PyTorch 库用于深度学习。深度学习模型的一些应用是解决回归或分类问题。
在本帖中,您将了解如何使用 PyTorch 为回归问题开发和评估神经网络模型。
完成这篇文章后,您将了解:
- 如何从 scikit-learn 加载数据并适配 PyTorch 模型
- 如何使用 PyTorch 为回归问题创建神经网络
- 如何通过数据预处理技术提高模型性能
通过我的《用PyTorch进行深度学习》一书来启动你的项目。它提供了包含可用代码的自学教程。
让我们开始吧。

在 PyTorch 中构建回归模型 由 Sam Deng 拍摄。部分权利保留。
数据集描述
在本教程中,您将使用 加州房价数据集。
这是一个描述加州各地区房屋中值的数据集。每个数据样本是一个人口普查街区组。目标变量是 1990 年的房屋中值(以 10 万美元为单位),有 8 个输入特征,每个特征描述了房屋的某些信息。它们分别是:
- MedInc:街区组的收入中位数
- HouseAge:街区组的房屋年龄中位数
- AveRooms:户均房间数
- AveBedrms:户均卧室数
- Population:街区组人口
- AveOccup:户均人口
- Latitude:街区组中心点纬度
- Longitude:街区组中心点经度
此数据之所以特殊,是因为输入数据的尺度差异很大。例如,房屋的房间数通常很小,而街区组的人口通常很大。此外,大多数特征应该是正数,但经度必须是负数(因为这涉及到加州)。处理如此多样的数据对某些机器学习模型来说是一个挑战。
您可以从 scikit-learn 获取该数据集,而 scikit-learn 又从互联网实时下载。
|
1 2 3 4 5 6 |
from sklearn.datasets import fetch_california_housing data = fetch_california_housing() print(data.feature_names) X, y = data.data, data.target |
构建模型和训练
这是一个回归问题。与分类问题不同,输出变量是一个连续值。对于神经网络,通常在输出层使用线性激活(即没有激活),这样输出范围理论上可以是负无穷到正无穷之间的任何值。
同样,对于回归问题,您永远不应该期望模型能够完美地预测值。因此,您应该关心预测值与实际值有多接近。您可以使用均方误差 (MSE) 或平均绝对误差 (MAE) 作为损失度量。但您也可能对均方根误差 (RMSE) 感兴趣,因为它是与输出变量相同单位的度量。
让我们尝试神经网络的传统设计,即金字塔结构。金字塔结构是指每层的神经元数量随着网络向输出的进展而减少。输入特征的数量是固定的,但您在第一层隐藏层设置大量神经元,并在后续层逐渐减少神经元数量。因为这个数据集中只有一个目标,所以最后一层应该只输出一个值。
一种设计如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import torch.nn as nn # 定义模型 model = nn.Sequential( nn.Linear(8, 24), nn.ReLU(), nn.Linear(24, 12), nn.ReLU(), nn.Linear(12, 6), nn.ReLU(), nn.Linear(6, 1) ) |
要训练这个网络,您需要定义一个损失函数。MSE 是一个不错的选择。您还需要一个优化器,例如 Adam。
|
1 2 3 4 5 6 |
import torch.nn as nn import torch.optim as optim # 损失函数和优化器 loss_fn = nn.MSELoss() # 均方误差 optimizer = optim.Adam(model.parameters(), lr=0.0001) |
要训练此模型,您可以使用常规的训练循环。为了获得评估分数,让您确信模型有效,您需要将数据分成训练集和测试集。您可能还想通过跟踪测试集 MSE 来避免过拟合。以下是带有训练-测试拆分的训练循环:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
import copy import numpy as np import torch 最后,您可以使用 matplotlib 绘制每个 epoch 的损失和准确率,如下所示: from sklearn.model_selection import train_test_split # 数据集的训练-测试拆分 X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, shuffle=True) X_train = torch.tensor(X_train, dtype=torch.float32) y_train = torch.tensor(y_train, dtype=torch.float32).reshape(-1, 1) X_test = torch.tensor(X_test, dtype=torch.float32) y_test = torch.tensor(y_test, dtype=torch.float32).reshape(-1, 1) # 训练参数 n_epochs = 100 # 运行的 epoch 数 batch_size = 10 # 每个批次的大小 batch_start = torch.arange(0, len(X_train), batch_size) # 保存最佳模型 best_mse = np.inf # 初始化为无穷大 best_acc = - np.inf # 初始化为负无穷大 history = [] # 训练循环 for epoch in range(n_epochs): model.train() with tqdm.tqdm(batch_start, unit="batch", mininterval=0, disable=True) as bar: bar.set_description(f"Epoch {epoch}") for start in bar: # 获取一个批次 