随着注意力机制在机器学习中日益普及,融合了注意力机制的神经网络架构也越来越多。
在本教程中,您将了解与注意力机制结合使用的主要神经网络架构。
完成本教程后,您将更好地理解注意力机制是如何融入不同的神经网络架构以及其目的。
使用我的书籍《构建基于注意力的Transformer模型》启动您的项目。它提供了带有工作代码的自学教程,指导您构建一个可以运行的完整Transformer模型。
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...
让我们开始吧。

基于注意力机制的架构之旅
图片来源:Lucas Clara,保留部分权利。
教程概述
本教程分为四个部分;它们是
- 编码器-解码器架构
- Transformer
- 图神经网络
- 记忆增强神经网络
编码器-解码器架构
编码器-解码器架构已广泛应用于语言处理的序列到序列 (seq2seq) 任务。语言处理领域中此类任务的示例包括机器翻译和图像字幕生成。
注意力机制最早被用作基于 RNN 的编码器-解码器框架的一部分,以编码长输入句子 [Bahdanau et al. 2015]。因此,注意力机制最广泛地与该架构结合使用。
—— 注意力模型的一项综合调查,2021年。
在机器翻译的背景下,这种 seq2seq 任务将涉及将输入序列,$I = \{ A, B, C, <EOS> \}$,翻译成不同长度的输出序列,$O = \{ W, X, Y, Z, <EOS> \}$。
