
注意力可能就是我们所需要的一切……但为什么?
作者 | Ideogram 提供图片
引言
如今,许多生成式人工智能模型,尤其是大型语言模型(LLMs)之所以取得成功并取得进步,很大程度上归功于其底层架构的惊人能力:一种名为 **Transformer** 的高级深度学习架构模型。更具体地说,Transformer 架构内部的一个组件对于这些模型的成功起到了关键作用:**注意力机制**。
本文将深入探讨 Transformer 架构的注意力机制,用简单的语言解释它们的工作原理、如何处理和理解文本信息,以及为什么它们在理解和生成语言方面相比以前的方法取得了实质性进展。
注意力机制之前与之后
在 2017 年原始 Transformer 架构彻底改变了机器学习和计算语言学界之前,处理自然语言的先前方法主要基于**循环神经网络架构**(RNNs)。在这些模型中,文本序列(如下面的图片所示)是以纯粹的顺序方式处理的,一次处理一个 token 或一个单词。
但有一个警告:虽然 RNN 的“记忆单元”可以保留一些近期处理过的 token(当前处理的单词之前的几个单词)的信息,但这种记忆能力是有限的。因此,在尝试处理更长、更复杂的文本序列时,由于类似于记忆丧失的效应,语言部分之间的长程关系会被忽略。
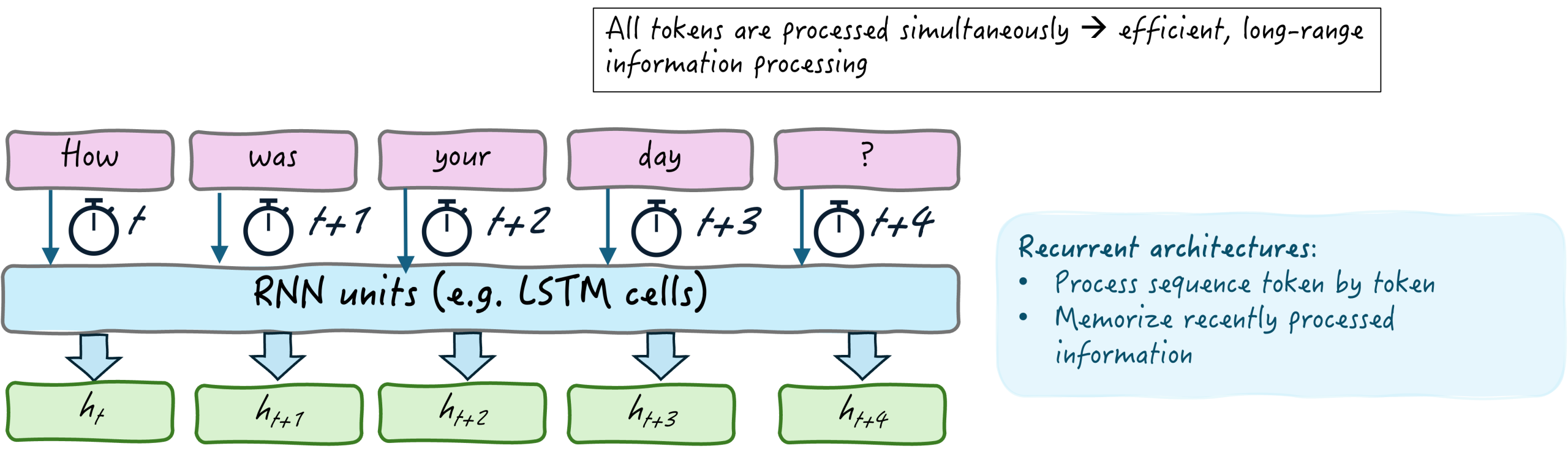
循环架构(如 RNN)如何处理顺序文本数据
作者提供图片
幸运的是,随着 Transformer 模型的出现,**注意力机制**应运而生,以克服 RNN 等经典架构中的这一局限性。注意力机制是整个 Transformer 模型“灵魂”,是驱动整个 Transformer 架构中其余部分对语言进行更深层次理解的关键组件。
