为深度学习模型选择优化算法,可能会影响在几分钟、几小时或几天内获得良好结果的差异。
Adam优化算法是随机梯度下降的一种扩展,最近在计算机视觉和自然语言处理的深度学习应用中得到了更广泛的应用。
在这篇文章中,你将获得关于在深度学习中使用Adam优化算法的入门介绍。
阅读本文后,你将了解:
- Adam算法是什么,以及使用该方法优化模型的优点。
- Adam算法如何工作,以及它与相关的AdaGrad和RMSProp方法有何不同。
- Adam算法如何配置以及常用的配置参数。
用我的新书《更好的深度学习》来启动你的项目,书中包含分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
什么是Adam优化算法?
Adam是一种优化算法,可以替代经典的随机梯度下降过程,根据训练数据迭代更新网络权重。
Adam由OpenAI的Diederik Kingma和多伦多大学的Jimmy Ba在其2015年的ICLR会议论文(海报)《Adam: A Method for Stochastic Optimization》中提出。在这篇文章中,我将大量引用他们的论文,除非另有说明。
该算法名为Adam。它不是首字母缩写,也不是写成“ADAM”。
……Adam这个名字来源于自适应矩估计(adaptive moment estimation)。
在介绍该算法时,作者们列出了在非凸优化问题中使用Adam的吸引人之处,如下所示:
- 易于实现。
- 计算效率高。
- 内存需求少。
- 对梯度的对角重缩放具有不变性。
- 非常适合数据量大和/或参数量大的问题。
- 适用于非平稳目标。
- 适用于梯度非常嘈杂/或稀疏的问题。
- 超参数具有直观的解释,通常需要很少的调整。
想要通过深度学习获得更好的结果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
Adam是如何工作的?
Adam与经典的随机梯度下降不同。
随机梯度下降为所有权重更新维护一个单一的学习率(称为alpha),并且学习率在训练过程中不改变。
为每个网络权重(参数)维护一个学习率,并随着学习的进行而单独调整。
该方法根据梯度的第一和第二矩的估计值,为不同参数计算单独的自适应学习率。
作者们将Adam描述为结合了另外两个随机梯度下降扩展的优点。具体来说:
- 自适应梯度算法(AdaGrad),它维护一个每参数学习率,在梯度稀疏的问题(例如自然语言和计算机视觉问题)上能提高性能。
- 均方根传播(RMSProp),它也维护每参数学习率,该学习率根据权重最近梯度的平均幅度(例如它改变的速度)进行调整。这意味着该算法在在线和非平稳问题(例如嘈杂)上表现良好。
Adam实现了AdaGrad和RMSProp两者的优点。
与RMSProp根据平均一阶矩(均值)来调整参数学习率不同,Adam还利用了梯度二阶矩(未中心化的方差)的平均值。
具体来说,该算法计算梯度和平方梯度的指数移动平均值,而参数beta1和beta2控制这些移动平均值的衰减率。
移动平均值和beta1、beta2值接近1.0(推荐)的初始值会导致矩估计值偏向于零。通过先计算有偏估计,然后再计算无偏估计来克服这种偏差。
这篇论文非常易读,如果你对具体的实现细节感兴趣,我鼓励你阅读它。
如果你想学习如何在Python中从头开始编写Adam代码,请参阅教程
Adam是有效的
Adam是深度学习领域中一个流行的算法,因为它能快速获得良好的结果。
实证结果表明,Adam在实践中效果良好,与其他随机优化方法相比具有优势。
在原始论文中,Adam通过实证进行了演示,以表明其收敛性符合理论分析的预期。Adam被应用于逻辑回归算法在MNIST数字识别和IMDB情感分析数据集上,以及多层感知机算法在MNIST数据集上,还有卷积神经网络在CIFAR-10图像识别数据集上。他们得出结论:
使用大型模型和数据集,我们证明Adam可以有效地解决实际的深度学习问题。
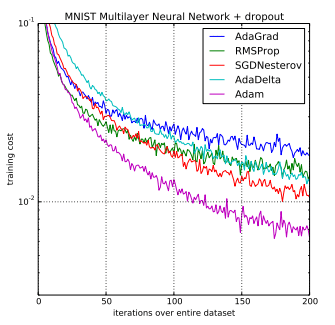
Adam与其他优化算法的比较:训练多层感知机
摘自《Adam: A Method for Stochastic Optimization》, 2015。
Sebastian Ruder撰写了一篇关于现代梯度下降优化算法的综合性综述,题为《An overview of gradient descent optimization algorithms》,最初发表为博客文章,随后在2016年作为技术报告发布。
这篇论文基本上是现代方法的概览。在其题为“选择哪个优化器?”的部分,他推荐使用Adam。
总而言之,RMSprop、Adadelta和Adam是非常相似的算法,在相似的情况下表现良好……其偏差修正有助于Adam在优化后期,随着梯度变得稀疏,略微优于RMSprop。总而言之,Adam可能是最佳的总体选择。
