在开始一个新的机器学习问题时,花时间了解您的数据非常重要。
您可以查看关键信息以快速了解您的数据集,例如描述性统计数据和数据可视化。
在这篇文章中,您将了解如何在Weka机器学习工作台中通过查看描述性统计数据和数据可视化来了解更多关于您的数据。
阅读本文后,您将了解:
- 通过查看统计摘要了解属性分布。
- 通过查看单变量图了解属性分布。
- 通过查看多变量图了解属性之间的关系。
通过我的新书《Weka机器学习精通》启动您的项目,其中包括所有示例的分步教程和清晰的截图。
让我们开始吧
通过描述性统计数据更好地理解您的数据
Weka浏览器将自动计算数值属性的描述性统计数据。
- 打开Weka GUI选择器。
- 点击“浏览器”打开Weka浏览器。
- 从data/diabetes.arff加载Pima Indians数据集。
Pima Indians数据集包含数值输入变量,我们可以用它来演示描述性统计数据的计算。
首先,请注意“当前关系”部分中的数据集摘要。此面板总结了有关加载数据集的以下详细信息:
- 数据集名称(关系)。
- 行数(实例数)。
- 列数(属性数)。

Weka数据集摘要
点击“属性”面板中数据集的第一个属性。
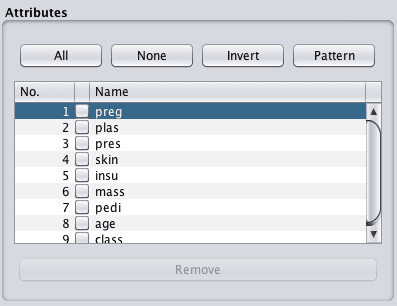
Weka属性列表
请注意“选定属性”面板中的详细信息。它列出了有关选定属性的许多信息,例如:
- 属性名称。
- 缺失值的数量以及整个数据集中缺失值的比率。
- 不同值的数量。
- 数据类型。
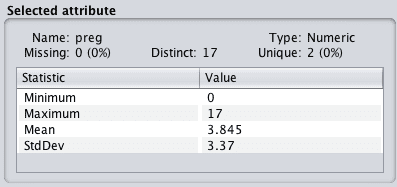
Weka属性摘要
下表列出了一些描述性统计数据及其值。为数值属性提供了有用的四项摘要,包括:
- 最小值。
- 最大值。
- 平均值。
- 标准差。
您可以从这些信息中获得很多启发。例如:
- 缺失数据的存在和比率可以为您提供是否需要删除或填充值的指示。
- 均值和标准差可以量化地反映每个属性的数据分布情况。
- 不同值的数量可以为您提供属性分布的粒度概念。
点击类别属性。此属性为名义类型。查看“选定属性面板”。
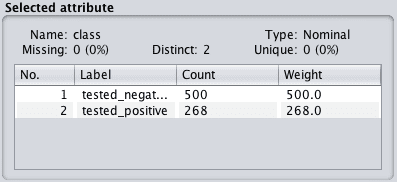
Weka类别属性摘要
现在我们可以看到,对于名义属性,我们得到一个包含每个类别以及属于每个类别的实例数量的列表。还提到了权重,目前我们可以忽略它。如果我们要为数据集中的特定属性值或实例分配更多或更少的权重,则会使用此功能。
在Weka机器学习方面需要更多帮助吗?