具体而言,Transformer 通常使用一种称为**自注意力**的机制,它同时对文本序列中的所有 token 的重要性进行加权,而不是逐个处理。这使得能够模拟和捕捉长程依赖关系——例如,在一篇长文中,对一个人或一个地方的两次提及相隔几个段落。它还使得长文本序列的处理更加高效。
正如下图所示,自注意力机制不仅对语言的每个元素进行加权,还对 token 之间的相互关系进行加权。例如,它可以检测动词与其对应主语之间的依赖关系,即使它们在文本中相距很远。
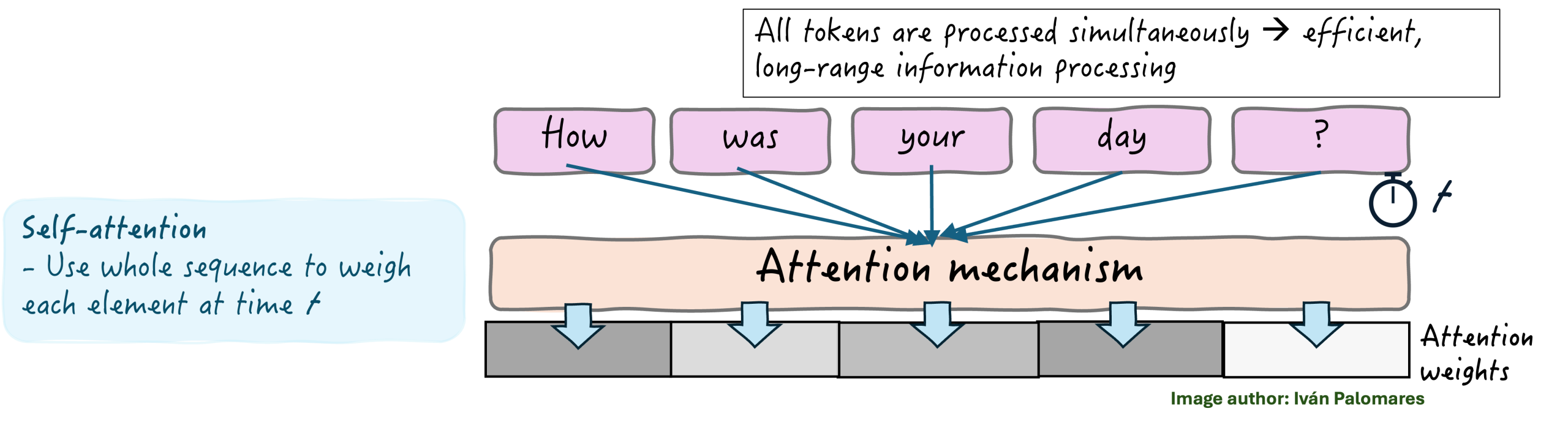
Transformer 的自注意力机制如何工作
作者提供图片
自注意力机制的解剖
通过深入了解自注意力机制,我们将更好地理解这种方法如何帮助 Transformer 模型理解自然语言序列元素之间的相互关系。
想象一下一个 token 嵌入序列(嵌入是文本片段的数值表示),来自像“拉面是我最喜欢的食物”这样的文本。token 嵌入序列被线性投影到三个不同的矩阵——**查询 (Q)、键 (K)** 和 **值 (V)**——每个都在注意力计算中扮演不同的角色。从 token 获得的这三个矩阵彼此之间并非完全相同:它们是通过对 token 嵌入应用不同的线性变换得到的;一个线性变换与查询相关,一个与键相关,一个与值相关。它们的区别在于过程中使用的权重,而这些权重是在模型训练时学习到的。
然后,我们取前两个 token 投影(查询和键),并在自注意力机制的核心应用缩放点积方法。**点积方法**计算序列中任意两个 token 的查询和键向量之间的相似度得分——一个反映一个单词应该对另一个单词给予多少注意力的值。这会产生一个 `nxn` 的注意力得分矩阵(`n` 是我们原始序列中的 token 数量)。这个注意力得分矩阵的元素是序列中单词之间关系的原始、初步的指示。下面的简短代码片段展示了使用 PyTorch 实现此机制的最小示例
