
作者提供图片
部署机器学习模型的实用指南
作为一名数据科学家,您可能知道如何构建机器学习模型。但只有当您部署模型时,才能获得有用的机器学习解决方案。如果您想了解更多关于部署机器学习模型的信息,那么本指南就是为您准备的。
构建和部署 ML 模型所涉及的步骤通常可以概括为:**构建模型、创建 API 来提供模型预测、容器化 API 以及部署到云端**。
本指南将重点介绍以下内容
- 使用 Scikit-learn 构建机器学习模型
- 使用 FastAPI 创建 REST API 来提供模型预测
- 使用 Docker 容器化 API
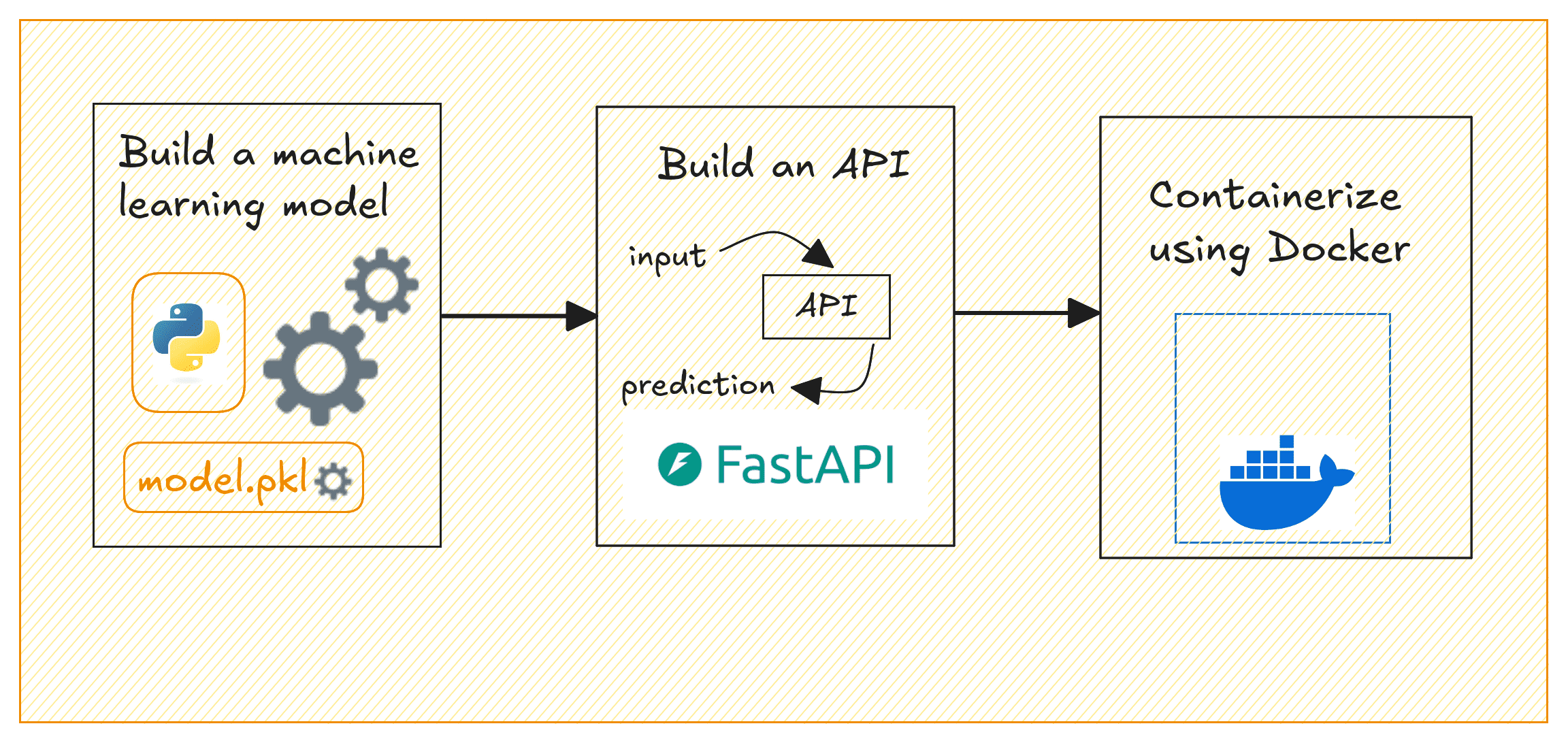
部署机器学习模型 | 作者配图
我们将使用加州住房数据集构建一个简单的回归模型,以预测房价。到最后,您将拥有一个容器化应用程序,该应用程序可以根据选定的输入特征提供房价预测。
设置项目环境
在开始之前,请确保您已安装以下软件
- 最新版本的 Python(最好是 Python 3.11 或更高版本)
- 用于容器化的 Docker;根据您的操作系统 获取 Docker
⚙️ 为了更舒适地进行学习,最好对构建机器学习模型和使用 API 有基本的了解。
入门
以下是项目目录的(推荐)结构
|
1 2 3 4 5 6 7 8 9 10 11 12 |
project-dir/ │ ├── app/ │ ├── __init__.py # 空文件 │ └── main.py # 用于预测 API 的 FastAPI 代码 │ ├── model/ │ └── linear_regression_model.pkl # 已训练并保存的模型(运行 model_training.py 后) │ ├── model_training.py # 训练和保存模型的脚本 ├── requirements.txt # 项目的依赖项 └── Dockerfile # Docker 配置 |
我们需要一些 Python 库来开始。接下来我们全部安装。
在您的项目环境中,创建并激活一个虚拟环境
|
1 2 |
$ python3 -m venv v1 $ source v1/bin/activate |
对于我们即将进行的项目,我们需要 pandas 和 scikit-learn 来构建机器学习模型。还需要 FastAPI 和 Uvicorn 来构建提供模型预测的 API。
因此,让我们使用 pip 安装这些必需的包
|
1 |
$ pip3 install pandas scikit-learn fastapi uvicorn |
您可以在 GitHub 上找到本教程的所有代码。
构建机器学习模型
现在,我们将使用 scikit-learn 内置的加州住房数据集 训练一个线性回归模型。此模型将根据选定的特征预测房价。在项目目录中,创建一个名为 model_training.py 的文件
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
