编码器-解码器架构之所以流行,是因为它在一系列领域中展示了最先进的成果。
该架构的一个限制是它将输入序列编码为固定长度的内部表示。这限制了可以合理学习的输入序列的长度,并导致对于非常长的输入序列性能下降。
在这篇文章中,您将了解用于循环神经网络的注意力机制,它旨在克服这一限制。
阅读本文后,你将了解:
- 编码器-解码器架构和固定长度内部表示的局限性。
- 克服该限制的注意力机制允许网络学习在输出序列的每个项目上,应将注意力集中在输入序列的哪些部分。
- 注意力机制与循环神经网络在文本翻译、语音识别等领域的5种应用。
通过我的新书《使用Python的长短期记忆网络》启动您的项目,其中包括分步教程和所有示例的Python源代码文件。
让我们开始吧。

长短期记忆循环神经网络中的注意力机制
图片由Jonas Schleske提供,保留部分权利。
长序列问题
编码器-解码器循环神经网络是一种架构,其中一组LSTM学习将输入序列编码成固定长度的内部表示,第二组LSTM读取内部表示并将其解码成输出序列。
这种架构在文本翻译等困难的序列预测问题上取得了最先进的成果,并迅速成为主流方法。
例如,请参见
- 使用神经网络进行序列到序列学习, 2014
- 使用 RNN 编码器-解码器学习短语表示进行统计机器翻译, 2014
编码器-解码器架构在各种问题上仍然取得了优异的成果。然而,它受到所有输入序列都被强制编码为固定长度内部向量的限制。
这被认为限制了这些网络的性能,尤其是在考虑长输入序列时,例如文本翻译问题中非常长的句子。
这种编码器-解码器方法的一个潜在问题是,神经网络需要能够将源句的所有必要信息压缩成一个固定长度的向量。这可能使得神经网络难以处理长句子,尤其是那些比训练语料库中的句子更长的句子。
— Dzmitry Bahdanau 等人,《通过联合学习对齐和翻译的神经机器翻译》,2015年
需要 LSTM 帮助进行序列预测吗?
参加我的免费7天电子邮件课程,了解6种不同的LSTM架构(附代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
序列内的注意力
注意力的理念是使编码器-解码器架构摆脱固定长度的内部表示。
这通过保留编码器 LSTM 在输入序列每个步骤的中间输出,并训练模型学习有选择地关注这些输入,并将它们与输出序列中的项目关联起来实现。
换句话说,输出序列中的每个项目都取决于输入序列中的选择性项目。
每当提出的模型在翻译中生成一个单词时,它都会(软)搜索源句子中信息最相关的几个位置。然后,模型根据与这些源位置相关的上下文向量以及所有之前生成的词语来预测目标词。
……它将输入句子编码成一系列向量,并在解码翻译时自适应地选择这些向量的子集。这使得神经翻译模型无需将源句的所有信息(无论其长度如何)压缩成固定长度的向量。
— Dzmitry Bahdanau 等人,《通过联合学习对齐和翻译的神经机器翻译》,2015年
这增加了模型的计算负担,但带来了更具针对性且性能更好的模型。
此外,该模型还能够展示在预测输出序列时如何关注输入序列。这有助于理解和诊断模型正在考虑什么以及特定输入-输出对的程度。
