自动编码器是一种可以用于学习原始数据压缩表示的神经网络。
自动编码器由编码器和解码器子模型组成。编码器压缩输入,解码器尝试根据编码器提供的压缩版本来重建输入。训练后,保存编码器模型,丢弃解码器。
然后,编码器可用作数据预处理技术,对原始数据进行特征提取,用于训练其他机器学习模型。
在本教程中,您将了解如何为分类预测建模开发和评估自动编码器。
完成本教程后,您将了解:
- 自动编码器是一种可以用于学习原始数据压缩表示的神经网络模型。
- 如何在训练数据集上训练自动编码器模型,并仅保存模型的编码器部分。
- 如何将编码器用作训练机器学习模型的数据预处理步骤。
让我们开始吧。

如何为分类开发自动编码器
照片来源:Bernd Thaller,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- 用于特征提取的自动编码器
- 用于分类的自动编码器
- 编码器作为预测模型的预处理数据
用于特征提取的自动编码器
一个 自动编码器 是一个旨在学习输入数据压缩表示的神经网络模型。
自动编码器是一种训练为尝试将其输入复制到其输出的神经网络。
— 第 502 页,《深度学习》,2016。
它们是一种无监督学习方法,尽管从技术上讲,它们是使用监督学习方法训练的,称为自监督。
自动编码器通常作为更广泛模型的一部分进行训练,该模型试图重现输入。
例如
- X = model.predict(X)
自动编码器模型的设计通过在模型中间设置瓶颈(bottleneck)来有意地增加这一难度,然后从瓶颈处进行输入数据的重构。
自动编码器有很多类型,其用途各不相同,但最常见的用途可能是作为学习到的或自动化的特征提取模型。
在这种情况下,一旦模型拟合完成,就可以丢弃模型的重构部分,并使用直到瓶颈点的模型。瓶颈点处的模型输出是一个固定长度的向量,它提供了输入数据的压缩表示。
通常,它们会受到限制,只允许它们近似复制,并且只复制与训练数据相似的输入。由于模型被迫优先选择输入的哪些方面应该被复制,因此它通常会学习到数据的有用属性。
— 第 502 页,《深度学习》,2016。
然后可以将来自领域的数据输入模型,瓶颈处的模型输出可用作监督学习模型的特征向量,用于可视化,或更普遍地用于降维。
接下来,让我们探讨一下如何为分类预测建模问题开发一个用于特征提取的自动编码器。
用于分类的自动编码器
在本节中,我们将开发一个自动编码器,为分类预测建模问题学习输入特征的压缩表示。
首先,我们来定义一个分类预测建模问题。
我们将使用 make_classification() scikit-learn 函数来定义一个合成的二元(2类)分类任务,包含 100 个输入特征(列)和 1,000 个样本(行)。重要的是,我们将以一种方式定义问题,即大部分输入变量是冗余的(100个中的90个,即90%),从而使自动编码器能够学习有用的压缩表示。
下面的示例定义了数据集并总结了其形状。
|
1 2 3 4 5 6 |
# 合成分类数据集 from sklearn.datasets import make_classification # 定义数据集 X, y = make_classification(n_samples=1000, n_features=100, n_informative=10, n_redundant=90, random_state=1) # 汇总数据集 print(X.shape, y.shape) |
运行示例将定义数据集并打印数组的形状,以确认行数和列数。
|
1 |
(1000, 100) (1000,) |
接下来,我们将开发一个多层感知机 (MLP) 自动编码器模型。
该模型将接受所有输入列,然后输出相同的值。它将学习精确地重现输入模式。
自动编码器包含两部分:编码器和解码器。编码器学习如何解释输入并将其压缩到瓶颈层定义的内部表示中。解码器接收编码器的输出(瓶颈层),并尝试重现输入。
自动编码器训练完成后,解码器将被丢弃,我们只保留编码器,并使用它来压缩输入示例到瓶颈层输出的向量。
在这个第一个自动编码器中,我们不会对输入进行任何压缩,并将使用一个与输入大小相同的瓶颈层。这应该是一个模型可以近乎完美学习的简单问题,旨在确认我们的模型已正确实现。
我们将使用函数式 API 定义模型;如果这对您来说是新的,我推荐此教程
在定义和拟合模型之前,我们将数据分为训练集和测试集,并通过将值归一化到 0-1 的范围来缩放输入数据,这是 MLP 的一个良好实践。
|
1 2 3 4 5 6 7 8 |
... # 拆分为训练测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # 缩放数据 t = MinMaxScaler() t.fit(X_train) X_train = t.transform(X_train) X_test = t.transform(X_test) |
我们将编码器定义为有两个隐藏层,第一个层具有输入数量的两倍(例如 200),第二个层具有与输入数量相同(100),然后是具有与数据集相同数量的输入(100)的瓶颈层。
为了确保模型能够很好地学习,我们将使用批量归一化和 Leaky ReLU 激活。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
... # 定义编码器 visible = Input(shape=(n_inputs,)) # 编码器第一层 e = Dense(n_inputs*2)(visible) e = BatchNormalization()(e) e = LeakyReLU()(e) # 编码器第二层 e = Dense(n_inputs)(e) e = BatchNormalization()(e) e = LeakyReLU()(e) # 瓶颈层 n_bottleneck = n_inputs bottleneck = Dense(n_bottleneck)(e) |
解码器的结构将类似,但顺序相反。
它将有两层隐藏层,第一层拥有数据集中输入数量的节点(例如 100),第二层拥有输入数量的两倍(例如 200)。输出层将拥有与输入数据列数相同的节点数,并将使用线性激活函数输出数值。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
... # 定义解码器,第一层 d = Dense(n_inputs)(bottleneck) d = BatchNormalization()(d) d = LeakyReLU()(d) # 解码器第二层 d = Dense(n_inputs*2)(d) d = BatchNormalization()(d) d = LeakyReLU()(d) # 输出层 output = Dense(n_inputs, activation='linear')(d) # 定义自动编码器模型 model = Model(inputs=visible, outputs=output) |
该模型将使用高效的 Adam 随机梯度下降版本进行拟合,并最小化均方误差,因为重构是一种多输出回归问题。
|
1 2 3 |
... # 编译自动编码器模型 model.compile(optimizer='adam', loss='mse') |
我们可以绘制自动编码器模型中的层,以了解数据如何在模型中流动。
|
1 2 3 |
... # 绘制自动编码器 plot_model(model, 'autoencoder_no_compress.png', show_shapes=True) |
下图显示了自动编码器的图。
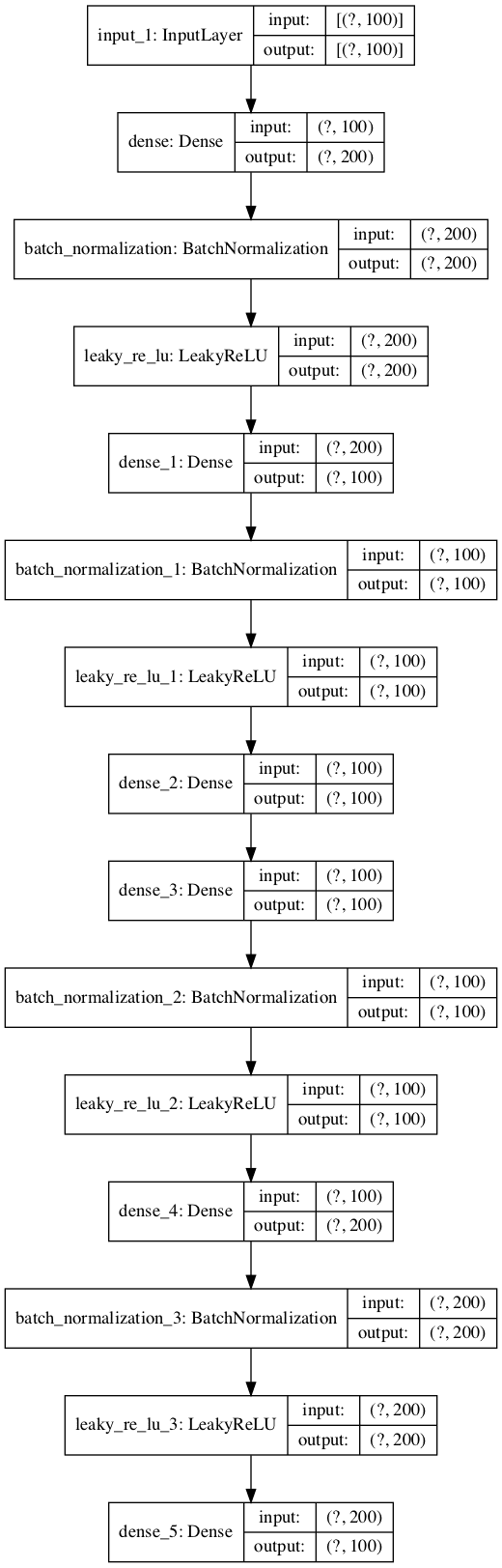
未压缩分类自动编码器模型的图
接下来,我们可以训练模型来重现输入,并跟踪模型在保留测试集上的性能。
|
1 2 3 |
