在这篇文章中,我们将带您了解 最流行的机器学习算法。
了解该领域的主要算法,以便对可用方法有所了解,这是很有用的。
算法种类繁多,当算法名称被抛出时,您需要知道它们是什么以及它们适合哪里,这可能会让人感到不知所措。
我想向您介绍两种思考和分类您在该领域可能遇到的算法的方法。
- 第一种是按算法的学习方式分组。
- 第二种是按算法的形式或功能相似性分组(就像将相似的动物分组一样)。
两种方法都很有用,但我们将重点关注按相似性对算法进行分组,并介绍各种不同类型的算法。
阅读本文后,您将对最流行的有监督学习机器学习算法及其相互关系有更深入的了解。
使用我的新书掌握机器学习算法启动您的项目,其中包括分步教程和所有示例的Excel电子表格文件。
让我们开始吧。
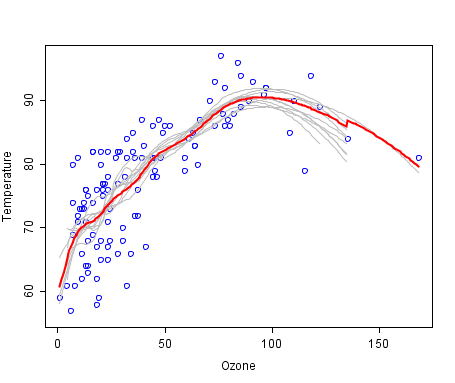
最佳拟合线集合的一个很酷的例子。弱成员是灰色的,组合预测是红色的。
图片来自维基百科,根据公共领域许可。
按学习方式分组的算法
根据算法与经验、环境或我们称之为输入数据的交互方式,算法可以有不同的方式来建模问题。
在机器学习和人工智能教科书中,首先考虑算法可以采用的学习方式是很常见的。
算法只有少数几种主要的学习方式或学习模型,我们将在这里介绍它们,并提供一些适合它们的算法和问题类型的示例。
这种对机器学习算法进行分类或组织的方式很有用,因为它迫使您思考输入数据和模型准备过程的作用,并选择最适合您问题的方法以获得最佳结果。
让我们看看机器学习算法中的三种不同学习方式
1. 有监督学习
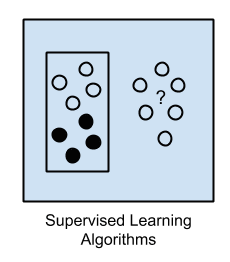 输入数据称为训练数据,具有已知标签或结果,例如垃圾邮件/非垃圾邮件或特定时间的股票价格。
输入数据称为训练数据,具有已知标签或结果,例如垃圾邮件/非垃圾邮件或特定时间的股票价格。
模型通过训练过程准备,在该过程中,它需要进行预测,并在预测错误时进行纠正。训练过程持续到模型在训练数据上达到所需的准确度水平。
示例问题包括分类和回归。
示例算法包括:逻辑回归和反向传播神经网络。
2. 无监督学习
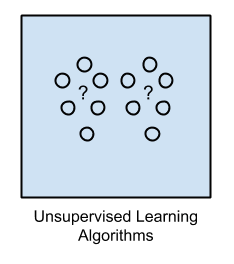 输入数据未标记且没有已知结果。
输入数据未标记且没有已知结果。
模型通过推断输入数据中存在的结构来准备。这可能是为了提取通用规则。它可能是通过数学过程系统地减少冗余,也可能是通过相似性来组织数据。
示例问题包括聚类、降维和关联规则学习。
示例算法包括:Apriori 算法和 K-Means。
3. 半监督学习
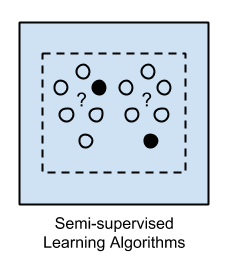 输入数据是标记和未标记示例的混合。
输入数据是标记和未标记示例的混合。
存在一个期望的预测问题,但模型必须学习组织数据的结构并进行预测。
示例问题包括分类和回归。
示例算法是对其他灵活方法的扩展,这些方法对如何对未标记数据进行建模做出假设。
机器学习算法概述
在处理数据以建模业务决策时,您最常使用有监督和无监督学习方法。
目前的热门话题是在图像分类等领域中的半监督学习方法,这些领域拥有大型数据集,但标记示例很少。
按相似性分组的算法
算法通常根据其功能(它们的工作方式)的相似性进行分组。例如,基于树的方法和受神经网络启发的方法。
我认为这是对算法进行分组最有效的方式,也是我们在这里采用的方法。
这是一种有用的分组方法,但它并不完美。仍然有一些算法可以很容易地归入多个类别,例如学习向量量化,它既是受神经网络启发的方法,也是基于实例的方法。还有一些类别名称相同,既描述了问题又描述了算法类别,例如回归和聚类。
我们可以通过两次列出算法或选择主观上“最合适”的组来处理这些情况。我喜欢后者的方法,即不重复算法,以保持简单。
在本节中,我们列出了许多流行的机器学习算法,并按照我们认为最直观的方式进行分组。该列表在组或算法方面都不是详尽无遗的,但我认为它具有代表性,并且有助于您了解情况。
请注意:这里强烈偏向于用于分类和回归的算法,这两种是最常见的有监督机器学习问题。
如果您知道未列出的算法或算法组,请在评论中写下并与我们分享。让我们深入探讨。
回归算法
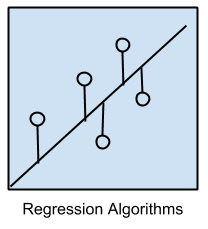 回归关注变量之间关系的建模,并通过模型预测中的误差度量进行迭代优化。
回归关注变量之间关系的建模,并通过模型预测中的误差度量进行迭代优化。
回归方法是统计学的主力,并已被纳入统计机器学习。这可能会令人困惑,因为我们可以使用回归来指代问题类别和算法类别。实际上,回归是一个过程。
最流行的回归算法是
- 普通最小二乘回归 (OLSR)
- 线性回归
- 逻辑回归
- 逐步回归
- 多元自适应回归样条 (MARS)
- 局部估计散点图平滑 (LOESS)
基于实例的算法
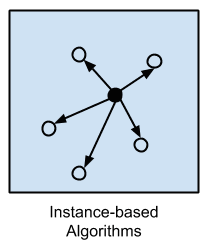 基于实例的学习模型是一个决策问题,它使用被认为对模型重要或必需的训练数据实例或示例。
基于实例的学习模型是一个决策问题,它使用被认为对模型重要或必需的训练数据实例或示例。
此类方法通常建立一个示例数据库,并使用相似性度量将新数据与数据库进行比较,以找到最佳匹配并进行预测。因此,基于实例的方法也称为赢家通吃方法和基于记忆的学习。重点放在存储实例的表示和实例之间使用的相似性度量。
最流行的基于实例的算法是
- k-近邻 (kNN)
- 学习向量量化 (LVQ)
- 自组织映射 (SOM)
- 局部加权学习 (LWL)
- 支持向量机 (SVM)
正则化算法
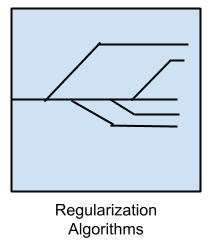 对另一种方法(通常是回归方法)的扩展,根据模型的复杂性对其进行惩罚,偏爱更简单且泛化能力更好的模型。
对另一种方法(通常是回归方法)的扩展,根据模型的复杂性对其进行惩罚,偏爱更简单且泛化能力更好的模型。
我在这里单独列出了正则化算法,因为它们很流行、功能强大,并且通常是对其他方法进行的简单修改。
最流行的正则化算法是
- 岭回归
- 最小绝对收缩和选择算子 (LASSO)
- 弹性网络
- 最小角回归 (LARS)
决策树算法
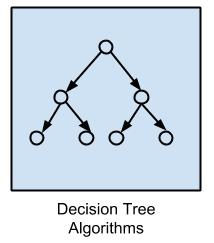 决策树方法根据数据中属性的实际值构建决策模型。
决策树方法根据数据中属性的实际值构建决策模型。
决策在树结构中分支,直到对给定记录做出预测决策。决策树针对分类和回归问题在数据上进行训练。决策树通常快速准确,是机器学习中的一大热门。
最流行的决策树算法是
- 分类与回归树 (CART)
- 迭代二分器 3 (ID3)
- C4.5 和 C5.0(强大方法的不同版本)
- 卡方自动交互检测 (CHAID)
- 决策桩
- M5
- 条件决策树
贝叶斯算法
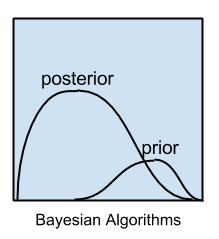 贝叶斯方法是明确应用贝叶斯定理解决分类和回归等问题的方法。
贝叶斯方法是明确应用贝叶斯定理解决分类和回归等问题的方法。
最流行的贝叶斯算法是
- 朴素贝叶斯
- 高斯朴素贝叶斯
- 多项式朴素贝叶斯
- 平均单依赖估计器 (AODE)
- 贝叶斯信念网络 (BBN)
- 贝叶斯网络 (BN)
聚类算法
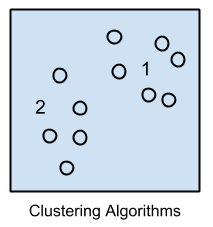 聚类与回归一样,描述了问题类别和方法类别。
聚类与回归一样,描述了问题类别和方法类别。
聚类方法通常按建模方法组织,例如基于中心点和分层。所有方法都关注利用数据中固有的结构,以最大程度地将数据组织成具有最大共性的组。
