
LangChain 构建本地 RAG 应用实用指南
作者 | Ideogram 提供图片
检索增强生成 (RAG) 包含一类系统,它们通过整合来自文档库的检索知识来扩展传统的语言模型(无论大小),从而在用户查询时生成更真实、更相关的响应。
在此背景下,LangChain 作为一个简化 RAG 应用开发的框架而备受关注,它提供了用于将 LLM 与外部数据源集成、管理检索管道以及以稳健且可扩展的方式处理不同复杂度的工作流的编排工具。
本文提供了一个关于使用 LangChain 构建非常简单的本地 RAG 应用的实用分步指南,并在每个步骤中定义了所需的关键组件。为了引导您完成这个过程,我们将使用 Python。本文旨在作为补充 RAG 基础知识的入门实践资源,这些基础知识已在理解 RAG 系列中涵盖。如果您是 RAG 新手并正在寻找一个温和的理论背景,我们建议您先阅读这个文章系列!
分步实践指南
让我们动手实操,通过编码学习如何使用 Langchain 构建我们的第一个本地 RAG 系统。作为参考,下图摘自理解 RAG 第二部分,展示了一个基本 RAG 系统的简化版本及其核心组件,我们将自己构建这些组件。
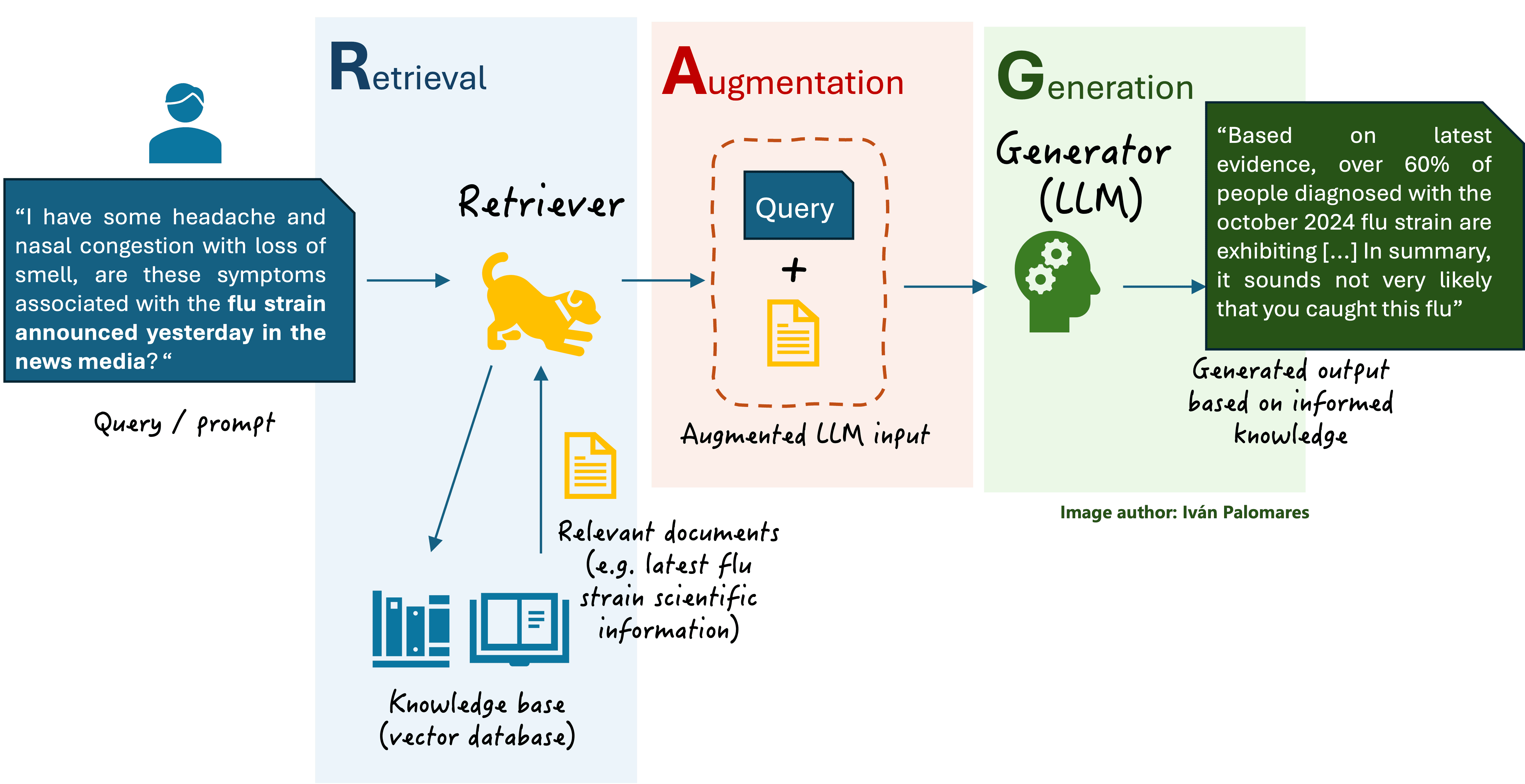
基本 RAG 方案
首先,我们安装必要的库和框架。最新版本的 LangChain 可能需要 **langchain-community**,因此我们也一并安装。FAISS 是一个用于在向量数据库中进行高效相似性搜索的框架。为了加载和使用现有的 LLM,我们将借助 Hugging Face 的 **transformers** 和 **sentence-transformers** 库,后者提供针对句子级别文本嵌入优化的预训练模型。您是否需要后者,取决于您将使用的具体 Hugging Face 模型。
首先,我们将安装上述库。
|
1 |
pip install langchain langchain_community faiss-cpu sentence-transformers transformers |
接下来,我们添加必要的导入以开始编码。
|
1 2 3 4 5 6 |
from langchain.llms import HuggingFacePipeline from langchain.chains import RetrievalQA from langchain.chains.question_answering import load_qa_chain from langchain.prompts import PromptTemplate from transformers import pipeline from langchain_community.vectorstores import FAISS |
我们需要的第一项是**知识库**,它被实现为一个**向量数据库**。它存储将由 RAG 系统用于上下文检索的文本文档,信息通常被编码为向量嵌入。我们将使用一个包含九篇短文本的集合,这些文本描述了东亚和东南亚的几个目的地。该数据集可以通过此链接以压缩的 .zip 文件形式提供。下面的代码将下载数据集,解压缩并提取文本文件。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import os import urllib.request import zipfile zip_url = "https://github.com/gakudo-ai/open-datasets/raw/refs/heads/main/asia_documents.zip" zip_path = "asia_documents.zip" extract_folder = "asia_txt_files" print("Downloading zip file...") urllib.request.urlretrieve(zip_url, zip_path) print("Download complete!") print("Extracting files...") os.makedirs(extract_folder, exist_ok=True) with zipfile.ZipFile(zip_path, "r") as zip_ref: zip_ref.extractall(extract_folder) print(f"Files extracted to: {extract_folder}") print("Extracted files:") print(os.listdir(extract_folder)) |
