过拟合是梯度提升等复杂非线性学习算法的一个问题。
在这篇文章中,您将了解如何在 Python 中使用 XGBoost 通过提前停止来限制过拟合。
阅读本文后,你将了解:
- 关于提前停止作为减少训练数据过拟合的一种方法。
- 如何监控 XGBoost 模型在训练过程中的性能并绘制学习曲线。
- 如何在最佳时期使用提前停止来过早停止 XGBoost 模型的训练。
通过我的新书《XGBoost With Python》启动您的项目,其中包括所有示例的分步教程和 Python 源代码文件。
让我们开始吧。
- 2017 年 1 月更新:已更新以反映 scikit-learn API 0.18.1 版本中的更改。
- **2018 年 3 月更新**:添加了下载数据集的备用链接,因为原始链接似乎已被删除。

在 Python 中使用 XGBoost 通过早停避免过拟合
照片由 Michael Hamann 拍摄,保留部分权利。
在 Python 中使用 XGBoost 需要帮助吗?
参加我的免费 7 天电子邮件课程,探索 xgboost(含示例代码)。
立即点击注册,还将免费获得本课程的 PDF 电子书版本。
提前停止以避免过拟合
提前停止是训练复杂机器学习模型以避免过拟合的一种方法。
它通过监控模型在单独测试数据集上的性能来工作,一旦测试数据集上的性能在固定数量的训练迭代后没有改进,就停止训练过程。
它通过尝试自动选择拐点来避免过拟合,在该拐点处,测试数据集上的性能开始下降,而训练数据集上的性能随着模型开始过拟合而继续提高。
性能度量可以是用于训练模型的损失函数(例如对数损失),也可以是通常与问题相关的外部度量(例如分类准确率)。
使用 XGBoost 监控训练性能
XGBoost 模型可以在训练期间评估和报告模型在测试集上的性能。
它通过在训练模型时调用 model.fit() 时指定测试数据集和评估指标,并指定详细输出,来支持此功能。
例如,我们可以报告 XGBoost 模型训练期间独立测试集 (eval_set) 上的二元分类错误率 (“error”),如下所示:
|
1 2 |
eval_set = [(X_test, y_test)] model.fit(X_train, y_train, eval_metric="error", eval_set=eval_set, verbose=True) |
XGBoost 支持一系列评估指标,包括但不限于:
- “rmse” 表示均方根误差。
- “mae” 表示平均绝对误差。
- “logloss” 表示二元对数损失,“mlogloss” 表示多类别对数损失(交叉熵)。
- “error” 表示分类错误。
- “auc” 表示 ROC 曲线下面积。
完整列表在 XGBoost 参数网页的“学习任务参数”部分提供。
例如,我们可以演示如何在 Pima Indians 糖尿病发作数据集上跟踪 XGBoost 模型的训练性能。
下载数据集文件并将其放在当前工作目录中。
下面提供了完整的示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 监控训练性能 从 numpy 导入 loadtxt from xgboost import XGBClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # 加载数据 dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",") # 将数据拆分为 X 和 y X = dataset[:,0:8] Y = dataset[:,8] # 将数据拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.33, random_state=7) # 拟合模型,无训练数据 model = XGBClassifier() eval_set = [(X_test, y_test)] model.fit(X_train, y_train, eval_metric="error", eval_set=eval_set, verbose=True) # 对测试数据进行预测 y_pred = model.predict(X_test) predictions = [round(value) for value in y_pred] # 评估预测 accuracy = accuracy_score(y_test, predictions) print("Accuracy: %.2f%%" % (accuracy * 100.0)) |
运行此示例会用 67% 的数据训练模型,并在每个训练时期对 33% 的测试数据集进行模型评估。
每次迭代都会报告分类错误,最后报告分类准确率。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
输出如下,为简洁起见进行了截断。我们可以看到每次训练迭代(在每个提升树添加到模型之后)都会报告分类错误。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
... [89] validation_0-error:0.204724 [90] validation_0-error:0.208661 [91] validation_0-error:0.208661 [92] validation_0-error:0.208661 [93] validation_0-error:0.208661 [94] validation_0-0error:0.208661 [95] validation_0-error:0.212598 [96] validation_0-error:0.204724 [97] validation_0-error:0.212598 [98] validation_0-error:0.216535 [99] validation_0-error:0.220472 准确率:77.95% |
查看所有输出,我们可以看到模型在测试集上的性能趋于平稳,甚至在训练结束时变得更差。
使用学习曲线评估 XGBoost 模型
我们可以检索模型在评估数据集上的性能并绘制它,以深入了解训练期间的学习过程。
在拟合 XGBoost 模型时,我们将 X 和 y 对数组提供给 eval_metric 参数。除了测试集之外,我们还可以提供训练数据集。这将提供模型在训练期间在训练集和测试集上的表现报告。
例如:
|
1 2 |
eval_set = [(X_train, y_train), (X_test, y_test)] model.fit(X_train, y_train, eval_metric="error", eval_set=eval_set, verbose=True) |
此外,模型在每个评估集上的性能在训练后通过调用 model.evals_result() 函数进行存储和提供。这会返回一个评估数据集和分数的字典,例如:
|
1 2 |