... # 拟合自动编码器模型以重构输入 history = model.fit(X_train, X_train, epochs=200, batch_size=16, verbose=2, validation_data=(X_test,X_test)) |
训练后,我们可以绘制训练集和测试集的学习曲线,以确认模型已很好地学习了重构问题。
|
1 2 3 4 5 6 |
... # 绘制损失 pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='test') pyplot.legend() pyplot.show() |
最后,我们可以根据需要保存编码器模型以备将来使用。
|
1 2 3 4 5 6 |
... # 定义编码器模型(不含解码器) encoder = Model(inputs=visible, outputs=bottleneck) plot_model(encoder, 'encoder_no_compress.png', show_shapes=True) # 将编码器保存到文件 encoder.save('encoder.h5') |
在保存编码器的同时,我们还将绘制编码器模型,以了解瓶颈层输出的形状,例如一个 100 维的向量。
下面提供了该图的一个示例。
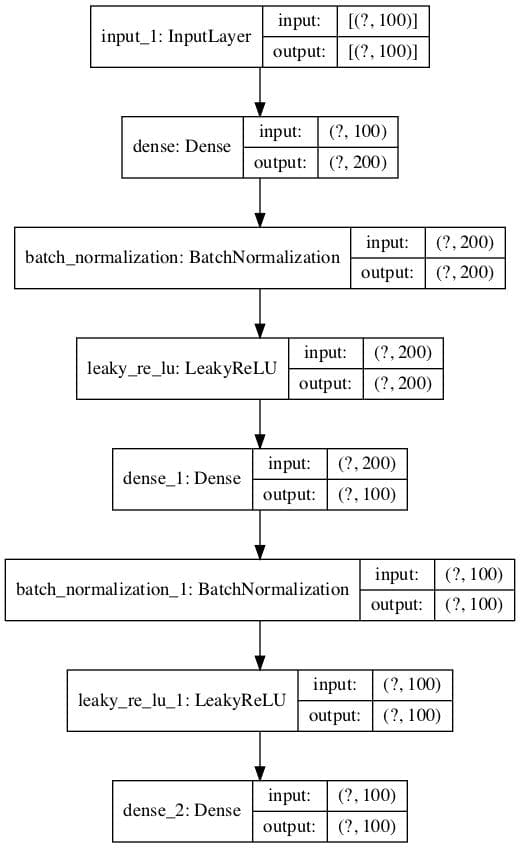
未压缩分类编码器模型的图
总而言之,下面列出了用于重构分类数据集的输入数据、在瓶颈层没有压缩的自动编码器的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
# 训练用于分类的自动编码器,瓶颈层无压缩 from sklearn.datasets import make_classification 从 sklearn.预处理 导入 MinMaxScaler from sklearn.model_selection import train_test_split from tensorflow.keras.models import Model from tensorflow.keras.layers import Input from tensorflow.keras.layers import Dense from tensorflow.keras.layers import LeakyReLU from tensorflow.keras.layers import BatchNormalization from tensorflow.keras.utils import plot_model from matplotlib import pyplot # 定义数据集 X, y = make_classification(n_samples=1000, n_features=100, n_informative=10, n_redundant=90, random_state=1) # 输入列数 n_inputs = X.shape[1] # 拆分为训练测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # 缩放数据 t = MinMaxScaler() t.fit(X_train) X_train = t.transform(X_train) X_test = t.transform(X_test) # 定义编码器 visible = Input(shape=(n_inputs,)) # 编码器第一层 e = Dense(n_inputs*2)(visible) e = BatchNormalization()(e) e = LeakyReLU()(e) # 编码器第二层 e = Dense(n_inputs)(e) e = BatchNormalization()(e) e = LeakyReLU()(e) # 瓶颈层 n_bottleneck = n_inputs bottleneck = Dense(n_bottleneck)(e) # 定义解码器,第一层 d = Dense(n_inputs)(bottleneck) d = BatchNormalization()(d) d = LeakyReLU()(d) # 解码器第二层 d = Dense(n_inputs*2)(d) d = BatchNormalization()(d) d = LeakyReLU()(d) # 输出层 output = Dense(n_inputs, activation='linear')(d) # 定义自动编码器模型 model = Model(inputs=visible, outputs=output) # 编译自动编码器模型 model.compile(optimizer='adam', loss='mse') # 绘制自动编码器 plot_model(model, 'autoencoder_no_compress.png', show_shapes=True) # 拟合自动编码器模型以重构输入 history = model.fit(X_train, X_train, epochs=200, batch_size=16, verbose=2, validation_data=(X_test,X_test)) # 绘制损失 pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='test') pyplot.legend() pyplot.show() # 定义编码器模型(不含解码器) encoder = Model(inputs=visible, outputs=bottleneck) plot_model(encoder, 'encoder_no_compress.png', show_shapes=True) # 将编码器保存到文件 encoder.save('encoder.h5') |
运行示例将拟合模型,并沿途报告训练集和测试集上的损失。
注意:如果您在创建模型图时遇到问题,可以注释掉导入并调用plot_model()函数。
注意:您的 结果可能因算法或评估程序的随机性、或数值精度的差异而有所不同。请考虑运行示例几次并比较平均结果。
在这种情况下,我们看到损失值较低,但没有达到零(正如我们所预期的),瓶颈层也没有压缩。可能需要进一步调整模型架构或学习超参数。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
... 42/42 - 0s - loss: 0.0032 - val_loss: 0.0016 Epoch 196/200 42/42 - 0s - loss: 0.0031 - val_loss: 0.0024 Epoch 197/200 42/42 - 0s - loss: 0.0032 - val_loss: 0.0015 Epoch 198/200 42/42 - 0s - loss: 0.0032 - val_loss: 0.0014 Epoch 199/200 42/42 - 0s - loss: 0.0031 - val_loss: 0.0020 Epoch 200/200 42/42 - 0s - loss: 0.0029 - val_loss: 0.0017 |
创建了学习曲线图,显示模型在重构输入方面达到了良好的拟合,并且在整个训练过程中保持稳定,没有过拟合。
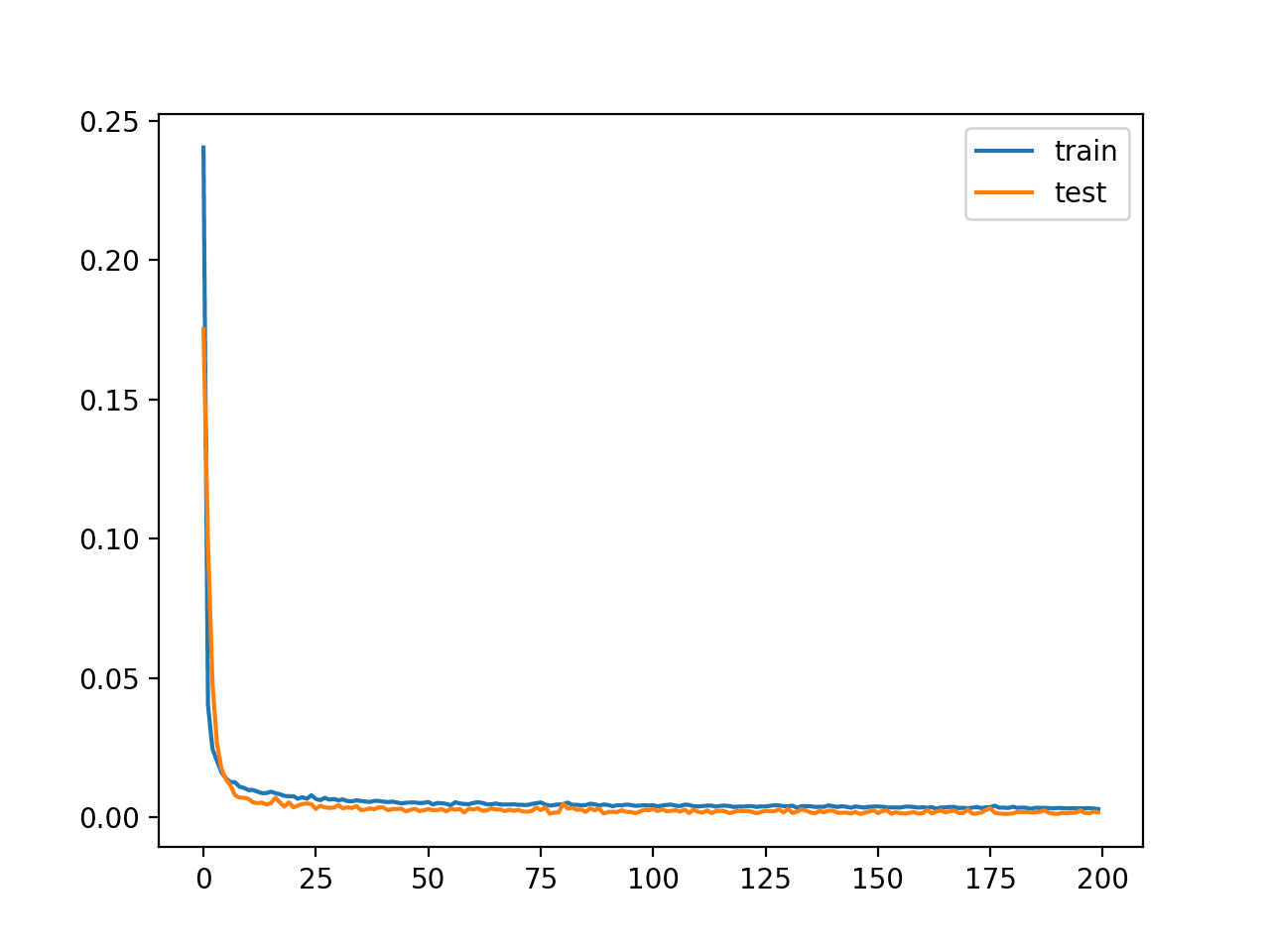
未压缩自动编码器模型训练的学习曲线
到目前为止,一切顺利。我们知道如何开发没有压缩的自动编码器。
接下来,让我们改变模型的配置,使瓶颈层的节点数减半(例如 50)。
|
1 2 3 4 |
... # 瓶颈层 n_bottleneck = round(float(n_inputs) / 2.0) bottleneck = Dense(n_bottleneck)(e) |
