向量空间模型用于考虑数据之间由向量表示的关系。它在信息检索系统中很受欢迎,但也可用于其他目的。通常,它允许我们从几何角度比较两个向量的相似性。
在本教程中,我们将了解什么是向量空间模型以及它的作用。
完成本教程后,您将了解:
- 什么是向量空间模型以及余弦相似度的性质
- 余弦相似度如何帮助您比较两个向量
- 余弦相似度和L2距离之间有什么区别
让我们开始吧。

向量空间模型简明介绍
照片作者:liamfletch,保留部分权利。
教程概述
本教程分为3个部分;它们是
- 向量空间与余弦公式
- 使用向量空间模型进行相似度计算
- 向量空间模型和余弦距离的常见用法
向量空间与余弦公式
向量空间是一个定义某些向量运算的数学术语。通俗地说,我们可以将其想象成一个 $n$ 维度量空间,其中每个点都由一个 $n$ 维向量表示。在这个空间中,我们可以进行任何向量加法或标量-向量乘法。
考虑向量空间是有益的,因为它有助于将事物表示为向量。例如,在机器学习中,我们通常有一个具有多个特征的数据点。因此,将数据点表示为向量会很方便。
使用向量,我们可以计算其**范数**。最常见的是 L2 范数或向量的长度。对于同一向量空间中的两个向量,我们可以找到它们的差值。假设这是一个 3 维向量空间,两个向量为 $(x_1, x_2, x_3)$ 和 $(y_1, y_2, y_3)$。它们的差值是向量 $(y_1-x_1, y_2-x_2, y_3-x_3)$,差值的 L2 范数是这两个向量之间的**距离**,或者更准确地说,是欧几里得距离。
$$
\sqrt{(y_1-x_1)^2+(y_2-x_2)^2+(y_3-x_3)^2}
$$
除了距离,我们还可以考虑两个向量之间的**夹角**。如果我们考虑向量 $(x_1, x_2, x_3)$ 为 3D 坐标系中从点 $(0,0,0)$ 到 $(x_1,x_2,x_3)$ 的线段,那么还有另一条从 $(0,0,0)$ 到 $(y_1,y_2, y_3)$ 的线段。它们在相交处形成一个角度。
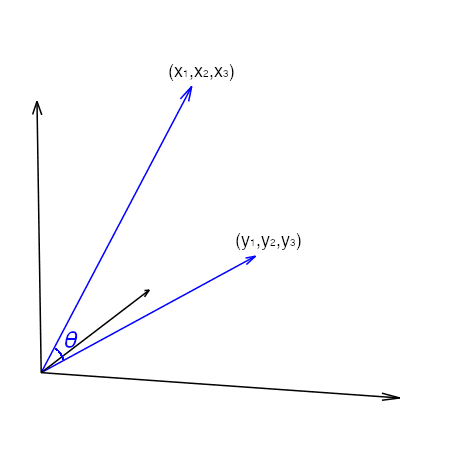
可以使用余弦公式找到两条线段之间的夹角。
$$
\cos \theta = \frac{a\cdot b} {\lVert a\rVert_2\lVert b\rVert_2}
$$
其中 $a\cdot b$ 是向量点积,$\lVert a\rVert_2$ 是向量 $a$ 的 L2 范数。该公式源于将点积视为向量 $a$ 在向量 $b$ 指向的方向上的投影。余弦的性质表明,随着角度 $\theta$ 从 0 度增加到 90 度,余弦值从 1 减小到 0。有时我们会将 $1-\cos\theta$ 称为**余弦距离**,因为它随着两个向量相互远离而从 0 变为 1。这是我们将在向量空间模型中利用的一个重要属性。
使用向量空间模型进行相似度计算
让我们看一个向量空间模型有用的例子。
世界银行收集了关于世界各国和地区的各种数据。虽然每个国家都不同,但我们可以尝试在向量空间模型下进行比较。为了方便起见,我们将使用 Python 中的 pandas_datareader 模块从世界银行读取数据。您可以使用 pip 或 conda 命令安装 pandas_datareader。
|
1 |
pip install pandas_datareader |
世界银行收集的数据系列通过标识符命名。例如,“SP.URB.TOTL”是国家/地区的总城市人口。许多系列是每年的。当我们下载一个系列时,我们必须输入开始和结束年份。通常数据更新不及时。因此,最好查看几年前的数据,而不是最近一年的数据,以避免数据丢失。
下面,我们尝试在 2010 年收集**所有**国家的某些经济数据。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
from pandas_datareader import wb import pandas as pd pd.options.display.width = 0 names = [ "NE.EXP.GNFS.CD", # 出口商品和服务(当前美元) "NE.IMP.GNFS.CD", # 进口商品和服务(当前美元) "NV.AGR.TOTL.CD", # 农业、林业和渔业增加值(当前美元) "NY.GDP.MKTP.CD", # GDP(当前美元) "NE.RSB.GNFS.CD", # 商品和服务对外收支差额(当前美元) ] df = wb.download(country="all", indicator=names, start=2010, end=2010).reset_index() countries = wb.get_countries() non_aggregates = countries[countries["region"] != "Aggregates"].name df_nonagg = df[df["country"].isin(non_aggregates)].dropna() print(df_nonagg) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