最流行的聚类算法是
- k-Means
- k-Medians
- 期望最大化 (EM)
- 层次聚类
关联规则学习算法
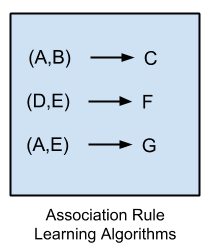 关联规则学习方法提取最能解释数据中变量之间观察到的关系的规则。
关联规则学习方法提取最能解释数据中变量之间观察到的关系的规则。
这些规则可以在大型多维数据集中发现重要且具有商业价值的关联,这些关联可以被组织利用。
最流行的关联规则学习算法是
- Apriori 算法
- Eclat 算法
人工神经网络算法
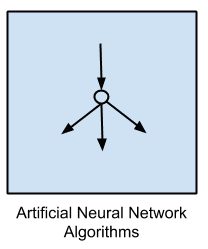 人工神经网络是受生物神经网络结构和/或功能启发的模型。
人工神经网络是受生物神经网络结构和/或功能启发的模型。
它们是一类模式匹配,通常用于回归和分类问题,但实际上是一个由数百种算法和针对各种问题类型的变体组成的庞大子领域。
请注意,我已将深度学习与神经网络分开,因为该领域增长和普及迅速。这里我们关注的是更经典的方法。
最流行的人工神经网络算法是
- 感知器
- 多层感知器 (MLP)
- 反向传播
- 随机梯度下降
- 霍普菲尔德网络
- 径向基函数网络 (RBFN)
深度学习算法
 深度学习方法是对人工神经网络的现代更新,利用了廉价的丰富计算。
深度学习方法是对人工神经网络的现代更新,利用了廉价的丰富计算。
它们关注构建更大、更复杂的神经网络,正如上文所述,许多方法都关注非常大的标记模拟数据集,例如图像、文本、音频和视频。
最流行的深度学习算法是
- 卷积神经网络 (CNN)
- 循环神经网络 (RNNs)
- 长短期记忆网络 (LSTMs)
- 堆叠自编码器
- 深度玻尔兹曼机 (DBM)
- 深度信念网络 (DBN)
降维算法
 与聚类方法类似,降维寻求并利用数据中固有的结构,但在这种情况下以无监督的方式或顺序总结或描述数据,使用更少的信息。
与聚类方法类似,降维寻求并利用数据中固有的结构,但在这种情况下以无监督的方式或顺序总结或描述数据,使用更少的信息。
这对于可视化高维数据或简化数据很有用,简化后的数据可以用于有监督学习方法。这些方法中的许多都可以适用于分类和回归。
- 主成分分析 (PCA)
- 主成分回归 (PCR)
- 偏最小二乘回归 (PLSR)
- Sammon 映射
- 多维标度 (MDS)
- 投影追踪
- 线性判别分析 (LDA)
- 混合判别分析 (MDA)
- 二次判别分析 (QDA)
- 灵活判别分析 (FDA)
- t-分布随机邻域嵌入 (t-SNE)
- 均匀流形近似与投影降维 (UMAP)
集成算法
 集成方法是由多个弱模型组成的模型,这些弱模型独立训练,其预测以某种方式组合以形成整体预测。
集成方法是由多个弱模型组成的模型,这些弱模型独立训练,其预测以某种方式组合以形成整体预测。
在组合哪种类型的弱学习器以及如何组合它们方面付出了很多努力。这是一类非常强大的技术,因此非常流行。
- 提升
- 自助聚合 (Bagging)
- AdaBoost
- 加权平均 (Blending)
- 堆叠泛化(Stacking)
- 梯度提升机 (GBM)
- 梯度提升回归树 (GBRT)
- 随机森林
其他机器学习算法
许多算法未涵盖。
我没有涵盖机器学习过程中专门任务的算法,例如
- 特征选择算法
- 算法准确度评估
- 性能指标
- 优化算法
我也没有涵盖机器学习专门子领域的算法,例如
- 计算智能(进化算法等)
- 计算机视觉 (CV)
- 自然语言处理 (NLP)
- 推荐系统
- 强化学习
- 图形模型
- 等等…
这些可能会出现在未来的帖子中。
关于机器学习算法的进一步阅读
这次机器学习算法之旅旨在为您提供一个概览,了解现有算法以及如何将算法相互关联起来。
我为您收集了一些资源,以继续您对算法的阅读。如果您有具体问题,请留言。
其他机器学习算法列表
如果您感兴趣,还有其他很棒的算法列表。以下是一些精选示例。
- 机器学习算法列表:在维基百科上。尽管内容广泛,但我不认为此列表或算法的组织特别有用。
- 机器学习算法类别:也在维基百科上,比维基百科上面出色的列表稍微有用一些。它按字母顺序组织算法。
- CRAN 任务视图:机器学习和统计学习:R 中所有包及其支持的所有机器学习算法的列表。让您对现有内容以及人们日常用于分析的内容有一个切实的了解。
- 数据挖掘十大算法:关于数据挖掘中最流行的算法。另一种基于现实且不那么令人不知所措的方法,您可以深入学习。
如何学习机器学习算法
算法是机器学习的重要组成部分。这是一个我非常热衷并在这个博客上写了很多的领域。以下是一些精选的帖子,您可能会感兴趣,以供进一步阅读。
- 如何学习任何机器学习算法:一种系统方法,您可以使用“算法描述模板”来学习和理解任何机器学习算法(我使用这种方法来写我的第一本书)。
- 如何创建有针对性的机器学习算法列表:如何创建自己的系统性机器学习算法列表,以快速启动下一个机器学习问题的工作。
- 如何研究机器学习算法:一种系统方法,您可以使用它来研究机器学习算法(与上面列出的模板方法结合使用效果很好)。
- 如何研究机器学习算法行为:一种方法,您可以通过创建和执行非常小的行为研究来了解机器学习算法的工作原理。研究不仅仅是学术界的专属!
- 如何实现机器学习算法:从头开始实现机器学习算法的过程以及技巧和窍门。
如何运行机器学习算法
有时你只想直接编写代码。以下是一些链接,你可以用来运行机器学习算法,使用标准库编写它们,或者从头开始实现它们。
- 如何在R中开始使用机器学习算法:链接到本网站上的大量代码示例,演示R中的机器学习算法。
- scikit-learn中的机器学习算法食谱:一系列Python代码示例,演示如何使用scikit-learn创建预测模型。
- 如何在Weka中运行你的第一个分类器:一个在Weka中运行你的第一个分类器的教程(无需代码!)。
结束语
希望您觉得这次旅程有所帮助。
如果您对如何改进算法之旅有任何问题或想法,请留言。
更新:继续在HackerNews和reddit上讨论。







强化学习算法在算法相似性分类中如何处理?
贝叶斯学习中还有一个叫做吉布斯算法。
布鲁斯说得对,我把那些方法漏掉了。你想让我写一篇关于强化学习方法的文章吗?
是的!!!!
附言:拜托 :0
Jason,
我喜欢你的博客和你用简单的语言解释复杂话题的写作风格。
我有一个请求。你有没有选择正确算法的备忘单?我想知道作为初学者指南,何时使用何种机器学习算法?
谢谢你,
Bk
为问题选择“正确”的算法是一个过程
https://machinelearning.org.cn/a-data-driven-approach-to-machine-learning/
你好 Jason,希望你一切都好!
我们如何借助神经网络制作推荐系统
&
如何使用神经网络实现协同过滤
分类器和算法有什么区别?两者一样吗?
你好 Sam,
算法是一种程序。比如从数据中学习一棵树。算法的结果是一个模型或分类器,比如用于预测的树。
那我不太明白为什么“人工神经网络算法”标题下同时列出了反向传播和霍普菲尔德网络。反向传播显然是一种训练算法,而霍普菲尔德网络可能是一种分类器?
好帖子!
这很公平。与其列出反向传播,我们应该列出多层感知器。
嗨 Jason,非常有趣的文章……我有点新手……我遇到了“机器学习算法”、“机器学习方法”和“机器学习模型”这些短语。
我想我理解算法和模型。那么“方法”的具体细微差别是什么?
