数据清洗是任何机器学习项目中至关重要的一步。
在表格数据中,您可以使用许多不同的统计分析和数据可视化技术来探索数据,以识别可能需要执行的数据清洗操作。
在深入研究复杂方法之前,您可能应该在每个机器学习项目中执行一些非常基本的数据清洗操作。这些操作非常基本,以至于经验丰富的机器学习从业者也常常忽略它们,但它们又如此关键,如果跳过,模型可能会崩溃或报告过于乐观的性能结果。
在本教程中,您将发现始终应该在数据集上执行的基本数据清洗操作。
完成本教程后,您将了解:
- 如何识别并删除只包含单个值的列变量。
- 如何识别并考虑具有极少数唯一值的列变量。
- 如何识别并删除包含重复观测值的行。
通过我的新书《机器学习数据准备》启动您的项目,其中包括分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- 2020 年 4 月更新:添加了关于数据集和方差阈值的部分。
- 2020 年 5 月更新:添加了引文和书籍参考。

您在机器学习中必须执行的基本数据清洗
图片由 Allen McGregor 拍摄,保留部分权利。
教程概述
本教程分为七个部分,它们是:
- 凌乱的数据集
- 识别包含单个值的列
- 删除包含单个值的列
- 考虑具有极少数值的列
- 删除方差较低的列
- 识别包含重复数据的行
- 删除包含重复数据的行
凌乱的数据集
数据清洗是指识别并纠正数据集中可能对预测模型产生负面影响的错误。
数据清洗指的是检测和修复数据中错误的各种任务和活动。
— 第 xiii 页,《数据清洗》,2019。
尽管数据清洗至关重要,但它并不令人兴奋,也不涉及花哨的技术。只需要对数据集有很好的了解。
清理数据不是最光鲜的任务,但却是数据整理的重要组成部分。[...] 了解如何正确清理和组织数据将使您在同行中脱颖而出。
— 第 149 页,《使用 Python 进行数据整理》,2016。
数据集中存在许多类型的错误,其中一些最简单的错误包括不包含太多信息的列和重复的行。
在我们深入识别和纠正混乱数据之前,让我们先定义一些混乱的数据集。
我们将使用两个数据集作为本教程的基础:溢油数据集和鸢尾花数据集。
想开始学习数据准备吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
溢油数据集
所谓的“溢油”数据集是一个标准的机器学习数据集。
任务是预测补丁是否包含溢油(例如,来自海洋中非法或意外倾倒的油),给定描述卫星图像补丁内容的向量。
共有 937 个案例。每个案例由 48 个数值计算机视觉派生特征、一个补丁编号和一个类别标签组成。
正常情况是没有溢油,分配的类别标签为 0,而溢油则用类别标签 1 表示。没有溢油的案例有 896 个,溢油的案例有 41 个。
您可以在此处访问整个数据集
查看文件内容。
文件的前几行应如下所示
|
1 2 3 4 5 6 |
1,2558,1506.09,456.63,90,6395000,40.88,7.89,29780,0.19,214.7,0.21,0.26,0.49,0.1,0.4,99.59,32.19,1.84,0.16,0.2,87.65,0,0.47,132.78,-0.01,3.78,0.22,3.2,-3.71,-0.18,2.19,0,2.19,310,16110,0,138.68,89,69,2850,1000,763.16,135.46,3.73,0,33243.19,65.74,7.95,1 2,22325,79.11,841.03,180,55812500,51.11,1.21,61900,0.02,901.7,0.02,0.03,0.11,0.01,0.11,6058.23,4061.15,2.3,0.02,0.02,87.65,0,0.58,132.78,-0.01,3.78,0.84,7.09,-2.21,0,0,0,0,704,40140,0,68.65,89,69,5750,11500,9593.48,1648.8,0.6,0,51572.04,65.73,6.26,0 3,115,1449.85,608.43,88,287500,40.42,7.34,3340,0.18,86.1,0.21,0.32,0.5,0.17,0.34,71.2,16.73,1.82,0.19,0.29,87.65,0,0.46,132.78,-0.01,3.78,0.7,4.79,-3.36,-0.23,1.95,0,1.95,29,1530,0.01,38.8,89,69,1400,250,150,45.13,9.33,1,31692.84,65.81,7.84,1 4,1201,1562.53,295.65,66,3002500,42.4,7.97,18030,0.19,166.5,0.21,0.26,0.48,0.1,0.38,120.22,33.47,1.91,0.16,0.21,87.65,0,0.48,132.78,-0.01,3.78,0.84,6.78,-3.54,-0.33,2.2,0,2.2,183,10080,0,108.27,89,69,6041.52,761.58,453.21,144.97,13.33,1,37696.21,65.67,8.07,1 5,312,950.27,440.86,37,780000,41.43,7.03,3350,0.17,232.8,0.15,0.19,0.35,0.09,0.26,289.19,48.68,1.86,0.13,0.16,87.65,0,0.47,132.78,-0.01,3.78,0.02,2.28,-3.44,-0.44,2.19,0,2.19,45,2340,0,14.39,89,69,1320.04,710.63,512.54,109.16,2.58,0,29038.17,65.66,7.35,0 ... |
我们可以看到第一列包含补丁编号的整数。我们还可以看到计算机视觉派生特征是实数值,具有不同的比例,例如第二列中的千位和其他列中的小数。
此数据集包含具有极少数唯一值的列,为数据清洗提供了良好的基础。
鸢尾花数据集
所谓的“鸢尾花”数据集是另一个标准的机器学习数据集。
该数据集涉及根据鸢尾花以厘米为单位的测量值预测花卉种类。