在斯坦福大学关于深度学习在计算机视觉领域的课程“CS231n: Convolutional Neural Networks for Visual Recognition”中,由Andrej Karpathy等人开发,Adam算法再次被推荐为深度学习应用的默认优化方法。
在实践中,Adam目前被推荐为默认使用的算法,并且通常比RMSProp效果稍好。然而,尝试SGD+Nesterov动量作为替代也是值得的。
随后更直白地说:
推荐使用的两种更新方式是SGD+Nesterov动量或Adam。
Adam正在被改编用于深度学习论文中的基准测试。
例如,它被用于关于图像字幕生成中注意力的论文“Show, Attend and Tell: Neural Image Caption Generation with Visual Attention”和关于图像生成的论文“DRAW: A Recurrent Neural Network For Image Generation”中。
你知道Adam的其他例子吗?在评论中告诉我。
Adam配置参数
- alpha。也称为学习率或步长。权重更新的比例(例如0.001)。较大的值(例如0.3)会在学习率更新前导致更快的初始学习。较小的值(例如1.0E-5)会大大减慢训练过程中的学习速度。
- beta1。一阶矩估计的指数衰减率(例如0.9)。
- beta2。二阶矩估计的指数衰减率(例如0.999)。在梯度稀疏的问题(例如NLP和计算机视觉问题)上,此值应设置为接近1.0。
- epsilon。一个非常小的数字,用于防止在实现中出现任何除以零的情况(例如10E-8)。
此外,学习率衰减也可以与Adam一起使用。论文中使用了衰减率alpha = alpha/sqrt(t),每过一个epoch(t)更新一次,用于逻辑回归演示。
Adam论文建议:
在测试的机器学习问题中,良好的默认设置是alpha=0.001,beta1=0.9,beta2=0.999,epsilon=10−8。
TensorFlow文档建议对epsilon进行一些调整:
epsilon的默认值1e-8可能不是一个好的通用默认值。例如,在ImageNet上训练Inception网络时,一个好的选择是1.0或0.1。
我们可以看到,流行的深度学习库通常使用论文推荐的默认参数。
- TensorFlow:learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08。
Keras:lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0。 - Blocks:learning_rate=0.002, beta1=0.9, beta2=0.999, epsilon=1e-08, decay_factor=1。
- Lasagne:learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08
- Caffe:learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08
- MxNet:learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-8
- Torch:learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-8
你知道Adam的其他标准配置吗?在评论中告诉我。
进一步阅读
本节列出了学习Adam优化算法的更多资源。
- Adam:一种随机优化方法, 2015.
- 随机梯度下降(维基百科)
- 梯度下降优化算法综述, 2016.
- ADAM: A Method for Stochastic Optimization(一篇评论)
- 深度网络优化(幻灯片)
- Adam: A Method for Stochastic Optimization(幻灯片)。
- 从零开始编写Adam梯度下降优化器
你知道关于Adam的其他好资源吗?在评论中告诉我。
总结
在这篇文章中,你了解了用于深度学习的Adam优化算法。
具体来说,你学到了:
- Adam是用于训练深度学习模型的随机梯度下降的替代优化算法。
- Adam结合了AdaGrad和RMSProp算法的最佳特性,提供了一种能够处理稀疏梯度和嘈杂问题的优化算法。
- Adam相对容易配置,并且默认配置参数在大多数问题上都表现良好。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。


")




这个名字有点奇怪。AdaMomE有什么问题?缩写名字只有在包含名字,即自适应矩估计时才有意义。我认为写有用论文的一部分是想出一个不会让领域内其他人感到恼火的缩写,比如任何叫Adam的人。
Adam这个名字朗朗上口。
呵呵,你的名字叫亚当。
哈哈!你为什么把它看作是针对你个人呢?嗯,你看上去像《亚当斯一家》里的一个角色。值得思考!
