PyTorch 库是用于深度学习的。深度学习模型的一些应用是用于解决回归或分类问题。在本教程中,您将了解如何使用 PyTorch 开发和评估用于多类别分类问题的神经网络模型。
完成本分步教程后,您将了解
- 如何从 CSV 加载数据并使其可供 PyTorch 使用
- 如何准备多类别分类数据以用于神经网络建模
- 如何使用交叉验证来评估 PyTorch 神经网络模型
通过我的《用PyTorch进行深度学习》一书来启动你的项目。它提供了包含可用代码的自学教程。
让我们开始吧。

在 PyTorch 中构建多类别分类模型
照片作者:Cheung Yin。部分权利保留。
问题描述
在本教程中,您将使用一个标准的机器学习数据集,称为鸢尾花数据集。这是一个经过充分研究的数据集,非常适合练习机器学习。它有四个输入变量;所有变量都是数值型的,单位为厘米,是长度测量值。因此,它们的尺度相似。每个数据样本描述了观察到的鸢尾花特性。其目标是利用测量值(输入特征)来分类鸢尾花的种类(输出标签)。
数据集中有三种鸢尾花。因此,这是一个多类别分类问题。多类别分类问题很特殊,因为它们需要特殊处理来指定类别。
该数据集来自现代统计学之父 Sir Ronald Fisher。它是最著名的模式识别数据集,您可以达到 95% 至 97% 的模型准确率。您可以将此作为您开发深度学习模型的目标。
您可以从 UCI 机器学习存储库下载 鸢尾花数据集,并将其放在当前工作目录中,文件名为“iris.csv”。您也可以 在此处 下载数据集。
加载数据集
读取 CSV 文件有多种方法。最简单的方法可能是使用 pandas 库。读取数据集后,您需要将其拆分为特征和标签,因为您需要进一步处理标签才能使用。与 NumPy 或 PyTorch 张量不同,pandas DataFrame 只能通过 iloc 按索引进行切片。
|
1 2 3 4 |
import pandas as pd data = pd.read_csv("iris.csv", header=None) X = data.iloc[:, 0:4] y = data.iloc[:, 4:] |
现在,您已经加载了数据集,并将属性(即输入特征,DataFrame 中的列)作为 X,并将输出变量(即物种标签)作为单列 DataFrame y 分割开。
编码分类变量
物种标签是字符串,但您希望它们是数字。这是因为数字数据更容易使用。在此数据集中,三个类别标签是 Iris-setosa、Iris-versicolor 和 Iris-virginica。将这些标签转换为数字(即编码它们)的一种方法是简单地分配一个整数值,例如 0、1 或 2 来替换这些标签。但是有一个问题:您不希望模型认为 Iris-virginica 是 Iris-setosa 和 Iris-versicolor 的总和。事实上,在统计学中,测量存在不同级别:
- 标称数字:这些数字实际上是名称。对它们进行运算没有意义。
- 顺序数字:它们是某物的顺序。进行大于或小于的比较是有意义的,但加法或减法则没有。
- 区间数字:它们是测量值,例如今天的年份,因此减法有意义(例如,您多大了),但零值是任意的,不是特殊的。
- 比例数字:与区间类似,但零有意义,例如长度或时间的测量。在这种情况下,减法和除法都有意义,您可以说某物的长度是两倍。
编码后的标签是标称的。您不希望将其误认为是区间或比例数据,但您的模型不会知道。一种避免此类错误的方法是 **独热编码**,它不将标签转换为整数,而是将标签转换为 **独热向量**。独热向量是整数向量,但只有一个是 1,其余都是零。在这种情况下,您将标签转换为以下形式:
|
1 2 3 |
Iris-setosa 1 0 0 Iris-versicolor 0 1 0 Iris-virginica 0 0 1 |
以上是独热编码的二元矩阵。您无需手动创建它。您可以使用 scikit-learn 类 LabelEncoder 将字符串一致地编码为整数,或使用类 OneHotEncoder 将其编码为独热编码向量。
|
1 2 3 4 5 6 |
from sklearn.preprocessing import OneHotEncoder ohe = OneHotEncoder(handle_unknown='ignore', sparse_output=False).fit(y) print(ohe.categories_) y = ohe.transform(y) print(y) |
由此,您可以看到 OneHotEncoder 学习到了这三个类别。
|
1 |
[array(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'], dtype=object)] |
然后字符串标签被转换为如下的独热向量。
|
1 2 3 4 5 6 7 |
[[1. 0. 0.] [1. 0. 0.] [1. 0. 0.] ... [0. 0. 1.] [0. 0. 1.] [0. 0. 1.]] |
想开始使用PyTorch进行深度学习吗?