现在我们有了一个“原始”的文本文件知识库,我们需要将整个数据分割成块,并将它们转换成**向量嵌入**。
在 RAG 系统中,**分块**很重要,因为 LLM 有令牌限制,而高效检索相关信息需要将文档分割成易于管理的片段,同时保持上下文的完整性,这对于 LLM 之后生成适当的响应至关重要。
关于将文档转换为适合我们 RAG 应用的向量数据库的块,FAISS 将负责高效地存储和索引向量嵌入,从而实现准确高效的基于相似性的搜索。as_retriever() 方法有助于与 LangChain 的检索方法集成,以便可以动态地检索相关的文档块,从而优化 LLM 的响应。请注意,为了创建嵌入,我们使用的是一个为此任务训练的 Hugging Face 模型,具体是 `all-MiniLM-L6-v2`。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import os from langchain_community.document_loaders import TextLoader from langchain.text_splitter import CharacterTextSplitter from langchain_community.embeddings import HuggingFaceEmbeddings folder_path = "asia_txt_files" documents = [] for filename in os.listdir(folder_path): if filename.endswith(".txt"): file_path = os.path.join(folder_path, filename) loader = TextLoader(file_path) documents.extend(loader.load()) text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=100) docs = text_splitter.split_documents(documents) embedding_model = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2") vectorstore = FAISS.from_documents(docs, embedding_model) retriever = vectorstore.as_retriever() |
在上一段代码的结尾,我们刚刚初始化了我们一个关键的 RAG 组件:检索器。为了使其完全正常运行,当然,我们需要开始将 RAG 的其余部分粘合在一起。
下面,我们充分发挥 LangChain 的编排能力。下面的代码首先定义了一个使用 Hugging Face 的 Transformers 库和 GPT-2 模型进行文本生成的 LLM 管道。
`device=0` 参数确保模型在 GPU(如果可用)上运行,从而显著提高推理速度。如果您在笔记本电脑上运行此代码,我们建议保持原样。`max_new_tokens` 参数对于控制生成响应的长度很重要,它可以防止输出过长或被截断,同时保持连贯性。稍后可以尝试更改其值,看看它如何影响生成输出的质量。
|
1 2 3 4 5 6 7 |
from langchain.chains import LLMChain from langchain.prompts import PromptTemplate from langchain.chains import RetrievalQA from transformers import pipeline llm_pipeline = pipeline("text-generation", model="gpt2", device=0, max_new_tokens=200) llm = HuggingFacePipeline(pipeline=llm_pipeline) |
接下来的内容会更加令人兴奋。接下来,我们定义一个**提示模板**,即一个结构化且格式化的提示,它动态地包含检索到的上下文,确保模型生成基于相关知识的响应。此步骤与前面讨论的 RAG 架构中的**增强**块一致。
