当今的大型语言模型是 Transformer 模型的简化形式。它们被称为仅解码器模型,因为它们的作用类似于 Transformer 的解码器部分,即给定部分序列作为输入,生成输出序列。从架构上讲,它们更接近 Transformer 模型的编码器部分。在这篇文章中,您将构建一个用于文本生成的仅解码器 Transformer 模型,其架构与 Meta 的 Llama-2 或 Llama-3 相同。具体来说,您将学习:
- 如何构建仅解码器模型
- 仅解码器模型的架构设计变体
- 如何训练模型
让我们开始吧。

构建用于文本生成的仅解码器 Transformer 模型
图片来源:Jay。保留部分权利。
概述
本文分为五个部分,它们是:
- 从完整 Transformer 到仅解码器模型
- 构建仅解码器模型
- 用于自监督学习的数据准备
- 训练模型
- 扩展
从完整 Transformer 到仅解码器模型
Transformer 模型最初是作为序列到序列 (seq2seq) 模型而出现的,它将输入序列转换为上下文向量,然后使用该向量生成新的序列。在此架构中,编码器部分负责将输入序列转换为上下文向量,而解码器部分则从该上下文向量生成新的序列。
我们能否不使用上下文向量生成一个全新的序列,而是将其投影到表示词汇表中每个标记概率的 logits 向量中?这样,给定部分序列作为输入,模型就可以预测下一个最可能的标记。通过迭代地将序列反馈给模型,我们可以一次生成一个标记的连贯文本,就像文本编辑器中的自动完成功能一样。这种简化架构只专注于预测下一个标记,被称为仅解码器模型。
构建仅解码器模型
仅解码器模型比完整的 Transformer 模型具有更简单的架构。从上一篇文章中讨论的完整 Transformer 架构开始,您可以通过完全移除编码器组件并调整解码器以独立操作来创建仅解码器模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
class DecoderLayer(nn.Module): def __init__(self, hidden_dim, num_heads, num_kv_heads, dropout=0.1): super().__init__() self.self_attn = GQA(hidden_dim, num_heads, num_kv_heads, dropout) self.mlp = SwiGLU(hidden_dim, 4 * hidden_dim) self.norm1 = nn.RMSNorm(hidden_dim) self.norm2 = nn.RMSNorm(hidden_dim) def forward(self, x, mask=None, rope=None): # self-attention sublayer out = self.norm1(x) out = self.self_attn(out, out, out, mask, rope) x = out + x # MLP sublayer out = self.norm2(x) out = self.mlp(out) return out + x class TextGenerationModel(nn.Module): def __init__(self, num_layers, num_heads, num_kv_heads, hidden_dim, max_seq_len, vocab_size, dropout=0.1): super().__init__() self.rope = RotaryPositionalEncoding(hidden_dim // num_heads, max_seq_len) self.embedding = nn.Embedding(vocab_size, hidden_dim) self.decoders = nn.ModuleList([ DecoderLayer(hidden_dim, num_heads, num_kv_heads, dropout) for _ in range(num_layers) ]) self.norm = nn.RMSNorm(hidden_dim) self.out = nn.Linear(hidden_dim, vocab_size) def forward(self, ids, mask=None): x = self.embedding(ids) for decoder in self.decoders: x = decoder(x, mask, self.rope) x = self.norm(x) return self.out(x) |
此实现重用了完整 Transformer 模型中的大部分代码。`DecoderLayer` 类与之前实现中的 `EncoderLayer` 具有相同的结构。`TextGenerationModel` 类具有简化的 `forward()` 方法,因为它不再需要处理编码器-解码器交互。它只是将输入的 token ID 转换为嵌入,通过堆叠的解码器层进行处理,并将输出投影到表示词汇表中每个 token 概率的 logits。
在图中,该模型如下所示。这与 Meta 提出的 Llama-2/Llama-3 模型的架构设计相同。
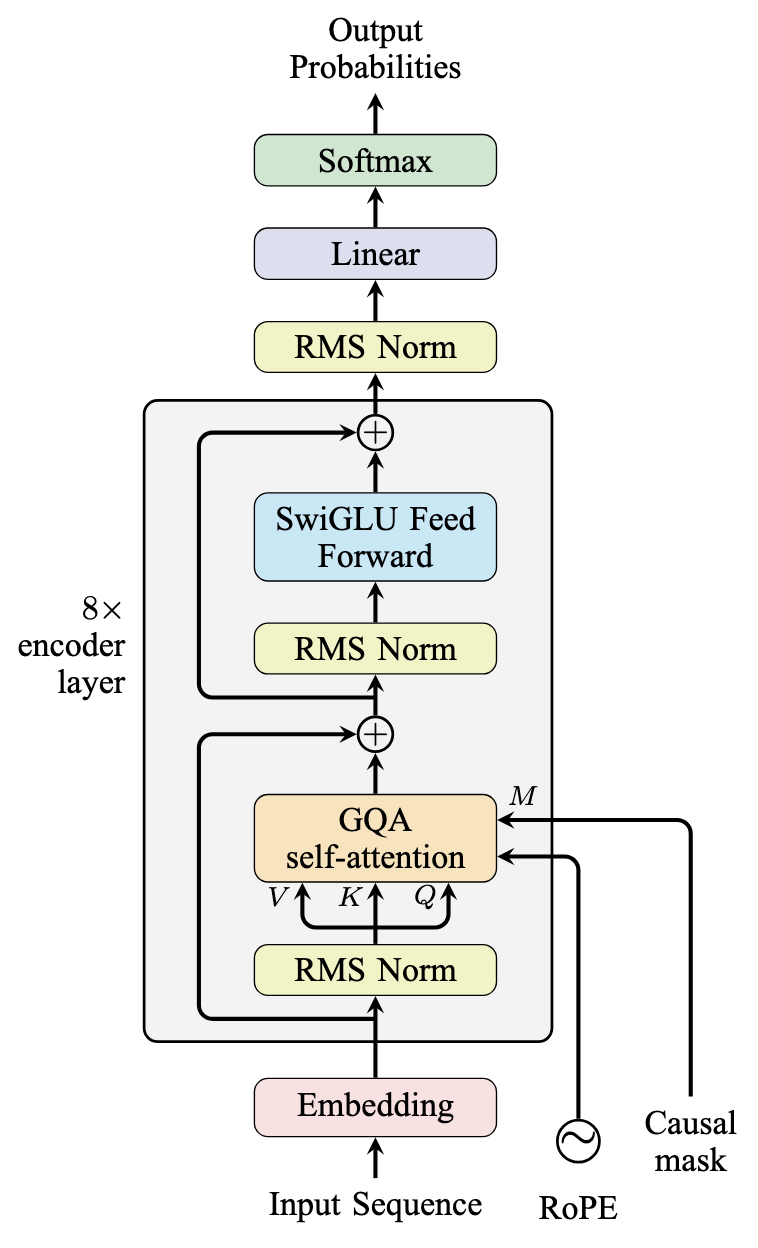
遵循 Llama-2/Llama-3 架构的仅解码器模型
用于自监督学习的数据准备
我们的目标是创建一个模型,即使提示只包含一个单词,也能从给定的提示生成连贯的文本段落。为了有效地训练这样的模型,我们需要仔细考虑我们的训练方法和数据要求。
我们将使用的训练技术称为自监督学习。与需要手动标记数据的传统监督学习不同,自监督学习利用文本本身的内在结构。当我们输入一个文本序列时,模型会学习预测下一个标记,而文本中实际的下一个标记则作为真实标签。这消除了手动标记的需要。
训练数据集的大小至关重要。对于包含 $N$ 个标记的词汇表和包含 $M$ 个单词的数据集,每个标记平均出现约 $M/N$ 次。为了确保模型学习所有标记的有意义的表示,这个比率需要足够大。
