生成对抗网络(GAN)可能是最有效的图像合成生成模型。
然而,它们通常仅限于生成小图像,并且训练过程仍然脆弱,需要特定的增强和超参数才能获得良好结果。
BigGAN 是一种将近期训练类条件图像的最佳实践以及扩展批次大小和模型参数数量的套件整合在一起的方法。其结果是常规生成高分辨率(大)和高质量(高保真度)图像。
在这篇文章中,您将了解用于扩展类条件图像合成的 BigGAN 模型。
阅读本文后,你将了解:
- 图像大小和训练脆弱性仍然是 GAN 的主要问题。
- 扩展模型大小和批次大小可以显著生成更大、更高质量的图像。
- 扩展 GAN 需要特定的模型架构和训练配置。
通过我的新书《Python 生成对抗网络》启动您的项目,其中包括逐步教程和所有示例的Python 源代码文件。
让我们开始吧。

BigGAN 温和介绍
图片来源:rey perezoso,保留部分权利。
概述
本教程分为四个部分;它们是
- GAN 训练的脆弱性
- 通过扩展开发更好的 GAN
- 如何使用 BigGAN 扩展 GAN
- BigGAN 生成图像示例
GAN 训练的脆弱性
生成对抗网络,简称 GAN,能够生成高质量的合成图像。
然而,生成的图像大小仍然相对较小,例如 64×64 或 128×128 像素。
此外,尽管大量研究已经调查并提出了改进方案,模型训练过程仍然脆弱。
如果没有辅助的稳定技术,这种训练过程就非常脆弱,需要精确调整超参数和架构选择才能正常工作。
— 用于高保真自然图像合成的大规模 GAN 训练,2018。
训练过程的大多数改进都集中在目标函数或训练过程中约束判别器模型的更改上。
因此,最近的许多研究都集中在对原始 GAN 过程进行修改以实现稳定性,借鉴了日益增多的经验和理论见解。一个方向的工作是改变目标函数 […] 以鼓励收敛。另一个方向是侧重于通过梯度惩罚 [...] 或归一化 [...] 来约束 D,两者都是为了抵消无界损失函数的使用,并确保 D 在 G 的任何地方都提供梯度。
— 用于高保真自然图像合成的大规模 GAN 训练,2018。
最近,工作重点已转向 GAN 在生成高质量和更大图像方面的有效应用。
一种方法是尝试扩展已经运行良好的 GAN 模型。
想从零开始开发GAN吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
通过扩展开发更好的 GAN
BigGAN 是 GAN 架构的一种实现,旨在利用已普遍报告有效的最佳实践。
它由 Andrew Brock 等人在 2018 年的论文《用于高保真自然图像合成的大规模 GAN 训练》中描述,并发表于 ICLR 2019 会议。
具体来说,BigGAN 旨在用于类条件图像生成。也就是说,通过潜空间中的一个点和图像类别信息作为输入来生成图像。用于训练类条件 GAN 的示例数据集包括 CIFAR 或 ImageNet 图像分类数据集,这些数据集具有数十、数百或数千个图像类别。
顾名思义,BigGAN 专注于扩展 GAN 模型。
这包括具有以下特点的 GAN 模型:
- 更多模型参数(例如更多特征图)。
- 更大的批次大小
- 架构变更
我们证明了 GAN 从扩展中受益匪浅,并且与现有技术相比,训练的模型参数数量是其两到四倍,批次大小是其八倍。我们引入了两个简单、通用的架构变更,以提高可扩展性,并修改了一个正则化方案以改善条件化,显著提升了性能。
— 用于高保真自然图像合成的大规模 GAN 训练,2018。
BigGAN 架构还引入了图像生成过程中使用的“截断技巧”,该技巧可提高图像质量,并引入相应的正则化技术以更好地支持该技巧。
其结果是一种能够生成更大、更高质量图像的方法,例如 256×256 和 512×512 图像。