然后,我们定义一个**LLMChain**,这是一个关键的 LangChain 组件,它协调 LLM 和将包含增强输入并确保结构化查询-响应流的提示模板之间的交互。
最后但同样重要的是,我们使用 `RetrievalQA` 类初始化一个**问答 (QA)** 对象。在 LangChain 中,在创建链后指定目标语言任务的类型是定义适合该特定任务(例如,问答)的应用程序的关键。上述类将检索器与 LLM Chain 联系起来。现在,我们已经将所有 RAG 构建块都整合在一起了!
|
1 2 3 4 5 6 7 8 9 10 11 12 |
prompt_template = "Answer the following question based on the provided context: {context}\n\nQuestion: {query}\nAnswer:" prompt = PromptTemplate(input_variables=["query", "context"], template=prompt_template) llm_chain = LLMChain(llm=llm, prompt=prompt) retrieval_qa = RetrievalQA.from_chain_type( llm=llm, chain_type="stuff", retriever=retriever, verbose=True ) |
我们即将完成,准备尝试我们的 RAG 应用了。只剩一步,即定义一个支持函数,该函数将确保增强的上下文保持在 LLM 指定的令牌限制内,并在需要时截断输入。
|
1 2 3 4 5 |
def truncate_to_max_tokens(text, max_tokens=500): tokens = text.split() if len(tokens) > max_tokens: return " ".join(tokens[:max_tokens]) return text |
是时候用一个关于亚洲美食的问题来尝试我们的 RAG 系统了。让我们看看它的表现(请注意,不要抱太高的期望,请记住我们使用的是较小的、可管理的预训练模型用于学习目的。不要期望有类似 ChatGPT 的输出质量!)。您可以稍后尝试通过替换下面注释行中的 1 来更改用于增强的 Top-K 检索文档数量,将其更改为 2 或更多。
|
1 2 3 4 5 6 7 8 |
query = "What are the best Asian cuisine dishes?" # 重要提示:默认只使用 Top-1 文档 retrieved_docs = retriever.get_relevant_documents(query)[:1] context = " ".join([doc.page_content for doc in retrieved_docs]) context = truncate_to_max_tokens(context, max_tokens=500) response = retrieval_qa.run(query) print("Answer:", response) |
这是一个示例响应
问题:最好的亚洲菜肴是什么?
有益的答案:许多人渴望喝“酸”(酸味食物)以获得良好效果。这包括许多受欢迎的亚洲菜肴,包括辣味米饭、斑豆、酱油等。许多亚洲食品公司一直使用甜味(酱油、酸奶油以及西瓜、卷心菜和姜的组合)作为主要成分,这导致许多人喜欢美味的传统中餐、日本料理和越南美食。
越南美食对想要了解这个国家并可能花时间学习或参加 A+ 或以上课程的越南学生和专业人士来说,通常更具吸引力。
日本料理喜忧参半。日本料理中最受欢迎的菜肴往往是炒饭(鼘雅)、炒蔬菜(鞊雅)和海藻(雅枊),但其他……
不算太差。一些文本部分可能存在信息混杂的情况,但总的来说,我们可以看到该系统如何利用我们原始文本文件数据集中的检索信息,以及 GPT-2 的温和、有限的能力,这些能力很大程度上受到其训练所用的通用数据集的影响。
总结
我们对构建第一个本地 RAG 应用进行了温和的实践性入门介绍,依赖 LangChain 来协调其主要组件,主要是检索器和语言模型。利用这些步骤和技术来构建您自己符合规范的本地 RAG 应用,可能性是无限的。






暂无评论。