立即参加我的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
定义神经网络模型
现在您需要一个模型,它可以接受输入并预测输出,最好是独热向量的形式。神经网络模型的設計沒有科學依據。但要知道一件事——它必須接受一個包含 4 個特徵的向量,並輸出一個包含 3 個值的向量。這 4 個特徵對應於您數據集中的內容。輸出 3 個值是因為我們知道獨熱向量有 3 個元素。任何事物都可能在這之間,稱為“隱藏層”,因為它們既不是輸入也不是輸出。
最簡單的方法是只設置一個隱藏層。讓我們設置一個如下所示的層:
|
1 |
[4 个输入] -> [8 个隐藏神经元] -> [3 个输出] |
这种设计被称为网络拓扑。您应该在输出层使用“softmax”激活。在公式中,它表示:
$$
\sigma(z_i) = \dfrac{e^{z_i}}{\sum_{j=1}^3 e^{z_j}}
$$
这会将值 ($z_1,z_2,z_3$) 标准化,并应用非线性函数,使得所有 3 个输出的总和为 1,并且每个输出都在 0 到 1 的范围内。这使得输出看起来像一个概率向量。在输出中使用 softmax 函数是多类别分类模型的标志。但在 PyTorch 中,如果您将其与合适的损失函数结合,则可以跳过此步骤。
在 PyTorch 中,您可以如下构建这样的模型:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import torch import torch.nn as nn class Multiclass(nn.Module): def __init__(self): super().__init__() self.hidden = nn.Linear(4, 8) self.act = nn.ReLU() self.output = nn.Linear(8, 3) def forward(self, x): x = self.act(self.hidden(x)) x = self.output(x) return x model = Multiclass() |
此模型的输出是三个类别的“权重”。理想情况下,模型输出应该只有一个元素为正无穷大,其余元素为负无穷大,从而与输入特征属于三个类别中的哪一个产生极大的对比和绝对的置信度。在不完美的情况下,一如既往,您期望一个好的模型告诉您其中一个值为正值很大,而其他值为负值很大。或者,如果您使用 sigmoid 函数或 softmax 函数转换这些值,则一个非常接近 1,而其他则非常接近 0。
在这种情况下,输出的损失度量可以简单地测量输出与您从标签转换的独热向量的接近程度。但通常,在多类别分类中,您使用类别交叉熵作为损失度量。公式为:
$$
H(p,q) = -\sum_x p(x) \log q(x)
$$
这意味着,给定真实概率向量 $p(x)$ 和预测概率向量 $q(x)$,相似度是每个元素 $x$ 的 $p(x)$ 与 $\log q(x)$ 乘积的总和。独热向量被视为概率向量 $p(x)$,模型输出为 $q(x)$。由于它是独热向量,只有实际类别具有 $p(x)=1$,而其他类别具有 $p(x)=0$。上述总和本质上是实际类别 $x$ 的 $-\log q(x)$。当 $q(x)=1$ 时,该值为 0,并且当 $q(x)$ 接近 0(softmax 可以产生的最小值)时,$-\log q(x)$ 趋于无穷大。
以下是定义损失度量的方法。PyTorch 中的 CrossEntropyLoss 函数将 softmax 函数与交叉熵计算结合起来,因此您无需在模型输出层进行任何激活函数。您还需要一个优化器,下面选择了 Adam。
|
1 2 3 4 |
import torch.optim as optim loss_fn = nn.<span class="sig-name descname"><span class="pre">CrossEntropyLoss</span></span>() optimizer = optim.Adam(model.parameters(), lr=0.001) |
请注意,在定义优化器时,您还需要告诉它模型的参数,因为这些是优化器将要更新的。
现在您需要运行训练循环来训练您的模型。最低限度,您需要在循环中执行三个步骤:前向传播、反向传播和权重更新。前向传播将输入提供给模型并获取输出。反向传播从基于模型输出的损失度量开始,并将梯度反向传播到输入。权重更新基于用于更新权重的梯度。
可以使用 for 循环实现最小的训练循环。但是,您可以使用 tqdm 创建一个进度条可视化。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import tqdm # 将 pandas DataFrame (X) 和 numpy 数组 (y) 转换为 PyTorch 张量 X = torch.tensor(X.values, dtype=torch.float32) y = torch.tensor(y, dtype=torch.float32) # 训练参数 n_epochs = 200 batch_size = 5 batches_per_epoch = len(X) // batch_size for epoch in range(n_epochs): with tqdm.trange(batches_per_epoch, unit="batch", mininterval=0) as bar: bar.set_description(f"Epoch {epoch}") for i in bar: # 获取一个批次 start = i * batch_size X_batch = X[start:start+batch_size] y_batch = y[start:start+batch_size] # 前向传播 y_pred = model(X_batch) loss = loss_fn(y_pred, y_batch) # 反向传播 optimizer.zero_grad() loss.backward() # 更新权重 optimizer.step() |