在这篇文章中,您将从古腾堡计划下载一些小说,并将其用作训练模型的数据集。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import os import requests # 从古腾堡计划下载小说 DATASOURCE = { "moby_dick": "https://www.gutenberg.org/ebooks/2701.txt.utf-8", "frankenstein": "https://www.gutenberg.org/ebooks/84.txt.utf-8", "dracula": "https://www.gutenberg.org/ebooks/345.txt.utf-8", "little_women": "https://www.gutenberg.org/ebooks/37106.txt.utf-8", "pride_and_prejudice": "https://www.gutenberg.org/ebooks/1342.txt.utf-8", "alice_in_wonderland": "https://www.gutenberg.org/ebooks/11.txt.utf-8", "crime_and_punishment": "https://www.gutenberg.org/ebooks/2554.txt.utf-8", "tom_sawyer": "https://www.gutenberg.org/ebooks/74.txt.utf-8", "tale_of_two_cities": "https://www.gutenberg.org/ebooks/98.txt.utf-8", "sherlock_holmes": "https://www.gutenberg.org/ebooks/1661.txt.utf-8", "war_and_peace": "https://www.gutenberg.org/ebooks/2600.txt.utf-8", } for filename, url in DATASOURCE.items(): if not os.path.exists(f"{filename}.txt"): response = requests.get(url) with open(f"{filename}.txt", "wb") as f: f.write(response.content) |
这些来自不同作者和不同体裁的公共领域小说提供了一个多样化的数据集,这将帮助我们的模型学习广泛的词汇和写作风格。
下载这些小说后,您可以将主要内容提取为字符串,并将这些字符串保留为列表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 读取并预处理文本 def preprocess_gutenberg(filename): with open(filename, "r", encoding="utf-8") as f: text = f.read() # 找到实际内容的开始和结束 start = text.find("*** START OF THE PROJECT GUTENBERG EBOOK") start = text.find("\n", start) + 1 end = text.find("*** END OF THE PROJECT GUTENBERG EBOOK") # 提取主要内容 text = text[start:end].strip() # 基本预处理 # 移除多个换行符和空格 text = "\n".join(line.strip() for line in text.split("\n") if line.strip()) return text def get_dataset_text(): all_text = [] for filename in DATASOURCE: text = preprocess_gutenberg(f"{filename}.txt") all_text.append(text) return all_text |
下一步是创建分词器。您可以通过将文本分割成单词来构建一个简单的分词器。您也可以使用字节对编码 (BPE) 算法来创建一个更复杂的分词器,如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import tokenizers # 使用 BPE 进行分词 tokenizer = tokenizers.Tokenizer(tokenizers.models.BPE()) # 配置预分词器,在句子开头添加空格 tokenizer.pre_tokenizer = tokenizers.pre_tokenizers.ByteLevel(add_prefix_space=True) # 配置解码器以移除词边界符号 tokenizer.decoder = tokenizers.decoders.ByteLevel() # 训练 BPE VOCAB_SIZE = 10000 trainer = tokenizers.trainers.BpeTrainer( vocab_size=VOCAB_SIZE, special_tokens=["[pad]", "[eos]"], show_progress=True ) text = get_dataset_text() tokenizer.train_from_iterator(text, trainer=trainer) tokenizer.enable_padding(pad_id=tokenizer.token_to_id("[pad]"), pad_token="[pad]") # 保存训练好的分词器 tokenizer.save("gutenberg_tokenizer.json", pretty=True) |
这使用 `tokenizers` 库来训练 BPE 分词器。您调用 `get_dataset_text()` 获取所有小说的文本,然后在此基础上训练分词器。您还需要两个特殊标记:`[pad]` 和 `[eos]`。最重要的是,`[eos]` 标记用于指示序列的结束。如果您的模型生成此标记,您就知道可以停止生成。