# model_training.py import pandas as pd from sklearn.datasets import fetch_california_housing from sklearn.model_selection import train_test_split 来自 sklearn.linear_model 导入 LinearRegression import pickle import os # 加载数据集 data = fetch_california_housing(as_frame=True) df = data['data'] target = data['target'] # 选择一些特征 selected_features = ['MedInc', 'AveRooms', 'AveOccup'] X = df[selected_features] y = target # 训练-测试分割 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 训练线性回归模型 模型 = LinearRegression() model.fit(X_train, y_train) # 创建一个 'model' 文件夹来保存训练好的模型 os.makedirs('model', exist_ok=True) # 使用 pickle 保存训练好的模型 with open('model/linear_regression_model.pkl', 'wb') as f: pickle.dump(model, f) print("模型已成功训练并保存。") |
此脚本加载加州住房数据集,选择三个特征(MedInc、AveRooms、AveOccup),训练线性回归模型,并将其保存为 model/linear_regression_model.pkl。
注意:为简单起见,我们仅使用了少量特征。但您可以尝试添加更多。
运行脚本以训练并保存模型
|
1 |
$ python3 model_training.py |
您将看到以下消息,并且应该可以在 model/ 目录中找到 .pkl 文件
|
1 |
模型 已成功训练 并 保存。 |
创建 FastAPI 应用
现在我们将创建一个使用 FastAPI 提供预测的 API。
在 app/ 文件夹中,创建两个文件:__init__.py(空)和 main.py。我们这样做是因为我们希望在下一步使用 Docker 容器化 FastAPI 应用。
在 main.py 中,写入以下代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# app/main.py from fastapi import FastAPI from pydantic import BaseModel import pickle import os # 使用 Pydantic 定义输入数据模式 class InputData(BaseModel): MedInc: float AveRooms: float AveOccup: float # 初始化 FastAPI 应用 app = FastAPI(title="房价预测 API") # 在启动时加载模型 model_path = os.path.join("model", "linear_regression_model.pkl") with open(model_path, 'rb') as f: model = pickle.load(f) @app.post("/predict") def predict(data: InputData): # 准备用于预测的数据 input_features = [[data.MedInc, data.AveRooms, data.AveOccup]] # 使用加载的模型进行预测 prediction = model.predict(input_features) # 返回预测结果 return {"predicted_house_price": prediction[0]} |