模型基准测试
模型的目标从来不是匹配数据集本身。您想要构建机器学习模型的原因是为将要遇到的、尚未见过的数据做准备。您如何知道模型可以做到这一点?您需要一个测试集。它是一个与训练集结构相同但分开的数据集。所以它就像训练过程中未见过的数据,您可以将其作为基准。这种评估模型的技术称为 **交叉验证**。
通常,您不会添加测试集,而是将获得的数据集拆分为训练集和测试集。然后,您在最后使用测试集来评估模型。这样的基准测试还有另一个目的:您不希望模型过拟合。这意味着模型过度学习了训练集,未能泛化。如果发生这种情况,您会发现模型在测试集上的结果不佳。
使用 scikit-learn 可以轻松地将数据拆分为训练集和测试集。从加载数据到独热编码和拆分的流程如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.preprocessing import OneHotEncoder # 读取数据并应用独热编码 data = pd.read_csv("iris.csv", header=None) X = data.iloc[:, 0:4] y = data.iloc[:, 4:] ohe = OneHotEncoder(handle_unknown='ignore', sparse_output=False).fit(y) y = ohe.transform(y) # 将 pandas DataFrame (X) 和 numpy 数组 (y) 转换为 PyTorch 张量 X = torch.tensor(X.values, dtype=torch.float32) y = torch.tensor(y, dtype=torch.float32) # 划分 X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, shuffle=True) |
参数 train_size=0.7 和 shuffle=True 意味着随机选择数据集中 70% 的样本作为训练集,其余的作为测试集。
完成此操作后,您需要修改训练循环,使其在训练中使用训练集,并在每个 epoch 结束时使用测试集进行基准测试。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
n_epochs = 200 batch_size = 5 batches_per_epoch = len(X_train) // batch_size for epoch in range(n_epochs): with tqdm.trange(batches_per_epoch, unit="batch", mininterval=0) as bar: bar.set_description(f"Epoch {epoch}") for i in bar: # 获取一个批次 start = i * batch_size X_batch = X_train[start:start+batch_size] y_batch = y_train[start:start+batch_size] # 前向传播 y_pred = model(X_batch) loss = loss_fn(y_pred, y_batch) # 反向传播 optimizer.zero_grad() loss.backward() # 更新权重 optimizer.step() y_pred = model(X_test) ce = loss_fn(y_pred, y_test) acc = (torch.argmax(y_pred, 1) == torch.argmax(y_test, 1)).float().mean() print(f"Epoch {epoch} validation: Cross-entropy={float(ce)}, Accuracy={float(acc)}") |
您为训练循环添加了更多行,但这是有原因的。当您在训练集和测试集之间切换时,最好在训练模式和评估模式之间切换模型。在这个特定的模型中,没有什么变化。但对于其他模型,它会影响模型的行为。
您将指标收集在 Python 列表中。您需要小心将 PyTorch 张量(即使它是标量值)转换为 Python 浮点数。此转换的目的是创建一个数字的副本,以便 PyTorch 不会无意中修改它(例如,通过优化器)。
每个 epoch 之后,您会根据测试集计算准确率,并且在准确率较高时会保存模型的权重。然而,当您取出模型权重时,您应该进行深拷贝;否则,当模型在下一个 epoch 中更改其权重时,您就会丢失它们。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
