神经网络由相互连接的层构建而成。有许多不同类型的层。对于图像相关应用,你总能找到卷积层。它是一种参数很少但应用于大尺寸输入的层。它之所以强大,是因为它能够保留图像的空间结构。因此,它被用于在计算机视觉神经网络上产生最先进的结果。在这篇文章中,你将学习卷积层及其构建的网络。完成本文后,你将了解:
- 什么是卷积层和池化层
- 它们如何在神经网络中协同工作
- 如何设计使用卷积层的神经网络
通过我的《用PyTorch进行深度学习》一书来启动你的项目。它提供了包含可用代码的自学教程。
让我们开始吧。

在 PyTorch 中构建卷积神经网络
图片由 Donna Elliot 拍摄。保留部分权利。
概述
本文分为四个部分;它们是:
- 卷积神经网络的案例
- 卷积神经网络的构建模块
- 卷积神经网络的示例
- 特征图中有什么?
卷积神经网络的案例
让我们考虑构建一个神经网络来处理灰度图像作为输入,这是计算机视觉深度学习中最简单的用例。
灰度图像是一个像素数组。每个像素通常是 0 到 255 范围内的值。一个 32x32 大小的图像将有 1024 个像素。将其作为神经网络的输入意味着第一层至少有 1024 个输入权重。
查看像素值对理解图像的作用不大,因为数据隐藏在空间结构中(例如,图片上是否存在水平线或垂直线)。因此,传统神经网络很难从图像输入中找出信息。
卷积神经网络使用卷积层来保留像素的空间信息。它学习相邻像素的相似程度并生成**特征表示**。卷积层从图像中看到的内容在一定程度上对失真是不变的。例如,即使输入图像颜色发生偏移、旋转或缩放,卷积神经网络也能预测相同的结果。此外,卷积层具有更少的权重,因此更容易训练。
卷积神经网络的构建模块
卷积神经网络最简单的用例是分类。你会发现它包含三种类型的层:
- 卷积层
- 池化层
- 全连接层
卷积层上的神经元称为滤波器。在图像应用中,它通常是一个 2D 卷积层。滤波器是一个 2D 补丁(例如,3x3 像素),应用于输入图像的像素。这个 2D 补丁的大小也称为感受野,表示它一次可以看到图像的多少部分。
卷积层的滤波器将与输入像素相乘,然后将结果求和。此结果是输出中的一个像素值。滤波器将在输入图像上移动以填充输出中的所有像素值。通常,多个滤波器应用于相同的输入,生成多个输出张量。这些输出张量称为该层生成的**特征图**。它们堆叠在一起形成一个张量并作为输入传递到下一层。
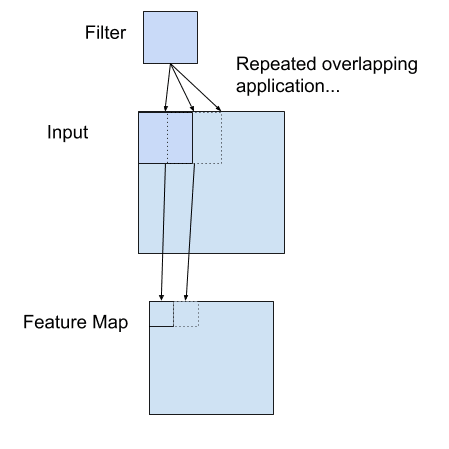
将滤波器应用于二维输入以创建特征图的示例
卷积层的输出称为特征图,因为它们通常学习了输入图像的特征。例如,在某个位置是否存在垂直线。从像素中学习特征有助于更高层次地理解图像。多个卷积层堆叠在一起,以便从较低层次的细节中推断出更高层次的特征。
池化层用于**下采样**上一层的特征图。它通常在卷积层之后使用,以整合学习到的特征。它可以压缩和泛化特征表示。池化层也有一个感受野,通常它是在感受野上取所有值的平均值(平均池化)或最大值(最大池化)。
全连接层通常是网络中的最后一层。它将前一个卷积层和池化层整合的特征作为输入,以产生预测。可能会有多个全连接层堆叠在一起。在分类的情况下,你通常会看到最后一个全连接层的输出应用了 softmax 函数,以产生类似概率的分类。
想开始使用PyTorch进行深度学习吗?
