异常检测是寻找偏离常态的数据点。换句话说,它们是不遵循预期模式的点。异常值和例外是用来描述不寻常数据的术语。异常检测在各个领域都很重要,因为它能提供有价值且可操作的见解。例如,核磁共振成像扫描中的异常可能表示大脑中的肿瘤区域,而制造工厂传感器中的异常读数可能表示组件损坏。
完成本教程后,您将能够
- 定义并理解异常检测。
- 实现异常检测算法来分析和解释结果。
- 发现任何数据中可能导致异常行为的隐藏模式。
让我们开始吧。

使用孤立森林和核密度估计进行异常检测
照片由 Katherine Chase 提供。部分权利保留。
什么是异常检测?
异常值只是一个数据点,它与特定数据集中的其他数据点显著不同。同样,异常检测是帮助我们识别数据异常值或与其他数据点相比显著偏离的点。
对于大型数据集,可能包含人眼无法通过简单观察数据来检测的复杂模式。因此,为了实现关键的机器学习应用,异常检测的研究具有重大意义。
异常类型
在数据科学领域,我们有三种不同的方法来对异常进行分类。正确理解它们可能会对您如何处理异常产生重大影响。
- 点异常或全局异常:全局异常是与其余数据点显著不同的数据点,是已知最常见的异常形式。通常,全局异常会出现在远离任何数据分布的均值或中位数的地方。
- 上下文异常或条件异常:这些异常的值与同一上下文中的其他数据点的值存在显著差异。一个数据集中的异常在另一个数据集中可能不是异常。
- 集体异常:由于具有相同的异常特征而紧密聚集的异常对象被称为集体异常。例如,您的服务器并非每天都遭受网络攻击,因此,这将被视为异常。
虽然有许多用于异常检测的技术,但让我们实现其中一些来理解如何将它们用于各种用例。
孤立森林
与随机森林类似,Isolation Forests 是使用决策树构建的。它们以无监督的方式实现,因为没有预定义的标签。Isolation Forests 的设计理念是,异常值是数据集中“稀少且独特”的数据点。
回想一下,决策树是使用基尼指数或熵等信息标准构建的。明显不同的组在树的根部被分离,并在分支的深处识别出更细微的区别。基于随机选择的特征,Isolation Forest 以树状结构处理随机抽样的数据。那些进入树更深处并需要更多分割才能区分的样本是异常值的概率非常小。同样,那些位于树较短分支上的样本更有可能是异常值,因为树更容易将它们与其他数据区分开。
在本节中,我们将使用 Python 实现 Isolation Forest,以了解它是如何检测数据集中异常值的。我们都知道惊人的 scikit-learn API 提供了各种 API 以方便实现。因此,我们将使用它来应用 Isolation Forests 以展示其在异常检测方面的有效性。
首先,让我们加载必要的库和包。
|
1 2 3 4 |
from sklearn.datasets import make_blobs from numpy import quantile, random, where from sklearn.ensemble import IsolationForest import matplotlib.pyplot as plt |
数据准备
我们将使用 make_blob() 函数来创建具有随机数据点的 the dataset。
|
1 2 |
random.seed(3) X, _ = make_blobs(n_samples=300, centers=1, cluster_std=.3, center_box=(20, 5)) |
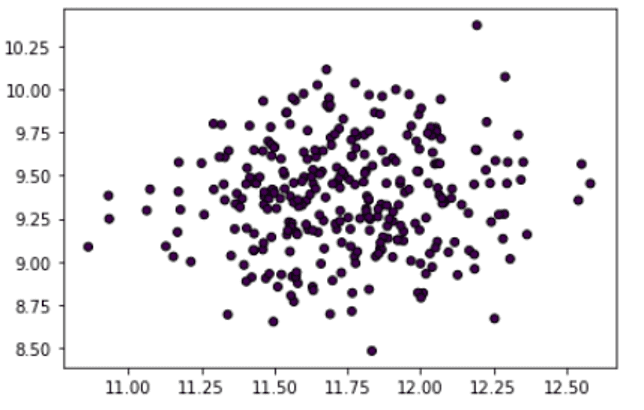
让我们可视化数据集图,看看数据点在样本空间中随机分布。
|
1 |
plt.scatter(X[:, 0], X[:, 1], marker="o", c=_, s=25, edgecolor="k") |
定义和拟合 Isolation Forest 模型进行预测
如前所述,我们将使用 scikit-learn API 中的 IsolationForest 类来定义我们的模型。在类参数中,我们将设置估计器数量和异常值比例。然后,我们将使用 fit_predict() 函数通过将数据集拟合到模型来获取预测结果。
|
1 2 |
IF = IsolationForest(n_estimators=100, contamination=.03) predictions = IF.fit_predict(X) |
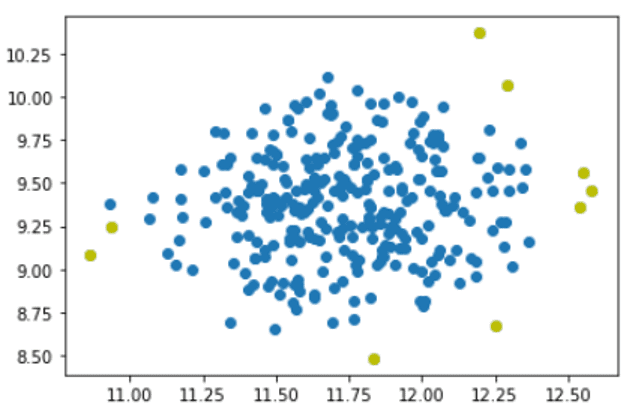
现在,让我们提取负值作为异常值,并用突出显示的异常值的颜色来绘制结果。
|
1 2 3 4 5 6 |
outlier_index = where(predictions==-1) values = X[outlier_index] plt.scatter(X[:,0], X[:,1]) plt.scatter(values[:,0], values[:,1], color='y') plt.show() |
将所有这些放在一起,下面是完整的代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
