我们迄今为止的讨论都围绕着线性模型家族展开。从简单的线性回归到Lasso和Ridge等正则化技术,每种方法都为基于线性关系预测连续结果提供了宝贵的见解。在我们开始探索基于树的模型时,重申我们的重点仍然是回归很重要。虽然基于树的模型用途广泛,但它们处理、评估和优化结果的方式在分类和回归任务之间存在显著差异。
基于树的回归模型是机器学习中强大的工具,可以处理非线性关系和复杂的数据结构。在这篇文章中,我们将介绍一系列基于树的模型,突出它们的优点和缺点。然后,我们将深入研究一个使用sklearn和matplotlib实现和可视化决策树的实际例子。最后,我们将使用dtreeviz(一个提供更详细见解的工具)来增强我们的可视化效果。
通过我的书《进阶数据科学》启动您的项目。它提供了带有可运行代码的自学教程。
让我们开始吧。

拓展思路:探索用于回归的树状模型
图片由Michael Held拍摄。保留部分权利。
概述
这篇博文分为三部分;它们是:
- 一系列基于树的回归模型
- 使用
sklearn和matplotlib可视化决策树 - 使用
dtreeviz进行增强可视化
一系列基于树的回归模型
基于树的模型有各种复杂性,每个模型都有独特的功能,适用于不同的场景。为了更好地理解基于树的回归模型的范围,让我们看看下面的可视化图,它总结了一些流行的模型
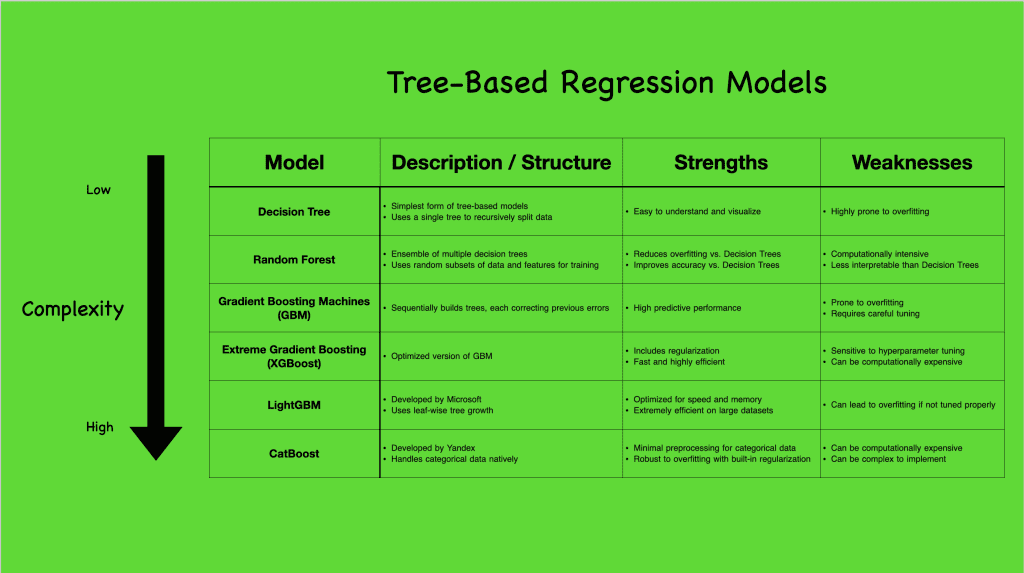
基于树的回归模型。点击放大。
从最简单的形式决策树(CART)开始,我们看到一个构建单个树以捕获数据分割的模型。虽然直观,但它容易过拟合,但为更复杂的模型奠定了基础。通过集成方法,如随机森林和梯度提升机(GBM),甚至更进一步到XGBoost、LightGBM和CatBoost等高级算法,我们观察到处理数据、减少过拟合和提高预测准确性的日益复杂的方法。
线性模型假设特征和结果之间存在直接的线性关系,而基于树的模型则打破了这种模式,轻松捕获非线性交互。这种非线性使得基于树的模型能够发现数据中复杂的模式,使其在变量关系很少纯粹线性的实际应用中特别强大。它们对异常值具有鲁棒性,并且可以灵活处理不同的数据类型,对特征缩放没有严格要求。然而,这种灵活性也伴随着挑战,特别是过拟合和计算需求,尤其当模型变得复杂时。
想开始学习进阶数据科学吗?
