中心极限定理是统计学和机器学习中经常被引用但又常被误解的基石。
它经常与大数定律混淆。尽管该定理对初学者来说可能显得有些晦涩,但它对于我们如何以及为何能够推断机器学习模型的性能至关重要,例如一个模型是否在统计学上优于另一个模型,以及模型性能的置信区间。
在本教程中,您将了解中心极限定理及其作为统计学和概率学重要基石对应用机器学习的影响。
完成本教程后,您将了解:
- 中心极限定理将样本均值的分布形状描述为高斯分布,这是一个统计学领域非常熟悉的分布。
- 如何在Python中开发一个模拟掷骰子示例来演示中心极限定理。
- 中心极限定理和高斯分布知识如何在应用机器学习中用于推断模型性能。
开启您的项目,阅读我的新书《机器学习统计学》,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。

机器学习中心极限定理入门指南
照片作者:Alan Levine,部分权利保留。
教程概述
本教程分为3个部分;它们是
- 中心极限定理
- 带示例的计算
- 对机器学习的影响
需要机器学习统计学方面的帮助吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
中心极限定理
中心极限定理,简称CLT,是统计学和概率学领域一项重要的发现和基石。
初看之下可能有些晦涩,请坚持住。事实证明,这项发现对于在应用机器学习中进行推断至关重要。
该定理指出,随着样本量的增加,多个样本的均值分布将近似于高斯分布。
让我们来分解一下。
我们可以想象进行一次试验并得到一个结果或观测值。我们可以再次重复试验并得到一个新的独立观测值。收集起来,多个观测值就代表了一个样本。
样本是来自一个更广泛总体(所有可能的观测值)的观测值集合。
- 观测值:实验一次试验的结果。
- 样本:从独立试验中收集的一组结果。
- 总体:一次试验可能看到的全部可能观测值的空间。
如果我们计算一个样本的均值,它将是总体分布均值的一个估计。但是,与任何估计一样,它会包含一些误差。如果我们抽取多个独立样本并计算它们的均值,那么这些均值的分布将形成高斯分布。
重要的是,导致观测值的每一次试验都必须是独立的,并且以相同的方式进行。这是为了确保样本是从相同的潜在总体分布中抽取的。更正式地说,这种期望被称为独立同分布,或 iid。
首先,中心极限定理非常令人印象深刻,尤其是在我们从中抽取样本的总体分布形状如何时,它都会发生。它表明估计总体均值的误差分布符合统计学领域非常了解的分布。
其次,随着从总体中抽取的样本量增加,这种高斯分布的估计将变得更准确。这意味着如果我们利用我们对高斯分布的一般了解来开始推断从总体中抽取的样本均值,那么随着我们增加样本量,这些推断将变得更有用。
中心极限定理的一个有趣推论是一位非常聪明的科学家曾告诉我,你可以用它来生成高斯随机数。你可以生成均匀分布的随机整数,将它们组合起来,这些和的结果将是高斯分布的。请记住,均值只是样本的归一化和。它比其他方法(如Box-Muller方法)生成随机高斯变量的速度慢,但这是该定理的一个清晰(且巧妙)的应用。
大数定律
初学者经常将中心极限定理与大数定律混淆。
大数定律是统计学中的另一个不同定理。它更简单,因为它指出随着样本量的增加,样本均值将成为总体均值更准确的估计。
中心极限定理并未说明单个样本均值的情况;相反,它更广泛,说明了样本均值的形状或分布。
大数定律是直观的。这就是为什么我们认为收集更多数据将导致对领域观测值进行更具代表性的抽样。该定理支持了这种直觉。
