Transformer 架构于 2017 年推出,通过消除循环神经网络的需要,彻底改变了序列到序列的任务,例如语言翻译。相反,它依赖于自注意力机制来处理输入序列。在本帖中,您将学习如何从头开始构建 Transformer 模型。特别是,您将理解
- 自注意力机制如何处理输入序列
- Transformer 编码器和解码器如何工作
- 如何实现一个完整的 Transformer 翻译系统
让我们开始吧。

构建用于语言翻译的 Transformer 模型
照片来自 Sorasak。部分权利保留。
概述
这篇文章分为六个部分;它们是:
- 为什么 Transformer 优于 Seq2Seq
- 数据准备与分词
- Transformer 模型的设计
- 构建 Transformer 模型
- 因果掩码和填充掩码
- 训练与评估
为什么 Transformer 优于 Seq2Seq
传统的基于循环神经网络的 seq2seq 模型有两个主要局限性
- 顺序处理阻碍了并行化
- 捕捉长期依赖关系的能力有限,因为每当处理一个元素时,隐藏状态都会被覆盖
Transformer 架构在 2017 年的论文“Attention is All You Need”中提出,克服了这些局限性。它可以使用自注意力机制捕捉序列中任何位置之间的依赖关系。它可以并行处理整个序列。Transformer 模型的序列处理能力不依赖于循环连接。
数据准备与分词
在本帖中,您将构建一个用于翻译的 Transformer 模型,因为这是完整 Transformer 的典型用例。
您将使用的数据集是 Anki 的英法翻译数据集,其中包含英法句子对。这与您在之前帖子中使用的相同数据集,并且准备步骤也类似。
法语文本包含重音符号和复杂的动词变位,比简单的单词分割需要更复杂的分词。字节对编码 (BPE) 有效地处理这些子词单元和形态丰富的语言。它也是处理未知词语的好解决方案。
首先,您需要下载数据集并将其读入内存。该数据集是纯文本文件,每行包含一个由制表符分隔的英语和法语句子。以下是如何下载和读取数据集
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import os import unicodedata import zipfile import requests # Download dataset provided by Anki: https://www.manythings.org/anki/ with requests if not os.path.exists("fra-eng.zip"): url = "http://storage.googleapis.com/download.tensorflow.org/data/fra-eng.zip" response = requests.get(url) with open("fra-eng.zip", "wb") as f: f.write(response.content) # Normalize text # each line of the file is in the format "<english>\t<french>" # 我们将文本转换为小写,并对 Unicode (UFKC) 进行规范化 def normalize(line): """规范化一行文本并在制表符处分成两部分""" line = unicodedata.normalize("NFKC", line.strip().lower()) eng, fra = line.split("\t") return eng.lower().strip(), fra.lower().strip() text_pairs = [] with zipfile.ZipFile("fra-eng.zip", "r") as zip_ref: for line in zip_ref.read("fra.txt").decode("utf-8").splitlines(): eng, fra = normalize(line) text_pairs.append((eng, fra)) |
法语句子使用 Unicode 字符,这些字符可以有多种表示形式。我们在处理之前将文本规范化为“NFKC”形式以确保一致的表示。这是一个确保文本“干净”的好习惯,以便模型可以专注于文本的实际内容。
text_pairs 中的翻译对是完整句子的字符串对。您可以使用它们来训练 BPE 分词器,然后使用该分词器对后续句子进行分词。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
import tokenizers if os.path.exists("en_tokenizer.json") and os.path.exists("fr_tokenizer.json"): en_tokenizer = tokenizers.Tokenizer.from_file("en_tokenizer.json") fr_tokenizer = tokenizers.Tokenizer.from_file("fr_tokenizer.json") else: en_tokenizer = tokenizers.Tokenizer(tokenizers.models.BPE()) fr_tokenizer = tokenizers.Tokenizer(tokenizers.models.BPE()) # Configure pre-tokenizer to split on whitespace and punctuation, add space at beginning of the sentence en_tokenizer.pre_tokenizer = tokenizers.pre_tokenizers.ByteLevel(add_prefix_space=True) fr_tokenizer.pre_tokenizer = tokenizers.pre_tokenizers.ByteLevel(add_prefix_space=True) # Configure decoder: So that word boundary symbol "Ġ" will be removed en_tokenizer.decoder = tokenizers.decoders.ByteLevel() fr_tokenizer.decoder = tokenizers.decoders.ByteLevel() # Train BPE for English and French using the same trainer VOCAB_SIZE = 8000 trainer = tokenizers.trainers.BpeTrainer( vocab_size=VOCAB_SIZE, special_tokens=["[start]", "[end]", "[pad]"], show_progress=True ) en_tokenizer.train_from_iterator([x[0] for x in text_pairs], trainer=trainer) fr_tokenizer.train_from_iterator([x[1] for x in text_pairs], trainer=trainer) en_tokenizer.enable_padding(pad_id=en_tokenizer.token_to_id("[pad]"), pad_token="[pad]") fr_tokenizer.enable_padding(pad_id=fr_tokenizer.token_to_id("[pad]"), pad_token="[pad]") # Save the trained tokenizers en_tokenizer.save("en_tokenizer.json", pretty=True) fr_tokenizer.save("fr_tokenizer.json", pretty=True) |
上面的代码使用 Hugging Face 的 tokenizers 库来训练分词器。训练好的分词器会保存为 JSON 文件以供重复使用。在训练分词器时,您添加了三个特殊标记:[start]、[end] 和 [pad]。这些标记用于标记句子的开头和结尾,以及将序列填充到相同的长度。分词器设置为 enable_padding(),因此当您使用分词器处理字符串时,会添加填充标记。您将在后面的部分中看到它们是如何使用的。
下面是如何使用分词器的示例
|
1 2 3 4 5 6 7 |
... encoded = fr_tokenizer.encode("[start] " + fr_sample + " [end]") print(f"Original: {fr_sample}") print(f"Tokens: {encoded.tokens}") print(f"IDs: {encoded.ids}") print(f"Decoded: {fr_tokenizer.decode(encoded.ids)}") |
分词器不仅将文本分割成标记,还提供了一种将标记编码为整数 ID 的方法。这对于 Transformer 模型至关重要,因为模型需要将输入序列作为数字序列进行处理。
Transformer 模型的设计
Transformer 结合了编码器和解码器。编码器包含多层自注意力和前馈网络,而解码器还包含交叉注意力。编码器处理输入序列,解码器生成输出序列,这与 seq2seq 模型的情况相同。然而,Transformer 模型中有许多变体。常见的架构变体包括
- 位置编码:提供位置信息,因为 Transformer 会并行处理序列。有多种策略可以将序列中元素的��置传递给模型。
