提到的公式更新位置和速度,之后再更新 $pbest^i$ 和 $gbest$。
|
1 2 3 4 5 6 7 8 9 10 11 |
c1 = c2 = 0.1 w = 0.8 # 一次迭代 r = np.random.rand(2) V = w * V + c1*r[0]*(pbest - X) + c2*r[1]*(gbest.reshape(-1,1)-X) X = X + V obj = f(X[0], X[1]) pbest[:, (pbest_obj >= obj)] = X[:, (pbest_obj >= obj)] pbest_obj = np.array([pbest_obj, obj]).max(axis=0) gbest = pbest[:, pbest_obj.argmin()] gbest_obj = pbest_obj.min() |
第一次迭代后的位置如下。我们用黑点标记每个粒子的最佳位置,以区别于它们当前的蓝色位置。
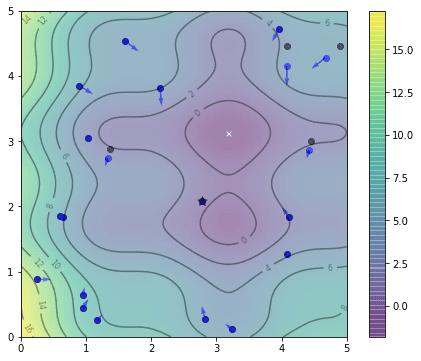
一次迭代后粒子的位置
我们可以多次重复上述代码段,看看粒子是如何探索的。这是第二次迭代后的结果:
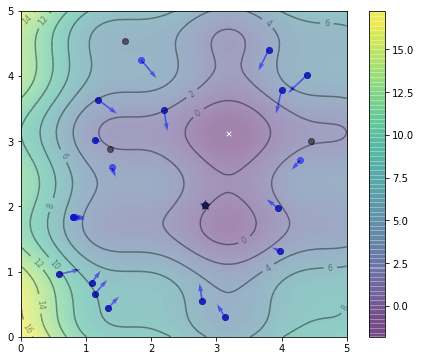
两次迭代后粒子的位置
这是第五次迭代后的结果,注意 $gbest$ 的位置(用星号表示)发生了变化。
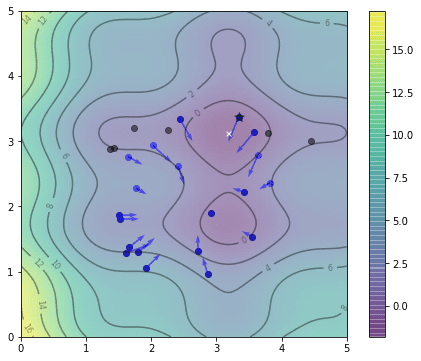
五次迭代后粒子的位置
这是第 20 次迭代后的结果,我们已经非常接近最优解了。
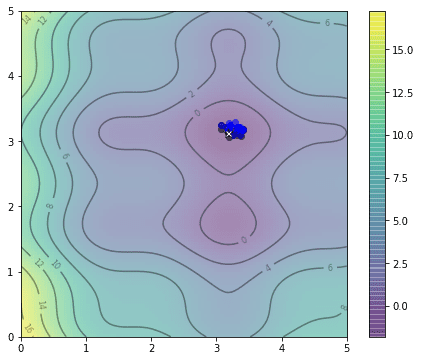
二十次迭代后粒子的位置
这是显示算法进程中如何找到最优解决方案的动画。看看是否能找到与鸟群运动的相似之处。

粒子运动的动画
那么我们的解决方案有多接近呢?在这个特定的例子中,我们通过穷举搜索找到的全局最小值位于坐标 $(3.182,3.131)$,而上面 PSO 算法找到的解决方案位于 $(3.185,3.130)$。
变体
正如我们上面提到的,所有 PSO 算法大部分是相同的。在上面的例子中,我们将 PSO 设置为在固定数量的迭代中运行。可以很容易地将迭代次数设置为动态响应进度。例如,我们可以设置当全局最佳解 $gbest$ 在一定次数的迭代中没有更新时停止。
PSO 的研究主要集中在如何确定超参数 $w$、$c_1$ 和 $c_2$,或者如何随着算法的进展改变它们的值。例如,有人提出将惯性权重线性递减。也有人提出使认知系数 $c_1$ 递减,同时使群体系数 $c_2$ 递增,以便在开始时进行更多探索,在结束时进行更多利用。有关示例,请参阅 Shi 和 Eberhart (1998) 以及 Eberhart 和 Shi (2000)。
完整示例
从上面的代码很容易看出我们如何将其更改为求解更高维的目标函数,或者从最小化切换到最大化。以下是求解上面提出的函数 $f(x,y)$ 的最小点以及生成绘图动画的代码的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 |
import numpy as np import matplotlib.pyplot as plt from matplotlib.animation import FuncAnimation def f(x,y): "目标函数" return (x-3.14)**2 + (y-2.72)**2 + np.sin(3*x+1.41) + np.sin(4*y-1.73) # 计算并以 3D 形式绘制 [0,5]x[0,5] 区域内的函数 x, y = np.array(np.meshgrid(np.linspace(0,5,100), np.linspace(0,5,100))) z = f(x, y) # 找到全局最小值 x_min = x.ravel()[z.argmin()] y_min = y.ravel()[z.argmin()] # 算法的超参数 c1 = c2 = 0.1 w = 0.8 # 创建粒子 n_particles = 20 np.random.seed(100) X = np.random.rand(2, n_particles) * 5 V = np.random.randn(2, n_particles) * 0.1 # 初始化数据 pbest = X pbest_obj = f(X[0], X[1]) gbest = pbest[:, pbest_obj.argmin()] gbest_obj = pbest_obj.min() def update(): "执行一次粒子群优化迭代的函数" global V, X, pbest, pbest_obj, gbest, gbest_obj # 更新参数 r1, r2 = np.random.rand(2) V = w * V + c1*r1*(pbest - X) + c2*r2*(gbest.reshape(-1,1)-X) X = X + V obj = f(X[0], X[1]) pbest[:, (pbest_obj >= obj)] = X[:, (pbest_obj >= obj)] pbest_obj = np.array([pbest_obj, obj]).min(axis=0) gbest = pbest[:, pbest_obj.argmin()] gbest_obj = pbest_obj.min() # 设置基础图形:等高线图 fig, ax= plt.subplots(figsize=(8,6)) fig.set_tight_layout(True) img = ax.imshow(z, extent=[0, 5, 0, 5], origin='lower', cmap='viridis', alpha=0.5) fig.colorbar(img, ax=ax) ax.plot([x_min], [y_min], marker='x', markersize=5, color="white") contours = ax.contour(x, y, z, 10, colors='black', alpha=0.4) ax.clabel(contours, inline=True, fontsize=8, fmt="%.0f") pbest_plot = ax.scatter(pbest[0], pbest[1], marker='o', color='black', alpha=0.5) p_plot = ax.scatter(X[0], X[1], marker='o', color='blue', alpha=0.5) p_arrow = ax.quiver(X[0], X[1], V[0], V[1], color='blue', width=0.005, angles='xy', scale_units='xy', scale=1) gbest_plot = plt.scatter([gbest[0]], [gbest[1]], marker='*', s=100, color='black', alpha=0.4) ax.set_xlim([0,5]) ax.set_ylim([0,5]) def animate(i): "PSO 算法的步骤:更新算法并显示在图中" title = '迭代 {:02d}'.format(i) # 更新参数 update() # 设置图片 ax.set_title(title) pbest_plot.set_offsets(pbest.T) p_plot.set_offsets(X.T) p_arrow.set_offsets(X.T) p_arrow.set_UVC(V[0], V[1]) gbest_plot.set_offsets(gbest.reshape(1,-1)) return ax, pbest_plot, p_plot, p_arrow, gbest_plot anim = FuncAnimation(fig, animate, frames=list(range(1,50)), interval=500, blit=False, repeat=True) anim.save("PSO.gif", dpi=120, writer="imagemagick") print("PSO在f({})={}(处找到最佳解)".format(gbest, gbest_obj)) print("全局最优解为f({})={}".format([x_min,y_min], f(x_min,y_min))) |
