时间序列数据在使用机器学习算法之前,必须重新构建为监督学习数据集。
时间序列中没有输入和输出特征的概念。相反,我们必须选择要预测的变量,并使用特征工程构建所有用于预测未来时间步长的输入。
在本教程中,您将学习如何使用 Python 对时间序列数据进行特征工程,以便使用机器学习算法对时间序列问题进行建模。
完成本教程后,您将了解:
- 时间序列数据特征工程的原理和目标。
- 如何开发基于日期时间的基本输入特征。
- 如何开发更复杂的滞后和滑动窗口摘要统计特征。
通过我的新书《使用 Python 进行时间序列预测入门》启动您的项目,包括分步教程和所有示例的Python 源代码文件。
让我们开始吧。
- 2017年6月更新:修正了扩展窗口代码示例中的一个拼写错误。
- 2019 年 4 月更新:更新了数据集链接。
- 2019年8月更新:更新了数据加载以使用新的API。
- 2019年9月更新:修正了数据加载中的错误。

在Python中使用时间序列数据进行基本特征工程
图片由José Morcillo Valenciano提供,保留部分权利。
时间序列的特征工程
时间序列数据集必须经过转换才能作为监督学习问题进行建模。
也就是说,它看起来像
|
1 2 3 |
时间 1,值 1 时间 2,值 2 时间 3,值 3 |
变成看起来像
|
1 2 3 |
输入 1,输出 1 输入 2,输出 2 输入 3,输出 3 |
这样我们就可以训练一个监督学习算法。
在机器学习领域,输入变量也称为特征,我们的任务是从时间序列数据集中创建或发明新的输入特征。理想情况下,我们只希望那些能够最好地帮助学习方法建模输入(X)和我们希望预测的输出(y)之间关系的输入特征。
在本教程中,我们将研究可以从时间序列数据集中创建的三类特征:
- 日期时间特征:这些是每个观测值时间步本身的组成部分。
- 滞后特征:这些是先前时间步的值。
- 窗口特征:这些是先前固定时间步窗口内的值的汇总。
在我们深入探讨从时间序列数据创建输入特征的方法之前,让我们首先回顾一下特征工程的目标。
停止以**慢速**学习时间序列预测!
参加我的免费7天电子邮件课程,了解如何入门(附带示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
特征工程的目标
特征工程的目标是为监督学习算法提供新输入特征与输出特征之间强大且理想情况下简单的关系,以便进行建模。
实际上,我们正在转移复杂性。
复杂性存在于输入和输出数据之间的关系中。在时间序列的情况下,没有输入和输出变量的概念;我们必须从头开始发明这些并构建监督学习问题。
我们可以依靠复杂模型的能力来理解问题的复杂性。如果我们可以更好地揭示数据中输入和输出之间固有的关系,我们可以使这些模型的工作变得更容易(甚至可以使用更简单的模型)。
困难在于我们不知道我们试图揭示的输入和输出之间潜在的固有函数关系。如果知道,我们可能就不需要机器学习了。
相反,我们唯一的反馈是根据我们创建的监督学习数据集或问题“视图”开发的模型的性能。实际上,最好的默认策略是利用所有可用知识从时间序列数据集中创建许多好的数据集,并使用模型性能(以及其他项目要求)来帮助确定什么是好的特征和好的问题视图。
为清晰起见,我们将在示例中关注单变量(一个变量)时间序列数据集,但这些方法同样适用于多变量时间序列问题。接下来,让我们看看本教程中将使用的数据集。
日最低气温数据集
在这篇文章中,我们将使用每日最低气温数据集。
该数据集描述了澳大利亚墨尔本10年(1981-1990)的每日最低气温。
单位是摄氏度,共有3650个观测值。数据来源归功于澳大利亚气象局。
以下是数据的前 5 行样本,包括标题行。
|
1 2 3 4 5 6 |
“日期”,“温度” "1981-01-01",20.7 "1981-01-02",17.9 "1981-01-03",18.8 "1981-01-04",14.6 "1981-01-05",15.8 |
以下是整个数据集的图。
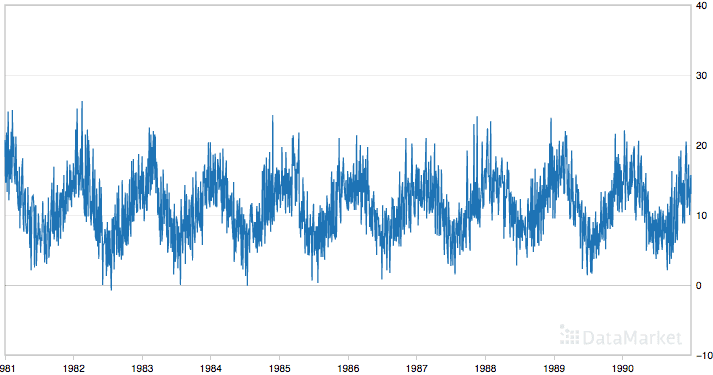
日最低气温
该数据集显示出上升趋势,并且可能包含一些季节性成分。
日期时间特征
让我们从一些最简单的特征开始。
这些是来自每个观测值的日期/时间特征。事实上,它们可以从简单开始,并深入到相当复杂的特定领域。
我们可以从每个观测值的整数月份和日期开始。我们可以想象监督学习算法可能会使用这些输入来帮助提取年份或月份的季节性信息。
我们提出的监督学习问题是根据月份和日期预测每日最低温度,如下所示:
|
1 2 3 |
月份,日期,温度 月份,日期,温度 月份,日期,温度 |
我们可以使用 Pandas 来实现。首先,时间序列作为 Pandas 的 `Series` 加载。然后,我们为转换后的数据集创建一个新的 Pandas `DataFrame`。
接下来,逐个添加列,其中月份和日期信息从序列中每个观测值的时间戳信息中提取。
下面是实现此功能的 Python 代码。
|
1 2 3 4 5 6 7 8 9 |
# 创建数据集的日期时间特征 from pandas import read_csv from pandas import DataFrame series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0, parse_dates=True, squeeze=True) dataframe = DataFrame() dataframe['month'] = [series.index[i].month for i in range(len(series))] dataframe['day'] = [series.index[i].day for i in range(len(series))] dataframe['temperature'] = [series[i] for i in range(len(series))] print(dataframe.head(5)) |
运行此示例将打印转换后数据集的前5行。
|
1 2 3 4 5 6 |
月份 日期 温度 0 1 1 20.7 1 1 2 17.9 2 1 3 18.8 3 1 4 14.6 4 1 5 15.8 |
仅仅使用月份和日期信息来预测温度并不复杂,很可能会导致模型性能不佳。然而,这些信息与附加的工程特征结合起来,最终可能会产生更好的模型。
您可以枚举时间戳的所有属性,并考虑哪些可能对您的问题有用,例如:
- 一天中经过的分钟数。
- 一天中的小时。
- 是否为工作时间。
- 是否为周末。
- 一年中的季节。