对于不带注意力机制的基于 RNN 的编码器-解码器架构,展开每个 RNN 将生成以下图表:
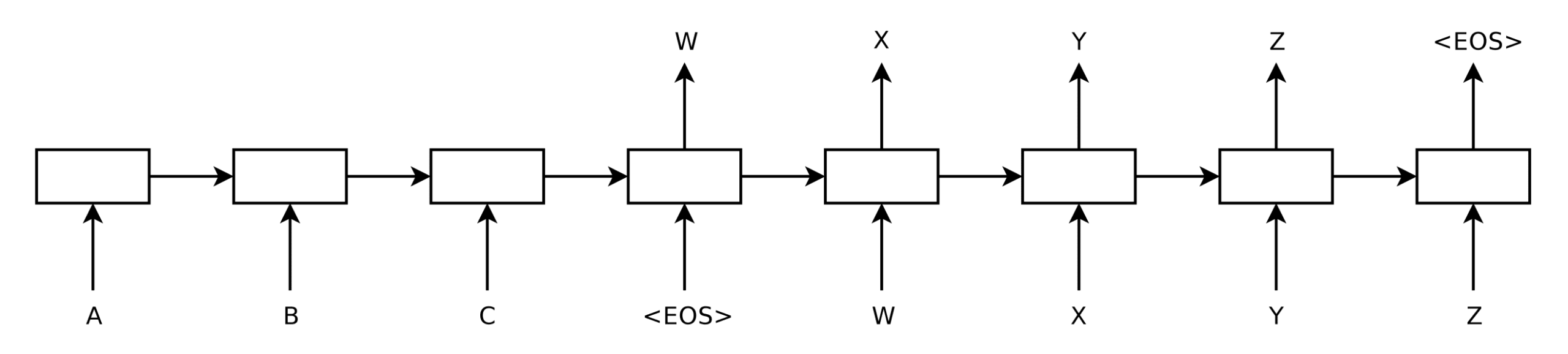
展开的基于 RNN 的编码器和解码器
摘自“使用神经网络进行序列到序列学习”
在这里,编码器一次读取输入序列中的一个词,每次更新其内部状态。当遇到 <EOS> 符号时停止,该符号表示已到达序列末尾。编码器生成的隐藏状态本质上包含输入序列的向量表示,解码器将对其进行处理。
解码器一次生成一个输出序列中的词,将前一时间步(t – 1)的词作为输入,以生成输出序列中的下一个词。解码侧的 <EOS> 符号表示解码过程已结束。
正如我们之前提到的,不带注意力机制的编码器-解码器架构的问题在于,当不同长度和复杂性的序列由固定长度的向量表示时,可能导致解码器丢失重要信息。
为了规避这个问题,基于注意力机制的架构在编码器和解码器之间引入了注意力机制。
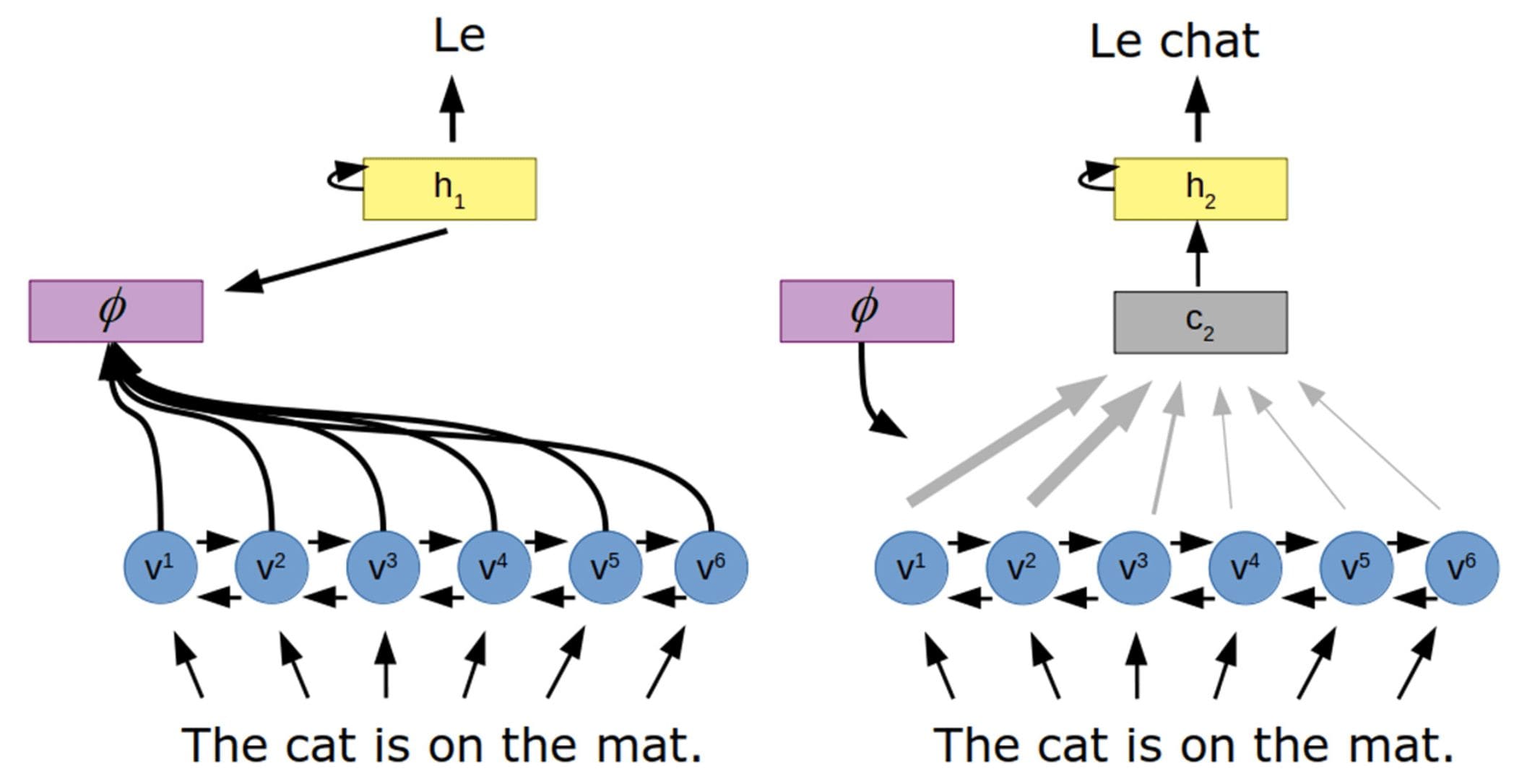
带注意力机制的编码器-解码器架构
摘自“心理学、神经科学和机器学习中的注意力机制”