立即参加我的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
卷积神经网络的示例
以下是一个在 CIFAR-10 数据集上进行图像分类的程序。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
import torch import torch.nn as nn import torch.optim as optim import torchvision transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()]) trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) batch_size = 32 trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True) testloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True) class CIFAR10Model(nn.Module): def __init__(self): super().__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=(3,3), stride=1, padding=1) self.act1 = nn.ReLU() self.drop1 = nn.Dropout(0.3) self.conv2 = nn.Conv2d(32, 32, kernel_size=(3,3), stride=1, padding=1) self.act2 = nn.ReLU() self.pool2 = nn.MaxPool2d(kernel_size=(2, 2)) self.flat = nn.Flatten() self.fc3 = nn.Linear(8192, 512) self.act3 = nn.ReLU() self.drop3 = nn.Dropout(0.5) self.fc4 = nn.Linear(512, 10) def forward(self, x): # input 3x32x32, output 32x32x32 x = self.act1(self.conv1(x)) x = self.drop1(x) # input 32x32x32, output 32x32x32 x = self.act2(self.conv2(x)) # input 32x32x32, output 32x16x16 x = self.pool2(x) # input 32x16x16, output 8192 x = self.flat(x) # input 8192, output 512 x = self.act3(self.fc3(x)) x = self.drop3(x) # input 512, output 10 x = self.fc4(x) return x model = CIFAR10Model() loss_fn = nn.CrossEntropyLoss() optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9) n_epochs = 20 for epoch in range(n_epochs): for inputs, labels in trainloader: # forward, backward, and then weight update y_pred = model(inputs) loss = loss_fn(y_pred, labels) optimizer.zero_grad() loss.backward() optimizer.step() acc = 0 count = 0 for inputs, labels in testloader: y_pred = model(inputs) acc += (torch.argmax(y_pred, 1) == labels).float().sum() count += len(labels) acc /= count print("Epoch %d: model accuracy %.2f%%" % (epoch, acc*100)) torch.save(model.state_dict(), "cifar10model.pth") |
CIFAR-10 数据集提供 32x32 像素的 RGB 彩色图像(即 3 个颜色通道)。它有 10 个类别,标记为整数 0 到 9。无论何时使用 PyTorch 神经网络模型处理图像,你都会发现姐妹库 torchvision 很有用。在上面,你使用它从互联网下载 CIFAR-10 数据集并将其转换为 PyTorch 张量。
|
1 2 3 4 5 |
... transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()]) trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) |
