在数据分析中,SQL 是一种强大的工具,以其在管理和查询数据库方面的强大功能而闻名。Python 中的 Pandas 库将类似 SQL 的功能带给了数据科学家,无需传统的 SQL 数据库即可进行复杂的数据操作和分析。在接下来的内容中,您将应用类似 SQL 的 Python 函数来剖析和理解数据。

超越SQL:用Pandas将房地产数据转化为可操作的见解
照片由 Lukas W. 某些权利保留。
让我们开始吧。
概述
这篇博文分为三部分;它们是:
- 使用 Pandas 的
DataFrame.query()方法探索数据 - 聚合和分组数据
- 掌握 Pandas 中的行和列选择
- 利用透视表进行深入的住房市场分析
使用 Pandas 的 DataFrame.query() 方法探索数据
Pandas 的 DataFrame.query() 方法允许根据指定条件选择行,类似于 SQL 的 SELECT 语句。从基础开始,您将根据单个和多个条件过滤数据,从而为更复杂的数据查询奠定基础。
|
1 2 3 4 5 6 7 8 9 10 |
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt # 加载数据集 Ames = pd.read_csv('Ames.csv') # 简单查询:选择价格高于 600,000 美元的房屋 high_value_houses = Ames.query('SalePrice > 600000') print(high_value_houses) |
在上面的代码中,您使用 Pandas 的 DataFrame.query() 方法过滤出价格高于 600,000 美元的房屋,并将结果存储在一个名为 high_value_houses 的新 DataFrame 中。此方法允许根据作为字符串指定的条件进行简洁且可读的查询。在这种情况下,即 'SalePrice > 600000'。
下面的结果 DataFrame 展示了选定的高价值房产。此查询有效地将数据集缩小到销售价格超过 600,000 美元的房屋,仅显示符合此条件的 5 处房产。此过滤视图为 Ames 数据集中的高端住房市场提供了专注的视角,从而洞察了最高价值房产的特征和位置。
|
1 2 3 4 5 6 7 8 |
PID GrLivArea ... Latitude Longitude 65 528164060 2470 ... 42.058475 -93.656810 584 528150070 2364 ... 42.060462 -93.655516 1007 528351010 4316 ... 42.051982 -93.657450 1325 528320060 3627 ... 42.053228 -93.657649 1639 528110020 2674 ... 42.063049 -93.655918 [5 行 x 85 列] |
在下面的下一个示例中,让我们进一步探索 DataFrame.query() 方法的功能,以根据更具体的标准过滤 Ames Housing 数据集。此查询选择卧室超过 3 间(BedroomAbvGr > 3)且价格低于 300,000 美元(SalePrice < 300000)的房屋。通过逻辑 AND 运算符(&)实现这些条件的组合,允许您一次将多个过滤器应用于数据集。
|
1 2 3 |