X_batch = X_train[start:start+batch_size] y_batch = y_train[start:start+batch_size] # 前向传播 y_pred = model(X_batch) loss = loss_fn(y_pred, y_batch) # 反向传播 optimizer.zero_grad() loss.backward() # 更新权重 optimizer.step() # 打印进度 bar.set_postfix(mse=float(loss)) # 在每个 epoch 结束时评估准确率 model.eval() y_pred = model(X_test) mse = loss_fn(y_pred, y_test) mse = float(mse) history.append(mse) if mse < best_mse: best_mse = mse best_weights = copy.deepcopy(model.state_dict()) # 恢复模型并返回最佳准确率 print(f"Epoch {epoch} validation: Cross-entropy={ce}, Accuracy={acc}") |
在训练循环中,使用 tqdm 设置进度条,并在每次迭代中计算并报告 MSE。您可以通过将上面的 tqdm 参数 disable 设置为 False 来查看 MSE 的变化。
请注意,在训练循环中,每个 epoch 都使用训练集运行前向和后向步骤几次以优化模型权重,并在 epoch 结束时使用测试集评估模型。存储在列表 history 中的是来自测试集的 MSE。它也是评估模型的指标,最佳模型存储在变量 best_weights 中。
运行此代码后,您将获得恢复的最佳模型,并且最佳 MSE 存储在变量 best_mse 中。请注意,均方误差是预测值与实际值之差的平方的平均值。其平方根,即 RMSE,可以视为平均差值,在数值上更有用。
下面,您可以显示 MSE 和 RMSE,并绘制 MSE 的历史记录。它应该随着 epoch 的增加而下降。
|
1 2 3 4 |
print("MSE: %.2f" % best_mse) print("RMSE: %.2f" % np.sqrt(best_mse)) plt.plot(history) plt.show() |
该模型产生了
|
1 2 |
MSE: 0.47 RMSE: 0.68 |
MSE 图看起来像这样。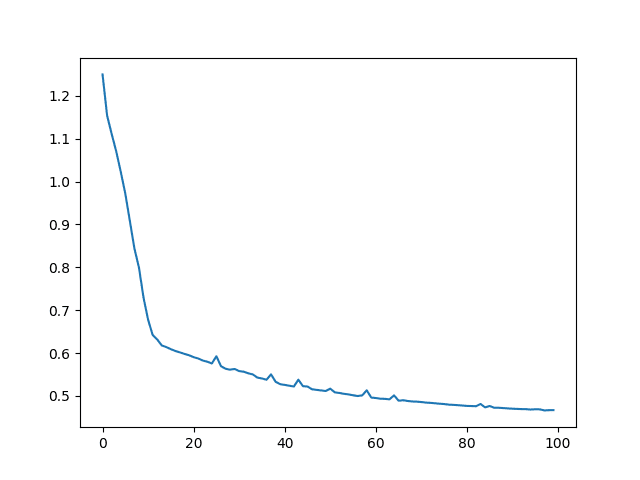
将所有内容放在一起,完整的代码如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 |
import copy import matplotlib.pyplot as plt import numpy as np import pandas as pd import torch import torch.nn as nn import torch.optim as optim 最后,您可以使用 matplotlib 绘制每个 epoch 的损失和准确率,如下所示: from sklearn.model_selection import train_test_split from sklearn.datasets import fetch_california_housing # 读取数据 data = fetch_california_housing() X, y = data.data, data.target # 用于模型评估的训练-测试拆分 X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, shuffle=True) # 转换为 2D PyTorch 张量 X_train = torch.tensor(X_train, dtype=torch.float32) y_train = torch.tensor(y_train, dtype=torch.float32).reshape(-1, 1) X_test = torch.tensor(X_test, dtype=torch.float32) y_test = torch.tensor(y_test, dtype=torch.float32).reshape(-1, 1) # 定义模型 model = nn.Sequential( nn.Linear(8, 24), nn.ReLU(), nn.Linear(24, 12), nn.ReLU(), nn.Linear(12, 6), nn.ReLU(), nn.Linear(6, 1) ) # 损失函数和优化器 loss_fn = nn.MSELoss() # 均方误差 optimizer = optim.Adam(model.parameters(), lr=0.0001) n_epochs = 100 # 运行的 epoch 数 batch_size = 10 # 每个批次的大小 batch_start = torch.arange(0, len(X_train), batch_size) # 保存最佳模型 best_mse = np.inf # 初始化为无穷大 best_acc = - np.inf # 初始化为负无穷大 history = [] for epoch in range(n_epochs): model.train() with tqdm.tqdm(batch_start, unit="batch", mininterval=0, disable=True) as bar: bar.set_description(f"Epoch {epoch}") for start in bar: # 获取一个批次 X_batch = X_train[start:start+batch_size] y_batch = y_train[start:start+batch_size] # 前向传播 y_pred = model(X_batch) loss = loss_fn(y_pred, y_batch) # 反向传播 optimizer.zero_grad() loss.backward() # 更新权重 optimizer.step() # 打印进度 bar.set_postfix(mse=float(loss)) # 在每个 epoch 结束时评估准确率 model.eval() y_pred = model(X_test) mse = loss_fn(y_pred, y_test) mse = float(mse) history.append(mse) if mse < best_mse: best_mse = mse best_weights = copy.deepcopy(model.state_dict()) # 恢复模型并返回最佳准确率 print(f"Epoch {epoch} validation: Cross-entropy={ce}, Accuracy={acc}") print("MSE: %.2f" % best_mse) print("RMSE: %.2f" % np.sqrt(best_mse)) plt.plot(history) plt.show() |
想开始使用PyTorch进行深度学习吗?
立即参加我的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
通过预处理改进模型
在上文中,您看到 RMSE 为 0.68。实际上,通过在训练前对数据进行处理,可以轻松地改进 RMSE。此数据集的问题在于特征的多样性:有些范围很窄,有些范围很宽。有些是小的正数,有些是非常负的数。这确实对大多数机器学习模型不太友好。
一种改进方法是应用标准化器。它是将每个特征转换为其标准分数。换句话说,对于每个特征 $x$,您将其替换为:
$$
z = \frac{x – \bar{x}}{\sigma_x}
$$
其中 $\bar{x}$ 是 $x$ 的均值,$\sigma_x$ 是标准差。这样,每个转换后的特征都围绕 0 中心化,并且在一个较窄的范围内,大约 70% 的样本介于 -1 到 +1 之间。这可以帮助机器学习模型收敛。
您可以应用 scikit-learn 的标准化器。以下是如何修改上述代码的数据预处理部分:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
import torch from sklearn.model_selection import train_test_split from sklearn.datasets import fetch_california_housing from sklearn.preprocessing import StandardScaler # 读取数据 data = fetch_california_housing() X, y = data.data, data.target # 用于模型评估的训练-测试拆分 X_train_raw, X_test_raw, y_train, y_test = train_test_split(X, y, train_size=0.7, shuffle=True) # 标准化数据 scaler = StandardScaler() scaler.fit(X_train_raw) X_train = scaler.transform(X_train_raw) X_test = scaler.transform(X_test_raw) # 转换为 2D PyTorch 张量 X_train = torch.tensor(X_train, dtype=torch.float32) y_train = torch.tensor(y_train, dtype=torch.float32).reshape(-1, 1) X_test = torch.tensor(X_test, dtype=torch.float32) y_test = torch.tensor(y_test, dtype=torch.float32).reshape(-1, 1) |
请注意,标准化器是在训练-测试拆分后应用的。上面的 StandardScaler 是在训练集上拟合的,但应用于训练集和测试集。您不能将标准化器应用于所有数据,因为不应该向模型透露测试集中的任何信息。否则,您将引入数据泄露。
除此之外,几乎没有什么需要改变:您仍然有 8 个特征(只是值不同)。您仍然使用相同的训练循环。如果您使用缩放后的数据训练模型,您应该会看到 RMSE 有所提高,例如:
|
1 2 |
MSE: 0.29 RMSE: 0.54 |
虽然 MSE 历史记录呈类似的下降趋势,但 Y 轴显示缩放后确实有所改善: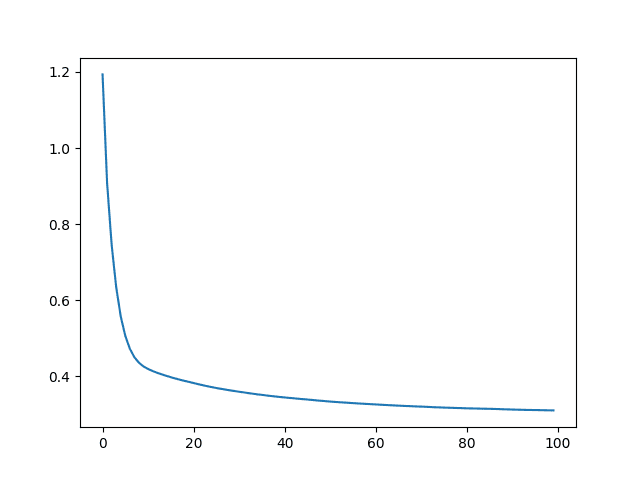
然而,您需要在最后要小心:当您使用训练好的模型并将其应用于新数据时,您应该在将数据输入模型之前对输入数据应用缩放器。也就是说,推理应如下进行:
|
1 2 3 4 5 6 7 8 9 |
model.eval() with torch.no_grad(): # 使用原始测试集中的 5 个样本进行推理测试 for i in range(5): X_sample = X_test_raw[i: i+1] X_sample = scaler.transform(X_sample) X_sample = torch.tensor(X_sample, dtype=torch.float32) y_pred = model(X_sample) print(f"{X_test_raw[i]} -> {y_pred[0].numpy()} (expected {y_test[i].numpy()})") |
以下是完整的代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 |