你还使用了 PyTorch 中的 DataLoader 来帮助创建用于训练的批次。训练是通过随机梯度下降来优化模型的交叉熵损失。这是一个分类模型,因此分类的准确性比交叉熵更直观,分类准确性是在每个 epoch 结束时通过比较输出对数中最大值与数据集标签来计算的。
|
1 2 |
... acc += (torch.argmax(y_pred, 1) == labels).float().sum() |
运行上述程序训练网络需要时间。这个网络应该能够达到 70% 以上的分类准确率。
在图像分类网络中,通常早期阶段由卷积层组成,并穿插着 dropout 和池化层。然后,在后期,卷积层的输出被展平并由一些全连接层处理。
特征图中有什么?
上面定义的网络中有两个卷积层。它们都以 3x3 的核大小定义,因此一次查看 9 个像素以生成一个输出像素。请注意,第一个卷积层将 RGB 图像作为输入。因此,每个像素有三个通道。第二个卷积层将具有 32 个通道的特征图作为输入。它看到的每个“像素”将有 32 个值。因此,即使它们具有相同的感受野,第二个卷积层也具有更多的参数。
让我们看看特征图里有什么。假设我们从训练集中选取一个输入样本:
|
1 2 3 4 |
import matplotlib.pyplot as plt plt.imshow(trainset.data[7]) plt.show() |
你应该会看到这是一张马的图片,分辨率为 32x32 像素,带有 RGB 通道: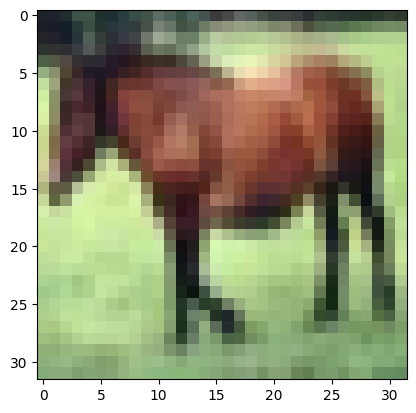
首先,你需要将其转换为 PyTorch 张量并将其制成一个批次的图像。PyTorch 模型期望每个图像都是 (通道, 高度, 宽度) 格式的张量,但你读取的数据是 (高度, 宽度, 通道) 格式的。如果你使用 torchvision 将图像转换为 PyTorch 张量,这种格式转换会自动完成。否则,你需要在使用前**调整**维度。
然后,将其通过模型的第一层卷积层并捕获输出。你需要告诉 PyTorch 此计算不需要梯度,因为你不会优化模型权重。
|
1 2 3 4 |
X = torch.tensor([trainset.data[7]], dtype=torch.float32).permute(0,3,1,2) model.eval() with torch.no_grad(): feature_maps = model.conv1(X) |
特征图都在一个张量中。你可以使用 matplotlib 将它们可视化。
|
1 2 3 4 5 |
fig, ax = plt.subplots(4, 8, sharex=True, sharey=True, figsize=(16,8)) for i in range(0, 32): row, col = i//8, i%8 ax[row][col].imshow(feature_maps[0][i]) plt.show() |
你可能会看到以下内容: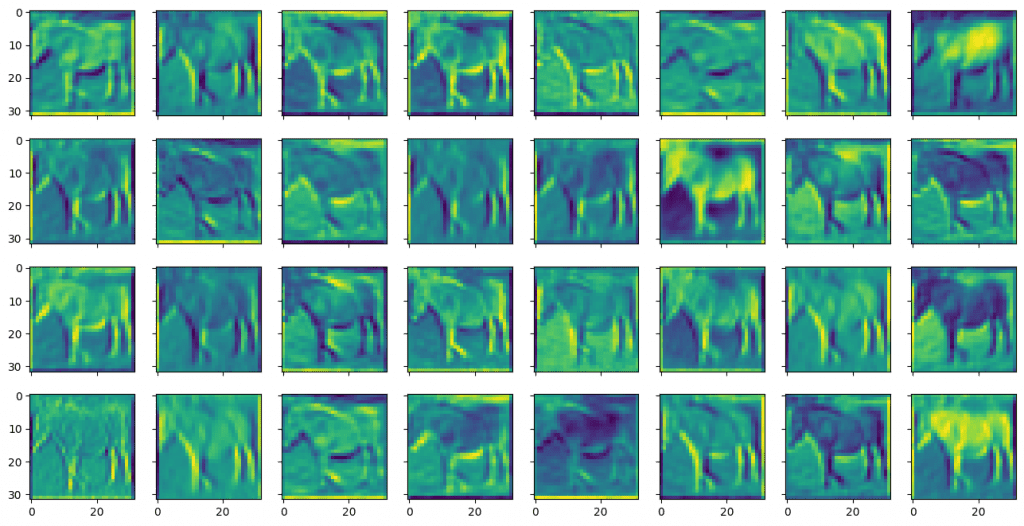
你可以看到它们被称为特征图,因为它们突出显示了输入图像的某些特征。特征通过一个小的窗口(在本例中,使用 3x3 像素的滤波器)进行识别。输入图像有三个颜色通道。每个通道都应用了不同的滤波器,它们的结果被组合起来生成一个输出特征。
你可以类似地显示第二个卷积层输出的特征图,如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
X = torch.tensor([trainset.data[7]], dtype=torch.float32).permute(0,3,1,2) model.eval() with torch.no_grad(): feature_maps = model.act1(model.conv1(X)) feature_maps = model.drop1(feature_maps) feature_maps = model.conv2(feature_maps) fig, ax = plt.subplots(4, 8, sharex=True, sharey=True, figsize=(16,8)) for i in range(0, 32): row, col = i//8, i%8 ax[row][col].imshow(feature_maps[0][i]) plt.show() |
显示如下: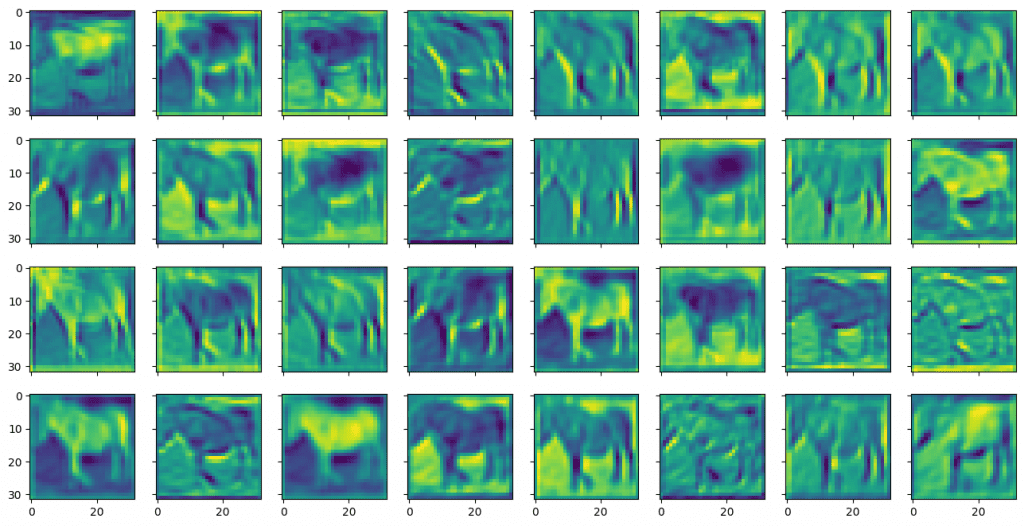
与第一个卷积层的输出相比,第二个卷积层的特征图看起来更模糊、更抽象。但这些对模型识别物体更有用。
总而言之,以下代码加载了上一节中保存的模型并生成了特征图。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