- 注意力机制:虽然缩放点积注意力是标准方法,但在模型级别存在其实现的变体,例如多头注意力 (MHA)、多查询注意力 (MQA)、分组查询注意力 (GQA) 和多头潜在注意力 (MLA)。这是因为 Transformer 模型中的每个注意力层都包含多个并行运行的注意力“头”。这些是将输入应用于不同头的不同方法。
- 前馈网络:这是一个多层感知器网络,但您可以选择不同的激活函数或层数。在需要处理各种输入的模型较大的情况下,可以使用专家混合网络作为前馈网络的替代方案。
- 层归一化:应在注意力和前馈网络之间应用层归一化或 RMS 归一化。您可以使用带跳跃连接的“预归一化”或“后归一化”。
- 超参数:对于相同的设计,您可以调整隐藏维度的大小、头/层的数量、dropout 率以及模型应支持的最大序列长度来扩展模型。
在本帖中,我们将使用以下内容
- 位置编码:旋转位置编码,最大序列长度为 768
- 注意力机制:分组查询注意力,具有 8 个查询头和 4 个键值头
- 前馈网络:两层 SwiGLU,隐藏层维度为 512
- 层归一化:RMS Norm,预归一化
- 隐藏维度:128
- 编码器和解码器层数:4
- Dropout 率:0.1
要构建的 Transformer 模型
我们将构建的模型如下图所示
构建 Transformer 模型
各种位置编码方法及其实现已在之前的帖子中介绍。对于 RoPE,这是 PyTorch 的实现
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
def rotate_half(x): x1, x2 = x.chunk(2, dim=-1) return torch.cat((-x2, x1), dim=-1) def apply_rotary_pos_emb(x, cos, sin): return (x * cos) + (rotate_half(x) * sin) class RotaryPositionalEncoding(nn.Module): def __init__(self, dim, max_seq_len=1024): super().__init__() N = 10000 inv_freq = 1. / (N ** (torch.arange(0, dim, 2).float() / dim)) position = torch.arange(max_seq_len).float() inv_freq = torch.cat((inv_freq, inv_freq), dim=-1) sinusoid_inp = torch.outer(position, inv_freq) self.register_buffer("cos", sinusoid_inp.cos()) self.register_buffer("sin", sinusoid_inp.sin()) def forward(self, x, seq_len=None): if seq_len is None: seq_len = x.size(1) cos = self.cos[:seq_len].view(1, seq_len, 1, -1) sin = self.sin[:seq_len].view(1, seq_len, 1, -1) return apply_rotary_pos_emb(x, cos, sin) |
旋转位置编码通过将向量的每两个元素乘以一个 2x2 的旋转矩阵来改变输入向量。
$$
\mathbf{\hat{x}}_m = \mathbf{R}_m\mathbf{x}_m = \begin{bmatrix}
\cos(m\theta_i) & -\sin(m\theta_i) \\
\sin(m\theta_i) & \cos(m\theta_i)
\end{bmatrix} \mathbf{x}_m
$$
其中 $\mathbf{x}_m$ 代表位置 $m$ 上向量的元素对 $(i, d/2+i)$。实际使用的矩阵取决于向量在序列中的位置 $m$。
RoPE 与原始 Transformer 的正弦位置编码不同之处在于,它是在注意力子层内部应用的,而不是在外部。
您将使用的注意力是分组查询注意力 (GQA)。PyTorch 支持 GQA,但在注意力子层中,您应该实现查询、键和值的投影。GQA 的实现已在之前的帖子中介绍,但以下是一个扩展版本,允许您不仅在自注意力中,还在交叉注意力中使用它。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
class GQA(nn.Module): def __init__(self, hidden_dim, num_heads, num_kv_heads=None, dropout=0.1): super().__init__() self.num_heads = num_heads self.num_kv_heads = num_kv_heads or num_heads self.head_dim = hidden_dim // num_heads self.num_groups = num_heads // num_kv_heads self.dropout = dropout self.q_proj = nn.Linear(hidden_dim, hidden_dim) self.k_proj = nn.Linear(hidden_dim, hidden_dim) self.v_proj = nn.Linear(hidden_dim, hidden_dim) self.out_proj = nn.Linear(hidden_dim, hidden_dim) def forward(self, q, k, v, mask=None, rope=None): q_batch_size, q_seq_len, hidden_dim = q.shape k_batch_size, k_seq_len, hidden_dim = k.shape v_batch_size, v_seq_len, hidden_dim = v.shape # 投影 q = self.q_proj(q).view(q_batch_size, q_seq_len, -1, self.head_dim).transpose(1, 2) k = self.k_proj(k).view(k_batch_size, k_seq_len, -1, self.head_dim).transpose(1, 2) v = self.v_proj(v).view(v_batch_size, v_seq_len, -1, self.head_dim).transpose(1, 2) # 应用旋转位置编码 if rope: q = rope(q) k = rope(k) # 计算分组查询注意力 q = q.contiguous() k = k.contiguous() v = v.contiguous() output = F.scaled_dot_product_attention(q, k, v, attn_mask=mask, dropout_p=self.dropout, enable_gqa=True) output = output.transpose(1, 2).reshape(q_batch_size, q_seq_len, hidden_dim).contiguous() output = self.out_proj(output) return output |
请注意,在GQA类的forward()方法中,您可以在rope参数中指定位置编码模块。这使得位置编码成为可选的。在PyTorch中,为了优化注意力计算,输入张量应该是内存中的连续块。如果张量不是连续的,则使用q = q.contiguous()这行代码来对其进行重塑。
您将使用的前馈网络是双层SwiGLU。SwiGLU激活函数很独特,因为PyTorch不支持它,但可以通过SiLU激活来实现。下面是来自之前一篇帖子的SwiGLU前馈网络实现。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
class SwiGLU(nn.Module): def __init__(self, hidden_dim, intermediate_dim): super().__init__() self.gate = nn.Linear(hidden_dim, intermediate_dim) self.up = nn.Linear(hidden_dim, intermediate_dim) self.down = nn.Linear(intermediate_dim, hidden_dim) self.act = nn.SiLU() def forward(self, x): x = self.act(self.gate(x)) * self.up(x) x = self.down(x) return x |
这样,您就可以构建编码器和解码器层了。编码器层更简单,因为它由一个自注意力层和一个前馈网络组成。但是,您仍然需要实现跳跃连接和使用RMS范数的预归一化。下面是编码器层的实现。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