results = model.evals_result() print(results) |
这将打印如下结果(为简洁起见已截断):
|
1 2 3 4 |
{ 'validation_0': {'error': [0.259843, 0.26378, 0.26378, ...]}, 'validation_1': {'error': [0.22179, 0.202335, 0.196498, ...]} } |
“validation_0” 和 “validation_1” 分别对应于调用 fit() 时提供给 eval_set 参数的数据集顺序。
特定结果数组,例如第一个数据集和误差指标,可以按如下方式访问:
|
1 |
results['validation_0']['error'] |
此外,我们可以通过向 fit() 函数的 eval_metric 参数提供一个指标数组来指定更多的评估指标进行评估和收集。
然后我们可以使用这些收集到的性能度量来创建折线图,并进一步了解模型在训练时期内在训练集和测试集上的表现。
下面是显示如何将收集到的结果可视化为折线图的完整代码示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
# 绘制学习曲线 从 numpy 导入 loadtxt from xgboost import XGBClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from matplotlib import pyplot # 加载数据 dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",") # 将数据拆分为 X 和 y X = dataset[:,0:8] Y = dataset[:,8] # 将数据拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.33, random_state=7) # 拟合模型,无训练数据 model = XGBClassifier() eval_set = [(X_train, y_train), (X_test, y_test)] model.fit(X_train, y_train, eval_metric=["error", "logloss"], eval_set=eval_set, verbose=True) # 对测试数据进行预测 y_pred = model.predict(X_test) predictions = [round(value) for value in y_pred] # 评估预测 accuracy = accuracy_score(y_test, predictions) print("Accuracy: %.2f%%" % (accuracy * 100.0)) # 检索性能指标 results = model.evals_result() epochs = len(results['validation_0']['error']) x_axis = range(0, epochs) # 绘制对数损失 fig, ax = pyplot.subplots() ax.plot(x_axis, results['validation_0']['logloss'], label='Train') ax.plot(x_axis, results['validation_1']['logloss'], label='Test') ax.legend() pyplot.ylabel('Log Loss') pyplot.title('XGBoost Log Loss') pyplot.show() # 绘制分类误差 fig, ax = pyplot.subplots() ax.plot(x_axis, results['validation_0']['error'], label='Train') ax.plot(x_axis, results['validation_1']['error'], label='Test') ax.legend() pyplot.ylabel('Classification Error') pyplot.title('XGBoost Classification Error') pyplot.show() |
运行此代码会报告每个时期在训练和测试数据集上的分类错误。我们可以通过在调用 fit() 函数时将 verbose=False(默认值)来关闭此功能。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
创建了两个图。第一个显示了 XGBoost 模型在训练和测试数据集上每个时期的对数损失。
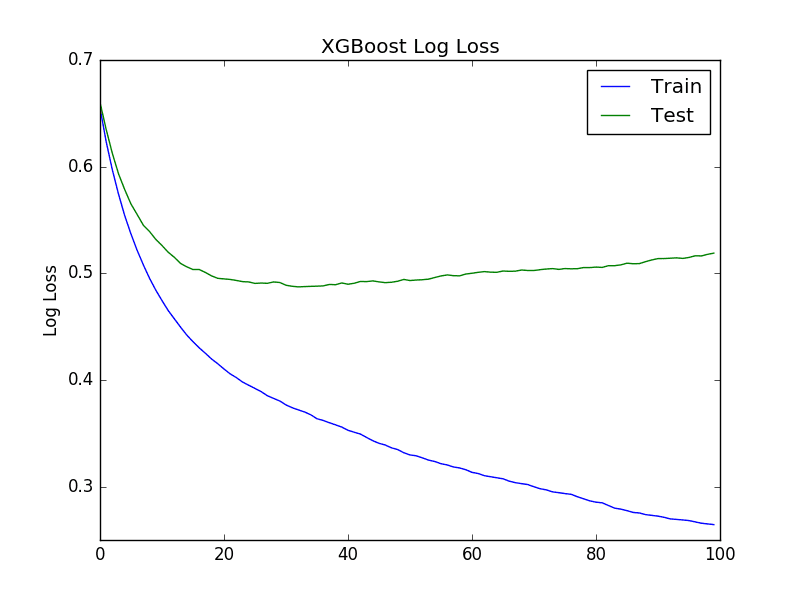
XGBoost 学习曲线对数损失
第二个图显示了 XGBoost 模型在训练和测试数据集上每个时期的分类错误。
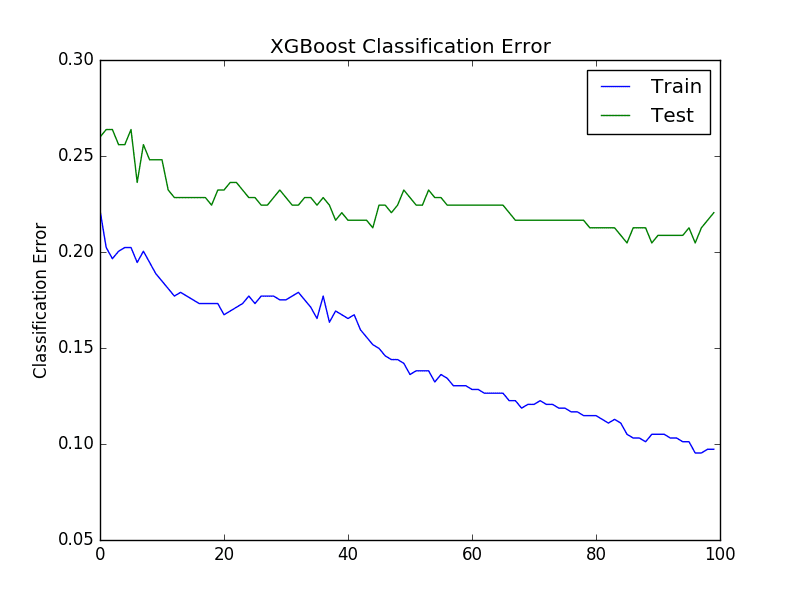
XGBoost 学习曲线分类误差
从对数损失图来看,似乎有机会提前停止学习,可能在大约 20 到 40 个时期左右。
分类错误也出现了类似的情况,在大约 40 个时期时错误似乎又回升了。
使用 XGBoost 提前停止
XGBoost 支持在固定数量的迭代后提前停止。
除了指定每个时期评估的度量和测试数据集之外,您还必须指定在固定数量的时期内未观察到改进的窗口。这在 early_stopping_rounds 参数中指定。
例如,我们可以检查在 10 个时期内对数损失没有改进,如下所示:
|
1 2 |
eval_set = [(X_test, y_test)] model.fit(X_train, y_train, early_stopping_rounds=10, eval_metric="logloss", eval_set=eval_set, verbose=True) |
如果提供了多个评估数据集或多个评估指标,则提前停止将使用列表中的最后一个。
下面提供了带有提前停止功能的完整示例,以供参考。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 提前停止 从 numpy 导入 loadtxt from xgboost import XGBClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # 加载数据 dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",") # 将数据拆分为 X 和 y X = dataset[:,0:8] Y = dataset[:,8] # 将数据拆分为训练集和测试集 seed = 7 test_size = 0.33 X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed) # 拟合模型,无训练数据 model = XGBClassifier() eval_set = [(X_test, y_test)] model.fit(X_train, y_train, early_stopping_rounds=10, eval_metric="logloss", eval_set=eval_set, verbose=True) # 对测试数据进行预测 y_pred = model.predict(X_test) predictions = [round(value) for value in y_pred] # 评估预测 accuracy = accuracy_score(y_test, predictions) print("Accuracy: %.2f%%" % (accuracy * 100.0)) |