立即参加我的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
使用sklearn和matplotlib可视化决策树
在上一节中,我们探索了一系列基于树的回归模型及其不同的复杂性。现在,让我们深入研究最简单但最基本的模型之一:决策树。我们将使用Ames住房数据集来理解决策树在实践中如何工作。下面的代码块演示了如何导入必要的库、提取没有缺失值的数值数据(为简单起见)、训练决策树模型,以及使用Matplotlib和内置的sklearn.tree.plot_tree函数可视化生成的树结构
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# 导入必要的库 import pandas as pd from sklearn import tree import matplotlib.pyplot as plt 来自 sklearn.tree 导入 DecisionTreeRegressor from sklearn.model_selection import train_test_split # 加载所有没有缺失值的数值特征 Ames = pd.read_csv('Ames.csv').select_dtypes(include=['int64', 'float64']) Ames.dropna(axis=1, inplace=True) X = Ames.drop('SalePrice', axis=1) y = Ames['SalePrice'] # 划分数据 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 初始化并拟合决策树 tree_model = DecisionTreeRegressor(max_depth=3) tree_model.fit(X_train, y_train) # 使用sklearn可视化决策树 plt.figure(figsize=(20, 10)) tree.plot_tree(tree_model, feature_names=X.columns, filled=True, impurity=False, rounded=True, precision=2, fontsize=12) plt.show() |
我们特意设置了max_depth=3来限制树的复杂性。这个参数限制了树的最大深度,确保它不会变得太深。通过这样做,我们使树更简单,更容易可视化,这有助于理解模型的基本结构和决策过程,而不会迷失在过多的细节中。
这是我们决策树的最终可视化效果
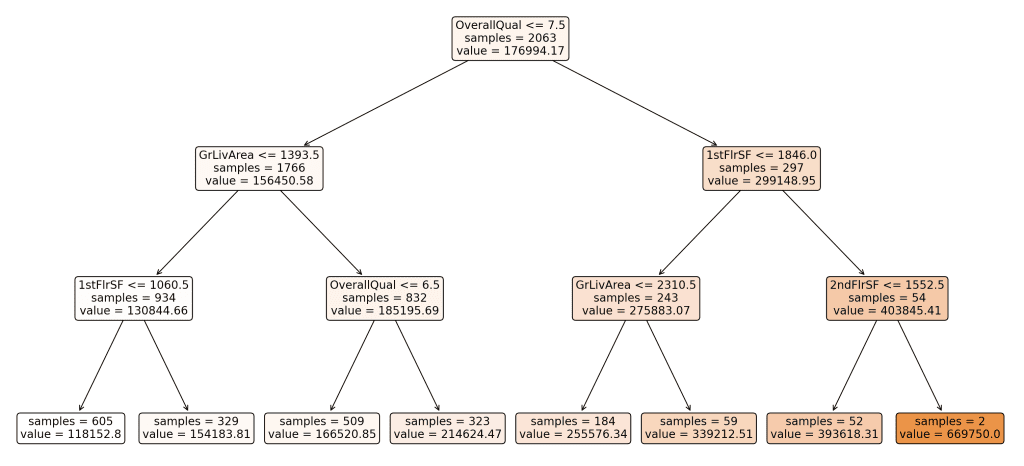
派生决策树。点击放大。
这棵树表示模型如何根据各种特征分割数据,以预测房屋的销售价格。树中的每个节点都表示基于特征值的决策点,叶子表示最终的预测值。
理解分割
- 为什么树会以这种方式分割?
决策树算法在每个节点处分割数据,以最小化目标变量的均方误差(MSE),在本例中是销售价格。MSE衡量误差平方的平均值,即预测值与实际值之间的差值。通过选择减少MSE的分割,树旨在创建在目标变量方面尽可能同质的数据组。 - 选择了哪些特征进行分割?