当在 ImageNet 上以 128×128 分辨率训练时,我们的模型(BigGAN)改进了最先进的技术 […] 我们还成功地在 ImageNet 上以 256×256 和 512×512 分辨率训练了 BigGAN …
— 用于高保真自然图像合成的大规模 GAN 训练,2018。
如何使用 BigGAN 扩展 GAN
BigGAN 模型的贡献在于模型和训练过程的设计决策。
这些设计决策对于重新实现 BigGAN 以及提供关于可能对 GAN 更普遍有利的配置选项的见解都非常重要。
BigGAN 模型的目标是增加模型参数的数量和批次大小,然后配置模型和训练过程以达到最佳结果。
在本节中,我们将回顾 BigGAN 中的具体设计决策。
1. 自注意力模块和合页损失
该模型的基础是自注意力 GAN,简称 SAGAN,由 Han Zhang 等人在 2018 年的论文《自注意力生成对抗网络》中描述。这涉及引入一个应用于特征图的注意力图,允许生成器和判别器模型关注图像的不同部分。
这涉及在深度卷积模型架构中添加注意力模块。
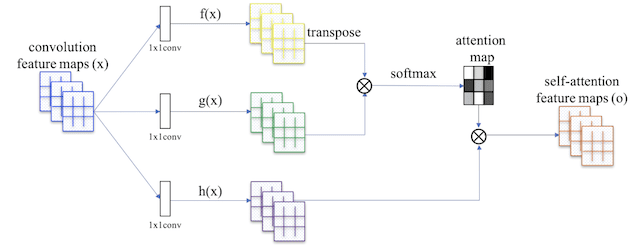
自注意力 GAN 中使用的自注意力模块概述。
摘自:自注意力生成对抗网络。
此外,该模型通过 合页损失 进行训练,该损失通常用于训练支持向量机。
在 SAGAN 中,所提出的注意力模块已应用于生成器和判别器,它们通过最小化对抗损失的合页版本以交替方式进行训练。
— 自注意力生成对抗网络,2018。
BigGAN 使用带有 SAGAN 注意力模块的模型架构,并通过合页损失进行训练。
论文附录 B 标题为“架构细节”,概述了生成器和判别器模型中使用的模块及其配置。描述了两个版本的模型:BigGAN 和 BigGAN-deep,后者涉及更深层的 resnet 模块,并因此获得了更好的结果。
2. 类别条件信息
类别信息通过类别条件批次归一化提供给生成器模型。
这由 Vincent Dumoulin 等人在其 2016 年的论文《一种用于艺术风格的学习表示》中描述。在论文中,该技术被称为“条件实例归一化”,它涉及根据给定风格图像的统计数据对激活进行归一化,或者在 BigGAN 的情况下,根据给定类别图像的统计数据对激活进行归一化。
我们称这种方法为条件实例归一化。该过程的目标是 [将] 层的激活 x 转换为特定于绘画风格 s 的归一化激活 z。
— 一种用于艺术风格的学习表示,2016。
类别信息通过投影提供给判别器。
这由 Takeru Miyato 等人在其 2018 年的论文《生成对抗网络的谱归一化》中描述。这涉及使用类别值的整数嵌入,该嵌入被连接到网络的中间层。
条件 GAN 的判别器。为了计算简便,我们将 {0, . . . , 1000} 中的整数标签 y 嵌入到 128 维,然后将该向量连接到中间层的输出。
— 生成对抗网络的谱归一化,2018。
为了减少权重数量,使用了共享嵌入,而不是每个类别标签一个类别嵌入。
我们选择使用共享嵌入,而不是为每个嵌入设置单独的层,该共享嵌入线性投影到每个层的增益和偏置。这减少了计算和内存成本,并通过 37% 提高了训练速度(达到给定性能所需的迭代次数)。
— 用于高保真自然图像合成的大规模 GAN 训练,2018。
3. 谱归一化
生成器的权重使用谱归一化进行归一化。
生成对抗网络中使用的谱归一化由 Takeru Miyato 等人在其 2018 年的论文《生成对抗网络的谱归一化》中描述。具体来说,它涉及对权重矩阵的谱范数进行归一化。
我们的谱归一化对权重矩阵 W 的谱范数进行归一化,使其满足 Lipschitz 约束 sigma(W) = 1
— 生成对抗网络的谱归一化,2018。
高效的实现需要在小批量随机梯度下降期间更改权重更新,这在谱归一化论文的附录 A 中有描述。