这是一个多类别分类问题。每个类别的观测值数量是平衡的。有 150 个观测值,包含 4 个输入变量和 1 个输出变量。
您可以在此处访问整个数据集
查看文件内容。
文件的前几行应如下所示
|
1 2 3 4 5 6 |
5.1,3.5,1.4,0.2,Iris-setosa 4.9,3.0,1.4,0.2,Iris-setosa 4.7,3.2,1.3,0.2,Iris-setosa 4.6,3.1,1.5,0.2,Iris-setosa 5.0,3.6,1.4,0.2,Iris-setosa ... |
我们可以看到所有四个输入变量都是数值型,目标类别变量是一个表示鸢尾花种类的字符串。
此数据集包含重复行,为数据清洗提供了良好的基础。
识别包含单个值的列
只包含单个观测值或值的列对于建模可能没有用处。
这些列或预测变量被称为零方差预测变量,因为如果计算它们的方差(值与平均值的平均平方差),它将为零。
当一个预测变量包含单个值时,我们称之为零方差预测变量,因为它确实没有显示出任何变化。
— 第 96 页,《特征工程与选择》,2019。
这里,单个值意味着该列的每一行都具有相同的值。例如,列 X1 在数据集的所有行中都具有值 1.0
|
1 2 3 4 5 6 7 |
X1 1.0 1.0 1.0 1.0 1.0 ... |
所有行都具有单个值的列不包含任何用于建模的信息。
根据数据准备和建模算法的选择,具有单个值的变量也可能导致错误或意外结果。
您可以使用 unique() NumPy 函数检测具有此属性的行,该函数将报告每列中唯一值的数量。
下面的示例加载包含 50 个变量的溢油分类数据集,并汇总每列的唯一值数量。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 使用 numpy 汇总每列的唯一值数量 from urllib.request import urlopen 从 numpy 导入 loadtxt from numpy import unique # 定义数据集位置 path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/oil-spill.csv' # 加载数据集 data = loadtxt(urlopen(path), delimiter=',') # 汇总每列的唯一值数量 for i in range(data.shape[1]): print(i, len(unique(data[:, i]))) |
运行该示例会直接从 URL 加载数据集,并打印每列的唯一值数量。
我们可以看到,索引为 22 的列只有一个值,应该删除。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
0 238 1 297 2 927 3 933 4 179 5 375 6 820 7 618 8 561 9 57 10 577 11 59 12 73 13 107 14 53 15 91 16 893 17 810 18 170 19 53 20 68 21 9 22 1 23 92 24 9 25 8 26 9 27 308 28 447 29 392 30 107 31 42 32 4 33 45 34 141 35 110 36 3 37 758 38 9 39 9 40 388 41 220 42 644 43 649 44 499 45 2 46 937 47 169 48 286 49 2 |
一个更简单的方法是使用 nunique() Pandas 函数,它会为您完成这项艰巨的工作。
下面是使用 Pandas 函数的相同示例。
|
1 2 3 4 5 6 7 8 |
# 使用 numpy 汇总每列的唯一值数量 from pandas import read_csv # 定义数据集位置 path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/oil-spill.csv' # 加载数据集 df = read_csv(path, header=None) # 汇总每列的唯一值数量 print(df.nunique()) |
运行该示例,我们得到相同的结果,即列索引和每列的唯一值数量。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
0 238 1 297 2 927 3 933 4 179 5 375 6 820 7 618 8 561 9 57 10 577 11 59 12 73 13 107 14 53 15 91 16 893 17 810 18 170 19 53 20 68 21 9 22 1 23 92 24 9 25 8 26 9 27 308 28 447 29 392 30 107 31 42 32 4 33 45 34 141 35 110 36 3 37 758 38 9 39 9 40 388 41 220 42 644 43 649 44 499 45 2 46 937 47 169 48 286 49 2 数据类型:int64 |
删除包含单个值的列
具有单个值的变量或列应该从数据集中删除。
……只需删除零方差预测变量。
— 第 96 页,《特征工程与选择》,2019。
从 NumPy 数组或 Pandas DataFrame 中删除列相对容易。
一种方法是记录所有具有单个唯一值的列,然后通过调用 drop() 函数将它们从 Pandas DataFrame 中删除。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 删除具有单个唯一值的列 from pandas import read_csv # 定义数据集位置 path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/oil-spill.csv' # 加载数据集 df = read_csv(path, header=None) print(df.shape) # 获取每列的唯一值数量 counts = df.nunique() # 记录要删除的列 to_del = [i for i,v in enumerate(counts) if v == 1] print(to_del) # 删除无用的列 df.drop(to_del, axis=1, inplace=True) print(df.shape) |