class EncoderLayer(nn.Module): def __init__(self, hidden_dim, num_heads, num_kv_heads=None, dropout=0.1): super().__init__() self.self_attn = GQA(hidden_dim, num_heads, num_kv_heads, dropout) self.mlp = SwiGLU(hidden_dim, 4 * hidden_dim) self.norm1 = nn.RMSNorm(hidden_dim) self.norm2 = nn.RMSNorm(hidden_dim) def forward(self, x, mask=None, rope=None): # 自注意力子层 out = x out = self.norm1(x) out = self.self_attn(out, out, out, mask, rope) x = out + x # MLP子层 out = self.norm2(x) out = self.mlp(out) return out + x |
前馈网络已实现为之前定义的SwiGLU模块。您可以看到中间维度被定义为隐藏维度大小的4倍。这是行业中的常见设计,但您可以尝试不同的比例。
解码器层更复杂,因为它由一个自注意力层、一个交叉注意力层和一个前馈网络组成。实现如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
class DecoderLayer(nn.Module): def __init__(self, hidden_dim, num_heads, num_kv_heads=None, dropout=0.1): super().__init__() self.self_attn = GQA(hidden_dim, num_heads, num_kv_heads, dropout) self.cross_attn = GQA(hidden_dim, num_heads, num_kv_heads, dropout) self.mlp = SwiGLU(hidden_dim, 4 * hidden_dim) self.norm1 = nn.RMSNorm(hidden_dim) self.norm2 = nn.RMSNorm(hidden_dim) self.norm3 = nn.RMSNorm(hidden_dim) def forward(self, x, enc_out, mask=None, rope=None): # 自注意力子层 out = x out = self.norm1(out) out = self.self_attn(out, out, out, mask, rope) x = out + x # 交叉注意力子层 out = self.norm2(x) out = self.cross_attn(out, enc_out, enc_out, None, rope) x = out + x # MLP子层 x = out + x out = self.norm3(x) out = self.mlp(out) return out + x |
您可以看到,自注意力和交叉注意力子层都是使用GQA类实现的。区别在于它们在forward()方法中的使用方式。RoPE应用于两者,但掩码仅用于自注意力子层。
Transformer模型构建用于连接编码器和解码器,但在将序列传递给编码器或解码器之前,输入序列的token ID首先被转换为嵌入向量。实现如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
class Transformer(nn.Module): def __init__(self, num_layers, num_heads, num_kv_heads, hidden_dim, max_seq_len, vocab_size_src, vocab_size_tgt, dropout=0.1): super().__init__() self.rope = RotaryPositionalEncoding(hidden_dim // num_heads, max_seq_len) self.src_embedding = nn.Embedding(vocab_size_src, hidden_dim) self.tgt_embedding = nn.Embedding(vocab_size_tgt, hidden_dim) self.encoders = nn.ModuleList([ EncoderLayer(hidden_dim, num_heads, num_kv_heads, dropout) for _ in range(num_layers) ]) self.decoders = nn.ModuleList([ DecoderLayer(hidden_dim, num_heads, num_kv_heads, dropout) for _ in range(num_layers) ]) self.out = nn.Linear(hidden_dim, vocab_size_tgt) def forward(self, src_ids, tgt_ids, src_mask=None, tgt_mask=None): # 编码器 x = self.src_embedding(src_ids) for encoder in self.encoders: x = encoder(x, src_mask, self.rope) enc_out = x # 解码器 x = self.tgt_embedding(tgt_ids) for decoder in self.decoders: x = decoder(x, enc_out, tgt_mask, self.rope) return self.out(x) |
可以看到,Transformer类在其构造函数中拥有大量的参数。这是因为它作为创建整个模型的入口点,Transformer类将初始化所有子层。这是一个很好的设计,因为您可以将Python字典定义为模型配置。下面是如何使用上面定义的类创建模型的示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
model_config = { "num_layers": 4, "num_heads": 8, "num_kv_heads": 4, "hidden_dim": 128, "max_seq_len": 768, "vocab_size_src": len(en_tokenizer.get_vocab()), "vocab_size_tgt": len(fr_tokenizer.get_vocab()), "dropout": 0.1, } device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = Transformer(**model_config).to(device) |
因果掩码和填充掩码
训练模型的第一个步骤是创建一个数据集对象,该对象可用于以批次和随机顺序迭代数据集。在上一个部分,您已将数据集读入列表text_pairs。您还为英语和法语创建了分词器。现在,您可以使用PyTorch的Dataset类来创建数据集对象。下面是数据集对象的实现。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import torch from torch.utils.data import Dataset, DataLoader class TranslationDataset(torch.utils.data.Dataset): def __init__(self, text_pairs): self.text_pairs = text_pairs def __len__(self): return len(self.text_pairs) def __getitem__(self, idx): eng, fra = self.text_pairs[idx] return eng, "[start] " + fra + " [end]" def collate_fn(batch): en_str, fr_str = zip(*batch) en_enc = en_tokenizer.encode_batch(en_str, add_special_tokens=True) fr_enc = fr_tokenizer.encode_batch(fr_str, add_special_tokens=True) en_ids = [enc.ids for enc in en_enc] fr_ids = [enc.ids for enc in fr_enc] return torch.tensor(en_ids), torch.tensor(fr_ids) BATCH_SIZE = 32 dataset = TranslationDataset(text_pairs) dataloader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True, collate_fn=collate_fn) |
您可以尝试从数据集中打印一个样本。
|
1 2 3 4 |
for en_ids, fr_ids in dataloader: print(f"English: {en_ids}") print(f"French: {fr_ids}") break |
TranslationDataset类封装了text_pairs,并向法语句子添加了[start]和[end]标记。dataloader对象在分词后提供批处理的、随机化的样本。collate_fn()函数负责分词和填充,以确保每个批次中的序列长度一致。
对于训练,我们使用交叉熵损失和Adam优化器。模型采用教师强制技术,在训练过程中向解码器提供真实序列,而不是重复使用其自身的输出。请注意,在教师强制中,解码器在生成第 N 个标记时应该只能看到前 N-1 个标记。