此树中选择用于分割的特征包括“OverallQual”、“GrLivArea”、“1stFlrSF”和“2ndFlrSF”。这些特征是根据它们在分割数据时减少MSE的能力来选择的。这些分割的级别或阈值(例如,OverallQual <= 7.5)在训练过程中确定,以优化数据点分离为更同质的组。 - 解释分割和箭头
- 树中的每个节点都包含一个特征和一个阈值。例如,根节点根据“OverallQual”是否小于或等于7.5来分割数据。
- 指向左侧的箭头表示符合条件的数据点(例如,OverallQual <= 7.5),而指向右侧的箭头表示不符合条件的数据点(例如,OverallQual > 7.5)。
- 随后的分割进一步划分数据以细化预测,每个分割都旨在减少结果组内的MSE。
- 分支的颜色编码
可视化中的分支从白色到更深的阴影进行颜色编码,以指示每个节点的预测值。较浅的颜色表示较低的预测值,而较深的阴影表示较高的预测值。这种颜色渐变有助于视觉上区分树上的预测并理解销售价格的分布。 - 叶子和最终预测
树的叶子表示目标变量的最终预测值。每个叶子节点显示预测的销售价格(例如,value = 118152.80)和落入该叶子的样本数量(例如,samples = 605)。这些值计算为该组中所有数据点的平均销售价格。
决策树模型直观且易于解释,是理解更复杂基于树的模型的一个很好的起点。然而,如前所述,一个主要缺点是它容易过拟合,特别是对于更深的树。当模型捕获训练数据中的噪声时,就会发生过拟合,导致对未见数据的泛化能力差。
使用dtreeviz进行增强可视化
在上一部分中,我们使用matplotlib和内置的sklearn.tree.plot_tree函数可视化了决策树,以理解模型的决策过程。虽然这提供了一个很好的概述,但还有更复杂的工具可以提供增强的可视化效果。
在本节中,我们将使用dtreeviz,这是一个为决策树提供详细可视化的库。有关可能需要根据您的操作系统安装的依赖项和库的列表,请参阅此GitHub存储库。下面的代码块演示了如何导入必要的库、准备数据、训练决策树模型,以及使用dtreeviz可视化树。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 导入必要的库 import pandas as pd 来自 sklearn.tree 导入 DecisionTreeRegressor from sklearn.model_selection import train_test_split import dtreeviz # 加载所有没有缺失值的数值特征 Ames = pd.read_csv('Ames.csv').select_dtypes(include=['int64', 'float64']) Ames.dropna(axis=1, inplace=True) X = Ames.drop('SalePrice', axis=1) y = Ames['SalePrice'] # 划分数据 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 初始化并拟合决策树 tree_model = DecisionTreeRegressor(max_depth=3) tree_model.fit(X_train.values, y_train) # 使用dtreeviz可视化决策树 viz = dtreeviz.model(tree_model, X_train, y_train, target_name='SalePrice', feature_names=X_train.columns.tolist()) # 在Jupyter Notebook中,您可以直接使用以下命令查看可视化 # viz.view() # 渲染并显示SVG可视化 # 在PyCharm中,您可以渲染并显示SVG图像 v = viz.view() # 将SVG渲染为内部对象 v.show() # 弹出窗口 |
这是使用dtreeviz增强的可视化(再次使用max_depth=3)
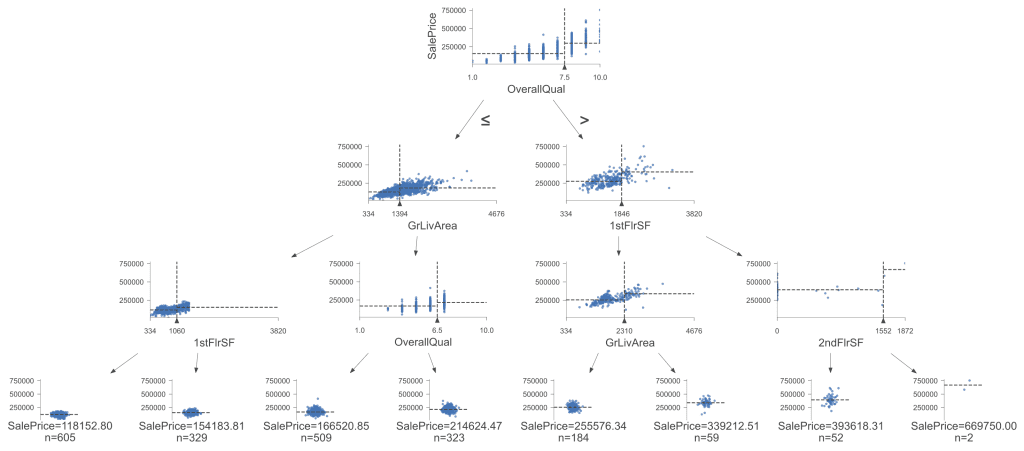
决策树的可视化。点击放大。
此可视化提供了更多信息和决策树的详细视图。每个节点处的散点图有助于我们理解每次分割的特征分布和影响,这对于理解复杂分割和不同特征的重要性特别有用。该树基于与我们第一个可视化相同的规则和决策边界进行分割,从而得出相同的结论。然而,dtreeviz 使在树变得更深时更容易可视化同质或聚类数据,从而更清晰地了解数据点如何根据分割进行分组。
进一步阅读
API
GitHub / PIP
- dtreeviz GitHub
- pip install dtreeviz
教程
资源
总结
在这篇文章中,我们介绍了基于树的回归模型,重点是决策树。我们首先概述了各种基于树的模型,强调了它们的优点和缺点。然后,我们使用sklearn和matplotlib可视化了决策树,以理解其基本结构和决策过程。最后,我们使用dtreeviz增强了可视化,提供了更深入的见解和更具交互性的模型视图。
具体来说,你学到了:
- 各种基于树的回归模型的优点和缺点。
- 如何使用
sklearn和matplotlib训练和可视化决策树。 - 如何使用
dtreeviz进行更详细的决策树可视化。
您有任何问题吗?请在下面的评论中提出您的问题,我将尽力回答。







暂无评论。