参加我为期14天的免费电子邮件课程,逐步探索如何使用该平台。
点击注册,同时获得该课程的免费PDF电子书版本。
单变量属性分布
每个属性的分布都可以绘制成图,以提供对分布的视觉定性理解。
当您在“预处理”选项卡中选择一个属性时,Weka会自动提供这些图。
我们可以接着上一节继续,我们已经加载了Pima Indians数据集。
点击“属性面板”中的“preg”属性,注意“选定属性”面板下方的图表。您将在x轴上看到从0到17的preg值分布。y轴显示每个preg值的计数或频率。
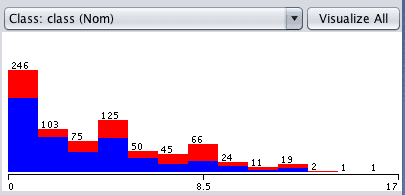
Weka单变量属性分布
请注意,红色和蓝色分别代表正类和负类。颜色会自动分配给每个分类值。如果类值有三个类别,我们将看到由三种颜色而不是两种颜色分解的preg分布。
这对于快速了解给定属性的问题是否容易分离很有用,例如,所有红色和蓝色对于单个属性都清晰分离。点击“属性”列表中的每个属性并查看图表,我们可以看到类之间没有如此容易的分离。
通过点击单变量图上方的“全部可视化”按钮,我们可以快速概览数据集中所有属性的分布以及按类别划分的分布。
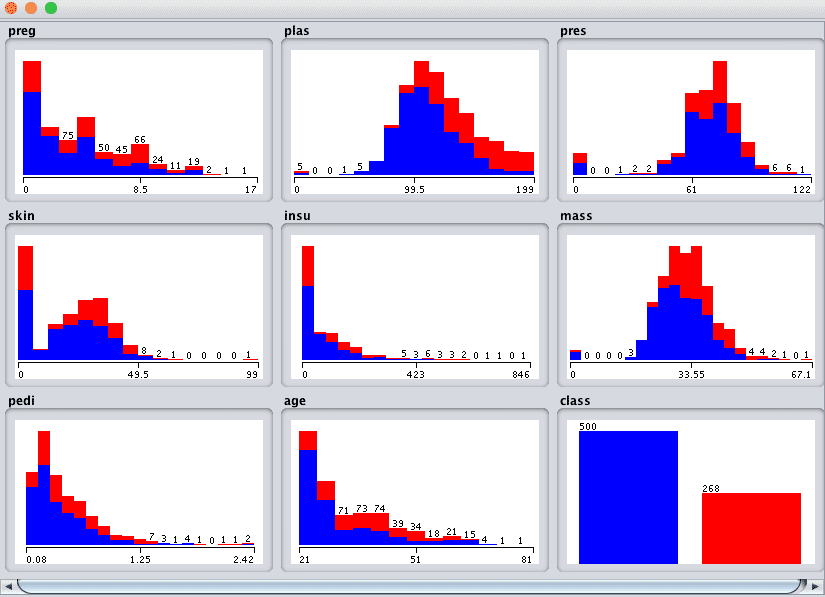
Weka所有单变量属性分布
查看这些图表,我们可以发现关于此数据集的一些有趣之处。
