特征重要性是指为输入特征分配分数的技术,这些分数表明特征在预测目标变量方面的有用程度。
特征重要性分数有许多类型和来源,尽管流行的例子包括统计相关性分数、作为线性模型一部分计算的系数、决策树和置换重要性分数。
特征重要性分数在预测建模项目中起着重要作用,包括提供对数据的洞察、对模型的洞察,以及作为 降维 和 特征选择 的基础,这些可以提高预测模型在问题上的效率和有效性。
在本教程中,您将了解 Python 中机器学习的特征重要性分数。
完成本教程后,您将了解:
- 特征重要性在预测建模问题中的作用。
- 如何从线性模型和决策树计算和审查特征重要性。
- 如何计算和审查置换特征重要性分数。
开始您的项目,阅读我的新书《机器学习数据准备》,其中包括分步教程和所有示例的Python源代码文件。
让我们开始吧。
- 2020年5月更新:增加了使用重要性进行特征选择的示例。

如何使用 Python 计算特征重要性
照片作者:Bonnie Moreland,保留部分权利。
教程概述
本教程分为六个部分;它们是:
- 特征重要性
- 准备
- 检查 Scikit-Learn 版本
- 测试数据集
- 系数作为特征重要性
- 线性回归特征重要性
- 逻辑回归特征重要性
- 决策树特征重要性
- CART 特征重要性
- 随机森林特征重要性
- XGBoost 特征重要性
- 置换特征重要性
- 置换特征重要性用于回归
- 置换特征重要性用于分类
- 使用重要性进行特征选择
特征重要性
特征重要性是指一类为预测模型分配分数的技术,这些分数表明每个特征在进行预测时的相对重要性。
特征重要性分数可以为涉及预测数值(称为回归)的问题以及涉及预测类别标签(称为分类)的问题计算。
这些分数非常有用,并且可以在预测建模问题的各种情况下使用,例如:
- 更好地理解数据。
- 更好地理解模型。
- 减少输入特征的数量。
特征重要性分数可以提供对数据集的洞察。相对分数可以突出哪些特征可能与目标最相关,反之,哪些特征最不相关。这可以由领域专家进行解释,并可作为收集更多或不同数据的基础。
特征重要性分数可以提供对模型的洞察。大多数重要性分数是通过在数据集上拟合的预测模型计算的。检查重要性分数可以深入了解该特定模型,以及在进行预测时哪些特征对模型最重要和最不重要。这是一种模型解释,对于支持它的模型可以执行。
特征重要性可用于改进预测模型。这可以通过使用重要性分数来选择要删除的特征(分数最低)或要保留的特征(分数最高)来实现。这是一种特征选择,可以简化被建模的问题,加快建模过程(删除特征称为降维),并在某些情况下提高模型在问题上的性能。
通常,我们希望量化预测变量与结果之间关系的力量。[...] 以这种方式对预测变量进行排名,在筛选大量数据时会非常有用。
— 第 463 页,应用预测建模,2013。
特征重要性分数可以馈送到包装模型,例如 SelectFromModel 类,以执行特征选择。
有许多方法可以计算特征重要性分数,也有许多模型可以用于此目的。
也许最简单的方法是计算每个特征与目标变量之间的简单系数统计。有关此方法的更多信息,请参阅教程。
在本教程中,我们将介绍三种更高级别的特征重要性;它们是:
- 来自模型系数的特征重要性。
- 来自决策树的特征重要性。
- 来自置换测试的特征重要性。
让我们仔细看看每一个。
想开始学习数据准备吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
准备
在我们深入之前,让我们确认我们的环境并准备一些测试数据集。
检查 Scikit-Learn 版本
首先,请确保您安装了最新版本的 scikit-learn 库。
这很重要,因为我们将在本教程中探讨的某些模型需要库的最新版本。
您可以使用以下代码示例检查已安装库的版本:
|
1 2 3 |
# 检查 scikit-learn 版本 import sklearn print(sklearn.__version__) |
运行该示例将打印库的版本。在撰写本文时,大约是 0.22 版本。
您需要使用此版本或更高版本的 scikit-learn。
|
1 |
0.22.1 |
测试数据集