好问题,这会有帮助
https://machinelearning.org.cn/difference-between-algorithm-and-model-in-machine-learning/
是的,请
也发布一本关于强化学习和无监督深度学习的电子书。你真是太棒了,Jason。你让这些困难的概念对我们来说变得非常简单易懂。
谢谢你的建议,Sameer。
当然。我一遍又一遍地翻阅杰森的书籍/博客,以完成各种任务,并且它们都只需稍作调整即可奏效
谢谢!
Jason 的资料帮助我成功完成了我的博士研究。非常感谢他
谢谢!祝贺你的博士学位!
我也很想这样
新手(没有分析/统计背景)从哪里开始学习这些算法?更重要的是,如何将它们与 Hadoop 等大数据工具一起使用?
你好 qnaguru,我建议您从小处着手,使用 Weka 等工具在小数据集上试验算法。它是一个 GUI 工具,开箱即用,提供了一系列标准数据集和算法。
我建议您先在小数据集上积累一些技能,然后再转向 Hadoop 和 Mahout 等大数据工具。
qnaguru,
我推荐 Coursera 课程。
我还建议阅读几本书,为您提供一些关于可能性和局限性的背景知识。Nate Silver 的《信号与噪声》和 Daniel Kahneman 的《思考,快与慢》。
我发现写得最好的一本是:《统计学习要素:数据挖掘、推断和预测,第二版》。然而,在阅读之前,你可能需要具备一些数学/统计/计算背景(特别是如果你打算实现它们)。对于通用算法的实现,我建议阅读《数值食谱第三版:科学计算的艺术》。
我是数值食谱的忠实粉丝,谢谢你的书目推荐。
推荐系统一个都没有吗?
我会把推荐系统称为一个更高阶的系统,它内部正在解决回归或分类问题。你同意吗?
确实如此
遗传算法这些天似乎正在慢慢消亡(之前讨论过 https://news.ycombinator.com/item?id=7712824 )
这是一个很好的观点。计算机速度足够快,可以比遗传算法收敛得更快地枚举搜索空间(至少对于经典的玩具问题而言)。
我喜欢这篇文章,但我认为这是一个误导性的说法。遗传算法在大搜索空间(在这里枚举是不可能的,我们谈论的是10^100的空间)和高度复杂的非凸函数中最为有用。现代算法比80年代使用的简单技术要复杂得多,例如(http://en.wikipedia.org/wiki/CMA-ES)和(http://en.wikipedia.org/wiki/Estimation_of_distribution_algorithm)。这里有一个不错的近期应用:http://www.cc.gatech.edu/~jtan34/project/learningBicycleStunts.html
谢谢 Alex,您还可以查阅我 2011 年的算法食谱一书,名为《巧妙算法:自然启发式编程食谱》。书中我涵盖了 5 种不同的分布估计算法和 10 种不同的进化算法。
嗨,各位,这太棒了!推荐系统呢?我对Netflix、亚马逊和其他网站如何根据我的喜好推荐商品感到着迷。
说得好。
您可以将推荐系统分解为分类或回归问题。
没错,甚至可以使用 Apriori 等规则归纳法…
想象力何在?它会是一种无监督反馈学习吗?也许它是神经网络深度集成网络。我想做梦就是睡觉时想象,因此白日梦就是想象新的学习算法 🙂
这对我来说太深奥了@mycall
很多人都推崇这张图表来帮助缩小机器学习方法的选择范围:https://scikit-learn.cn/stable/_static/ml_map.png。它似乎没有涵盖您文章中列出的所有类型。也许一张更全面的图表会很有用。
谢谢 vas 的链接!
感谢分享,已贴在我的墙上。有用但并非详尽无遗。缺少一些主题:预处理包括特征选择、自然语言处理
太棒了。我一直在寻找“所有类型”的机器学习算法。我很喜欢阅读这篇,并期待进一步阅读
非常欢迎您@Nevil。
这很好也很实用……我一直被大量数据弄得头昏脑涨,这就像提供了一个菜单,我可以从中选择哪些东西可以帮助我理解这些信息 🙂 谢谢
@UD,这是一个很棒的思考方式,一个算法菜单。
您可能希望在摘要中包含基于熵的方法。我在我的工作中使用基于相对熵的监控来识别时间序列数据中的异常。当使用注入异常值的人工数据进行测试时,这种方法具有更好的召回率和更低的误报率。只是一个想法,您的总结对于这种高层次的概念概述来说非常出色。
嗨,Tim
你能给我一些可以学习基于相对熵的监控的参考资料吗?
谢谢你!真的很值得我花时间!
谢谢@Tim,我想我会增加一个关于时间序列算法的部分。
你好,
谢谢这次巡览,非常有帮助!但我不同意您关于 LDA 方法的说法,它属于核方法。首先,您说的 LDA 是指线性判别分析吗?如果不是,我评论的下一部分就没用了 :p
如果您谈论的是这种方法,那么您应该写 KLDA(代表核 LDA),而不是简单地写 LDA。因为 LDA 更像是一种降维方法而不是核方法(它找到最佳超平面,优化费舍尔判别式,以便将数据投影到其上)。
其次,我不知道我们是否可以将 RBF 视为一种真正的机器学习方法,我认为它更像是一种映射函数,但它显然用于映射到更高维度。
除了这两点,这篇文章很棒!再次感谢。
谢谢@Vincent,我会考虑稍微调整一下算法的分组。
在我看来,LDA 和类似的算法可以自成一类,因为它们既能降维,又能用作分类器。
另一个出色的例子是 t-SNE。
你说的对。这里发布的只是分类的多种方式之一。谢谢你的评论。
@Vincent,我想他指的是径向基网络 (RBN),这是一种使用径向基函数的人工神经网络 [1]。Jason 将其归入人工神经网络分类是正确的。
[1] https://en.wikipedia.org/wiki/Radial_basis_function_network
很棒的帖子,但我同意 Vincent 的观点。核方法本身不是机器学习方法,而是一种扩展,可以克服输入数据不是线性可分时遇到的一些困难。SVM 和 LDA 不是基于核的,但它们的定义可以进行调整以利用著名的核技巧,从而产生 KSVM 和 KLDA,它们能够在更高维空间中线性分离数据。核技巧可以应用于各种机器学习方法
– LDA
– SVM
– PCA
– K均值
等等…
此外,我不认为 RBF 可以被视为一种机器学习方法。它是一个核函数,与核技巧一起用于将数据投影到高维空间。因此,“核方法”中的列表似乎有输入错误 :p
最后一点,您不认为 LDA 可以添加到“降维”类别中吗?事实上,这更是一个开放性问题,但是,混合方法(聚类)和因子分析可以被视为“降维方法”,因为数据可以通过其聚类 ID 或其因子进行标记。
再次感谢您的这篇帖子,提供机器学习方法的概述是一件很棒的事情。
很棒的评论@Rémi,我会稍微调整一下。
我对此感到困惑,不得不查了一下。
– 径向基函数 (RBF) 可以用作核函数
– 径向基网络 (RBN) 是一种使用径向基函数的人工神经网络
你好 qnaguru,我收集了一些不错的参考书来开始深入研究机器学习。我建议你从《统计学习导论》开始,之后你可以查阅《统计学习要素:数据挖掘、推断和预测,第二版》和 David Barber 的《概率机器学习》。
非常好的方法分类。有两点小小的异议,都在决策树部分。
1) MARS 不是树方法,而是样条方法。你已经在回归组中列出了它,但甚至可以放在正则化组中。(恕我直言,它不适合任何一个类别)。
2) 随机森林是一种集成方法,在树组中显得有些格格不入。是的,它们是树,但 MART (TreeNet) 和某些 Adaboost 变体也是。既然你已经有了集成方法,并且 RF 已经在那里,我认为你可以安全地将其从树中删除。
再次强调,你做的这个列表非常棒。恭喜!
Dean
谢谢 Dean,我会把你的评论记在心里。
很棒的文章。我的机器学习知识在广度上有所提高,但在深度上没有。我该如何提高我的学习?我用回归分析和随机森林做了一些实时实现。我也在上 Coursera 课程。我如何获得使用 Hadoop 的 ML R 的实时经验?
谢谢布朗利先生的有用指导。我们能在哪里找到所有这些算法的实现?我安装了weka,但它没有其中一些算法
您可能需要使用 R 和 scikit-learn 等其他平台。
您是否正在寻找特定算法的实现?
好文章!
我目前正在学习稀疏编码。我很难将稀疏编码归入您创建的类别中。
——您对稀疏编码有什么看法?
——它应该属于哪个类别?
您能提供一些学习稀疏编码的建议吗?
——我应该具备哪些数学基础?
——有没有好的教程资源?
——您能推荐一个学习路线图吗?
我正在上凸优化课程。这是一个正确的路线图吗?
