GPT-3 的推出,特别是其聊天机器人形式 ChatGPT,已被证明是人工智能领域的一个里程碑,标志着生成式人工智能(GenAI)革命的开始。尽管图像生成领域之前已经存在模型,但正是 GenAI 的浪潮吸引了所有人的注意力。
Stable Diffusion 是用于图像生成的 GenAI 系列的一员。它以其定制的可能性、可在自己的硬件上免费运行以及持续改进而闻名。它并非唯一。例如,OpenAI 发布了 DALLE-3 作为其 ChatGPTPlus 订阅的一部分,用于允许图像生成。但 Stable Diffusion 在从文本生成图像以及从其他现有图像生成图像方面取得了显著成功。最近将视频生成功能集成到扩散模型中,为研究这项尖端技术提供了令人信服的理由。
在这篇文章中,您将了解 Stable Diffusion 的一些技术细节以及如何在自己的硬件上设置它。
通过我的书《掌握 Stable Diffusion 数字艺术》来启动您的项目。它提供了带有工作代码的自学教程。
让我们开始吧。

Stable Diffusion 技术入门
照片作者: Denis Oliveira。部分权利保留。
概述
本帖共分为四个部分:
- 扩散模型如何工作
- 扩散模型的数学原理
- 为什么 Stable Diffusion 如此特别?
- 如何安装 Stable Diffusion WebUI
扩散模型如何工作
为了理解扩散模型,让我们先回顾一下在 Stable Diffusion 或其同类产品出现之前,机器是如何进行图像生成的。一切都始于 GAN(生成对抗网络),其中两个神经网络进行竞争和合作的学习过程。
第一个是生成器网络,它生成难以与真实图像区分的合成数据,在此案例中是图像。它会产生随机噪声,并通过多个层逐步对其进行细化,以生成越来越逼真的图像。
第二个网络,即判别器网络,充当对手,仔细检查生成的图像,以区分真实和合成图像。其目标是准确地将图像分类为真实或虚假。
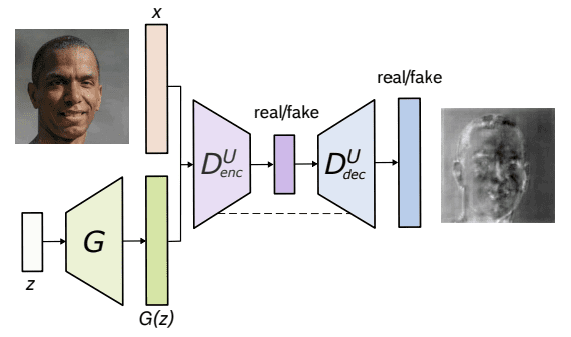
U-Net GAN 架构。来源:Schonfeld 等人(2020)
扩散模型假设有噪声的图像或纯噪声是原始图像上重复叠加噪声(或高斯噪声)的结果。这个噪声叠加过程称为前向扩散。现在,与此完全相反的是反向扩散,它涉及一次从有噪声的图像到噪声较少的图像。
下面是从右到左(即从清晰到有噪声的图像)的前向扩散过程的说明。

扩散过程。图片来源:Ho 等人(2020)
扩散模型的数学原理
前向扩散和反向扩散过程都遵循马尔可夫链,这意味着在任何时间步长 t,图像中的像素值或噪声仅取决于前一幅图像。
前向扩散
从数学上讲,前向扩散过程的每一步都可以用下面的方程表示
$$q(\mathbf{x}_t\mid \mathbf{x}_{t-1}) = \mathcal{N}(\mathbf{x}_t;\mu_t = \sqrt{1-\beta_t}\mathbf{x}_{t-1}, \Sigma_t = \beta_t \mathbb{I})$$
其中 $q(x_t\mid x_{t-1})$ 是均值为 $\mu_t = \sqrt{1-\beta_t}x_{t-1}$,方差为 $\Sigma_t = \beta_t \mathbb{I}$ 的正态分布,$\mathbf{I}$ 是单位矩阵,每个步骤中的图像(作为潜在变量)$\mathbf{x}_t$ 是一个向量,均值和方差由标量值 $\beta_t$ 参数化。
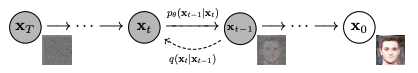
前向扩散 $q(\mathbf{x}_t\mid\mathbf{x}_{t-1})$ 和反向扩散 $p_\theta(\mathbf{x}_{t-1}\mid\mathbf{x}_t)$。图片来源:Ho 等人(2020)
因此,前向扩散过程所有步骤的后验概率定义如下
$$q(\mathbf{x}_{1:T}\mid \mathbf{x}_0) = \prod_{t=1}^T q(\mathbf{x}_t\mid\mathbf{x}_{t-1})$$
这里,我们从时间步长 1 应用到 $T$。
反向扩散
反向扩散,与前向扩散过程相反,工作方式类似。前向过程映射了给定先验概率的后验概率,而反向过程则相反,即映射了给定后验概率的先验概率。
$$p_\theta(\mathbf{x}_{t-1}\mid\mathbf{x}_t) = \mathcal{N}(\mathbf{x}_{t-1};\mu_\theta(\mathbf{x}_t,t),\Sigma_\theta(\mathbf{x}_t,t))$$