- plas、pres和mass属性看起来呈近似高斯分布。
- pres、skin、insu和mass的值在0处看起来格格不入。
查看此类图表并记录下浮现的想法,可以为您提供进一步数据准备操作(例如将0值标记为损坏)的思路,甚至可能是有用的技术(例如假设输入变量呈高斯分布的线性判别分析和逻辑回归)。
可视化属性交互
到目前为止,我们只关注了单个特征的属性,接下来我们将查看属性组合中的模式。
当属性为数值型时,我们可以绘制一个属性与另一个属性的散点图。这很有用,因为它可以突出属性之间关系中的任何模式,例如正或负相关性。
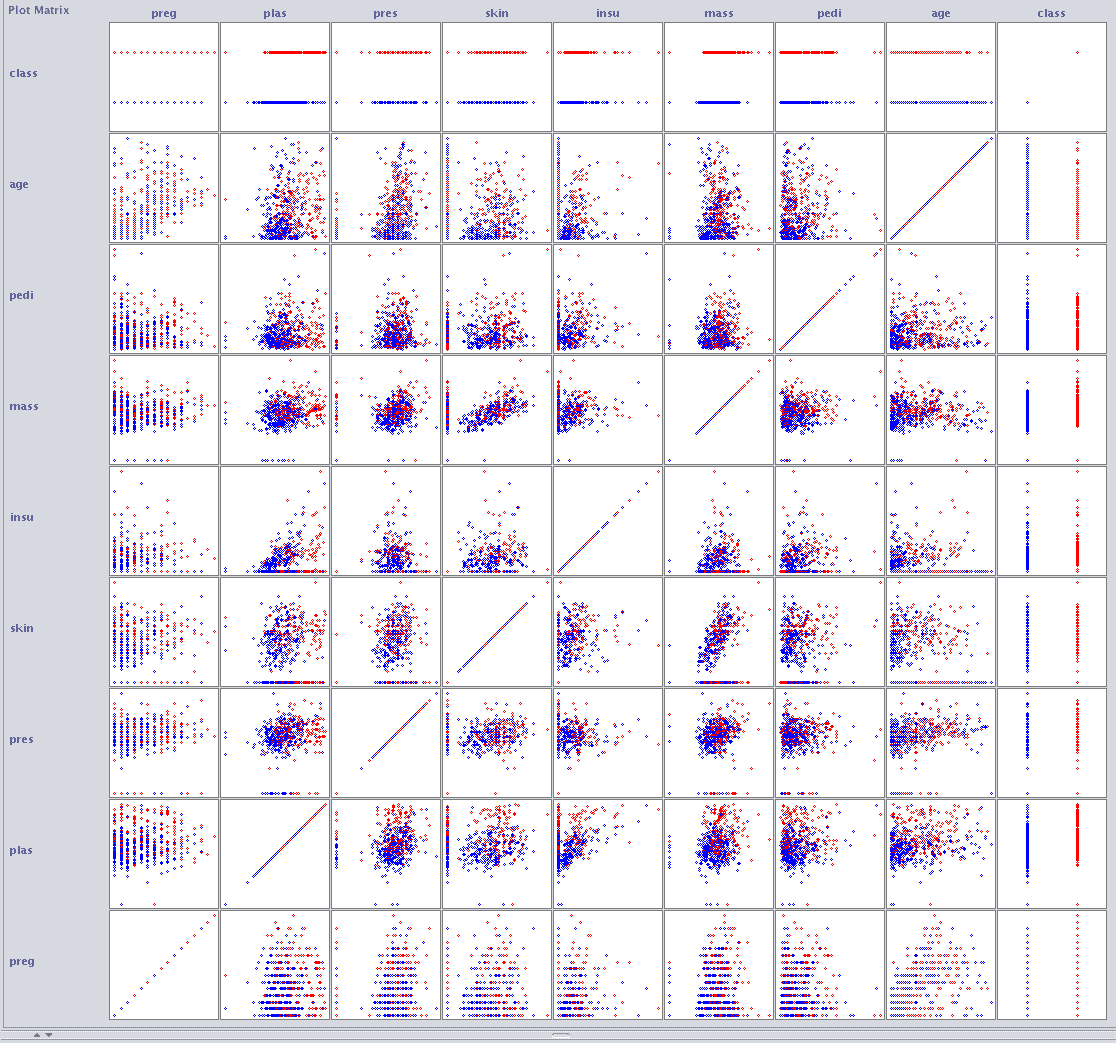
我们可以为所有成对的输入属性创建散点图。这称为散点图矩阵,在对数据进行建模之前对其进行审查可以为进一步的数据预处理技术提供更多线索。
Weka在“可视化”选项卡中默认提供散点图矩阵以供审查。
Weka可视化选项卡
接着上一节继续,在加载了Pima Indians数据集的情况下,点击“可视化”选项卡,并调整窗口大小以便查看所有单个散点图。
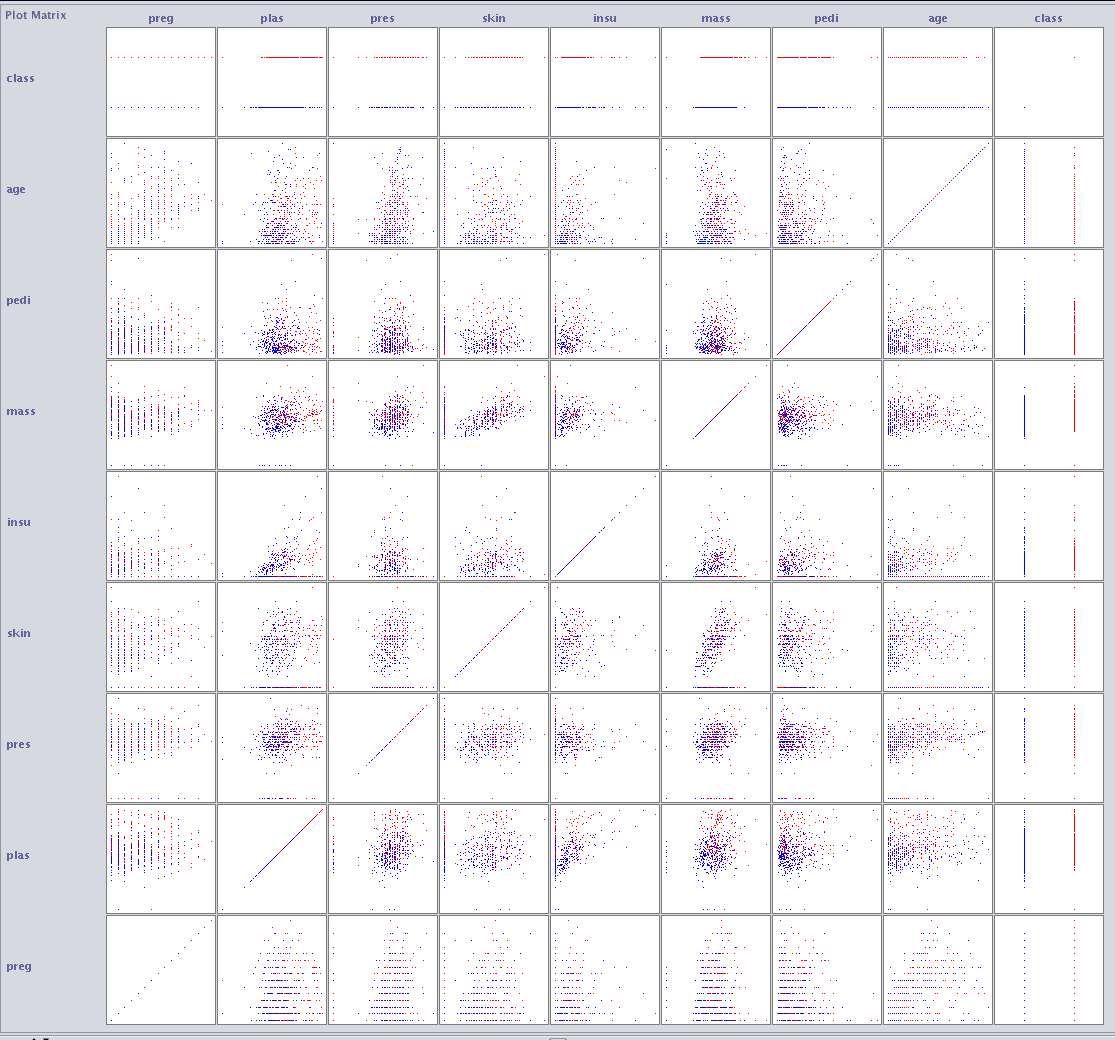
Weka散点图矩阵