from sklearn.datasets import make_blobs from numpy import quantile, random, where from sklearn.ensemble import IsolationForest import matplotlib.pyplot as plt random.seed(3) X, _ = make_blobs(n_samples=300, centers=1, cluster_std=.3, center_box=(20, 5)) plt.scatter(X[:, 0], X[:, 1], marker="o", c=_, s=25, edgecolor="k") IF = IsolationForest(n_estimators=100, contamination=.03) predictions = IF.fit_predict(X) outlier_index = where(predictions==-1) values = X[outlier_index] plt.scatter(X[:,0], X[:,1]) plt.scatter(values[:,0], values[:,1], color='y') plt.show() |
核密度估计
如果我们认为数据集的常态符合某种概率分布,那么异常值就是我们应该很少看到或概率非常低的值。核密度估计是一种在样本空间中随机估计数据点概率密度函数的技术。利用密度函数,我们可以检测数据集中的异常值。
为了实现这一点,我们将准备数据,创建一个均匀分布,然后应用 scikit-learn 库中的 KernelDensity 类来检测异常值。
首先,我们将加载必要的库和包。
|
1 2 3 4 5 |
from sklearn.neighbors import KernelDensity from numpy import where, random, array, quantile from sklearn.preprocessing import scale import matplotlib.pyplot as plt from sklearn.datasets import load_boston |
准备和绘制数据
让我们编写一个简单的函数来准备数据集。将使用随机生成的数据作为目标数据集。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
random.seed(135) def prepData(N): X = [] for i in range(n): A = i/1000 + random.uniform(-4, 3) R = random.uniform(-5, 10) if(R >= 8.6): R = R + 10 elif(R < (-4.6)): R = R +(-9) X.append([A + R]) return array(X) n = 500 X = prepData(n) |
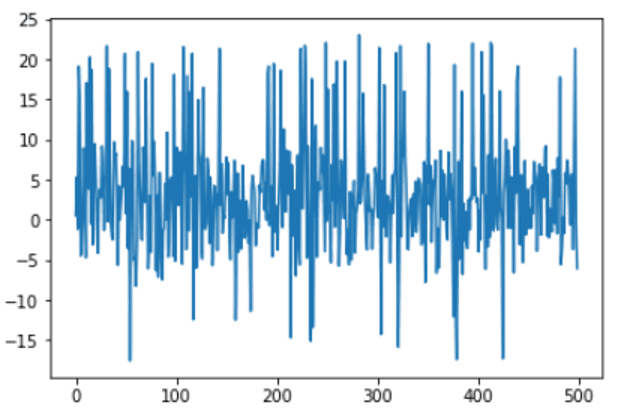
让我们可视化图表以检查数据集。
|
1 2 3 |
x_ax = range(n) plt.plot(x_ax, X) plt.show() |
准备和拟合核密度函数进行预测
我们将使用 scikit-learn API 来准备和拟合模型。然后使用 score_sample() 函数获取数据集中的样本分数。接下来,我们将使用 quantile() 函数获取阈值。
|
1 2 3 4 5 6 |
kern_dens = KernelDensity() kern_dens.fit(X) scores = kern_dens.score_samples(X) threshold = quantile(scores, .02) print(threshold) |
|
1 |
-5.676136054971186 |
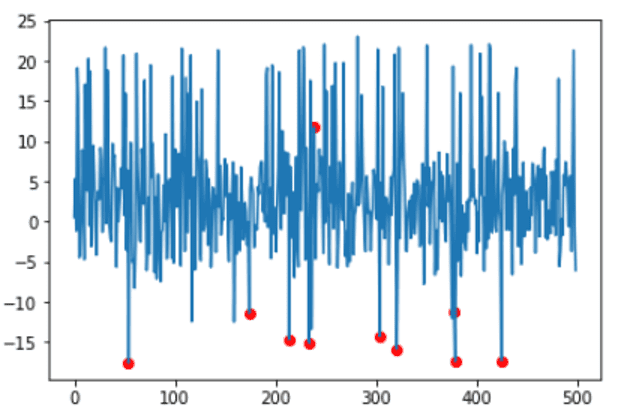
分数等于或低于所得阈值的样本将被检测出来,然后以突出显示的异常值的颜色进行可视化
|
1 2 3 4 5 6 |
idx = where(scores <= threshold) values = X[idx] plt.plot(x_ax, X) plt.scatter(idx,values, color='r') plt.show() |
将所有这些放在一起,下面是完整的代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