训练模型
分词器和数据集准备就绪后,您现在可以训练模型。
首先,您需要创建一个可用于训练模型的 `Dataset` 对象。PyTorch 为此提供了一个框架。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import torch class GutenbergDataset(torch.utils.data.Dataset): def __init__(self, text, tokenizer, seq_len=512): self.seq_len = seq_len # 编码整个文本 self.encoded = tokenizer.encode(text).ids def __len__(self): return len(self.encoded) - self.seq_len def __getitem__(self, idx): chunk = self.encoded[idx:idx + self.seq_len + 1] # +1 用于目标 x = torch.tensor(chunk[:-1]) y = torch.tensor(chunk[1:]) return x, y BATCH_SIZE = 32 text = "\n".join(get_dataset_text()) dataset = GutenbergDataset(text, tokenizer, seq_len=model_config["max_seq_len"]) dataloader = torch.utils.data.DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True) |
此 `Dataset` 对象用于创建一个 `DataLoader` 对象,该对象可用于训练模型。`DataLoader` 对象将自动批量处理数据并对其进行混洗。
`Dataset` 对象在 `__getitem__()` 方法中生成一对输入和输出序列。它们的长度相同,但偏移了一个标记。当输入序列传递给模型时,模型为序列中的每个位置生成下一个标记。因此,真实输出来自同一源,偏移了一个标记。这就是您如何设置自监督训练。
现在您可以创建并训练模型了。您可以使用此代码创建一个非常大的模型。但是,如果您不期望模型非常强大,您可以设计一个更小的模型。让我们创建一个具有以下特征的模型:
- 8 层
- 注意力机制使用 8 个查询头和 4 个键值头
- 隐藏维度为 768
- 最大序列长度为 512
- 注意力机制的 dropout 设置为 0.1
- 使用 AdamW 优化器训练,初始学习率为 0.0005
- 学习率调度器具有 2000 步预热,然后是余弦退火
- 训练 2 个 epoch,批量大小为 32,梯度范数裁剪为 6.0
以上一切都很典型。训练一个仅解码器模型通常需要非常大的数据集,并且 epoch 的数量可能少至 1。重要的是训练步数。训练将使用线性预热在开始时逐渐增加学习率,这可以减少模型初始化方式的影响。然后,余弦退火将逐渐降低学习率,以便在训练结束时,当模型几乎收敛时,它将学习率保持在一个非常小的值以稳定结果。
模型创建和训练的代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 |
# 训练配置 model_config = { "num_layers": 8, "num_heads": 8, "num_kv_heads": 4, "hidden_dim": 768, "max_seq_len": 512, "vocab_size": len(tokenizer.get_vocab()), "dropout": 0.1, } # 初始化模型、优化器等。 device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = TextGenerationModel(**model_config).to(device) # 创建数据集和数据加载器 BATCH_SIZE = 32 text = "\n".join(get_dataset_text()) dataset = GutenbergDataset(text, tokenizer, seq_len=model_config["max_seq_len"]) dataloader = torch.utils.data.DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True) # 训练循环 N_EPOCHS = 2 LR = 0.0005 WARMUP_STEPS = 2000 CLIP_NORM = 6.0 optimizer = optim.AdamW(model.parameters(), lr=LR) loss_fn = nn.CrossEntropyLoss(ignore_index=tokenizer.token_to_id("[pad]")) # 学习率调度 warmup_scheduler = optim.lr_scheduler.LinearLR( optimizer, start_factor=0.01, end_factor=1.0, total_iters=WARMUP_STEPS) cosine_scheduler = optim.lr_scheduler.CosineAnnealingLR( optimizer, T_max=N_EPOCHS * len(dataloader) - WARMUP_STEPS, eta_min=0) scheduler = optim.lr_scheduler.SequentialLR( optimizer, schedulers=[warmup_scheduler, cosine_scheduler], milestones=[WARMUP_STEPS]) print(f"Training for {N_EPOCHS} epochs with {len(dataloader)} steps per epoch") best_loss = float('inf') for epoch in