在这里,注意力机制($\phi$)学习一组注意力权重,这些权重捕捉编码向量(v)和解码器隐藏状态(h)之间的关系,通过编码器所有隐藏状态的加权和生成一个上下文向量(c)。通过这样做,解码器将能够访问整个输入序列,并特别关注与生成输出最相关的输入信息。
Transformer
Transformer 的架构也实现了编码器和解码器。然而,与上面回顾的架构不同,它不依赖于循环神经网络的使用。因此,本文将单独回顾这种架构及其变体。
Transformer 架构摒弃了任何循环,而是完全依赖于自注意力(或内部注意力)机制。
就计算复杂度而言,当序列长度 n 小于表示维度 d 时,自注意力层比循环层更快……
—— 使用 Python 进行高级深度学习,2019年。
自注意力机制依赖于查询、键和值的使用,这些是通过将编码器对同一输入序列的表示与不同的权重矩阵相乘生成的。Transformer 使用点积(或乘法)注意力,其中每个查询通过点积运算与键数据库匹配,从而生成注意力权重。然后将这些权重乘以值以生成最终的注意力向量。
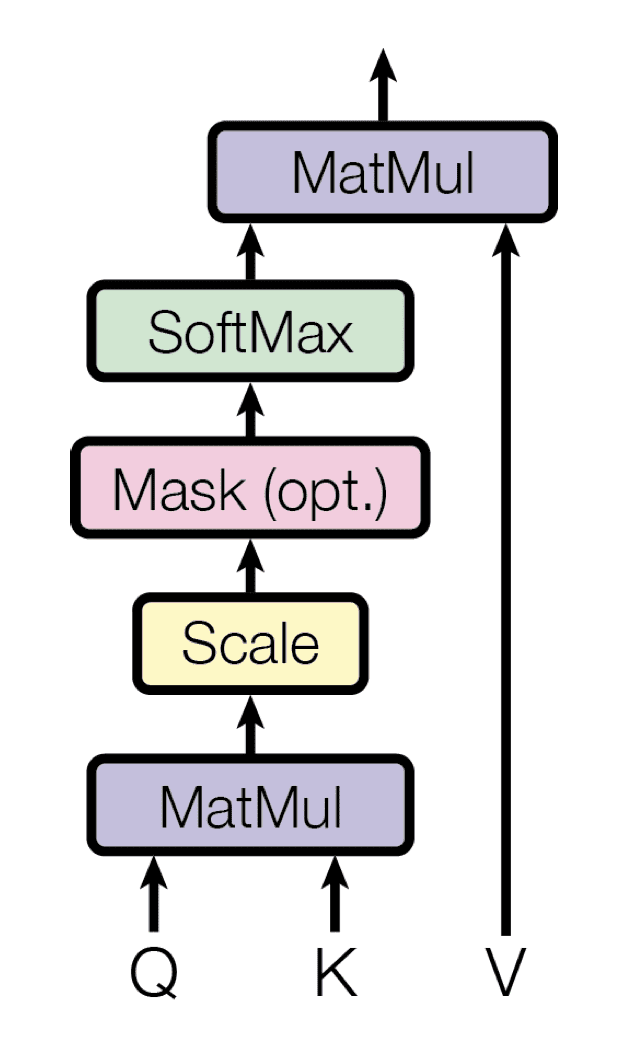
乘法注意力
摘自“Attention Is All You Need”
直观地,由于所有的查询、键和值都源自同一个输入序列,自注意力机制捕捉了同一序列中不同元素之间的关系,突出显示彼此最相关的元素。