其中 $p_\theta$ 应用反向扩散,也称为轨迹。
当时间步长 $t$ 趋于无穷大时,潜在变量 $\mathbf{x}_T$ 趋于一个近似各向同性的高斯分布(即纯噪声,没有图像内容)。目标是学习 $q(\mathbf{x}_{t-1}\mid \mathbf{x}_t)$,该过程从从 $\mathcal{N}(0,\mathbf{I})$ 采样得到,称为 $\mathbf{x}_T$。我们一次一步运行完整的反向过程,以达到从 $q(\mathbf{x}_0)$ 采样,即从实际数据分布生成的样本。通俗地说,反向扩散是通过许多小步骤从随机噪声中创建图像。
为什么 Stable Diffusion 如此特别?
Stable Diffusion 没有直接将扩散过程应用于高维输入,而是使用编码器网络将输入投影到较低的潜在空间(扩散过程就发生在那里)。这种方法的理由是通过在较低维空间中处理输入来减少训练扩散模型所需的计算量。随后,使用常规的扩散模型(如 U-Net)生成新数据,然后使用解码器网络进行上采样。
如何安装 Stable Diffusion WebUI?
您可以按订阅服务使用 Stable Diffusion,也可以下载并在自己的计算机上运行。在计算机上使用它的两种主要方法是:WebUI 和 CompfyUI。这里将向您展示如何安装 WebUI。
注意: Stable Diffusion 对计算要求很高。您可能需要性能不错的硬件和支持的 GPU 才能以合理的性能运行。
用于 Python 编程语言的 Stable Diffusion WebUI 包可以从其 GitHub 页面免费下载和使用。以下是在 Apple Silicon 芯片上安装该库的步骤,其他平台的安装过程大致相同。
-
- 先决条件。该过程的先决条件之一是有一个运行 WebUI 的设置。它是一个基于 Python 的 Web 服务器,UI 使用 Gradio 构建。设置大部分是自动的,但您应确保某些基本组件可用,例如
git和wget。运行 WebUI 时,会创建一个 Python 虚拟环境。
在 macOS 上,您可能希望使用 Homebrew 安装 Python 系统,因为某些依赖项可能需要比 macOS 默认安装的更新版本的 Python。请参阅 Homebrew 的设置指南。然后您可以使用 Homebrew 安装 Python:
1brew install cmake protobuf rust python@3.10 git wget - 下载。 WebUI 是一个 GitHub 存储库。要将 WebUI 复制到您的计算机,您可以运行以下命令:
1git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
这将创建一个名为stable-diffusion-webui的文件夹,您应该在接下来的步骤中在此文件夹中进行操作。 - 检查点。 WebUI 用于运行流水线,但不包含 Stable Diffusion 模型。您需要下载模型(也称为检查点),并且有几个版本可供选择。这些通常可以从 HuggingFace 下载。下一节将更详细地介绍此步骤。所有 Stable Diffusion 模型/检查点都应放在
stable-diffusion-webui/models/Stable-diffusion目录中。 - 首次运行。 使用命令行导航到
stable-diffusion-webui目录并运行./webui.sh来启动 Web UI。此操作将创建并激活一个使用venv的 Python 虚拟环境,自动获取并安装任何剩余的必需依赖项。
WebUI 首次运行时安装的 Python 模块
- 后续运行。 要将来访问 Web UI,请在 WebUI 目录中重新运行
./webui.sh。请注意,WebUI 不会自动更新;要更新它,您必须在运行命令之前执行git pull以确保您使用的是最新版本。这个webui.sh脚本的作用是启动一个 Web 服务器,您可以通过浏览器访问 Stable Diffusion。所有交互都应通过浏览器进行,并且可以通过关闭运行webui.sh的终端中的 Web 服务器(例如,按 Control-C)来关闭 WebUI。
- 先决条件。该过程的先决条件之一是有一个运行 WebUI 的设置。它是一个基于 Python 的 Web 服务器,UI 使用 Gradio 构建。设置大部分是自动的,但您应确保某些基本组件可用,例如
对于其他操作系统,官方自述文件提供了最佳指南。
如何下载模型?
