
使用 Pandas 的 ColumnTransformer 和 NumPy 数组的 Scikit-Learn Pipelines 进行高级特征工程
图片由编辑提供
Pandas、NumPy 和 Scikit-learn。这个强大的组合在各种数据处理过程中都表现出色,包括特征工程。这三个库分别有助于构建健壮、可扩展和模块化的高级特征工程工作流。本文将说明如何做到这一点。
所需原料
在我们开始动手操作之前,先介绍一下我们将用于构建高级特征工程流水线的关键原料。
- Scikit-learn Pipelines:一种便捷的机制,用于定义一系列操作(通常是转换,但也可能包括机器学习建模)以应用于数据集。Pipelines 的诀窍在于将一系列操作封装为单个对象。
- Pandas ColumnTransformer 是一个类,旨在自定义应用于我们选择的数据集中特定列的转换类型。
- NumPy 数组是我们目标问题中的点睛之笔,它们有助于高效处理大量数据,并且是 scikit-learn 模型最终需要的内部数据格式(而不是 Pandas
DataFrame对象)。
食谱
现在我们熟悉了今天特征工程食谱中的原料,是时候开始烹饪了,但首先要准备好必要的工具,即需要导入的 Python 库和模块。
|
1 2 3 4 5 6 |
import numpy as np import pandas as pd from sklearn.pipeline import Pipeline from sklearn.compose import ColumnTransformer from sklearn.preprocessing import StandardScaler, OneHotEncoder from sklearn.ensemble import RandomForestClassifier |
还有一件事:既然我们希望您在此操作指南中保持富有创造性的心情,何不创建您自己的自定义数据集来演示此管道驱动的特征工程过程呢?
|
1 2 3 4 5 6 7 |
df = pd.DataFrame({ 'age': np.random.randint(18, 70, size=20), 'income': np.random.randint(30000, 120000, size=20), 'gender': np.random.choice(['male', 'female'], size=20), 'city': np.random.choice(['NY', 'SF', 'LA'], size=20), 'label': np.random.choice([0, 1], size=20) }) |
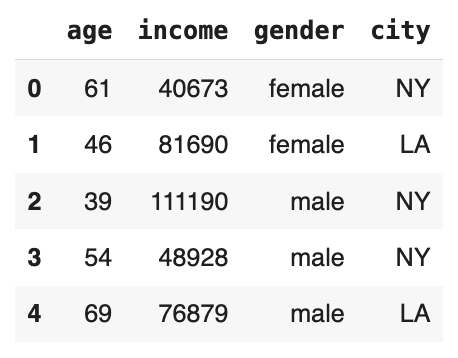
上面的代码创建了一个小型数据集,其中包含 size=20 个公民数据实例,这些实例具有随机生成的值和类别,具体取决于属性类型。具体来说,每个公民由两个数值特征(年龄和收入)、两个分类属性(性别和城市)以及一个二进制目标标签(在此示例中没有特定语义,例如,可以将其解释为该公民是否会投票给某个特定政党)来描述。
在开始特征工程管道之前,我们将标签与其余特征分开,并定义两个 Python 列表,分别包含数值特征和分类特征的名称。这些列表将在使用 ColumnTransformer 应用定制的数据转换(因特征而异)时发挥关键作用。
|
1 2 3 4 5 |
X = df.drop('label', axis=1) y = df['label'] numeric_features = ['age', 'income'] categorical_features = ['gender', 'city'] |