import copy import matplotlib.pyplot as plt import numpy as np import pandas as pd import torch import torch.nn as nn import torch.optim as optim 最后,您可以使用 matplotlib 绘制每个 epoch 的损失和准确率,如下所示: from sklearn.model_selection import train_test_split from sklearn.datasets import fetch_california_housing from sklearn.preprocessing import StandardScaler # 读取数据 data = fetch_california_housing() X, y = data.data, data.target # 用于模型评估的训练-测试拆分 X_train_raw, X_test_raw, y_train, y_test = train_test_split(X, y, train_size=0.7, shuffle=True) # 标准化数据 scaler = StandardScaler() scaler.fit(X_train_raw) X_train = scaler.transform(X_train_raw) X_test = scaler.transform(X_test_raw) # 转换为 2D PyTorch 张量 X_train = torch.tensor(X_train, dtype=torch.float32) y_train = torch.tensor(y_train, dtype=torch.float32).reshape(-1, 1) X_test = torch.tensor(X_test, dtype=torch.float32) y_test = torch.tensor(y_test, dtype=torch.float32).reshape(-1, 1) # 定义模型 model = nn.Sequential( nn.Linear(8, 24), nn.ReLU(), nn.Linear(24, 12), nn.ReLU(), nn.Linear(12, 6), nn.ReLU(), nn.Linear(6, 1) ) # 损失函数和优化器 loss_fn = nn.MSELoss() # 均方误差 optimizer = optim.Adam(model.parameters(), lr=0.0001) n_epochs = 100 # 运行的 epoch 数 batch_size = 10 # 每个批次的大小 batch_start = torch.arange(0, len(X_train), batch_size) # 保存最佳模型 best_mse = np.inf # 初始化为无穷大 best_acc = - np.inf # 初始化为负无穷大 history = [] for epoch in range(n_epochs): model.train() with tqdm.tqdm(batch_start, unit="batch", mininterval=0, disable=True) as bar: bar.set_description(f"Epoch {epoch}") for start in bar: # 获取一个批次 X_batch = X_train[start:start+batch_size] y_batch = y_train[start:start+batch_size] # 前向传播 y_pred = model(X_batch) loss = loss_fn(y_pred, y_batch) # 反向传播 optimizer.zero_grad() loss.backward() # 更新权重 optimizer.step() # 打印进度 bar.set_postfix(mse=float(loss)) # 在每个 epoch 结束时评估准确率 model.eval() y_pred = model(X_test) mse = loss_fn(y_pred, y_test) mse = float(mse) history.append(mse) if mse < best_mse: best_mse = mse best_weights = copy.deepcopy(model.state_dict()) # 恢复模型并返回最佳准确率 print(f"Epoch {epoch} validation: Cross-entropy={ce}, Accuracy={acc}") print("MSE: %.2f" % best_mse) print("RMSE: %.2f" % np.sqrt(best_mse)) plt.plot(history) plt.show() model.eval() with torch.no_grad(): # 测试 5 个样本的推理 for i in range(5): X_sample = X_test_raw[i: i+1] X_sample = scaler.transform(X_sample) X_sample = torch.tensor(X_sample, dtype=torch.float32) y_pred = model(X_sample) print(f"{X_test_raw[i]} -> {y_pred[0].numpy()} (expected {y_test[i].numpy()})") |
当然,模型仍有改进的空间。一种方法是将目标转换为对数尺度,或者等效地,使用平均绝对百分比误差 (MAPE) 作为损失函数。这是因为目标变量是房屋的价值,并且范围很广。对于相同的误差幅度,这对低价值的房屋来说问题更大。修改上述代码以获得更好的预测是您的练习。
总结
在本帖中,您了解了如何使用 PyTorch 构建回归模型。
您学会了如何逐步处理 PyTorch 中的回归问题,具体而言:
- 如何加载和准备数据以在 PyTorch 中使用
- 如何创建神经网络模型并选择回归的损失函数
- 如何通过应用标准化器来提高模型准确性
开始使用PyTorch进行深度学习!