运行该示例首先加载数据集并报告行数和列数。
计算每列的唯一值数量,并识别出具有单个唯一值的列。在本例中,为列索引 22。
然后从 DataFrame 中删除已识别的列,并报告 DataFrame 的行数和列数以确认更改。
|
1 2 3 |
(937, 50) [22] (937, 49) |
考虑具有极少数值的列
在上一节中,我们看到示例数据集中的某些列具有很少的唯一值。
例如,有些列只有 2、4 和 9 个唯一值。这对于有序或分类变量可能是有意义的。在这种情况下,数据集只包含数值变量。因此,列中只有 2、4 或 9 个唯一的数值可能会令人惊讶。
我们可以将这些列或预测变量称为接近零方差预测变量,因为它们的方差不为零,而是一个非常接近零的小数。
……接近零方差预测变量,或者在重采样过程中有可能出现接近零方差。这些预测变量具有很少的唯一值(例如二元虚拟变量的两个值)并且在数据中不常出现。
— 第 96-97 页,《特征工程与选择》,2019。
这些列可能有助于模型的技能,也可能无助于模型的技能。我们不能假设它们对建模是无用的。
尽管接近零方差的预测变量可能包含很少有价值的预测信息,但我们可能不希望将其过滤掉。
— 第 97 页,《特征工程与选择》,2019。
根据数据准备和建模算法的选择,具有极少数数值的变量也可能导致错误或意外结果。例如,我曾见过它们在使用幂变换进行数据准备和拟合假设“合理”数据概率分布的线性模型时导致错误。
为了突出这类列,您可以将每个变量的唯一值数量计算为数据集中总行数的百分比。
让我们手动使用 NumPy 完成此操作。完整示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 使用 numpy 汇总每列的唯一值百分比 from urllib.request import urlopen 从 numpy 导入 loadtxt from numpy import unique # 定义数据集位置 path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/oil-spill.csv' # 加载数据集 data = loadtxt(urlopen(path), delimiter=',') # 汇总每列的唯一值数量 for i in range(data.shape[1]): num = len(unique(data[:, i])) percentage = float(num) / data.shape[0] * 100 print('%d, %d, %.1f%%' % (i, num, percentage)) |
运行示例会报告列索引和每列的唯一值数量,然后是唯一值占数据集中所有行数的百分比。
在这里,我们可以看到有些列的唯一值百分比非常低,例如低于 1%。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
0, 238, 25.4% 1, 297, 31.7% 2, 927, 98.9% 3, 933, 99.6% 4, 179, 19.1% 5, 375, 40.0% 6, 820, 87.5% 7, 618, 66.0% 8, 561, 59.9% 9, 57, 6.1% 10, 577, 61.6% 11, 59, 6.3% 12, 73, 7.8% 13, 107, 11.4% 14, 53, 5.7% 15, 91, 9.7% 16, 893, 95.3% 17, 810, 86.4% 18, 170, 18.1% 19, 53, 5.7% 20, 68, 7.3% 21, 9, 1.0% 22, 1, 0.1% 23, 92, 9.8% 24, 9, 1.0% 25, 8, 0.9% 26, 9, 1.0% 27, 308, 32.9% 28, 447, 47.7% 29, 392, 41.8% 30, 107, 11.4% 31, 42, 4.5% 32, 4, 0.4% 33, 45, 4.8% 34, 141, 15.0% 35, 110, 11.7% 36, 3, 0.3% 37, 758, 80.9% 38, 9, 1.0% 39, 9, 1.0% 40, 388, 41.4% 41, 220, 23.5% 42, 644, 68.7% 43, 649, 69.3% 44, 499, 53.3% 45, 2, 0.2% 46, 937, 100.0% 47, 169, 18.0% 48, 286, 30.5% 49, 2, 0.2% |
我们可以更新示例,只汇总那些唯一值低于行数 1% 的变量。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 使用 numpy 汇总每列的唯一值百分比 from urllib.request import urlopen 从 numpy 导入 loadtxt from numpy import unique # 定义数据集位置 path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/oil-spill.csv' # 加载数据集 data = loadtxt(urlopen(path), delimiter=',') # 汇总每列的唯一值数量 for i in range(data.shape[1]): num = len(unique(data[:, i])) percentage = float(num) / data.shape[0] * 100 if percentage < 1: print('%d, %d, %.1f%%' % (i, num, percentage)) |
运行示例后,我们可以看到 50 个变量中有 11 个数值变量的唯一值低于行数的 1%。
这并不意味着这些行和列应该被删除,但它们需要进一步关注。
例如
- 也许唯一值可以编码为序数值?
- 也许唯一值可以编码为分类值?
- 也许比较删除每个变量后模型的性能?