是的,当然了,爸爸,有什么问题吗?🙁 我喜欢你的名字,我觉得它在这个时代也很高效;)
你好,兄弟!不要否认你的名字,给有心人。
已经使用一年了,找不到任何理由使用其他东西。我对深度学习的主要问题仍然是,由于神经网络存在大量冗余的对称性,导致存在多个等效的局部最优,因此损失了大量效率。一定有一种数学方法来解决这个问题。这让我很困惑,为什么没有人做过任何事情。如果你在组合学(旅行商问题类型的问题)中做过这个,这将被视为一个糟糕的模型配方。
能看到你在这方面有什么发现会很棒。神经网络已经被一些非常聪明的人研究了很长时间。
那些聪明人可能在统计学方面很出色,但非线性非凸优化是一个非常专业的领域,其他非常聪明的人在那里表现出色。整数和组合优化也是如此:非常专业的领域。 the days of “homo universalis” are long gone。顺便说一句,虽然我印象深刻于深度学习的最新成果,但我不那么佩服这项技术。它只是一个无约束的非常大的非线性优化问题,那又怎样?而且,你不应该尝试去寻找真正的最优值,因为那百分之百会过拟合。所以,最后,我们不得不得出结论,真正的学习(泛化)与优化某个目标函数不同,基本上,我们仍然不知道“学习是什么”,但我们知道它不是“深度学习”。我有一种预感,这种(深度学习)通往“通用人工智能”的方法将会失败。
我倒是认为深度学习方法只解决了人工智能的感知部分。
但你描述的是使用过多节点的结果,你担心过拟合。
使用适当数量的节点,它们不会成为冗余逻辑的“野兽”。
但我猜很多人都忽略了该训练什么、使用什么数据以及为该任务使用最佳神经网络的问题。
我刚读了一篇文章,其中有人改进了自然语言到文本的转换,因为他考虑了这些事情,结果他不需要深度网络,而且他还能轻松地为任何语言(而非最常见的5种)进行训练。并且获得了更好的语音到文本评分。
我认为随着硬件的发展,人们常常忘记了“优雅”的高效编码,这同样适用于神经网络设计。
我常常说,最有影响力的点在于问题的设定。
你能分享一下参考文献吗?
也许“彩票假说”在这里是相关的?
@Gerrit 我也一直在思考同样的问题——是否有办法找到对称性或规范形式,从而显著减小搜索空间?除了可能加速学习之外,这种表示法也许能带来更好的迁移学习,或者给我们带来对学习的一般性洞察。深度学习的理论似乎远远落后于实践。我必须说,结果通常是惊人的,但我不满意这种几乎完全是经验性的方法。
嗨 Jason。感谢您提供的精彩教程。我已经阅读了一些,并正在将一些内容付诸实践。就像网上许多其他博客一样,我通过搜索“如何训练模型后预测数据”找到了您的博客,因为我正在尝试使用LSTM做一个个人项目。当然,我遇到了您内容丰富的好博客。
我想评论的一件事是,您提到不必获得博士学位就能成为机器学习大师,我认为这是一个有偏见的说法,完全取决于读者的目标。然而,我在网上发现的大多数博士毕业生——例如,您本人、您在这篇文章中推荐的Sebastian、Andrew Ng、Matt Mazur、Michael Nielsen、Adrian Rosebrock,以及我关注并撰写了精彩内容的一些人,都拥有博士学位。排除Siraj,他是一位现任的YouTube博主,制作了很棒的机器学习视频——他是我迄今为止见过为数不多的没有博士学位,甚至没有学士学位的人之一。我的观点和问题是……没有博士学位,您会有能力制作出您网站上所有这些内容吗?我指的不仅仅是精通AI这个主题,还有撰写精彩的深度主题、为网站创建出色的设计、为他人提供书籍,甚至编写干净的Python代码吗?