- 一年中的商业季度。
- 是否为夏令时。
- 是否为公共假期。
- 是否为闰年。
从这些示例中,您可以看到您不限于原始整数值。您也可以使用二进制标志特征,例如观测值是否在公共假期记录。
在最低温度数据集的情况下,季节可能更具相关性。创建此类特定领域特征更有可能为您的模型增加价值。
基于日期时间的特征是一个好的开始,但包含先前时间步的值通常更有用。这些被称为滞后值,我们将在下一节中介绍如何添加这些特征。
滞后特征
滞后特征是将时间序列预测问题转化为监督学习问题的经典方法。
最简单的方法是根据前一个时间点 (t-1) 的值来预测下一个时间点 (t+1) 的值。具有偏移值的监督学习问题如下所示:
|
1 2 3 |
值(t-1),值(t+1) 值(t-1),值(t+1) 值(t-1),值(t+1) |
Pandas 库提供了 shift() 函数来帮助从时间序列数据集中创建这些偏移或滞后特征。将数据集偏移 1 会创建 t-1 列,并在第一行添加一个 NaN(未知)值。未经偏移的时间序列数据集表示 t+1。
让我们用一个例子来具体说明。温度数据集的前3个值是20.7、17.9和18.8。因此,前3个观测值的偏移和未偏移的温度列表是:
|
1 2 3 4 |
偏移的,原始的 NaN,20.7 20.7, 17.9 17.9, 18.8 |
我们可以使用 concat() 函数将偏移的列沿着列轴(axis=1)连接到一个新的 DataFrame 中。
综合起来,下面是一个为我们的每日温度数据集创建滞后特征的示例。值从加载的序列中提取,并创建这些值的偏移和未偏移列表。为了清晰起见,DataFrame 中的每个列也已命名。
|
1 2 3 4 5 6 7 8 |
from pandas import read_csv from pandas import DataFrame 从 pandas 导入 concat series = read_csv('daily-min-temperatures.csv', header=0, index_col=0) temps = DataFrame(series.values) dataframe = concat([temps.shift(1), temps], axis=1) dataframe.columns = ['t-1', 't+1'] print(dataframe.head(5)) |
运行示例会打印带有滞后特征的新数据集的前5行。
|
1 2 3 4 5 6 |
t-1 t+1 0 NaN 20.7 1 20.7 17.9 2 17.9 18.8 3 18.8 14.6 4 14.6 15.8 |
您可以看到我们必须丢弃第一行才能使用数据集来训练监督学习模型,因为它不包含足够的数据。
滞后特征的添加称为滑动窗口方法,在本例中,窗口宽度为1。就好像我们沿着时间序列的每个观测值滑动我们的焦点,只关注窗口宽度内的内容。
我们可以扩大窗口宽度并包含更多滞后特征。例如,下面是修改后的上述情况,其中包含最近3个观测值来预测下一个时间步的值。
|
1 2 3 4 5 6 7 8 |
from pandas import read_csv from pandas import DataFrame 从 pandas 导入 concat series = read_csv('daily-min-temperatures.csv', header=0, index_col=0) temps = DataFrame(series.values) dataframe = concat([temps.shift(3), temps.shift(2), temps.shift(1), temps], axis=1) dataframe.columns = ['t-3', 't-2', 't-1', 't+1'] print(dataframe.head(5)) |
运行此示例将打印新滞后数据集的前5行。
|
1 2 3 4 5 6 |
t-3 t-2 t-1 t+1 0 NaN NaN NaN 20.7 1 NaN NaN 20.7 17.9 2 NaN 20.7 17.9 18.8 3 20.7 17.9 18.8 14.6 4 17.9 18.8 14.6 15.8 |
再次,您可以看到我们必须丢弃前几行,因为它们没有足够的数据来训练监督模型。
滑动窗口方法的一个难点是为您的实际问题选择多大的窗口。
也许一个好的起点是进行敏感性分析,并尝试一系列不同的窗口宽度,从而创建一系列不同的数据集“视图”,看看哪个能带来性能更好的模型。最终会出现收益递减的情况。
此外,为什么要局限于线性窗口?也许您需要上周、上个月和去年滞后值。同样,这取决于具体的领域。
就温度数据集而言,前一年或前几年同一天的滞后值可能很有用。
我们可以用一个窗口做更多的事情,而不仅仅是包含原始值。在下一节中,我们将介绍包含在窗口中汇总统计信息的特征。
滚动窗口统计
除了添加原始滞后值之外,更进一步是添加先前时间步值的汇总。
我们可以计算滑动窗口中值的汇总统计量,并将其作为特征包含在我们的数据集中。也许最有用的是前几个值的平均值,也称为滚动平均值。
例如,我们可以计算前两个值的平均值,并用它来预测下一个值。对于温度数据,我们必须等待3个时间步才能得到2个值进行平均,然后才能使用该平均值来预测第3个值。
例如:
|
1 2 3 |
均值(t-2, t-1), t+1 均值(20.7, 17.9), 18.8 19.3, 18.8 |
Pandas 提供了一个 rolling() 函数,它为每个时间步创建一个包含值窗口的新数据结构。然后,我们可以对每个时间步收集的值窗口执行统计函数,例如计算均值。
首先,序列必须被移位。然后可以创建滚动数据集,并计算每个两个值窗口的平均值。
以下是前三个滚动窗口中的值
|
1 2 3 4 |
#,窗口值 1,NaN 2,NaN,20.7 3, 20.7, 17.9 |
这表明我们直到第3行才会有可用数据。
最后,像上一节一样,我们可以使用 concat() 函数来构建一个只包含新列的新数据集。
以下示例演示如何使用 Pandas 和大小为 2 的窗口来完成此操作。
|
1 2 3 4 5 6 7 8 9 10 11 |