Transformer是一种可以并行化的架构。当您向解码器提供长度为N的序列时,它可以并行处理序列的所有元素并输出长度为N的序列。通常,我们将此输出序列的最后一个元素视为输出。或者,为了节省计算量,您可以使用输入序列的最后一个元素作为注意力中的“查询”,同时使用完整的输入序列作为“键”和“值”。
如果您仔细观察,您会发现对于长度为N的序列,您可以训练模型N次。如果模型可以并行化,您就可以为相同的输入序列N并行生成N个输出。但是,有一个问题:当模型生成输出N时,您希望它只使用直到位置N-1的序列,而不是位置N或之后的任何内容。
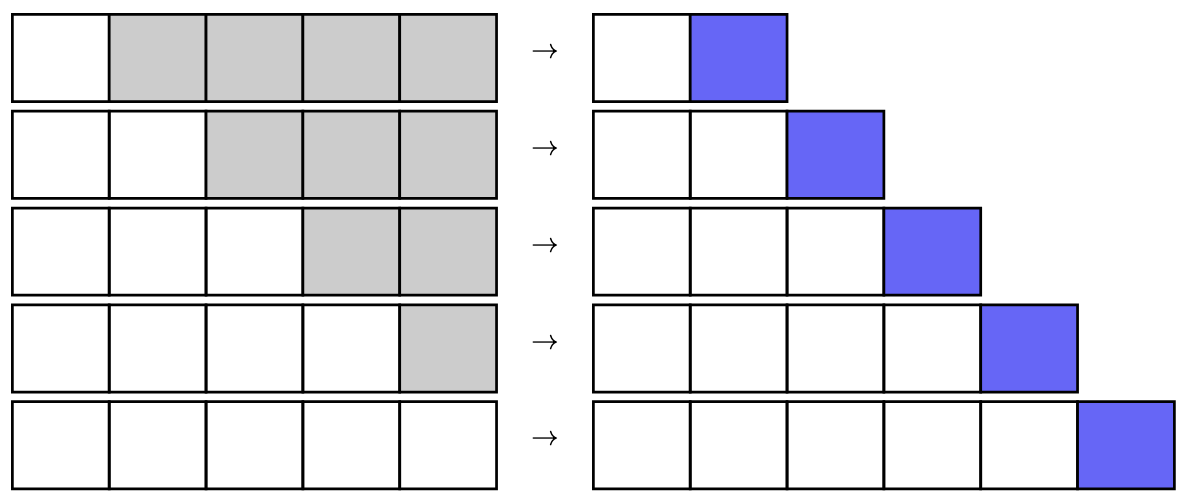
训练Transformer时的因果预测:迭代地向解码器提供更长的序列(白色方块)。每一步,解码器预测一个额外的输出(蓝色方块)。灰色方块在相应步骤中未提供给模型。
为了实现这一点,可以使用因果掩码。因果掩码是一个形状为(N, N)的方阵,其中N是序列长度。如今,因果掩码被实现为三角矩阵,对角线以上的元素设置为$-\infty$,对角线或对角线下方的元素设置为0,如下所示。
$$
M = \begin{bmatrix}
0 & -\infty & -\infty & \cdots & -\infty \\
0 & 0 & -\infty & \cdots & -\infty \\
0 & 0 & 0 & \cdots & -\infty \\
\vdots & \vdots & \vdots & \ddots & \vdots \\
0 & 0 & 0 & \cdots & 0
\end{bmatrix}
$$
因果掩码通过注意力类GQA在解码器中使用,并由PyTorch中的scaled_dot_product_attention()函数调用。它将“掩盖”不允许注意到的位置(即“未来”位置)的注意力分数,以便softmax操作将那些位置设置为零。上面所示的矩阵M垂直表示“查询”,水平表示“键”。矩阵中的0位置表示查询只能注意到不晚于其自身位置的键。因此得名“因果”。
因果掩码应用于解码器的自注意力,其中查询和键是相同的序列。因此,M是一个方阵。您可以在PyTorch中创建这样的矩阵,如下所示。
|
1 2 3 |
def create_causal_mask(seq_len, device): mask = torch.triu(torch.full((seq_len, seq_len), float('-inf'), device=device), diagonal=1) return mask |
除了因果掩码之外,您还想跳过序列中的填充标记。填充标记是在批次中的序列长度不一致时添加的。由于它们不应携带任何信息,因此应将其从注意或输出的损失计算中排除。填充掩码也是每个序列的方阵。以下是根据张量中的序列批次创建填充掩码的Python代码。
|
1 2 3 4 5 6 |
def create_padding_mask(batch, padding_token_id): batch_size, seq_len = batch.shape device = batch.device padded = torch.zeros_like(batch, device=device) .float().masked_fill(batch == padding_token_id, float('-inf')) mask = torch.zeros(batch_size, seq_len, seq_len, device=device) + padded[:,:,None] + padded[:,None,:] return mask[:, None, :, :] |
此代码首先创建一个与张量batch形状匹配的二维张量padded。张量padded在所有地方都为零,除了原始张量batch等于填充标记ID的位置。然后创建一个三维张量mask,其形状为(batch_size, seq_len, seq_len)。张量mask是方阵的批次。在每个方阵中,行和列都用padded进行设置,使得对应于填充标记的位置被设置为$-\infty$。
上述函数使用了PyTorch中的维度扩展技术。用None索引一个张量会在该位置添加一个新的维度。它还利用PyTorch的广播功能用padded张量填充mask。
创建的填充掩码的形状为(batch_size, 1, seq_len, seq_len)。然而,因果掩码的形状为(seq_len, seq_len)。当应用自注意力时,它们可以被广播并相加。
训练与评估
现在您可以按如下方式实现训练循环。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
N_EPOCHS = 60 LR = 0.005 WARMUP_STEPS = 1000 CLIP_NORM = 5.0 loss_fn = nn.CrossEntropyLoss(ignore_index=fr_tokenizer.token_to_id("[pad]")) optimizer = optim.Adam(model.parameters(), lr=LR) warmup_scheduler = optim.lr_scheduler.LinearLR( optimizer, start_factor=0.01, end_factor=1.0, total_iters=WARMUP_STEPS) cosine_scheduler = optim.lr_scheduler.CosineAnnealingLR( optimizer, T_max=N_EPOCHS * len(dataloader) - WARMUP_STEPS, eta_min=0) scheduler = optim.lr_scheduler.SequentialLR( optimizer, schedulers=[warmup_scheduler, cosine_scheduler], milestones=[WARMUP_STEPS]) for epoch in range(N_EPOCHS): model.train() epoch_loss = 0 for en_ids, fr_ids in dataloader: # 将“句子”移到设备上 en_ids = en_ids.to(device) fr_ids = fr_ids.to(device) # create source mask as padding mask, target mask as causal mask src_mask = create_padding_mask(en_ids, en_tokenizer.token_to_id("[pad]")) tgt_mask = create_causal_mask(fr_ids.shape[1], device).unsqueeze(0) tgt_mask = tgt_mask + create_padding_mask(fr_ids, fr_tokenizer.token_to_id("[pad]")) # 清零梯度,然后进行前向传播 optimizer.zero_grad() outputs = model(en_ids, fr_ids, src_mask, tgt_mask) # 计算损失:比较 3D logits 和 2D 目标 loss = loss_fn(outputs[:, :-1, :].reshape(-1, outputs.shape[-1]), fr_ids[:, 1:].reshape(-1)) loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), CLIP_NORM, error_if_nonfinite=False) optimizer.step() scheduler.step() epoch_loss += loss.item() print(f"Epoch {epoch+1}/{N_EPOCHS}; Avg loss {epoch_loss/len(dataloader)}; Latest loss {loss.item()}") |
训练循环实现为嵌套的for循环。每个epoch扫描一次整个数据集。从数据集中提取的每个批次都用于创建掩码。然后,将数据和掩码传递给模型以生成输出。然后通过将输出与真实值进行比较来计算损失。损失反向传播以更新模型参数。
用于编码器的掩码是源(英语)序列的填充掩码。用于解码器的掩码是因果掩码加上目标(法语)序列的填充掩码。反向传播计算的梯度被裁剪以减轻梯度爆炸问题。
虽然训练循环使模型能够学会生成目标序列,但在每个epoch之后运行评估以评估模型的性能并保存最佳模型也很有益。评估实现如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