带谱归一化的 SGD 算法
摘自:生成对抗网络的谱归一化
4. 判别器更新次数多于生成器
在 GAN 训练算法中,通常先更新判别器模型,然后再更新生成器模型。
BigGAN 对此进行了轻微修改,在每次训练迭代中,先更新判别器模型两次,然后再更新生成器模型。
5. 模型权重的移动平均
生成器模型根据生成的图像进行评估。
在生成图像进行评估之前,模型权重通过 移动平均 在先前的训练迭代中进行平均。
这种用于生成器评估的模型权重移动平均方法由 Tero Karras 等人在其 2017 年的论文《GAN 的渐进式增长以提高质量、稳定性和多样性》中描述和使用。
…为了在训练期间任何给定点可视化生成器输出,我们对生成器的权重使用指数移动平均,衰减率为 0.999。
——《GAN 的渐进式增长以提高质量、稳定性和变异性》,2017年。
6. 正交权重初始化
模型权重使用正交初始化进行初始化。
这由 Andrew Saxe 等人在其 2013 年的论文《深度线性神经网络中学习非线性动力学的精确解》中描述。这涉及将权重设置为随机正交矩阵。
…将每层的初始权重设置为随机正交矩阵(满足 W^T . W = I)…
— 深度线性神经网络中学习非线性动力学的精确解,2013。
请注意,Keras 直接支持正交权重初始化。
7. 更大的批次大小
测试并评估了非常大的批次大小。
这包括 256、512、1024 和 2048 图像的批次大小。
更大的批次大小通常会生成更高质量的图像,其中批次大小为 2048 图像时达到最佳图像质量。
…简单地将批次大小增加 8 倍,就能将最先进的 IS 提高 46%。
— 用于高保真自然图像合成的大规模 GAN 训练,2018。
直观地说,更大的批次大小提供了更多的“模式”,进而为更新模型提供了更好的梯度信息。
我们推测这是因为每个批次覆盖了更多的模式,为两个网络提供了更好的梯度。
— 用于高保真自然图像合成的大规模 GAN 训练,2018。
8. 更多模型参数
模型参数的数量也急剧增加。
这是通过将每个层中的通道或特征图(滤波器)数量加倍来实现的。
然后,我们将每个层的宽度(通道数)增加 50%,使两个模型中的参数数量大约翻倍。这导致 IS 进一步提高了 21%,我们认为这是由于模型相对于数据集复杂性的容量增加所致。
— 用于高保真自然图像合成的大规模 GAN 训练,2018。
9. Skip-z 连接
在生成器模型中添加了跳跃连接,以将输入潜在点直接连接到网络深处的特定层。
这些被称为 skip-z 连接,其中 z 指的是输入潜在向量。
接下来,我们从噪声向量 z 到 G 的多个层添加直接跳跃连接(skip-z),而不仅仅是初始层。这种设计背后的直觉是允许 G 使用潜在空间直接影响不同分辨率和层次结构级别的特征。[...] Skip-z 提供了大约 4% 的适度性能提升,并使训练速度进一步提高了 18%。
— 用于高保真自然图像合成的大规模 GAN 训练,2018。
10. 截断技巧
截断技巧涉及在训练期间和推理或图像合成期间对生成器的潜在空间使用不同的分布。
在训练期间使用高斯分布,在推理期间使用截断高斯分布。这被称为“截断技巧”。
我们称之为截断技巧:通过重新采样幅度超过选定阈值的值来截断 z 向量,可以在降低整体样本多样性的情况下提高单个样本的质量。
— 用于高保真自然图像合成的大规模 GAN 训练,2018。
截断技巧在图像质量或保真度与图像多样性之间提供了权衡。较窄的采样范围可获得更好的质量,而较大的采样范围可获得更多样化的采样图像。
这种技术允许对给定 G 的样本质量和多样性之间的权衡进行精细的后验选择。
— 用于高保真自然图像合成的大规模 GAN 训练,2018。
11. 正交正则化
并非所有模型都能很好地响应截断技巧。
当使用截断技巧时,一些较深的模型会产生饱和伪影。
为了更好地鼓励更广泛的模型与截断技巧良好配合,使用了正交正则化。
这由 Andrew Brock 等人在其 2016 年的论文《使用内省对抗网络的神经照片编辑》中介绍。
这与正交权重初始化有关,并引入了权重正则化项,以鼓励权重保持其正交属性。
正交性是 ConvNet 滤波器中一种理想的品质,部分原因在于正交矩阵的乘法不会改变原始矩阵的范数。[...] 我们提出了一种简单的权重正则化技术,即正交正则化,通过将权重推向最近的正交流形来鼓励它们正交。
— 使用内省对抗网络的神经照片编辑,2016。
BigGAN 生成图像示例
BigGAN 能够生成大型、高质量的图像。
在本节中,我们将回顾论文中提出的一些示例。
以下是 BigGAN 生成的一些高质量图像示例。