from pandas import read_csv from pandas import DataFrame 从 pandas 导入 concat series = read_csv('daily-min-temperatures.csv', header=0, index_col=0) temps = DataFrame(series.values) shifted = temps.shift(1) window = shifted.rolling(window=2) means = window.mean() dataframe = concat([means, temps], axis=1) dataframe.columns = ['mean(t-2,t-1)', 't+1'] print(dataframe.head(5)) |
运行示例将打印新数据集的前5行。我们可以看到前两行没有用。
- 第一个 NaN 是由序列的移位创建的。
- 第二个是因为 NaN 不能用于计算平均值。
- 最后,第三行显示了预期的值19.30(20.7和17.9的平均值),用于预测序列中的第三个值18.8。
|
1 2 3 4 5 6 |
均值(t-2,t-1) t+1 0 NaN 20.7 1 NaN 17.9 2 19.30 18.8 3 18.35 14.6 4 16.70 15.8 |
我们可以计算更多的统计数据,甚至可以用不同的数学方法来定义“窗口”。
下面是另一个示例,展示了一个宽度为3的窗口,以及一个包含更多摘要统计信息的数据集,特别是窗口中的最小值、平均值和最大值。
您可以在代码中看到,我们明确地将滑动窗口宽度指定为命名变量。这使我们可以在计算序列的正确偏移量和向 `rolling()` 函数指定窗口宽度时都使用它。
在这种情况下,窗口宽度为3意味着我们必须将序列向前移动2个时间步。这将使前两行为NaN。接下来,我们需要计算每个窗口包含3个值的窗口统计量。需要3行才能在窗口中从序列中获得足够的数据来开始计算统计量。前5个窗口中的值如下所示:
|
1 2 3 4 5 6 |
#,窗口值 1,NaN 2,NaN,NaN 3,NaN,NaN,20.7 4,NaN,20.7,17.9 5, 20.7, 17.9, 18.8 |
这表明我们预计至少要到第5行(数组索引4)才会有可用数据。
|
1 2 3 4 5 6 7 8 9 10 11 |
from pandas import read_csv from pandas import DataFrame 从 pandas 导入 concat series = read_csv('daily-min-temperatures.csv', header=0, index_col=0) temps = DataFrame(series.values) width = 3 shifted = temps.shift(width -1) window = shifted.rolling(window=width) dataframe = concat([window.min(), window.mean(), window.max(), temps], axis=1) dataframe.columns = ['min', 'mean', 'max', 't+1'] print(dataframe.head(5)) |
运行代码将打印新数据集的前5行。
我们可以检查第5行(数组索引4)值的正确性。我们可以看到17.9确实是[20.7, 17.9, 18.8]窗口中的最小值,而20.7是最大值。
|
1 2 3 4 5 6 |
最小值 平均值 最大值 t+1 0 NaN NaN NaN 20.7 1 NaN NaN NaN 17.9 2 NaN NaN NaN 18.8 3 NaN NaN NaN 14.6 4 17.9 19.133333 20.7 15.8 |
扩展窗口统计
另一种可能有用的窗口类型是包含序列中所有先前数据。
这称为扩展窗口,有助于跟踪可观测数据的边界。与 `DataFrame` 上的 `rolling()` 函数一样,Pandas 提供了一个 `expanding()` 函数,该函数收集每个时间步的所有先前值集。
这些先前的数字列表可以进行汇总并作为新特征包含在内。例如,以下是序列前5个时间步的扩展窗口中的数字列表:
|
1 2 3 4 5 6 |
#,窗口值 1, 20.7 2, 20.7, 17.9, 3, 20.7, 17.9, 18.8 4, 20.7, 17.9, 18.8, 14.6 5, 20.7, 17.9, 18.8, 14.6, 15.8 |
再次,您可以看到我们必须将序列向前移动一个时间步,以确保我们希望预测的输出值被排除在这些窗口值之外。因此,输入窗口如下所示:
|
1 2 3 4 5 6 |
#,窗口值 1,NaN 2,NaN,20.7 3, NaN, 20.7, 17.9, 4, NaN, 20.7, 17.9, 18.8 5, NaN, 20.7, 17.9, 18.8, 14.6 |
幸好,统计计算会排除扩展窗口中的 NaN 值,这意味着不需要进一步修改。
以下是计算每日温度数据集上扩展窗口的最小值、平均值和最大值的示例。
|
1 2 3 4 5 6 7 8 9 10 |
# 创建扩展窗口特征 from pandas import read_csv from pandas import DataFrame 从 pandas 导入 concat series = read_csv('daily-min-temperatures.csv', header=0, index_col=0) temps = DataFrame(series.values) window = temps.expanding() dataframe = concat([window.min(), window.mean(), window.max(), temps.shift(-1)], axis=1) dataframe.columns = ['min', 'mean', 'max', 't+1'] print(dataframe.head(5)) |
运行示例将打印数据集的前5行。
检查扩展的最小值、平均值和最大值表明示例达到了预期效果。
|
1 2 3 4 5 6 |
最小值 平均值 最大值 t+1 0 20.7 20.700000 20.7 17.9 1 17.9 19.300000 20.7 18.8 2 17.9 19.133333 20.7 14.6 3 14.6 18.000000 20.7 15.8 4 14.6 17.560000 20.7 15.8 |
总结
在本教程中,您学习了如何使用特征工程将时间序列数据集转换为机器学习的监督学习数据集。
具体来说,你学到了:
- 时间序列数据特征工程的重要性及目标。
- 如何开发日期时间特征和滞后特征。
- 如何开发滑动和扩展窗口摘要统计特征。
您还知道其他时间序列的特征工程方法吗?