进一步阅读
这些是提出粒子群优化算法的原始论文,以及关于调整其超参数的早期研究
- Kennedy J. and Eberhart R. C. Particle swarm optimization. In Proceedings of the International Conference on Neural Networks; Institute of Electrical and Electronics Engineers. Vol. 4. 1995. pp. 1942–1948. DOI: 10.1109/ICNN.1995.488968
- Eberhart R. C. and Shi Y. Comparing inertia weights and constriction factors in particle swarm optimization. In Proceedings of the 2000 Congress on Evolutionary Computation (CEC ‘00). Vol. 1. 2000. pp. 84–88. DOI: 10.1109/CEC.2000.870279
- Shi Y. and Eberhart R. A modified particle swarm optimizer. In Proceedings of the IEEE International Conferences on Evolutionary Computation, 1998. pp. 69–73. DOI: 10.1109/ICEC.1998.699146
总结
在本教程中我们学习了
- 粒子群优化是如何工作的
- 如何实现 PSO 算法
- 算法的一些可能的变体
由于粒子群优化算法没有太多的超参数,并且对目标函数非常宽容,因此可以用来解决各种各样的问题。

")





Jason,文章写得非常好。感谢分享。
我们可以用它来寻找和设置神经网络的初始权重,以节省训练时间。并使用bep来寻找权重被优化且误差最小的全局最小值。
梯度下降可以做到这一点,但我们有梯度消失问题,而且训练时间很长,对于复杂的网络来说。所以,与其用一些随机权重初始化网络,不如从pso找到的优化权重开始,然后由bep完成剩余的工作。
我在多个项目上都这样做过,效果很好。
我同意,你可以用它来初始化神经网络的权重,并有望在更少的轮次中训练。你能告诉我你是否用TensorFlow或PyTorch等流行库做过吗?
如何将pso与ann或svm结合用于回归任务?或者任何其他机器学习算法?
我想我们可以将损失函数用作目标函数。
是的,你可以将整个模型封装为目标函数,然后应用你喜欢的优化算法。
谢谢您,先生。这篇文章非常有启发性。您有没有一个例子说明如何将PSO应用于我们的机器学习模型?
嗨 Amr……以下资源是一个很好的起点
https://link.springer.com/article/10.1007/s11831-021-09694-4
PSO是一种优化方法。例如,你可以用它来搜索最优超参数。只需将你的机器学习模型作为目标函数,然后对其参数应用PSO。
Adrian,
精彩的文章!粒子群技术正成为工作中一个很大的关注领域,而这是一个关于该主题的绝佳入门!
很高兴你喜欢它!
谢谢 Jason!我找这个找了很久,想用它来代替反向传播。
希望你喜欢!
谢谢你!
再次感谢,你不仅精确地涵盖了主题,还对PSO算法的功能进行了令人印象深刻的演示。你将它分解的方式令人钦佩!!