由于 Transformer 不依赖于 RNN,可以通过用位置编码增强编码器对每个元素的表示来保留序列中每个元素的位置信息。这意味着 Transformer 架构也可以应用于信息不一定按顺序相关的任务,例如图像分类、分割或字幕生成等计算机视觉任务。
Transformer 可以捕捉输入和输出之间的全局/长程依赖关系,支持并行处理,需要最小的归纳偏置(先验知识),在大型序列和数据集上表现出可扩展性,并允许使用相似的处理块对多种模态(文本、图像、语音)进行领域无关的处理。
—— 注意力模型的一项综合调查,2021年。
此外,多个注意力层可以并行堆叠,这被称为多头注意力。每个头并行地对同一输入的各种线性变换进行操作,然后将这些头的输出连接起来以产生最终的注意力结果。拥有多头模型的好处是每个头可以关注序列的不同元素。
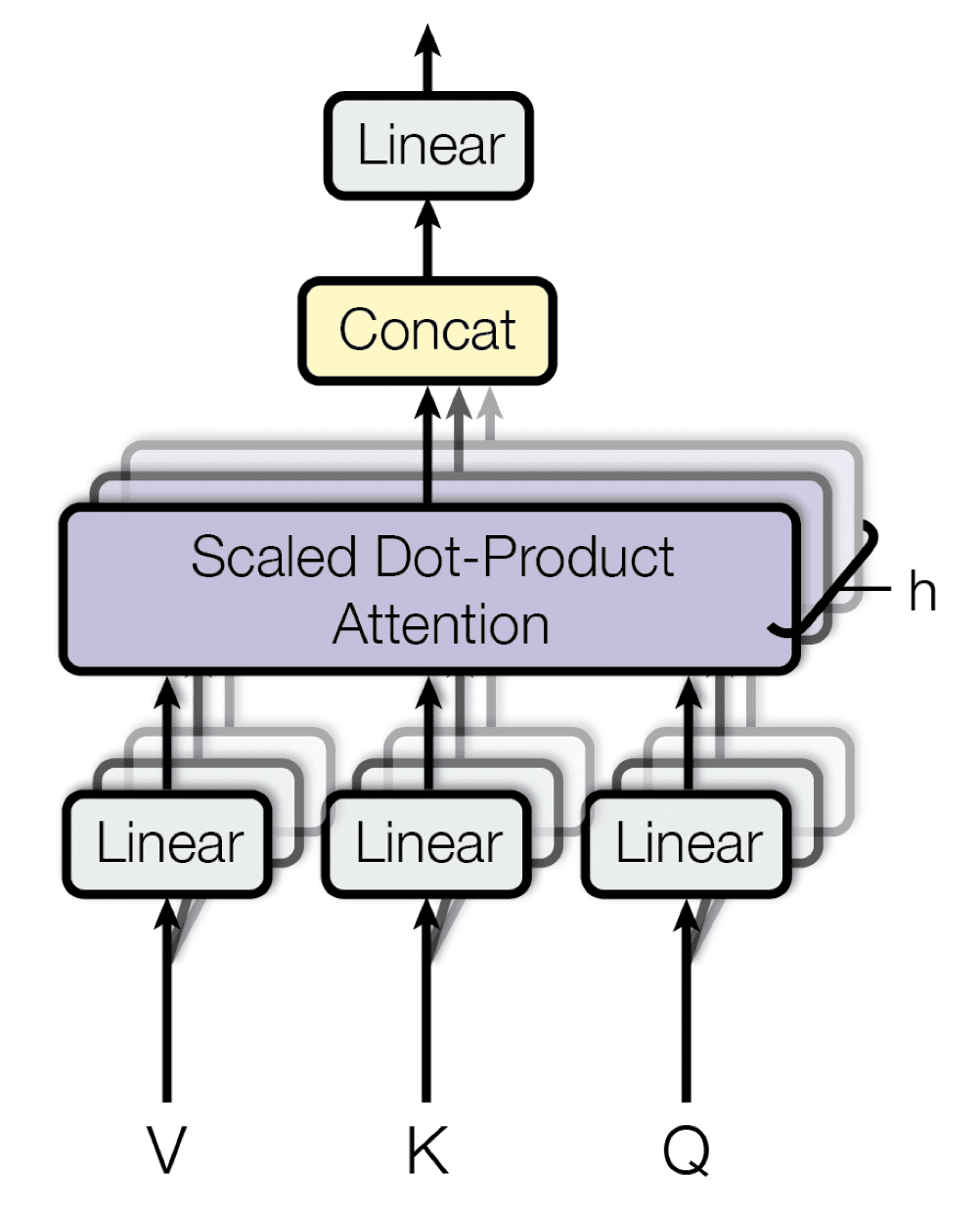
多头注意力
摘自“Attention Is All You Need”
Transformer 架构的某些变体解决了普通模型的局限性,例如:
- Transformer-XL:引入了循环机制,使其能够学习超出通常用于训练的片段序列固定长度的更长期依赖关系。
- XLNet:一种双向Transformer,通过引入基于置换的机制在Transformer-XL的基础上构建,其中训练不仅在构成输入序列的元素的原始顺序上进行,还在输入序列顺序的不同置换上进行。
想开始构建带有注意力的 Transformer 模型吗?