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
# 训练用于分类的自动编码器,瓶颈层有压缩 from sklearn.datasets import make_classification 从 sklearn.预处理 导入 MinMaxScaler from sklearn.model_selection import train_test_split from tensorflow.keras.models import Model from tensorflow.keras.layers import Input from tensorflow.keras.layers import Dense from tensorflow.keras.layers import LeakyReLU from tensorflow.keras.layers import BatchNormalization from tensorflow.keras.utils import plot_model from matplotlib import pyplot # 定义数据集 X, y = make_classification(n_samples=1000, n_features=100, n_informative=10, n_redundant=90, random_state=1) # 输入列数 n_inputs = X.shape[1] # 拆分为训练测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # 缩放数据 t = MinMaxScaler() t.fit(X_train) X_train = t.transform(X_train) X_test = t.transform(X_test) # 定义编码器 visible = Input(shape=(n_inputs,)) # 编码器第一层 e = Dense(n_inputs*2)(visible) e = BatchNormalization()(e) e = LeakyReLU()(e) # 编码器第二层 e = Dense(n_inputs)(e) e = BatchNormalization()(e) e = LeakyReLU()(e) # 瓶颈层 n_bottleneck = round(float(n_inputs) / 2.0) bottleneck = Dense(n_bottleneck)(e) # 定义解码器,第一层 d = Dense(n_inputs)(bottleneck) d = BatchNormalization()(d) d = LeakyReLU()(d) # 解码器第二层 d = Dense(n_inputs*2)(d) d = BatchNormalization()(d) d = LeakyReLU()(d) # 输出层 output = Dense(n_inputs, activation='linear')(d) # 定义自动编码器模型 model = Model(inputs=visible, outputs=output) # 编译自动编码器模型 model.compile(optimizer='adam', loss='mse') # 绘制自动编码器 plot_model(model, 'autoencoder_compress.png', show_shapes=True) # 拟合自动编码器模型以重构输入 history = model.fit(X_train, X_train, epochs=200, batch_size=16, verbose=2, validation_data=(X_test,X_test)) # 绘制损失 pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='test') pyplot.legend() pyplot.show() # 定义编码器模型(不含解码器) encoder = Model(inputs=visible, outputs=bottleneck) plot_model(encoder, 'encoder_compress.png', show_shapes=True) # 将编码器保存到文件 encoder.save('encoder.h5') |
运行示例将拟合模型,并沿途报告训练集和测试集上的损失。
注意:您的 结果可能因算法或评估程序的随机性、或数值精度的差异而有所不同。请考虑运行示例几次并比较平均结果。
在这种情况下,我们看到损失值与上面未压缩的示例一样低,这表明模型在瓶颈尺寸减半的情况下性能也同样良好。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
... 42/42 - 0s - loss: 0.0029 - val_loss: 0.0010 Epoch 196/200 42/42 - 0s - loss: 0.0029 - val_loss: 0.0013 Epoch 197/200 42/42 - 0s - loss: 0.0030 - val_loss: 9.4472e-04 Epoch 198/200 42/42 - 0s - loss: 0.0028 - val_loss: 0.0015 Epoch 199/200 42/42 - 0s - loss: 0.0033 - val_loss: 0.0021 Epoch 200/200 42/42 - 0s - loss: 0.0027 - val_loss: 8.7731e-04 |
创建了学习曲线图,同样显示模型在重构输入方面达到了良好的拟合,并且在整个训练过程中保持稳定,没有过拟合。
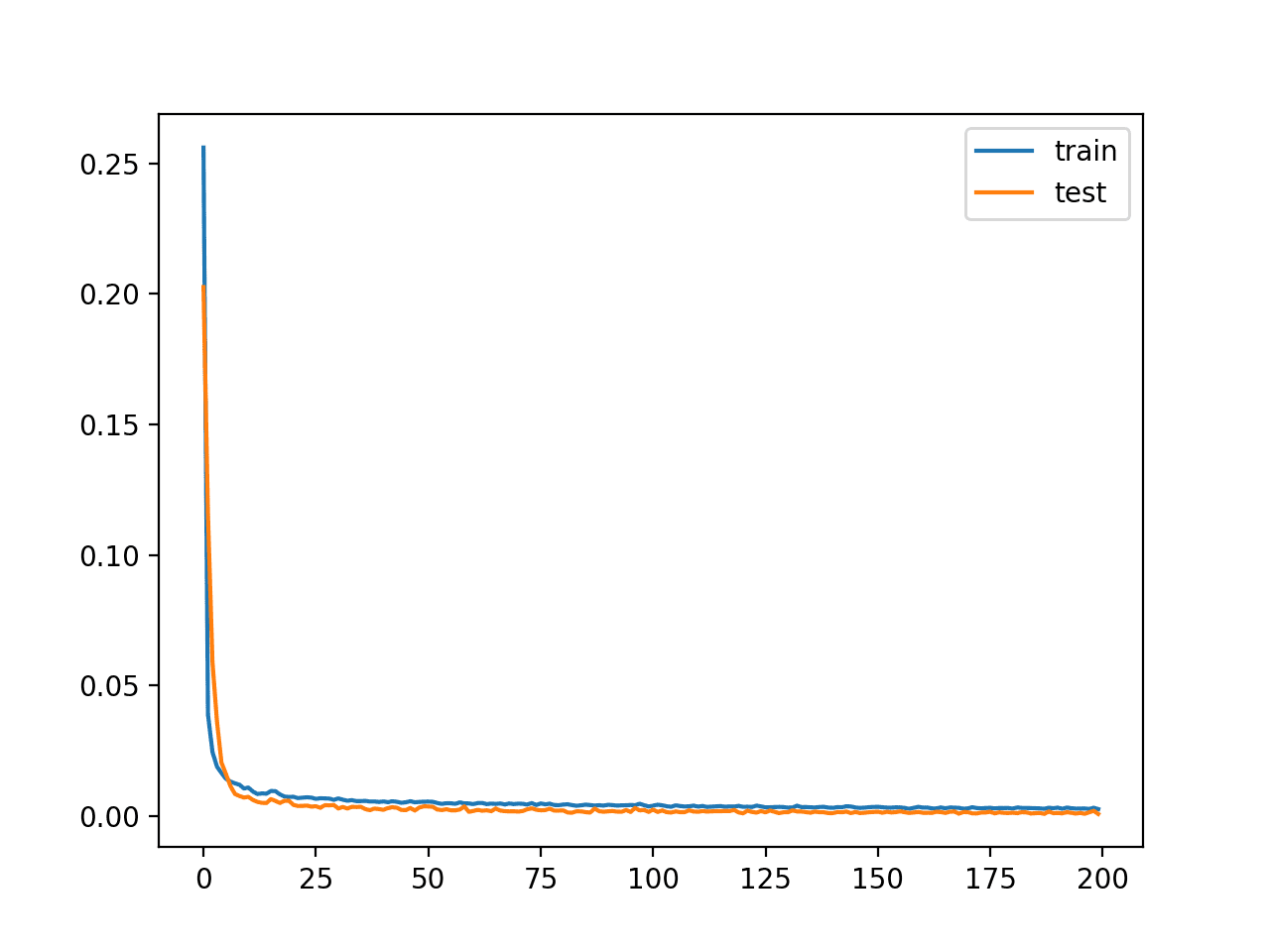
带有压缩的自动编码器模型训练的学习曲线
训练好的编码器已保存到文件“encoder.h5”,我们可以加载并稍后使用。
接下来,让我们探讨一下如何使用训练好的编码器模型。
编码器作为预测模型的预处理数据
在本节中,我们将使用自动编码器训练好的编码器来压缩输入数据并训练另一个预测模型。
首先,我们在此问题上建立一个性能基线。这一点很重要,因为如果模型的性能没有通过压缩编码得到提升,那么压缩编码就不会为项目增加价值,也不应该使用。
我们可以直接在训练数据集上训练逻辑回归模型,并在保留测试集上评估模型的性能。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 逻辑回归模型的性能基线 from sklearn.datasets import make_classification 从 sklearn.预处理 导入 MinMaxScaler from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score # 定义数据集 X, y = make_classification(n_samples=1000, n_features=100, n_informative=10, n_redundant=90, random_state=1) # 拆分为训练测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # 缩放数据 t = MinMaxScaler() t.fit(X_train) X_train = t.transform(X_train) X_test = t.transform(X_test) # 定义模型 model = LogisticRegression() # 在训练集上拟合模型 model.fit(X_train, y_train) # 在测试集上进行预测 yhat = model.predict(X_test) # 计算准确率 acc = accuracy_score(y_test, yhat) print(acc) |