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import torch import torch.nn.functional as F # 3 个 token,4 维嵌入 Q = torch.rand(3, 4) K = torch.rand(3, 4) V = torch.rand(3, 4) attention_scores = Q @ K.T # (3x4) x (4x3) -> 3x3 scaled_scores = attention_scores / (4 *** 0.5) # 按 sqrt(d_k) 缩放 weights = F.softmax(scaled_scores, dim=-1) # 在最后一个轴上应用 softmax output = weights @ V # (3x3) x (3x4) -> 3x4 |
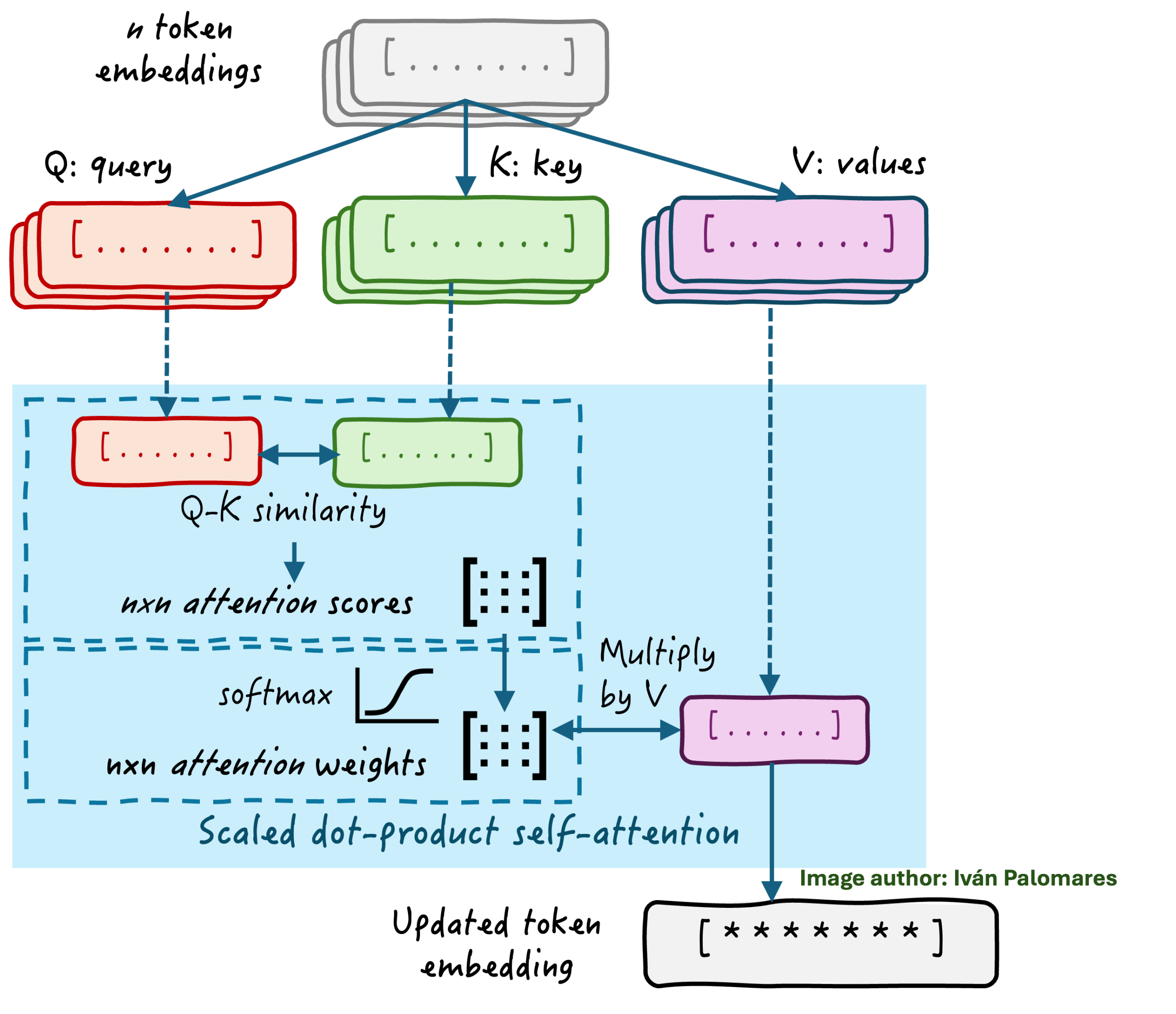
注意力头内部
作者提供图片
更进一步,原始注意力得分使用 `softmax` 数学函数进行归一化或缩放,从而得到一个缩放后的**注意力权重矩阵**。注意力权重提供了对模型在“拉面是我最喜欢的食物”等序列中每个 token 应该给予多少注意力的相关性或注意力的调整视图。
然后,将注意力权重乘以我们之前为每个 token 构建的第三个初始矩阵投影,即值,以获得更新的 token 嵌入,这些嵌入将序列中的相关信息融入到每个 token 的嵌入中。这就像在每个单词的 DNA 中注入来自它所属文本中其他单词的 DNA 片段的信息。通过这种方式,信息在 Transformer 架构的后续模块和层中流动,成功地捕捉了文本部分之间复杂关系的信息。