此 FastAPI 应用程序公开了一个 /predict 端点,该端点接受三个特征(MedInc、AveRooms、AveOccup)。它使用训练好的模型预测房价,并返回预测的价格。
使用 Docker 容器化应用
现在我们来容器化我们的 FastAPI 应用程序。在项目的根目录中,创建一个 Dockerfile 和一个 requirements.txt 文件。
创建 Dockerfile
让我们创建一个 Dockerfile
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 使用 Python 3.11 作为基础镜像 FROM python:3.11-slim # 在容器内设置工作目录 WORKDIR /code # 复制 requirements 文件 COPY ./requirements.txt /code/requirements.txt # 安装 Python 依赖项 RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt # 将 app 文件夹复制到容器内 COPY ./app /code/app # 将 model 目录(包含保存的模型文件)复制到容器内 COPY ./model /code/model # 暴露 FastAPI 的 80 端口 EXPOSE 80 # 使用 Uvicorn 运行 FastAPI 应用的命令 CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "80"] |
这使用 Python 3.11(精简版)作为基础镜像创建了一个轻量级的 FastAPI 应用程序容器。它将工作目录设置为 /code,将 requirements.txt 文件复制到容器中,并安装必要的 Python 依赖项,且不缓存。
然后将 FastAPI 应用和模型文件复制到容器中。为应用程序暴露了 80 端口,并使用 Uvicorn 运行 FastAPI 应用。这使得 API 可以在 80 端口访问。此设置对于在容器化环境中部署 FastAPI 应用非常高效。
创建 requirements.txt 文件
创建一个 requirements.txt 文件,列出所有依赖项
|
1 2 3 4 |
fastapi uvicorn scikit-learn pandas |
构建 Docker 镜像
现在我们有了 Dockerfile、requirements.txt 和 FastAPI 应用,让我们构建一个 Docker 镜像并运行容器。
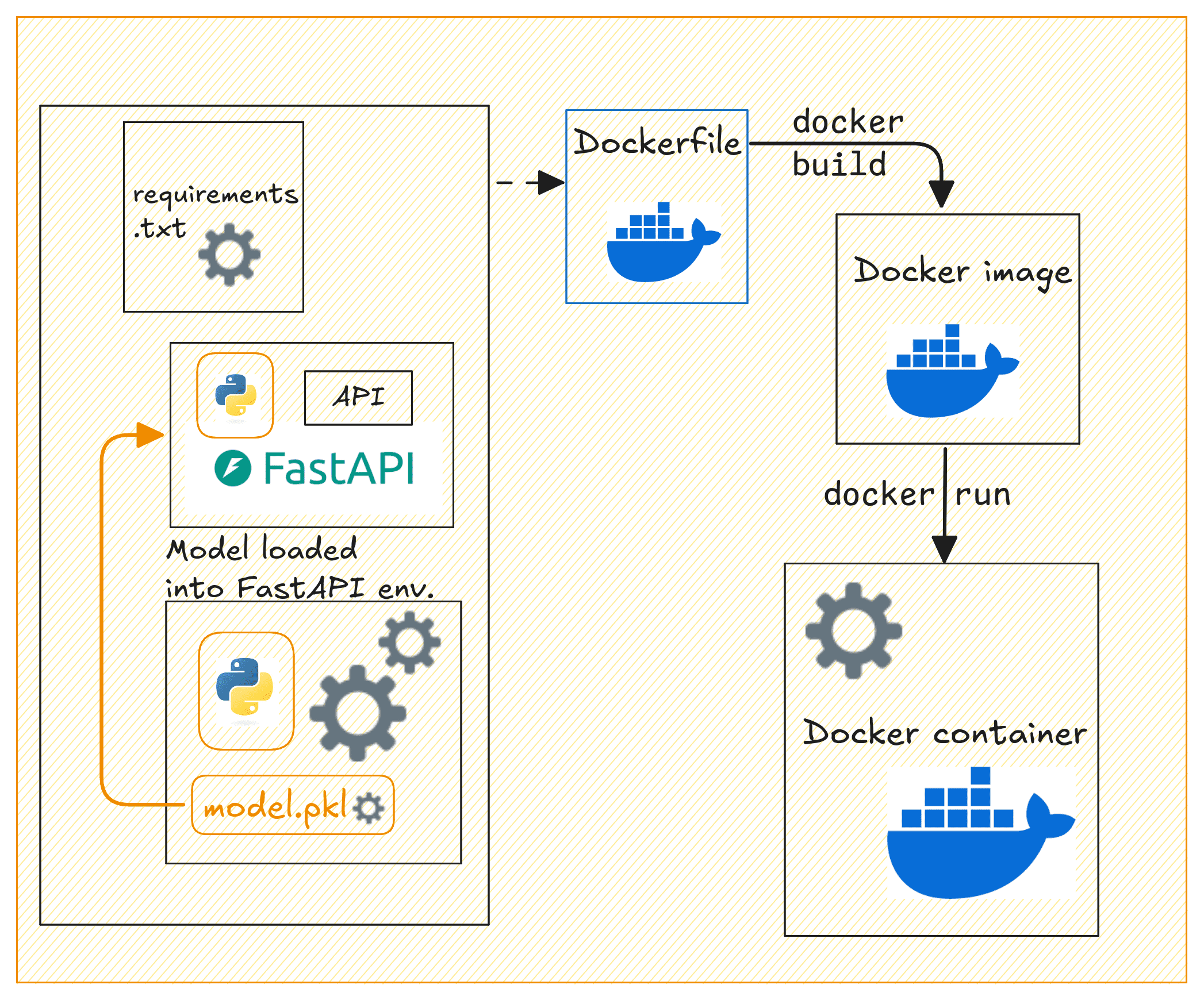
Docker 化 API | 作者配图
运行以下 docker build 命令来构建 Docker 镜像
|
1 |