立即参加我的免费12天电子邮件速成课程(含示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
图神经网络
图可以定义为通过连接(或边)连接的一组节点(或顶点)。
图是一种通用的数据结构,非常适合许多现实世界场景中数据组织的方式。
—— 使用 Python 进行高级深度学习,2019年。
例如,以社交网络为例,用户可以用图中的节点表示,他们与朋友的关系可以用边表示。或者一个分子,其中节点将是原子,边将表示它们之间的化学键。
我们可以把图像看作一个图,其中每个像素都是一个节点,直接连接到其相邻像素……
—— 使用 Python 进行高级深度学习,2019年。
特别令人感兴趣的是图注意力网络(GAT),它在图卷积网络(GCN)中采用自注意力机制,后者通过对图的节点执行卷积来更新状态向量。卷积操作应用于中心节点和相邻节点,使用加权滤波器来更新中心节点的表示。GCN 中的滤波器权重可以是固定的或可学习的。
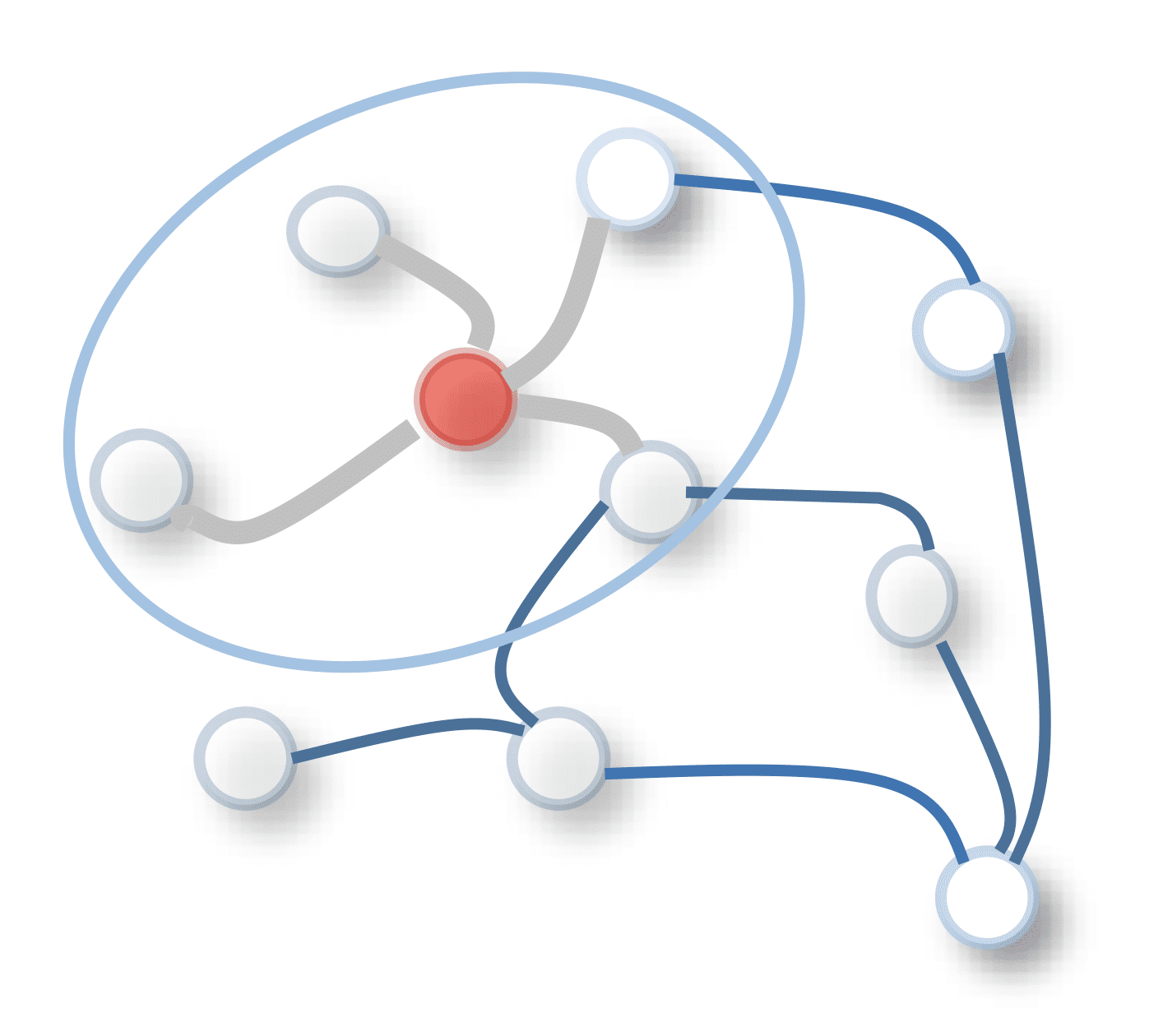
中心节点(红色)及其邻域节点的图卷积
摘自“图神经网络综合调查”
相比之下,GAT 使用注意力分数将权重分配给相邻节点。
这些注意力分数的计算遵循与上述 seq2seq 任务方法类似的过程:(1) 首先计算两个相邻节点特征向量之间的对齐分数,从中 (2) 通过应用 softmax 操作计算注意力分数,最后 (3) 可以通过所有邻居特征向量的加权组合计算每个节点的输出特征向量(相当于 seq2seq 任务中的上下文向量)。
多头注意力也可以在这里以与之前在 Transformer 架构中提出的非常相似的方式应用。图中的每个节点都将分配多个头,它们的输出将在最后一层中进行平均。