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
运行示例会提供以下输出,为简洁起见已截断。
|
1 2 3 4 5 6 7 8 9 10 11 |
... [35] validation_0-logloss:0.487962 [36] validation_0-logloss:0.488218 [37] validation_0-logloss:0.489582 [38] validation_0-logloss:0.489334 [39] validation_0-logloss:0.490969 [40] validation_0-logloss:0.48978 [41] validation_0-logloss:0.490704 [42] validation_0-logloss:0.492369 停止中。最佳迭代 [32] validation_0-logloss:0.487297 |
我们可以看到模型在第 42 个时期停止训练(接近我们根据学习曲线手动判断的预期),并且在第 32 个时期观察到具有最佳损失的模型。
通常,最好将 early_stopping_rounds 选择为训练时期总数(本例中为 10%)的合理函数,或者尝试与学习曲线图上可能观察到的拐点周期相对应。
总结
在这篇文章中,您了解了性能监控和提前停止。
您学到了
- 关于提前停止技术,以在模型过拟合训练数据之前停止模型训练。
- 如何监控 XGBoost 模型在训练过程中的性能并绘制学习曲线。
- 如何配置 XGBoost 模型训练时的提前停止。
您对过拟合或本文有任何疑问吗?请在评论中提出您的问题,我将尽力回答。
发现赢得竞赛的算法!

在几分钟内开发您自己的 XGBoost 模型
...只需几行 Python 代码
在我的新电子书中探索如何实现
使用 Python 实现 XGBoost
它涵盖了自学教程,例如:
算法基础、缩放、超参数等等……
将 XGBoost 的强大功能带入您自己的项目
跳过学术理论。只看结果。






嗨,Jason,
感谢简洁明了的解释。
请问您能详细阐述以下几点吗?
1. 如果训练误差高于测试误差,我们应该怎么做?
2. 除了提前停止,我们如何有效地调整正则化参数?
我很高兴你觉得它们有用,shivam。
有趣的问题。理想情况下,我们希望训练和测试的误差都很好。通常,训练误差会比测试误差略低。如果反过来,那可能是一个偶然现象,也是欠学习的迹象。
试错。我发现采样方法(随机梯度提升)作为 XGBoost 中的正则化非常有效,更多信息在这里:
https://machinelearning.org.cn/stochastic-gradient-boosting-xgboost-scikit-learn-python/
嗨,Jason,
非常感谢您的所有帖子。您的网站真的帮助我入门了。
快速提问:eval_metric 和 eval_set 参数除了 XGBoost 之外,是否适用于其他模型(例如 KNN、LogReg 或 SVM)的 .fit()?
另外,这些参数是否可以在网格/随机搜索中使用?例如,grid_search.fit(X, y, eval_metric "error", eval_set= […. ….] )
谢谢 Andy。
这些参数是 XGBoost 特有的。
这是一个网格搜索 XGBoost 的示例:
https://machinelearning.org.cn/tune-learning-rate-for-gradient-boosting-with-xgboost-in-python/
嗨,Jason,
感谢您的这篇帖子,它非常实用且清晰。
如果我的任务通过另一个指标(如 F-score)进行衡量,我们会在损失学习曲线中还是在这个新指标中找到最佳时期?它们是否成比例,即使与准确率相比?
我建议使用新的指标,但可以尝试两种方法并比较结果。
根据数据做出决策。
嗨 Jason
感谢您的分享!
我有一个问题,因为 Python API 文档提到:
```
提前停止返回的是最后一次迭代的模型(而不是最佳模型)。如果发生提前停止,模型将有三个额外的字段:bst.best_score、bst.best_iteration 和 bst.best_ntree_limit。
```
所以,当提前停止发生时,我们得到的模型可能不是最佳模型,对吗?
我们如何获得那个最佳模型?
嗨,Jimmy,
提前停止可能不是获取“最佳”模型的最佳方法,无论您如何定义它(训练或测试性能和指标)。
您可能需要编写一个自定义回调函数,以便在模型得分低于迄今为止观察到的最佳得分时保存模型。
抱歉,我没有示例,但我预计您将需要使用原生的 XGBoost API 而不是 sklearn 包装器。
嗨,Jimmy,
最佳模型(相对于 eval_metric 和 eval_set)在 bst.best_ntree_limit 中可用。您可以调用以下方法进行预测:
bst.predict(X_val, ntree_limit=bst.best_ntree_limit)
另请参阅预测部分:
http://xgboost.apachecn.org/en/latest/python/python_intro.html?highlight=early%20stopping#early-stopping
祝好,
马库斯
很好,谢谢分享。
实际上,当调用 xgb 估计器的 predict 方法时,默认会使用最佳模型。该方法的文档说明:
“ntree_limit (int) – 限制预测中的树的数量;如果已定义(即已使用提前停止进行训练),则默认为 best_ntree_limit,否则为 0(使用所有树)。”
向这里的最佳答案致敬:https://stackoverflow.com/a/53572126/13165659
太棒了,谢谢!
你选择了提前停止回合数为 10,但为什么总共达到了 42 个时期。既然你说最好的可能不是最好的,那我如何控制最终模型中的时期数量?
好问题,shud,
提前停止只有在 10 个时期内没有改进时才会触发。它不是对时期总数的限制。
既然模型在第 32 个时期停止了,我的模型就训练到那个时候,我的预测是基于 32 个时期的吗?
