用于梯度提升的 XGBoost 库专为高效的多核并行处理而设计。
这使得它在训练时可以有效利用系统中的所有 CPU 核心。
在这篇文章中,您将了解 Python 中 XGBoost 的并行处理能力。
阅读本文后,您将了解
- 如何确认您的系统上 XGBoost 多线程支持是否正常工作。
- 如何评估增加线程数对 XGBoost 的影响。
- 如何在交叉验证和网格搜索中使用多线程 XGBoost 时获得最佳效果。
通过我的新书《XGBoost With Python》启动您的项目,其中包括所有示例的分步教程和 Python 源代码文件。
让我们开始吧。
- 2017 年 1 月更新:已更新以反映 scikit-learn API 0.18.1 版本中的更改。

如何在 Python 中为 XGBoost 最佳地调整多线程支持
照片由 Nicholas A. Tonelli 拍摄,保留部分权利。
在 Python 中使用 XGBoost 需要帮助吗?
参加我的免费 7 天电子邮件课程,探索 xgboost(含示例代码)。
立即点击注册,还将免费获得本课程的 PDF 电子书版本。
问题描述:Otto 数据集
在本教程中,我们将使用 Otto Group 产品分类挑战赛 数据集。
此数据集可从 Kaggle 获取(您需要注册 Kaggle 才能下载此数据集)。您可以从 数据页面 下载训练数据集 train.zip,并将解压后的 train.csv 文件放入您的工作目录。
此数据集描述了超过 61,000 种产品中 93 个模糊的详细信息,这些产品分为 10 个产品类别(例如时尚、电子等)。输入属性是某种不同事件的计数。
目标是为新产品进行预测,预测结果是每个 10 个类别的概率数组,模型使用多类对数损失(也称为交叉熵)进行评估。
此竞赛于 2015 年 5 月结束,此数据集对 XGBoost 来说是一个很好的挑战,因为示例数量不少,问题难度不低,并且除了将字符串类变量编码为整数之外,几乎不需要数据预处理。
线程数的影响
XGBoost 使用 C++ 实现,以明确利用 OpenMP API 进行并行处理。
梯度提升中的并行性可以在单个树的构建中实现,而不是像随机森林那样并行创建树。这是因为在提升中,树是顺序添加到模型中的。XGBoost 的速度在于在单个树的构建中添加并行性,以及高效准备输入数据以帮助加快树的构建速度。
根据您的平台,您可能需要专门编译 XGBoost 以支持多线程。有关更多详细信息,请参阅 XGBoost 安装说明。
用于 scikit-learn 的 XGBoost 的 XGBClassifier 和 XGBRegressor 封装类提供了 nthread 参数,用于指定 XGBoost 在训练期间可以使用的线程数。
默认情况下,此参数设置为 -1,以利用系统中的所有核心。
|
1 |
model = XGBClassifier(nthread=-1) |
通常,您的 XGBoost 安装应该无需额外工作即可获得多线程支持。
根据您的 Python 环境(例如 Python 3),您可能需要明确启用 XGBoost 的多线程支持。如果您需要帮助,XGBoost 库提供了一个示例。
您可以通过构建多个不同的 XGBoost 模型,指定线程数并计时每个模型构建所需的时间来确认 XGBoost 多线程支持是否正常工作。这种趋势将表明多线程支持已启用,并给出其在构建模型时的效果指示。
例如,如果您的系统有 4 个核心,您可以训练 8 个不同的模型,并计时创建每个模型所需的秒数,然后比较这些时间。
|
1 2 3 4 5 6 7 8 9 10 |
# 评估线程数的影响 results = [] num_threads = [1, 2, 3, 4] for n in num_threads: start = time.time() model = XGBClassifier(nthread=n) model.fit(X_train, y_train) elapsed = time.time() - start print(n, elapsed) results.append(elapsed) |
我们可以在 Otto 数据集上使用这种方法。完整的示例在下面提供,以供参考。