多头注意力
许多现实世界的 Transformer 应用更进一步,使用我们刚刚分析的自注意力机制的扩展版本。这种机制通常也被称为**注意力头**,我们可以将多个头组合成一个单一的组件来构建**多头注意力机制**。在实践中,这有助于并行化多个注意力头来学习序列中的不同语言和语义方面:一个注意力头可能专注于学习上下文,旁边的头可能专注于语法交互,依此类推。
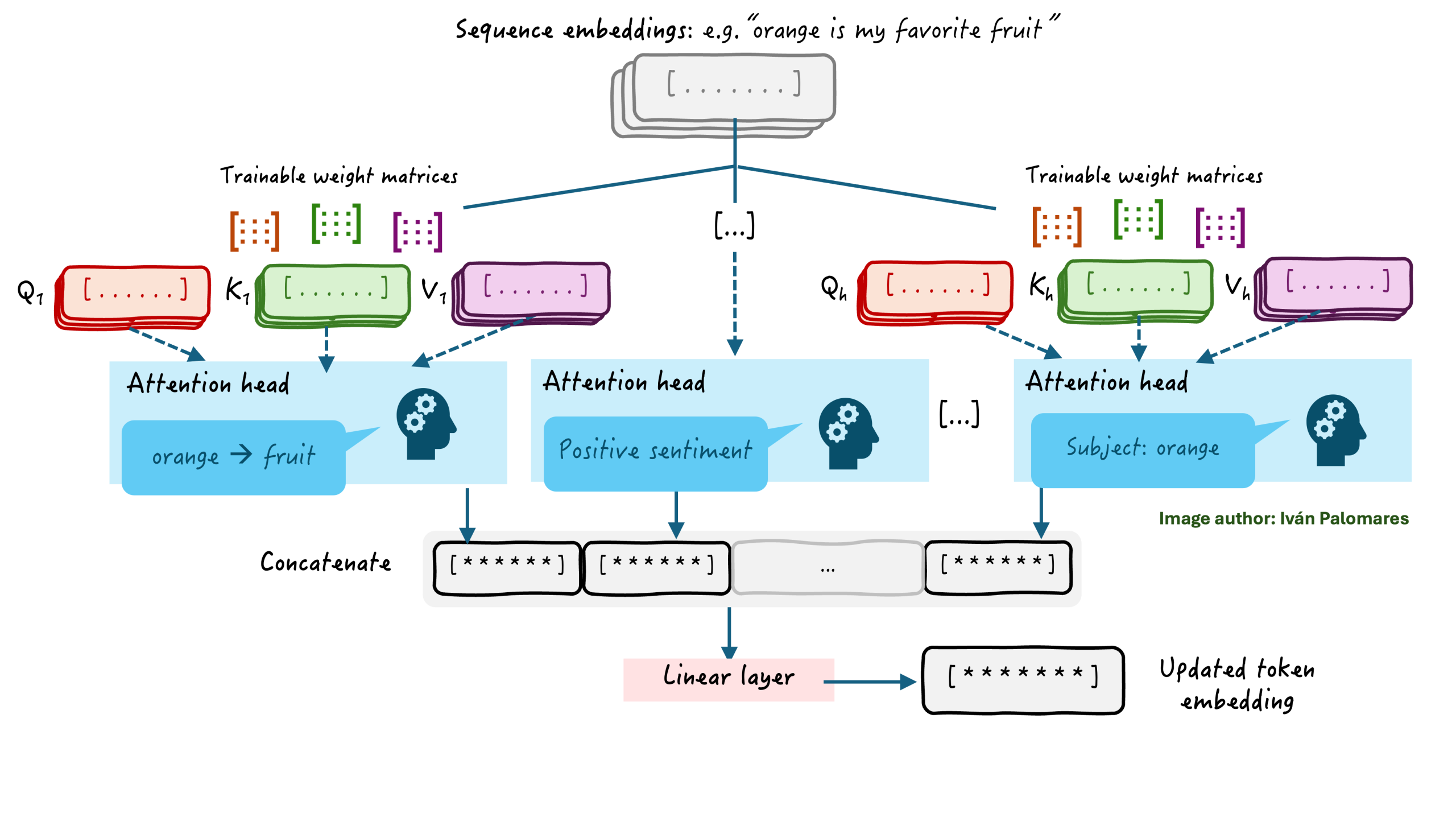
多头注意力机制
作者提供图片
在使用多头注意力机制时,每个头的输出会被连接起来,并线性投影到原始嵌入维度,以获得一个全局丰富化的文本嵌入版本,该版本捕捉了文本的多种语言和语义细微差别。
总结
本文深入而温和地探讨了 Transformer 架构中最成功的组件——注意力机制,它帮助革新了整个人工智能领域。我们探讨了注意力是如何工作的,以及它为什么重要。
您可以在这篇最近发布的 Machine Learning Mastery 文章中找到 Transformer 模型实用的、基于代码的介绍。






你好 Ivan!非常感谢你的文章!它非常直观,而且完美地解释了所有内容,毫无困难!我有一个问题,与前两张图片有关。我认为信息“所有 Token 同时处理 -> 高效、长程信息处理”仅在第二张图片中是正确的,对吗?因为第一张图片实际上是在谈论 RNN,那么每个 Token 都是以单独的方式处理的!
所以我想也许在创建照片时信息被重复了 xD
无论如何,非常感谢你的文章!非常易于阅读且信息丰富!
Grazie mille!
感谢您的反馈和支持!请随时向我们更新您的进展!