|
1 2 3 4 5 6 7 8 9 10 11 |
21, 9, 1.0% 22, 1, 0.1% 24, 9, 1.0% 25, 8, 0.9% 26, 9, 1.0% 32, 4, 0.4% 36, 3, 0.3% 38, 9, 1.0% 39, 9, 1.0% 45, 2, 0.2% 49, 2, 0.2% |
例如,如果我们想删除所有 11 个唯一值低于行数 1% 的列;下面的示例演示了这一点。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 删除唯一值数量低于行数 1% 的列 from pandas import read_csv # 定义数据集位置 path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/oil-spill.csv' # 加载数据集 df = read_csv(path, header=None) print(df.shape) # 获取每列的唯一值数量 counts = df.nunique() # 记录要删除的列 to_del = [i for i,v in enumerate(counts) if (float(v)/df.shape[0]*100) < 1] print(to_del) # 删除无用的列 df.drop(to_del, axis=1, inplace=True) print(df.shape) |
运行该示例首先加载数据集并报告行数和列数。
计算每列的唯一值数量,并识别出唯一值数量低于行数 1% 的列。在本例中,有 11 列。
然后从 DataFrame 中删除已识别的列,并报告 DataFrame 的行数和列数以确认更改。
|
1 2 3 |
(937, 50) [21, 22, 24, 25, 26, 32, 36, 38, 39, 45, 49] (937, 39) |
删除方差较低的列
解决唯一值很少的列问题的另一种方法是考虑列的方差。
回想一下,方差是对变量计算的统计量,表示样本值与均值的平均平方差。
方差可以用作筛选器,用于识别要从数据集中删除的列。具有单个值的列的方差为 0.0,而具有极少数唯一值的列将具有较小的方差值。
scikit-learn 库中的 VarianceThreshold 类支持此作为一种特征选择类型。可以创建一个类的实例,指定“threshold”参数,该参数默认为 0.0,以删除具有单个值的列。
然后可以通过调用 fit_transform() 函数将其拟合并应用于数据集,以创建数据集的转换版本,其中方差低于阈值的列已自动删除。
|
1 2 3 4 5 |
... # 定义转换 transform = VarianceThreshold() # 转换输入数据 X_sel = transform.fit_transform(X) |
我们可以在溢油数据集上演示这一点,如下所示
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 应用方差阈值的示例 from pandas import read_csv from sklearn.feature_selection import VarianceThreshold # 定义数据集位置 path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/oil-spill.csv' # 加载数据集 df = read_csv(path, header=None) # 将数据拆分为输入和输出 data = df.values X = data[:, :-1] y = data[:, -1] print(X.shape, y.shape) # 定义转换 transform = VarianceThreshold() # 转换输入数据 X_sel = transform.fit_transform(X) print(X_sel.shape) |
运行示例首先加载数据集,然后应用转换以删除所有方差为 0.0 的列。
在转换前后报告数据集的形状,我们可以看到所有值都相同的单个列已被删除。
|
1 2 |
(937, 49) (937,) (937, 48) |
我们可以扩展这个例子,看看当我们使用不同的阈值时会发生什么。
我们可以定义一个从 0.0 到 0.5 的阈值序列,步长为 0.05,例如 0.0、0.05、0.1 等。
|
1 2 3 |
... # 定义要检查的阈值 thresholds = arange(0.0, 0.55, 0.05) |
然后我们可以报告每个给定阈值下转换数据集中特征的数量。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
... # 应用每个阈值进行转换 results = list() for t in thresholds: # 定义转换 transform = VarianceThreshold(threshold=t) # 转换输入数据 X_sel = transform.fit_transform(X) # 确定输入特征的数量 n_features = X_sel.shape[1] print('>Threshold=%.2f, Features=%d' % (t, n_features)) # 存储结果 results.append(n_features) |
最后,我们可以绘制结果。