运行示例将在训练数据集上拟合逻辑回归模型,并在测试集上进行评估。
注意:您的 结果可能因算法或评估程序的随机性、或数值精度的差异而有所不同。请考虑运行示例几次并比较平均结果。
在这种情况下,我们可以看到模型达到了约 89.3% 的分类准确率。
我们期望并希望在编码后的输入上拟合的逻辑回归模型能获得更好的准确率,这样编码才被认为是有效的。
|
1 |
0.8939393939393939 |
我们可以更新示例,首先使用上一节中训练的编码器模型对数据进行编码。
首先,我们可以从文件中加载训练好的编码器模型。
|
1 2 3 |
... # 从文件加载模型 encoder = load_model('encoder.h5') |
然后,我们可以使用编码器将原始输入数据(例如 100 列)转换为瓶颈向量(例如 50 维向量)。
此过程可应用于训练集和测试集。
|
1 2 3 4 5 |
... # 编码训练数据 X_train_encode = encoder.predict(X_train) # 编码测试数据 X_test_encode = encoder.predict(X_test) |
然后,我们可以使用这些编码后的数据来训练和评估逻辑回归模型,如同之前一样。
|
1 2 3 4 5 6 7 |
... # 定义模型 model = LogisticRegression() # 在训练集上拟合模型 model.fit(X_train_encode, y_train) # 对测试集进行预测 yhat = model.predict(X_test_encode) |
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# 在编码输入上评估逻辑回归 from sklearn.datasets import make_classification 从 sklearn.预处理 导入 MinMaxScaler from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score from tensorflow.keras.models import load_model # 定义数据集 X, y = make_classification(n_samples=1000, n_features=100, n_informative=10, n_redundant=90, random_state=1) # 拆分为训练测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # 缩放数据 t = MinMaxScaler() t.fit(X_train) X_train = t.transform(X_train) X_test = t.transform(X_test) # 从文件加载模型 encoder = load_model('encoder.h5') # 编码训练数据 X_train_encode = encoder.predict(X_train) # 编码测试数据 X_test_encode = encoder.predict(X_test) # 定义模型 model = LogisticRegression() # 在训练集上拟合模型 model.fit(X_train_encode, y_train) # 对测试集进行预测 yhat = model.predict(X_test_encode) # 计算分类准确率 acc = accuracy_score(y_test, yhat) print(acc) |
运行示例首先使用编码器对数据集进行编码,然后对训练数据集拟合逻辑回归模型并在测试集上进行评估。
注意:您的 结果可能因算法或评估程序的随机性、或数值精度的差异而有所不同。请考虑运行示例几次并比较平均结果。
在这种情况下,我们可以看到模型达到了约 93.9% 的分类准确率。
这比在原始数据集上评估的相同模型获得了更好的分类准确率,这表明编码对于我们选择的模型和测试框架是有帮助的。
|
1 |
0.9393939393939394 |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
书籍
- 深度学习, 2016.
API
文章
总结
在本教程中,您学习了如何开发和评估用于分类预测建模的自动编码器。
具体来说,你学到了:
- 自动编码器是一种可以用于学习原始数据压缩表示的神经网络模型。
- 如何在训练数据集上训练自动编码器模型,并仅保存模型的编码器部分。
- 如何将编码器用作训练机器学习模型的数据预处理步骤。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。





 for Feature Selection in Python")
谢谢 Jason,
您能否再次解释一下为什么我们期望使用编码器压缩的数据集比原始数据集产生更好的结果?我们不是因为压缩而丢失信息吗?
我认为压缩的价值在于我们可以处理一个特征更少的数据集。
我猜想它以某种方式学习了更有用的潜在特征,类似于嵌入的工作原理?是这样吗?
谢谢
我们并不期望它能带来更好的性能,但如果能的话,对我们的项目来说是很好的。
这类似于离散数据的嵌入。
是的,类似于降维或特征选择,但使用更少的特征只有在获得相同或更好的性能时才有意义。
我认为他在问的是,为什么这种压缩会提高结果?
谢谢。
瓶颈层可以将大/复杂的输入特征压缩到低维空间。这有助于降维。这种压缩可能对预测模型有用,也可能没用,但通常是有用的。
因为输入维度可能太大,我们的模型无法与我们拥有的训练数据匹配。通过压缩输入数据,我们可以使模型拟合,而不过拟合的可能性更小。
它不仅降低了数据的维度,你还对特征应用了滤波器,所以
网络执行的操作可以生成新的特征,这些新特征可能有助于更好地理解输入。
这就像我们过滤信号一样,我们从转换中获得新特征,并且可以在转换后的空间中更清晰地看到某些特征。
另外,由于经过了自动编码器,它会生成特征之间的隐藏的非线性交互,这是逻辑回归可能无法学到的东西。
感谢这个教程!
encoder.save(‘encoder.h5’) 是如何从模型对象中获取学习到的权重?如何通过实例化一个使用 encoder = Model(inputs=visible, outputs=bottleneck) 的新模型对象来保留权重?
保存模型包括将架构和权重保存到一个文件中。然后我们可以加载它并直接使用它。
更多关于保存和加载模型的信息在这里
https://machinelearning.org.cn/save-load-keras-deep-learning-models/
在这一行中,我们定义了一个新模型,该模型现在与两个模型共享层——编码器-解码器模型和编码器模型。我们只保留编码器模型。
亲爱的 Jason,
先生,我看不出你是如何从代码中消除解码部分,只提取编码部分特征的!
我只看到你使用了整个模型!
请,我需要从解码部分提取特征,然后将它们输入到像SVM这样的分类器中!
我们定义了一个编码器模型并单独保存它。我们还定义了一个完整模型,该模型会重用编码器的一些层。我们不保存这个完整模型。
这有帮助吗?
老师……我想知道您在这个教程中使用了哪种类型的自动编码器……例如,它是稀疏的、堆叠的还是多层自动编码器。
抱歉,我不知道它如何归入分类学。它只是一个自动编码器,没有什么特别之处。
亲爱的 Jason,感谢您分享的所有信息。我像 John 一样在一点上感到困惑。新的编码器模型如何从自动编码器学习权重,或者为什么我们不编译编码器模型?
不客气。
我们将在自动编码器中训练编码器,然后只保存编码器部分。这两个模型共享权重。
不需要编译编码器,因为它不是直接训练的。
亲爱的 Jason,
感谢这个精彩的教程。有没有一种有效的方法来查看数据如何在瓶颈层中投影?我想将投影与 PCA 进行比较。
谢谢!