中心极限定理并不直观。相反,这是一个我们可以利用以对样本均值进行声明的发现。
带示例的计算
我们可以通过一个涉及掷骰子的示例来具体化中心极限定理。
请记住,骰子是一个立方体,每个面都有一个从1到6的数字。每次掷骰子出现每个数字的概率都是六分之一。由于概率相等,掷骰子出现的数字分布是均匀的。
我们可以使用NumPy的randint()函数生成指定数量(例如50个)介于1到6之间的随机掷骰子次数。
|
1 2 |
# 生成一个骰子投掷样本 rolls = randint(1, 7, 50) |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 |
# 生成随机骰子投掷 from numpy.random import seed from numpy.random import randint from numpy import mean # 为随机数生成器设置种子 seed(1) # 生成一个骰子投掷样本 rolls = randint(1, 7, 50) print(rolls) print(mean(rolls)) |
运行该示例将生成并打印50次骰子投掷的样本以及样本的平均值。
我们知道该分布的平均值是3.5,计算方法为 (1 + 2 + 3 + 4 + 5 + 6) / 6 或 21 / 6。
我们可以看到样本的平均值略有偏差,这是可以预期的,因为它是总体均值的一个估计。
|
1 2 3 |
[6 4 5 1 2 4 6 1 1 2 5 6 5 2 3 5 6 3 5 4 5 3 5 6 3 5 2 2 1 6 2 2 6 2 2 1 5 2 1 1 6 4 3 2 1 4 6 2 2 4] 3.44 |
这是模拟骰子投掷50次的结果。
然后,我们可以多次重复此过程,例如1000次。这将使我们得到1000个样本均值。根据中心极限定理,这些样本均值的分布将是高斯分布。
下面的示例执行了此实验,并绘制了样本均值分布的图。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 中心极限定理演示 from numpy.random import seed from numpy.random import randint from numpy import mean from matplotlib import pyplot # 为随机数生成器设置种子 seed(1) # 计算1000次50次骰子投掷的平均值 means = [mean(randint(1, 7, 50)) for _ in range(1000)] # 绘制样本均值分布 pyplot.hist(means) pyplot.show() |
运行该示例将生成样本均值的直方图。
从分布的形状可以看出,该分布是高斯分布。值得注意的是,在1000次50次骰子投掷试验中,我们可以看到样本均值中存在的误差。
此外,中心极限定理还指出,随着每个样本的大小(在此为50)增加,样本均值将更好地逼近高斯分布。
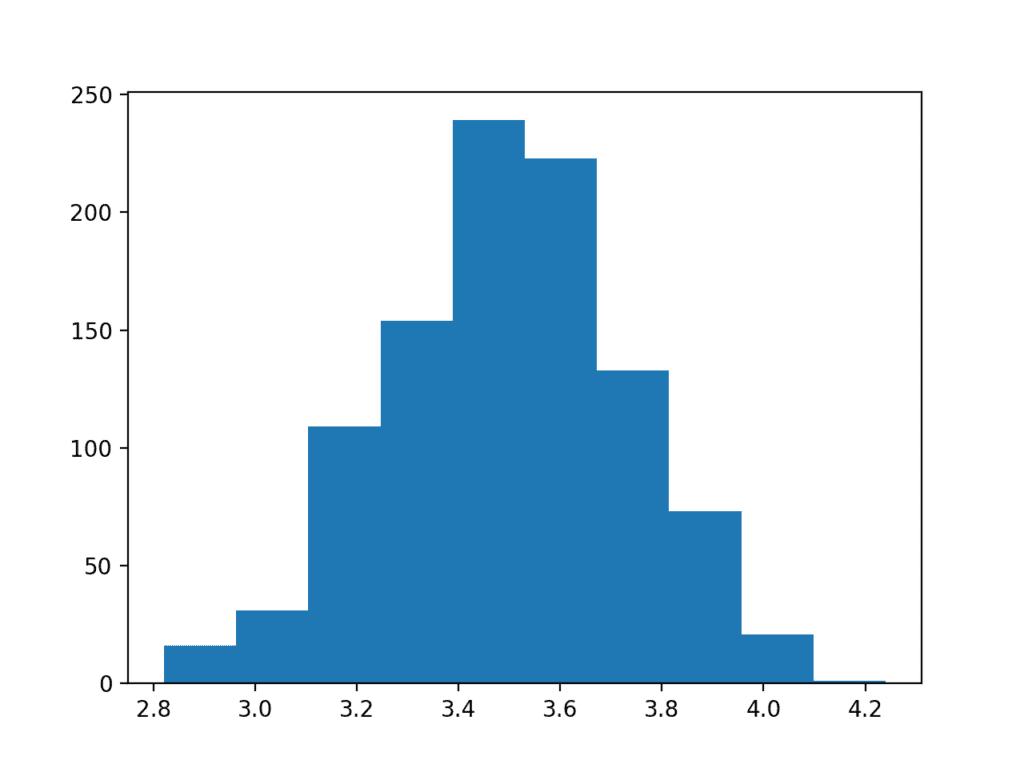
来自骰子投掷的样本均值直方图
对机器学习的影响
中心极限定理对应用机器学习有重要意义。
该定理确实为线性回归等线性算法提供了解决方案,但并不适用于人工神经网络等需要数值优化方法来解决的奇异算法。相反,我们必须通过实验来观察和记录算法的行为,并使用统计方法来解释其结果。
让我们看两个重要的例子。
显著性检验