# 高级查询:选择卧室超过 3 间且价格低于 300,000 美元的房屋 specific_houses = Ames.query('BedroomAbvGr > 3 & SalePrice < 300000') print(specific_houses) |
此查询的结果存储在一个名为 specific_houses 的新 DataFrame 中,该 DataFrame 包含满足两个条件的全部房产。通过打印 specific_houses,您可以检查那些卧室数量多且价格实惠的房屋的详细信息,从而瞄准住房市场的特定细分市场,这可能会吸引那些在特定预算范围内寻求宽敞居住空间的家庭。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
PID GrLivArea ... Latitude Longitude 5 908128060 1922 ... 42.018988 -93.671572 23 902326030 2640 ... 42.029358 -93.612289 33 903400180 1848 ... 42.029544 -93.627377 38 527327050 2030 ... 42.054506 -93.631560 40 528326110 2172 ... 42.055785 -93.651102 ... ... ... ... ... ... 2539 905101310 1768 ... 42.033393 -93.671295 2557 905107250 1440 ... 42.031349 -93.673578 2562 535101110 1584 ... 42.048256 -93.619860 2575 905402060 1733 ... 42.027669 -93.666138 2576 909275030 2002 ... NaN NaN [352 行 x 85 列] |
此高级查询成功从 Ames Housing 数据集中识别出总共 352 处符合指定条件的房屋:拥有 3 间以上卧室且销售价格低于 300,000 美元。此房产子集突显了市场上的重要部分,这些部分提供了宽敞的居住选择,而不会超出预算,迎合了那些正在寻找价格实惠且宽敞的住房的家庭或个人。为了进一步探索此子集的动态,让我们将销售价格与地面居住面积之间的关系可视化,并增加一层显示卧室数量。这种图形表示将帮助您理解居住空间和卧室数量如何影响这些房屋在指定条件下的可负担性和吸引力。
|
1 2 3 4 5 6 7 8 |
# 可视化高级查询结果 plt.figure(figsize=(10, 6)) sns.scatterplot(x='GrLivArea', y='SalePrice', hue='BedroomAbvGr', data=specific_houses, palette='viridis') plt.title('Sales Price vs. Ground Living Area') plt.xlabel('Ground Living Area (sqft)') plt.ylabel('Sales Price ($)') plt.legend(title='Bedrooms Above Ground') plt.show() |
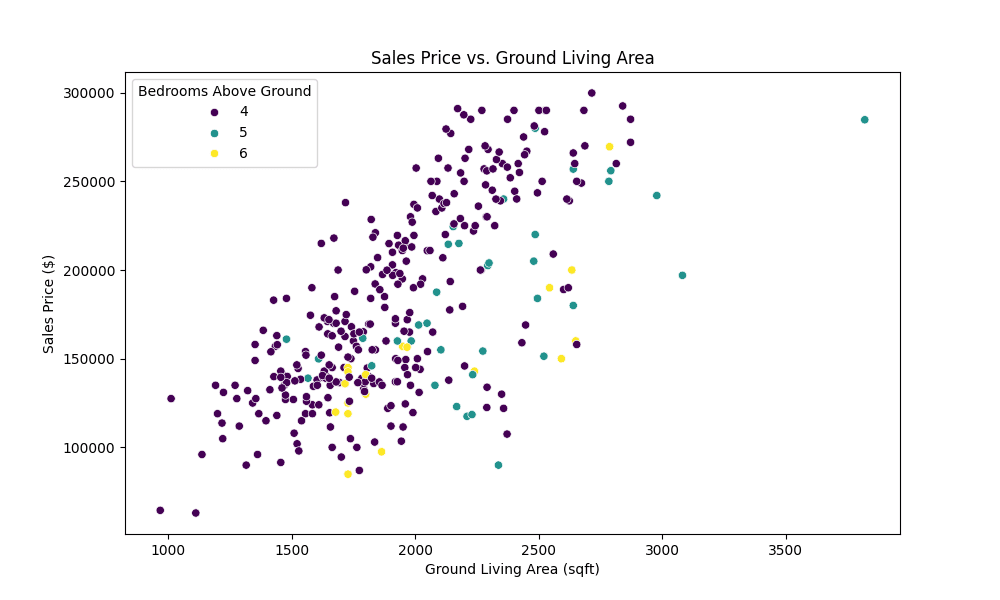
显示销售价格与卧室数量和居住面积相关性的散点图
上面的散点图生动地展示了销售价格、居住面积和卧室数量之间微妙的相互作用,强调了 Ames 住房市场这一细分市场中提供的多样化选择。它强调了更大的居住空间和额外的卧室如何增加房产的价值,为潜在买家和投资者关注宽敞但实惠的房屋提供了宝贵的见解。这种视觉分析不仅使数据更易于访问,而且还为 Pandas 在揭示关键市场趋势方面的实际效用提供了支持。
通过我的书 The Beginner’s Guide to Data Science 启动您的项目。它提供带有可运行代码的自学教程。
聚合和分组数据