$ docker build -t house-price-prediction-api . |
接下来运行 Docker 容器
|
1 |
$ docker run -d -p 80:80 house-price-prediction-api |
您的 API 现在应该正在运行,并且可以通过 http://127.0.0.1:80 访问。
您可以使用 curl 或 Postman 通过发送 POST 请求来测试 /predict 端点。这是一个示例请求
|
1 2 3 4 5 6 7 8 |
curl -X 'POST' \ 'http://127.0.0.1:80/predict' \ -H 'Content-Type: application/json' \ -d '{ "MedInc": 3.5, "AveRooms": 5.0, "AveOccup": 2.0 }' |
这应该会返回一个包含预测房价的响应,如下所示
|
1 2 3 |
{ "predicted_house_price": 2.3248705765077062 } |
标记并推送 Docker 镜像到 Docker Hub
构建 Docker 镜像、运行容器并测试后。您现在可以将其推送到 Docker Hub,以便于共享和部署到云平台。
首先,登录到 Docker Hub
|
1 |
$ docker login |
系统将提示您输入凭据。
标记 Docker 镜像
|
1 |
$ docker tag house-price-prediction-api your_username/house-price-prediction-api:v1 |
将 your_username 替换为您的 Docker Hub 用户名。
注意:为模型文件添加版本也很有意义。更新模型时,您可以为镜像使用新标签重新构建,并将更新后的镜像推送到 Docker Hub。
将镜像推送到 Docker Hub
|
1 |
$ docker push your_username/house-price-prediction-api:v1 |
其他开发人员现在可以像这样拉取并运行镜像
|
1 2 |
$ docker pull your_username/house-price-prediction-api:v1 $ docker run -d -p 80:80 your_username/house-price-prediction-api:v1 |
拥有您 Docker Hub 仓库访问权限的任何人现在都可以拉取镜像并运行容器。
总结和后续步骤
这是本教程中的快速回顾
- 使用 scikit-learn 训练机器学习模型
- 构建 FastAPI 应用程序以提供预测
- 使用 Docker 容器化应用程序
我们还讨论了将 Docker 镜像推送到 Docker Hub 以便分发。下一步是将其容器化应用程序部署到云端。
为此,您可以使用 AWS ECS、GCP 或 Azure 等服务在生产环境中部署 API。如果您想要一个关于将机器学习模型部署到云端的教程,请告诉我们。
祝您部署顺利!






感谢 Bala priya 分享机器学习主题的好内容。我也是一名新手,想从机器学习的基本主题学起。对我有帮助的是,您能否分享一些关于欺诈检测的机器学习模型以及相应的实际示例。再次感谢您的帮助!