谢谢。很高兴你喜欢。
你能解释一下这个花哨的布尔索引吗?
pbest_obj = np.array([pbest_obj, obj]).max(axis=0)
如果 X 是一个向量,(X > n) 会给你一个布尔向量,“true”表示 X 的元素大于 n,否则为“false”。然后 Y[(X > n)] 会根据布尔值从 Y 中选择元素。这本质上是根据布尔值从 Y 中选择一个子向量或子矩阵。
亲爱的 Adrian Tam
谢谢你的精彩博文,以及如何将pso与机器学习算法在其他数据集上结合?比如 xgboost
这取决于你的目的。如果你想探索XGBoost的超参数,你可以将你的XGBoost模型包装成一个函数,输入是超参数,输出是分数。然后将这个函数输入到优化中,以找到最佳性能的超参数。
Adrian,
下午好!如果您有时间,我想知道您是否可以帮助我扩展一下。假设我想让粒子不仅仅搜索“x”,而是去追逐一个移动的“x”。有什么相对有效的方法可以做到这一点吗?为了简单起见,我似乎可以保持数据初始化部分不变。然后,也许定义一个正方形的点,例如,并使用这四个点作为pbest_obj和gbest_obj?
这是一个很棒的代码!我通过修改目标函数和超参数来深入了解算法是如何工作的,从中获益良多。非常感谢您发布此代码以及您宝贵的时间!
亲爱的 Adrian,
非常有用的文章。特别是图形部分!我只注意到下面一行有一个非常小的更正
pbest_obj = np.array([pbest_obj, obj]).max(axis=0)
我想 max(axis=0) 应该改为 min(axis=0),因为我们要寻找目标函数的最小值。你在“完整示例”部分已经更正了。
再次感谢,
Erfan,非常好的反馈!
我该如何设置约束和迭代次数?
嗨 Betty……您可能会发现以下内容很有趣
https://medium.com/swlh/particle-swarm-optimization-731d9fbb6923
同样的问题。是在“animate(i)”中吗?这里的“i”是迭代次数吗?
你好,
感谢教程。做得好!
我正在处理一个数据集,使用不同的算法(如 KNN 和 SVM(使用 Python 中的 sklearn 库))来查找手势分类的准确性。现在我需要使用粒子群优化算法来优化 SVM 找到的准确性。但我不知道该从哪里开始,遵循你的 PSO 指南。
我的 SVM 部分的实现已经完成,现在我想使用 PSO 来优化它。
关于此事,任何帮助都将不胜感激。或者即使你能指出正确的方向,也会有帮助。
再次感谢。
嗨 Ryan……请明确说明你试图完成什么,以及/或者教程中你不清楚如何应用的部分。
感谢您的回答,
我将从头开始解释。
我有一个 CSV 格式的数据集,其中包含关于手势作为特征提取的手势信息,其中包含小数(没有字符串)。作为参考,我附上了一篇论文的参考,以便更好地理解或解释我正在做的事情。
https://revistas.usal.es/index.php/2255-2863/article/view/ADCAIJ2021102123136
现在,我想计算哪个 ANN 算法变体(如 K 近邻、支持向量机、朴素贝叶斯、决策树等)在该数据集上能提供最佳准确性。因此,使用 Python 中的内置库(numpy、pandas、sklearn),我创建了一个 Python 代码,将我的数据分割成训练和测试集,然后将 SVM 等算法应用于我的数据集,并获得了 75% 的准确率。现在,我想使用粒子群优化或遗传算法等优化算法来提高这种准确性。对于那部分我需要帮助。例如……如何使用上面 Python 代码中的粒子群优化来优化 SVM 的准确性……?
你上面有一个 PSO 代码示例。我该如何按照你的例子来为我应用了 SVM 算法的数据集获得最好的结果……?
再次感谢您抽出时间阅读我的评论。
等待您的回复。
谢谢
我该如何为函数添加约束?
嗨 Monish……以下内容可能会让您感兴趣
https://www.cs.cinvestav.mx/~constraint/papers/eisci.pdf
嗨 James,
如果可能,您能否也回复我上面提出的评论?我将非常感激。
非常感谢。
嗨 James,
您能否花些时间评论我上面提出的问题?我将非常感谢您的帮助。
谢谢
精彩的演示,非常感谢您,先生
有一个小问题,在第三张图下面,在代码片段中,我认为第9行,max(axis=0)应该改为min(axis=0),就像完整的示例代码,第42行一样
再次非常感谢,解释得非常好。
您是否有使用 PSO(或其他,如 NSGA-III 或 MOEA/D)的多目标问题示例?