range(N_EPOCHS): model.train() epoch_loss = 0 for x, y in dataloader: x = x.to(device) y = y.to(device) # 创建因果掩码 mask = create_causal_mask(x.shape[1], device) # 前向传播 optimizer.zero_grad() outputs = model(x, mask.unsqueeze(0)) # 计算损失 loss = loss_fn(outputs.view(-1, outputs.shape[-1]), y.view(-1)) # 反向传播 loss.backward() torch.nn.utils.clip_grad_norm_( model.parameters(), CLIP_NORM, error_if_nonfinite=True ) optimizer.step() scheduler.step() epoch_loss += loss.item() avg_loss = epoch_loss / len(dataloader) print(f"Epoch {epoch+1}/{N_EPOCHS}; Avg loss: {avg_loss:.4f}") # 如果损失改善,保存检查点 if avg_loss < best_loss: best_loss = avg_loss torch.save(model.state_dict(), "textgen_model.pth") |
在训练循环中,您执行了常见的前向和后向传播。每当损失改善时,模型都会被保存。为简单起见,没有实现评估。您应该定期(不一定在每个 epoch 之后)评估模型以监控进度。
由于词汇量和序列长度较大,训练过程计算密集。即使在高端 RTX 4090 GPU 上,每个 epoch 也需要大约 10 小时才能完成。
训练完成后,您可以加载模型并生成文本。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# 生成函数 def generate_text(model, tokenizer, prompt, max_length=100, temperature=0.7): model.eval() device = next(model.parameters()).device # 编码提示 input_ids = torch.tensor(tokenizer.encode(prompt).ids).unsqueeze(0).to(device) with torch.no_grad(): for _ in range(max_length): # 获取模型对下一个标记的预测作为输出的最后一个元素 outputs = model(input_ids) next_token_logits = outputs[:, -1, :] / temperature # 从分布中采样 probs = F.softmax(next_token_logits, dim=-1) next_token = torch.multinomial(probs, num_samples=1) # 追加到 input_ids input_ids = torch.cat([input_ids, next_token], dim=1) # 如果预测到结束标记,则停止 if next_token[0].item() == tokenizer.token_to_id("[eos]"): break return tokenizer.decode(input_ids[0].tolist()) # 用一些提示测试模型 test_prompts = [ "Once upon a time,", "We the people of the", "In the beginning was the", ] print("\nGenerating sample texts:") for prompt in test_prompts: generated = generate_text(model, tokenizer, prompt) print(f"\nPrompt: {prompt}") print(f"Generated: {generated}") print("-" * 80) |
模型在 `generate_text()` 函数中用于生成文本。它期望一个不完整的句子作为输入 `prompt`,模型将在 for 循环的每一步中用于生成下一个标记。生成算法使用概率采样,而不是总是选择最可能的标记。这使得模型能够生成更具创造性的文本。`temperature` 参数控制生成文本的创造性水平。
模型的输出是一个 logits 向量,采样过程生成一个 token ID 向量。这个向量将由分词器转换回字符串。
如果您运行此代码,您可能会看到以下输出:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
生成示例文本 提示:曾几何时, 生成: 曾几何时, 汤姆和她一起休息,他们谈论着家,那里的朋友, 以及舒适的床,最重要的是,光明!贝基哭了,汤姆 试图想办法安慰她,但他所有的鼓励 都已用尽,听起来像讽刺。疲劳严重地压在贝基身上, 她睡着了。汤姆很感激。 他 -------------------------------------------------------------------------------- 提示:我们人民的 生成: 我们法国人民的 附近:那里有一个可怕的危险 在危险事件中我们从猿猴跳了出来。 那些士兵,害怕被 能够自己攻击法国人。 很明显,俄罗斯的巢穴被摧毁了,但在被摧毁的 俄罗斯生活秩序的地方,皮埃尔 不自觉地感觉到,在这个被毁的巢穴上,已经建立了一种 完全不同、坚固的法国秩序。 -------------------------------------------------------------------------------- 提示:最初是 生成: 最初是第一次 我亲爱的姐姐的沉思。” “等一下,”福尔摩斯说,“你确定 皇帝是干净的,而不是你,而且我不需要费心 只要我有一台机器,比简好得多,而且 带着一个不常被提及的女人的真相, 与任何其他人一样,这种步骤的后果必须 为节日而放弃 -------------------------------------------------------------------------------- |