综合来看,比较方差阈值与所选特征数量的完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# 探索方差阈值对所选特征数量的影响 from numpy import arange from pandas import read_csv from sklearn.feature_selection import VarianceThreshold from matplotlib import pyplot # 定义数据集位置 path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/oil-spill.csv' # 加载数据集 df = read_csv(path, header=None) # 将数据拆分为输入和输出 data = df.values X = data[:, :-1] y = data[:, -1] print(X.shape, y.shape) # 定义要检查的阈值 thresholds = arange(0.0, 0.55, 0.05) # 应用每个阈值进行转换 results = list() for t in thresholds: # 定义转换 transform = VarianceThreshold(threshold=t) # 转换输入数据 X_sel = transform.fit_transform(X) # 确定输入特征的数量 n_features = X_sel.shape[1] print('>Threshold=%.2f, Features=%d' % (t, n_features)) # 存储结果 results.append(n_features) # 绘制阈值与所选特征数量的关系 pyplot.plot(thresholds, results) pyplot.show() |
运行示例首先加载数据并确认原始数据集有 49 列。
接下来,将 VarianceThreshold 应用于原始数据集,其值范围从 0.0 到 0.5,并报告应用转换后剩余的特征数量。
我们可以看到,数据集中特征的数量从未更改数据中的 49 个迅速下降到阈值为 0.15 时的 35 个。之后,在阈值为 0.5 时下降到 31 个(删除了 18 列)。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
(937, 49) (937,) >阈值=0.00,特征=48 >阈值=0.05,特征=37 >阈值=0.10,特征=36 >阈值=0.15,特征=35 >阈值=0.20,特征=35 >阈值=0.25,特征=35 >阈值=0.30,特征=35 >阈值=0.35,特征=35 >阈值=0.40,特征=35 >阈值=0.45,特征=33 >阈值=0.50,特征=31 |
然后创建一个折线图,显示阈值与转换数据集中特征数量之间的关系。
我们可以看到,即使在 0.15 到 0.4 之间的小阈值下,也有大量特征(14 个)被立即删除。
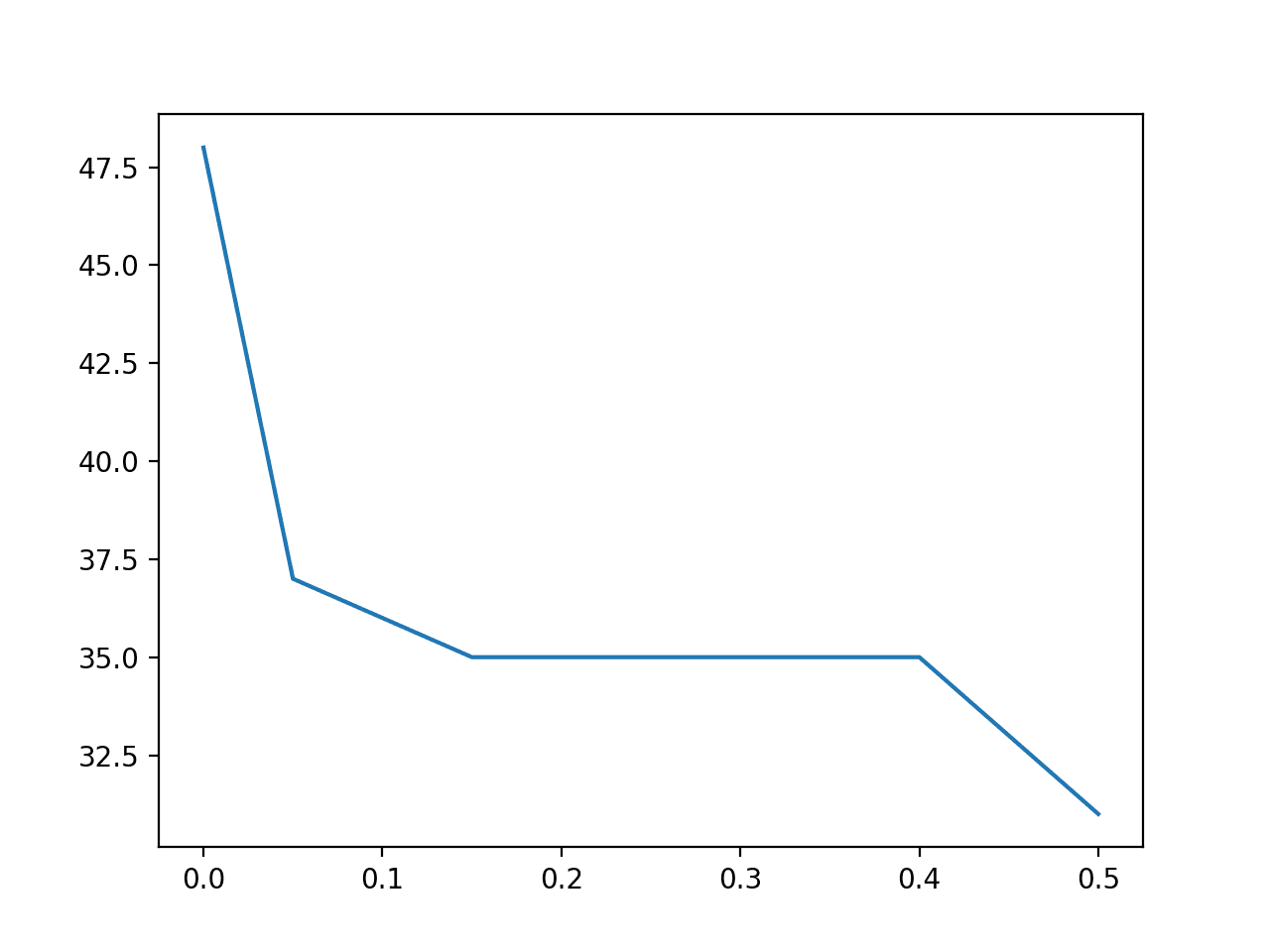
方差阈值 (X) 与所选特征数量 (Y) 的折线图
识别包含重复数据的行
具有相同数据的行可能无用,甚至在模型评估期间具有危险的误导性。
这里,重复行是指该行中每列的每个值都以完全相同的顺序(相同的列值)出现在另一行中。
……如果您使用了可能包含重复条目的原始数据,那么删除重复数据将是确保数据能够准确使用的重要步骤。
— 第 173 页,《使用 Python 进行数据整理》,2016。
从概率的角度来看,您可以将重复数据视为调整类别标签或数据分布的先验。如果您希望有目的地偏置先验,这可能有助于像朴素贝叶斯这样的算法。通常情况下,情况并非如此,通过识别和删除具有重复数据的行,机器学习算法将表现更好。
从算法评估的角度来看,重复行将导致误导性的性能。例如,如果您正在使用训练/测试分割或k折交叉验证,那么重复行或多行可能同时出现在训练和测试数据集中,并且对这些行进行模型评估将是(或应该是)正确的。这将导致对未见数据性能的乐观偏差估计。
数据去重,也称为重复检测、记录链接、记录匹配或实体解析,是指识别一个或多个关系中引用相同现实世界实体的元组的过程。
— 第 47 页,《数据清洗》,2019。
如果您认为您的数据集或所选模型不属于这种情况,请设计一个受控实验来测试它。这可以通过评估原始数据集和删除重复项后的数据集的模型技能并比较性能来实现。另一个实验可能涉及通过不同数量的随机选择的重复示例来扩充数据集。
pandas 函数 duplicated() 将报告给定行是否重复。所有行都标记为 False 表示不是重复项,或 True 表示是重复项。如果存在重复项,则行的第一次出现被标记为 False(默认情况下),正如我们所预期的那样。
下面的示例检查重复项。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 定位重复数据行 from pandas import read_csv # 定义数据集位置 path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/iris.csv' # 加载数据集 df = read_csv(path, header=None) # 计算重复项 dups = df.duplicated() # 报告是否存在任何重复项 print(dups.any()) # 列出所有重复行 print(df[dups]) |
运行示例首先加载数据集,然后计算行重复项。
首先,报告是否存在任何重复行,在这种情况下,我们可以看到存在重复行 (True)。
然后报告所有重复行。在这种情况下,我们可以看到识别出的三行重复行被打印出来。
|
1 2 3 4 5 |
真 0 1 2 3 4 34 4.9 3.1 1.5 0.1 鸢尾花-setosa 37 4.9 3.1 1.5 0.1 鸢尾花-setosa 142 5.8 2.7 5.1 1.9 鸢尾花-virginica |
删除包含重复数据的行
在建模之前,应将重复数据行从数据集中删除。
如果您的数据集只是有重复行,则无需担心保留数据;它已经是完成数据集的一部分,您可以直接从清理后的数据中删除或丢弃这些行。