或者是否可以使用 pyMoo、playpus 或 jMetalPy?
您好 Keith…我们目前没有直接与这些概念相关的示例。
您有什么建议或参考资料,说明如何将 PSO 应用于多目标优化问题吗?
您好 Peter…以下论文是一个很好的起点
https://core.ac.uk/download/pdf/48631978.pdf
非常感谢,我有一个问题,请告诉我如何使用这个例子来优化甘特图上的日程安排。
您好 noor… 不客气!请澄清您模型的具体目标以及输入的性质,以便我们能更好地帮助您。
我该如何将上面的代码应用为甘特图的优化?
或者,代码如何与甘特图结合?
???? 帮帮我
我需要使用代码与甘特图调度 PSO 方法,我该如何做??
您好 sara…以下资源可能会有所帮助
https://www.researchgate.net/publication/260087478_A_Particle_Swarm_Optimization_Algorithm_for_Scheduling_Against_Restrictive_Common_Due_Dates
非常感谢,这很有帮助,但我能获得这篇论文的代码吗?
***论文
您好,关于解决任何优化问题,我有一个问题。我目前正在进行各项媒体的预算支出优化。我的历史数据格式为 x1, x2, x3, x4 和 y,其中 x1, x2, x3 和 x4 是输入变量,代表每个渠道的支出,y 是输出,即基于 x1 + x2 + x3 + x4 支出的总收入。最大的问题是如何从历史绩效数据中导出目标函数?您能帮帮我吗?我这几天一直在尝试找出答案,但一直没有成功。🙁
嗨
我需要使用 pso 来建模 keras conv1d
如何将其添加到模型中?以优化超参数
您好,我一直在尝试使用 cvxpy 库解决营销支出优化问题。我的输入是 x1, x2, x3 和 x4,输出是 y。因此,x1, x2, x3 和 x4 是每个媒体渠道的支出(我们有 4 个渠道),然后 y 是由于 x1 + x2 + x3 + x4 的联合支出而实现的总体收入。我也有所有 4 个渠道的个体渠道收入。现在我最大的挑战是如何导出目标函数来解决这类问题?您能否分享一些想法或任何指导,我将不胜感激。
您好 Siddharth…以下资源应该会引起您的兴趣
https://machinelearning.org.cn/optimization-for-machine-learning-crash-course/
嗨
我需要使用 pso 来建模 keras conv1d
如何将其添加到模型中?以优化超参数
您是否有使用模拟退火算法的 python 代码模型?
您好 Firman…以下资源可能会引起您的兴趣
https://machinelearning.org.cn/simulated-annealing-from-scratch-in-python/
您能否通过一个小型示例,一步一步地讨论全成员基于优化技术?先谢谢您。
您好 Lakshmi…以下资源可能会引起您的兴趣
https://www.techscience.com/cmc/v70n2/44661
嗨
感谢您的所有帮助????
我问如何使用 pso 来优化 cnn1d 的超参数过滤器??如果您能帮助我,请提供代码。
用几行代码很难实现,但我可以与您分享方法:为 CNN 创建一个函数,该函数接受超参数作为输入,并输出一些评估指标(例如,固定测试数据集的 MSE)。在函数中,您使用超参数构建 CNN,进行训练,然后进行评估。然后将 PSO 应用于此函数,PSO 用于更改超参数并观察函数的输出。
请注意,由于 PSO 中的每次迭代都需要创建多个 CNN 并对其进行评估,因此涉及大量计算。您需要耐心。
谢谢你,Json,这篇文章很棒,我开始从你的作品中学习这个算法。
我对下面的代码很好奇
python
pbest_obj = np.array([pbest_obj, obj]).max(axis=0)
我认为这可能是一个错误,您想要使用的函数是 min(axis=0)
您好 Dean…不客气!请详细说明您为什么不同意原始代码。
这个网站是学习优化、Python 和机器学习的最佳网站。我发现 Python 中至少有 12 种优化算法。是否有 ICA 的代码?国服竞争算法?