尽管生成的文本显示出一定的连贯性和对语言模式的理解,但它并不完美。然而,考虑到我们模型相对较小的规模和有限的训练数据,这些结果令人鼓舞。
为了完整性,下面是模型和训练的完整代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 |
import os import requests import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim import tokenizers import tqdm # 从古腾堡计划下载小说 DATASOURCE = { "moby_dick": "https://www.gutenberg.org/ebooks/2701.txt.utf-8", "frankenstein": "https://www.gutenberg.org/ebooks/84.txt.utf-8", "dracula": "https://www.gutenberg.org/ebooks/345.txt.utf-8", "little_women": "https://www.gutenberg.org/ebooks/37106.txt.utf-8", "pride_and_prejudice": "https://www.gutenberg.org/ebooks/1342.txt.utf-8", "alice_in_wonderland": "https://www.gutenberg.org/ebooks/11.txt.utf-8", "crime_and_punishment": "https://www.gutenberg.org/ebooks/2554.txt.utf-8", "tom_sawyer": "https://www.gutenberg.org/ebooks/74.txt.utf-8", "tale_of_two_cities": "https://www.gutenberg.org/ebooks/98.txt.utf-8", "sherlock_holmes": "https://www.gutenberg.org/ebooks/1661.txt.utf-8", "war_and_peace": "https://www.gutenberg.org/ebooks/2600.txt.utf-8", } for filename, url in DATASOURCE.items(): if not os.path.exists(f"{filename}.txt"): response = requests.get(url) with open(f"{filename}.txt", "wb") as f: f.write(response.content) # 读取并预处理文本 def preprocess_gutenberg(filename): with open(filename, "r", encoding="utf-8") as f: text = f.read() # 找到实际内容的开始和结束 start = text.find("*** START OF THE PROJECT GUTENBERG EBOOK") start = text.find("\n", start) + 1 end = text.find("*** END OF THE PROJECT GUTENBERG EBOOK") # 提取主要内容 text = text[start:end].strip() # 基本预处理 # 移除多个换行符和空格 text = "\n".join(line.strip() for line in text.split("\n") if line.strip()) return text def get_dataset_text(): all_text = [] for filename in DATASOURCE: text = preprocess_gutenberg(f"{filename}.txt") all_text.append(text) return all_text # 使用 BPE 进行分词 if os.path.exists("gutenberg_tokenizer.json"): tokenizer = tokenizers.Tokenizer.from_file("gutenberg_tokenizer.json") else: tokenizer = tokenizers.Tokenizer(tokenizers.models.BPE()) # 配置预分词器,在句子开头添加空格 tokenizer.pre_tokenizer = tokenizers.pre_tokenizers.ByteLevel(add_prefix_space=True) # 配置解码器以移除词边界符号 tokenizer.decoder = tokenizers.decoders.ByteLevel() # 训练 BPE VOCAB_SIZE = 10000 trainer = tokenizers.trainers.BpeTrainer( vocab_size=VOCAB_SIZE, special_tokens=["[pad]", "[eos]"], show_progress=True ) text = get_dataset_text() tokenizer.train_from_iterator(text, trainer=trainer) tokenizer.enable_padding(pad_id=tokenizer.token_to_id("[pad]"), pad_token="[pad]") # 保存训练好的分词器 tokenizer.save("gutenberg_tokenizer.json", pretty=True) # 创建 