正确。
嗨,Jason,
我有一个关于使用测试集进行提前停止以避免过拟合的问题…
难道不应该使用训练集吗?我们难道不应该只使用测试集来测试模型,而不是用于优化模型吗?(我认为提前停止是一种模型优化)
此致,
G
提前停止使用单独的数据集,例如测试或验证数据集,以避免过拟合。
如果只使用训练数据集,我们就无法获得提前停止的好处。我们怎么知道何时停止?
我原以为当训练集上的性能在 xx 轮中没有提高时就停止,以避免创建太多无用的树。然后使用选定的估计器数量来计算测试集上的性能。否则,我们可能会冒着使用过于乐观的结果来评估模型的风险。也就是说,我们可能会得到非常高的 AUC,因为我们选择了最佳模型,但在我们没有标签的真实世界实验中,我们的性能会大大下降。在评估集上使用提前停止是合法的..您能详细阐述并给出您的意见吗?
谢谢你
PS 我真的很喜欢你的帖子..
简而言之,我的观点是:如果(原则上)我们应该只使用测试集的标签来评估模型的结果,而不是进一步“训练/优化”模型,那么我们如何才能在测试集上使用提前停止?
通常我们会将数据分成训练/测试/验证集以避免乐观的结果。
根据我的经验,我完全同意 G 的观点。Jason,我认为同时使用测试集进行提前停止和预测是不正确的。
致以最诚挚的问候。
嗨,Jason,我同意。但是你在你的帖子里写道:
“它通过监控模型在单独测试数据集上的性能来工作,一旦测试数据集上的性能在固定数量的训练迭代后没有改进,就停止训练过程。
它通过尝试自动选择拐点来避免过拟合,在该拐点处,测试数据集上的性能开始下降,而训练数据集上的性能随着模型开始过拟合而继续提高。”
这可能会导致在最终测试集上使用提前停止的错误,而它应该在验证集上使用,或者直接在训练集上使用以避免创建过多的树。
你能证实这一点吗?
此致
提前停止需要两个数据集,一个训练集和一个验证集或测试集。
你好,先生,
感谢您的出色工作。先生,我将您的代码适配到我的数据集中,我的“validation_0”错误始终为零,只有“validation_1”错误发生变化。先生,这意味着什么?谢谢您,致以诚挚的问候。
抱歉,我不太明白。
也许您可以提供更多细节或一个示例?
很抱歉一开始没有表达清楚。我使用了你的 XGBoost 代码,validation_0 一直保持为 0,而 validation_1 在整个训练过程中也一直保持为 0.0123 的常数值。我只是想请教一下为什么它是常数。致以诚挚的问候。
这很奇怪。
尝试不同的配置,尝试不同的数据。看看情况是否会改变。你可能需要稍加探索来调试问题。
[56] validation_0-error:0 validation_0-logloss:0.02046 validation_1-error:0 validation_1-logloss:0.028423
[57] validation_0-error:0 validation_0-logloss:0.020461 validation_1-error:0 validation_1-logloss:0.028407
[58] validation_0-error:0 validation_0-logloss:0.020013 validation_1-error:0 validation_1-logloss:0.027592
停止中。最佳迭代
[43] validation_0-error:0 validation_0-logloss:0.020612 validation_1-error:0 validation_1-logloss:0.027545
准确率:100.00%
非常好!
感谢您的辛勤工作,先生。
很高兴它有帮助。
感谢您的帖子!
谢谢 davalo,很高兴能帮到你。
嗨,Jason,我有一个关于提前停止的问题。
在保存了达到最佳验证误差的模型(例如在第 50 个时期)后,我如何利用这些知识重新训练它(以获得更好的结果)?
在训练集和验证集的混合数据上,考虑到这 50 个时期,重新训练模型并期望再次获得最佳结果是否有效?我知道在添加更多示例后可能会出现一些差异,但考虑到数据集基数的标准比例值(训练集=0.6,交叉验证集=0.2,测试集=0.2),使用验证数据重新训练模型足以破坏我之前 50 个时期的结果吗?在机器学习竞赛中,最好的实践是什么?
另一个快速问题:您如何管理用于超参数化和提前停止的验证集?您使用相同的集合吗?
非常感谢,Markos。
好问题。
没有明确的答案,你必须进行实验。
也许你可以训练 5-10 个模型,每个模型训练 50 个时期,然后将它们集成。也许可以将集成结果与通过提前停止找到的最佳模型进行比较。
我将训练集分成训练集和验证集,请参阅这篇帖子:
https://machinelearning.org.cn/difference-test-validation-datasets/
谢谢你的回答。很高兴能有像您这样知识渊博的人来回答我们的问题。
输出结果是
停止中。最佳迭代
[32] validation_0-logloss:0.487297
如何将 32 提取到一个变量中,即保留 32 的值,这样我就知道它是最佳步数?我显然可以看到屏幕并将其写下来,但如何用代码实现呢?
例如,我可能想运行几个不同的交叉验证,并将迭代次数平均在一起。
好问题,我暂时不确定。将输出管道化到日志文件并解析它会很糟糕(例如,一个笨拙的解决方案)。
首先考虑你为什么需要知道时期——也许思考这一点会揭示获取最终结果的其他方法。
通常,我建议编写自己的钩子来监控时期和自己的提前停止,这样你就可以记录你需要的一切——例如,模型和时期编号。
XGBoost API 中提到,一旦您使用“early_stopping”,就会添加 3 个变量,
bst.best_score
bst.best_iteration
bst.best_ntree_limit
第二个和第三个是最后几次迭代。其中一个就是您想要的数字。
引自 API:
“如果发生提前停止,模型将有三个额外的字段:bst.best_score、bst.best_iteration 和 bst.best_ntree_limit。(如果参数中出现 num_parallel_tree 和/或 num_class,请使用 bst.best_ntree_limit 获取正确的值)”
谢谢 Eran。
你好,Jason Brownlee!
您知道如何使用模型在提前停止中产生的最佳迭代吗?
[42] validation_0-logloss:0.492369
停止中。最佳迭代
[32] validation_0-logloss:0.487297
我如何使用模型直到第 32 次迭代?
或者我应该重新训练一个新模型并设置 n_epoach = 32 吗?