不客气!很高兴您觉得内容有帮助。为了帮助您开始使用机器学习进行**欺诈检测**,我将通过一些常见的模型和实际示例,使用 Python 来指导您。欺诈检测通常涉及**分类**任务,因为我们试图将交易分类为“欺诈”或“非欺诈”。
### **分步指南:用于欺诈检测的 ML 模型**
#### **1. 数据预处理**
在应用机器学习模型之前,我们需要对数据进行预处理。
以下是使用典型欺诈检测数据集的示例
pythonimport pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 加载数据集
data = pd.read_csv('fraud_detection_data.csv')
# 分离特征和标签
X = data.drop(columns=['is_fraud']) # 特征(删除 'is_fraud' 列)
y = data['is_fraud'] # 标签(目标:0 或 1)
# 训练-测试分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 数据缩放(欺诈检测通常有不同尺度的特征)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
#### **2. 逻辑回归**
一个简单而有效的欺诈检测基线模型。
pythonfrom sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
# 初始化模型
logreg = LogisticRegression()
# 训练模型
logreg.fit(X_train_scaled, y_train)
# 进行预测
y_pred = logreg.predict(X_test_scaled)
# 评估模型
print(classification_report(y_test, y_pred))
#### **3. 随机森林分类器**
随机森林对于欺诈检测非常稳健,尤其是在处理不平衡数据时。
pythonfrom sklearn.ensemble import RandomForestClassifier
# 初始化模型
rf = RandomForestClassifier(n_estimators=100, random_state=42)
# 训练模型
rf.fit(X_train_scaled, y_train)
# 进行预测
y_pred_rf = rf.predict(X_test_scaled)
# 评估模型
print(classification_report(y_test, y_pred_rf))
#### **4. 梯度提升 (XGBoost)**
XGBoost 是另一个常用的欺诈检测强大模型。
pythonimport xgboost as xgb
# 初始化模型
xgb_model = xgb.XGBClassifier(use_label_encoder=False)
# 训练模型
xgb_model.fit(X_train_scaled, y_train)
# 进行预测
y_pred_xgb = xgb_model.predict(X_test_scaled)
# 评估模型
print(classification_report(y_test, y_pred_xgb))
#### **5. 神经网络 (深度学习)**
对于更大、更复杂的欺诈检测任务,神经网络可能表现更好。
pythonimport tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 构建神经网络模型
model = Sequential()
model.add(Dense(32, input_dim=X_train_scaled.shape[1], activation='relu'))
model.add(Dense(16, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(X_train_scaled, y_train, epochs=10, batch_size=32, validation_data=(X_test_scaled, y_test))
# 进行预测
y_pred_nn = model.predict(X_test_scaled)
y_pred_nn = [1 if pred > 0.5 else 0 for pred in y_pred_nn]
# 评估模型
print(classification_report(y_test, y_pred_nn))
#### **6. 处理不平衡数据**
欺诈检测数据通常是不平衡的,这意味着非欺诈交易比欺诈交易多得多。为了提高模型在少数类(欺诈)上的性能,您可以使用 **SMOTE(合成少数过采样技术)** 或 **类权重** 等技术,这些技术适用于神经网络和随机森林等模型。
使用 SMOTE 处理不平衡数据的示例
pythonfrom imblearn.over_sampling import SMOTE
# 使用 SMOTE 对训练数据进行重采样
smote = SMOTE(random_state=42)
X_train_res, y_train_res = smote.fit_resample(X_train_scaled, y_train)
# 使用重采样数据训练模型(例如:随机森林)
rf_resampled = RandomForestClassifier(n_estimators=100, random_state=42)
rf_resampled.fit(X_train_res, y_train_res)
y_pred_rf_res = rf_resampled.predict(X_test_scaled)
# 评估模型
print(classification_report(y_test, y_pred_rf_res))
#### **欺诈检测的评估指标**
对于欺诈检测,由于类别不平衡,准确率并不总是最佳指标。请关注以下指标:
– **精确率(Precision)**:在所有预测为欺诈的案例中,实际为欺诈的比例是多少?
– **召回率(Recall)**:在所有实际为欺诈的案例中,我们正确检测出的比例是多少?