您可以更改 num_threads 数组以适应您系统上的核心数量。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# Otto,调整线程数 from pandas import read_csv from xgboost import XGBClassifier from sklearn.preprocessing import LabelEncoder import time from matplotlib import pyplot # 加载数据 data = read_csv('train.csv') dataset = data.values # 将数据拆分为 X 和 y X = dataset[:,0:94] y = dataset[:,94] # 将字符串类值编码为整数 label_encoded_y = LabelEncoder().fit_transform(y) # 评估线程数的影响 results = [] num_threads = [1, 2, 3, 4] for n in num_threads: start = time.time() model = XGBClassifier(nthread=n) model.fit(X, label_encoded_y) elapsed = time.time() - start print(n, elapsed) results.append(elapsed) # 绘制结果 pyplot.plot(num_threads, results) pyplot.ylabel('速度(秒)') pyplot.xlabel('线程数') pyplot.title('XGBoost 训练速度 vs 线程数') pyplot.show() |
注意:由于算法或评估过程的随机性,或数值精度的差异,您的 结果可能会有所不同。建议运行几次示例并比较平均结果。
运行此示例会总结每种配置的执行时间(秒)。
|
1 2 3 4 |
(1, 115.51652717590332) (2, 62.7727689743042) (3, 46.042901039123535) (4, 40.55334496498108) |
这些时间表的图表如下所示。
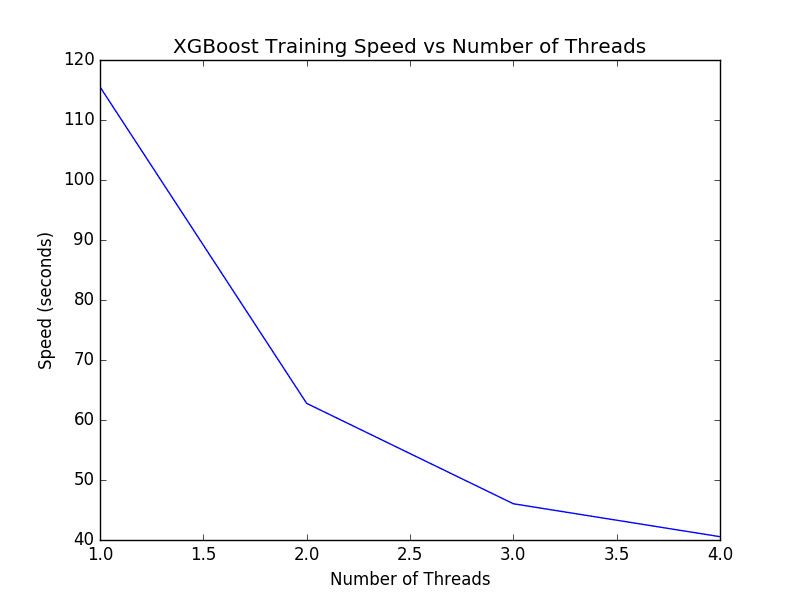
XGBoost 单模型线程数调整
我们可以看到随着线程数的增加,执行时间呈现良好的下降趋势。
如果每个新线程运行时间没有改善,您可能需要调查如何在安装或运行时启用 XGBoost 中的多线程支持。
我们可以在具有更多核心的机器上运行相同的代码。据报道,大型 Amazon Web Services EC2 实例有 32 个核心。我们可以调整上述代码,以计时使用 1 到 32 个核心训练模型所需的时间。结果如下所示。
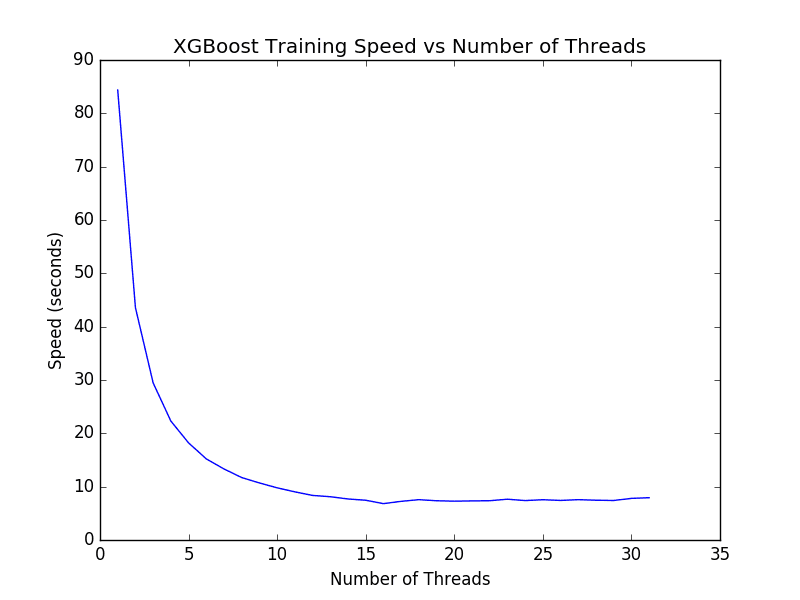
XGBoost 在 1 到 32 个核心上训练模型的时间
有趣的是,我们注意到超过 16 个线程后(大约 7 秒),性能并没有显著改善。我预计这是因为亚马逊实例只提供 16 个硬件核心,而额外的 16 个核心是通过超线程提供的。结果表明,如果您的机器支持超线程,您可能希望将 num_threads 设置为等于您机器中物理 CPU 核心的数量。
XGBoost 与 OpenMP 的低级优化实现充分利用了这样一台大型机器的每一个周期。
交叉验证 XGBoost 模型时的并行性
scikit-learn 中的 k-折交叉验证也支持多线程。
例如,用于使用 k-折交叉验证评估数据集上模型的 cross_val_score() 函数上的 n_jobs 参数允许您指定要运行的并行作业数。
默认情况下,这设置为 1,但可以设置为 -1 以使用系统中的所有 CPU 核心,这是一种好做法。例如
|
1 |
results = cross_val_score(model, X, label_encoded_y, cv=kfold, scoring='log_loss', n_jobs=-1, verbose=1) |
这就提出了交叉验证应该如何配置的问题
- 禁用 XGBoost 中的多线程支持,并允许交叉验证在所有核心上运行。
- 禁用交叉验证中的多线程支持,并允许 XGBoost 在所有核心上运行。
- 同时启用 XGBoost 和交叉验证的多线程支持。
我们可以通过简单地计时在每种情况下评估模型所需的时间来回答这个问题。
在下面的示例中,我们使用 10 折交叉验证来评估 Otto 训练数据集上的默认 XGBoost 模型。对上述每种情况进行评估,并报告评估模型所需的时间。