我会训练一个有 32 个时期的新模型。
嗨 Jason,你提到了训练一个有 32 个时期的新模型……但是 XGBclassifier 既没有 n_epoch 参数,也没有 model.fit 有这样的参数……那么,如果我的 best_iteration 是 900,那么在重新训练模型时,我如何将其指定为时期数呢?
啊,是的,回合数是以树的添加(n_estimators)来衡量的,而不是以时期来衡量的。
嗨,Jason,
非常感谢您提供的本教程以及所有其他教程。它们是我进行数据科学研究的首选资源。
我有一个关于 XGBoost 交叉验证和提前停止的问题。我正在使用 sklearn 的随机网格搜索交叉验证实现来调整 XGBRegressor 模型的参数。我还想使用提前停止。我的想法是,最好使用每个交叉验证迭代中的验证集作为“eval_set”来决定是否触发提前停止。但是,在调用 fit 方法时,我无法通过标准的 sklearn 实现访问每个交叉验证循环的测试集。
为了用代码解释这一点,目前我在网格搜索对象上调用 .fit 时是这样调用的:
model.fit(X_train, y_train, early_stopping_rounds=20, eval_metric = “mae”, eval_set = [[X_test, y_test]])
其中 X_test 和 y_test 是之前保留的集合。问题在于,这会根据完全依赖的测试集评估提前停止,而不是根据所讨论的交叉验证折叠的测试集(这将是训练集的一个子集)。除了编写我自己的网格搜索模块之外,您知道有什么方法可以访问交叉验证循环的测试集吗?
再次感谢!
抱歉,我没有将这两种方法结合起来。通常我使用提前停止来估计交叉验证期间停止训练的好时机。
您可能需要稍作尝试才能知道是否可行。
嗨,Jason,
感谢您的本教程。
我只有一个问题,关于提前停止和交叉验证(例如 k 折交叉验证)之间的关系。
对于每个折叠,我训练模型并监控其在验证数据集上的性能(假设我们正在使用迭代算法)。通过提前停止,当验证误差在几次后续迭代中增长时,训练过程就会中断(希望如此)。
因此,每个折叠中考虑的性能是指相对于验证数据集观察到的最小误差,对吗?
然后,我们对所有折叠的性能进行平均,以了解该特定模型执行任务和泛化的效果。
最后,在我们确定了最佳总体模型之后,我们应该如何精确地构建最终模型,即将在实践中使用的模型?
我的意思是,如果我们使用整个数据集重新训练模型并让训练算法进行到收敛(即直到达到最小训练集),我们是否会过拟合它?
我不知道我的问题是否足够清楚……但我仍然无法完全理解——对于通过迭代过程(例如,MLP 网络)训练的模型,我们如何构建最终模型以避免过拟合。
交叉验证后不再使用提前停止了吗?为什么?
谢谢您的关注
是的,折叠的性能将在训练停止时达到。然后可以对这些分数进行平均。
最终模型将在所有数据和用于停止标准的保留验证集上训练时使用提前停止进行拟合。
实际上,我从昨天开始一直在思考,这确实很有意义。
但是我们必须将这个“最终”验证集分开来拟合最终模型,对吗?
此外,还会有一个测试集(与之前使用的任何其他数据集都不同)来评估最终训练模型的预测,对吗?
再次感谢!
理想情况下,验证集应与所有其他测试分开。
更弱地说,您可以合并所有数据,并为最终模型划分新的训练/验证集。
最佳迭代是第一次迭代,你会感到震惊吗?
这可能意味着什么?
这可能意味着数据集很小,或者问题很简单,或者模型很简单,或者很多事情。
假设数据集很大,问题很困难,而且我尝试过使用不同的复杂模型。由于是时间序列数据集,我每天都在回测中重新训练,有些模型训练时最佳树是 10,有些则只选择第一个。接下来你会怎么做来深入研究这个问题?
我通常规避风险。我计算某个方法的平均性能,然后使用集成方法(例如多次运行)来减少方差,以确保我能够持续地达到最低限度。
对于一个增强回归树,您将如何估计模型预测的不确定性?目前我正在使用评估集并从中获取误差,但理想情况下,我希望误差是动态的,并随着进入 xgboost 模型的特征而变化。Python xgboost 实现中是否有办法查看数据最终所在的叶节点,然后获取最终在同一叶节点中的所有数据点的方差?
通常,我会使用 bootstrap 来估计置信区间。
有关置信区间的更多信息,请参见此处:
https://machinelearning.org.cn/confidence-intervals-for-machine-learning/
嗨 Jason
我正在为一个项目研究不平衡的多类别分类,并使用 xgboost 分类器作为我的模型。
您的文档对我的项目有很大的帮助!!
我还有一些问题,希望您能给我一些宝贵的建议!
首先,我的数据非常不平衡,有 43 个目标类别。
我有大约 10,000,000 个数据集,但有些目标类别只有 100 个数据。
目前,我的模型准确率为 84%,我仍在努力改进它。
现在我正在使用 XgbClassifier 的基本参数(使用 multi::prob,mlogloss 作为我的 obj 和 eval_metric)。
有没有什么选项或建议可以帮助我改进模型??
此外,为了改进我的模型,我尝试为我的 xgboost 模型定制损失函数,并找到了 focal loss (https://github.com/zhezh/focalloss/blob/master/focalloss.py)。
但我不知道如何将自定义损失函数实现到 xgboost 中。
实际上我找到了一些代码示例,但解释不够充分……
由于我的数据集太大,整个数据集无法放到我的 GPU 上。因此尝试分割我的数据并尝试对模型进行增量学习。
然而,它似乎没有增量学习,并且测试集上的模型准确性根本没有提高。
您能针对我的情况提供任何建议吗?
感谢您的关注,希望您能回复我的问题!!
我在这里提供关于处理不平衡数据的建议:
https://machinelearning.org.cn/tactics-to-combat-imbalanced-classes-in-your-machine-learning-dataset/
非常感谢作者!