best_loss = float('inf') ... model.eval() epoch_loss = 0 with torch.no_grad(): for en_ids, fr_ids in tqdm.tqdm(dataloader, desc="Evaluating"): en_ids = en_ids.to(device) fr_ids = fr_ids.to(device) src_mask = create_padding_mask(en_ids, en_tokenizer.token_to_id("[pad]")) tgt_mask = create_causal_mask(fr_ids.shape[1], device).unsqueeze(0) + create_padding_mask(fr_ids, fr_tokenizer.token_to_id("[pad]")) outputs = model(en_ids, fr_ids, src_mask, tgt_mask) loss = loss_fn(outputs[:, :-1, :].reshape(-1, outputs.shape[-1]), fr_ids[:, 1:].reshape(-1)) epoch_loss += loss.item() print(f"Eval loss: {epoch_loss/len(dataloader)}") if epoch_loss < best_loss: best_loss = epoch_loss torch.save(model.state_dict(), f"transformer-epoch-{epoch+1}.pth") |
此评估复用了与训练相同的评估集,因为你没有单独的测试集。代码与训练循环类似,只是你不需要反向传播,并且在 torch.no_grad() 上下文中运行模型。
损失是针对整个数据集平均计算的。变量 best_loss 跟踪最低损失。每当损失得到改善时,模型的一个副本就会被保存。
一个训练良好的模型应该能达到 0.1 或更低的平均损失。训练完成后,你的模型就可以使用了。下面是一个例子
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# 测试几个样本 model.eval() N_SAMPLES = 5 MAX_LEN = 60 with torch.no_grad(): start_token = torch.tensor([fr_tokenizer.token_to_id("[start]")]).to(device) for en, true_fr in random.sample(dataset.text_pairs, N_SAMPLES): en_ids = torch.tensor(en_tokenizer.encode(en).ids).unsqueeze(0).to(device) # 获取编码器的上下文 src_mask = create_padding_mask(en_ids, en_tokenizer.token_to_id("[pad]")) x = model.src_embedding(en_ids) for encoder in model.encoders: x = encoder(x, src_mask, model.rope) enc_out = x # 从解码器生成输出 fr_ids = start_token.unsqueeze(0) for _ in range(MAX_LEN): tgt_mask = create_causal_mask(fr_ids.shape[1], device).unsqueeze(0) tgt_mask = tgt_mask + create_padding_mask(fr_ids, fr_tokenizer.token_to_id("[pad]")) x = model.tgt_embedding(fr_ids) for decoder in model.decoders: x = decoder(x, enc_out, tgt_mask, model.rope) outputs = model.out(x) outputs = outputs.argmax(dim=-1) fr_ids = torch.cat([fr_ids, outputs[0, -1]], axis=-1) if fr_ids[0, -1] == fr_tokenizer.token_to_id("[end]"): break # Decode the predicted IDs pred_fr = fr_tokenizer.decode(fr_ids[0].tolist()) print(f"English: {en}") print(f"French: {true_fr}") print(f"Predicted: {pred_fr}") print() |
这比训练循环更复杂,因为你没有使用模型的 forward() 方法,而是分别使用了编码器和解码器。你首先使用编码器获取上下文 enc_out。然后,你以 fr_ids 作为起始 token 开始,并从 transformer 的解码器部分迭代生成输出。每一步都会将 fr_ids 扩展一个 token。生成将在生成结束 token 或达到最大长度时结束。
你也可以使用模型的 forward() 方法,但你会在每一步都用相同的源序列调用编码器。这上面代码中已优化了不必要的计算。实际上,你可能希望在模型类中实现一个仅用于推理的方法。
运行上面的代码,你会看到以下输出
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
English: are there any bananas? French: y a-t-il des bananes ? Predicted: y a-t-il des bananes ? English: tom helped you, didn't he? French: tom t'a aidée, n'est-ce pas ? Predicted: tom vous a aidées, n'est-ce pas ? English: i miss my parents. French: mes parents me manquent. Predicted: mes parents me manquent. j'ai manqué. English: the game's almost over. French: la manche est presque terminée. Predicted: la manche est presque terminée. English: turn left at the second traffic light. French: tourne au second feu à gauche ! Predicted: tournez au deuxième feu à gauche ! |
为了完整起见,完整的代码如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 |
# PyTorch 中的 Transformer 模型实现 import random import os import re import unicodedata import zipfile import requests import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim import tokenizers import tqdm # # Data preparation # # Download dataset provided by Anki: https://www.manythings.org/anki/ with requests if not os.path.exists("fra-eng.zip"): url = "http://storage.googleapis.com/download.tensorflow.org/data/fra-eng.zip" response = requests.get(url) with open("fra-eng.zip", "wb") as f: f.write(response.content) # Normalize text # each line of the file is in the format "<english>\t<french>" # We convert text to lowercasee, normalize unicode (UFKC) def normalize(line): """规范化一行文本并在制表符处分成两部分""" line = unicodedata.normalize("NFKC", line.strip().lower()) eng, fra = line.split("\t") return eng.lower().strip(), fra.lower().strip() text_pairs = [] with zipfile.ZipFile("fra-eng.zip", "r") as zip_ref: for line in zip_ref.read("fra.txt").decode("utf-8").splitlines(): eng, fra = normalize(line) text_pairs.append((eng, fra)) # # 使用 BPE 进行分词 # if os.path.exists("en_tokenizer.json") and os.path.exists("fr_tokenizer.json"): en_tokenizer = tokenizers.Tokenizer.from_file("en_tokenizer.json") fr_tokenizer = tokenizers.Tokenizer.from_file("fr_tokenizer.json") else: en_tokenizer = tokenizers.Tokenizer(tokenizers.models.BPE()) fr_tokenizer = tokenizers.Tokenizer(tokenizers.models.BPE()) # Configure pre-tokenizer to split on whitespace and