一旦产生最终输出,这可以作为后续特定任务层的输入。图可以解决的任务可以是不同组之间单个节点的分类(例如,预测一个人会决定加入哪个俱乐部)。或者它们可以是单个边的分类,以确定两个节点之间是否存在边(例如,预测社交网络中的两个人是否可能是朋友),甚至可以是完整图的分类(例如,预测一个分子是否具有毒性)。
使用我的书籍《构建基于注意力的Transformer模型》启动您的项目。它提供了带有工作代码的自学教程,指导您构建一个可以运行的完整Transformer模型。
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...
记忆增强神经网络
在迄今为止回顾的基于编码器-解码器注意力机制的架构中,编码输入序列的向量集可以被视为外部记忆,编码器向其写入,解码器从中读取。然而,存在一个限制,即编码器只能写入此记忆,而解码器只能读取。
记忆增强神经网络(MANNs)是旨在解决此限制的最新算法。
神经图灵机(NTM)是一种MANNs。它由一个神经网络控制器组成,该控制器接收输入以产生输出并执行对内存的读写操作。
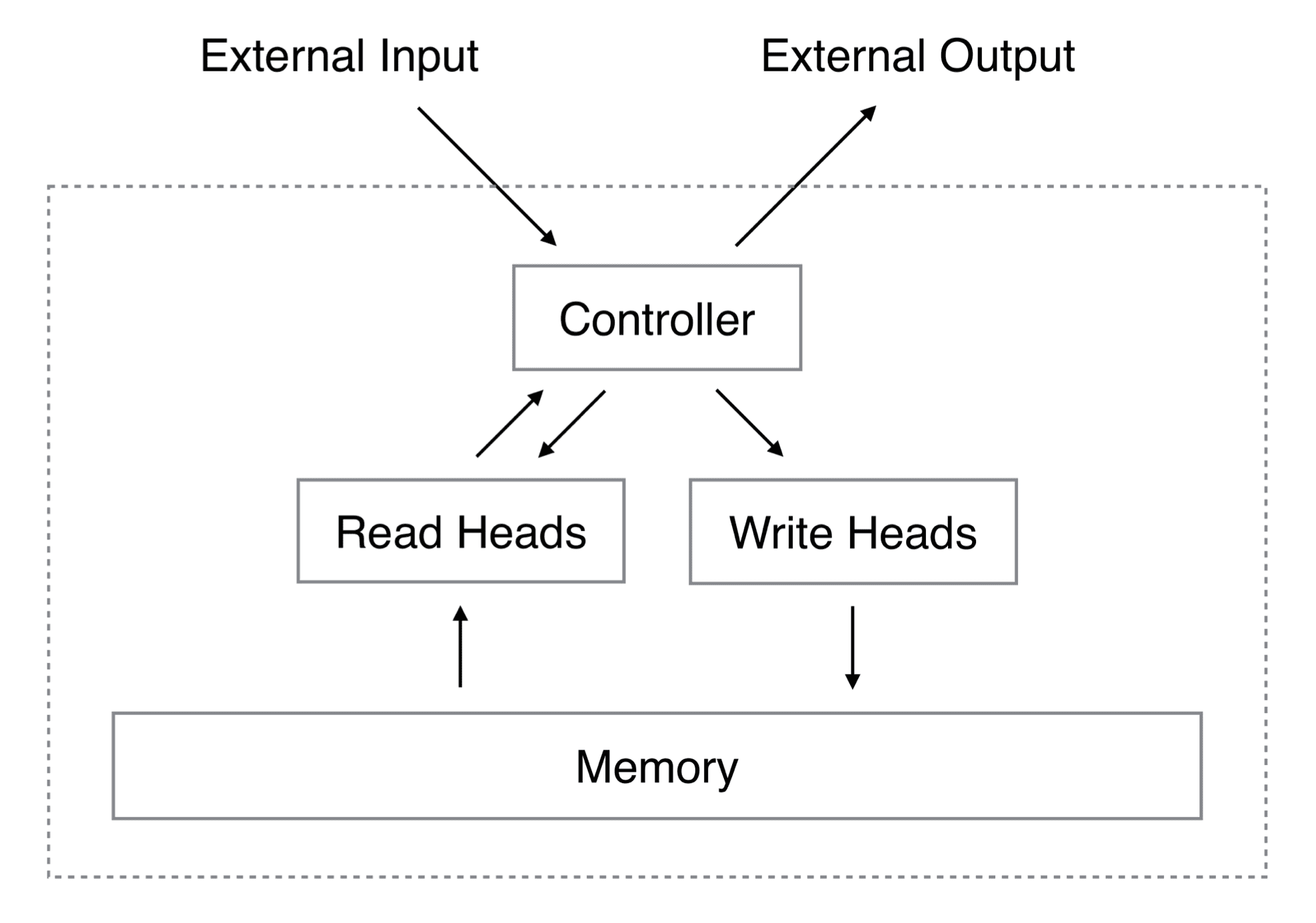
神经图灵机架构
摘自“神经图灵机”
读头执行的操作类似于用于 seq2seq 任务的注意力机制,其中注意力权重表示所考虑的向量在形成输出中的重要性。
读头总是读取完整的记忆矩阵,但它以不同的强度关注不同的记忆向量。
—— 使用 Python 进行高级深度学习,2019年。
读取操作的输出由记忆向量的加权和定义。
写头也利用注意力向量,以及擦除和添加向量。根据注意力向量和擦除向量中的值擦除内存位置,并通过添加向量写入信息。