— 第 186 页,《使用 Python 进行数据整理》,2016。
有很多方法可以实现这一点,尽管 Pandas 提供了 drop_duplicates() 函数,它正好实现了这一点。
下面的示例演示了从数据集中删除重复行。
|
1 2 3 4 5 6 7 8 9 10 |
# 从数据集中删除重复数据行 from pandas import read_csv # 定义数据集位置 path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/iris.csv' # 加载数据集 df = read_csv(path, header=None) print(df.shape) # 删除重复行 df.drop_duplicates(inplace=True) print(df.shape) |
运行该示例首先加载数据集并报告行数和列数。
接下来,识别并从 DataFrame 中删除重复数据行。然后报告 DataFrame 的形状以确认更改。
|
1 2 |
(150, 5) (147, 5) |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
书籍
- 数据清洗, 2019.
- 使用 Python 进行数据整理, 2016.
- 特征工程与选择, 2019.
API
- numpy.unique API.
- pandas.DataFrame.nunique API.
- sklearn.feature_selection.VarianceThreshold API。
- pandas.DataFrame.drop API.
- pandas.DataFrame.duplicated API.
- pandas.DataFrame.drop_duplicates API.
总结
在本教程中,您学习了始终应该在数据集上执行的基本数据清洗操作。
具体来说,你学到了:
- 如何识别并删除只包含单个值的列变量。
- 如何识别并考虑具有极少数唯一值的列变量。
- 如何识别并删除包含重复观测值的行。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







干得好
谢谢。
嗨,Jason,
我可以知道删除具有唯一值的列的原因吗?
请赐教。谢谢。
我们删除那些没有太多唯一值的列,因为它们对目标变量没有贡献,或者可能没有贡献。
谢谢。我正在使用 R,并考虑学习 Python。您知道是否有关于相同主题(如何清理数据集)的 R 教程吗?
Python 和 R 结合使用值得吗?
抱歉,我手头上没有,抱歉。
我建议坚持使用一个平台。
我真的很喜欢这个教程。
谢谢!
好文章,有时我们在构建机器学习模型时会忘记基础知识。谢谢Jason
谢谢!
是的,我们确实会。
感谢您的教程。它为我们提供了更多清理选项。
谢谢。
教程中的思路很好。我喜欢识别非唯一数据的方法。我在工业计算领域工作,我们经常有大量的“1/0”常量条目,表示阀门何时打开和关闭,但在一段时间内,删除常量值将有助于识别错误。
感谢您的思考!
谢谢。
很棒的教程,谢谢。您有一些关于数据清洗、评估特征等的文章……您有一本包含所有内容的书吗?
目前还没有,希望将来能有。
移除/填充 NaN 实例的过程也属于数据清洗吗?我猜这应该在您的文章中介绍的步骤之前执行。
此致!
是的!
很好的教程,谢谢。我是新来的,想问一下您是否有关于通过聚合多个位置的数据来训练机器学习模型的教程?
不客气。
也许这会给你一些想法
https://machinelearning.org.cn/faq/single-faq/how-to-develop-forecast-models-for-multiple-sites
你好,
我正在使用图像数据集(我的模型将两张图像作为输入(一张图像和其真实值))。我想对我的数据库进行数据清理。目前还没有关于如何进行的教程(所有教程都使用CSV数据集)。您能指导我如何做吗?非常感谢您的时间。
是的,你可以在这里看到关于图像处理的教程
https://machinelearning.org.cn/start-here/#dlfcv
尊敬的Jason博士,
感谢您的文章。
我需要澄清 unique 和 nunique 的操作方式。这些函数是按行操作还是按列操作。
重现步骤。
我需要澄清一下计数。鉴于有 50 个特征和 937 行,从上面的代码中,例如 238、297、927、933、179 是什么意思。
那是指有 238 个计数,还是 238 是唯一数字?
或者那是指 50 列中的每个唯一数字分别是 238、297、927、933、179。
或者那是指例如第一列中有 238 个唯一值?
参考
示例 1,网址:https://numpy.com.cn/doc/stable/reference/generated/numpy.unique.html
谢谢你,
悉尼的Anthony
尊敬的Jason博士,
我使用了一个较小的数据集,现在明白了。摘要在后台程序之后出现。
我明白了。我将在唯一的每个数字的计数/统计摘要之后询问您。
总结
unique 和 DataFrame 的 nunique 以相同的方式工作。
每次调用 unique() 和 df.nunique() 时,每列都会生成一个数字的唯一出现次数。
如果调用 unique 和 df.unique 没有带 (),那么我们会打印出整个矩阵。
问题
我们如何统计和/或获取列中每个数字的频率。
谢谢你,
悉尼的Anthony
尊敬的Jason博士,
一个小小的修正。
unique(stuff) – 产生一个数字列表。它不产生计数。
要从使用 unique 运算符中找出唯一数字的唯一数量。
请原谅我的双关语,但这并不是确定每列中唯一数字数量的唯一方法。
我的问题依然存在
我们如何统计和/或获取列中每个数字的频率?