不客气,我很高兴它有所帮助。
使用 AUC 指标进行分类问题。对案例的“顺序”感兴趣。数据集分为训练集和验证集 (75:25)。提前停止基于验证 AUC。得到不错的结果。
案例 1
始终使用最近历史的测试集,而整个数据集代表更长的历史。测试数据集上的预测合理,但不如验证数据集好。
案例 II
如果我将测试集中的案例包含在验证集中,并进行训练直到验证 AUC 停止改进,那么对于相同的案例(现在包含在验证集中的测试案例),预测会好得多。
我的期望是,无论是在验证集中还是测试集中,最近历史的预测都应该给出相同的结果,但事实并非如此。还注意到,在这两种情况下,下半部分“顺序”几乎相似,但上半部分“顺序”有显著变化。您能帮忙解释一下这是怎么回事吗?
抱歉,我不太明白,您能进一步总结您的问题吗?
案例一:通过使用验证数据集监控 eval_metric 进行提前停止训练得到的模型,在对测试数据集进行预测时会给出某些结果。
案例二:然而,当将相同测试数据集的观测值包含在验证集中并按上述方式训练模型时,对这些观测值(案例一中现在包含在案例二验证数据集中的测试数据)的预测要好得多。
我预期两种情况下的预测结果应该相似,您能帮我澄清一下吗?
如果您需要更多信息,请参阅原始问题,也许会更清楚。
模型不应该在验证数据集上进行训练,并且测试集不应该用作验证数据集。也许你把事情搞混了,这可能有助于理清思路:
https://machinelearning.org.cn/difference-test-validation-datasets/
谢谢,我会仔细阅读链接。
然而,在这两种情况下,模型都是仅使用训练集进行训练的。
我用 75% 的数据训练模型,并在每一轮之后使用我称之为验证集(在本教程中称为测试集)来评估模型(用于提前停止)。很抱歉表述不清。
看完链接后,我总结了三点您可能会回应的观点。
“如果您多次使用验证集,可能会有点过拟合?”
(您在引用中提到的链接中,您在 2018 年 6 月 1 日上午 8:13 的回复 #)
“也许测试集与训练/验证集确实不同,例如,它更能/更少代表问题?”
(您在引用中提到的链接中,您在 2018 年 6 月 1 日上午 8:13 的回复 #)
“由于验证数据集上的技能被纳入模型配置中,评估变得更具偏差。”
(摘自您在引用中提到的链接中对验证数据集的定义。)
我的回复依次是:
——在我的案例中,验证集在模型构建的不同实例之间从不相同,因为我尝试了属性、参数等的选择。
——整个数据在 20 年间是连续的。测试集并非随机,而是最近历史的一小部分。根据领域知识,我排除了测试集片段与训练集和验证集中的大部分数据有任何不同的可能性。
——我的预期是,偏差是通过算法选择和训练集引入的。如果我使用 GBM,我期望模型在随后的轮次中基于对训练数据集的预测残差进行训练。验证集只会影响评估指标和最佳迭代/轮次。我的理解正确吗?
我不太明白。
是的——一般来说,在重复运行中重用训练集和/或验证集会给模型选择过程带来偏差。
你好,
感谢约翰的教程,
我尝试在我的数据上运行您的源代码,但我遇到了问题。
我得到:[99] validation_0-rmse:0.435455
但是当我尝试:print(“RMSE : “, np.sqrt(metrics.mean_squared_error(y_test, y_pred)))
在预测之后我得到 0.5168
我如何才能获得最佳分数?
有没有类似“best_estimator_”的方法来获取最佳迭代的参数?
再次感谢
一种方法是使用通过提前停止找到的指定迭代次数重新运行。
非常感谢 Jason 的回复,现在一切正常。
很高兴听到这个消息!
嗨,Jason,
我不能使用 GridSearchCV 来同时找到最佳超参数和最佳树的数量(n_estimators)吗?如果我事先知道最佳超参数,那么我可以使用提前停止来确定所需的最佳树的数量。但既然我事先不知道它们,我认为将 n_estimators 包含在参数网格中会更容易。
我的模型不是很大(4 个特征和 400 个实例),因此进行详尽的 GridSearchCV 并不是一个计算成本很高的问题。但我不想错过提前停止可能带来的任何额外优势(我可能遗漏了)。以下是我所指的示例代码:
xgb_model = xgb.XGBRegressor(random_state=42)
## 对模型进行网格搜索
reg_xgb = RandomizedSearchCV(xgb_model,{‘max_depth’: [2,4,5,6,7,8],’n_estimators’: [50,100,108,115,400,420],’learning_rate'[0.001,0.04,0.05,0.052,0.07]},random_state=42,cv=5,verbose=1,scoring=’neg_mean_squared_error’)
reg_xgb.fit(X_train, y_train)
这给了我一组最佳的超参数,它们在训练集上表现良好(例如,最低的 MSE),包括 n_estimators(在我的例子中是 115)。现在我在验证集上使用这个模型(我正在使用训练集、验证集和测试集),并估计验证集上的 MSE,如果我不能通过调整 n_estimators 来进一步降低这个 MSE,我将把它视为我的最佳模型,并用它来预测测试集。
所以我看不出提前停止能给我带来什么好处,如果我事先不知道最佳超参数的话。请问我采取的方法是否正确,以及提前停止是否能帮助我省去一些额外的麻烦。
是的,提前停止可以是您正在测试的“系统”的一个方面,只要其用法是恒定的。
通常它会导致问题/令人困惑,所以我建议不要使用它。
根据 SKLearn API(XGBClassifier 是其一部分)的文档,当指定 early_stopping_rounds 参数时,fit 方法返回的是最新迭代的模型,而不是最佳迭代的模型。以下是引用:
“该方法返回最后一次迭代的模型(而不是最佳迭代的模型)。”
是的,正如所提到的,你可以使用结果来指示在第二次运行中训练时使用的时期数。
嗨,Jason,首先感谢您分享您的知识。
我有一个回归问题,我正在使用 XGBoost 回归器。我想知道回归器模型是否提供 evals_result(),因为我收到了以下错误:
AttributeError: ‘Booster’ object has no attribute ‘evals_result’
不客气。
抱歉,我以前从未见过这个错误,也许可以尝试在 Stack Overflow 上提问?