是的。如果您愿意,可以创建编码瓶颈向量的 PCA 投影。
好的。您是否有关于可视化主成分的教程?
我认为没有。
这很简单,检索向量,运行 PCA,然后散点图显示结果。
也许从这里开始
https://machinelearning.org.cn/?s=Principal+Component&post_type=post&submit=Search
非常感谢您提供的这个信息丰富的教程。请告诉我实现这些代码所需的 Keras 和 TensorFlow 版本。
您可以使用最新版本的 Keras 和 TensorFlow 库。
亲爱的Jason
这是一个分类问题,为什么我们将损失函数设为 MSE?
我们使用 MSE 损失来衡量输入的重建误差,输入是数值型的。
感谢这个教程。是否可以进行单个预测?我们应该应用哪种转换?
是的,使用编码器对输入进行编码,然后将输入传递给训练模型的 predict() 函数。
Jason,现在您只在 Python 中展示代码……能否也为 R 用户提供 R 语言的版本……谢谢
感谢您的建议。
亲爱的 Jason,我认为在
# 训练用于分类的自动编码器,瓶颈层无压缩
在 filt 调用中
你写了“history = model.fit(X_train, X_train, epochs=200, batch_size=16, verbose=2, validation_data=(X_test,X_test))”
我认为 y_train 不是 X_train 的两倍
此致
感谢教程
不,这是正确的。
自动编码器被训练来重建输入——这就是自动编码器的全部意义。
尊敬的Jason博士,
感谢您的教程。
该方法在确定无监督学习中的聚类数量方面看起来不错。我尝试用它来降维,并先在大规模合成数据集(超过 25000 个实例和 100 个特征,其中 10 个是信息性特征)上估计聚类数量,然后对相同真实的有噪声数据重复进行。在这两种情况下,我都通过将特征数量减少到少于信息性特征(在本例中为五个)取得了良好的结果。该方法有助于在高斯混合模型图上清晰地看到 AIC、BIC 信息准则的“拐点”,并大大加快算法的工作速度。
不客气。
工作做得好,感谢分享你的发现!
你好……我们是否可以使用此教程进行多标签分类问题??
自动编码器可以直接使用,只需更改利用编码输入进行预测的模型即可。
你好,
是否可以使用多项逻辑回归的自动编码器模型对无标签数据进行多标签分类(无监督)?
你好 Santobedi……以下内容可能对你有用
https://machinelearning.org.cn/autoencoder-for-regression/
嗨 Jason
非常感谢您提供的所有免费的优秀教程目录……这是世界上最好的之一!它为我的后续工作提供了灵感!
我分享了我应用了对您的基准自动编码器分类代码的几个修改后的结论
1.) 代码修改
1.1) 我决定比较 5 种不同分类模型的准确性结果
(LogisticRegression, SVC, ExtratreesClassifier, RandomForestClassifier, XGBClassifier)
1.2) 我通过著名的“KFold()”和 SKLearn 库的“cross_val_score()”函数对模型结果进行统计评估
1.3) 最重要的是,我应用了多种自动编码特征压缩率,例如 1(完全不压缩),1/2(您的选择),1/4(甚至更压缩),当然还有不自动编码,甚至将特征扩展到两倍以观察会发生什么(某种嵌入?)。..
2.) 我的结论是,在获得与您的 LogisticRegression 模型相同的方法结果后,结果对所选模型更加敏感。
有时自动编码不如不自动编码,有时 1/4 压缩是最好的……因此,许多变化表明您必须为每个特定问题以启发式的方式进行工作!
特别是我的最佳结果是选择了 SVC 分类模型且不自动编码,但在逻辑回归模型上,确实通过自动编码和特征压缩(1/2)取得了最佳结果。
可惜我无法在这里插入(我不知道如何?)我的图表结果来可视化它!
正如我所说,您为我们提供了基本的工具和概念,然后我们可以对这些想法进行实验。
谢谢!
做得好,听起来是个很棒的实验。
结果可能受限于合成数据集。也许在更大、更真实的数据集上,结果会更有趣/更多样化,因为特征提取可以发挥重要作用。
事实上,我将相同的自动编码分析应用于更“真实”的数据集,如“乳腺癌”和“糖尿病 Pima India”,并且我得到了与之前类似的结果,但准确性较低,约为癌症 75%,糖尿病 77%,可能是因为样本太少(癌症 286 个,糖尿病 768 个)……
在这两种情况下,逻辑回归现在都是最佳模型,无论是否进行自动编码和压缩……我记得在癌症案例中使用“onehotencoding”时也获得了相同的结果……
因此,对于每个特定问题,尝试不同的模型和不同的编码方法似乎是唯一的出路……
干得漂亮!
没有万能的特征提取方法,仅此而已。只是我们工具箱中的另一种方法。
你好
我需要这个教程的 Matlab 代码
抱歉,我没有 Matlab 代码。
嗨,Jason,
非常感谢您提供的这份富有洞察力的指南。
当仅使用 AE 进行特征创建时,是否可以跳过解码和拟合步骤?即只使用编码器部分?
# 定义编码器
visible = Input(shape=(n_inputs,))
# 编码器第一层
e = Dense(n_inputs*2)(visible)
e = BatchNormalization()(e)
e = LeakyReLU()(e)
# 编码器第二层
e = Dense(n_inputs)(e)
e = BatchNormalization()(e)
e = LeakyReLU()(e)
# 瓶颈层
n_bottleneck = n_inputs
bottleneck = Dense(n_bottleneck)(e)
然后通过跳转到
encoder = Model(inputs=visible, outputs=bottleneck)
X_train_encode = encoder.predict(X_train)
X_test_encode = encoder.predict(X_test)
换句话说,在使用 AE 创建特征时,有必要提前编码和拟合吗?
非常感谢。
这正是我们在教程最后所做的。
但在教程的最后,您加载并使用了保存的编码器——encoder = load_model(‘encoder.h5’)。我只是想知道在保存编码器之前进行编码和拟合是否会对创建最终结果产生任何影响。谢谢
* 解码和拟合
编码器模型在可以使用之前必须进行拟合。
您可以选择将拟合后的编码器模型保存到文件,也可以不保存,这对它的性能没有影响。
解码器不保存,它会被丢弃。
为什么我们在特征创建中拟合编码器模型,如果拟合仅仅用于重建输入(而我们不需要)?
它是在重建项目中拟合的,然后我们丢弃解码器,只留下知道如何以有用方式压缩输入数据的编码器。
明白了,非常感谢。我只是想确保在仅使用潜在表示时,loss 和 val_loss 仍然相关,即使解码器被丢弃了。
损失仅与重建输入任务相关。
瓶颈层中实现的编码可能对使用输入数据的预测任务有用,也可能无用,这取决于具体的数据集。
通常,这可能是有帮助的——本教程的全部目的是教您如何做到这一点,以便您可以针对您自己的数据进行测试并找出答案。
好的,所以当只采用编码表示时,loss 是不相关的。我正在尝试比较不同的(特征提取)自动编码器。我曾希望通过比较 loss 和 val_loss 来做到这一点,但我想这只有在提取 AE 特征后,拟合分类模型时才相关。
谢谢
是的,唯一相关的比较(对于预测建模)是它对使用编码输入的分类器/回归器的影响。
亲爱的 Jason,
我将使用编码器部分作为生成新特征的工具,并将它们与原始数据集结合。
那么,如何在代码中控制我想得到的新特征的数量?
好问题。
对编码中特征数量的控制是通过瓶颈层中的节点数来实现的。
我已经做过了,但它总是给出与我原始输入相同数量的特征。
这是我更改的代码。
或者如果您有时间,请发送修改后的版本给我,该版本为我提供了 10 个新特征。
abdelrahmanahmedfayed@gmail.com
# 定义编码器
visible = Input(shape=(n_inputs,))
# 编码器第一层
e = Dense(round(float(n_inputs) / 2.0))(visible)
e = BatchNormalization()(e)
e = LeakyReLU()(e)
# 编码器第二层
e = Dense(round(float(n_inputs) / 2.0))(e)
e = BatchNormalization()(e)
e = LeakyReLU()(e)
# 瓶颈层
n_bottleneck = 10
bottleneck = Dense(n_bottleneck)(e)
抱歉,我没有能力为您定制教程。
我们可以将此代码用于多类分类吗?在这种情况下,哪些行需要调整?
Jason Brownlee,请至少给点提示,我已经在寻找关于多分类自动编码器的文章好几周了。
是的,无需更改。
亲爱的 Jason,
非常感谢您的教程!