接下来,让我们仔细看看我们可以用作演示和探索特征重要性分数的测试数据集。
每个测试问题都有五个重要特征和五个不重要特征,并且找出哪些方法在根据重要性查找或区分特征方面是一致的可能会很有趣。
分类数据集
我们将使用 make_classification() 函数来创建测试二分类数据集。
该数据集将包含 1,000 个样本,具有 10 个输入特征,其中五个是信息性的,其余五个是冗余的。我们将固定随机数种子,以确保每次运行代码时都能获得相同的样本。
下面列出了创建和汇总数据集的示例。
|
1 2 3 4 5 6 |
# 测试分类数据集 from sklearn.datasets import make_classification # 定义数据集 X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, n_redundant=5, random_state=1) # 汇总数据集 print(X.shape, y.shape) |
运行该示例会创建数据集并确认预期的样本数和特征数。
|
1 |
(1000, 10) (1000,) |
回归数据集
我们将使用 make_regression() 函数 创建一个测试回归数据集。
与分类数据集一样,回归数据集也将包含 1,000 个样本,具有 10 个输入特征,其中五个是信息性的,其余五个是冗余的。
|
1 2 3 4 5 6 |
# 测试回归数据集 from sklearn.datasets import make_regression # 定义数据集 X, y = make_regression(n_samples=1000, n_features=10, n_informative=5, random_state=1) # 汇总数据集 print(X.shape, y.shape) |
运行该示例会创建数据集并确认预期的样本数和特征数。
|
1 |
(1000, 10) (1000,) |
接下来,让我们更仔细地研究一下系数作为重要性分数。
系数作为特征重要性
线性机器学习算法拟合的模型,其中预测是输入值的加权总和。
示例包括线性回归、逻辑回归以及添加正则化的扩展,例如岭回归和弹性网络。
所有这些算法都找到一组系数来用于加权总和以进行预测。这些系数可以直接用作一种粗略的特征重要性分数。
让我们更仔细地研究一下将系数用作分类和回归的特征重要性。我们将对数据集拟合一个模型来查找系数,然后总结每个输入特征的重要性分数,最后创建一个条形图来了解特征的相对重要性。
线性回归特征重要性
我们可以拟合一个 LinearRegression 模型到回归数据集并检索包含每个输入变量系数的 _coeff_ 属性。
这些系数可以作为粗略特征重要性分数的基础。这假设输入变量具有相同的尺度或在拟合模型之前已进行了缩放。
下面列出了将线性回归系数用作特征重要性的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 线性回归特征重要性 from sklearn.datasets import make_regression 来自 sklearn.linear_model 导入 LinearRegression from matplotlib import pyplot # 定义数据集 X, y = make_regression(n_samples=1000, n_features=10, n_informative=5, random_state=1) # 定义模型 模型 = LinearRegression() # 拟合模型 model.fit(X, y) # 获取重要性 importance = model.coef_ # 总结特征重要性 for i,v in enumerate(importance): print('Feature: %0d, Score: %.5f' % (i,v)) # 绘制特征重要性 pyplot.bar([x for x in range(len(importance))], importance) pyplot.show() |