国家 年份 NE.EXP.GNFS.CD NE.IMP.GNFS.CD NV.AGR.TOTL.CD NY.GDP.MKTP.CD NE.RSB.GNFS.CD 50 阿尔巴尼亚 2010 3.337089e+09 5.792189e+09 2.141580e+09 1.192693e+10 -2.455100e+09 51 阿尔及利亚 2010 6.197541e+10 5.065473e+10 1.364852e+10 1.612073e+11 1.132067e+10 54 安哥拉 2010 5.157282e+10 3.568226e+10 5.179055e+09 8.379950e+10 1.589056e+10 55 安提瓜和巴布达 2010 9.142222e+08 8.415185e+08 1.876296e+07 1.148700e+09 7.270370e+07 56 阿根廷 2010 8.020887e+10 6.793793e+10 3.021382e+10 4.236274e+11 1.227093e+10 .. ... ... ... ... ... ... ... 259 委内瑞拉,RB 2010 1.121794e+11 6.922736e+10 2.113513e+10 3.931924e+11 4.295202e+10 260 越南 2010 8.347359e+10 9.299467e+10 2.130649e+10 1.159317e+11 -9.521076e+09 262 西岸和加沙 2010 1.367300e+09 5.264300e+09 8.716000e+08 9.681500e+09 -3.897000e+09 264 赞比亚 2010 7.503513e+09 6.256989e+09 1.909207e+09 2.026556e+10 1.246524e+09 265 津巴布韦 2010 3.569254e+09 6.440274e+09 1.157187e+09 1.204166e+10 -2.871020e+09 [174 行 x 7 列] |
上面我们获得了 2010 年各国的一些经济指标。wb.download() 函数将从世界银行下载数据并返回一个 pandas DataFrame。类似地,wb.get_countries() 将获取世界银行标识的国家和地区名称,我们将用它来过滤掉“东亚”和“世界”等非国家汇总。Pandas 允许通过布尔索引过滤行,其中 df["country"].isin(non_aggregates) 给出了一个布尔向量,指示哪些行在 non_aggregates 列表中,并在此基础上,df[df["country"].isin(non_aggregates)] 选择其中那些。出于各种原因,并非所有国家/地区都拥有所有数据。因此,我们使用 dropna() 删除那些数据缺失的。实际上,我们可能希望应用一些插补技术而不是仅仅删除它们。但作为一个例子,我们继续处理剩余的 174 个数据点。
为了更好地说明想法,而不是将实际操作隐藏在 pandas 或 numpy 函数中,我们首先将每个国家/地区的数据提取为向量。
|
1 2 3 4 5 6 |
... vectors = {} for rowid, row in df_nonagg.iterrows(): vectors[row["country"]] = row[names].values 打印(vectors) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
{'阿尔巴尼亚': array([3337088824.25553, 5792188899.58985, 2141580308.0144, 11926928505.5231, -2455100075.33431], dtype=object), '阿尔及利亚': array([61975405318.205, 50654732073.2396, 13648522571.4516, 161207310515.42, 11320673244.9655], dtype=object), '安哥拉': array([51572818660.8665, 35682259098.1843, 5179054574.41704, 83799496611.2004, 15890559562.6822], dtype=object), ... '西岸和加沙': array([1367300000.0, 5264300000.0, 871600000.0, 9681500000.0, -3897000000.0], dtype=object), '赞比亚': array([7503512538.82554, 6256988597.27752, 1909207437.82702, 20265559483.8548, 1246523941.54802], dtype=object), '津巴布韦': array([3569254400.0, 6440274000.0, 1157186600.0, 12041655200.0, -2871019600.0], dtype=object)} |
我们创建的 Python 字典以每个国家的名称作为键,以经济指标作为 numpy 数组。有 5 个指标,因此每个指标都是一个 5 维向量。