聚合和分组对于汇总数据见解至关重要。在第一部分对基础查询技术进行了探索的基础上,让我们更深入地研究 Python 中数据聚合和分组的强大功能。类似于 SQL 的 GROUP BY 子句,Pandas 提供了一个强大的 groupby() 方法,允许您将数据分段以进行详细分析。您旅程的下一阶段将重点关注利用这些功能来揭示 Ames Housing 数据集中隐藏的模式和见解。具体来说,您将检查卧室超过三间、价格低于 300,000 美元且位于不同社区的房屋的平均销售价格。通过聚合这些数据,您旨在突出 Ames, Iowa 空间画布中住房可负担性和库存的可变性。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 高级查询:选择卧室超过 3 间且价格低于 300,000 美元的房屋 specific_houses = Ames.query('BedroomAbvGr > 3 & SalePrice < 300000') # 按社区分组,然后计算平均和总销售价格,并统计房屋数量 grouped_data = specific_houses.groupby('Neighborhood').agg({ 'SalePrice': ['mean', 'count'] }) # 重命名列以提高清晰度 grouped_data.columns = ['Average Sales Price', 'House Count'] # 将平均销售价格四舍五入到小数点后两位 grouped_data['Averages Sales Price'] = grouped_data['Average Sales Price'].round(2) print(grouped_data) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
Average Sales Price House Count Neighborhood BrDale 113700.00 1 BrkSide 154840.00 10 ClearCr 206756.31 13 CollgCr 233504.17 12 Crawfor 199946.68 19 Edwards 142372.41 29 Gilbert 222554.74 19 IDOTRR 146953.85 13 MeadowV 135966.67 3 Mitchel 152030.77 13 NAmes 158835.59 59 NPkVill 143000.00 1 NWAmes 203846.28 39 NoRidge 272222.22 18 NridgHt 275000.00 3 OldTown 142586.72 43 SWISU 147493.33 15 Sawyer 148375.00 16 SawyerW 217952.06 16 Somerst 247333.33 3 StoneBr 270000.00 1 Timber 247652.17 6 |
通过使用 Seaborn 进行可视化,让我们旨在创建对聚合数据直观且易于访问的表示。您继续创建一个条形图,该图展示了每个社区的平均销售价格,并通过房屋数量的注释进行补充,以在单个连贯的图形中说明价格和销量。