MANNs 的应用示例包括问答和聊天机器人,其中外部记忆存储一个大型序列(或事实)数据库,神经网络可以从中获取信息。注意力机制在从数据库中选择与当前任务更相关的事实方面至关重要。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
- 使用 Python 进行高级深度学习, 2019.
- 深度学习要点, 2018.
论文
- 注意力模型的一项综合调查, 2021.
- 心理学、神经科学和机器学习中的注意力, 2020.
总结
在本教程中,您了解了与注意力机制结合使用的主要神经网络架构。
具体来说,您更好地理解了注意力机制是如何融入不同的神经网络架构以及其目的。
你有什么问题吗?
在下面的评论中提出您的问题,我将尽力回答。
学习 Transformer 和注意力!

教您的深度学习模型阅读句子
...使用带有注意力的 Transformer 模型
在我的新电子书中探索如何实现
使用注意力机制构建 Transformer 模型
它提供了自学教程和可运行代码,指导您构建一个可以
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...






Stefania,这篇帖子太棒了,对图神经网络做了精彩的简化介绍,你有没有关于卷积图神经网络的例子,附带代码或者特别是用于图像分析的链接?感谢你的帖子!
谢谢你,Stefania——一篇非常有趣的帖子。对我来说,了解更多关于LSTM架构中注意力机制在时间序列预测方面的应用也很有趣。
很棒的介绍。比较让我理解了很多。谢谢。
非常欢迎 Valdez!我们非常感谢您的反馈和支持!