PyTorch 数据集 class GutenbergDataset(torch.utils.data.Dataset): def __init__(self, text, tokenizer, seq_len=512): self.seq_len = seq_len # 编码整个文本 self.encoded = tokenizer.encode(text).ids def __len__(self): return len(self.encoded) - self.seq_len def __getitem__(self, idx): chunk = self.encoded[idx:idx + self.seq_len + 1] # +1 用于目标 x = torch.tensor(chunk[:-1]) y = torch.tensor(chunk[1:]) return x, y def rotate_half(x): x1, x2 = x.chunk(2, dim=-1) return torch.cat((-x2, x1), dim=-1) def apply_rotary_pos_emb(x, cos, sin): return (x * cos) + (rotate_half(x) * sin) class RotaryPositionalEncoding(nn.Module): def __init__(self, dim, max_seq_len=1024): super().__init__() N = 10000 inv_freq = 1. / (N ** (torch.arange(0, dim, 2).float() / dim)) position = torch.arange(max_seq_len).float() inv_freq = torch.cat((inv_freq, inv_freq), dim=-1) sinusoid_inp = torch.outer(position, inv_freq) self.register_buffer("cos", sinusoid_inp.cos()) self.register_buffer("sin", sinusoid_inp.sin()) def forward(self, x, seq_len=None): if seq_len is None: seq_len = x.size(1) cos = self.cos[:seq_len].view(1, seq_len, 1, -1) sin = self.sin[:seq_len].view(1, seq_len, 1, -1) return apply_rotary_pos_emb(x, cos, sin) class SwiGLU(nn.Module): def __init__(self, hidden_dim, intermediate_dim): super().__init__() self.gate = nn.Linear(hidden_dim, intermediate_dim) self.up = nn.Linear(hidden_dim, intermediate_dim) self.down = nn.Linear(intermediate_dim, hidden_dim) self.act = nn.SiLU() def forward(self, x): x = self.act(self.gate(x)) * self.up(x) x = self.down(x) return x class GQA(nn.Module): def __init__(self, hidden_dim, num_heads, num_kv_heads=None, dropout=0.1): super().__init__() self.num_heads = num_heads self.num_kv_heads = num_kv_heads or num_heads self.head_dim = hidden_dim // num_heads self.num_groups = num_heads // num_kv_heads self.dropout = dropout self.q_proj = nn.Linear(hidden_dim, hidden_dim) self.k_proj = nn.Linear(hidden_dim, hidden_dim) self.v_proj = nn.Linear(hidden_dim, hidden_dim) self.out_proj = nn.Linear(hidden_dim, hidden_dim) def forward(self, q, k, v, mask=None, rope=None): q_batch_size, q_seq_len, hidden_dim = q.shape k_batch_size, k_seq_len, hidden_dim = k.shape v_batch_size, v_seq_len, hidden_dim = v.shape # projection q = self.q_proj(q).view(q_batch_size, q_seq_len, -1, self.head_dim).transpose(1, 2) k = self.k_proj(k).view(k_batch_size, k_seq_len, -1, self.head_dim).transpose(1, 2) v = self.v_proj(v).view(v_batch_size, v_seq_len, -1, self.head_dim).transpose(1, 2) # apply rotary positional encoding if rope: q = rope(q) k = rope(k) # compute grouped query attention q = q.contiguous() k = k.contiguous() v = v.contiguous() output = F.scaled_dot_product_attention(q, k, v, attn_mask=mask, dropout_p=self.dropout, enable_gqa=True) output = output.transpose(1, 2).reshape(q_batch_size, q_seq_len, hidden_dim).contiguous() output = self.out_proj(output) return output class DecoderLayer(nn.Module): def __init__(self, hidden_dim, num_heads, num_kv_heads, dropout=0.1): super().