punctuation, add space at beginning of the sentence en_tokenizer.pre_tokenizer = tokenizers.pre_tokenizers.ByteLevel(add_prefix_space=True) fr_tokenizer.pre_tokenizer = tokenizers.pre_tokenizers.ByteLevel(add_prefix_space=True) # Configure decoder: So that word boundary symbol "Ġ" will be removed en_tokenizer.decoder = tokenizers.decoders.ByteLevel() fr_tokenizer.decoder = tokenizers.decoders.ByteLevel() # Train BPE for English and French using the same trainer VOCAB_SIZE = 8000 trainer = tokenizers.trainers.BpeTrainer( vocab_size=VOCAB_SIZE, special_tokens=["[start]", "[end]", "[pad]"], show_progress=True ) en_tokenizer.train_from_iterator([x[0] for x in text_pairs], trainer=trainer) fr_tokenizer.train_from_iterator([x[1] for x in text_pairs], trainer=trainer) en_tokenizer.enable_padding(pad_id=en_tokenizer.token_to_id("[pad]"), pad_token="[pad]") fr_tokenizer.enable_padding(pad_id=fr_tokenizer.token_to_id("[pad]"), pad_token="[pad]") # Save the trained tokenizers en_tokenizer.save("en_tokenizer.json", pretty=True) fr_tokenizer.save("fr_tokenizer.json", pretty=True) # Test the tokenizer print("Sample tokenization:") en_sample, fr_sample = random.choice(text_pairs) encoded = en_tokenizer.encode(en_sample) print(f"Original: {en_sample}") print(f"Tokens: {encoded.tokens}") print(f"IDs: {encoded.ids}") print(f"Decoded: {en_tokenizer.decode(encoded.ids)}") print() encoded = fr_tokenizer.encode("[start] " + fr_sample + " [end]") print(f"Original: {fr_sample}") print(f"Tokens: {encoded.tokens}") print(f"IDs: {encoded.ids}") print(f"Decoded: {fr_tokenizer.decode(encoded.ids)}") print() # # Create PyTorch dataset for the BPE-encoded translation pairs # class TranslationDataset(torch.utils.data.Dataset): def __init__(self, text_pairs, en_tokenizer, fr_tokenizer): self.text_pairs = text_pairs def __len__(self): return len(self.text_pairs) def __getitem__(self, idx): eng, fra = self.text_pairs[idx] return eng, "[start] " + fra + " [end]" def collate_fn(batch): en_str, fr_str = zip(*batch) en_enc = en_tokenizer.encode_batch(en_str, add_special_tokens=True) fr_enc = fr_tokenizer.encode_batch(fr_str, add_special_tokens=True) en_ids = [enc.ids for enc in en_enc] fr_ids = [enc.ids for enc in fr_enc] return torch.tensor(en_ids), torch.tensor(fr_ids) BATCH_SIZE = 32 dataset = TranslationDataset(text_pairs, en_tokenizer, fr_tokenizer) dataloader = torch.utils.data.DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True, collate_fn=collate_fn) # 测试数据集 for en_ids, fr_ids in dataloader: print(f"English: {en_ids}") print(f"French: {fr_ids}") break # # Transformer 模型组件 # def rotate_half(x): x1, x2 = x.chunk(2, dim=-1) return torch.cat((-x2, x1), dim=-1) def apply_rotary_pos_emb(x, cos, sin): return (x * cos) + (rotate_half(x) * sin) class RotaryPositionalEncoding(nn.Module): def __init__(self, dim, max_seq_len=1024): super().__init__() N = 10000 inv_freq = 1. / (N ** (torch.arange(0, dim, 2).float() / dim)) position = torch.arange(max_seq_len).float() inv_freq = torch.cat((inv_freq, inv_freq), dim=-1) sinusoid_inp = torch.outer(position, inv_freq) self.register_buffer("cos", sinusoid_inp.cos()) self.register_buffer("sin", sinusoid_inp.sin()) def forward(self, x, seq_len=None): if seq_len is None: seq_len = x.size(1) cos = self.cos[:seq_len].view(1, seq_len, 1, -1) sin = self.sin[:seq_len].view(1, seq_len, 1, -1) return apply_rotary_pos_emb(x, cos, sin) class SwiGLU(nn.Module): def __init__(self, hidden_dim, intermediate_dim): super().__init__() self.gate = nn.Linear(hidden_dim, intermediate_dim) self.up = nn.Linear(hidden_dim, intermediate_dim) self.down = nn.Linear(intermediate_dim, hidden_dim) self.act = nn.SiLU() def forward(self, x): x = self.act(self.gate(x)) * self.up(x) x = self.down(x) return x class GQA(nn.Module): def __init__(self, hidden_dim, num_heads, num_kv_heads=None, dropout=0.1): super().