排名如何融入机器学习算法?它是否在文章中提到的某些类别之下?我只有在专门搜索排名时才会发现机器学习文章中提到排名,而其他机器学习文章都没有讨论它。
哪种相似度算法效率更高?
Amelie,使用计算复杂性评估相似性算法,并对它们进行实证测试看看。
什么方法/算法适用于交易模式分析。我是说查看过去6个月的交易图表(例如SPY)。目前,我正在目视查看图表。算法能帮助我吗(我目前正在上一门在线数据挖掘课程)?
这听起来像一个时间序列问题,可以考虑从自回归开始。
嗨,Jason,
这是一篇很棒的文章。我希望你能提供一份在医学研究领域流行的机器学习算法列表。
此致,
Saima Safdar
太棒了。Jason,这确实为我理清了思路!我有一个关于批量梯度下降和正规方程的问题。它们被认为是估计器吗?
我希望看到一篇帖子,简单易懂地介绍每种算法可以使用的不同类型的估计器/优化器。此外,特征缩放(最小-最大缩放和标准化)以及其他内容属于哪个类别?它们也是优化器吗?好多东西啊!
非常感谢您分享您的知识!
嗨 Jason
对您上面关于推荐系统的评论很感兴趣,即:
“我会把推荐系统称为一个更高阶的系统,它内部正在解决回归或分类问题。”以及,
“你可以把推荐系统分解成一个分类问题或者一个回归问题。”
您能详细阐述您的思考过程吗?总的来说,我发现人们在谈论构建或想要一个“分类器”时,因为它是一个时尚的热词(并且与深度学习有关),而实际上,一个推荐系统或其他东西就能完成这项工作。无论如何,很棒的讨论。
Jason,真是太棒了!关于您12月26日的评论,我投票赞成看到一篇关于强化学习方法的帖子
嗨,Jason,
我正在尝试通过计算机视觉和机器学习实现目标检测,但我在寻找合适的方法时遇到了瓶颈。您能建议哪种算法能帮助我吗?我想对此进行更深入的研究。
嗨..我正在使用机器学习方法寻找缺失值..
有人能建议新的方法吗?
我是一名研究学者
嗨,Jason,
只是一个小问题:在我看来,k-NN、SVM、朴素贝叶斯、决策树、最大熵(即使这里没有提到)都被认为是基于实例的,对吗?
很棒的帖子,现在我知道自己的位置了。
我开始阅读,但我觉得我无法理解它。
我不明白哪种算法适合哪种类型的问题。
我认为每个算法的小例子会很有用。
你好,
我如何将支持向量机及其扩展归入您的列表?
Jason:为每个“家族”的机器学习算法添加了简单的图形,这是一个很好的补充。这与我回忆中的这篇文章的早期版本有所不同。该图有助于可视化该家族的活动,从而帮助建立一个关于家族成员如何运作的内部模型。
简单而强大的效果。
贝叶斯算法的图形应该重新制作。特别是,
1) 两个密度函数下的面积都应积分到1。虽然没有提供比例,但先验积分值似乎比后验小得多。
2) 通常,给定观测值,后验比先验更窄/更集中。
3) (将基线解释为零密度)后验通常将先验的概率集中在一个更小的范围内;它从不将概率“移动”到先验密度为零的范围。
你好 jason,
您能为我下面的问题推荐一个算法吗?
我需要一个能进行时间序列分析,也能进行贝叶斯分析的算法。
对于测试集,
我获得了半天的小时价格变动数据,任务是预测下半天的价格变动。这显然是一个时间序列 (TS) 问题。
但除此之外,我还获得了训练集和测试集中每天10个离散因子的信息。
您知道有没有算法可以根据各种离散因子在开始时的值(或范围)创建多个时间序列模型?
嗨 Jason
非常感谢您的分享,我想了解哪些机器学习方法(算法)在预测中很有用。
嗨 Jason
如果能告诉我哪种神经网络对多元时间序列分类有用,我将不胜感激。例如,当我们有每个特征的多个时间序列时,如何对病患和健康人进行分类。
你找到解决方案了吗?我也有同样的问题。我正在考虑使用卷积神经网络,并利用特征空间创建热力图图像作为输入。例如,像素图像中的每一行将是一个由特征映射的RGB值,每一列将是一个特定的时间点。这样,你可以将所有多元时间序列都放在一个图像中。如果时间间隔非常高,你可能需要降低维度,或者将时间间隔分区为图像的各个部分(例如,图像上半部分的第一个500个时间点)。我不知道这是否会奏效,只是一些想法……
我在人工智能和机器学习方面有很好的背景,我必须说这是一个非常好的列表,我不会用任何其他方式进行分类,它非常接近完美。信息非常中肯。
然而,如果能为强化学习、遗传算法和概率模型包含学习风格类别会更好(但与此同时,您已经在文章末尾提到了它们,这为读者提供了一个很好的提示)。
末尾的链接非常好,特别是“如何学习机器学习算法”。如果能列出机器学习在线课程(Coursera、Udacity等——甚至有 Geoffrey Hinton 的课程!)以及关于如何检查和验证您的机器学习算法在您的数据集上运行良好的教程链接(交叉验证、泛化曲线、ROC、混淆矩阵等)也会很好。
另外,感谢之前的评论者,您的评论也非常中肯,为文章增色不少!
为了完善我关于添加学习风格类别的建议:我认为应该添加这些学习算法类别,因为它们越来越被使用(尽管不如当前列出的方法受欢迎),并且它们无法被其他学习类别取代,它们带来了自己的能力。
——强化学习以奖惩的方式进行学习。这允许以与实际大脑使用愉悦回路学习非常相似的方式(TD学习)探索和记忆环境状态或行动。它还具有一个非常有用的能力:阻断,这自然允许强化学习模型只使用有助于预测奖励的刺激和信息,无用的刺激将被“阻断”(即,过滤掉)。目前,这与深度学习结合使用,以建模更具生物学合理性和强大功能的神经网络,例如,也许可以解决围棋游戏问题(参见谷歌的DeepMind AlphaGo)。
——遗传算法,正如一位评论者所说,最适用于面临高维问题或多模态优化(即存在多个同样好的解决方案,又称多重均衡)的情况。此外,一个巨大的优势是遗传算法是无导数成本优化方法,因此它们非常通用,几乎可以应用于任何问题并找到一个好的解决方案(即使其他算法可能找到更好的)。
——概率模型(例如,蒙特卡罗、马尔可夫链、马尔可夫过程、高斯混合等)和概率图模型(例如,贝叶斯网络、信度网络、马尔可夫图等)非常适合不确定情况和推理,因为它们可以处理不确定值和隐藏变量。图模型与深度学习有些接近,但它们更灵活(从您想做什么的语义来定义PGM比定义深度学习网络更容易)。
——也许最后提一下模糊逻辑,它本身不是机器学习算法,但与概率模型接近,只是它可以被视为一个超集,也允许定义可能性值(参见可能性逻辑和Edwin Jaynes的工作)。
你好,
你很好地阐述了这些算法,谢谢。
祝好,
vicky | techvicky.com
嗨,Jason,
我才刚刚开始学习机器学习算法。我还需要一些时间来消化我在这里读到的内容。我的背景是金融/投资,因此我一直试图更多地了解机器学习在投资中的应用。我来自基本面投资背景,因此我很想知道您是否有见解。鉴于有如此多的算法(以及不同的分支 https://www.youtube.com/watch?v=B8J4uefCQMc,我认为这是一个有趣的视频),我想问您如何知道哪种类型的机器学习分支/算法对投资更有用?
祝好,
婷
感谢这篇精彩的文章。
它确实有助于理清各种算法类型,并理清这个有趣领域的复杂性。
很高兴听到您这么说,Marc。
非常有用的一个。
谢谢Jitu。
什么都无法下载。它只是不断地确认我的订阅。
很抱歉听到这个消息。确认订阅后,您将通过电子邮件收到思维导图。
也许检查一下你的其他电子邮件文件夹?
见解深刻,感谢您的撰写。
不客气,Francis。
精彩的帖子。我一直在关注这个博客,印象深刻!