请在下方评论中告诉我。
您有任何问题吗?
请在下方评论中提出您的问题,我将尽力回答。
想用Python开发时间序列预测吗?

几分钟内开发您自己的预测
...只需几行python代码在我的新电子书中探索如何实现
Python 时间序列预测入门
它涵盖了**自学教程**和**端到端项目**,主题包括:*数据加载、可视化、建模、算法调优*等等。
最终将时间序列预测带入
您自己的项目
跳过学术理论。只看结果。






关于时间序列特征工程的精彩介绍。我原以为这只适用于科学头脑,但实际上它非常简单。我很享受您解释的简单方式。我现在已经准备好迎接在我专业领域中使用时间序列的任何挑战。谢谢!!!!
我很高兴听到这个消息,Dario。
最小值 平均值 最大值 t+1
0 NaN NaN NaN 20.7
1 NaN NaN NaN 17.9
2 NaN NaN NaN 18.8
3 NaN NaN NaN 14.6
4 17.9 19.133333 20.7 15.8
为什么你移动了2步而不是1步?为了使其
最小值 平均值 最大值 t+1
0 NaN NaN NaN 20.7
1 NaN NaN NaN 17.9
2 NaN NaN NaN 18.8
3 17.9 19.133333 20.7 14.6
顺便说一句,帖子很棒……谢谢!!
你好Fai,移位可能会让人困惑。
我试图通过展示在构建时窗口中每行观测值组的样子来解释它。我想它没有起到解释工具的作用。
谢谢回复。这是一个很好的解释工具。但我很好奇,
如果移动1步,我们可以得到以下窗口观测值,
并且第4行可以有足够的数据来计算包含3个值的窗口统计量。
1,NaN
2,NaN,20.7
3,NaN,20.7,17.9
4, 20.7, 17.9, 18.8
那么为什么我们要移动2步呢(我们只能从第5行开始计算)?
1,NaN
2,NaN,NaN
3,NaN,NaN,20.7
4,NaN,20.7,17.9
5, 20.7, 17.9, 18.8
如果你问为什么窗口大小是“3”或“2”甚至“1”,这没有原因。只是为了演示目的。
我们可以使用自相关来找到好的窗口大小(ACF(自相关函数)和相关图),我将在未来的帖子中深入探讨这一点。
这有帮助吗?还是我仍然误解了?
嗨,Jason,
实际上,我也有同样的疑问。我们在这里应用了两个概念。
1. 滚动窗口。大小是3,这不是问题。
2. 滞后。偏移量是2,问题是:为什么我们不使用时间步长1、2和3来为时间步长4创建特征?为什么我们使用时间步长1、2和3来在时间步长5中创建特征?我指的是特征(3个领先测量值的最小值、最大值和均值)。
不是:shifted = temps.shift(width – 1)
我们为什么不使用:shifted = temps.shift(1)
没有理由。这是一个错误。偏移量应该始终是1,而不是与窗口大小相关。
对不起,您能详细解释一下如何使用自相关来找到合适的窗口大小吗?
是的,请看这篇文章
https://machinelearning.org.cn/gentle-introduction-autocorrelation-partial-autocorrelation/
是的,我也很困惑。看起来平均值是用(t-4,t-3,t-2)计算的。我期望用(t-3,t-2,t-1)计算。你能解释一下为什么不是这样吗?
0 (t+1) (t-1) (t-2) (t-3) (t-4) mean(t-2, t-1) mean(t-3, t-2, t-1) mean(t-4, t-3, t-2)
1 20.7 NA NA NA NA NA NA NA
2 17.9 20.7 NA NA NA NA NA NA
3 18.8 17.9 20.7 NA NA 19.3 NA NA
4 14.6 18.8 17.9 20.7 NA 18.35 19.13333 NA
5 15.8 14.6 18.8 17.9 20.7 16.7 17.1 19.13333
这是随意选择的。您可以根据自己的喜好进行计算。
嗨,Jason,很棒的介绍。如果你对更多统计特征感兴趣,请查看
http://rsif.royalsocietypublishing.org/content/10/83/20130048.full 及相关的github仓库。
我发现它是时间序列特征工程最完整的工作。
谢谢分享,Hicham。
Hicham,很棒的参考资料,谢谢!Jason,你的博客、网站和解释都很出色,谢谢你。
你好,
在滚动平均值中,为什么您要对原始变量进行滞后处理,而不是直接使用原始变量?
在这种情况下,数据是单变量的,除了“发明”的滞后变量之外,没有其他变量。
嗨 Jason
当你写“预测每日最高气温”时,你的意思是“预测每日最低气温”吗?
是的,Daniel,谢谢。已修复。
我读取数据时出错了。你到底在哪里发现了问号?
您可以使用文本编辑器和查找替换功能。
如何为测试数据创建滞后变量?我们对测试数据一无所知,对吗?
测试数据的滞后将是训练数据的末尾。
您可以使用本文中的函数准备数据。
https://machinelearning.org.cn/convert-time-series-supervised-learning-problem-python/
嗨,Jason,
感谢这篇精彩的文章。
我可以问一下哪个在前吗?
在原始时间序列数据集上分割训练/测试集
或
在转换后的(例如,经过特征工程后)数据集上分割训练/测试集?