完整的代码示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# Otto,并行交叉验证 from pandas import read_csv from xgboost import XGBClassifier from sklearn.model_selection import StratifiedKFold from sklearn.model_selection import cross_val_score from sklearn.preprocessing import LabelEncoder import time # 加载数据 data = read_csv('train.csv') dataset = data.values # 将数据拆分为 X 和 y X = dataset[:,0:94] y = dataset[:,94] # 将字符串类值编码为整数 label_encoded_y = LabelEncoder().fit_transform(y) # 准备交叉验证 kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7) # 单线程 XGBoost,并行线程 CV start = time.time() model = XGBClassifier(nthread=1) results = cross_val_score(model, X, label_encoded_y, cv=kfold, scoring='neg_log_loss', n_jobs=-1) elapsed = time.time() - start print("单线程 XGBoost,并行线程 CV:%f" % (elapsed)) # 并行线程 XGBoost,单线程 CV start = time.time() model = XGBClassifier(nthread=-1) results = cross_val_score(model, X, label_encoded_y, cv=kfold, scoring='neg_log_loss', n_jobs=1) elapsed = time.time() - start print("并行线程 XGBoost,单线程 CV:%f" % (elapsed)) # 并行线程 XGBoost 和 CV start = time.time() model = XGBClassifier(nthread=-1) results = cross_val_score(model, X, label_encoded_y, cv=kfold, scoring='neg_log_loss', n_jobs=-1) elapsed = time.time() - start print("并行线程 XGBoost 和 CV:%f" % (elapsed)) |
注意:由于算法或评估过程的随机性,或数值精度的差异,您的 结果可能会有所不同。建议运行几次示例并比较平均结果。
运行示例会打印以下结果。
|
1 2 3 |
单线程 XGBoost,并行线程 CV:359.854589 并行线程 XGBoost,单线程 CV:330.498101 并行线程 XGBoost 和 CV:313.382301 |
我们可以看到,在交叉验证折叠上并行化 XGBoost 会带来好处。这是有道理的,因为 10 个顺序的快速任务优于(10 除以核心数)的慢任务。
有趣的是,我们看到通过同时启用 XGBoost 和交叉验证中的多线程实现了最佳结果。这令人惊讶,因为它意味着 num_cores 数量的并行 XGBoost 模型正在争夺相同 num_cores 来构建它们的模型。尽管如此,这实现了最快的结果,并且是建议的 XGBoost 交叉验证用法。
因为网格搜索使用相同的并行化底层方法,所以我们期望相同的发现也适用于优化 XGBoost 的超参数。
总结
在这篇文章中,您了解了 XGBoost 的多线程能力。
您学到了
- 如何检查您的系统上是否启用了 XGBoost 中的多线程支持。
- 增加线程数如何影响训练 XGBoost 模型的性能。
- 如何在 Python 中最佳配置 XGBoost 和交叉验证以实现最短运行时间。
您对 XGBoost 的多线程支持或本帖子有任何疑问吗?请在评论中提出您的问题,我将尽力回答。
发现赢得竞赛的算法!