您好 MBT…我们非常感谢您的反馈!以下位置是我们所有内容的绝佳起点。
https://machinelearning.org.cn/start-here/
谢谢 Adrian Tam 的这篇文章。它真的很有帮助。我有一个问题。您能帮助我将 PSO 算法应用于 Kullback-Leibler 散度函数吗?
您好 Mebarka…以下资源是一个很好的起点
http://dx.doi.org/10.1371/journal.pcbi.1006694
谢谢 James 提供这份文件。
你好 James,
我之前读过您博客上的很多主题。所有解释都非常独特。我理解了 PSO 的概念。我需要一些帮助,将 PSO 应用于自定义 U-net 模型。请建议我如何编写目标函数以降低复杂性,PSO 的参数应该是什么,需要传递什么参数来初始化种群?
您好 Nagamani…下面是一个简化的示例,说明如何在 Python 中使用 `pyswarm` 库进行优化和 `tensorflow` 构建和训练 U-Net 模型来优化 U-Net 模型的超参数。此示例假设一个简单的二元图像分割任务。
pythonimport numpy as np
import tensorflow as tf
from pyswarm import pso
# 定义 U-Net 模型架构
def unet_model(input_shape, num_filters)
inputs = tf.keras.layers.Input(input_shape)
# Encoder
conv1 = tf.keras.layers.Conv2D(num_filters, 3, activation='relu', padding='same')(inputs)
pool1 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(conv1)
# Decoder
conv2 = tf.keras.layers.Conv2D(num_filters, 3, activation='relu', padding='same')(pool1)
up1 = tf.keras.layers.UpSampling2D(size=(2, 2))(conv2)
# Output
outputs = tf.keras.layers.Conv2D(1, 1, activation='sigmoid')(up1)
model = tf.keras.Model(inputs=inputs, outputs=outputs)
return model
# PSO 需要最小化的目标函数
def objective_function(params)
# 要优化的超参数
input_shape = (256, 256, 1)
num_filters = int(params[0])
# 构建 U-Net 模型
model = unet_model(input_shape, num_filters)
# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 虚拟数据(替换为您自己的数据)
x_train = np.random.rand(100, 256, 256, 1)
y_train = np.random.randint(2, size=(100, 256, 256, 1))
# 训练模型
model.fit(x_train, y_train, epochs=3, batch_size=32, verbose=0)
# 评估模型
loss, _ = model.evaluate(x_train, y_train, verbose=0)
return loss
# num_filters 的搜索空间边界
lb = [16] # num_filters 的下界
ub = [64] # num_filters 的上界
# 运行 PSO 优化
num_particles = 10
max_iterations = 20
best_params, _ = pso(objective_function, lb, ub, swarmsize=num_particles, maxiter=max_iterations)
print("最佳过滤器数量:", int(best_params[0]))
在此示例中:
– 我们使用简单的编码器-解码器结构定义 U-Net 模型架构。
– 目标函数 `objective_function` 接收 U-Net 模型中的过滤器数量作为输入,使用给定的超参数构建模型,对其进行训练,并返回验证损失。
– 我们使用 `pyswarm.pso` 函数来优化目标函数并找到最佳超参数。
– 搜索空间由过滤器数量的下界(`lb`)和上界(`ub`)定义。
请确保用您自己的数据集替换虚拟数据以进行训练和评估。此外,您可能需要根据您的具体任务和要求调整模型架构和目标函数。
非常感谢 James。
您能否建议我如何将遗传算法与粒子群优化算法结合起来进行超参数调优?