非常有用的信息,尤其是最后一部分
) 我非常关心这些信息。我一直在寻找这些
特定的信息很久了。谢谢你,祝你好运。
我很高兴您觉得它有用。
嗨,Jason,
我想知道SVM的类别。
它无法完全适应这种分类法。
感谢您对网站的投入
以及您提供的详细信息。很高兴偶尔能遇到
一个并非千篇一律的博客。
非常棒的阅读体验!我已收藏您的网站,并将您的RSS订阅
添加到我的Google账户。
谢谢。
您将逻辑回归列为回归算法。我一直认为该方法是神经网络的基础,因此更像是一个分类器而不是回归算法。
我完全同意你的观点。一个(简单)逻辑回归的结果是二元的,该算法应该属于分类方法的一部分,就像你提到的神经网络一样。
您好,先生。非常感谢您的帮助。但我们知道机器学习需要强大的“数学”背景。我对数学很感兴趣,但在这方面有些薄弱。所以,我想要好的、易于理解的机器学习所需数学资源。谢谢。
我教授一种无需理论或数学理解即可入门的方法。将机器学习视为可以用来解决问题和创造价值的工具。如果需要为了提供更好的解决方案,深层的数学理解可以在以后获得。
请看这篇文章
https://machinelearning.org.cn/how-do-i-get-started-in-machine-learning/
Jason,感谢您的撰写。在有监督学习中使用回归分析时,我找到的所有例子都处理简单的标量输入,也许是一个输入的多个特征。如果输入数据更复杂,例如两个值,其中一个是二次曲线,另一个是实数,该怎么办?我有一些数据,由两对值组成:单变量二次函数(表示为二次函数或点数组)和一个实数R。每个二次函数F会根据其实数对R相当可预测地改变其偏斜/形状,并变为(改变为)F'。给定一个新的实数R',它变为F''等等。这是训练数据,我大约有上千对函数和实数。基于当前函数F和新的实数R,我们能否使用有监督学习和回归分析预测F'的形状?如果可以,我应该注意什么?任何帮助都将不胜感激!
最佳子集选择、逐步选择、向后选择作为降维方法怎么样?这是正则化方法,但你也可以将其用作收缩维度。
是否有任何算法具有反馈循环?
Jason——想详细讨论使用您的算法预测体育赛事结果的能力。您研究过吗?
请发邮件
utdad1@gmail.com
Bryan,我在这方面只做了一些工作。
您可以在这里直接联系我
https://machinelearning.org.cn/contact
感谢您对机器学习算法动物园的精彩游览——比真实的更有趣。
Howard,我很高兴您觉得它有用。
这很有用,但对于该领域的新手来说,可以使其更有用,特别是在算法按相似性分组的部分,通过准确阐明正在学习的内容。例如,回归算法学习最适合数据点的曲线,贝叶斯学习算法学习贝叶斯网络的参数和结构,决策树算法学习决策树的结构等。
此外,某种基于任务的分类也会有所帮助。例如,如果您正在尝试分类,那么以下类型的机器学习算法是最好的;如果您正在尝试进行推理,那么规则学习和贝叶斯网络学习是很好的;如果您正在进行曲线拟合,那么回归是很好的,等等。
为了澄清我提出的第一点:例如,当您写朴素贝叶斯时,学习的不是朴素贝叶斯方法本身,也不是某个水果是苹果还是梨,而是应用贝叶斯方法并可用于对给定水果进行分类的网络结构和参数。
很好的建议,谢谢Srinivas。
嗨,Jason,
这篇文章至少对我(作为初学者)来说,理论上描述了几乎所有最好的算法。
但我刚接触机器学习,所以无法将算法的用例与实际问题/场景联系起来。您能给我一些链接,让我能够将每种算法与不同的实时/真实商业问题联系起来吗?
提前致谢! 🙂
Anuj你好,通常将预测建模问题视为分类(预测类别或类型)和回归(预测数字)是有帮助的。
然后您可以将算法分为分类和回归类型。
此页面列出了现代和流行的机器学习问题
https://machinelearning.org.cn/tour-of-real-world-machine-learning-problems/
你好,Jason。
我是机器学习的初学者。您能建议我如何开始学习以及需要哪些基本知识吗?
此致,
Avdhesh
Avdhesh,好问题,
我教授一种自上而下的机器学习方法,您可以在这里了解所有相关信息
https://machinelearning.org.cn/start-here/#getstarted
Jason,这是一个很棒的列表,谢谢。
我完全是这个领域的新手——所以这是一个很好的起点。在其他我更熟悉的方法、模式或算法类型“领域”中,通常可以定义通用的弱点/痛点、优点/收益以及需要注意的事项(例如如何设置参数)。我想知道您指定的每个算法组的这些会是什么。
我看到您描述了用例,例如,可以使用贝叶斯算法和决策树算法进行分类。但是,在分类时,我什么时候会倾向于选择其中一个而不是另一个呢?……只是一个例子……
Steffen,这是一个很好的问题,而且很难回答。
找到给定问题的最佳/良好算法的最佳实用方法是试错法。启发式方法提供了一个很好的指导,但有时/通常您可以通过打破一些规则或建模假设来获得最佳结果。
我建议对给定问题进行经验试错(或方法之间的竞争),这是最好的方法。
尊敬的Jason博士,
很棒的帖子。谢谢
Khalid,我很高兴您觉得它有用。
嗨,Jason,
非常感谢您的文章。
您会建议如何利用自然语言处理(NLP)来衡量研究绩效?
抱歉,我对 NLP 并不熟悉,Tammi。
嗨,Jason,
精彩的帖子!真的帮助我很多,让我理解了不同的算法。
我的问题是,我见过很多除了上述列表之外的算法。
您能发布这些算法如何工作以及一些例子吗?
例如:Cart算法(决策树)——它们如何分裂、熵、信息增益、基尼指数和不纯度。
我希望您理解我的问题。所有算法都如此。
当然,我在这本书中解释了算法是如何工作的
https://machinelearning.org.cn/master-machine-learning-algorithms/
如果您更像一名程序员,我在这本书中用 Python 代码解释了它们是如何工作的
https://machinelearning.org.cn/machine-learning-algorithms-from-scratch/
希望这能有所帮助。
你的页面,不,你的网站是金子。我对机器学习的了解非常贫乏,你在几段话中帮助我更多地了解何时使用哪种算法。
我还没有阅读你的书,但我决定必须说声谢谢。非常感谢。
谢谢 Iman。
嗨,Jason,
感谢您的友好回复。
掌握机器学习算法——通过这本书,是否有可能理解算法的工作原理以及如何为不同类型的训练集构建预测模型。
通过观察问题或训练数据,我们能否判断机器学习(基于树、knn、朴素贝叶斯或优化)和算法(cart、c4.5)是否最适合?
我可以购买您提到的那本书——
但我更关心算法的工作原理(更多说明)以及在机器学习中的应用。目前我正在使用R。
sbollav你好,阅读《掌握机器学习算法》后,您将了解10种顶级算法的工作原理。
对于在R中解决预测建模问题,我建议阅读以下书籍:《R语言机器学习精通》
https://machinelearning.org.cn/machine-learning-with-r/
它不教授算法的工作原理,相反,阅读之后,您将能够自信地解决自己的机器学习问题,并使用R获得可用结果。
希望这能有所帮助。
非常感谢您的精彩帖子
您对PQSQ算法有什么了解吗?可以深入探讨一下吗?
抱歉,我没有听说过这类算法。
嘿,Jason。
我正在写关于运动分析中MLA(侧重于仪器化鞋垫)的论文,我想知道哪种MLA最有用,以及您的电子书是否包含我需要的信息(例如哪种数据需要哪种MLA),或者我是否应该继续在PubMed上寻找答案。我主要找到了C4.5、CART、朴素贝叶斯、多层感知机和支持向量机(尤其是SVM,它似乎在康复技术中最受欢迎),但我想彻底研究。毕竟我的学位就指望它了😛
您在此页面上的总结已经非常有帮助了,为此感谢您!
Cara你好,我没有直接涵盖运动分析的问题。
我建议评估一系列算法来解决这个问题,看看哪个效果最好。可以把文献中其他人尝试过的方法作为启发式方法或建议来尝试。
嗨,Jason,
这确实是一个绝妙的算法分类。
您能帮我解决以下问题吗?
我有一些规则,通过这些规则将目标变量分类为0或1。
现在我想让机器学习这些规则并预测我的目标变量。
您能建议我哪种算法最适合这样做吗?
Vicky,为什么不直接使用你的规则呢?为什么还需要其他算法?
嗨,Jason,
这些规则并不简单,需要SME(领域专家)的判断。
我想知道是否有任何可能性让机器学习这些规则。
Vicky你好,
是的,会有很多方法。通常,机器学习旨在从数据输入和输出的示例中自动学习映射/规则。
也许可以尝试这种方法,尝试几种不同的方法。您甚至可能会发现一个客观上更好的映射。
嗨 Jason
首先感谢你的解释。
我是机器学习新手,我有一个问题,所有算法都可以用于监督学习吗?以及如何知道哪种模型最适合图像分类?
谢谢你
好问题,Dina,
我们无法知道哪种算法最适合特定问题。我们必须设计实验来发现它。
请看这篇关于该主题的帖子
https://machinelearning.org.cn/a-data-driven-approach-to-machine-learning/
让我们来看看机器学习算法中的四种不同学习风格:第四种在哪里?