您可以通过 Hugging Face 下载 Stable Diffusion 模型,选择感兴趣的模型,然后转到“文件和版本”部分。查找标记为“.ckpt”或“.safetensors”扩展名的文件,然后单击文件大小旁边的向右箭头开始下载。SafeTensor 是 Python 的 pickle 序列化库的替代格式;WebUI 会自动处理它们的差异,因此您可以将它们视为等效的。
如果您按模型名称“stable-diffusion”搜索,Hugging Face 上有几个模型。
我们将在接下来的章节中使用的一些官方 Stable Diffusion 模型包括:
- Stable Diffusion 1.4 (
sd-v1-4.ckpt) - Stable Diffusion 1.5 (
v1-5-pruned-emaonly.ckpt) - Stable Diffusion 1.5 修复 (
sd-v1-5-inpainting.ckpt)
Stable Diffusion 2.0 和 2.1 需要模型和配置文件。此外,在生成图像时,请确保图像的宽度和高度设置为 768 或更高。
- Stable Diffusion 2.0 (
768-v-ema.ckpt) - Stable Diffusion 2.1 (
v2-1_768-ema-pruned.ckpt)
配置文件可以在 GitHub 上的以下位置找到:
下载上面的 v2-inference-v.yaml 后,应将其放置在与模型文件名匹配的模型同一文件夹中(例如,如果您下载了 768-v-ema.ckpt 模型,则应将此配置文件重命名为 768-v-ema.yaml,并将其与模型一起存储在 stable-diffusion-webui/models/Stable-diffusion 中)。
还有一个 Stable Diffusion 2.0 深度模型(512-depth-ema.ckpt)。在这种情况下,您应该从以下位置下载 v2-midas-inference.yaml 配置文件:
并将其另存为 stable-diffusion-webui/models/Stable-diffusion/512-depth-ema.yaml。此模型在 512 宽度/高度或更高的图像尺寸下效果最佳。
您可以在 https://civitai.com/ 找到 Stable Diffusion 模型检查点的另一个位置,您也可以在那里查看示例。
进一步阅读
以下是上面引用的一些论文:
- Schonfeld、Schiele 和 Khoreva 的《基于 U-Net 的生成对抗网络判别器》。收录于 CVPR 2020 会议论文集,第 8207-8216 页。
- Ho、Jain 和 Abbeel(2020)的《去噪扩散概率模型》。arXiv 2006.11239
总结
在这篇文章中,我们了解了扩散模型的基础知识及其在各个领域的广泛应用。除了扩展其在图像和视频生成方面的最新成功之外,我们还讨论了前向和反向扩散过程以及后验概率建模。
Stable Diffusion 的独特方法包括将高维输入投影到较低的潜在空间,通过编码器和解码器网络降低计算需求。
接下来,我们将学习使用 Stable Diffusion WebUI 生成图像的实际方面。我们的探索将涵盖模型下载和利用 Web 界面进行图像生成。
立即开始用 Stable Diffusion 精通数字艺术!

学习如何让 Stable Diffusion 为您服务
……通过学习图像生成过程中的一些关键要素
在我的新电子书中探索如何实现
使用 Stable Diffusion 精通数字艺术
本书提供了自学教程,其中包含 Python 中的所有工作代码,引导您从新手成长为图像生成专家。它教您如何设置 Stable Diffusion、微调模型、自动化工作流程、调整关键参数等等……所有这些都是为了帮助您创作出令人惊叹的数字艺术。






暂无评论。