这有什么帮助呢?我们可以使用每个国家的向量表示来查看它与另一个国家有多相似。让我们同时尝试差值的 L2 范数(欧几里得距离)和余弦距离。我们选择一个国家,例如澳大利亚,并根据选定的经济指标将其与列表中的所有其他国家进行比较。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
... import numpy as np euclid = {} cosine = {} target = "Australia" for country in vectors: vecA = vectors[target] vecB = vectors[country] dist = np.linalg.norm(vecA - vecB) cos = (vecA @ vecB) / (np.linalg.norm(vecA) * np.linalg.norm(vecB)) euclid[country] = dist # 欧几里得距离 cosine[country] = 1-cos # 余弦距离 |
在上面的 for 循环中,我们将 vecA 设置为目标国家(即澳大利亚)的向量,将 vecB 设置为另一个国家的向量。然后,我们计算它们差值的 L2 范数作为两个向量之间的欧几里得距离。我们还使用公式计算余弦相似度,并从中减去 1 以获得余弦距离。拥有一百多个国家,我们可以看到哪个国家与澳大利亚的欧几里得距离最近。
|
1 2 3 4 5 |
... import pandas as pd df_distance = pd.DataFrame({"euclid": euclid, "cos": cosine}) print(df_distance.sort_values(by="euclid").head()) |
|
1 2 3 4 5 6 |
euclid cos 澳大利亚 0.000000e+00 -2.220446e-16 墨西哥 1.533802e+11 7.949549e-03 西班牙 3.411901e+11 3.057903e-03 土耳其 3.798221e+11 3.502849e-03 印度尼西亚 4.083531e+11 7.417614e-03 |
通过对结果进行排序,我们可以看到,在欧几里得距离方面,墨西哥最接近澳大利亚。然而,在余弦距离方面,哥伦比亚最接近澳大利亚。
|
1 2 |
... df_distance.sort_values(by="cos").head() |
|
1 2 3 4 5 6 |
euclid cos 澳大利亚 0.000000e+00 -2.220446e-16 哥伦比亚 8.981118e+11 1.720644e-03 古巴 1.126039e+12 2.483993e-03 意大利 1.088369e+12 2.677707e-03 阿根廷 7.572323e+11 2.930187e-03 |
为了理解为什么两种距离会产生不同的结果,我们可以观察这三个国家的指标如何相互比较。
|
1 2 |
... print(df_nonagg[df_nonagg.country.isin(["Mexico", "Colombia", "Australia"])]) |
|
1 2 3 4 |
国家 年份 NE.EXP.GNFS.CD NE.IMP.GNFS.CD NV.AGR.TOTL.CD NY.GDP.MKTP.CD NE.RSB.GNFS.CD 59 澳大利亚 2010 2.270501e+11 2.388514e+11 2.518718e+10 1.146138e+12 -1.180129e+10 91 哥伦比亚 2010 4.682683e+10 5.136288e+10 1.812470e+10 2.865631e+11 -4.536047e+09 176 墨西哥 2010 3.141423e+11 3.285812e+11 3.405226e+10 1.057801e+12 -1.443887e+10 |
从这张表中可以看出,澳大利亚和墨西哥的指标在数量级上非常接近。但是,如果比较同一国家内各项指标的比例,哥伦比亚与澳大利亚的匹配程度更高。实际上,从余弦公式可以看出:
$$
\cos \theta = \frac{a\cdot b} {\lVert a\rVert_2\lVert b\rVert_2} = \frac{a}{\lVert a\rVert_2} \cdot \frac{b} {\lVert b\rVert_2}
$$
这意味着两个向量之间的夹角的余弦是在它们被归一化为长度为 1 之后,对应向量的点积。因此,余弦距离实际上是在计算距离之前对数据应用了一个标量。
总而言之,以下是完整代码。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