谢谢,已修正。
Jason,很高兴找到你的网站,这里讨论了机器学习及其算法。这令人欣慰。我正在研究自然语言处理,并打算为其添加一个机器学习算法,但你却将自然语言处理列为其他类型的机器学习算法。这令人惊讶!因为我的目标是找到最好的算法来使用。
谢谢,很高兴有你在这里。
我希望今年晚些时候能详细介绍 NLP。
Jason,如何使用机器学习、自然语言处理(NLP)或两者结合,根据之前输入的文本预测用户的下一句话?
我还没有很多NLP的例子,希望很快会有。
这可能作为一个起点有所帮助
https://machinelearning.org.cn/predict-sentiment-movie-reviews-using-deep-learning/
先生,需要对“按形式或功能相似性分组的算法”进行正式介绍。互联网上随处可见它属于监督学习风格中的聚类分类,那么它是否是学习风格的一部分呢?
我想你漏掉了像ARIMA、TBATS、Prophet等等的预测算法。
我在这里详细介绍了时间序列
https://machinelearning.org.cn/start-here/#timeseries
嗨,Jason……你创建了一个很棒的网站。
继续分享好东西。
上帝保佑你。
谢谢Deepak!
嗨,Jason,
感谢分享这些很棒的内容。我需要在图像数据库中(烟雾、云等)对非刚性物体检测选择一种机器学习算法。您对合适的算法有什么建议或如何找到它?我目前倾向于使用CNN。但仍然不确定为什么一定要用它?
非常感谢
是的,我推荐使用 CNN。
我们如何决定为特定问题使用哪种机器学习算法?
好问题,请看这篇帖子
https://machinelearning.org.cn/a-data-driven-approach-to-machine-learning/
嗨,Jason,这是很棒的材料。您对在线聚类技术有什么建议吗?
谢谢 Kumar,抱歉我没有关于聚类的材料。
我想知道“算法”是如何在“机器”上运行的?
这里,请将“机器”视为“人类”或“生物病毒”或“任何活细胞”。
我会说生物个体有一系列逻辑算法,它们调节着它们的指令和反应。这些算法我们可以称之为“遗传物质”,如“DNA或RNA”;但我想将它们视为调节所有活动(如反应和指令)的“算法”。因为特定的DNA或RNA序列具有特殊的代码,可以被不同的执行者(这里是酶)使用。
我的问题是,我们能否形成像DNA或RNA那样能够运行机器的算法?
是否有可能形成一种人造生物病毒,能够治愈人体内的感染细胞?
当然,看看受生物学启发的计算方法。
我写了一本关于这个主题的完整书籍,我的博士毕业后就写了,在线免费阅读
http://cleveralgorithms.com/nature-inspired/index.html
Jason,很棒的文章……评论区也很吸引人,这很少见。
感谢您的努力,也感谢所有其他人。评论本身与文章一样信息丰富。
谢谢Pavan。
#编辑#
“一个引人入胜的评论区,这在许多其他网站上很少见”
我努力回复我看到的每一条评论。现在每天有数百条评论,这越来越难了。
尊敬的Jason博士;
我在使用快速正交搜索(FOS)进行降维时遇到了问题。您有什么关于在MATLAB中构建它的建议吗?
谢谢
抱歉,我没有。
我有一个疑问,我们能否将受自然启发的算法与机器学习相结合,以提高数据的准确性水平?
也许吧。例如,遗传算法可以帮助调整超参数或选择特征。
我写了一本关于受自然启发算法的书,在我完成博士学业后,它可以在线免费获取
http://cleveralgorithms.com/nature-inspired/index.html
您好Jason,您能否将此页面上的所有算法都标记为监督式、无监督式或半监督式?理解这三种不同类型足够容易,但哪种是哪种呢?谢谢。
大多数应用机器学习(例如预测建模)都关注监督学习算法。
此页面上列出的大多数算法都是监督式的。
嗨,Jason,感谢您的精彩文章!我建议将机器学习算法另类分类为两组:(i)那些在相同数据集以相同顺序呈现记录进行训练时,始终产生相同模型的算法,和(ii)那些每次产生不同模型的算法。但我对您对此的看法很感兴趣。
此致,David
很棒的David。这实际上就是“模型方差”的轴。
不过,把它看作一个连续体,而不是二元的。许多(大多数!)机器学习算法都会遭受某种程度的方差。
谢谢你的回复,Jason。是的,连续的尺度会更好。几年前我曾研究过模拟退火/梯度下降、遗传算法和神经网络(它们会随机跳跃以逃离局部最小值)。然而,另一方面,规则归纳算法(如M5Rules)中的信息增益计算总是遵循相同的路径(?)这可以成为一篇文章的基础;-
感应算法,如M5Rules总是遵循相同的路径(?),这可以成为一篇文章的基础;-
谢谢你的建议,David。
干得好,但你没有包含你的主题的参考文献!!!
谢谢 Mirna,你想看什么参考文献?
是否有可能从无监督机器学习中生成一个函数?
当然,你具体指什么?
谢谢您的回复,先生。假设我收集了大量数据,例如一段时间内的温度。我想知道如何将机器学习应用于解释这些数据。这就是为什么我的想法是根据图表生成一个函数,这与机器学习仍然相关吗?
听起来你是在描述一个回归方程,比如最佳拟合线。
如果最佳拟合线对您来说足够好,那么我建议您使用它。
您可以使用一套机器学习算法进行预测,这个过程将让您了解其中涉及的内容
https://machinelearning.org.cn/start-here/#process
嗨 Jason
我用一些回归和分类估计器创建了几个有监督模型。我想知道如何使用这些模型创建数据驱动应用程序?您能解释一下这意味着什么吗?
您需要像对待任何其他软件项目一样对待它,并从定义项目目标/需求开始。
谢谢 Jason。又一次出色的工作。 🙂
一段时间以来,我一直在寻找一篇关于机器学习算法的分类学、调查和分类的权威论文,并附有示例。这篇文章绝对是朝着这个方向迈出的一步——可以将其修改成一篇分类学/调查论文吗?
尽管如此,正如其他读者所注意到的,它缺少一些主题:预处理(包括异常检测和特征选择)、自然语言处理(NLP)、遗传算法、推荐系统等。
不知道您是否了解这方面的任何学术著作。我在ACM CSUR中没有找到。
焦急等待! 🙂
感谢您的建议。
我很快会更新帖子并添加更多算法。抱歉,我没有计划将其转变为一份调查。
嗨 Jason
我正在做一个分类项目,最终分类器中有不确定的规则。
您认为在这种情况下哪种算法会更有效率?
尝试一系列算法,看看哪个在您的问题上效果最好?
如果模型将响应分类到正确的标签中,并且如果没有,用户提供了正确的标签,那么可以使用哪些算法每天使用包含用户反馈的新数据重新训练模型?我想使用此反馈重新训练模型,并在未来更加重视具有正确标签的签名。
许多算法都是可更新的。我建议测试一系列算法,看看哪个在您的问题上有效,然后选择一个可更新的。
嗨Jason,我是一名前端开发人员,但现在我想学习机器学习。您能指导我如何以最佳方式学习它吗?
我最好的建议在这里
https://machinelearning.org.cn/start-here/#getstarted
我建议您从 Weka 开始
https://machinelearning.org.cn/start-here/#weka
嗯……下载地图链接坏了……。
抱歉……言之过早……网站链接出错了,但刚刚收到了下载邮件。谢谢!
抱歉,下载没问题,但重定向到我的感谢页面出错了。我正在处理。
支持向量机(SVM),一个有监督的机器学习算法,在机器学习算法思维导图中没有明确列出。
我是否遗漏了什么?
没错。如果你愿意,可以添加。
哪种优化算法最好?遗传算法(或)ABC算法(或)支持向量机(或)粒子群优化(或)蚁群优化。请解释一下。
没有最好的算法。尝试一系列方法,看看哪种最适合您的特定样本数据和需求。
嗨Jason,分类很有用。谢谢。我想知道HMM和FST是否被认为是机器学习算法?
是的,当然。
感谢如此精彩的博客文章!
不客气,很高兴能帮到你!
Jason,真棒的工作和页面!您做得非常出色。非常感谢您的努力。
谢谢Alex!
非常感谢这次旅行,
我正在研究网络中的异常检测,您可能会建议哪种算法,
谢谢你
尝试多种算法,看看哪种最适合您的特定数据。
嗨 Jason
我能知道用Python进行机器学习有什么先决条件吗?
除了学习一些 Python 之外,没什么特别的。
您可以在这里开始学习 Python 中的机器学习
https://machinelearning.org.cn/start-here/#python
嗨,Jason,
我是编程新手,我计划使用机器学习算法来校准传感器数据与参考数据(使用Python)。您会推荐哪些算法?
谢谢!