这就是特征的样子。
接下来,我们定义预处理步骤,即两个并行管道(每个管道对应前面确定的属性子集),并通过一个列转换器将它们连接起来。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
numeric_transformer = Pipeline(steps=[ ('scaler', StandardScaler()) ]) categorical_transformer = Pipeline(steps=[ ('encoder', OneHotEncoder(handle_unknown='ignore')) ]) # 两个“原子”管道被组合起来 preprocessor = ColumnTransformer( transformers=[ ('num', numeric_transformer, numeric_features), ('cat', categorical_transformer, categorical_features) ] ) |
请注意,每个管道中的 steps 列表可能包含一个或多个要按顺序应用于管道的过程阶段。在这种情况下,两个管道都是单阶段的——一个应用标准化,另一个应用独热编码——但稍后,我们将定义一个具有多个顺序阶段的总体管道。
同时,ColumnTransformer 对象是我们通过其 transformers 属性将两个管道组合在一起的地方,以便管道并行应用。只需在此指定哪些特征将由两个管道中的每个管道目标:这就是先前定义的两个属性名称列表派上用场的地方。
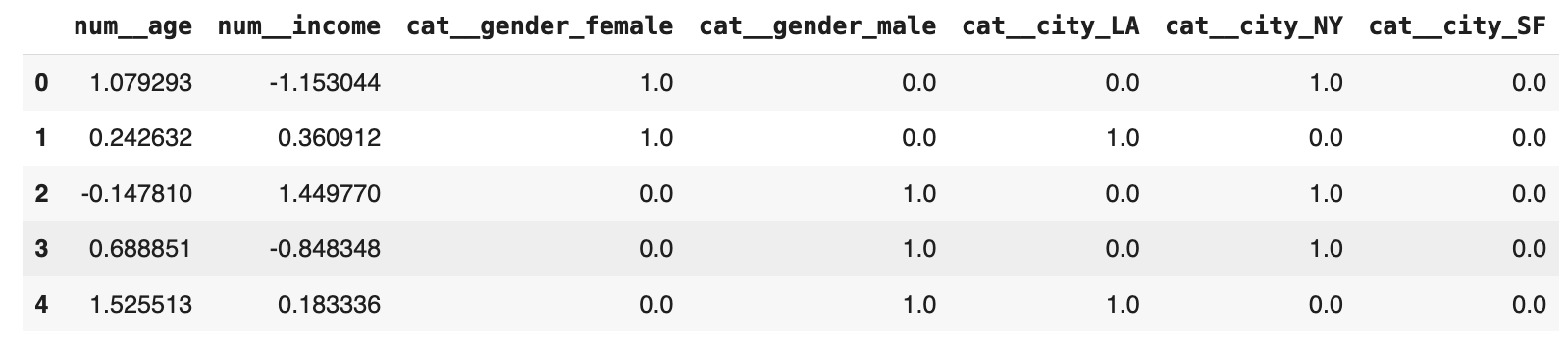
此时,我们可以试用我们刚刚定义的组合特征工程管道,并查看转换后的数据外观(结果 NumPy 数组映射到一个 DataFrame 以获得更炫酷的可视化)。
|
1 2 3 4 5 6 |
X_preprocessed = preprocessor.fit_transform(X) preprocessed_feature_names = preprocessor.get_feature_names_out() X_preprocessed_df = pd.DataFrame(X_preprocessed, columns=preprocessed_feature_names) print("预处理后的数据:") X_preprocessed_df.head() |
在最后定稿之前,我将向您展示如何将我们创建的特征工程管道(名为 preprocessor)与机器学习分类模型(例如随机森林)的构建结合起来,形成一个总体管道,这次它包含两个步骤:特征工程和机器学习建模。
|
1 2 3 4 5 6 7 8 9 |
feng_pipeline = Pipeline(steps=[ ('preprocessing', preprocessor), ('classifier', RandomForestClassifier()) ]) feng_pipeline.fit(X, y) predictions = feng_pipeline.predict(X) print(predictions) |
由于预处理后使用了 NumPy 数组,管道可以直接将这些数据结构传递给随机森林进行训练,而无需进行任何数据结构修改。
总结
本文展示了如何使用 Scikit-learn 的 Pipeline 和 Pandas 的 ColumnTransformer 对象,以及 NumPy 数组,来对包含各种不同类型特征的数据集执行高级且定制化的特征工程过程。






暂无评论。