为了对一个模型的性能与另一个模型的性能进行推断,我们必须使用统计显著性检验等工具。
这些工具估计两个模型性能得分样本来自相同或不同未知潜在模型性能得分分布的概率。如果样本看起来是从同一总体中抽取的,那么就假定模型性能之间没有差异,任何实际差异都归因于统计噪声。
能够进行此类推断的能力归功于中心极限定理以及我们对高斯分布的了解,以及两个样本均值作为样本均值的高斯分布的一部分的可能性。
置信区间
在训练好最终模型后,我们可能希望对其在实践中的预期性能进行推断。
这种不确定性的呈现称为置信区间。
我们可以进行多个独立(或接近独立)的模型准确性评估,以产生候选性能估计的总体。这些性能估计的平均值将是对模型在该问题上真实潜在性能的估计(带有误差)。
由于中心极限定理知道样本均值将是高斯分布的一部分,我们可以利用高斯分布的知识来估计样本均值基于样本量的可能性,并计算围绕模型性能所需的置信度区间。
扩展
本节列出了一些您可能希望探索的扩展本教程的想法。
- 在应用机器学习中有两个额外领域,中心极限定理可能相关。
- 实现一个利用中心极限定理和从均匀分布中提取的数字来生成随机高斯数的函数。
- 更新骰子投掷演示,以展示样本量与样本均值高斯分布保真度之间的关系。
如果您探索了这些扩展中的任何一个,我很想知道。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
API
文章
总结
在本教程中,您了解了中心极限定理及其作为统计学和概率学重要基石对应用机器学习的影响。
具体来说,你学到了:
- 中心极限定理将样本均值的分布形状描述为高斯分布,这是一个统计学领域非常熟悉的分布。
- 如何在Python中开发一个模拟掷骰子示例来演示中心极限定理。
- 中心极限定理和高斯分布知识如何用于推断应用机器学习中的模型性能。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







嗨,Jason,
我们需要一本关于统计学的书,就像线性代数一样。
线性代数书给了我很大的信心。
感谢您出色的工作和教程。
汤姆
很快就会有。我非常期待!
统计学书籍会添加到套装中吗?有预计时间吗?
我将创建一个新的套装,其中包含统计学书籍
https://machinelearning.org.cn/faq/single-faq/do-i-get-new-books-for-free-if-i-buy-the-super-bundle
我希望我的编辑能在本月晚些时候完成本书的审校。
嗨Jason,迫不及待的好消息!
谢谢Matthew。
您将来是否计划创建一些关于微积分的内容?
是的,我希望如此。
您希望对哪些特定主题进行更深入的报道或进行示例计算?
嗨Jason,感谢您最近发表的关于统计学的文章!如果能有一本关于《机器学习统计学基础》的新书,我非常期待🙂
是的,应该很快就会有。
谢谢!
嗨,Jason,
这是一篇非常好的文章,请您能否也写一篇关于假设检验如何与机器学习结合使用的文章?
谢谢
Murali
我会的,谢谢您的建议。
我突然想到,也许积分(exp(-x^2))可以写成积分(Smooth(_/\_)),就像你把三角形形状在Blender 3D软件中以某种方式平滑一样。
我听说很多人引用CLT作为允许非正态数据用于需要正态分布数据的ML模型的依据。CLT是否可以应用于数据集特征,作为使其变为正态的转换?
在我(有限的)实践中没有见过这种情况。
也许你可以在scholar.google.com上找到一些例子/论文?