我需要对以下代码进行一些澄清
# 编码训练数据
X_train_encode = encoder.predict(X_train)
# 编码测试数据
X_test_encode = encoder.predict(X_test)
我的第一个问题是,我们在代码中实际做了什么?
我的第二个问题是,如果我们有了数据集的嵌入(即压缩数据),那么我们就可以直接从瓶颈层输出到逻辑回归分类模型。为什么我们需要上面的代码,我的意思是为什么我们要预测新的 x_train?
我们正在使用训练好的编码器来编码训练集和测试集的输入数据。
编码器的输出是瓶颈。
这些编码后的数据被输入到逻辑回归模型中。
亲爱的 Jason,
请告诉我如何将瓶颈层给出的潜在空间特征提取为 CSV 文件。可以吗?encoder 的类型是 tensorflow.python.keras.engine.functional.Functional。
如果你愿意,可以通过编码器预测每个输入并将结果保存到 csv。
亲爱的 Jason,
从瓶颈层提取的特征包含 NAN 值,请提供一些建议来摆脱它们。
谢谢你
这很令人惊讶,也许这些技巧会有帮助。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
亲爱的 Jason,
抱歉,您的代码对我来说运行得非常好,但我将其用于我自己的问题时出现了这些 NAN 值,所以我请您建议一些好的实践,或者可能的原因或解决方案来避免它。
谢谢你
也许可以检查一下您在建模之前是否缩放了数据,并且您的数据不包含 nan 值。
很棒的东西。我尝试使用多项式扩展特征数量,然后通过自动编码器进行处理以去除无用的特征。效果非常好。谢谢。
哇,这是个很酷的想法!
(我怎么没想到呢???)
干得好!
亲爱的 Jason,
自动编码器可以用于多类别分类吗?例如,5 个类别?
当然可以。
尊敬的Jason博士,
感谢您的教程。
我看了代码,但不知道在哪里应用我的数据库。
在哪个部分以及如何做到?
也许这能帮助您加载数据集。
https://machinelearning.org.cn/load-machine-learning-data-python/
Jason博士您好,
我非常欣赏您的精彩教程。
当我想定义编码器和解码器部分时,我的输入形状出现了问题。
我的输入形状是:(75, 75, 3)。我不知道如何根据我的输入调整卷积层。
提前感谢您的帮助
上面的例子是针对表格数据的,而不是图像,抱歉。
Jason,感谢您的精彩教程 :) 我有一个问题,我们可以使用自动编码器从图像中提取特征,而不是表格数据吗?如果可以,您能提供一些链接让我理解一下吗?
当然,这被称为迁移学习。
https://machinelearning.org.cn/how-to-use-transfer-learning-when-developing-convolutional-neural-network-models/
尊敬的Jason博士,
感谢您的教程。
我正在处理时间序列数据。我知道输入数据在编码状态下被压缩了,并且特征可以在该压缩数据上可视化。但是,我想在这些编码特征上可视化我的原始输入数据(就像我们在 PCA 和聚类中可以可视化一样)。有可能这样做吗?如果可以,请建议一下!
不行。
嗨,Jason,
非常感谢您的教程。我正在进行故障检测分类。其中涉及两个数据集。一个是无故障数据(正常),另一个是故障操作数据,其中包含故障的标签。我可以在无故障(正常)数据上训练自动编码器,然后将编码器用于“故障”数据以进行SVM分类吗?
也许可以试试,并将其结果与在两个数据集上操作的模型进行比较。
只要编码器应用于相似的数据,它应该就可以了(类似于迁移学习)?
也许可以。
你好 Jason,
您的教程在我学习这些东西时给了我很大的帮助。事实上,即使现在,当我查找与使用Python实现某些东西相关的信息时,特别是与神经网络相关的信息时,我首先会尝试查找您的教程。话虽如此,最近我发现没有关于使用TFP(TensorFlow的概率模块)进行概率编程,特别是VAE的信息。虽然这可能不是一个询问VAE的好地方,但我还是会尝试一下。
您能否使用TFP做一个关于这个主题的小教程?
提前感谢。
谢谢!
感谢您的建议。
嗨Jason!谢谢。在使用自己的图像数据集时,您能告诉我如何修改modify.fit()吗?也许使用Keras的ImageDataGenerator,但如何将其用于model.fit()?
我不认为这个例子是处理图像数据的合适起点,也许从这里开始
https://machinelearning.org.cn/start-here/#dlfcv
抱歉,笔误。
model.fit()
如何将编码后的数据(在您的情况下是X_train_encode)重塑为二维,并使其与y_train对齐?我训练了一个自动编码器,我得到的x_train_encode的潜在空间是32x32x32,尽管我最初有5900张图像,每张图像都是254x254x254。现在,我如何将这个32x32x32的矩阵与我的y_train和图像进行匹配,以便与KNN或SVM等分类器进行训练?谢谢!
上面的例子不是针对图像的。
如果您正在处理图像,我建议从这里开始
https://machinelearning.org.cn/start-here/#dlfcv
你好,
非常感谢您的帖子!
我想知道为什么验证损失比训练损失低?
这与TensorFlow计算损失的方式有关吗?
谢谢,
这可能是一个统计上的巧合。
这可能是因为验证数据集很小,不能代表训练集。
你好,
我正在训练一个具有类似架构的模型,并且也发现验证损失远低于训练损失。虽然这不影响我的模型结果,但我想弄清楚为什么会发生这种荒谬的情况。我最初认为可能有数据泄露,因此我使用了不同的方法来分割我的训练和验证数据集。然而,情况仍然如此。经过几次尝试后,当我将损失函数从均方误差改为(1 - 结构相似性)时,我很快就解决了问题。因此,我想知道损失的计算是否像Yahya提到的那样引起了问题。看到我的回复后,如果您对这个问题有任何新的想法,请告诉我。
谢谢
可能是验证数据集太小或不能代表训练数据集。
我尝试将数据集分成两半,一半作为训练集,另一半作为验证集。我也尝试不打乱数据集,但这些都没有太大改变。我从未见过自动编码器以外的情况。这很奇怪,我不确定是否应该忽略这个问题。
也许也可以探索其他模型配置?
我们可以使用编码器作为数据准备步骤来训练神经网络模型吗?
当然。但为什么不直接训练您的模型呢。
我想通过自动编码器预训练模型以获得权重初始化,然后将权重用于神经网络模型。您有教程给我吗?
没有,抱歉。
这可能会给你一些想法
https://machinelearning.org.cn/how-to-improve-performance-with-transfer-learning-for-deep-learning-neural-networks/
我们如何计算这个分类器的准确率?我需要准确率的值,而不是X光图像的图形表示,用Python,我需要源代码。
也许这会有帮助。
https://scikit-learn.cn/stable/modules/generated/sklearn.metrics.accuracy_score.html
嗨 Jason
感谢精彩的教程。
当我为我的数据集运行代码时,模型运行了,并且损失随着epoch的增加而减小。但出现了一个警告:
WARNING:tensorflow:已编译加载的模型,但编译的指标尚未构建。在训练或评估模型之前,`model.compile_metrics`将为空。
您知道为什么会出现这个警告吗?我在网上找不到任何信息。先谢谢了。
不客气。
您目前可能可以安全地忽略该警告。
嗨,Jason,
非常感谢您的教程。我想用自动编码器来创建一个用于作者身份验证的模型,通过文本来确定两个文档是否由同一作者撰写,但我遇到了很多问题,我不理解数据集以及如何训练和构建我的模型。
请帮我理解一下!!
数据集的架构如下
第一个.jsonl文件如下:
{“id”: “6cced668-6e51-5212-873c-717f2bc91ce6”, “fandoms”: [“Fandom 1”, “Fandom 2”], “pair”: [“Text 1…”, “Text 2…”]}
{“id”: “ae9297e9-2ae5-5e3f-a2ab-ef7c322f2647”, “fandoms”: [“Fandom 3”, “Fandom 4”], “pair”: [“Text 3…”, “Text 4…”]}
第二个.jsonl真实文件是
{“id”: “6cced668-6e51-5212-873c-717f2bc91ce6”, “same”: true, “authors”: [“1446633”, “1446633”]}
{“id”: “ae9297e9-2ae5-5e3f-a2ab-ef7c322f2647”, “same”: false, “authors”: [“1535385”, “1998978”]}
也许你可以尝试不同的问题构架?
也许你可以将其建模为一个二元分类任务,使用一个接收两个来源文本的模型?
非常感谢您的回复,Jason先生。
先生,能否请您为我推荐一些用于此数据的深度学习技术?