另外,关于我自己,在过去的十年里,我的职业一直在信息技术领域。我目前是一家中型企业的系统管理员,但在过去三年里,自从我上大学以来,我对编程产生了热情,这最终发展到了机器学习。我沉迷于神经网络及其反向传播,现在正沉迷于学习更多关于LSTM的知识。我一直在测试您的一个代码。虽然我仍然在预测数据方面遇到困难。如果不能预测数据,我感觉自己迷失了方向。例如,我找到的大多数文章,包括您的文章(如果我还没有在您的网站上找到答案,我很抱歉),只展示了如何训练数据和测试数据。所以,例如,我发现的是:
x= 0001 y= 0010
x= 0010 y= 0011
x[m1,,,,,,m]
y[m1,,,,,,m]
—通常我得到的输出是—
但是至今,我还没有学会如何将未知数据输入神经网络并预测下一个未知输出,例如:
如果 x== 0100,那么 ‘y’会是什么?也就是说,不向神经网络输入下一个可能的输出,而是应该根据之前学习的模式来告诉我?
如果训练集==m,测试集也==m,那么我应该能够请求结果==n。也许你可以指导我朝着正确的方向前进?
我现在是一名计算机科学学士的第一学期学生,我一直在心里想着一路攻读博士学位,也就是成为我自己机器学习领域内容的杰出作家——不仅仅是成为一个“还行”的数据科学家,尽管我离达到那个水平还很远。坦率地说,真正吸引我攻读高等学位的是,学校里学的数学很难作为爱好来掌握。而我的情况是;这是我每天的爱好。
谢谢您 Jason,现在该继续阅读您的博客了…… :-p。
创建一个像这样的网站和教育材料,与在工作中用ML交付成果是不同的。
就像开发人员与教授开发人员教学的区别一样。非常不同的技能组合。
考虑这篇关于完成模型以进行预测的文章
https://machinelearning.org.cn/train-final-machine-learning-model/
这有帮助吗?
嘿 Jason!Nadam 和 Adam 相比怎么样?
Nadam 是 Keras 中的一个优化器,它本质上是“Adam”+ Nesterov 动量。
另外,什么是 Nesterov 动量?
我们如何为特定问题找出合适的 epsilon?
非常感谢!
好问题。抱歉,我不太了解。
https://i.stack.imgur.com/wBIpz.png
希望这有帮助 :)
在这里 http://cs229.stanford.edu/proj2015/054_report.pdf 你可以找到这篇论文。
感谢分享。
感谢您的精彩文章。如果我使用Adam作为优化器,我还需要在训练过程中进行学习率调度吗?
非常感谢
不,我不这么认为。
在MNIST的特定案例中,我使用adam+学习率调度器(测试精度99.71)取得了比仅使用Adam(测试精度99.2)更好的结果。
我不确定这是否合理,因为Adam中的每个权重都有自己的学习率。
我也曾这样想过,但后来我对不同的学习率(未调度)进行了一些优化,它对收敛速度有显著影响。这有点像,因为我可以这样说:“任何(全局)学习率都会被个体学习率补偿”。这样来看:
如果你看实现,你提到的“个体学习率”(在原始论文中是
(m/sqrt(v))_i)是由梯度的幅度构成的。这与学习率完全无关!(当然,前提是前几步的梯度相同)。但不同的学习率在相同的梯度历史下会缩放所有步长,从而使alpha越大,步长就越大。想象一下:你正在优化一个线性斜率。动量被拾取,但有一个最大值,因为之前的步长具有指数级的较少影响。假设论文中的“m”趋向于1。这与“learning_rate”是无关的。这意味着,改变它会改变收敛速度(是的,在这种情况下“x”趋向于无穷大,但忘掉它……)。让我们回到一个有解决方案的问题:这意味着“learning_rate”会在开始时限制最大的收敛速度。但在接近解决方案时,一个大的学习率会增加实际的步长(尽管m/sqrt(v)很小),这仍然可能导致过冲。当然不会像没有自动适应那样大。
我使用了OperatorDiscretizationLibrary (ODL: https://github.com/odlgroup/odl),它具有与原始论文(或Tensorflow)中提到的相同的默认参数。
感谢分享。
作为一名潜在的作者,很可能会建议一位名叫Adam的先生作为可能的审稿人,我拒绝作者的“Adam”拼写,而使用ADAM,我称之为“通过平均矩衰减的算法”(Algorithm to Decay by Average Moments),它使用了原作者“衰减”(decay)一词来表示Tensorflow称之为“损失”(loss)的。
这里的方差似乎不正确。我不是说不正确,而是说它似乎不能真正地代表方差;方差不应该也考虑到均值吗?
这里看起来方差在整个训练过程中都会持续增长。我们不希望方差在遇到变化很小的超曲面时缩小,而在遇到不稳定的超曲面时增加方差吗?