import torch import torch.nn as nn import torchvision import matplotlib.pyplot as plt trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True) class CIFAR10Model(nn.Module): def __init__(self): super().__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=(3,3), stride=1, padding=1) self.act1 = nn.ReLU() self.drop1 = nn.Dropout(0.3) self.conv2 = nn.Conv2d(32, 32, kernel_size=(3,3), stride=1, padding=1) self.act2 = nn.ReLU() self.pool2 = nn.MaxPool2d(kernel_size=(2, 2)) self.flat = nn.Flatten() self.fc3 = nn.Linear(8192, 512) self.act3 = nn.ReLU() self.drop3 = nn.Dropout(0.5) self.fc4 = nn.Linear(512, 10) def forward(self, x): # input 3x32x32, output 32x32x32 x = self.act1(self.conv1(x)) x = self.drop1(x) # input 32x32x32, output 32x32x32 x = self.act2(self.conv2(x)) # input 32x32x32, output 32x16x16 x = self.pool2(x) # input 32x16x16, output 8192 x = self.flat(x) # input 8192, output 512 x = self.act3(self.fc3(x)) x = self.drop3(x) # input 512, output 10 x = self.fc4(x) return x model = CIFAR10Model() model.load_state_dict(torch.load("cifar10model.pth")) plt.imshow(trainset.data[7]) plt.show() X = torch.tensor([trainset.data[7]], dtype=torch.float32).permute(0,3,1,2) model.eval() with torch.no_grad(): feature_maps = model.conv1(X) fig, ax = plt.subplots(4, 8, sharex=True, sharey=True, figsize=(16,8)) for i in range(0, 32): row, col = i//8, i%8 ax[row][col].imshow(feature_maps[0][i]) plt.show() with torch.no_grad(): feature_maps = model.act1(model.conv1(X)) feature_maps = model.drop1(feature_maps) feature_maps = model.conv2(feature_maps) fig, ax = plt.subplots(4, 8, sharex=True, sharey=True, figsize=(16,8)) for i in range(0, 32): row, col = i//8, i%8 ax[row][col].imshow(feature_maps[0][i]) plt.show() |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
文章
- 卷积层如何在深度学习神经网络中工作?
- 来自 PyTorch 教程的训练分类器
书籍
- 第 9 章:卷积网络,深度学习,2016 年。
API
- PyTorch 中的nn.Conv2d 层
总结
在这篇文章中,你学习了如何使用卷积神经网络处理图像输入以及如何可视化特征图。
具体来说,你学到了:
- 典型卷积神经网络的结构
- 滤波器大小对卷积层的影响
- 在网络中堆叠卷积层的作用
- 如何从卷积神经网络中提取和可视化特征图
开始使用PyTorch进行深度学习!

学习如何构建深度学习模型
...使用新发布的PyTorch 2.0库
在我的新电子书中探索如何实现
使用 PyTorch进行深度学习
它提供了包含数百个可用代码的自学教程,让你从新手变成专家。它将使你掌握:
张量操作、训练、评估、超参数优化等等...
")





在“卷积神经网络示例”代码部分的 #L13 行中
testloader = torch.utils.data.DataLoader( #这里 => trainset, batch_size=batch_size, shuffle=True)
我们应该使用 testset 而不是 trainset 对吗?
你好 Prashanth……是的。谢谢你的反馈!
你完全没有解释或提及这个类。作为初学者,这个过程中存在一个巨大的漏洞,让我很难理解和跟进整个指南。
谢谢你的反馈!