请指教,
Shaun
很好的问题。
缩放应用于每个变量。
转换为监督学习发生在分割之前。
但是,您需要确保任何缩放都仅在训练集上学习,并应用于测试集——这样就不会有数据泄露。
不确定这是否有帮助?
如果您能添加一些关于使用机器学习技术(如最近邻或SVR方法)进行时间序列预测的评论,那将非常棒。
很好的建议,我希望将来能涵盖它。
你好!
有一个使用 LSTM 进行时间序列预测的任务。
多个输入变量
1年
2. 月份
3. 星期几
4. 月份日期
5. 一天中的小时
…
一天中的小时。
是否为工作时间。
是否为周末。
印象数 – 销售量
需要帮助 – 如何在 Python 中使用 Keras 实现该算法。
谢谢!
我建议使用我关于时间序列 LSTM 的众多帖子中的任何一篇作为起点,并将其应用于您的问题。
我喜欢这句话:复杂性存在于输入和输出数据之间的关系中!
因为输出数据可能不是输入数据的直接结果,我们正在努力做的是在 A 和 B 之间建立可预测的关系。通过特征工程,我们希望通过可能更具信息量且更接近 B 的中间特征来降低建立关系的复杂性和难度。
我们总是希望建立更紧密的桥梁以节省时间和精力。
非常感谢您精辟的总结和精彩的解释!它非常鼓舞人心且有帮助。
顺便问一下,您在这里说“在时间序列的情况下,没有输入和输出变量的概念”是什么意思?我们难道不是总是得到一个带有时间步(输入)和其值(Y)的时间序列吗?您是指我们要发明的新特征的输入和输出变量概念吗?
谢谢。
谢谢!
我想我的意思是,在单变量时间序列中,我们实际上只有滞后观测值。
你好,Jason!这篇作品很棒!
我有一个关于如何对这类数据集进行采样的问题。
我的理解是,由于特征是从时间序列中生成的,行之间和变量之间存在时间依赖性。因此,它可能需要与我们假设行之间相互独立的正常数据集不同的处理。
您能否就应用于此类数据集的采样方法提供建议?
非常感谢!
是的,您可以使用前向验证来评估序列预测模型。
请看这篇文章
https://machinelearning.org.cn/backtest-machine-learning-models-time-series-forecasting/
你好,Jason。
您认为将日期时间特征与滞后特征结合起来如何?这种方法合理吗?
非常感谢。
也许可以。
我建议进行实验,并使用结果/数据来决定它是否适合您的特定预测问题。
你好,
我有一个多模态的时间序列数据(csv),(从不同的传感器获取)。我的任务是通过从这些数据中提取特征来实现多分类。你能给我一个起点吗?有没有关于分类的帖子?
好问题。
我还没有关于时间序列分类的帖子。我希望将来能有一些。
这取决于你想做什么。以及时间序列代表什么。例如,整个时间序列是否具有相同的标签。
你可以尝试计算整个时间序列的统计特征(在时间域和频率域)(如果你只有一个时间序列,这不太有价值),或者将时间序列分成窗口,并对这些窗口(针对每个传感器)计算特征。
与所有分类一样,您需要不同类别中足够数量的标签表示。因此,在我看来,您要么需要多个数据集,要么数据变化足够大,以便您可以将其拆分并标记每个部分。
在计算了一些通用统计特征后,您可以深入挖掘,看看是否可以开发一些与您问题相关的更具体的特征。
我对你的术语有点困惑。你使用“t-1”和“t+1”,并指使用滞后的“t-1”值通过监督机器学习预测“t+1”值。更准确的说法是不是我们使用“t-1”来预测“t”值?在使用机器学习算法时,“t”值会是“目标变量”吗?
为了澄清我问题的背景,这里有一些背景信息。我正在尝试使用机器学习示例来预测未来月份的商品销售额,给定销售历史记录。我的训练数据包含前3个月的滞后月度销售额,并且对于每个训练行,目标变量是当前月份的月度销售额。当我阅读你这篇出色的文章时,我开始思考我是否应该在每个训练行中添加一个额外的特征……即下个月的销售额(t+1)。
还有一个后续问题是,您是否发现添加“近期增长”特征很有用。在我的示例中,这将突出一个热门新产品或一个开始走下坡路的产品。
非常感谢这篇精彩的文章!
是的,t+1 应该是 t。我在关于该主题的书籍中清理了这些术语。
你说的很对。很棒的材料。谢谢。
谢谢。
感谢您这一系列出色的文章。我读了许多关于视频教程的书籍,但我总是发现,在阅读其他内容后遇到的任何问题,您的博客文章都能解答。
我有一个尚未找到答案的问题:提供单变量时间序列数据的均值、标准差或任何其他统计导数,还是仅提供原始滞后数据本身更好?这会取决于数据的领域(例如,如果数据包含股票价格与温度数据相比,答案会有很大差异吗?)还是这更多是一个独立于领域的统计问题?
换句话说,如果我必须回答一个问题,我应该提供数据的均值而不是原始数据(并假设数据是股票价格),我应该查阅机器学习的研究文献还是金融市场的文献?
感谢您的任何输入。
是的,这取决于数据以及您用来解决它的方法。
例如,对于机器学习算法可能合理,但对于ARIMA或ETS方法则不合理。
至于股价,它们是不可预测的。
https://machinelearning.org.cn/faq/single-faq/can-you-help-me-with-machine-learning-for-finance-or-the-stock-market
在日期时间特征中,我在温度列中得到了完整的日期 1981-01-01,有什么原因吗?(注意我是以 read_csv 而不是 series 的方式读取文件的)
谢谢
Brian
这可能是Pandas最新版本中的一个变化吗?
如果数据非平稳,我们是否先进行变换和差分以消除不恒定的方差和趋势,然后再进行特征工程?
您可以使用幂变换来调整变化的方差,然后进行差分以去除趋势/季节性。
感谢您这篇精彩的阅读。
我希望每一行都是按小时格式的,但算法要预测24小时后的值。
原因是预测变量的每小时变化太小,但我确实想每小时进行一次预测。
1. 计算一个带有 `shift(-24)` 的新列并将其用作预测值是否有意义?