__init__() self.num_heads = num_heads self.num_kv_heads = num_kv_heads or num_heads self.head_dim = hidden_dim // num_heads self.num_groups = num_heads // num_kv_heads self.dropout = dropout self.q_proj = nn.Linear(hidden_dim, hidden_dim) self.k_proj = nn.Linear(hidden_dim, hidden_dim) self.v_proj = nn.Linear(hidden_dim, hidden_dim) self.out_proj = nn.Linear(hidden_dim, hidden_dim) def forward(self, q, k, v, mask=None, rope=None): q_batch_size, q_seq_len, hidden_dim = q.shape k_batch_size, k_seq_len, hidden_dim = k.shape v_batch_size, v_seq_len, hidden_dim = v.shape # 投影 q = self.q_proj(q).view(q_batch_size, q_seq_len, -1, self.head_dim).transpose(1, 2) k = self.k_proj(k).view(k_batch_size, k_seq_len, -1, self.head_dim).transpose(1, 2) v = self.v_proj(v).view(v_batch_size, v_seq_len, -1, self.head_dim).transpose(1, 2) # 应用旋转位置编码 if rope: q = rope(q) k = rope(k) # 计算分组查询注意力 q = q.contiguous() k = k.contiguous() v = v.contiguous() output = F.scaled_dot_product_attention(q, k, v, attn_mask=mask, dropout_p=self.dropout, enable_gqa=True) output = output.transpose(1, 2).reshape(q_batch_size, q_seq_len, hidden_dim).contiguous() output = self.out_proj(output) return output class EncoderLayer(nn.Module): def __init__(self, hidden_dim, num_heads, num_kv_heads=None, dropout=0.1): super().__init__() self.self_attn = GQA(hidden_dim, num_heads, num_kv_heads, dropout) self.mlp = SwiGLU(hidden_dim, 4 * hidden_dim) self.norm1 = nn.RMSNorm(hidden_dim) self.norm2 = nn.RMSNorm(hidden_dim) def forward(self, x, mask=None, rope=None): # 自注意力子层 out = x out = self.norm1(x) out = self.self_attn(out, out, out, mask, rope) x = out + x # MLP子层 out = self.norm2(x) out = self.mlp(out) return out + x class DecoderLayer(nn.Module): def __init__(self, hidden_dim, num_heads, num_kv_heads=None, dropout=0.1): super().__init__() self.self_attn = GQA(hidden_dim, num_heads, num_kv_heads, dropout) self.cross_attn = GQA(hidden_dim, num_heads, num_kv_heads, dropout) self.mlp = SwiGLU(hidden_dim, 4 * hidden_dim) self.norm1 = nn.RMSNorm(hidden_dim) self.norm2 = nn.RMSNorm(hidden_dim) self.norm3 = nn.RMSNorm(hidden_dim) def forward(self, x, enc_out, mask=None, rope=None): # 自注意力子层 out = x out = self.norm1(out) out = self.self_attn(out, out, out, mask, rope) x = out + x # 交叉注意力子层 out = self.norm2(x) out = self.cross_attn(out, enc_out, enc_out, None, rope) x = out + x # MLP子层 x = out + x out = self.norm3(x) out = self.mlp(out) return out + x class Transformer(nn.Module): def __init__(self, num_layers, num_heads, num_kv_heads, hidden_dim, max_seq_len, vocab_size_src, vocab_size_tgt, dropout=0.1): super().__init__() self.rope = RotaryPositionalEncoding(hidden_dim // num_heads, max_seq_len) self.src_embedding = nn.Embedding(vocab_size_src, hidden_dim) self.tgt_embedding = nn.Embedding(vocab_size_tgt, hidden_dim) self.encoders = nn.ModuleList([ EncoderLayer(hidden_dim, num_heads, num_kv_heads, dropout) for _ in range(num_layers) ]) self.decoders = nn.ModuleList([ DecoderLayer(hidden_dim, num_heads, num_kv_heads, dropout) for _ in range(num_layers) ]) self.out = nn.Linear(hidden_dim, vocab_size_tgt) def forward(self, src_ids, tgt_ids, src_mask=None, tgt_mask=None): # 编码器 x = self.src_embedding(src_ids) for encoder in self.encoders: x = encoder(x, src_mask, self.rope) enc_out = x # 解码器 x = self.tgt_embedding(tgt_ids) for decoder in self.decoders: x = decoder(x, enc_out, tgt_mask, self.rope) return self.out(x) model_config = { "num_layers": 4, "num_heads": 8, "num_kv_heads": 4, "hidden_dim": 128, "max_seq_len": 768, "vocab_size_src": len(en_tokenizer.get_vocab()), "vocab_size_tgt": len(fr_tokenizer.get_vocab()), "dropout": 0.1, } device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = Transformer(**model_config).to(device) print(model) # 训练 print("Model created with:") print(f" 输入词汇量大小: {model_config['vocab_size_src']}") print(f" 输出词汇量大小: {model_config['vocab_size_tgt']}") print(f" 层数: {model_config['num_layers']}") print(f" 注意力头数: {model_config['num_heads']}") print(f" KV 头数: {model_config['num_kv_heads']}") print(f" 隐藏层维度: {model_config['hidden_dim']}") print(f" 最大序列长度: {model_config['max_seq_len']}") print(f" Dropout: {model_config['dropout']}") print(f" Total parameters: {sum(p.numel() for p in model.parameters() if p.requires_grad)}") def create_causal_mask(seq_len, device): """ 为自回归注意力创建因果掩码。 参数 seq_len: 序列长度 返回 形状为 (seq_len, seq_len) 的因果掩码 """ mask = torch.triu(torch.full((seq_len, seq_len), float('-inf'), device=device), diagonal=1) return mask def create_padding_mask(batch, padding_token_id): """ 为一批序列创建填充掩码。 