谢谢你,
悉尼的Anthony
你必须指定沿着哪个轴来计算唯一值,也许可以查看函数的文档。
唯一值是按列计算的。
尊敬的Jason博士,
我又没说清楚。
在我继续阐述我的意图之前,我想说的是:
* 正如我上面发现的,numpy 的 unique 和 DataFrame 的 nunique 都是按列操作的。
我最初的问题是关于计算每个特征(即列)的统计数据。
我想分享的是矩阵中唯一数字的统计/频率。
它使用 numpy 的 unique 函数,但带有参数 numpy.unique(stuff, return_counts = True)。
以下是查找整个矩阵中唯一数字的统计频率/计数的代码
现在让我们获取每个特征 = 列的唯一数字的频率/计数。
也许每个特征(即列)的计数/频率统计的呈现方式可以整理得更整洁。
上述用于整个矩阵或每个列(即特征)的方法并非唯一。其实现灵感来源于 https://kite.com/python/answers/how-to-count-frequency-of-unique-values-in-a-numpy-array-in-python 的代码。
你可以通过计数/频率统计获得每个特征(即列)的类似结果。
灵感来源:https://docs.pythonlang.cn/2/library/collections.html 中名为 Class collections.Counter 的部分
结论
这与用于确定特征计数的 unique/nunique 技术无关。
相反,我展示了两种技术来查找每列的计数/统计:一种是使用带有参数 return_counts=True 的 unique 函数,另一种是使用 collections 的 Counter。
谢谢你,
悉尼的Anthony
感谢分享。
谢谢你的文章,Jason!我真的很喜欢这个教程。
不客气,我很高兴听到这个消息。
亲爱的布朗利博士,
感谢您的精彩文章。我有一个疑问,我们是否可以使用 VarianceThreshold() 来删除对象数据类型?如果不能,是否有其他方法可以做到这一点?
或者您建议在数据转换之后再进行这一步?
谢谢,
Swati
不客气。
您说的对象类型是什么意思?例如字符串?类别?
是的,我相信它适用于这些数据类型——至少原则上是这样。试试看。
嗨 Jason,非常棒的文章!
我只是对阈值有一个疑问。如果我们将阈值设为0.5,这是否意味着如果变量有95%或更高的相同值,我们就将其删除?
同样,对于0.8的阈值,如果变量有92%或更高的相同值,就将其删除?
如果删除一个变量能带来更好的模型性能,那么我建议您删除它。
我想您误解了我的问题。
我指的是阈值。阈值0.5是什么意思?
您可以在这里了解预测概率的阈值
https://machinelearning.org.cn/threshold-moving-for-imbalanced-classification/
# 应用方差阈值的示例
from pandas import read_csv
from sklearn.feature_selection import VarianceThreshold
# 定义数据集位置
path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/oil-spill.csv'
# 加载数据集
df = read_csv(path, header=None)
# 将数据拆分为输入和输出
data = df.values
X = data[:, :-1]
y = data[:, -1]
print(X.shape, y.shape)
# 定义转换
transform = VarianceThreshold()
# 转换输入数据
X_sel = transform.fit_transform(X)
print(X_sel.shape)
在这个例子中,您使用的是 X = data[:, :-1],它不包括最后一列。为什么我们不包含最后一列?
X 是输入数据,我们不将输出变量作为输入的一部分。
嗨,Jason,
一如既往,感谢您精彩的教程。
我有一个问题。我的数据集高度不平衡,并且存在一些模糊性(相同的输入但不同的类别标签)。您认为将多数类别标签中的模糊数据点“重新分配”给少数类别标签更好吗?(因为我更关心少数类别)或者直接过滤掉这些数据点更好?
附注:我在训练时考虑了类别权重。
不客气。
好问题!尝试几种处理模糊数据的策略,看看哪种效果最好,例如尝试删除、尝试重新标记等。
嗨,Jason,
感谢您的教程。非常有启发性!
我有一个关于常量值特征的问题。对于分类问题,我有一个长度为80的特征向量,其中4个特征始终为零。无论是否移除零特征,我使用不同的分类器(SVM、随机森林、逻辑回归和两个不同的深度学习模型)都得到了几乎相同的结果。这是因为零特征占总特征数的百分比很小(4/80)吗?
接着这个问题,除了计算效率,如果具有常数值或非常小方差的特征部分相对于总特征数来说非常小,那么我们保留或移除这些具有常数值或非常小方差的特征,最终的分类得分是否几乎相同?在这种情况下,是否存在某些分类器,移除或保留这些特征可能会导致分类得分的差异?
感谢您的帮助!
不客气。
如果一个变量总是具有相同的值,则必须将其从数据集中删除。
也许您可以尝试替代数据准备、替代模型、替代模型配置、替代指标等。
感谢您的回复。
一般来说,如果您移除所有观测值中具有恒定零值的变量,您是否期望分类分数(如准确率和F分数)会有所下降?