H2o深度学习包使用ADADELTA作为默认自适应学习率。
它有rho、epsilon和rate参数。
rho:指定自适应学习率时间衰减因子。此参数
类似于动量,并与先前权重更新的记忆相关。
典型值在0.9到0.999之间。默认值为0.99。有关
自适应学习的更多详细信息,请参阅。
epsilon:启用时,指定自适应学习率的两个超参数中的第二个。
此参数类似于初始训练期间的学习率退火
以及后期阶段的动量,因为它有助于进步。
典型值在1e-10到1e-4之间。此参数仅在
自适应学习率启用时才有效。默认值为1e-8。有关
自适应学习的更多详细信息,请参阅。
rate:指定学习率。较高的值导致模型不稳定,
而较低的值会导致收敛缓慢。默认值为0.005。
我们可以将rho映射到beta2,将rate映射到alpha吗?
这些参数如何影响自适应学习率?(成正比还是反比?)
好问题,我一时不确定,也许可以稍微尝试一下?
每次我尝试理解某个机器学习主题时,很高兴找到这个博客。我可以获得如此简洁有用的信息,这让我恢复了对人类的信心。谢谢!
谢谢Daniel,我很乐意帮忙。
你写道:“在梯度稀疏的问题上,应将其设置为接近1.0”。“稀疏梯度”的定义是什么?
具有大量零值的梯度,例如平坦区域。
“与RMSProp根据平均一阶矩(均值)来调整参数学习率不同,Adam还利用了梯度二阶矩(未中心化的方差)的平均值。”
这不应该是
“与RMSProp根据平均二阶矩(未中心化的方差)来调整参数学习率不同,Adam还利用了梯度一阶矩(均值)的平均值。”
我认为RMSprop使用的是二阶矩,还是我弄混了?
你为什么要这么说呢?
我不记得具体细节了。
由于RMSprop使用平方梯度来更新学习率,这与二阶矩有关,据我所知。
(例如,参见https://en.wikipedia.org/wiki/Stochastic_gradient_descent#RMSProp的方程)。
我期待在这个页面的开头看到一些壁纸:)
那张壁纸很重要。看起来你忘了把它放在这里。
你什么意思?
嗨,Jason,
感谢这篇精彩的文章,它帮助了我很多:)
供您参考,我正在使用Keras和Python 2.7,默认epsilon设置为1e-7而不是1e-8(我知道我很挑剔)。
此外,还有一个“decay”参数,我不太理解。您知道如何设置它吗?(默认是None…如果这有帮助的话)
再次感谢!
弗洛里安
谢谢。
抱歉,我对衰减参数没有好的建议。也许论文中提到了衰减,可以提供一些想法?
不,不幸的是。它没有。
如果这对某人有帮助,我研究了代码,发现“decay”参数允许“learning_rate”参数消失。当前的衰减值计算为1 / (1 + decay*iteration)。然后,当前学习率简单地乘以这个当前衰减值。
结果是,步长越来越小以收敛。
弗洛里安
学习率衰减。
谢谢你付出的巨大努力
我有一个问题,请关于优化器.adam的衰减,例如
optimizer.adam(lr=0.01, decay=1e-6) 这里的衰减是指权重衰减,也用作正则化吗?!
先谢谢了
嗨,Jason,
您能否像为随机梯度下降一样,也提供一个 ADAM 在 Python 中的实现(最好是自制的)?这将有助于初学者理解 ADAM 优化。
感谢您提供的精彩摘要。
感谢您的建议。
Python 使用优化器 = Adam
https://github.com/llSourcell/How_to_simulate_a_self_driving_car/blob/master/model.py
感谢分享。
我的理解对吗:在反向传播训练期间,我的激活函数的梯度是通过Adam或Adaelta等进行优化的,而随机梯度下降也是像Adam或Adaelta这样的方法,或者这如何影响反向传播?