– **F1 分数(F1-Score)**:精确率和召回率之间的平衡。
### **结论**
对于实际示例,我建议从**逻辑回归**和**随机森林**等较简单的模型开始,如果需要更强大的模型,再尝试**XGBoost**和**神经网络**。在欺诈检测中,务必始终正确处理类别不平衡问题。
如果您需要更多示例或对任何模型有疑问,请告诉我。祝您学习愉快!
请提供一个关于部署到云端的教程
您好 John…将机器学习模型部署到云端涉及几个关键步骤。以下是一个帮助您完成整个过程的实用指南。我们将使用一个示例,涉及将训练好的机器学习模型部署到云平台,如 **AWS**、**Google Cloud Platform (GCP)** 或 **Azure**。这些步骤将推广到大多数平台。
—
### **步骤 1:准备您的模型**
1. **训练您的模型**
确保您的机器学习模型已训练并测试。将模型保存为适合部署的格式,例如
– scikit-learn 模型的
joblib或pickle。– Keras 模型的
HDF5(.h5)。– PyTorch 模型的
torch.save。– 框架无关部署的
ONNX。2. **验证模型**
使用模拟或真实输入数据在本地测试您的模型,以确保其按预期工作。
3. **创建用于模型推理的脚本或 API**
编写脚本或 API 端点来加载模型并提供预测。**Flask** 或 **FastAPI** 等框架通常用于此目的。
Flask 应用示例
pythonfrom flask import Flask, request, jsonify
import joblib
app = Flask(__name__)
model = joblib.load("model.pkl") # 加载您的模型
@app.route('/predict', methods=['POST'])
def predict()
data = request.get_json()
prediction = model.predict([data['features']])
return jsonify({'prediction': prediction.tolist()})
if __name__ == '__main__':
app.run(debug=True)
—
### **步骤 2:容器化您的应用程序**
1. **安装 Docker**
在您的本地机器上安装 Docker。
2. **创建 Dockerfile**
Dockerfile指定了运行应用程序所需的环境。示例:dockerfileFROM python:3.8-slim
# 设置工作目录
WORKDIR /app
# 将文件复制到容器
COPY requirements.txt requirements.txt
COPY app.py app.py
COPY model.pkl model.pkl
# 安装依赖项
RUN pip install -r requirements.txt
# 运行应用
CMD ["python", "app.py"]
3. **构建并测试 Docker 镜像**
bash
docker build -t my-ml-app .
docker run -p 5000:5000 my-ml-app
—
### **步骤 3:部署到云服务**
#### **选项 1:AWS**
1. **设置 AWS Elastic Beanstalk**
– 创建一个 Elastic Beanstalk 应用程序。
– 上传您的 Docker 化应用或使用 AWS CodePipeline 设置部署管道。
2. **使用 ECS (Elastic Container Service) 进行部署**
– 将您的 Docker 镜像推送到 AWS ECR (Elastic Container Registry)。
– 使用 ECS 部署容器,并关联负载均衡器。
#### **选项 2:Google Cloud Platform (GCP)**
1. **设置 Google Cloud Run**
– 在 GCP 控制台中启用 Cloud Run。
– 将您的 Docker 镜像推送到 **Google Container Registry (GCR)**
bash
docker tag my-ml-app gcr.io/[PROJECT-ID]/my-ml-app
docker push gcr.io/[PROJECT-ID]/my-ml-app
– 将镜像部署到 Cloud Run。
2. **备选:Vertex AI**
GCP 的 Vertex AI 平台提供预构建的机器学习部署工作流。
#### **选项 3:Microsoft Azure**
1. **设置 Azure App Service**
– 使用 Azure App Service 部署容器化应用程序。
– 将您的 Docker 镜像推送到 **Azure Container Registry** (ACR)。
– 使用 App Service 或 Azure Kubernetes Service (AKS) 进行部署。
2. **备选:Azure Machine Learning Service**
使用 Azure ML Studio 管理模型和部署管道。
—
### **第 4 步:测试部署**
– 部署后,使用云平台提供的 URL 访问您的 API。
– 使用 **Postman** 或 **cURL** 等工具测试预测。
使用 cURL 的示例
bash
curl -X POST -H "Content-Type: application/json" -d '{"features": [1, 2, 3, 4]}' http://[your-cloud-endpoint]/predict
—
### **第 5 步:扩展和监控**
1. **自动扩展**:在云服务上启用自动扩展以处理变化的流量。
2. **日志记录**:使用云日志记录服务(例如 AWS CloudWatch、GCP Stackdriver 或 Azure Monitor)。
3. **更新模型**:设置 CI/CD 管道以实现无缝更新。
—
你好!