尝试一系列方法,看看哪种最适合您的具体预测问题。
另请参阅此
https://machinelearning.org.cn/faq/single-faq/what-algorithm-config-should-i-use
感谢 Jason 分享如此精彩的文章。
假设患者服用了药物(X),并出现了五种可能的副作用(X-a、X-b、X-c、X-d、X-e)。
我需要根据一些参数(如严重性、可疑性等)找出药物与其副作用之间的信号,即因果关系。
如果参数存在,我给分数1;如果不存在,给分数0;如果不适用,给分数-1。
我应该使用哪种算法来根据分数找出最佳的药物-事件关系,或者您有什么替代方法推荐?
这个过程将帮助您系统地解决您的问题
https://machinelearning.org.cn/start-here/#process
嗨,Jason,
我目前正在学习机器学习,您展示的链接已完成50%。
我有点困惑,哪种算法适合根据少量参数找到最佳事件。
是分层聚类还是决策树,或者是您推荐的任何其他算法?
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/what-algorithm-config-should-i-use
嗨,Jason,
是否有可能将机器学习融入作业调度中的启发式或半启发式算法,以改进优化?如果可以,您能推荐一些相关材料给我吗?
也许吧。抱歉,我没有这方面的例子。
也许SVM应该归入基于实例的算法类别,但RVM应该放在哪里呢…… ;-)?
同意。
在机器学习中:什么是最先进的机器学习算法?
深度学习。
尊敬的@Jason,感谢您的及时回复,
那么深度学习中使用了哪些技术?您能告诉我列表吗?
最广泛使用的方法是MLP、CNN和LSTM。
好文章。在半监督学习下,有一个陈述:“模型必须学习结构……”。我相信你这里指的是算法……你甚至在你的常见问题中澄清了这一点,算法是从数据中学习以创建预测模型的。同意吗?
是的。
通过更详细的示例代码解释得更好
感谢您的建议,这里有一些代码示例
https://machinelearning.org.cn/start-here/#code_algorithms
我是机器学习的新手。我大学主修地球科学,只学习了两个月的Python。像我这样的学生,如何为机器学习做准备,而且机器学习有很多方向,比如计算机视觉、自然语言处理、深度学习。我们应该整体学习机器学习,还是选择一个方向学习?我明年四月毕业,如何找到一份与机器学习相关的工作。我是来自中国的学生。我的英语可能不太好。请不要介意我的错误。谢谢。
从小处着手,就从这里开始
https://machinelearning.org.cn/start-here/
嗨,Jason,
感谢您的文章,您将ReLU、GAN和RBM如何分类到这个思维导图中?如果您将逻辑回归和线性回归等激活函数放在回归部分下,那么ReLU是否也应该在那里?同样,GAN和RBM是否应该放在深度学习下?
ReLU是一个激活函数,是神经网络的一部分,本身不是一个算法。
GAN是一种无监督神经网络算法。
RBM是一种监督神经网络算法,并且是多余的,已被带ReLU的多层感知器取代。
逻辑回归和线性回归不是激活函数,它们是算法,通过最小二乘法求解。
你好,
接着这个评论,我想知道你有没有关于RBM的文章。我刚在你的一个帖子中找到了一个关于“http://videolectures.net/deeplearning2015_lee_boltzmann_machines/”的参考资料。
谢谢。
不,它们已经不再有用了
https://machinelearning.org.cn/faq/single-faq/do-you-have-examples-of-the-restricted-boltzmann-machine-rbm
也许值得一提的是,上面列表中出现的深度信念网络是由堆叠的RBM组成的。
谢谢。
学习机器学习是件好事。非计算机科学专业的人能学习这个吗?请告诉我学习方法。
是的,您可以从这里开始。
https://machinelearning.org.cn/start-here/#getstarted
我建议使用Weka,它不需要任何代码
https://machinelearning.org.cn/start-here/#weka
你好Jason,你的文章非常清晰,对每个人,尤其是对我很有帮助。我是这个领域的新手,我想知道哪种算法适合基于热像图检测和分类物体?我有一组数据,例如椅子、桌子、手机等,我想根据检测到的热像图对它们进行分类。你能给我一些建议吗?
我猜卷积神经网络 (CNN) 应该表现良好。
请提供您是否提供任何在线课程或机构以实时学习的详细信息。
没有,只有电子书
https://machinelearning.org.cn/products/
你真的把它讲得很清楚。
我相信许多在这个领域工作多年的人,都很难弄清楚自己在做什么,以及这与机器学习和人工智能的大局有什么关系。
人们也非常困惑,并认为NN或DNN就是AI的全部,而在我看来,ML(统计方法、基于NN的方法、任何数学算法公式)、生物/大脑启发算法(遗传算法、SWARM等)、密码学、认知学等都是AI的子集。有些是部分重叠的,有些是主要重叠的。
谢谢。也许你是对的。
你好,杰森,
这篇文章太棒了。但我的问题是,我如何系统地学习这些算法以通过技术面试。我希望你能理解。谢谢
抱歉,我不了解面试。
你好,杰森,
强化学习有可能用于回归吗?
可能不会,这种方法更适合于环境中的智能体。
我感觉受到了激励,现在将更加努力地开启机器学习领域的职业生涯,希望也能取得类似的成功。感谢您分享您的机器学习经验。
谢谢。很高兴您能成为ML Mastery社区的一员。
你好Jason,我对MLP是机器学习还是深度学习感到模糊?
这张图有帮助
https://machinelearning.org.cn/neural-networks-crash-course/
嗨,Jason,
你能帮我了解一下在以下情况下可以使用多少种机器学习算法吗?
1) 半监督学习。
2) 强化学习。
一般来说,我需要知道这两种情况下的算法名称。
此致
Ashish
也许从这里开始
https://en.wikipedia.org/wiki/Semi-supervised_learning
还有这里
https://en.wikipedia.org/wiki/Reinforcement_learning
Jason
有可能完全了解深度学习和机器学习算法吗?
没有人能完全了解任何一个研究领域。事实上,没有人能完全了解任何事物。
我们都只是学到足够好,能得到足够好的结果,然后继续前进。
请写关于强化学习的文章!我保证会在第一时间购买你的书
感谢您的建议和支持。
感谢更新算法。非常有用。
谢谢。
你真是我的精神导师!
谢谢!
这是一个非常有趣,但更重要的,令人愉快的帖子。
它富有启发性,写得非常好,易于阅读,读完之后,我这个新手脑海中形成了一幅路线图,这真是太棒了。
只有一件事让我有点困扰,这种倾向可能会让很多新手认为数学不重要,机器学习一点都不容易,它需要大量的数学知识,而忽视它们,只讲述了一个人过来、理解并开始编写大量代码的故事,却隐藏了她已经是一名工程师、数学家或统计学家等的事实。
无论如何,Jason,我刚刚被你折服,我会非常密切地关注你的博客,因为我相信你的文章对于我从理论物理学家转行数据科学家会非常有帮助。
谢谢你,马里奥。
总的来说,比较这些算法。我会添加HDT、Jackknife回归、密度估计、归因建模(用于优化营销组合)、链接(在欺诈检测中)、索引(用于创建分类法或用于聚类包含文本的大型数据集)、分桶和时间序列算法。
非常好,谢谢!
机器学习是目前人工智能的主要方法之一。逻辑回归、随机森林和深度学习是三种常见的机器学习方法。请解释这三种方法如何进行监督学习。
我有很多教程解释这三个,你可以在博客上搜索它们——使用搜索框。
“深度学习算法”属于哪种“学习方式”?
例如,CNN算法属于哪种学习方式?
监督学习。
您能推荐一种深度学习算法,可以学习连续(相邻)数据点之间存在的关联吗?
例如,通过识别3D坐标之间的关系来预测结构?
也许是流形学习
https://scikit-learn.cn/stable/modules/manifold.html
XGBoost算法应该属于集成算法吗?
是的!
嗨,感谢您提供如此好的信息。
不客气!
对利用机器学习开发算法的人工智能技术进行了精彩的总结和广阔的视角!感谢Jason Brownlee先生!!
谢谢!
嗨,Jason,
非常棒的总结!我有一个困惑:我可以理解kNN属于基于实例的算法,但为什么SVM也属于这一类呢?您有什么材料可以解释这一点吗?谢谢!
支持向量机(SVM)找到支持向量——特征空间中的点——用于定义类别之间的边界。例如,根据这种理解,它可能是一种基于实例的方法。
我明白了,那对我来说就清楚多了,谢谢Jason!
不客气。
嗨,Jason,
我再次阅读了你的帖子,因为我真的认为这是一种很棒的机器学习算法分类方式!在重新阅读你的帖子时,我有一个关于无监督机器学习的问题,也许你能帮助我?
你在帖子中列出的哪些算法属于无监督机器学习?聚类?原则上,对于无监督机器学习算法的模型性能评估,我们不需要将数据分为训练集和测试集,而是需要输入我们整个数据集进行训练,对吗?如果是这样,我们怎么知道是否应该使用这种无监督方法呢?
非常感谢!
好问题,这个框架将帮助你确定是否需要监督学习
https://machinelearning.org.cn/how-to-define-your-machine-learning-problem/
谢谢Jason,这篇文章帮助很大!