在几分钟内开发您自己的 XGBoost 模型
...只需几行 Python 代码
在我的新电子书中探索如何实现
使用 Python 实现 XGBoost
它涵盖了自学教程,例如:
算法基础、缩放、超参数等等……
将 XGBoost 的强大功能带入您自己的项目
跳过学术理论。只看结果。





")
很好,谢谢,真的很有趣!
谢谢 Mate,很高兴你觉得它有趣。
嗨 Jason,我正在运行这段代码,使用 XGB 书中的第一批线程数。它卡在 model.fit(X, label_encoded_y) 上… 我正在使用 Python 3+ 在 Jupyter Notebook 中运行… 有人遇到过这个问题吗?
谢谢
嗨 David,也许可以尝试在笔记本外部的命令行上运行?
嗨 Jason,对于一台有 4 个核心的电脑,nthread = -1 和 nthread = 4 是一样的吗?关于交叉验证中的并行性,在我的笔记本电脑上,同时并行 XGBoost 和 CV 花了很长时间才运行,而前两种情况在合理的时间内完成。有什么想法吗?谢谢!
没错,Ruiye。
这些场景对内存和 CPU 要求很高。它可能只是占用了你的硬件——抱歉。
你好,
由于某些原因,XGBoost 在我的 Mac OS 上 Python 3 中无法并行。
我这样安装了 xgboost:
git clone –recursive https://github.com/dmlc/xgboost cd xgboost; cp make/minimum.mk ./config.mk; make -j4 workon riskvenv cd python-package sudo python setup.py install
但是 xgboost 在运行时并没有使用所有的 4 个核心,即使我指定了线程数或者没有指定。
有人知道如何解决这个问题吗?
也许是 Python 3 的问题?
我可以确认我可以在 Python 2.7 中使用 xgboost 使用所有 4 个核心。
我真的认为这篇文章具有误导性,因为默认程序是使用所有线程,所以如果您想使用所有线程(这是迄今为止最常见的情况),调整此参数将不会给您带来任何收益。
我只认为,如果您知道您有 4 个不同的模型并且只想为每个模型使用一个线程,那么才有理由调整此参数,否则我认为这篇文章没有目的。
谢谢彼得。
我想展示使用更多核心带来的加速——例如,使用大型 AWS 实例可以帮助加速你的模型。
顺便说一句,在我的配置中(conda,python 3.6.5,xgboost 0.71),如果未指定 nthread,默认似乎不会进行多线程处理。请参阅下面的结果。我建议指定 nthread=-1 或按照此帖子中的描述进行测试,以确定哪个 nthread 值效果最好。
-1 3.9046308994293213
未设置 6.836001396179199
1 6.832951545715332
2 5.142981767654419
3 4.339038848876953
4 3.99072265625
5 3.7604596614837646
6 3.6778457164764404
7 3.56015944480896
8 3.5151889324188232
您好,先生,
您做得很好。我已调整了 XGBoost 的超参数,如 Gamma、Learning_rate、reg_lambda、max_depth、min_child_weight、subsample 等。现在我使用从调整中获得的值来查看准确性是否会改变,但它与未调整的准确性保持一致。先生,我该如何提高准确性?此致。
这可能与算法的随机性有关。考虑使用重复的 k 折交叉验证。
有关机器学习算法随机性的更多信息请见此处
https://machinelearning.org.cn/randomness-in-machine-learning/
谢谢 Jason 的帖子。
所以,在训练时代码是并行运行的。我正试图弄清楚运行时是否也发生并行性?