import copy 最后,您可以使用 matplotlib 绘制每个 epoch 的损失和准确率,如下所示: import numpy as np n_epochs = 200 batch_size = 5 batches_per_epoch = len(X_train) // batch_size import tqdm best_acc = - np.inf # 初始化为负无穷大 best_weights = None train_loss_hist = [] train_acc_hist = [] test_loss_hist = [] for epoch in range(n_epochs): test_acc_hist = [] epoch_loss = [] epoch_acc = [] model.train() with tqdm.trange(batches_per_epoch, unit="batch", mininterval=0) as bar: bar.set_description(f"Epoch {epoch}") for i in bar: # 获取一个批次 start = i * batch_size X_batch = X_train[start:start+batch_size] y_batch = y_train[start:start+batch_size] # 前向传播 y_pred = model(X_batch) loss = loss_fn(y_pred, y_batch) # 反向传播 optimizer.zero_grad() loss.backward() # 更新权重 optimizer.step() # 将模型设置为训练模式,并遍历每个批次 # 计算并存储指标 acc = (torch.argmax(y_pred, 1) == torch.argmax(y_batch, 1)).float().mean() epoch_loss.append(float(loss)) bar.set_postfix( epoch_acc.append(float(acc)) loss=float(loss), ) acc=float(acc) model.eval() y_pred = model(X_test) ce = loss_fn(y_pred, y_test) acc = (torch.argmax(y_pred, 1) == torch.argmax(y_test, 1)).float().mean() # 将模型设置为评估模式,并运行测试集 ce = float(ce) acc = float(acc) train_loss_hist.append(np.mean(epoch_loss)) train_acc_hist.append(np.mean(epoch_acc)) test_loss_hist.append(ce) test_acc_hist.append(acc) if acc > best_acc: best_acc = acc best_weights = copy.deepcopy(model.state_dict()) print(f"Epoch {epoch} validation: Cross-entropy={ce}, Accuracy={acc}") |
运行它时,您会看到类似这样的内容,其中显示了每个 epoch 的准确率和交叉熵损失:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Epoch 0: 100%|█████████████████████| 21/21 [00:00<00:00, 850.82batch/s, acc=0.4, loss=1.23] Epoch 0 validation: Cross-entropy=1.10, Accuracy=60.0% Epoch 1: 100%|████████████████████| 21/21 [00:00<00:00, 3155.53batch/s, acc=0.4, loss=1.24] Epoch 1 validation: Cross-entropy=1.08, Accuracy=57.8% Epoch 2: 100%|████████████████████| 21/21 [00:00<00:00, 3489.58batch/s, acc=0.4, loss=1.24] Epoch 2 validation: Cross-entropy=1.07, Accuracy=60.0% Epoch 3: 100%|████████████████████| 21/21 [00:00<00:00, 3312.79batch/s, acc=0.4, loss=1.22] Epoch 3 validation: Cross-entropy=1.06, Accuracy=62.2% ... Epoch 197: 100%|███████████████████| 21/21 [00:00<00:00, 3529.57batch/s, acc=1, loss=0.563] Epoch 197 validation: Cross-entropy=0.61, Accuracy=97.8% Epoch 198: 100%|███████████████████| 21/21 [00:00<00:00, 3479.10batch/s, acc=1, loss=0.563] Epoch 198 validation: Cross-entropy=0.61, Accuracy=97.8% Epoch 199: 100%|███████████████████| 21/21 [00:00<00:00, 3337.52batch/s, acc=1, loss=0.563] Epoch 199 validation: Cross-entropy=0.61, Accuracy=97.8% |
您为训练循环添加了更多行,但这是有原因的。当您在训练集和测试集之间切换时,最好在训练模式和评估模式之间切换模型。在这个特定的模型中,没有什么变化。但对于其他模型,它会影响模型的行为。
您将指标收集在 Python 列表中。您需要小心将 PyTorch 张量(即使它是标量值)转换为 Python 浮点数。此转换的目的是创建一个数字的副本,以便 PyTorch 不会无意中修改它(例如,通过优化器)。