__init__() self.self_attn = GQA(hidden_dim, num_heads, num_kv_heads, dropout) self.mlp = SwiGLU(hidden_dim, 4 * hidden_dim) self.norm1 = nn.RMSNorm(hidden_dim) self.norm2 = nn.RMSNorm(hidden_dim) def forward(self, x, mask=None, rope=None): # self-attention sublayer out = self.norm1(x) out = self.self_attn(out, out, out, mask, rope) x = out + x # MLP sublayer out = self.norm2(x) out = self.mlp(out) return out + x class TextGenerationModel(nn.Module): def __init__(self, num_layers, num_heads, num_kv_heads, hidden_dim, max_seq_len, vocab_size, dropout=0.1): super().__init__() self.rope = RotaryPositionalEncoding(hidden_dim // num_heads, max_seq_len) self.embedding = nn.Embedding(vocab_size, hidden_dim) self.decoders = nn.ModuleList([ DecoderLayer(hidden_dim, num_heads, num_kv_heads, dropout) for _ in range(num_layers) ]) self.norm = nn.RMSNorm(hidden_dim) self.out = nn.Linear(hidden_dim, vocab_size) def forward(self, ids, mask=None): x = self.embedding(ids) for decoder in self.decoders: x = decoder(x, mask, self.rope) x = self.norm(x) return self.out(x) def create_causal_mask(seq_len, device): """Create a causal mask for autoregressive attention.""" mask = torch.triu(torch.full((seq_len, seq_len), float('-inf'), device=device), diagonal=1) return mask # 训练配置 model_config = { "num_layers": 8, "num_heads": 8, "num_kv_heads": 4, "hidden_dim": 768, "max_seq_len": 512, "vocab_size": len(tokenizer.get_vocab()), "dropout": 0.1, } # 初始化模型、优化器等。 device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = TextGenerationModel(**model_config).to(device) # 创建数据集和数据加载器 BATCH_SIZE = 32 text = "\n".join(get_dataset_text()) dataset = GutenbergDataset(text, tokenizer, seq_len=model_config["max_seq_len"]) dataloader = torch.utils.data.DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True) # 训练循环 if os.path.exists("textgen_model.pth"): model.load_state_dict(torch.load("textgen_model.pth")) else: N_EPOCHS = 2 LR = 0.0005 WARMUP_STEPS = 2000 CLIP_NORM = 6.0 optimizer = optim.AdamW(model.parameters(), lr=LR) loss_fn = nn.CrossEntropyLoss(ignore_index=tokenizer.token_to_id("[pad]")) # Learning rate scheduling warmup_scheduler = optim.lr_scheduler.LinearLR( optimizer, start_factor=0.01, end_factor=1.0, total_iters=WARMUP_STEPS) cosine_scheduler = optim.lr_scheduler.CosineAnnealingLR( optimizer, T_max=N_EPOCHS * len(dataloader) - WARMUP_STEPS, eta_min=0) scheduler = optim.lr_scheduler.SequentialLR( optimizer, schedulers=[warmup_scheduler, cosine_scheduler], milestones=[WARMUP_STEPS]) print(f"Training for {N_EPOCHS} epochs with {len(dataloader)} steps per epoch") best_loss = float('inf') for epoch in range(N_EPOCHS): model.train() epoch_loss = 0 progress_bar = tqdm.tqdm(dataloader, desc=f"Epoch {epoch+1}/{N_EPOCHS}") for x, y in progress_bar: x = x.to(device) y = y.to(device) # Create causal mask mask = create_causal_mask(x.shape[1], device) # Forward pass optimizer.zero_grad() outputs = model(x, mask.unsqueeze(0)) # Compute loss loss = loss_fn(outputs.view(-1, outputs.shape[-1]), y.view(-1)) # Backward pass loss.backward() torch.nn.utils.clip_grad_norm_( model.parameters(), CLIP_NORM, error_if_nonfinite=True ) optimizer.step() scheduler.step() epoch_loss += loss.item() # Show loss in tqdm progress_bar.set_postfix(loss=loss.item()) avg_loss = epoch_loss / len(dataloader) print(f"Epoch {epoch+1}/{N_EPOCHS}; Avg loss: {avg_loss:.4f}") # Save checkpoint if loss improved if avg_loss < best_loss: best_loss = avg_loss torch.save(model.state_dict(), "textgen_model.pth") # 生成函数 def generate_text(model, tokenizer, prompt, max_length=100, temperature=0.7): model.eval() device = next(model.parameters()).device # 编码提示 input_ids = torch.tensor(tokenizer.encode(prompt).ids).unsqueeze(0).to(device) with torch.no_grad(): for _ in range(max_length): # 获取模型对下一个标记的预测作为输出的最后一个元素 outputs = model(input_ids) next_token_logits = outputs[:, -1, :] / temperature # 从分布中采样 probs = F.softmax(next_token_logits, dim=-1) next_token = torch.multinomial(probs, num_samples=1) # 追加到 input_ids input_ids = torch.cat([input_ids, next_token], dim=1) # 如果预测到结束标记,则停止 if next_token[0].item() == tokenizer.token_to_id("[eos]"): break return tokenizer.decode(input_ids[0].tolist()) # 用一些提示测试模型 test_prompts = [ "Once upon a time,", "We the people of the", "In the beginning was the", ] print("\nGenerating sample texts:") for prompt in test_prompts: generated = generate_text(model, tokenizer, prompt) print(f"\nPrompt: {prompt}") print(f"Generated: {generated}") print("-" * 80) |
扩展
虽然我们已经成功地实现了一个基本的仅解码器模型,但现代大型语言模型(LLM)要复杂得多。以下是关键的改进领域:
- 规模和架构:现代LLM使用更多的层和更大的隐藏维度。它们还融合了我们在这里实现的之外的先进技术,例如专家混合(mixture of experts)。
- 数据集大小和多样性:我们目前的数据集,仅包含几兆字节的小说文本,与现代LLM中使用的万亿字节级数据集相比,微不足道。生产模型是在多种语言的各种内容类型上进行训练的。
- 训练流程:我们在这里实现的是LLM开发中的“预训练”。生产模型通常会通过额外的微调阶段,使用专门的数据集和定制的训练目标来完成特定任务,例如问答或指令遵循。
- 训练基础设施:训练大型模型需要复杂的分布式训练技术,跨多个GPU进行训练、梯度累积以及其他优化,这需要对我们的训练循环进行重大修改。
进一步阅读
以下是一些您可能会觉得有用的链接:
总结
在这篇文章中,您已经了解了构建一个仅解码器Transformer模型进行文本生成的过程。具体来说,您学到了:
- 如何将完整的Transformer架构简化为仅解码器模型
- 实现用于文本生成任务的自监督学习
- 使用训练好的模型创建文本生成流程
这种仅解码器架构是许多现代大型语言模型的基础,使其成为自然语言处理领域中一个至关重要的概念。






暂无评论。