删除低方差数据将提高方法的效率,有时还会提高性能。
模型性能有没有可能下降?如果像我这种情况,分类分数几乎没有变化或者变化很小(比如百分之十的量级),这背后有什么原因吗?
我在想对于神经网络来说,那些值为零的特征的权重不会起作用,因为它们与特征的乘积总是零(我理解当值为零或方差恒定的特征数量增加时可能会产生数值问题)。那么,当值为零的特征数量很少时,对于神经网络来说,这真的会有什么不同吗?
也许吧。通过有无进行评估,为您的数据和模型找出答案。
抱歉问了这么多问题。
您能想到模型性能下降的任何原因吗,尽管移除了不传递任何信息的特征(例如始终为零或通常具有恒定方差的特征)?
是的,特征不相关的假设可能是错误的。
我只是想澄清我的问题。我说:“我使用不同的分类器(SVM、随机森林、逻辑回归和两个不同的深度学习模型)在有无移除零特征的情况下得到了几乎相同的结果。”我的意思是在有无保留这些零特征的情况下,每个分类器都得到了几乎相同的结果。我不是说所有分类器都得到了相同的结果。
嗨,Jason,
非常棒的教程!谢谢。
我发现 pandas 数据帧是非常强大的工具,可以清理、替换和过滤 .csv 和 excel 文件中的表格数据集,例如。有很多我不知道的 pandas 方法!
无论如何,我有点困惑,你可以得到,例如,所有值为零的列,或任何其他奇怪的值,如字符串等,通过构造如下命令:
n_0 = (dataframe == 0).sum()
但是,如果你应用相同的“结构”来获取所有列的“NaN”值,例如
n_nan= (datataframe ==np.nan).sum()
它不起作用!!
相反,你必须通过这个方法
n_nan = dataframe.isnull.sum()
某些逻辑的 pandas 路径失败!🙁
此致,
不客气。
是的,nan 是特殊的。我认为相等性不适用。
嗨,先生,解释得很棒。如果我的数据已经用z-score归一化,如何决定并找到用于方差阈值筛选可能无用特征的最佳阈值?我正在尝试进行特征降维,以找到最佳特征子集,以构建我的交叉验证训练数据上的校准Sigmoid SVC模型。我一直在使用阈值0、0.01、0.003和(.8 * (1 - .8)),但没有特征被过滤掉。
这个教程可能会有所帮助
https://machinelearning.org.cn/threshold-moving-for-imbalanced-classification/
我理解单变量列的移除如何应用于传统机器学习。它也适用于神经网络类型的机器学习吗?
是的,特征选择可以帮助神经网络。
嗨,先生,很棒的文章。我尝试了您提出的方法,并且看到它们已经运行良好,但我只是好奇在将数据集输入神经网络之前对其执行PCA是否会更好?或者隐藏层是否会在学习权重时自动找出主成分?
也许可以尝试一下。
收到错误消息:未在轴中找到。
# 记录要删除的列
to_del = [i for i,v in enumerate(counts) if (float(v)/df.shape[0]*100) < 1]
print(to_del)
????
通过打印值效果很好
# 删除无用的列
df.drop(to_del, axis=1, inplace=True)
????
但这个生成错误消息:未在轴中找到。
请问我该如何解决?
很抱歉您遇到问题,这些提示可能会有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
你好,我有一个包含1472条新闻标题的数据集,其中1172条标记为“正面”,302条标记为“负面”。这个数据集可以称为不平衡数据集吗?
这1472条新闻标题有170条重复记录。其中29条为负面,141条为正面。当我删除重复项并使用bert模型和svm实现我的方法1时,我获得了更高的准确性。但是当我删除重复项并使用corenlp依赖项一元、二元和tfidf与svm实现我的方法2时,我获得了更低的准确性。我的问题是,为什么两种方法在删除重复项上存在差异。
我不太确定。这可能是原因之一:https://machinelearning.org.cn/different-results-each-time-in-machine-learning/
嗨 Adrian,您的教程非常棒。我从您的大多数博客中学到了很多。
我有一个关于数据清理方法的问题。我正在寻找创建一种算法,该算法可以检测数据中的错误(重复、缺失、不正确、不一致、异常值、噪声数据等),并用合适的值替换它们,同时减少数据集中的错误。
您是否有任何资源或论文可以帮助我开发能够执行此任务的算法?
您的帮助将不胜感激。
你好匿名者……你正在描述一个叫做“数据插补”的概念。以下内容可能有助于澄清。
https://machinelearning.org.cn/handle-missing-data-python/
嗨,Jason,
对于具有多个唯一值的列,
例如:电子邮件列,
我正在提取域名并将其分类到不同的类别中,
这是处理具有太多值的字符串列的好方法吗?
和
为了进行分桶,我们首先需要查看不同的值,我说的对吗?
例如,如果域名中存在拼写错误,我们必须对其进行清理。例如:yahoo, yahooo, yhaoo -> 分桶为 “yahoo”
嗨 Justin……分桶可能是一个合理的方法。您是否已经实现了这个预处理步骤?
感谢您的回复,我正在清理数据,数据量为1500万,我应该首先提取唯一值,清理它们,然后才开始分桶,我说的对吗?
嗨,Jason,
在这篇文章中,有一个部分是关于移除低方差的列。然后显示可以移除14个特征。我们怎么知道哪些列可以移除?
谢谢