每个 epoch 之后,您会根据测试集计算准确率,并且在准确率较高时会保存模型的权重。然而,当您取出模型权重时,您应该进行深拷贝;否则,当模型在下一个 epoch 中更改其权重时,您就会丢失它们。
最后,您可以使用 matplotlib 绘制每个 epoch 的损失和准确率,如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import matplotlib.pyplot as plt plt.plot(train_loss_hist, label="train") plt.plot(test_loss_hist, label="test") plt.xlabel("epochs") plt.ylabel("交叉熵") plt.legend() plt.show() plt.plot(train_acc_hist, label="train") plt.plot(test_acc_hist, label="test") plt.xlabel("epochs") plt.ylabel("准确率") plt.legend() plt.show() |
典型结果如下
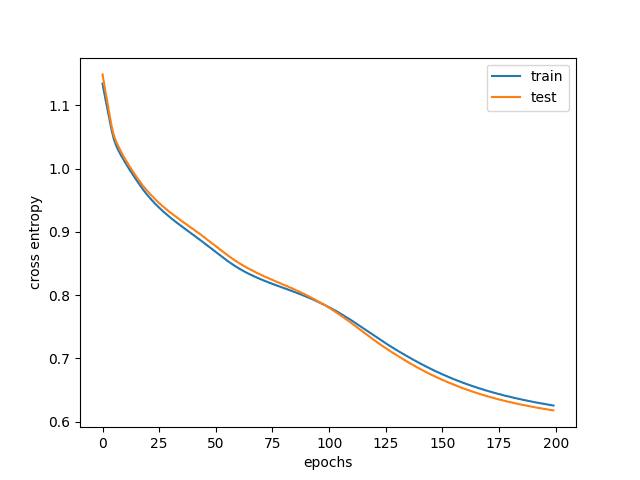
训练和验证损失
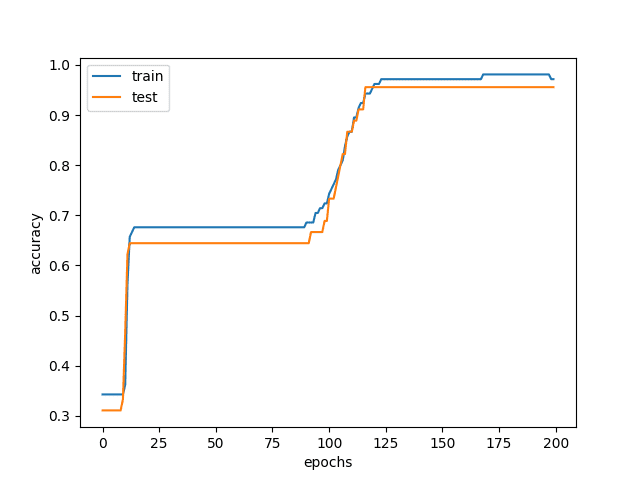
训练和验证准确率
从图中可以看出,一开始,训练和测试的准确率都很低。这是因为您的模型欠拟合,表现非常糟糕。随着您继续训练模型,准确率会提高,交叉熵损失会降低。但在某个点,训练准确率会高于测试准确率,事实上,即使训练准确率有所提高,测试准确率也会停滞不前甚至下降。这就是模型过拟合的时候,您不希望使用这样的模型。这就是为什么您需要跟踪测试准确率,并根据测试集将模型权重恢复到最佳结果。
完整示例
把所有东西放在一起,下面是完整的代码。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 |
import copy import matplotlib.pyplot as plt import numpy as np import pandas as pd import torch import torch.nn as nn import torch.optim as optim 最后,您可以使用 matplotlib 绘制每个 epoch 的损失和准确率,如下所示: from sklearn.model_selection import train_test_split from sklearn.preprocessing import OneHotEncoder # 读取数据并应用独热编码 data = pd.read_csv("iris.csv", header=None) X = data.iloc[:, 0:4] y = data.iloc[:, 4:] ohe = OneHotEncoder(handle_unknown='ignore', sparse_output=False).fit(y) y = ohe.transform(y) # 将 pandas DataFrame (X) 和 numpy 数组 (y) 转换为 PyTorch 张量 X = torch.tensor(X.values, dtype=torch.float32) y = torch.tensor(y, dtype=torch.float32) # 划分 X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, shuffle=True) class Multiclass(nn.Module): def __init__(self): super().__init__() self.hidden = nn.Linear(4, 8) self.act = nn.ReLU() self.output = nn.Linear(8, 3) def forward(self, x): x = self.act(self.hidden(x)) x = self.output(x) return x # 损失指标和优化器 model = Multiclass() loss_fn = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 准备模型和训练参数 n_epochs = 200 batch_size = 5 batches_per_epoch = len(X_train) // batch_size import tqdm best_acc = - np.inf # 初始化为负无穷大 best_weights = None train_loss_hist = [] train_acc_hist = [] test_loss_hist = [] # 训练循环 for epoch in range(n_epochs): test_acc_hist = [] epoch_loss = [] epoch_acc = [] model.train() with tqdm.trange(batches_per_epoch, unit="batch", mininterval=0) as bar: bar.set_description(f"Epoch {epoch}") for i in bar: # 获取一个批次 start = i * batch_size X_batch = X_train[start:start+batch_size] y_batch = y_train[start:start+batch_size] # 