from pandas_datareader import wb import numpy as np import pandas as pd pd.options.display.width = 0 # 从世界银行下载数据 names = [ "NE.EXP.GNFS.CD", # 出口商品和服务(当前美元) "NE.IMP.GNFS.CD", # 进口商品和服务(当前美元) "NV.AGR.TOTL.CD", # 农业、林业和渔业增加值(当前美元) "NY.GDP.MKTP.CD", # GDP(当前美元) "NE.RSB.GNFS.CD", # 商品和服务对外收支差额(当前美元) ] df = wb.download(country="all", indicator=names, start=2010, end=2010).reset_index() # 我们移除汇总数据,只保留没有缺失数据的国家 countries = wb.get_countries() non_aggregates = countries[countries["region"] != "Aggregates"].name df_nonagg = df[df["country"].isin(non_aggregates)].dropna() # 提取每个国家的向量 vectors = {} for rowid, row in df_nonagg.iterrows(): vectors[row["country"]] = row[names].values # 计算欧几里得距离和余弦距离 euclid = {} cosine = {} target = "Australia" for country in vectors: vecA = vectors[target] vecB = vectors[country] dist = np.linalg.norm(vecA - vecB) cos = (vecA @ vecB) / (np.linalg.norm(vecA) * np.linalg.norm(vecB)) euclid[country] = dist # 欧几里得距离 cosine[country] = 1-cos # 余弦距离 # 打印结果 df_distance = pd.DataFrame({"euclid": euclid, "cos": cosine}) print("欧几里得距离最近:") print(df_distance.sort_values(by="euclid").head()) print() print("余弦距离最近:") print(df_distance.sort_values(by="cos").head()) # 打印详细指标 print() print("详细指标:") print(df_nonagg[df_nonagg.country.isin(["Mexico", "Colombia", "Australia"])]) |
向量空间模型和余弦距离的常见用法
向量空间模型在信息检索系统中很常见。我们可以将文档(例如,一段话、一篇长文、一本书,甚至一个句子)表示为向量。这个向量可以很简单,例如计算文档中包含的单词数(即词袋模型),也可以是复杂的嵌入向量(例如 Doc2Vec)。然后,通过根据余弦距离对所有文档进行排序来回答查找最相关文档的查询。应该使用余弦距离,因为我们不想偏好较长或较短的文档,而是关注其内容。因此,我们利用其自带的归一化来考虑文档与查询的相关性,而不是查询中的词在文档中出现的次数。
如果我们考虑文档中的每个单词作为一个特征并计算余弦距离,这就是“硬”距离,因为我们不关心含义相似的单词(例如,“document”和“passage”含义相似,但“distance”不相似)。嵌入向量(如 word2vec)可以让我们考虑本体。在考虑了单词含义的情况下计算余弦距离是“**软余弦距离**”。像 gensim 这样的库提供了做到这一点的方法。
余弦距离和向量空间模型的另一个用例是计算机视觉。想象一下识别手势的任务,我们可以将手的某些部分(例如,五根手指)作为关键点。然后,将这些关键点的 (x,y) 坐标表示为向量,我们可以将其与现有数据库进行比较,看看哪个余弦距离最接近,从而确定它是什么手势。我们需要余弦距离,因为每个人的手大小都不同。我们不希望这影响我们对手势的判断。
正如您可能想象的那样,还有更多可以使用此技术的例子。
延伸阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
软件
文章
总结
在本教程中,您了解了用于测量向量相似性的向量空间模型。
具体来说,你学到了:
- 如何构建向量空间模型
- 如何在向量空间模型中计算余弦相似度以及由此产生的余弦距离
- 如何解释余弦距离与其他距离度量(如欧几里得距离)之间的差异
- 向量空间模型有哪些用途






 From Scratch With Python")
谢谢,非常清晰的介绍和很好的例子。
你好,Jason!
我对命名法有些疑问……如果我们使用 ML 学习向量,它就被称为向量嵌入,否则(使用更传统的方法,更广泛的向量化),我们就不认为它们是嵌入了吗?
谢谢你,
Imola
你好 Imola……术语可能会令人困惑!以下资源可能对您有帮助。
https://www.analyticsvidhya.com/blog/2021/06/part-5-step-by-step-guide-to-master-nlp-text-vectorization-approaches/
谢谢!我觉得这个很有趣!
你好 Mani……不客气!感谢您的反馈!