测试一系列技术,找出哪些效果好或最佳。
嗨Jason,感谢您与社区分享您的知识。我真的从您那里学到了很多。事实上,当我遇到疑问时,您的博客和书籍是我最常参考的。我刚刚完成了您的自动编码器教程,并希望您能就我陈述的问题给我一些专家指导。
dataframe_a =ID, col1, col2, col3, col4,col5,col6,col7,col8,col9 …..col21,label
dataframe_b = ID, col_A, col_B, col_C, col_D
dataframe_a的形状为 (3250, 23),而dataframe_b的形状为 (64911, 5)。注意:dataframe_b没有标签。
通过‘ID’执行内连接合并两个数据,得到一个形状为 (274, 27) 的小数据集,并且模型表现不佳。
我已经用第一个数据(dataframe_a)训练了一个二元分类模型,准确率达到了约70%,用于预测标签。我相信第二个数据(dataframe_b)中包含一些信息可以帮助提高我的模型性能,但如上所述,通过特征‘ID’映射两个数据只会得到一个很小的数据集。
如何将自动编码器与我已经在dataframe_a上训练好的模型结合使用,以获得更高的准确率?另外,如果您有与我的问题相关的用例,请分享。
期待您的回复。先谢谢了。
也许你可以标记缺失值,然后进行插补,或者使用一个可以忽略它们的模型。
也许你可以使用一个多输入模型,该模型在有数据时接受额外数据,否则输入全为零。
谢谢Jason,一如既往地提供了这个非常清晰的教程。
我想知道你为什么选择Adam优化器,有什么原因吗?你会选择哪个其他优化器,为什么?
谢谢!
不客气。
我选择Adam是因为它在大多数情况下效果都很好。你可以使用任何你喜欢的优化器。
嗨,Jason,
非常感谢您的精彩教程。我想为一些一维数据(光普)使用自动编码器进行降维。我只有180个样本(来自17名患者),每个样本包含1000个点,所以输入维度是180*1000,这是原始数据,之前没有进行任何特征提取。我需要将这些数据分类到两个类别(癌症、非癌症),但由于样本数量很少(180),我认为最好将维度从原始数据1000降至例如50,然后应用分类,例如全连接的密集网络。
我一直在考虑使用自动编码器进行这种原始数据降维,因为我不知道可以从原始数据中手动提取哪些特征,而且我认为自动编码器可以为我进行自动特征提取,然后我可以使用特征向量(例如180*50)作为任何分类器的输入。
在您的教程中,您进行了降维,从1000*100 > 1000*50,您能告诉我您认为我是否可以针对我的数据使用您的方法,考虑到我样本量很少?我想达到例如180*1000 > 180*50。另外,如果您能向我推荐任何解决这个分类问题的通用解决方案,特别是考虑到我的数据集很小,而且我也不知道该提取哪些特征(这就是为什么我考虑神经网络,甚至深度学习),我将非常感激。
提前感谢
此致
Sepi
也许您可以尝试一下,然后将其结果与直接在原始数据上拟合模型进行比较,然后使用效果最好的方法。
嗨,Jason,
谢谢您的回答。您能告诉我您说的“直接在原始数据上拟合模型”是什么意思吗?您的意思是例如使用全连接网络(密集)进行分类,使用原始数据(无特征提取)吗?
祝好
Sepi
是的。
亲爱的 Jason,
喜欢您的作品,非常感谢您所做的一切!
您是否知道可以检索编码器的权重,以便将其重新映射到原始数据以研究选择了哪些特征?
祝好,
reini
如果您有一个层,您可以执行layer.get_weights();但这只适用于一次处理一个层。您不能一次处理整个模型。
Jason博士,您好:
自动编码器是否可以用于所有类型的数据集?
我正在处理学生表现数据,其中包括学生的社会人口统计信息、课堂表现(期末成绩)以及最终结果(及格或不及格)。当我使用自动编码器时,我得到了一些非常奇怪的结果。我不知道我的错误在哪里,但有时我想知道自动编码器是否可以处理这类数据!
在这种情况下,您对自动编码器有什么期望?我最喜欢的自动编码器解释是输入数据的有损压缩。如果您可以将压缩与您的问题相关联,那么自动编码器是一个很好的模型。
我只是想看看自动编码器(特征提取)如何帮助提高使用任何传统分类器的预测模型的性能。这将通过与未使用提取的显著特征的同一分类器进行比较来实现。我问是因为我没有看到任何自动编码器在相同类型数据上工作的例子!
在这种情况下,自动编码器应被视为有损压缩。如果您有一个具有1000个特征的数据点,您可能会运行一个自动编码器来生成一个长度为50的向量。然后,您可以使用长度为50的向量而不是长度为1000的向量来应用分类器。您(1)节省内存并运行更快,因为您的模型不那么复杂,并且(2)可能更准确,因为我们假设自动编码器消除了原始数据中的噪声。
感谢您提供的极具信息量的回复。还有一件事,如何评估自动编码器的性能?当我列出自动编码器训练期间要监控的指标acc和val_acc时,两者都显示得很低。
自动编码器是一种无监督学习技术。应最小化的指标是解码器输出与编码器输入之间的误差。
先生您好,
特征向量的维度有限制吗?
具体来说,我是否应该使用特征向量维度小于10的样本?
实际上,我有一些尺寸不同的图像,所以为了将它们输入编码器,我采用了一个基于统计矩的简单特征向量,并将其作为输入提供给自动编码器。
您能否就此给我一些建议?
提前感谢。
没有限制,但我们希望它尽可能小。如果您碰巧找到了一个能完美预测分类的特征,您将得到一个非常好的简单模型。
谢谢您,先生。
亲爱的 Jason,
感谢您的精彩教程。您的教程对像我这样的初学者非常有帮助。非常非常感谢!
我正在处理一个多类分类问题。我正在尝试应用基于自动编码器的降维技术。在这种情况下,我们可以使用与代码中提到的相同的激活函数(“线性”)吗?
对于深度神经网络,我们使用softmax作为多类分类的激活函数。那么,我们可以尝试使用 sigmoid 和 softmax 等激活函数来进行多类分类任务的降维吗?
谢谢
感谢分享。很高兴您觉得这些教程有用。
亲爱的 Jason,
喜欢您的作品,非常感谢。
您能否解释一下Keras中自动编码器的性能是列式还是跨行式的?另一方面,AE模型是逐列扫描输入矩阵还是逐行扫描?
你能告诉我如果我们使用自动编码器进行特征提取,它的输出是什么吗?
嗨msec…请详细说明您的问题,以便我们更好地帮助您。
嗨,如何将自动编码器潜在向量(特征提取)可视化为RGB彩色轨迹?
嗨Mylo…您可能会对以下内容感兴趣
https://hackernoon.com/latent-space-visualization-deep-learning-bits-2-bd09a46920df
Jason,非常感谢您的教程。
在您的示例中,您没有编译编码器,而是编译了带有编码器/解码器的模型。我不明白。
提前非常感谢。
嗨JB…这只是为了说明。您应该编译模型。
嗨,感谢您的教程!
为什么编码器的第一层输出的特征数量是输入特征数量的两倍?有没有办法让它从第一层就开始输出少于特征数量的量?
即,您的示例有:Encoder:100 -> 200 -> 100 -> 50 <- 100 <- 200 85 -> 70 -> 50 <- 70 <- 85 <- 100
谢谢!
PM
嗨PM…以下资源可能有助于澄清。
https://deep-learning-study-note.readthedocs.io/en/latest/Part%203%20(Deep%20Learning%20Research)/14%20Autoencoders/14.3%20Representational%20Power,%20Layer%20Size%20and%20Depth.html
嗨,PM,我有一个和您一样的问题,如果您找到了答案,能否告诉我?
嗨Jason,感谢这篇信息丰富的帖子。我尝试在我的数据集上使用自动编码器(样本量为52,特征为86)。我的验证损失要么是恒定的,要么是在增加。我该怎么办?
嗨RK…非常欢迎!在这种情况下,我建议您专注于数据预处理。
https://machinelearning.org.cn/improve-model-accuracy-with-data-pre-processing/
嗨,感谢您所做的出色工作。
我有一些问题。
1)是否可以训练自动编码器(例如)猫和狗的图片,然后训练后给一张新的猫的图片,它就能自动预测这张图片是猫的图片?这种工作是使用自动编码器完成的吗?
嗨Ibrar…当然。这就是这种模型类型的目的。
先生,
我正在做我的自动编码器项目。我的数据集维度是19680行和64列。我已经训练了自动编码器,现在我想从编码器中获取编码后的特征。
编码特征的维度(行和列)是多少?