from sklearn.neighbors import KernelDensity from numpy import where, random, array, quantile from sklearn.preprocessing import scale import matplotlib.pyplot as plt from sklearn.datasets import load_boston random.seed(135) def prepData(N): X = [] for i in range(n): A = i/1000 + random.uniform(-4, 3) R = random.uniform(-5, 10) if(R >= 8.6): R = R + 10 elif(R < (-4.6)): R = R +(-9) X.append([A + R]) return array(X) n = 500 X = prepData(n) x_ax = range(n) plt.plot(x_ax, X) plt.show() kern_dens = KernelDensity() kern_dens.fit(X) scores = kern_dens.score_samples(X) threshold = quantile(scores, .02) print(threshold) idx = where(scores <= threshold) values = X[idx] plt.plot(x_ax, X) plt.scatter(idx,values, color='r') plt.show() |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
API
总结
在本教程中,您了解了如何检测数据集中的异常值。
具体来说,你学到了:
- 如何定义异常值及其不同类型
- 什么是 Isolation Forest 以及如何使用它进行异常检测
- 什么是核密度估计以及如何使用它进行异常检测







我有一些问题,你能给我你的电子邮件地址吗?
你好 5cc…是的。
使用联系表单。
它会直接进入我的收件箱。
我通常每天批量处理一次或两次电子邮件。这意味着我可能需要 12 到 24 小时才能回复。
我每天通常会收到数百封电子邮件,所以请保持简短。不要发送长篇大论、代码转储或冗长的问题列表。请每封电子邮件只问一个问题。
为什么 (230,12) 会有一个红点?
核密度估计不应该只标记那些根据底层分布“不太可能”的点吗?因此,在正态分布的情况下,应该远离均值?
所以我期望看到红点只出现在 +15 / -15 范围的 y 轴区域?
你好 Arne…你实现过这段代码来测试输出吗?
你好 James,感谢分享这篇信息丰富的文章。
不客气!
有趣的文章,感谢分享。
你好,
感谢这篇文章,它真的很有趣!我有一个问题。
你如何选择参数:n_estimators 和 contamination?
是否有任何数值方法,还是基于业务知识?
提前感谢你
你好,
如果你能写一篇关于异常检测应用于预测性维护的文章就太好了。
诚挚地
我指的是这篇文章中的图片,而不是我代码中的。
您可以看到红点在 (230,12) … 然而,对于 y 轴上半部分的异常值,我只期望在 y 值大于 15 或更多时出现红点。
或者我的理解有误?
我确实理解,通过核密度估计得到的典型时间序列包络不是全局的,但根据 x 轴的位置可能具有不同的值。但是点 (230,12) 看起来一点也不像异常值。
所以我的问题再说一遍:你能对那个点给出分析解释,为什么它甚至可能是一个异常值吗?
你好 @James,
我知道您有很多事情要做,而且这是一个免费的内容博客。尽管如此,我还是尝试最后一次推送我的答案。
你能详细说明为什么像在这篇文章的图片中看到的点 (230,12) 被归类为异常值吗?这对我来说毫无意义。
你好。我希望你一切都好。
感谢分享这篇文章。
我有一个问题。您能回答我吗?
我的数据集有 11000 个数据和大约 600 个特征。我的数据类型是整数或浮点数。
哪种异常检测方法适合它们?
我正在研究方法,但到目前为止还没有找到好的方法。
我研究过 Isolation Forest 对许多数据的数据集很好,但我认为它不适用于许多特征的数据集(我在我的数据集上尝试过,但收到错误)。
根据你的文章,我认为我选择 2x2 特征,并使用散点图来显示 2x2 特征,然后为它们使用 Isolation Forest。
这是个好方法吗?
你好 nirvana…以下内容可能对您感兴趣
https://machinelearning.org.cn/model-based-outlier-detection-and-removal-in-python/
https://machinelearning.org.cn/anomaly-detection-with-isolation-forest-and-kernel-density-estimation/
你好,我有一个巨大的非时间序列数据集,有 64 个特征。我该如何确定是哪个特征导致了异常值?
你好 George…您可能会发现以下资源很有趣
https://towardsdatascience.com/effective-approaches-for-time-series-anomaly-detection-9485b40077f1
请您更改您正在使用的代码。有些代码令人讨厌,并非所有人都能读懂别人的代码,谢谢。
我在我制作的数据框上尝试了这两个模型。在定义异常值的情况下,我在两个情况下都收到了相同的错误。
values=X[outlier_cases]
我收到 TypeError 和 InvalidIndexError。我的数据框有 2 列。
我需要帮助来理解为什么我会收到这个错误以及如何修复它。其他一切都正常。