学习如何构建深度学习模型
...使用新发布的PyTorch 2.0库
在我的新电子书中探索如何实现
使用 PyTorch进行深度学习
它提供了包含数百个可用代码的自学教程,让你从新手变成专家。它将使你掌握:
张量操作、训练、评估、超参数优化等等...






关于模型评估
第 92 行和第 935 行分别是:
model.eval()
with torch.no_grad()
# 测试 5 个样本的推理
for i in range(5)
而验证评估不包含代码“with torch.no_grad():”
见第 76 行
model.eval()
为什么在一个评估部分使用 torch.no.grad() 而在另一个部分不使用?
PyTorch 讨论网站指出,“with torch.no_grad():” 代码可用于两者。
嗨 George…没有特定的原因或限制。您应该使这些部分保持一致,并告知我们您的发现。
嗨 James,
这不是程序的运行方式,也不是评估的调用时机。这不会告诉我太多信息。
您需要了解的是 PyTorch 文档的内容,而不是依赖于特定模型如何运行。
在迭代 epoch 时,有没有办法关闭中间输出?谢谢。
你好,James,
我正在使用 PyTorch 为多输入多输出编写回归模型,首先我进行了输入和输出的归一化(转换),但在反归一化阶段,我的代码出现了错误,你能帮我调试一下吗?
TypeError: ‘int’ object is not callable
你好 Dimple…虽然我没有遇到过这个特定的错误,但以下资源可能会帮助您更清楚地了解如何解决它
https://www.freecodecamp.org/news/typeerror-int-object-is-not-callable-how-to-fix-in-python/#:~:text=The%20%E2%80%9Cint%20object%20is%20not%20callable%E2%80%9D%20error%20occurs%20when%20you,while%20performing%20a%20mathematical%20operation.
谢谢,詹姆斯。
您能提供一个关于使用 PyTorch 在 Python 中进行 PINNS 问题的教程吗?如果您能展示如何使用一个或多个多输出神经网络的输出来编写自定义损失函数,我将非常感激。
非常感谢您的所有教程,它们对我帮助很大,您太棒了。
Jorge,不客气!我们非常感谢您的支持和反馈!
嗨 James,
您能澄清一下:重塑 y_train 和 y_test 张量的目的是什么? ( y_test = torch.tensor(y_test, dtype=torch.float32).reshape(-1, 1) )
你好 Nick…以下资源可能对您感兴趣
https://discuss.pytorch.org/t/reshape-tensors-your-preserve-variable-information-structure/140300
谢谢,詹姆斯。
我可能应该说清楚我的问题。我搞不清楚为什么要在那里使用 reshape
y_train = torch.tensor(y_train, dtype=torch.float32).reshape(-1, 1)
y_test = torch.tensor(y_test , dtype=torch.float32).reshape(-1, 1)
将 torch.Size([14447]) 转换为 torch.Size([14447, 1]) 的意义何在?这有什么帮助?
你好 Nick…以下内容可能对您感兴趣
https://dzone.com/articles/reshaping-pytorch-tensors