权重通过一种称为随机梯度下降的算法进行优化。
一种有效的梯度下降版本是Adam。
权重更新是通过一种称为“误差反向传播”或简称反向传播的方法执行的。
你好,据我所知,Adam优化器也负责更新权重。它可能会使用一种像反向传播的方法来实现。
Adam用于“使用电子健康记录进行可扩展和准确的深度学习”,在此处描述:https://ai.googleblog.com/2018/03/making-healthcare-data-work-better-with.html。然而,对Adam的引用是在论文的补充材料中,https://static-content.springer.com/esm/art%3A10.1038%2Fs41746-018-0029-1/MediaObjects/41746_2018_29_MOESM1_ESM.pdf
感谢分享。
Adam也用于Codevilla、Müller、Lopez等人的“End-to-end driving via Conditional Imitation Learning” https://arxiv.org/pdf/1710.02410.pdf
谢谢。
嗨 Jason,感谢这篇文章!
我有个部分没弄懂。
你说:“为每个网络权重(参数)维护一个学习率,并随着学习的进行而单独调整。”
论文说:“该方法根据梯度的第一和第二矩的估计值,为不同参数计算单独的自适应学习率。”
我不确定我是否真正理解它:算法基本上为每个权重计算一个特定的学习率,所以如果我们有一个拥有2.55亿个参数的网络,它会计算2.55亿个学习率吗?
但这是如何可能的?我们有 alpha,这就是学习率……
查看论文中的伪代码,我猜测它可能是这样工作的:它使用学习率alpha作为静态值,乘以(mt/(vt + e)),这在实践中会为算法的特定迭代生成一个新的学习率,但我不确定。
我完全不理解这一部分:“并随着学习的进行而单独调整。”
你能更清楚地解释一下吗?
谢谢!
很抱歉造成困惑。
我强调的是,确实,为每个参数维护一个单独的学习率,并且每个学习率根据在该点流过网络的特定梯度进行调整——例如,与该权重相关,即学习率是单独调整的。
这是基于我对论文的阅读。
这有帮助吗?
也许,我将尝试解释我的想法
基本上,我们有一个学习率 alpha(我们手动设置),然后我们有另一个学习率 alpha2 在算法内部,当权重更新时,它会考虑我们的学习率 alpha(固定)以及为这个特定迭代计算的学习率(alpha2)。
下一个迭代,我们有我们的固定学习率 alpha,但之前的学习率 alpha2 将被更新为另一个值,所以我们丢失了 alpha2 的先前值。
这是一个正确的解释吗?
顺便说一句,在寻找“alpha2”时,我注意到伪代码(https://arxiv.org/pdf/1412.6980.pdf,第2页)唯一让我想到 alpha2 是 mt/(root(vt) – epsilon),否则我不知道它可能是什么。
我使用Keras为回归问题构建了一个经典的BP ANN,它有两个隐藏层,神经元数量很少(每个层最多8个)。我使用的优化器是ADAM。用于训练和验证的样本量为20000,分别分为90%和10%。
这些图有什么问题吗?
https://i.imgur.com/wrP18WR.jpg
在VAL_LOSS开始时出现这种下降是正常的吗?批次大小太小(目前是128)?是否存在过拟合/欠拟合?
干得好。
我有一些关于解释学习曲线的建议
https://machinelearning.org.cn/learning-curves-for-diagnosing-machine-learning-model-performance/
感谢链接。您能评论一下我的图吗?这是一个好的学习曲线吗?学习率太快(默认)?
看起来收敛很快。也许尝试减慢学习率,看看它对最终结果有什么影响?
嗨,Jason,
感谢对 Adam 的介绍。它非常有帮助且易于理解。
我目前正在使用 MATLAB 神经网络工具来分类光谱。您知道
(i)MATLAB 是否为使用 Adam 进行分类生成模板?
(ii)在使用基于 Adam 的系统对光谱进行分类时,是否有任何首选的起始参数(alpha、beta 1、beta 2)?
抱歉,我没有 MATLAB 的例子。
是的,有一些合理的 Adam 默认值,它们在 Keras 中设置。
https://keras.org.cn/optimizers/
嗨,Jason,
我希望你能对一些优化器进行比较,例如 SGD、Adam 和 AdaBound,使用不同的批次大小、学习率、动量等。
目前我正在为这三者进行网格搜索。我将 AdaBound 用于 Keras
https://github.com/titu1994/keras-adabound
干得不错。
你好 Jason,由于 Adam 除以 √v,哪些模型参数会获得更大的更新?这可能如何帮助学习?
澄清一下,为什么在更新学习参数时,一阶矩要除以二阶矩的平方根?