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# 确保 'Neighborhood' 是一个列(如果它是索引,则重置索引) grouped_data_reset = grouped_data.reset_index().sort_values(by='Average Sales Price') # 设置图表的美学风格 sns.set_theme(style="whitegrid") # 创建条形图 plt.figure(figsize=(12, 8)) barplot = sns.barplot( x='Neighborhood', y='Average Sales Price', data=grouped_data_reset, palette="coolwarm", hue='Neighborhood', legend=False, errorbar=None # 移除置信区间条 ) # 旋转 x 轴标签以提高可读性 plt.xticks(rotation=45) # 用房屋数量注释每个条形图,使用 enumerate 访问位置的索引 for index, value in enumerate(grouped_data_reset['Average Sales Price']): house_count = grouped_data_reset.loc[index, 'House Count'] plt.text(index, value, f'{house_count}', ha='center', va='bottom') plt.title('Average Sales Price by Neighborhood', fontsize=18) plt.xlabel('Neighborhood') plt.ylabel('Average Sales Price ($)') plt.tight_layout() # 调整布局 plt.show() |
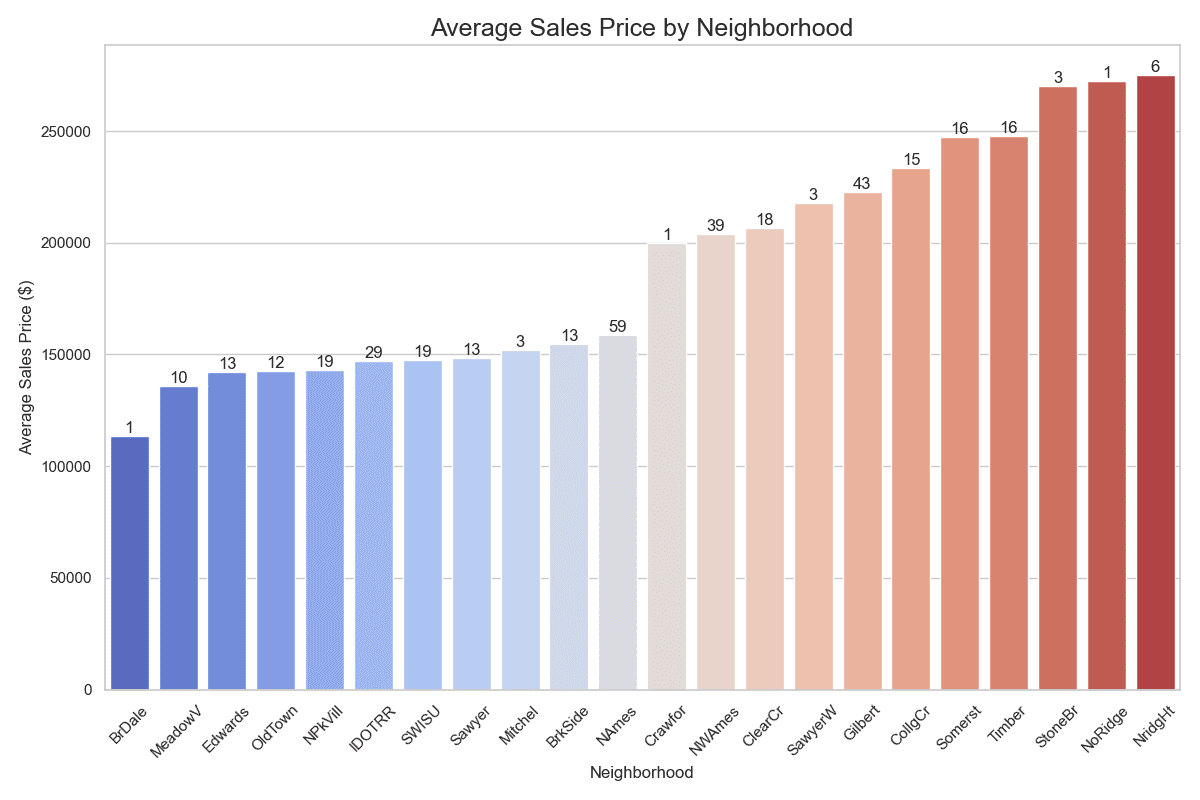
按平均销售价格升序比较社区
分析和随后的可视化突显了 Ames, Iowa 各社区在满足特定标准(卧室超过三间且价格低于 300,000 美元)的房屋的可负担性和可用性方面存在显著差异。这不仅证明了 Python 中类似 SQL 的函数在现实世界数据分析中的实际应用,而且还提供了关于当地房地产市场动态的有价值的见解。
掌握 Pandas 中的行和列选择
从 DataFrame 中选择特定数据子集是常见需求。您手中的两个强大方法是 DataFrame.loc[] 和 DataFrame.iloc[]。它们都服务于类似的目的——选择数据——但它们在引用行和列的方式上有所不同。
理解 DataFrame.loc[] 方法
DataFrame.loc[] 是一种基于标签的数据选择方法,这意味着您使用行和列的标签来选择数据。对于根据列名和行索引选择您感兴趣的特定标签的数据,它非常直观。
语法:DataFrame.loc[row_label, column_label]
目标:让我们选择所有卧室超过 3 间、价格低于 300,000 美元、位于根据您先前的发现平均销售价格较高的特定社区的房屋,并显示它们的“Neighborhood”、“SalePrice”和“GrLivArea”。
|
1 2 3 4 5 6 7 8 9 10 |
# 假设 'high_value_neighborhoods' 是平均销售价格较高的社区列表 high_value_neighborhoods = ['NridgHt', 'NoRidge', 'StoneBr'] # 使用 df.loc[] 根据您的条件以及仅在高价值社区中选择房屋 high_value_houses_specific = Ames.loc[(Ames['BedroomAbvGr'] > 3) & (Ames['SalePrice'] < 300000) & (Ames['Neighborhood'].isin(high_value_neighborhoods)), ['Neighborhood', 'SalePrice', 'GrLivArea']] print(high_value_houses_specific.head()) |
|