您可以看到所有属性组合都以系统的方式绘制。您还可以看到每个图出现两次,首先在左上角的三角形中,然后再次在右下角的三角形中,轴翻转。您还可以看到一系列图,从左下角开始并一直延伸到右上角,其中每个属性都与自身绘制。这些可以忽略。
最后,请注意散点图中的点按其类值着色。寻找点中的趋势或模式,例如颜色的清晰分离,是很有益的。
点击一个图表将打开一个新窗口,您可以在其中进一步操作该图表。
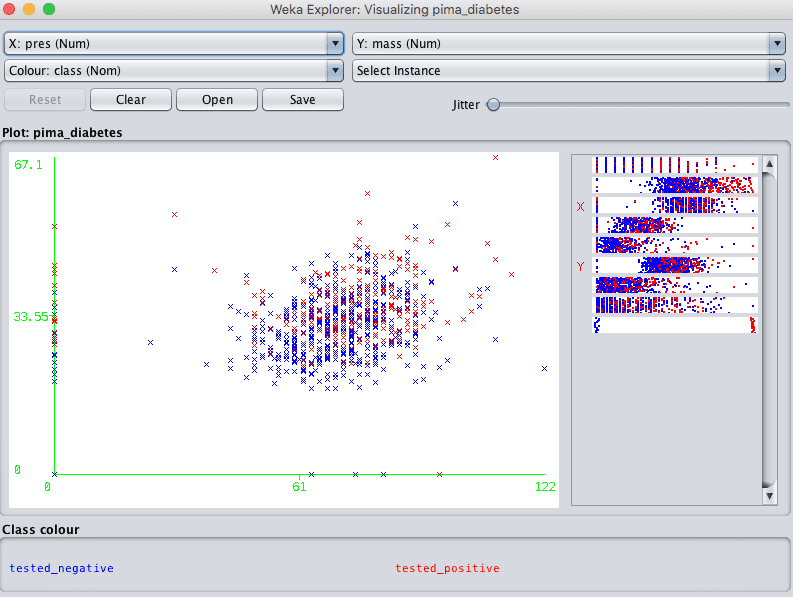
Weka单个散点图
请注意屏幕底部的控件。它们允许您增加图表大小、增加点的大小以及添加抖动。
关于抖动的最后一点很有用,当有很多点相互重叠并且很难看清发生的情况时。抖动会为图表中的数据添加一些随机噪声,稍微分散点,帮助您看清情况。
当您更改这些控件时,点击“更新”按钮以应用更改。
Weka散点图矩阵控件
例如,下面是相同的图,但点尺寸更大,使得更容易看到数据中的任何趋势。
Weka改进的散点图矩阵
总结
在这篇文章中,您发现了如何通过查看描述性统计数据和数据可视化来更好地了解您的机器学习数据。
具体来说,你学到了:
- Weka会自动计算每个属性的描述性统计数据。
- Weka允许您轻松查看每个属性的分布。
- Weka提供散点图可视化来查看属性之间的成对关系。
您对Weka中的描述性统计数据和数据可视化或本文有任何疑问吗?请在下面的评论中提出您的问题,我将尽力回答。
探索无需代码的机器学习!