2. 假设您没有足够多的墨尔本气温数据。
假设您想使用其他城市来构建通用模型(这样您就有更多数据)。
假设气温值不同,但它们的行为相似。
使用 `pct_change` 而不是原始值(甚至对于 `max`、`min` 和 `mean`)计算是否有意义?
我不确定我是否理解,抱歉。
感谢这篇精彩的文章!
我很好奇,在进行位移时,是否需要包含“位移”期间的特征?
例如,假设这是一个高度依赖去年销售额和是否是假期的时间序列,我想预测销售额。
那么我有一个特征是去年同期的销售额,一个特征是假期(1/0)。
如果我想预测2018年4月16日的销售额,它不是假日,所以该特征将为0,我将只使用2017年同期的销售额。但去年销售额的特征会受到影响,因为2017年那天是复活节。
那么我是否需要添加一个诸如“去年同日假期”的特征(1/0),或者这已经被其他特征涵盖了?
希望我的问题清晰….
感谢这个精彩的博客!
当然可以。
嗨,Jason,
在运行滚动窗口代码时,出现错误
“无法处理此类型 -> object”
我正在运行您所使用的数据集的代码
您使用的是 Python 3 和 statmodels 8+ 吗?
你好,
再次感谢您的精彩文章。您知道 Python Featuretools 和 Autokeras 吗?很高兴能看到这些工具的比较。
感谢 Magnus 的建议。
哇。你再次完美地解释了这些概念。
阅读了其他5篇关于同一主题的文章之后,我现在终于明白了。
非常感谢!
我很高兴它帮助了 Jon!
嗨,Jason,
非常感谢这篇有用的文章。但是请问您能展示一下如何编码非线性窗口吗,就像您这里提到的那样:“此外,为什么止步于线性窗口?也许您需要上周、上个月和去年的滞后值。同样,这取决于具体的领域。
就温度数据集而言,前一年或前几年同一天的滞后值可能很有用。”
再次感谢您!
感谢您的建议。
嘿,杰森!
您的教程总是非常有帮助!我有一个快速问题。如果我只想使用标准线性回归与这些类型的特征。填充偏移变量上的 NaN 值有哪些常见方法?
包含 NaN 的行必须被丢弃。
好的,非常感谢您的信息。您是否有使用此概念并展示如何构建预测的教程?例如,使用线性回归器或随机森林?如果没有,您能提供一个您可能使用的步骤的高级解释吗?同时我可能会编写一些代码来获得一些反馈。
我可能会,也许在这里查看一下
https://machinelearning.org.cn/start-here/#deep_learning_time_series
也许这个
https://machinelearning.org.cn/multi-step-time-series-forecasting-with-machine-learning-models-for-household-electricity-consumption/
这些是任何项目的步骤
https://machinelearning.org.cn/start-here/#process
嗨,Jason!
感谢这篇精彩的文章!它真的很有帮助。如果您不介意,我有一个问题。如果我要计算滚动窗口统计量,有没有确定窗口大小的方法?提前感谢您!
也许可以测试一系列不同的配置,看看哪种最适合您的特定数据集和模型选择。
嗨,Jason!
首先,感谢您的文章。但我有一些问题。在您的情况下,您只预测下一个时间序列,即 t+1。但如果我需要预测接下来两个或更多时间序列呢?
对于像ARIMA这样的线性模型,您可以调用forecast()或predict()并指定要预测的步数。
注意到一些可能与此相关的问题
series = Series.from_csv(‘daily-min-temperatures.csv’, header=0)
FutureWarning: from_csv 已弃用。请改用 read_csv(...)。
我测试了几种使用 read_csv 的选项,这看起来很匹配(别忘了导入 pandas 为 pd)
series = pd.read_csv(‘daily-min-temperatures.csv’, index_col=0, squeeze=True)
复制/粘贴错误,应该是
series = pd.read_csv(‘daily-min-temperatures.csv’, index_col=0, parse_dates=True, squeeze=True)
感谢分享。
嗨,我认为这部分代码是错误的
from pandas import read_csv
from pandas import DataFrame
series = read_csv(‘daily-min-temperatures.csv’, header=0, index_col=0)
dataframe = DataFrame()
dataframe[‘month’] = [series.index[i].month for i in range(len(series))]
dataframe[‘day’] = [series.index[i].day for i in range(len(series))]
dataframe[‘temperature’] = [series[i] for i in range(len(series))]
print(dataframe.head(5))
它给我以下错误
AttributeError: 'str' object has no attribute 'month'
谢谢,我已经更新了示例。
嗨,Jason,
首先,感谢您的教程!
我们如何决定窗口的宽度?我们应该使用频率吗?有什么通用的规则吗?谢谢!
也许可以测试一系列配置,找出最适合您的数据集和模型选择的配置?
此外,ACF/PACF 图也可能提供一些见解。
这些对我有帮助。非常感谢!我能练习并把它放到我的github上吗?当然,源代码链接也会一起上传。
如果不是公开的。
嗨,Jason,
感谢您出色的工作。我有一个问题,希望您不介意。我正在尝试使用 Xgboost 构建一个每周销售预测模型。我的目标是使用该模型预测未来8周的销售额。但我对滞后(lag)和差分(diff)特征感到困惑。我创建了许多特征,例如滞后2、滞后3、滞后4、滞后5以及差分2、差分3、差分4、差分5。它在我的训练集和测试集(基于历史数据)中表现出色。同时,我还检查了特征重要性。这些滞后和差分特征在所有特征中排名靠前。但是当我想要预测未来几周的销售额时,我没有实际的销售数据,所以许多特征会变成 NaN,预测结果似乎不合理。我可以问一下您以前遇到过这个问题吗?我应该如何处理未来时间窗口上的滞后和差分特征?谢谢!