1 2 3 4 5 6 |
Neighborhood SalePrice GrLivArea 40 NoRidge 291000 2172 162 NoRidge 285000 2225 460 NridgHt 250000 2088 468 NoRidge 268000 2295 490 NoRidge 260000 2417 |
理解 DataFrame.iloc[] 方法
相比之下,DataFrame.iloc[] 是一种基于整数位置的索引方法。这意味着您使用整数来指定要选择的行和列。访问 DataFrame 中数据的位置特别有用。
语法:DataFrame.iloc[row_position, column_position]
目标:下一个重点是找出 Ames 数据集中不牺牲空间且价格实惠的住房选择,特别是针对拥有至少 3 间地上卧室且价格低于 300,000 美元的房屋,这些房屋位于高价值社区之外。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 过滤出不在 'high_value_neighborhoods' 中的房屋, # 拥有至少 3 间地上卧室,且价格低于 300,000 美元 low_value_spacious_houses = Ames.loc[(~Ames['Neighborhood'].isin(high_value_neighborhoods)) & (Ames['BedroomAbvGr'] >= 3) & (Ames['SalePrice'] < 300000)] # 按 'SalePrice' 对这些房屋进行排序,以明确突出较低的端 low_value_spacious_houses_sorted = low_value_spacious_houses.sort_values(by='SalePrice').reset_index(drop=True) # 使用 df.iloc 选择并打印此类低价值房屋的前 5 个观测值 low_value_spacious_first_5 = low_value_spacious_houses_sorted.iloc[:5, :] # 仅打印相关列以匹配较早的高价值示例:'Neighborhood'、'SalePrice'、'GrLivArea' print(low_value_spacious_first_5[['Neighborhood', 'SalePrice', 'GrLivArea']]) |
|
1 2 3 4 5 6 |
Neighborhood SalePrice GrLivArea 0 IDOTRR 40000 1317 1 IDOTRR 50000 1484 2 IDOTRR 55000 1092 3 Sawyer 62383 864 4 Edwards 63000 1112 |
在对 DataFrame.loc[] 和 DataFrame.iloc[] 的探索中,您已经揭示了 Pandas 进行行和列选择的能力,证明了这些方法在数据分析中的灵活性和强大功能。通过 Ames Housing 数据集的实际示例,您已经看到了 DataFrame.loc[] 如何实现直观的、基于标签的选择,非常适合根据已知标签定位特定数据。相反,DataFrame.iloc[] 提供了一种通过整数位置访问数据的精确方法,为位置选择提供了必不可少的工具,尤其是在需要关注数据片段或样本的情况下。无论是过滤选定社区的高价值房产,还是识别更广泛市场中的入门级房屋,掌握这些选择技术都能丰富您数据科学工具包,从而实现更具针对性和更深入的数据探索。
想开始学习数据科学新手指南吗?