嗨,Jason,
非常感谢您的教程!
一个问题,为什么您同时使用对数损失和误差作为指标?
好问题。我猜对于这个例子来说,只使用对数损失就足够了。也许你可以试试看!
嗨
我可以在交叉验证中使用提前停止吗?
专注于循环交叉验证。结果是 model.best_score、model.best_iteration、model.best_ntree_limit
这适用吗?
结果如下:
1. EaslyStop- 最佳误差 7.12% – 迭代次数:58 – 树限制:59
2. EaslyStop- 最佳误差 16.55% – 迭代次数:2 – 树限制:3
3. EaslyStop- 最佳误差 16.67% – 迭代次数:81 – 树限制:82
代码如下:
kfold = KFold(n_splits=3, shuffle=False, random_state=1992)
for train, test in kfold.split(X)
X_train, X_test = X[train, :], X[test, :]
y_train, y_test = y[train], y[test]
eval_set = [(X_train, y_train), (X_test, y_test)]
model.fit(X_train, y_train, eval_metric=”error”,
eval_set=eval_set,verbose=show_verbose,early_stopping_rounds=50)
print(f’EaslyStop- 最佳误差 {round(model.best_score*100,2)}% – 迭代次数:
{model.best_iteration} – 树限制:{model.best_ntree_limit}’)
好问题,我在这里回答了:
https://machinelearning.org.cn/faq/single-faq/how-do-i-use-early-stopping-with-k-fold-cross-validation-or-grid-search
嗨,Jason,
我绘制了测试误差和训练误差与周期(len(results['validation_0']['error']))的关系图,以比较它们的性能。然而,我不确定如果我想评估模型在过拟合或欠拟合方面表现,X轴上应该是什么参数。我知道学习曲线,但我需要包含一些显示模型整体性能的图表,而不是针对超参数的。我一如既往地感谢您的帮助。
也许是算法迭代?
你能详细说明一下吗?或者有没有一个示例图表示模型的整体性能?
这是我根据您在教程中解释的内容绘制的图表。
https://flic.kr/p/2kd6gwm
是的,每次算法迭代都涉及向集成中添加一棵树。
根据图表,模型是否过拟合?或者这个图表没有说明模型是否过拟合/欠拟合?
我对这类图表的不同解释感到非常困惑。
本教程可以帮助您解释该图表。
https://machinelearning.org.cn/learning-curves-for-diagnosing-machine-learning-model-performance/
我通过将
early_stopping_rounds从10增加到50获得了更好的性能,并且max_iteration是2000,在这种情况下,使用early_stopping_rounds= 50训练的模型会有过拟合问题吗?干得好。
不会,使用效果最好的即可。
嗨
在Catboost的.fit方法中,我们有一个参数use_best_model。由于我们在这里的XGBoost中实现了提前停止,我们是否有这样的参数可以使用最佳模型?
我不这么认为,您可以查看API文档进行确认。
你好,Jason。
感谢这篇帖子。这是我读过最好的帖子之一。我已经订阅了你的邮件列表 😀
另一方面,我用其他算法做过模型,我有一个问题。我正在尝试训练一个模型,但传统模型并没有获得很高的准确度(虽然不差,但我们需要更多)。然而,在这种情况下,测试集和训练集表现得非常好(我们看到了很多稳定性)。使用本文,我创建了一个XGBoost,结果更好,但即使使用了提前停止条件,训练集和测试集之间仍有20%的差异。而其他算法则没有这种情况。您对XGBoost参数有什么建议可以继续避免过拟合吗?
谢谢!
提前停止只能用于渐进式拟合的算法,如决策树集成和神经网络。它只对那些容易过拟合的模型有帮助,如xgboost和神经网络。
嗨,Jason。我感谢您在这个领域的贡献。您的方法和材料对我们所有人都有很大的帮助!
我有一个问题。当您在sklearn中使用预处理管道时,“提前停止”过程是否可能实现?详细来说
我看到的所有提前停止的例子都是在拟合步骤开始时进行数据拆分,生成训练集和测试集。但在我正在处理的情况下,我在sklearn中创建了一个管道来预处理数据(填充、缩放、热编码等)。估计器(例如xgboost)是该管道的一部分。我使用GridsearchCV来调整超参数,并希望知道如何使用“early_stopping”来在高树数量时减少不必要的步骤。
当然,可以对初始数据集运行fit_transform进行填充、缩放、热编码,然后拆分该数据集以使用您文章中描述的方法,但我了解到这样做可能会导致数据泄露,最好在CV中使用管道,其中预处理(如缩放)只在每次CV迭代的训练折叠上完成。但那样的话,我该如何在那种情况下使用early_stopping呢?因为我没有看到任何与这种情况相关的参数,尤其是在GridsearchCV中的fit_params已被删除的情况下。
我不这么认为。您可能需要编写自定义代码。
感谢这个精彩的博客,假设我们进行50次迭代,如果我设置early_stopping_rounds = 10,这意味着我们的模型将在10次迭代后尝试找到没有改进的迭代,比如它在1-10次迭代中没有找到没有改进的迭代,但在10-50次迭代之间找到了没有改进的迭代,这就是early_stopping_rounds所指示的,我理解对吗?即使这是个愚蠢的问题,抱歉。
谢谢♥️
不客气。
如果您将轮次设置为10,那么它将在任意连续10个周期内寻找没有改进的情况。
嗨,Jason,
在使用GridSearchCV时,如何设置early_stopping_rounds?
提前感谢您!
也许可以尝试不同的配置,并找出在保留测试数据集上产生最佳性能的配置。
嗨,Jason,
我已经将你的代码应用到pima indians数据集上。我有一个关于对数损失图的问题。
你指出在大约20-40个epoch时可以停止,因为测试集上的对数损失没有减少。我应该如何解释一条不达到平台期,反而增加的测试线?这是否意味着存在严重的过拟合,我应该重新训练我的模型?
或者我可以在对数损失开始增加的点(在此图中的点7-8左右:https://imgur.com/zCDOlZA)处截断吗?