您好 IJAZ……以下资源可能会引起您的兴趣
https://towardsdatascience.com/autoencoder-on-dimension-reduction-100f2c98608c
嗨,Jason,
非常感谢这个很棒的教程。
我想知道为什么您不必拟合编码器。有特定原因吗?
提前感谢。
您好 Pascal……不客气!以下讨论可能有助于澄清
https://www.kaggle.com/getting-started/116296
您好 Joson,
什么可能导致这种变暖
WARNING:tensorflow:已编译加载的模型,但编译的指标尚未构建。在训练或评估模型之前,`model.compile_metrics`将为空。
您好 Amina……以下讨论可能很有见地
https://stackoverflow.com/questions/67970389/warningtensorflowcompiled-the-loaded-model-but-the-compiled-metrics-have-yet
感谢 Jason 博士的精彩教程。
我正在寻找基于 VAE 的 cifar100 分类问题。在这方面,
1. 您能否推荐类似的 VAE 教程
2. 如何将其用于 cifar100 分类。
3. 您是否有任何材料或书籍可供参考。
我正在使用您的 GAN 书籍,但还没有开始,因为我首先想实现 VAE。
谢谢和最好的祝愿
感谢您的教程,它非常有用。我有一个问题,我搜索了自动编码器的理论,但大多数示例表明我应该为一类(例如:无欺诈)训练它,这样,模型就可以识别该类的最重要特征,当您输入欺诈类别(例如)时,它将检测到异常,我看到很多工作都是这样做的,所以我不明白是否是这样,还是取决于问题或那部分是如何工作的,尽管示例中没有针对预测模型的**数据准备**部分 :c
您好 Meredith……您对自动编码器训练的理解是正确的!您可以在此处了解更多
https://medium.com/low-code-for-advanced-data-science/fraud-detection-using-a-neural-autoencoder-a5bdc244f390#id_token=eyJhbGciOiJSUzI1NiIsImtpZCI6ImVkODA2ZjE4NDJiNTg4MDU0YjE4YjY2OWRkMWEwOWE0ZjM2N2FmYzQiLCJ0eXAiOiJKV1QifQ.eyJpc3MiOiJodHRwczovL2FjY291bnRzLmdvb2dsZS5jb20iLCJhenAiOiIyMTYyOTYwMzU4MzQtazFrNnFlMDYwczJ0cDJhMmphbTRsamRjbXMwMHN0dGcuYXBwcy5nb29nbGV1c2VyY29udGVudC5jb20iLCJhdWQiOiIyMTYyOTYwMzU4MzQtazFrNnFlMDYwczJ0cDJhMmphbTRsamRjbXMwMHN0dGcuYXBwcy5nb29nbGV1c2VyY29udGVudC5jb20iLCJzdWIiOiIxMTA3MTAyODIwMDE0ODIwMjg4MzQiLCJlbWFpbCI6ImphbWVzcGNhcm1pY2hhZWxAZ21haWwuY29tIiwiZW1haWxfdmVyaWZpZWQiOnRydWUsIm5iZiI6MTcwNzY4NjQ0MCwibmFtZSI6IkphbWVzIENhcm1pY2hhZWwsIFAuRS4sIFBNUCIsInBpY3R1cmUiOiJodHRwczovL2xoMy5nb29nbGV1c2VyY29udGVudC5jb20vYS9BQ2c4b2NLSXdMdG9DYlczX21wLWxMN0t1OEdBWVF0S1VaSkdteGpIcm8zZDV2dUw9czk2LWMiLCJnaXZlbl9uYW1lIjoiSmFtZXMiLCJmYW1pbHlfbmFtZSI6IkNhcm1pY2hhZWwsIFAuRS4sIFBNUCIsImxvY2FsZSI6ImVuIiwiaWF0IjoxNzA3Njg2NzQwLCJleHAiOjE3MDc2OTAzNDAsImp0aSI6IjJiNDc5ZjUzMTVhYmQ5OWY5M2MwYzA2MDRkNDBjMDEwOTEwZTc4MTYifQ.VwJ9GOAKS61CVa7lbrQ5PmEKef1ODIbdn4UKuTdi5bMB72L9LKHsc5GyHuDOEv7fV2tRF0XReg_xaxNHl-5dh2oTAJq4QnrfhVVvQNnMdpmPl85ewWjM39QEjtFrcS2T9BZ2pEPgvXKL_wW7gimhbDBTIr8o_rOE8sGh0rpDGZaof6dWte-I62UJX-TR6COAYLi9_LRGLjMRodoNS4sorsyowVkJzJtpjXqQwCZD1fNpPv5VrXiLoxpA_7ZRuJYoHo-YvwK-cE1qTKLP3rthEEUzBZbrWDpdNmgSw1icbd34k4QenSxddgEYKN2UlVBnCZDtA7PwVi9zl-mQP2YAlA
自动编码器在训练和测试中的计算复杂度(空间和时间)是多少?
您好 Geo……**自动编码器**在**训练**和**测试**期间的计算复杂度取决于几个因素,包括输入数据的大小、神经网络的结构以及所选的优化算法。以下是**时间**和**空间复杂度**的分析
—
### **1. 训练复杂度**
#### **时间复杂度**
自动编码器训练的时间复杂度主要由以下因素决定:
– **层数和神经元数量:** 用 \( L \) 表示层数,\( n_i \) 表示第 \( i \) 层中的神经元数量,\( d \) 表示输入维度。
– **前向传播:** 单次通过自动编码器前向传播的时间复杂度为 \( O(\text{总权重}) \)。对于 \( L \) 层自动编码器:
\[
O\left(\sum_{i=1}^{L-1} n_i \cdot n_{i+1}\right)
\]
– **反向传播(梯度计算):** 对于每个参数(权重和偏置),都会计算梯度,这使计算量加倍。
\[
O\left(\sum_{i=1}^{L-1} n_i \cdot n_{i+1}\right)
\]
因此,一次完整的前向和后向传播的时间复杂度为:
\[
O\left(2 \cdot \sum_{i=1}^{L-1} n_i \cdot n_{i+1}\right)
\]
– **训练迭代次数:** 对于大小为 \( m \) 的数据集进行 \( t \) 次训练迭代:
\[
O\left(t \cdot m \cdot \sum_{i=1}^{L-1} n_i \cdot n_{i+1}\right)
\]
—
#### **空间复杂度**
– **权重和偏置:** 需要空间来存储每一层的权重和偏置。
\[
O\left(\sum_{i=1}^{L-1} n_i \cdot n_{i+1}\right)
\]
– **激活:** 在前向传播期间需要空间来存储所有层的激活。
\[
O\left(\sum_{i=1}^{L} n_i\right)
\]
– **梯度:** 需要空间来存储反向传播的梯度。
\[
O\left(\sum_{i=1}^{L-1} n_i \cdot n_{i+1}\right)
\]
– **总空间:** 将这些加起来,总空间复杂度为:
\[
O\left(\sum_{i=1}^{L-1} n_i \cdot n_{i+1} + \sum_{i=1}^{L} n_i\right)
\]
—
### **2. 测试复杂度**
#### **时间复杂度**
在测试期间,只需要前向传播。
– 对于单个输入,复杂度为:
\[
O\left(\sum_{i=1}^{L-1} n_i \cdot n_{i+1}\right)
\]
– 对于 \( m \) 个测试样本,则为:
\[
O\left(m \cdot \sum_{i=1}^{L-1} n_i \cdot n_{i+1}\right)
\]
#### **空间复杂度**
– 只需要存储权重、偏置和层激活的空间。
\[
O\left(\sum_{i=1}^{L-1} n_i \cdot n_{i+1} + \sum_{i=1}^{L} n_i\right)
\]
—
### **影响复杂度的关键因素**
1. **输入维度 (\( d \)):** 高维数据会增加计算负载。
2. **潜在空间大小 (\( h \)):** 编码的大小会影响训练/测试成本。
3. **批量大小 (\( b \)):** 训练通常以小批量进行,这会影响时间复杂度。
4. **网络深度和宽度:** 更深、更宽的网络会增加权重和计算成本。
—
### **示例**
对于具有以下特征的简单自动编码器:
– 输入大小 \( d \),
– 隐藏层大小 \( h \),
– 数据集大小 \( m \),
– 训练轮数 \( t \),
**训练复杂度:**
\[
O\left(t \cdot m \cdot (d \cdot h + h^2)\right)
\]
**测试复杂度:**
\[
O\left(m \cdot (d \cdot h + h^2)\right)
\]
空间需求同样取决于 \( d \)、\( h \) 和层数。
—