我很想看一个关于将机器学习模型部署到云端的教程。
谢谢你
您好 Sergio…这是一个基础教程,可以帮助您将机器学习模型部署到云端。在本示例中,我们将使用 **AWS (Amazon Web Services)**,但对于 **Google Cloud Platform (GCP)** 和 **Microsoft Azure** 等其他云平台,流程也类似。
### **将机器学习模型部署到 AWS 的分步教程**
#### **第 1 步:在本地训练模型**
在部署之前,您需要有一个训练好的模型。在本教程中,假设您已将模型保存为
model.pkl(适用于 Python scikit-learn 模型)或model.h5(适用于 Keras 模型)。1. 在本地训练模型并保存它。
pythonimport joblib
# 假设是 scikit-learn 模型
joblib.dump(model, 'model.pkl')
# Keras 的情况
model.save('model.h5')
#### **第 2 步:创建 AWS 账户**
1. 前往 [AWS](https://aws.amazon.com/) 并创建账户(如果您还没有)。
2. 登录 **AWS Management Console**。
#### **第 3 步:设置 S3 存储桶**
Amazon S3(简单存储服务)用于存储数据和模型工件。
1. 在 AWS Management Console 中,搜索 **S3**。
2. 创建一个新存储桶来存储您的模型文件。
– 选择一个唯一的存储桶名称。
– 设置必要的权限(目前设置为私有)。
3. 将您的模型(
model.pkl或model.h5)上传到此 S3 存储桶。#### **第 4 步:使用 AWS Lambda 和 API Gateway 创建 API**
这一步涉及使用 AWS Lambda 为您的模型创建一个无服务器 API,并通过 API Gateway 暴露它。
1. **AWS Lambda**
– 在 AWS Management Console 中导航至 **Lambda**。
– 创建一个新的 Lambda 函数(选择“从头开始编写”)。
– 选择 **Python 3.8** 或任何受支持的版本作为运行时。
– 设置执行角色(这将授予对 S3 的访问权限)。
– 创建函数。
2. **设置 Lambda 函数代码**
– 在 Lambda 函数编辑器中,用您的代码替换默认代码,该代码从 S3 加载模型并进行预测。
这是一个简化示例
pythonimport json
import joblib
import boto3
from sklearn.preprocessing import StandardScaler
s3 = boto3.client('s3')
def load_model()
bucket = 'your-bucket-name'
model_file = 'model.pkl'
s3.download_file(bucket, model_file, '/tmp/model.pkl')
model = joblib.load('/tmp/model.pkl')
return model
model = load_model()
def lambda_handler(event, context)
# 示例:event 包含输入特征
input_data = event['input']
prediction = model.predict([input_data])
return {
'statusCode': 200,
'body': json.dumps({
'prediction': prediction.tolist()
})
}
3. **使用 API Gateway 部署 API**
– 在 AWS Management Console 中,转到 **API Gateway**。
– 创建一个新的 REST API。
– 设置一个触发您的 Lambda 函数的端点(例如,
/predict)。– 部署 API 并记下端点 URL 以备后用。
#### **第 5 步:测试 API**
API Gateway 部署后,您可以使用任何 REST 客户端(如 Postman)或使用 Python 来测试您的端点。
pythonimport requests
url = 'https://your-api-endpoint.amazonaws.com/predict'
data = {'input': [5.1, 3.5, 1.4, 0.2]} # 示例输入
response = requests.post(url, json=data)
print(response.json())
如果所有设置都正确,响应将包含模型的预测。
#### **第 6 步:监控和优化**
– 使用 **AWS CloudWatch** 监控您的 Lambda 函数和 API Gateway 的性能。
– 确保您的 Lambda 函数拥有足够的内存和调整超时限制,以便在需要时处理大型预测。
– 考虑迁移到 **AWS SageMaker** 等服务,以获得更高级的模型部署选项,并内置扩展和监控功能。