BigGAN 生成的高质量类别条件图像示例。
摘自:用于高保真自然图像合成的大规模 GAN 训练。
以下是 BigGAN 生成的大尺寸高质量图像示例。

BigGAN 生成的大尺寸高质量类别条件图像示例。
摘自:用于高保真自然图像合成的大规模 GAN 训练。
训练 BigGAN 生成器时描述的一个问题是“类别泄露”的概念,这是一种新型的故障模式。
下面是一个部分训练的 BigGAN 产生的类别泄露示例,显示了网球和狗的交叉。

部分训练的 BigGAN 生成图像中的类别泄露示例。
摘自:用于高保真自然图像合成的大规模 GAN 训练。
以下是 BigGAN 以 256×256 分辨率生成的一些额外图像。

BigGAN 生成的大尺寸高质量 256×256 类别条件图像示例。
摘自:用于高保真自然图像合成的大规模 GAN 训练。
以下是 BigGAN 以 512×512 分辨率生成的更多图像。

BigGAN 生成的大尺寸高质量 512×512 类别条件图像示例。
摘自:用于高保真自然图像合成的大规模 GAN 训练。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- 用于高保真自然图像合成的大规模 GAN 训练, 2018.
- 用于高保真自然图像合成的大规模 GAN 训练,ICLR 2019.
- 自注意力生成对抗网络, 2018.
- 一种用于艺术风格的学习表示, 2016.
- 生成对抗网络的谱归一化, 2018.
- GAN 的渐进式增长以提高质量、稳定性和变异性, 2017.
- 深度线性神经网络中学习非线性动力学的精确解, 2013.
- 使用内省对抗网络的神经照片编辑, 2016.
代码
文章
总结
在这篇文章中,您了解了用于扩展类条件图像合成的 BigGAN 模型。
具体来说,你学到了:
- 图像大小和训练脆弱性仍然是 GAN 的主要问题。
- 扩展模型大小和批次大小可以显著生成更大、更高质量的图像。
- 扩展 GAN 需要特定的模型架构和训练配置。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发生成对抗网络!

在几分钟内开发您的GAN模型
...只需几行python代码在我的新电子书中探索如何实现
使用 Python 构建生成对抗网络
它提供了关于以下内容的自学教程和端到端项目:
DCGAN、条件GAN、图像翻译、Pix2Pix、CycleGAN
以及更多...





 From Scratch")
你能提供 big gan 的 keras 实现吗
感谢您的建议。
嗨,Jason,
将来会有与此类似性能的 GAN 架构吗?用于在真实传感器数据上训练,以生成伪多变量时间序列(例如 200 个时间步长 x 8 个变量),而不是图像。您知道任何能够实现这一点的 GAN 或实现吗?
谢谢你
祝好
抱歉,我没有时间序列 GAN 的示例。
感谢您的解释。您是否有任何 Keras 示例可以分享,用于执行自注意力模块和合页损失?
不客气。
目前还没有。
第 2 节(类别条件信息)中的信息具有误导性。关于判别器的条件,BigGAN 论文引用的是 Miyato 2018 的“cGANS with Projection Discriminator”,而不是谱归一化论文。条件信息是通过投影而不是拼接提供的。
谢谢。
嗨,Jason,
那么,当使用 Miyatos 2018 论文“cGANS with Projection Discriminator”中使用的合页损失时,我们是否期望判别器和生成器的损失都最小化?我正在研究一个例子,看起来生成器的损失对于性能更好的模型正在增加,所以我有点困惑。
关于那篇论文,我不能立刻确定。通常对于 GAN,不,它们不会最小化损失/收敛。
感谢您如此精彩的解释。我如何评估 BigGAN 判别器在无监督/无条件学习中的性能?损失函数应该是什么样的?
嗨!
我是这个领域的新手,希望你能回答我。我们知道生成器和判别器的输入都是分布。我的问题是图像如何变成分布
嗨 raga…以下资源可能会提供帮助
https://github.com/abhijitramesh/GAN-under-the-hood
https://towardsdatascience.com/how-gans-really-work-2e1db1f407bb
这很好
感谢您的反馈!如果您对我们的教程或其他内容有任何疑问,请告诉我们。