嗨 Jason,感谢您一如既往的精彩文章。简短的问题是,如果 Adam 会自己调整学习率,那么初始学习率的设置有什么区别?似乎每个参数的个体学习率甚至没有上限为1,所以无论如何它都不应该有什么大的影响,对吧?感谢您的回答。
好问题,起点在优化问题中很重要。
嗨,Jason,
感谢您的帖子。我有一些基本问题让我很困惑。
1)对于Adam,我们的损失函数是什么?它将是(1/N)(交叉熵)还是仅仅交叉熵,如果N是批次大小。
2)我遵循了这篇文章,作者使用了批次大小,但在更新参数时,他没有使用参数的平均值,也没有使用总和。也许我没有完全理解。你能帮帮我吗。
3)Adam在较大的批次大小下效果好吗?
Adam可以与你喜欢的任何损失函数一起使用。
Adam可以与你喜欢的任何批次大小一起使用。
Adam只是优化过程,是一种具有自适应学习率的随机梯度下降。
我忘了再问一个问题。在Adam优化过程中,我们需要衰减lambda(权重的惩罚项)和学习率吗?
你可以尝试使用 Adam,可以带或不带权重惩罚。
你好 Jason
请告诉我如何在 Python 中添加“Adam 版随机梯度下降”
在 Keras 中,您将优化器指定为 'adam',这里有一个示例
https://machinelearning.org.cn/tutorial-first-neural-network-python-keras/
你好先生,
祝您有美好的一天!
目前我在我的 CNN 模型中使用 adam 进行图像分类。
我能否在 CNN 中自定义 adam 或使用某些特征/数据作为优化器?是否可能或不可能?
请帮忙。
我不确定我的意思,你具体指的是什么?
Adam只是一个优化算法。它不使用特征。
先生,实际上我计算了我 CNN 模型中的特征相关性损失,并想将其用作优化器以提高模型精度。所以这是否可能?
一无所知,也许试试看?
嗨,Jason,
Beta1、Beta2和epsilon的超参数调整的合理范围是什么?
非常感谢您分享的所有精彩内容!
很好的问题。
学习率(lrate)可能以对数尺度进行调整。
beta1 可能以 0.1 为增量,在 0.5 到 0.9 之间。
beta2 可能以 0.01 为增量,在 0.90 到 0.99 之间?
eps – 无。
学习率(Lrate)是最有影响力的——这只是我的猜测。
在句子“Adam优化算法是随机梯度下降的扩展”中,“随机梯度下降”应该是“mini-batch梯度下降”,对吗?
不完全是。Mini-batch/batch梯度下降只是随机梯度下降的配置。
dragonfly优化器可以在Keras编译器上使用吗?
我的意思是 model.compile(loss=’binary_crossentropy’,optimizer=’adam’,metrics=[‘accuracy’])
使用这一行(optimizer=’adam’)。
什么是“dragonfly优化器”?
Dragonfly是一个开源的Python库,用于可扩展的贝叶斯优化。
贝叶斯优化用于优化黑盒函数,其评估通常成本高昂。除了普通的优化技术外,Dragonfly还提供了一系列工具,可将贝叶斯优化扩展到昂贵的、大规模的问题。这些工具包括特别适用于高维优化(优化大量变量)、同步或异步并行评估(并行执行多个评估)、多保真度优化(使用廉价的近似值来加速优化过程)以及多目标优化(同时优化多个函数)的功能。
https://github.com/dragonfly/dragonfly
https://dragonfly-opt.readthedocs.io/en/master/getting_started_py/
感谢分享!
这是否可能
不,不直接。您需要自己集成,而且我预计它不会表现得很好。
你好 Jason,
说Adam只优化“学习率”公平吗?如果不是,您能否简要说明除了学习率本身之外,它还触及了哪些其他领域?
它旨在优化优化过程本身。
嗨 Jason,对复杂主题的清晰阐述
您提到“与RMSProp根据平均一阶矩(均值)来调整参数学习率不同,Adam还利用了梯度二阶矩(未中心化的方差)的平均值”。
我相信RMSProp是那个“利用了梯度二阶矩(未中心化的方差)的平均值”。
我这样做对吗?
谢谢。
查看方差计数平衡的替代方案。
https://www.worldscientific.com/doi/abs/10.1142/S0218213020500104
感谢分享。
“再次,根据问题的具体情况,可以将列分成X和Y分量,这可以任意选择,例如,如果var1的当前观测值也作为输入提供,而只有var2需要被预测。”
在我们要预测var2(t)并且var1(t)也可用时。
var1(t-2),var2(t-2),var1(t-1) ,var2(t-1),var1(t),var2(t)
LSTM网络需要3D输入。我们应该为train_X提供什么形状?