所提出的方法提供了一种直观的方式来检查生成翻译中的单词与源句子中的单词之间的(软)对齐。这是通过可视化注释权重来完成的……每幅图中矩阵的每一行表示与注释相关的权重。从中我们可以看出在生成目标词时,源句子中的哪些位置被认为更重要。
— Dzmitry Bahdanau 等人,《通过联合学习对齐和翻译的神经机器翻译》,2015年
大图像的问题
应用于计算机视觉问题的卷积神经网络也存在类似的局限性,即很难在大图像上学习模型。
因此,可以通过对大图像进行一系列“瞥视”,在进行预测之前形成对图像的近似印象。
人类感知的一个重要特性是,人不会一次性处理整个场景。相反,人类会选择性地将注意力集中在视觉空间的某些部分,以便在需要时获取信息,并随着时间的推移将不同注视点的信息结合起来,以建立场景的内部表示,指导未来的眼球运动和决策。
— 视觉注意力的循环模型,2014年
这些基于“瞥视”的修改也可以被认为是注意力,但本文不予讨论。
请参阅相关论文。
- 视觉注意力的循环模型, 2014
- DRAW:用于图像生成的循环神经网络, 2014
- 使用视觉注意力的多目标识别, 2014
序列预测中注意力的5个例子
本节提供了一些具体示例,说明如何将注意力用于循环神经网络的序列预测。
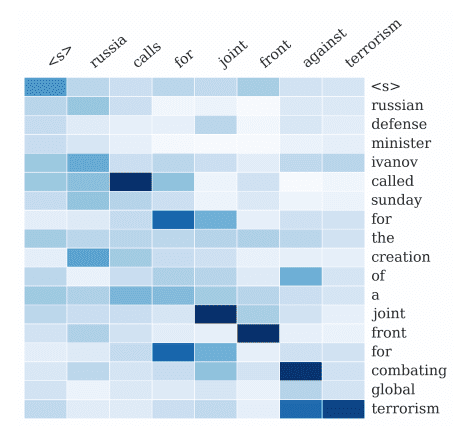
1. 文本翻译中的注意力
上面提到的激励性例子是文本翻译。
给定一个法语句子的输入序列,翻译并输出一个英语句子。注意力用于关注输出序列中每个单词的输入序列中的特定单词。
我们通过让模型在生成每个目标词时(软)搜索一组输入词或其由编码器计算的注释来扩展了基本的编码器-解码器。这使得模型无需将整个源句子编码成固定长度的向量,也让模型能够只关注与生成下一个目标词相关的信息。
— Dzmitry Bahdanau 等人,《通过联合学习对齐和翻译的神经机器翻译》,2015年
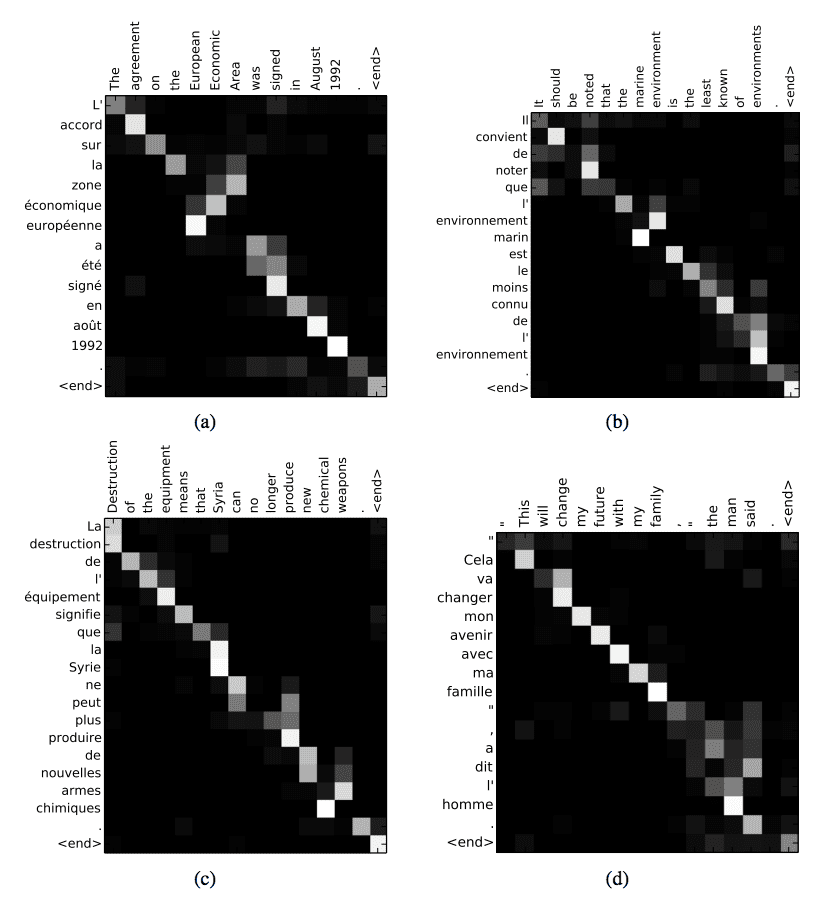
法英翻译的注意力解释
摘自 Dzmitry Bahdanau 等人,《通过联合学习对齐和翻译的神经机器翻译》,2015年
2. 图像描述中的注意力
与瞥视方法不同,基于序列的注意力机制可以应用于计算机视觉问题,以帮助了解如何最佳地使用卷积神经网络在输出序列(例如字幕)时关注图像。
给定图像输入,输出该图像的英文描述。注意力用于关注输出序列中每个单词的图像不同部分。
我们提出了一种基于注意力的方法,在三个基准数据集上提供了最先进的性能……我们还展示了如何利用学习到的注意力来更好地解释模型的生成过程,并证明学习到的对齐与人类直觉非常吻合。

输出词语与输入图像特定区域的注意力解释
摘自《展示、关注与讲述:利用视觉注意力生成神经图像字幕》,2016年
— 《展示、关注与讲述:利用视觉注意力生成神经图像字幕》,2016年
3. 蕴涵中的注意力
给定一个前提情景和关于该情景的英文假设,输出该前提是矛盾、不相关还是蕴涵该假设。
例如:
- 前提:“婚礼派对正在拍照”
- 假设:“有人结婚了”