大卫
好问题。
是的,您必须根据在需要进行预测时可用的数据来选择您的输入变量(构建预测问题)。例如,如果预测时没有具体的实验室观测数据,那么就不要将问题构建为包含该数据。
这有帮助吗?
嗨,Jason,
感谢您的回复。我曾尝试从我的数据框中移除差异变量,但在训练集和测试集上的损失函数都变大了。请问我是否可以使用ARIMA、Prophet等其他单变量预测方法的预测结果作为未来销售值来做差异特征,然后将其作为Xgboost模型的输入?我的想法有道理吗?
此致,
大卫
或许可以试试?
嗨 Jason,
希望您一切都好。关于寻找滞后我有一个疑问。我正在尝试将时间序列问题转换为回归问题。为此,我如何根据日期、产品和位置来寻找滞后?我的意思是,在寻找滞后之前如何排序。
谢谢!
谢谢。
看这里
https://machinelearning.org.cn/time-series-forecasting-supervised-learning/
你好,如何使用滑动窗口方法预测时间序列数据
我在这篇教程中没有找到任何使用滑动窗口的预测方法
请分享您使用滑动窗口方法预测时间序列数据的链接
请看这里的例子
https://machinelearning.org.cn/start-here/#deep_learning_time_series
太棒了!
很高兴它对您有帮助!
嗨,Jason,这是一篇很棒的教程!
我有两个问题
1. 关于数据转换(幂变换、季节性差分、趋势差分、标准化、归一化),如您文章中提到的
“时间序列预测的4种常见机器学习数据转换”,
何时进行特征工程——是使用转换后的数据还是原始数据?
2. 如果工程特征是从转换后的数据中得出的,是否也应该同样进行转换?据我理解(不确定是否正确),工程特征只有在从原始数据中获得时才需要转换。
谢谢!
两者皆可,或者两者都尝试一下。
我可能会从原始数据中提取特征,然后对它们进行相同类型的数据预处理,如果适用的话。
很棒的入门介绍,谢谢!一个观察是,将日期时间特征转换为循环变量可能更好,以捕捉时间的循环模式。我相信这篇文章很好地展示了这一点:http://blog.davidkaleko.com/feature-engineering-cyclical-features.html
谢谢。
嗨,Jason,
感谢您的教程。我有一个关于多变量时间序列分类的问题。我每时每刻都有20个传感器的测量值。由于我也对时间信息感兴趣,我将我的特征连接了多个时间点,比如10个时间点。所以,每个样本将有20 * 10 = 200的长度。我的问题是,我是在连接多个时间点上的特征之后还是之前进行数据标准化/缩放?谢谢!
在将数据转换为监督学习问题之前,可能需要先对数据进行缩放。例如,对每个变量进行缩放。
你好 Jason,
非常感谢这篇教程。我还有一个额外的问题:如果我有一个股票价格的每小时收盘价数据集,并且我想创建训练数据集。对于每个样本,我将需要过去6小时和过去6天作为特征。我将如何把每小时的数据集转换为包含过去6小时价格和过去6天价格的训练数据集?
非常感谢!
这会有帮助
https://machinelearning.org.cn/time-series-forecasting-supervised-learning/
还有这个。
https://machinelearning.org.cn/convert-time-series-supervised-learning-problem-python/
还有这个。
https://machinelearning.org.cn/faq/single-faq/can-you-help-me-with-machine-learning-for-finance-or-the-stock-market
我想在我的数据集上应用“滑动窗口”方法,窗口大小为5秒。您能举个例子帮我解决这个问题吗?
这将帮助您理解滑动窗口
https://machinelearning.org.cn/time-series-forecasting-supervised-learning/
此代码将帮助您准备数据
https://machinelearning.org.cn/convert-time-series-supervised-learning-problem-python/
亲爱的Jason
首先,感谢您如此清晰的解释!
我希望能得到您对一个我正在处理的问题的指导。
我目前正在撰写人工智能硕士论文,我们希望研究是否可以仅凭每日步数数据预测/检测慢性阻塞性肺疾病(COPD)患者的急性加重(事件)。
数据集中有几名患者发生过事件(或多次事件),我们知道事件开始的日期和持续时间。我们平均只有大约90天内的每日步数数据。
因此,我们拥有可用的数据:(i) 日期(日月年),(ii) 步数,以及 (iii) 是否发生事件(1/0)。
最后一个变量可以通过为事件发生前7天添加标签来扩展。这样,一天就可能有三个可能的标签:事件、无事件或风险。
第一种方法是将其视为一个分类问题。对于这个问题,我将提取特征(如本文详细解释的),并使用这些特征来预测一个数据点属于哪个类别(即事件、无事件或风险)。这里的假设是,如果我们可以正确预测某一天处于风险之中,那么它就能够在事件发生前预测/检测到事件。
我想听听您对这种方法的看法,以及这种特征提取对于分类问题(而不是预测问题)是否会有用。
提前感谢您!
诚挚的问候
Arne
也许可以开发一些原型,用真实数据来测试你的想法。
你好 Jason,
您有没有研究过使用TSFresh来生成时间序列特征?
目前还没有,我会把它加到列表中。
如果本文中给出的温度时间序列数据在技术报告、书籍、手稿等中复制或使用,我应该如何引用它?
数据集的详细信息在这里
https://raw.githubusercontent.com/jbrownlee/Datasets/master/daily-min-temperatures.names
嗨,Jason,
感谢您分享这篇帖子!我在理解时间序列预测的数据结构方面遇到了困难。特别是,我不明白训练集中的每一行看起来是什么样的。
例如,假设您有一个目标变量 (Y) 多年 (t),以及一些与 Y 同时测量的特征 (A 和 B)。在训练集中,模型是学习当 A 和 B 在同一年被测量时 Y 的值,还是应该对 A 和 B 进行滞后处理?换句话说,对于数据中的每一行,应该是 Y_t = A_t-1 + B_t-1 还是 Y_t = A_t + b_t?
