生成式机器学习模型的进步使计算机能够进行创造性工作。在绘画领域,有一些著名的模型可以将文本描述转换为像素阵列。目前最强大的模型是扩散模型家族的一部分。在这篇文章中,您将学习这种模型的工作原理以及如何控制其输出。
使用我的书 《使用 Stable Diffusion 掌握数字艺术》 启动您的项目。它提供了带有工作代码的自学教程。
让我们开始吧。

扩散模型用于图像生成简介
图片由 Dhruvin Pandya 拍摄。保留部分权利。
概述
这篇文章分为三个部分;它们是
- 扩散模型的工作流程
- 输出变化
- 它是如何训练的
扩散模型的工作流程
考虑到将图片文本描述转换为像素阵列图片的目标,机器学习模型的输出应该是一个 RGB 值阵列。但是,您应该如何向模型提供文本输入,以及如何执行转换呢?
由于文本输入描述了输出,模型需要理解文本的含义。对描述理解得越好,您的模型就能越准确地生成输出。因此,将文本视为字符串的简单解决方案效果不佳。您需要一个能够理解自然语言的模块,而最先进的解决方案是将输入表示为嵌入向量。
输入文本的嵌入表示不仅允许您提取文本的含义,而且还提供了统一的输入形状,因为不同长度的文本可以转换为标准大小的张量。
有多种方法可以将嵌入表示的张量转换为像素。回想一下生成对抗网络 (GAN) 的工作原理;您应该注意到这具有相似的结构,即输入(文本)转换为潜在结构(嵌入),然后转换为输出(像素)。
扩散模型是一系列神经网络模型,它将嵌入视为从随机像素恢复图片的一个提示。下面是 Rombach 等人论文中的一张图,用于说明此工作流程。
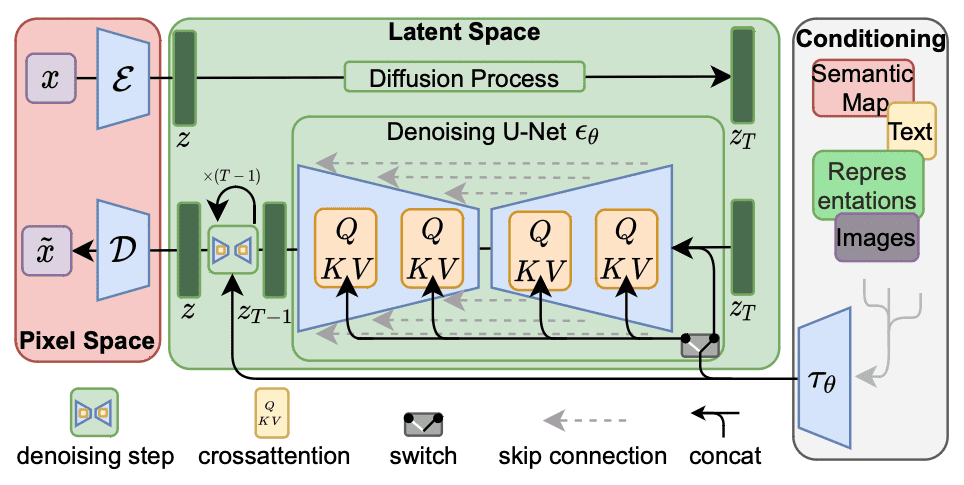
Stable Diffusion 架构。图摘自 Rombach 等人 (2021)
在这张图中,工作流程是从右到左。左侧的输出是使用用 $\mathcal{D}$ 表示的解码器网络将张量转换为像素空间。右侧的输入转换为嵌入 $\tau_\theta$,用作条件张量。关键结构位于中间的潜在空间。生成部分位于绿色框的下半部分,它使用去噪网络 $\epsilon_\theta$ 将 $z_T$ 转换为 $z_{T-1}$。
去噪网络接收输入张量 $z_T$ 和嵌入 $\tau_\theta$,输出张量 $z_{T-1}$。输出是一个比输入“更好”的张量,因为它与嵌入的匹配度更高。在最简单的形式中,解码器 $\mathcal{D}$ 只会复制来自潜在空间的输出。去噪网络的输入和输出张量 $z_T$ 和 $z_{T-1}$ 是 RGB 像素阵列,网络使其噪声更小。
它被称为去噪网络,因为它假设嵌入可以完美地描述输出,但输入和输出不同,因为某些像素被随机值替换。网络模型旨在去除这些随机值并恢复原始像素。这是一项艰巨的任务,但模型假设噪声像素是均匀添加的,并且噪声遵循高斯模型。因此,该模型可以多次重用,每次都会产生输入改进。下面是 Ho 等人论文中对此概念的说明。
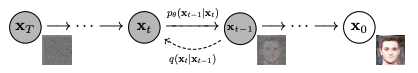
图像去噪。图摘自 Ho 等人 (2020)
由于这种结构,去噪网络假设输入 $z_T$ 和输出 $z_{T-1}$ 形状相同,以便网络可以重复运行直到生成最终输出 $z$。前图中去噪 U-net 块是为了保持输入和输出形状相同。去噪块的概念是执行以下操作:
$$
\begin{aligned}
w_t &= \textrm{NoisePredictor}(z_t, \tau_\theta, t) \\
z_{t-1} &= z_t – w_t
\end{aligned}
$$
也就是说,噪声分量 $w_t$ 是从带噪声图像 $z_t$、条件张量 $\tau_\theta$ 和步数 $t$ 预测的。然后噪声预测器根据 $t$ 来估计 $z_t$ 中的噪声水平,条件是最终图像 $z=z_0$ 应该是什么样子,如张量 $\tau_\theta$ 所描述的。$t$ 的值对预测器很有帮助,因为值越大,$z_t$ 中的噪声越多。
从 $z_t$ 中减去噪声将是去噪图像 $z_{t-1}$,它可以再次送入去噪网络,直到产生 $z=z_0$。该网络处理张量的次数 $T$ 是整个扩散模型的设计参数。由于在此模型中,噪声被表述为高斯噪声,因此解码器 $\mathcal{D}$ 的一部分是将潜在空间张量 $z$ 转换为三通道张量,并将浮点值量化为 RGB。
输出变化
一旦神经网络训练完成,每层的权重就固定了,只要输入是确定性的,输出就是确定性的。然而,在这个扩散模型工作流程中,输入是将被转换为嵌入向量的文本。去噪模型接受一个额外的输入,即潜在空间中的初始 $z_T$ 张量。这通常是随机生成的,例如通过采样高斯分布并填充去噪网络期望的形状的张量。使用不同的起始张量,您会得到不同的输出。这就是您如何通过相同的输入文本生成不同输出的方式。
事实上,现实远比这复杂。请记住,去噪网络分多步运行,每一步都旨在稍微改善输出,直到产生原始的最终输出。网络可以接收一个额外的提示,指示它处于哪一步(例如,总共 10 个计划步骤中的第 5 步)。高斯噪声由其均值和方差参数化,您可以提供一个函数来计算。您对每一步预期的噪声建模越好,去噪网络去除噪声的效果就越好。在 Stable Diffusion 模型中,去噪网络需要一个随机噪声样本,反映该步骤中的噪声强度,以便从带噪声图像中预测噪声分量。下图中的算法 2 展示了这一点,其中这种随机性以 $\sigma_t\mathbf{z}$ 的形式引入。您可以为此目的选择采样器。有些采样器比其他采样器收敛更快(即,您使用的步骤更少)。您还可以将潜在空间模型视为一个变分自编码器,其中引入的变化也会影响输出。
它是如何训练的
以 Stable Diffusion 模型为例,您可以看到工作流程中最重要的组件是潜在空间中的去噪模型。实际上,输入模型并未经过训练,而是采用了现有的文本嵌入模型,例如 BERT 或 T5。输出模型也可以是现成的模型,例如将 256×256 像素图像转换为 512×512 像素图像的超分辨率模型。
去噪网络模型的训练概念上如下:您选择一张图片并向其中添加一些噪声。然后您创建了一个包含三个组件的元组:图片、噪声和带噪声图片。然后训练网络以估计带噪声图片中的噪声部分。噪声部分可以通过向像素添加噪声的不同权重以及用于生成噪声的高斯参数而变化。训练算法如算法 1 所示:

训练和采样算法。图摘自 Ho 等人 (2020)
由于去噪网络假设噪声是加性的,因此可以将预测的噪声从输入中减去以产生输出。如上所述,去噪网络不仅将图像作为输入,还将反映文本输入的嵌入作为输入。嵌入的作用在于,要检测的噪声以嵌入为条件,这意味着输出应该与嵌入相关,并且要检测的噪声应该符合条件概率分布。技术上,图像和嵌入通过潜在模型中的交叉注意力机制相互作用,这在上述算法骨架中未显示。
有许多词汇可以描述一张图片,您可以想象让网络模型学习如何将一个词与一张图片关联起来并不容易。据报道,例如,Stable Diffusion 模型使用 LAION-5B 数据集(包含 58.5 亿张带文本描述的图像)进行了 23 亿张图像的训练,并消耗了 15 万 GPU 小时。然而,一旦模型训练完成,您就可以在您的笔记本电脑等商用计算机上使用它。
进一步阅读
以下是创建我们今天所知的图像生成扩散模型的几篇论文:
- Rombach、Blattmann、Lorenz、Esser 和 Ommer (2021) 的“使用潜在扩散模型进行高分辨率图像合成”
arXiv 2112.10752 - Ho、Jain 和 Abbeel (2020) 的“去噪扩散概率模型”
arXiv 2006.11239 - Dhariwal 和 Nichol (2021) 的“扩散模型在图像合成方面击败 GANs”
arXiv 2105.05233 - Nichol 和 Dhariwal (2021) 的“改进的去噪扩散概率模型”
arXiv 2102.09672
总结
在这篇文章中,您看到了扩散模型工作原理的概述。特别是,您学习了:
- 图像生成工作流程包含多个步骤,扩散模型在潜在空间中作为去噪神经网络工作。
- 图像生成通过从一张嘈杂图像开始实现,这是一组随机生成的像素。
- 在潜在空间的每一步中,去噪网络会去除一些噪声,并以最终图像的文本描述(以嵌入向量的形式)为条件。
- 通过解码潜在空间中的输出获得输出图像。
立即开始用 Stable Diffusion 精通数字艺术!

学习如何让 Stable Diffusion 为您服务
……通过学习图像生成过程中的一些关键要素
在我的新电子书中探索如何实现
使用 Stable Diffusion 精通数字艺术
本书提供了自学教程,其中包含所有可运行的 Python 代码,指导您从图像生成新手成长为专家。它教您如何设置 Stable Diffusion、微调模型、自动化工作流程、调整关键参数等等……所有这些都旨在帮助您创作出令人惊叹的数字艺术。






暂无评论。