注意力用于将假设中的每个词与前提中的词相关联,反之亦然。
我们提出了一个基于LSTM的神经模型,它一次性读取两个句子以确定蕴含关系,而不是将每个句子独立映射到语义空间。我们用神经词对词注意力机制扩展了这个模型,以鼓励对词对和短语的蕴含进行推理。……一个带有词对词神经注意力的扩展模型,其结果比这个强大的基准LSTM结果高出2.6个百分点,创下了新的最先进准确率……
— 《利用神经注意力进行蕴含推理》,2016年
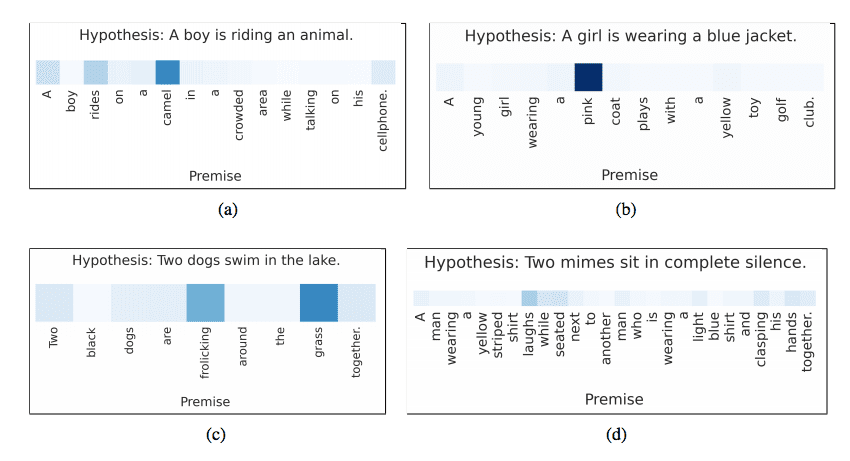
前提词与假设词的注意力解释
摘自《利用神经注意力进行蕴含推理》,2016年
4. 语音识别中的注意力
给定英文语音片段的输入序列,输出音素序列。
注意力用于将输出序列中的每个音素与输入序列中音频的特定帧相关联。
……一种新颖的端到端可训练语音识别架构,基于混合注意力机制,该机制结合内容和位置信息以选择输入序列中用于解码的下一个位置。所提出模型的一个理想特性是它可以识别比其训练时使用的更长的语音。
— 《基于注意力的语音识别模型》,2015年。
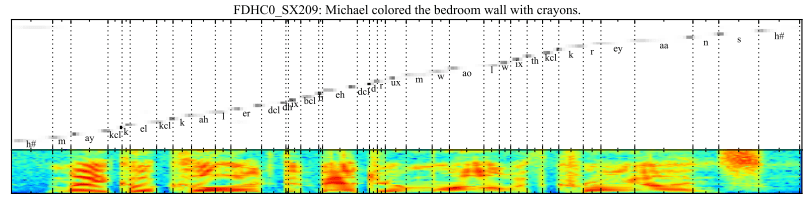
输出音素位置与输入音频帧的注意力解释
摘自《基于注意力的语音识别模型》,2015年
5. 文本摘要中的注意力
给定一篇英文文章的输入序列,输出一个总结输入的英文单词序列。
注意力用于将输出摘要中的每个单词与输入文档中的特定单词关联起来。
……一个用于抽象摘要的基于神经注意力的模型,基于神经机器翻译的最新发展。我们将这个概率模型与生成算法相结合,该算法能够生成准确的抽象摘要。
— 《用于抽象句摘要的神经注意力模型》,2015年
输入文档中单词与输出摘要的注意力解释
摘自《用于抽象句摘要的神经注意力模型》,2015年。
进一步阅读
本节提供了额外的资源,如果您想了解更多关于在LSTM中添加注意力机制的信息。
在撰写本文时,Keras 尚未提供开箱即用的注意力机制,但有一些第三方实现。请参阅
- 使用 Keras 进行问答的深度语言建模
- 注意力模型可用!
- Keras注意力机制
- 注意力与增强型循环神经网络
- 如何在循环层之上添加注意力(文本分类)
- 注意力机制实现问题
- 实现简单的神经注意力模型(用于填充输入)
- 注意力层需要另一个PR
- seq2seq库
您知道关于循环神经网络中注意力的好资源吗?
请在评论中告诉我。
总结
在这篇文章中,您了解了用于 LSTM 循环神经网络序列预测问题的注意力机制。
具体来说,你学到了:
- 循环神经网络的编码器-解码器架构使用固定长度的内部表示,这带来了限制长序列学习的约束。
- 注意力机制克服了编码器-解码器架构中的限制,它允许网络学习在输出序列的每个项目上,应将注意力集中在输入的哪些部分。
- 这种方法已应用于不同类型的序列预测问题,包括文本翻译、语音识别等。
您对循环神经网络中的注意力机制有任何疑问吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发用于序列预测的 LSTM!