这可能意味着过拟合,这可以帮助您解释图表。
https://machinelearning.org.cn/learning-curves-for-diagnosing-machine-learning-model-performance/
嗨,Jason,
您的内容太棒了!非常感谢!
我有一个问题,如果我们在XGBoost上使用超参数调优,并且搜索空间中的一个超参数是估计器数量/树的数量,我们还需要提前停止吗?如果训练过程的每个时期/迭代/轮次都添加一棵树,并且我们在优化树的数量,这难道不等同于提前停止吗?
再次感谢
嗨,Jose……以下内容可能对您有帮助
https://mljar.com/blog/xgboost-early-stopping/
谢谢你,詹姆斯!
所以,如果我理解正确,我的问题的答案是:估计器数量是树的最大数量,如果我们使用提前停止,可能无法达到这个数量。因此,使用超参数调优和估计器数量与使用提前停止是不同的。
这些例子是不正确的。性能是在一个测试集上测量的,而XGBoost算法已经反复使用该测试集来测试提前停止。反复使用测试集会造成大规模的数据泄露和卫生问题,正如Brownlee在其他帖子中指出的那样。解决这个问题的最简单方法是使用scikit-learn中的GradientBoostingClassifier。您所需要做的就是将validation_fraction参数设置为0.2,它将从训练数据中选择验证拆分,而不会造成数据泄露。或者这里的示例应该修改为
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.33, random_state=7)
X_train, X_val, y_train, y_val = train_test_split(X_train, X_test, test_size=0.2, random_state=7)
model = XGBClassifier()
eval_set = [(X_val, y_val)]
model.fit(X_train, y_train, eval_metric=”error”, eval_set=eval_set, verbose=True)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
感谢您的反馈和建议,John!我们很感激。
更一般地说,每当我们使用提前停止时,我们是否必须在一个单独的、未见过的、隔离的数据集上评估模型,该数据集既未用于训练模型,也未用于确定提前停止?
嗨!
我一直在调整我的回归超参数,并获得了测试集0.85的r2值(使用5折交叉验证)。然而,我的折叠产生的r2值变异性很高,我检查了我的训练r2,训练集为0.99…哦不。
这种方法通常除了调整超参数之外还会使用吗?它对回归问题也同样适用吗?
谢谢
嗨,roza……交叉验证分数的高度变异性和训练R²明显高于测试R²通常表明存在过拟合。在回归问题中,采用与分类任务类似的超参数调优和模型评估策略。以下是一些有助于解决此问题并确保模型性能稳健的步骤:
### 解决回归中过拟合和高变异性的步骤
1. **特征工程和选择:**
– 确保模型中使用的特征相关且不引入噪声。
– 考虑使用主成分分析 (PCA) 或特征选择方法来降低模型的维度和复杂性。
2. **正则化:**
– Ridge (L2) 或 Lasso (L1) 等正则化技术可以通过惩罚大系数来帮助减少过拟合。
– 使用交叉验证来调整正则化参数。
3. **模型复杂度:**
– 如果模型过于复杂,请简化它。例如,如果使用多项式回归,请考虑降低多项式次数。
– 评估不同类型的模型,例如线性回归、决策树或集成方法(如随机森林或梯度提升),以找到偏差和方差之间的最佳平衡。
4. **交叉验证策略:**
– 使用更高折叠数(例如,10折而不是5折)的K折交叉验证,以获得更可靠的模型性能估计。
– 分层K折交叉验证可确保每个折叠都代表整体分布,这有助于减少变异性。
5. **超参数调优:**
– 使用网格搜索或随机搜索进行超参数调优,并在搜索过程中结合交叉验证,以确保为泛化选择最佳参数。
– 考虑使用更高级的技术,如贝叶斯优化或遗传算法进行超参数调优。
6. **集成方法:**
– 组合多个模型(bagging、boosting、stacking)可以通过减少方差来提高稳定性和性能。
7. **验证曲线:**
– 绘制验证曲线以可视化不同超参数对训练和验证分数的影响。这有助于确定模型何时开始过拟合。
8. **学习曲线:**
– 绘制学习曲线以诊断更多训练数据是否有助于减少过拟合并提高模型性能。
– 学习曲线显示了作为训练集大小函数的训练和验证性能。
### 实际实现
以下是使用
scikit-learn在Python中实现其中一些策略的示例:pythonimport numpy as np
from sklearn.model_selection import train_test_split, KFold, cross_val_score, GridSearchCV
from sklearn.linear_model import Ridge
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.metrics import r2_score
import matplotlib.pyplot as plt
# 示例数据
X, y = load_your_data() # 替换为您的数据加载函数
# 拆分数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 带有StandardScaler和Ridge回归的管道
pipeline = Pipeline([
('scaler', StandardScaler()),
('regressor', Ridge())
])
# 为GridSearchCV定义参数网格
param_grid = {
'regressor__alpha': [0.01, 0.1, 1, 10, 100]
}
# 带有交叉验证的网格搜索
grid_search = GridSearchCV(pipeline, param_grid, cv=10, scoring='r2')
grid_search.fit(X_train, y_train)
# 最佳参数和分数
print("最佳参数:", grid_search.best_params_)
print("最佳交叉验证分数 (R²):", grid_search.best_score_)
# 在测试集上评估
y_pred = grid_search.predict(X_test)
test_r2 = r2_score(y_test, y_pred)
print("测试集 R²:", test_r2)
# 学习曲线
train_sizes, train_scores, val_scores = learning_curve(pipeline, X, y, cv=10, scoring='r2')
# 绘制学习曲线
plt.figure()
plt.plot(train_sizes, np.mean(train_scores, axis=1), 'o-', color='r', label='训练分数')
plt.plot(train_sizes, np.mean(val_scores, axis=1), 'o-', color='g', label='验证分数')
plt.xlabel('训练集大小')
plt.ylabel('R² 分数')
plt.title('学习曲线')
plt.legend(loc='best')
plt.show()
### 总结
通过实施这些策略,您可以解决交叉验证分数中的高变异性并减少回归模型中的过拟合。定期使用未见过的数据验证模型并监控性能指标将确保您的模型对新数据具有良好的泛化能力。