立即参加我的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
利用透视表进行深入的住房市场分析
在您更深入地研究 Ames Housing 数据集的深度时,您的分析之旅将为您介绍 Pandas 中透视表的强大功能。透视表是汇总、分析和呈现复杂数据并使其易于理解的宝贵工具。此技术允许您交叉制表和分段数据,以发现可能隐藏的模式和见解。在本节中,您将利用透视表更精细地剖析住房市场,重点关注社区特征、卧室数量和销售价格之间的相互作用。
为了为您构建透视表分析奠定基础,您将数据集过滤为价格低于 300,000 美元且地上至少有一间卧室的房屋。此标准侧重于更实惠的住房选择,确保您的分析与更广泛的受众相关。然后,您将继续构建一个透视表,按社区和卧室数量细分平均销售价格,旨在揭示决定 Ames 住房可负担性和偏好的模式。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 导入一个额外的库 import numpy as np # 过滤出价格低于 300,000 美元且地上卧室至少为 1 的房屋 affordable_houses = Ames.query('SalePrice < 300000 & BedroomAbvGr > 0') # 创建一个数据透视表,按社区和卧室数量分析平均销售价格 pivot_table = affordable_houses.pivot_table(values='SalePrice', index='Neighborhood', columns='BedroomAbvGr', aggfunc='mean').round(2) # 填充缺失值,用0表示,以提高可读性并表明该细分市场没有数据 pivot_table = pivot_table.fillna(0) # 调整pandas显示选项,以确保显示所有列 pd.set_option('display.max_columns', None) print(pivot_table) |
在讨论一些见解之前,让我们快速浏览一下数据透视表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
BedroomAbvGr 1 2 3 4 5 6 Neighborhood Blmngtn 178450.00 197931.19 0.00 0.00 0.00 0.00 Blueste 192500.00 128557.14 151000.00 0.00 0.00 0.00 BrDale 0.00 99700.00 111946.43 113700.00 0.00 0.00 BrkSide 77583.33 108007.89 140058.67 148211.11 214500.00 0.00 ClearCr 212250.00 220237.50 190136.36 209883.20 196333.33 0.00 CollgCr 154890.00 181650.00 196650.98 233504.17 0.00 0.00 Crawfor 289000.00 166345.00 193433.75 198763.94 210000.00 0.00 Edwards 59500.00 117286.27 134660.65 137332.00 191866.67 119900.00 Gilbert 0.00 172000.00 182178.30 223585.56 204000.00 0.00 Greens 193531.25 0.00 0.00 0.00 0.00 0.00 GrnHill 0.00 230000.00 0.00 0.00 