前向传播 y_pred = model(X_batch) loss = loss_fn(y_pred, y_batch) # 反向传播 optimizer.zero_grad() loss.backward() # 更新权重 optimizer.step() # 将模型设置为训练模式,并遍历每个批次 # 计算并存储指标 acc = (torch.argmax(y_pred, 1) == torch.argmax(y_batch, 1)).float().mean() epoch_loss.append(float(loss)) bar.set_postfix( epoch_acc.append(float(acc)) loss=float(loss), ) acc=float(acc) model.eval() y_pred = model(X_test) ce = loss_fn(y_pred, y_test) acc = (torch.argmax(y_pred, 1) == torch.argmax(y_test, 1)).float().mean() # 将模型设置为评估模式,并运行测试集 ce = float(ce) acc = float(acc) train_loss_hist.append(np.mean(epoch_loss)) train_acc_hist.append(np.mean(epoch_acc)) test_loss_hist.append(ce) test_acc_hist.append(acc) if acc > best_acc: best_acc = acc print(f"Epoch {epoch} validation: Cross-entropy={ce:.2f}, Accuracy={acc*100:.1f}%") # 恢复最佳模型 print(f"Epoch {epoch} validation: Cross-entropy={ce}, Accuracy={acc}") # 绘制损失和准确率图 plt.plot(train_loss_hist, label="train") plt.plot(test_loss_hist, label="test") plt.xlabel("epochs") plt.ylabel("交叉熵") plt.legend() plt.show() plt.plot(train_acc_hist, label="train") plt.plot(test_acc_hist, label="test") plt.xlabel("epochs") plt.ylabel("准确率") plt.legend() plt.show() |
总结
在这篇文章中,您学习了如何使用 PyTorch 开发和评估多类别分类神经网络。
通过完成本教程,您学习了
- 如何加载数据并将其转换为 PyTorch 张量
- 如何通过独热编码准备多类别分类数据以进行建模
- 如何使用 PyTorch 定义用于多类别分类的深度学习模型
- 如何衡量模型输出与多类别分类预期结果的相似度
- 如何运行 PyTorch 模型的训练循环并收集评估指标
开始使用PyTorch进行深度学习!

学习如何构建深度学习模型
...使用新发布的PyTorch 2.0库
在我的新电子书中探索如何实现
使用 PyTorch进行深度学习
它提供了包含数百个可用代码的自学教程,让你从新手变成专家。它将使你掌握:
张量操作、训练、评估、超参数优化等等...






你好 Adrian
教程很棒。谢谢。
在这一行
ohe = OneHotEncoder(handle_unknown=’ignore’, sparse_output=False).fit(y)
‘sparse_output’ 参数对我不起作用。我不得不将其更改为 ‘sparse’
祝好
很高兴您喜欢。您之所以看到问题,是因为您使用的 scikit-learn 版本。在 1.2 版本中,该参数为
sparse_output,而在早期版本中则为sparse。Alberto,不客气!感谢您的反馈!
如何用训练好的模型进行预测?
你好 Juan…以下内容可能对您有所帮助
https://machinelearning.org.cn/how-to-make-classification-and-regression-predictions-for-deep-learning-models-in-keras/
谢谢。我是 PyTorch 新手,您的教程很容易理解。
不客气 Anthony!我们很高兴知道您在我们的教程中取得了进步。
在 Colab 中运行代码时(到目前为止前面的所有代码都可以正常运行),我遇到了以下错误:
File “”, line 3
loss_fn = nn.CrossEntropyLoss()
^
SyntaxError: invalid syntax ^
你好 SFLam…您是复制代码还是手动输入的?
潜在的错误可能在于此处
import torch.optim as optim
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
你好,在 VS Code 中运行代码时,我遇到了以下错误:
Epoch 0: : 0batch [00:00, ?batch/s]
回溯(最近一次调用)
88 行 ce = loss_fn(y_pred, y_test)
^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: 期望 0D 或 1D 目标张量,不支持多目标
你好 kostas…您是复制代码还是手动输入的?另外,您在 Google Colab 中尝试过您的代码吗?