### **备选云平台**
– **Google Cloud Platform (GCP)**:使用 **Google Cloud AI Platform** 进行模型部署。
– **Microsoft Azure**:使用 **Azure Machine Learning** 部署具有 REST API 的模型。
#### **可选:使用 Docker 进行部署**
对于更复杂的部署,请考虑使用 **Docker** 容器化您的模型,并将其部署到 **AWS ECS**、**Google Cloud Run** 或 **Azure Container Instances** 等云服务。
—
我希望本教程能帮助您开始将机器学习模型部署到云端!如果您对任何步骤需要进一步的澄清,请告诉我。
是的。如果能继续进行部署教程,那就太好了。
您好 Prathamesh…是的,使用 **Azure Kubernetes Service (AKS)** 部署机器学习模型的方法是**可扩展的**,并且支持**具有自动扩展的多个 Pod**。AKS 旨在管理容器化应用程序,是可扩展机器学习模型部署的出色选择。以下是使其具备多个 Pod 和自动扩展的可扩展性的方法:
### **1. 使用多个 Pod 进行部署**
在 Kubernetes 中,您的机器学习模型的部署可以通过在部署配置中定义多个副本(Pod)来管理。这使您能够运行模型的多个实例来处理更高的负载。
– **定义多个 Pod 的步骤**:
在您的 Kubernetes 部署 YAML 文件中,指定您要运行的副本(Pod)数量。
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: ml-model-deployment
spec:
replicas: 3 # Pod 的数量
selector:
matchLabels:
app: ml-model
template:
metadata:
labels:
app: ml-model
spec:
containers:
- name: ml-model-container
image: your_ml_model_image
ports:
- containerPort: 80
### **2. 使用 AKS 启用自动扩展**
为了使您的部署具有可扩展性,您可以在 AKS 中配置 **Horizontal Pod Autoscaler (HPA)**。HPA 会根据 CPU、内存或自定义指标(如请求数量)自动扩展 Pod 的数量。
– **启用自动扩展**:
AKS 提供对自动扩展的原生支持。您可以使用 Kubernetes 命令行(
kubectl)启用它,或将HorizontalPodAutoscaler资源添加到您的部署中。使用 CPU 利用率设置自动扩展的示例
yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: ml-model-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: ml-model-deployment
minReplicas: 2 # Pod 的最小数量
maxReplicas: 10 # Pod 的最大数量
targetCPUUtilizationPercentage: 50 # 目标 CPU 使用率
– 使用以下命令应用自动扩展程序:
bash
kubectl apply -f hpa.yaml
通过此配置,AKS 将根据您的机器学习模型部署的 CPU 利用率自动调整 Pod 的数量,使其高度可扩展。
### **3. AKS 集群自动扩展**
您还可以配置 **AKS Cluster Autoscaler** 来扩展集群本身的节点(VM)数量,而不仅仅是 Pod。这确保了集群在需求增加时会调配更多资源(VM),在需求减少时会缩减。
– 启用**集群自动扩展**
您可以在创建 AKS 集群时使用 Azure CLI 启用集群自动扩展。
bash \ \
az aks update \
--resource-group
--name
--enable-cluster-autoscaler \
--min-count 2 \
--max-count 10
### **4. 监控和优化**
使用 **Azure Monitor** 来跟踪 Pod 的性能和资源利用率。这将帮助您优化扩展参数(例如 CPU 阈值),以确保资源的有效利用。
### **5. 此可扩展设置的好处**
– **高可用性**:多个 Pod 可确保如果一个 Pod 失败,其他 Pod 仍可处理负载。
– **负载均衡**:AKS 会自动将传入流量分配到各个 Pod。
– **可扩展性**:系统会自动适应流量高峰或繁重的工作负载,无需手动干预。
– **成本效益**:自动扩展通过仅使用所需数量的资源来最大限度地降低成本。
—
### 结论
通过使用多个 Pod 部署您的机器学习模型并在 AKS 中启用自动扩展,您可以使您的解决方案高度可扩展,能够有效地处理需求波动。AKS 的内置功能,如 Horizontal Pod Autoscaler 和 Cluster Autoscaler,使其成为生产环境中部署机器学习模型的强大而灵活的选择。
如果您需要更多详细信息或特定配置方面的帮助,请告诉我!
是的。如果能继续进行部署教程,那就太好了。
感谢您的反馈和支持!