不客气。
这真是太棒了……
Jason,向你致敬……
除了深度学习,机器学习还有哪些子集???
深度学习是机器学习的子集对吗???那还有哪些其他的子集???请帮忙……???
是的,深度学习是机器学习的一个子集。上面列出的所有算法都与深度学习并存。
这很有帮助,谢谢!
我有个问题
我想估计一块铝板的弹性模量,输入包括密度、共振频率和板材尺寸。输出是弹性模量。
哪种算法最适合,以及在哪里可以找到优化算法?
提前感谢!
好问题,我在这里回答
https://machinelearning.org.cn/faq/single-faq/what-algorithm-config-should-i-use
先生您好,请问哪种强化学习算法最适合解决连续计算复杂度问题?
抱歉,我没有强化学习的教程,我将来可能会写这个主题
https://machinelearning.org.cn/faq/single-faq/do-you-have-tutorials-on-deep-reinforcement-learning
要从事机器学习/深度学习,有必要了解实分析和测度论吗?
不行。
编写代码/成为一名开发人员需要计算理论、类型理论或编译器理论吗?
非常感谢这篇帖子!!真的很有帮助!!
不客气。
文章写得太棒了!直击要点!没有不必要的理论。非常棒
此致,
Aashish
德国慕尼黑
谢谢!
这真是太棒了……
Jason,向你致敬……
除了深度学习,机器学习还有哪些子集???
深度学习是机器学习的子集对吗???那还有哪些其他的子集???请帮忙
谢谢。
深度学习是机器学习的一个子集
https://machinelearning.org.cn/faq/single-faq/how-are-ml-and-deep-learning-related
对于像我这样的机器学习初学者来说,真是太棒了。我正在Coursera上开始Andrew的机器学习课程。我有超过10年的编程经验,我很好奇机器学习专家在解决了一个复杂的机器学习问题后究竟会做什么?我的意思是算法已经优化,假设也预测出了正确的结果,那么专家会做什么呢?被解雇吗?🙂
最终模型是在所有数据上拟合的,可以对新案例进行预测
https://machinelearning.org.cn/train-final-machine-learning-model/
该模型会像任何软件系统一样被部署和监控。
机器学习之旅对我这样的初学者学生来说是最好的。
谢谢你
谢谢。
一个精彩的概述!
赞美
谢谢!
嗨,Jason,
您能提供一些关于实时数据的在线机器学习分类教程吗?
是的,也许可以从这里的一些例子开始
https://machinelearning.org.cn/start-here/
分享了一篇关于机器学习算法历程的精彩文章。
谢谢!
感谢您分享这份宝贵的内容。
我很喜欢。它非常有价值。
不客气!
嘿,杰森!
非常感谢这些很棒的建议。
我一定会遵守这些指示。请继续写作。
谢谢。
汉娜
不客气。
你好Jason,感谢你的精彩总结,
我是机器学习新手,正在努力理解算法的分类。
我偶然发现了这里一个类似的总结
https://www.r-bloggers.com/2019/07/101-machine-learning-algorithms-for-data-science-with-cheat-sheets/
这个列表有一个单独的组叫做
“分类算法”,你没有,他把你的多个组的算法放在那里,这是一个错误吗?他似乎混淆了“算法类型”和“问题类型”,我说的对吗?
没有最好的方法。也许你可以向作者本人询问他们对算法分组的方法。
文章解释得很好
谢谢!
我一直在阅读关于这个话题的帖子,这篇是我读过的最有趣和最有信息量的一篇。谢谢你!
谢谢。
我一直在阅读关于这个话题的帖子,而https://www.google.com/这篇文章是我读过的最有趣和信息量最大的一篇。谢谢你!
谢谢!
通过这个网站,我获得了大量信息,知道了如何衡量网站
非常感谢Jason (
不客气。
这篇帖子很旧,但非常棒,谢谢分享!
不客气!
感谢您分享关于机器学习算法的如此有价值的信息
不客气!
我喜欢这篇帖子,它很有帮助……有人能在自然语言处理研究领域/主题方面帮助我吗?
您可以从这里开始
https://machinelearning.org.cn/start-here/#nlp
时间序列预测算作机器学习模型吗?如果不是,为什么?
是的。就像回归一样。
我的同事争论说统计预测不应该与机器学习混淆,尽管没有明确的理由。所以想了解一下是否存在这种论点?
确实有这种学派。但在实践中,如果找到了适合你问题的模型,又何必在意呢?例如,线性回归,我们可以找到最小二乘误差的闭式解。我们也可以使用SGD找到解。你不能仅仅因为使用矩阵的闭式解就说它不是一个好模型。
那自监督学习呢?
谢谢,我将来可能会讲到它。
你好Jason,感谢你详细的分类。我试图找到Catboost (https://catboost.ai/) 会被归类在哪里,但没有找到。我猜它属于集成技术,对吗?
是的,集成。
您的帖子真的很有帮助。感谢您提供如此精彩的内容。
谢谢。很高兴你喜欢。
感谢分享详细的帖子。这将对我帮助很大。
感谢您告诉我关于学习算法,并感谢您分享这篇文章。
你好ulfat……非常欢迎!请告诉我们您对机器学习的哪些领域最感兴趣。
此致,
你好
我是Umer,我有一个毕业设计项目:“无线传感器网络中传感器节点的优先级分配”
在这个项目中,我需要在任何定义的区域内随机部署传感器节点,然后从这些节点获取数据。
部署完成后,传感器节点会组成一个网络,网络建立后,它们会像我一样感知数据,我希望从网络区域中获取和提取部队数量,并根据这些感知到的数据,这些节点使用机器学习算法将区域划分为4个区域(基于感知到的数据),例如,如果部队数量 > 500 = 危险区
1# 最危险
2# 危险
3# 较不危险
4# 正常
并且还要使节点高效,如果最危险区域的节点数量少于正常区域,这些节点就会从正常区域移动到危险区域,以保护网络免受数据丢失。
这就是我的项目,请大家帮忙
你好,Umer,
一般来说,我建议你独立完成家庭作业和作业。
你选择了课程,甚至(也许)支付了学费。你选择通过自学投资自己。
为了最大程度地利用这项投资,你必须努力学习。
此外,你(可能)已经付钱给老师、讲师和支持人员来教你。利用这些资源,向他们寻求关于你的作业或任务的帮助和澄清。从某种意义上说,他们为你工作,没有人比他们更了解你的作业或任务以及它将如何被评估。
尽管如此,如果你仍然感到困惑,也许你可以把你的困难归结为一句话,然后联系我。
很棒的帖子!我正准备阅读这些信息,对我很有帮助。此外,你提供的所有有价值的信息都很棒,请继续保持你的出色工作。
谢谢你的反馈和好话,Rahul!
你好,詹姆斯先生
我只是想感谢您发布这篇信息丰富的帖子。它帮了我很多忙,尤其是其他人的有益讨论。非常感谢
非常欢迎你,Ramil!我们感谢你的支持和反馈!
我认为“领域适应”应该是按相似性分组中的另一个元素。
他们试图解决的问题是匹配分布。
一个著名的算法例子是GAN。
谢谢你的反馈,Peblo!
感谢这篇富有洞察力的帖子。它非常有帮助。
我特别喜欢你按“相似性”对算法进行分组的方式。据我理解,“相似性”在这里指的是算法的底层数学/算法理论/方法;而不是算法的目标。因此,例如,线性和逻辑回归都属于回归算法,尽管前者的目标是回归,而后者的目标是分类。
这就是为什么我认为SOM(例如)属于基于实例的算法,尽管有一个用于降维的组,而降维是SOM的目标。同样地,MLP属于ANN算法,尽管有一个用于聚类的组。
我想说的是,除非我弄错了,否则聚类和降维不应该作为组排除吗?如果你同意,我很想知道你会在哪里添加k-均值和PCA。
我还想知道你会把DBSCAN放在哪里。
谢谢你
你好Omar……非常欢迎你!以下资源应该能帮你理清思路。
https://machinelearning.org.cn/calculate-principal-component-analysis-scratch-python/
这篇帖子很旧,但非常棒,谢谢分享!
非常欢迎!我们感谢您的支持和反馈!
谢谢我亲爱的朋友们!
非常欢迎你,Jason!感谢你的反馈!
不错且全面的总结
谢谢 Jason
话说,它们是如何分类的?
– 当前和爆炸式增长的生成式机器学习技术,如ChatGPT等?
– GAN生成对抗网络技术是如何分类的?
– 或者NST神经风格迁移是如何分类的?
– 或者文本到图像的类型?
– 或者图像字幕
总之,我的大问题是
ChatGPT和其他大型语言模型技术是否会让所有其他的机器学习/深度学习技术过时?或者在你看来,它们还有存在的空间吗?
非常感谢你
不错的博客,非常有用。
感谢您的反馈!