参数 batch: 序列批次,形状为 (batch_size, seq_len) padding_token_id: 填充 token 的 ID 返回 形状为 (batch_size, seq_len, seq_len) 的填充掩码 """ batch_size, seq_len = batch.shape device = batch.device padded = torch.zeros_like(batch, device=device) .float().masked_fill(batch == padding_token_id, float('-inf')) mask = torch.zeros(batch_size, seq_len, seq_len, device=device) + padded[:,:,None] + padded[:,None,:] return mask[:, None, :, :] # 除非 model.pth 存在,否则进行训练 loss_fn = nn.CrossEntropyLoss(ignore_index=fr_tokenizer.token_to_id("[pad]")) if os.path.exists("transformer.pth"): model.load_state_dict(torch.load("transformer.pth")) else: N_EPOCHS = 60 LR = 0.005 WARMUP_STEPS = 1000 CLIP_NORM = 5.0 best_loss = float('inf') optimizer = optim.Adam(model.parameters(), lr=LR) warmup_scheduler = optim.lr_scheduler.LinearLR(optimizer, start_factor=0.01, end_factor=1.0, total_iters=WARMUP_STEPS) cosine_scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=N_EPOCHS * len(dataloader) - WARMUP_STEPS, eta_min=0) scheduler = optim.lr_scheduler.SequentialLR(optimizer, schedulers=[warmup_scheduler, cosine_scheduler], milestones=[WARMUP_STEPS]) print(f"Training for {N_EPOCHS} epochs with {len(dataloader)} steps per epoch") for epoch in range(N_EPOCHS): model.train() epoch_loss = 0 for en_ids, fr_ids in tqdm.tqdm(dataloader, desc="Training"): # 将“句子”移到设备 en_ids = en_ids.to(device) fr_ids = fr_ids.to(device) # 创建源掩码作为填充掩码,目标掩码作为因果掩码 src_mask = create_padding_mask(en_ids, en_tokenizer.token_to_id("[pad]")) tgt_mask = create_causal_mask(fr_ids.shape[1], device).unsqueeze(0) + create_padding_mask(fr_ids, fr_tokenizer.token_to_id("[pad]")) # 梯度清零,然后进行前向传播 optimizer.zero_grad() outputs = model(en_ids, fr_ids, src_mask, tgt_mask) # 计算损失:比较 3D logits 和 2D targets loss = loss_fn(outputs[:, :-1, :].reshape(-1, outputs.shape[-1]), fr_ids[:, 1:].reshape(-1)) loss.backward() if CLIP_NORM: torch.nn.utils.clip_grad_norm_(model.parameters(), CLIP_NORM, error_if_nonfinite=False) optimizer.step() scheduler.step() epoch_loss += loss.item() print(f"Epoch {epoch+1}/{N_EPOCHS}; Avg loss {epoch_loss/len(dataloader)}; Latest loss {loss.item()}") # 测试 model.eval() epoch_loss = 0 with torch.no_grad(): for en_ids, fr_ids in tqdm.tqdm(dataloader, desc="Evaluating"): en_ids = en_ids.to(device) fr_ids = fr_ids.to(device) src_mask = create_padding_mask(en_ids, en_tokenizer.token_to_id("[pad]")) tgt_mask = create_causal_mask(fr_ids.shape[1], device).unsqueeze(0) + create_padding_mask(fr_ids, fr_tokenizer.token_to_id("[pad]")) outputs = model(en_ids, fr_ids, src_mask, tgt_mask) loss = loss_fn(outputs[:, :-1, :].reshape(-1, outputs.shape[-1]), fr_ids[:, 1:].reshape(-1)) epoch_loss += loss.item() print(f"Eval loss: {epoch_loss/len(dataloader)}") if epoch_loss < best_loss: best_loss = epoch_loss torch.save(model.state_dict(), f"transformer-epoch-{epoch+1}.pth") # 保存训练后的最终模型 torch.save(model.state_dict(), "transformer.pth") # 测试几个样本 model.eval() N_SAMPLES = 5 MAX_LEN = 60 with torch.no_grad(): start_token = torch.tensor([fr_tokenizer.token_to_id("[start]")]).to(device) for en, true_fr in random.sample(dataset.text_pairs, N_SAMPLES): en_ids = torch.tensor(en_tokenizer.encode(en).ids).unsqueeze(0).to(device) # 获取编码器的上下文 src_mask = create_padding_mask(en_ids, en_tokenizer.token_to_id("[pad]")) x = model.src_embedding(en_ids) for encoder in model.encoders: x = encoder(x, src_mask, model.rope) enc_out = x # 从解码器生成输出 fr_ids = start_token.unsqueeze(0) for _ in range(MAX_LEN): tgt_mask = create_causal_mask(fr_ids.shape[1], device).unsqueeze(0) tgt_mask = tgt_mask + create_padding_mask(fr_ids, fr_tokenizer.token_to_id("[pad]")) x = model.tgt_embedding(fr_ids) for decoder in model.decoders: x = decoder(x, enc_out, tgt_mask, model.rope) outputs = model.out(x) outputs = outputs.argmax(dim=-1) fr_ids = torch.cat([fr_ids, outputs[0, -1]], axis=-1) if fr_ids[0, -1] == fr_tokenizer.token_to_id("[end]"): break # Decode the predicted IDs pred_fr = fr_tokenizer.decode(fr_ids[0].tolist()) print(f"English: {en}") print(f"French: {true_fr}") print(f"Predicted: {pred_fr}") print() |
进一步阅读
以下是一些可以帮助你了解 Transformer 模型的参考资料
总结
在本篇文章中,你构建并训练了一个完整的 Transformer 模型用于英法翻译。特别是,你学习了
- Transformer 通过自注意力实现并行处理,取代了循环层
- 各种架构选择会影响模型设计和性能
- 如何创建核心组件,包括自注意力、交叉注意力和位置编码
- 如何使用掩码和教师强制进行模型训练
虽然这个实现规模不大,但它包含了大型语言模型中的所有基本元素。






暂无评论。