如果我有 50 棵树,每棵树的输出是并行完成还是顺序完成?
它不像那样干净,因为树之间存在依赖关系。
我相信树本身的构建是并行化的。
嗨,Jason,
非常感谢这篇帖子。我仍然对最后一个场景感到困惑。如果您使用 nthreads=-1 和 njobs=-1,这意味着 XGBoost 拟合使用所有核心,并且 CV 也并行使用所有核心吗?假设我有 32 个核心,那么 32 个核心用于 XGBoost,然后为 CV 启动 32 个 XGBoost 作业?我不知道这两个参数是如何争夺计算时间的。您对此有什么更深入的了解吗?我想如果总共有 32 个核心,那么 n_threads x n_jobs 必须等于 32?
谢谢!
也许你可以用1个线程运行CV,用剩下的31个线程运行xgboost?
也许尝试 16/16 分割?实验一下,看看哪个效果最好。
嗨 Jason,我不知道发生了什么,但我得到了这个结果:
单线程 XGBoost,并行线程 CV:15.321717
并行线程 XGBoost,单线程 CV:12.168671
并行线程 XGBoost 和 CV:16.646298
我正在使用 Python 3.6
谢谢
您的 xgboost 安装可能没有设置为使用多个线程。
Michael 的结果是预期的减速。如果您运行 N (n_threads=-1) 个多线程 XGB 实例,每个实例使用 N 个线程,那么您将拥有 N^2 个线程,对应 N 个执行单元。如果 N 个执行单元表示超线程,则每个核心有 2N 个线程。如果 N 个执行单元表示核心,则每个核心有 N 个线程。无论哪种方式,都会出现超额订阅。XGB 倾向于受 CPU 限制。如果这篇文章能更新以显示类似 K 个线程用于 CV,而 N/K 个线程用于 XGB 的内容,那可能会很有趣。
关于 XGB 性能的进一步考虑,请参阅此处的“xgboost 精确速度”图表。超出物理核心数 (36),性能会变差。 https://github.com/dmlc/xgboost/issues/3810
谢谢。
XGBClassifier 弃用了
nthread,现在是n_jobs,默认值为1。来源:https://docs.xgboost.com.cn/en/latest/python/python_api.html
为了检查
XGBoost是否正常工作,我还建议简单地使用htop检查 CPU 使用率百分比,您应该会看到所有 CPU 都接近 100%。谢谢您的留言。
我正在使用 XGBoost 算法学习一个集成模型
当我打印 base_learners 时,它似乎存储为字典类型。像这样:
{‘dnn’: , ‘random forest’: RandomForestClassifier(bootstrap=True, class_weight=None, criterion=’gini’,
max_depth=4, max_features=’sqrt’, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=2, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=-1,
oob_score=False, random_state=42, verbose=0, warm_start=False), ‘extra trees’: ExtraTreesClassifier(bootstrap=False, class_weight=None, criterion=’gini’,
max_depth=4, max_features=’auto’, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=2, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=-1,
oob_score=False, random_state=42, verbose=0, warm_start=False)}
要将“base_learner”用于另一个文件,我该如何保存它?我不能使用 save_model()。因为那不是模型
而且,我不能使用 pickle 模块。我不知道为什么。
但我认为存在多线程错误问题。
当我使用 pickle 模块时,我收到了以下错误消息:
pickle.dump(base_learners, open(‘./models/base_learners.pkl’, ‘wb’))
TypeError: can’t pickle _thread.RLock objects
您知道解决方案吗?
我没有在 xgboost 中更改基础学习器的示例。
抱歉,我没有见过这个错误,也许可以尝试在 Stack Overflow 上提问?
嗨,Jason,
我在 scikit 封装的 XGBClassifier 的多线程处理上遇到了问题。我在一台 4 核机器上为 XGBClassifier 使用 n_jobs=4,CPU 使用率只显示约 100%。然而,我期望使用率达到约 400%,就像单独使用 XGBoost 时那样。您能给我一些线索解释为什么会这样吗?
我不知道,抱歉。
抱歉提出这个问题。我没有安装带有多线程的 xgboost
机器学习是计算密集型还是数据密集型?我们应该将并行编程(如 cuda)或大数据框架(如 hadoop)用于机器学习吗?
是的,也不是。这取决于项目。