在几分钟内开发您自己的 LSTM 模型。
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 构建长短期记忆网络
它提供关于以下主题的自学教程:
CNN LSTM、编码器-解码器 LSTM、生成模型、数据准备、进行预测等等...
最终将 LSTM 循环神经网络引入。
您的序列预测项目。
跳过学术理论。只看结果。






非常感谢,Jason博士,您撰写的这篇文章和文献参考。如果您能上传一个如何在LSTM层之上使用注意力模型进行文本和图像分析的示例代码,我将不胜感激。
期待您的回复。
此致
Abbey
很高兴它有帮助。
据我所知,正确实现简单注意力需要一个新的自定义层。我希望将来能准备一个示例并发布。我见过的现有示例大多似乎没有正确实现。
这篇综述确实是开始了解注意力机制的好方法。我非常期待一篇关于在Tensorflow/Keras中应用注意力的文章!
再次感谢您在6月底左右帮助我实现Keras中的截断反向传播。
很高兴有所帮助。我计划在2017年10月中旬发布一篇关于如何逐步计算注意力的文章。
Tensorflow contrib 中有几个带有注意力机制的 seq2seq 实现
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/legacy_seq2seq/python/ops/seq2seq.py
https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/seq2seq/python/ops
谢谢,利亚姆。
“2. 图像描述中的注意力”中显示的示例图像是原始论文中的图5,用于说明模型的错误。最好显示原始论文中的图4。
感谢您的建议。
在进行文本分类时,我们可以使用注意力机制吗?
是的!
嗨,Jason,
我们可以在时间序列问题中使用注意力机制吗?
由于我们使用多对一架构,我不确定是否应该使用它?
谢谢回复。
我看不出为什么不。
嗨,Jason
您是否在您的LSTM书籍中加入了注意力机制和Keras代码?
目前还没有,一旦 Keras 确定了其实现,我就会将注意力机制添加到书中。
您好,Jason Brownlee博士,
我们正在训练注意力序列到序列模型。两边都是长文档,所以使用注意力模型的一个问题是点积矩阵变得非常大,经常导致内存不足。您有什么建议来解决这个问题吗?
谢谢,
除了使用更短的序列或获取更多内存之外,我目前没有其他建议。
或许需要针对您的问题进行模型设计的仔细重新考量,David。
您的帖子对我有帮助。谢谢。
但我有一个问题。据我所知,注意力层有自己的可训练矩阵。什么信息将被训练到这个矩阵中?而且,解码器的隐藏状态在注意力机制下不再重要了吗?我对这些点不甚了解。
这里有一个方程式的演练,应该会更清楚
https://machinelearning.org.cn/how-does-attention-work-in-encoder-decoder-recurrent-neural-networks/
你好
你认为注意力机制会在像下一个词预测这样直接的问题上有所不同吗?
也许会。
谢谢杰森,这篇精彩的文章。我对LSTM和注意力网络还很陌生……我想知道是否有可能使用注意力机制来识别图像中的多个对象
注意力可能不是正确的机制,相反,您应该使用 RCNN 或 YOLO 等技术。
嗨,Jason,
您知道是否可以为多对一问题开发带有注意力机制的LSTM模型吗?如果可以,在Keras、TensorFlow或PyTorch中是否可能?
谢谢
我不确定,也许可以。
我预计您可以在任何平台上开发自己的实现。
抱歉,我不确定是否有现成的实现。
嗨,Jason,
一如既往地,这是一篇很棒的帖子。您能否提供一个关于如何在 Keras 中为时间序列预测的 LSTM 神经网络开发注意力层的示例?
谢谢
谢谢。
感谢您的建议。
亲爱的 Jason,
您能否解释一下注意力机制和自注意力机制有什么区别?
谢谢
好问题。我希望很快能详细介绍注意力机制。
感谢您的文章。
将自注意力机制与LSTM结合用于NLP任务(例如词性标注和命名实体识别)是否有意义?
或许可以开发一个原型来测试它?
你好,
感谢这篇文章。
LSTMs 无法并行化,因为它们是顺序的。
我有一个困惑。既然我们可以直接使用注意力机制(例如在机器翻译任务中),为什么还要将LSTMs与注意力机制结合起来呢?
抱歉,我不太明白您的区别。您能详细说明一下吗?
如何在 LSTM 中实现注意力模型用于预测而不是分类。也就是说,如何在 Keras 中为时间序列预测开发 LSTM 神经网络的注意力层。我希望您已经实现了这个。谢谢
我希望将来能写一篇关于这个主题的文章。
如何在 Keras 中为时间序列预测开发 LSTM 神经网络的注意力层?
您能建议一下您的工作吗?
我希望将来能写一篇关于这个主题的文章。