我的直觉是 A 和 B 应该滞后,因为如果我们真的关心预测,我们将不知道 A、B 和 Y 在未来的值。
我希望这个问题有意义,它困扰我一段时间了!
我建议从这里开始
https://machinelearning.org.cn/time-series-forecasting-supervised-learning/
嗨 Jason
我有一个数据集,其中销售额与个人收入的滞后值相关……个人收入的增加会在一段时间后影响销售额。我在确定滞后窗口方面遇到问题……您能给我一些建议吗?
测试一系列值,并使用能够产生最佳模型技能的窗口大小。
你好,
我目前正在撰写关于使用机器学习预测钻井中危险事件的硕士论文,我们希望根据时间序列钻井数据预测/检测钻井中的井涌或循环损失(钻井中的危险)。
总的来说,我有一些特征(可能20个或更多),我必须从中选择6-7个(最适合的)来构建我的机器学习模型。由于危险事件的发生基于多个因素,所以预测是一个多变量时间序列问题。
请问您能否指导我如何在这种情况下从20个特征中选择6-7个特征?
谢谢
也许这会有帮助。
https://machinelearning.org.cn/feature-selection-with-real-and-categorical-data/
我有一个天真的问题。在添加领域特定特征时,如果我们使用例如滞后为2的自回归模型进行时间序列分析,我们是否会将模型写为 x_t = a1*x_t-1 + a2*x_t-2+b*f1,其中 f1 是附加的领域特征?谢谢。
看起来差不多。
嗨,Jason,
“滞后特征是时间序列预测问题转换为监督学习问题的经典方式。”
我不明白为什么我们需要滞后时间序列数据。
我的意思是,如果我有一组预测因子,例如经济变量,并且我必须预测一个二元变量,那么仅使用我拥有的变量还不够吗?为什么要添加它们的滞后版本?
问题仍然可以是监督学习……我无法理解。
提前感谢
Luigi
好问题,请看这个
https://machinelearning.org.cn/time-series-forecasting-supervised-learning/
您好,非常感谢您的精彩解释,太棒了!我想知道您将如何把一个经过特征工程统计的时间序列数据集/数据框加载到ARIMA中?如果您有示例或文章,将不胜感激。谢谢!
谢谢!
抱歉,我没有关于这个主题的文章。
我希望使用滑动窗口提取时间序列的时域和频域特征。采样率为1000Hz。我不知道如何选择合适的窗口大小。我看到您提到ACF可能有用,但在阅读文章后我仍不明白它如何有用。
另外,对于rolling()函数,有可用的选项可以选择窗口类型
https://docs.scipy.org.cn/doc/scipy/reference/signal.windows.html#module-scipy.signal.windows
如何选择一个?
本教程将帮助您理解ACF和PACF图
https://machinelearning.org.cn/gentle-introduction-autocorrelation-partial-autocorrelation/
嗨 Jason
您能给我展示一个带有多时间步的多变量索引滞后的例子吗?
谢谢
也许这里的例子可以作为第一步帮助您
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
嗨,Jason,
非常感谢又一篇精彩的文章。我有一个快速问题——假设我们有一个温度预测的扩展。所以,我希望能够预测特定州或国家在下一个时间戳的温度。我是为每个州/国家分别创建这些特征吗?请就如何为这类问题创建特征提供建议。
谢谢
为了进行预测,您将需要模型预期的任何输入。这假设这些输入是可用的或可以构建的。如果不是,您可能需要根据预测时仅可用的数据来改变问题的框架。
您好,Brownlee先生
这篇教程对我帮助很大,非常感谢。
我只有一个问题
在时间序列问题中,我们可以使用GridSearchCV或RandomSearchCV方法来调整超参数吗?还是有其他方法我们应该使用?
致以最诚挚的问候。
是的,您可以。但这取决于您如何实现模型。GridSearchCV和RandomSearchCV看起来是指scikit-learn中的。它假定模型遵循scikit-learn API。只要您的模型是这样创建的,它就应该可以工作。
假设数据以高频率传入,这意味着所有提到的计算都会非常昂贵。我们如何在生产时处理特征工程?
嗨,KL……您的问题属于机器学习操作的范畴。以下是一个很好的起点
https://www.coursera.org/specializations/machine-learning-engineering-for-production-mlops?utm_source=gg&utm_medium=sem&utm_campaign=28-MLOps-DL.ai-US&utm_content=B2C&campaignid=13572037851&adgroupid=120618068101&device=c&keyword=mlops%20coursera&matchtype=p&network=g&devicemodel=&adpostion=&creativeid=528598123150&hide_mobile_promo&gclid=Cj0KCQiAmKiQBhClARIsAKtSj-kTX7CAJxkQWAtoIM5QJQcb_9e1BhozWdb7RH2ZrST2a9jcs1dhsn4aAhyAEALw_wcB
你好,非常感谢……我已经用Python实现了多元时间序列,感谢您的教程,但我一直注意到,当我使用多个变量(多元)时,模型性能与单变量相比相同甚至更差。实际上,我正在尝试构建有助于更好预测的特征,但一直没有成功……您有什么建议可以解决这个问题吗?谢谢
嗨,Zaid……不客气!以下是关于您问题的一个很好的起点
https://machinelearning.org.cn/feature-selection-time-series-forecasting-python/
嗨,Jason,
对于多变量时间序列预测,假设我想使用最后10行来预测接下来的1行。如果我首先划分训练和测试数据,然后在两个数据集中创建新列,该列是目标变量所有行的平均值(在训练和测试数据集上分别计算平均值)。我在这里不使用滚动平均值。我还创建了一个附加列,它是每行与平均值的偏差。这种特征生成是否正确,没有数据泄露?
嗨,Ajinkya……以下资源可能对您有用
https://spotintelligence.com/2023/08/04/data-leakage-in-machine-learning/#:~:text=Split%20Data%20Before%20Preprocessing%3A%20Ensure,feature%20engineering%20or%20data%20cleaning.