0.00 0.00 IDOTRR 67378.00 93503.57 111681.13 144081.82 162750.00 0.00 Landmrk 0.00 0.00 137000.00 0.00 0.00 0.00 MeadowV 82128.57 105500.00 94382.00 128250.00 151400.00 0.00 Mitchel 176750.00 150366.67 168759.09 149581.82 165500.00 0.00 NAmes 139500.00 133098.93 146260.96 159065.22 180360.00 144062.50 NPkVill 0.00 134555.00 146163.64 143000.00 0.00 0.00 NWAmes 0.00 177765.00 183317.12 201165.00 253450.00 0.00 NoRidge 0.00 262000.00 259436.67 272222.22 0.00 0.00 NridgHt 211700.00 215458.55 264852.71 275000.00 0.00 0.00 OldTown 83333.33 105564.32 136843.57 136350.91 167050.00 97500.00 SWISU 60000.00 121044.44 132257.88 143444.44 158500.00 148633.33 Sawyer 185000.00 124694.23 138583.77 148884.62 0.00 146166.67 SawyerW 216000.00 156147.41 185192.14 211315.00 0.00 237863.25 Somerst 205216.67 191070.18 225570.39 247333.33 0.00 0.00 StoneBr 223966.67 211468.75 233750.00 270000.00 0.00 0.00 Timber 0.00 217263.64 200536.04 241202.60 279900.00 0.00 Veenker 247566.67 245150.00 214090.91 0.00 0.00 0.00 |
上面的数据透视表提供了关于平均销售价格如何随社区和卧室数量的变化而变化的全面快照。此分析揭示了几个关键见解。
- 按社区划分的可负担性:您可以一目了然地看到哪些社区为具有特定卧室数量的房屋提供了最经济实惠的选择,从而有助于有针对性的房屋搜索。
- 卧室数量对价格的影响:该表突显了卧室数量如何影响每个社区内的销售价格,提供了对较大的房屋所支付的溢价的衡量标准。
- 市场空白和机会:值为零的区域表明缺乏符合特定标准的房屋,这标志着开发商和投资者潜在的市场空白或机会。
通过利用数据透视表进行此分析,您已成功地将艾姆斯(Ames)住房市场中的复杂关系提炼成一种既易于访问又信息丰富的格式。此过程不仅展示了 pandas 和类似 SQL 的分析技术之间的强大协同作用,还强调了复杂数据操作工具在揭示房地产市场中可操作见解方面的重要性。尽管数据透视表很有见地,但当与可视化分析相结合时,它们的真正潜力才能得到释放。