我是否必须提供形状[X,1,5]?
如果我们有一个偶数train_X(当我们没有var1(t)时),我们就必须这样塑形,
[X,2,2]
但现在它不是偶数,我不能这样塑形,因为我们有5个特征用于train_X
唯一的解决方案是提供形状[X,1,5]吗?
*X为数据集长度
请忽略这条评论,我发错了文章。
好问题,请看这个
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
我喜欢你解释事物的方式——它非常专注、简短且精确。
继续做,谢谢。
谢谢!
模型大小与不同的优化器相比有巨大差异,对吗?Adam训练的模型比SGD模型大得多。Adam模型比SGD模型更好,除了模型大小问题。我想知道你对此问题有什么建议。
模型的大小在不同的优化器下不会改变。
优化器的作用是使用固定的训练数据集在一个固定大小的模型中找到一组参数(权重)。
Adam需要学习率衰减吗?
是也不是,它会自动为每个参数调整学习率,并且这种自动调整的一部分涉及一些动量衰减。
谢谢。您真是我解答了所有问题的老师。
不客气,我很高兴听到这个消息。
如果我想为我的深度学习模型选择最佳优化器(从ADAM、Sgdm等中选择),我该如何比较它们之间的性能?是否有任何建议可以比较它们,通过图表、数值等?
而且,我应该先选择学习率还是优化器?
实际上,我该如何为模型选择最佳学习率和最佳优化器,先选择谁,以及如何选择??
也许可以逐一测试每种优化器,并尝试多种配置,看看哪种能带来最佳性能的模型。
先运行一次Adam,然后运行SGD并对其进行调整,看看它是否能做得更好,这可能更具成本效益。
你好!你的书《Better Deep Learning》中是否涵盖了Adam?如果没有,你是否在你的另一本书中涵盖了它?
不,还没有。我希望将来能有一本专门关于“优化”的书。
谢谢。非常好的文章。
谢谢。
您的文章一如既往地清晰地阐述了主题。存在一些小小的拼写错误。
“Adam是一种优化算法,可以代替经典的随机梯度下降过程,通过训练数据迭代地更新网络权重。”
您是指“iterativeLY based ON training data”(基于训练数据迭代地)吗?
谢谢。
您的文章一如既往地清晰地阐述了主题。存在一些小小的拼写错误。
“Adam是一种优化算法,可以代替经典的随机梯度下降过程,通过训练数据迭代地更新网络权重。”
您是指“iterativeLY based ON training data”(基于训练数据迭代地)吗?
“Adam与经典的随机梯度下降不同。”
我猜您是指“FROM classical…”(不同于经典…)?
“为每个网络权重(参数)维护一个学习率,并随着学习的进行进行单独调整。”——建议添加“使用Adam,一个学习率…”
“updted each epoch”(每个epoch更新)->“updated”(更新)
谢谢。
尊敬的Jason Brownlee先生
感谢您提供精彩的内容。
我有一个问题,正如原始论文所述,每个权重都有自己的学习率,但我使用Adam + 学习率调度器(ReduceLROnPlateau)得到了更好的结果。
您可以在此处查看:https://imgur.com/a/P2mkQWy
理论上没有材料可以证明这一点,您能解释一下可能的原因吗?
谢谢你。
你好Shah……我建议你研究一下以下资源中提供的例子
https://machinelearning.org.cn/optimization-for-machine-learning/
嗨,Jason,
感谢您提供精彩的文章。
我想告诉您,我正在使用学习调度器(Adam配合ReduceLROnPlateau)。我清楚地看到,它确实影响了模型的性能。您可以通过访问以下链接进行查看。
https://imgur.com/a/P2mkQWy
您能解释一下背后的逻辑吗?
我将非常感谢您
此致,
你好Zuheer,
我可以更好地协助您解决关于我们材料中提出的概念的具体问题。
此致,
好的,明白了。
非常感谢。
“Sebastian Ruder开发了一篇题为《梯度下降优化算法概述》的关于现代梯度下降优化算法的全面综述,最初发表为博客文章,然后于2016年发表为技术报告。”
-> 博客文章的链接不起作用。这是正确的链接吗?
https://ruder.io/optimizing-gradient-descent/