在几分钟内开发您自己的模型
...只需几次点击
在我的新电子书中探索如何实现
使用 Weka 精通机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、构建模型、调优等等...
最终将机器学习应用到你自己的项目中
跳过学术理论。只看结果。


")



太棒了,我喜欢。
谢谢Mirriam。
我是Weka的初学者,我真的看不懂图表上的任何东西。我看到点无处不在,但我不知道它们好在哪里,坏在哪里?以及通过理解这些图表中的信息,我能达到什么样的预处理?请问有什么帮助吗?非常感谢这个博客。简直太棒了!!!
我也是 :")
你好
类变量可以是数值吗?在这种情况下,如何建立属性和类之间的关系?
当我尝试这样做时,我无法在Weka中建立具有数值的类和具有名义值的属性之间的关系,而我可以为所有其他2种组合做到这一点。
你能解决这个问题吗?
提前感谢
Weka中的类值必须是标签。
我们如何获得名义数据的标准差?
抱歉,Bill,没有这样的概念。
您可以查看每个标签的频率。
非常感谢您的分析,但是我很想了解更多关于图表上集中点的解释。希望能收到您的回复。
你具体指的是什么?
感谢您的关注,我的意思是,我发现很难解释从分类输出中获得的曲线。例如,阈值曲线(x轴上的假阳性率和y轴上的真阳性率)。
边际曲线,真假值的成本/收益分析。真假值的成本曲线。
非常感谢,希望能收到您的回复。
明白了,也许可以看看这本书
《数据挖掘:实用机器学习工具与技术》(Data Mining: Practical Machine Learning Tools and Techniques)
http://amzn.to/2hLzJHJ
你好,Jason!
我有一个网店,希望了解人们是如何分组到不同的群集中的,这些群组的特征是什么,以及这些群组之间有何不同。我如何使用Weka做到这一点?
抱歉,我没有关于聚类的资料。
Weka中x轴是如何绘制的。使用了什么逻辑?
抱歉,我不明白您的问题,也许您可以重新措辞?
我怎么知道属性之间的关系是正向的还是负向的?
您可以计算每对变量之间的相关性。
万分感谢
我想问一下是否能在Weka中找到Q1和Q3值?如何操作?
Q1和Q3是什么意思?
您是指第25和第75百分位数吗?如果是,我不确定,抱歉,也许可以尝试在weka用户组上发帖。
https://machinelearning.org.cn/help-with-weka/
你好,先生
我想将我提出的方法与其他4到5种最先进的算法进行比较。我有一个这些方法的分类准确度表格。我想应用t检验来找出我提出的方法的相应胜/平/负。我该怎么做?
如果您已经有了数字表格,也许可以直接在Excel中输入并使用Excel中的测试?
否则,您可以在Weka的Experimenter界面中设计实验,并让它为您执行测试。
先生,我有一个这样的表格:
数据集 方法1 方法2 方法3 方法4
D1 43 45 48 55
D2 35 48 54 83
D3 86 64 73 82
D4 91 87 76 89
D5 67 71 69 70
我想将方法1与其余3种方法(方法2、方法3和方法4)进行比较,并找出对于每个数据集,方法1获胜/平局/失败的次数(v/*/ ),像这样:
数据集 方法1 方法2 方法3 方法4
D1 43 45* 48* 55v (0/2/1)
D2 35 48v 54v 83v (0/0/3)
D3 86 64 73 82* (2/1/0)
D4 91 87 76v 89* (1/1/1)
D5 67 71 69* 70* (0/2/1)
我该如何进行这种t检验并分配(v/*/ )符号?
这个教程会有帮助
https://machinelearning.org.cn/multi-class-classification-tutorial-weka/
你好,先生
在一次练习中,说我们应该这样做——>
从训练数据中删除样本间折叠差异小于2的数据
这意味着我必须在过滤器中使用remove folds,并将折叠数设置为2,然后应用它吗?
也许可以问问练习的作者他们是什么意思?
嗨,Jason,
正如你所说,Weka有助于查看每个属性的分布。我期待分析分类变量的类别分布,例如其类别、出现次数和频率(%)。
有什么方法可以获得分类变量的类别分布吗?
谢谢你。
是的,当您查看变量时,它写在图表下方。