为了进一步阐明您的发现并使其更直观,您将从数值分析转向可视化表示。热力图是实现此目的的绝佳工具,尤其是在处理此类多维数据时。但是,为了提高热力图的清晰度并将注意力集中在可操作数据上,您将采用自定义颜色方案,该方案可以清晰地突出社区和卧室数量不存在的组合。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# 导入一个额外的库 import matplotlib.colors # 创建一个自定义颜色映射 cmap = matplotlib.colors.LinearSegmentedColormap.from_list("", ["red", "yellow", "green"]) # 掩码用于“零”值,以便用不同的色调着色 mask = pivot_table == 0 # 设置绘图大小 plt.figure(figsize=(14, 10)) # 使用掩码创建热力图 sns.heatmap(pivot_table, cmap=cmap, annot=True, fmt=".0f", linewidths=.5, mask=mask, cbar_kws={'label': 'Average Sales Price ($)'}) # 添加标题和标签以提高清晰度 plt.title('Average Sales Price by Neighborhood and Number of Bedrooms', fontsize=16) plt.xlabel('Number of Bedrooms Above Grade', fontsize=12) plt.ylabel('Neighborhood', fontsize=12) # 显示热力图 plt.show() |
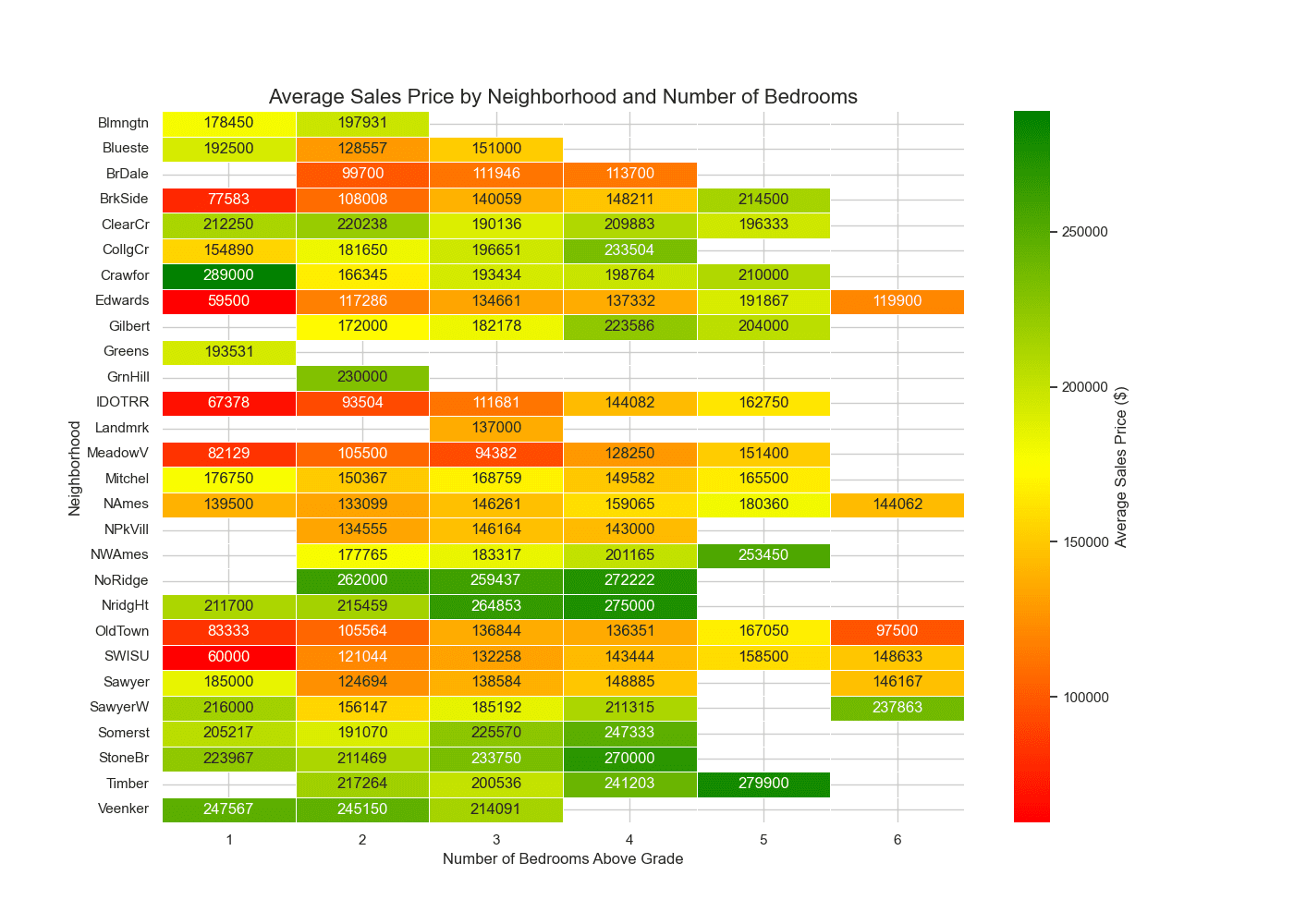
显示按社区划分的平均销售价格的热力图
热力图生动地说明了平均销售价格在不同社区中的分布情况,并按卧室数量进行了细分。这种颜色编码的视觉辅助工具可以立即清楚地表明,艾姆斯(Ames)的哪些区域为不同规模的家庭提供了最经济实惠的住房选择。此外,零值的独特着色——表示不存在的社区和卧室数量组合——是市场分析的关键工具。它突出了市场上可能存在需求但供应不足的空白,为开发商和投资者提供了宝贵的见解。值得注意的是,您的分析还强调,“老城区”(Old Town)社区中拥有 6 间卧室的房屋标价低于 100,000 美元。这一发现表明,对于希望以经济实惠的价格购买卧室数量多的房屋的大家庭或投资者来说,这是一个绝佳的机会。
通过这次视觉探索,您不仅加深了对住房市场动态的理解,还展示了高级数据可视化在房地产分析中不可或缺的作用。数据透视表与热力图的结合,恰恰说明了复杂的数据操作和可视化技术如何能够揭示有关住房行业的有见地的见解。
进一步阅读
如果您想深入了解此主题,本节提供了更多资源。
Python 文档
- Pandas 的
DataFrame.query()方法 - Pandas 的
DataFrame.groupby()方法 - Pandas 的
DataFrame.loc[]方法 - Pandas 的
DataFrame.iloc[]方法 - Pandas 的
DataFrame.pivot_table()方法
资源
总结
这份关于艾姆斯(Ames)住房数据集的全面旅程,强调了 pandas 在进行复杂数据分析方面的多功能性和强大功能,其效果通常可以与 SQL 在非传统数据库环境中的功能相媲美,甚至超越。从识别详细的住房市场趋势到发现独特的投资机会,您展示了一系列技术,为分析师提供了进行深度数据探索的工具。具体来说,您学会了如何
- 利用
DataFrame.query()进行数据选择,类似于 SQL 的SELECT语句。 - 使用
DataFrame.groupby()进行数据聚合和汇总,类似于 SQL 的GROUP BY。 - 应用高级数据操作技术,如
DataFrame.loc[]、DataFrame.iloc[]和DataFrame.pivot_table()进行更深入的分析。
您有任何问题吗?请在下面的评论中提出您的问题,我将尽力回答。







暂无评论。