运行该示例会拟合模型,然后报告每个特征的系数。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行示例几次并比较平均结果。
分数表明模型找到了五个重要特征,并将所有其他特征标记为零系数,实际上将它们从模型中移除。
|
1 2 3 4 5 6 7 8 9 10 |
Feature: 0, Score: 0.00000 Feature: 1, Score: 12.44483 Feature: 2, Score: -0.00000 Feature: 3, Score: -0.00000 Feature: 4, Score: 93.32225 Feature: 5, Score: 86.50811 Feature: 6, Score: 26.74607 Feature: 7, Score: 3.28535 Feature: 8, Score: -0.00000 Feature: 9, Score: 0.00000 |
然后为特征重要性分数创建条形图。
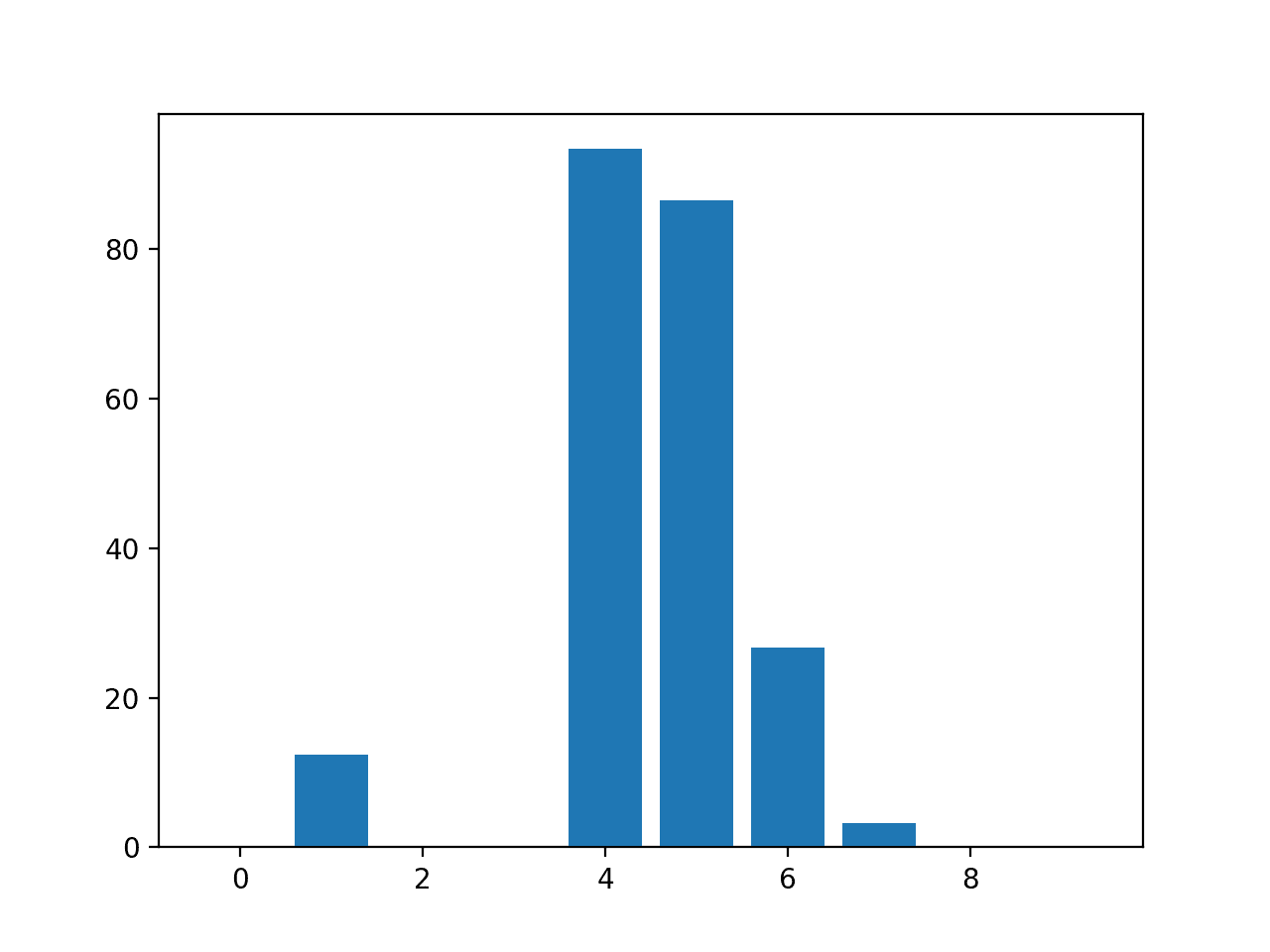
线性回归系数作为特征重要性分数的条形图
这种方法也可用于 Ridge 和 ElasticNet 模型。
逻辑回归特征重要性
我们可以拟合一个 LogisticRegression 模型到回归数据集并检索包含每个输入变量系数的 _coeff_ 属性。
这些系数可以作为粗略特征重要性分数的基础。这假设输入变量具有相同的尺度或在拟合模型之前已进行了缩放。
下面列出了将逻辑回归系数用作特征重要性的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 用于特征重要性的逻辑回归 from sklearn.datasets import make_classification from sklearn.linear_model import LogisticRegression from matplotlib import pyplot # 定义数据集 X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, n_redundant=5, random_state=1) # 定义模型 model = LogisticRegression() # 拟合模型 model.fit(X, y) # 获取重要性 importance = model.coef_[0] # 总结特征重要性 for i,v in enumerate(importance): print('Feature: %0d, Score: %.5f' % (i,v)) # 绘制特征重要性 pyplot.bar([x for x in range(len(importance))], importance) pyplot.show() |
运行该示例会拟合模型,然后报告每个特征的系数。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行示例几次并比较平均结果。
回想一下,这是一个分类问题,类别为 0 和 1。请注意,系数既有正值也有负值。正分数表示预测类别 1 的特征,而负分数表示预测类别 0 的特征。
从这些结果中,至少从我所能判断的来看,无法识别出重要和不重要特征的清晰模式。
|
1 2 3 4 5 6 7 8 9 10 |
Feature: 0, Score: 0.16320 Feature: 1, Score: -0.64301 Feature: 2, Score: 0.48497 Feature: 3, Score: -0.46190 Feature: 4, Score: 0.18432 Feature: 5, Score: -0.11978 Feature: 6, Score: -0.40602 Feature: 7, Score: 0.03772 Feature: 8, Score: -0.51785 Feature: 9, Score: 0.26540 |
然后为特征重要性分数创建条形图。
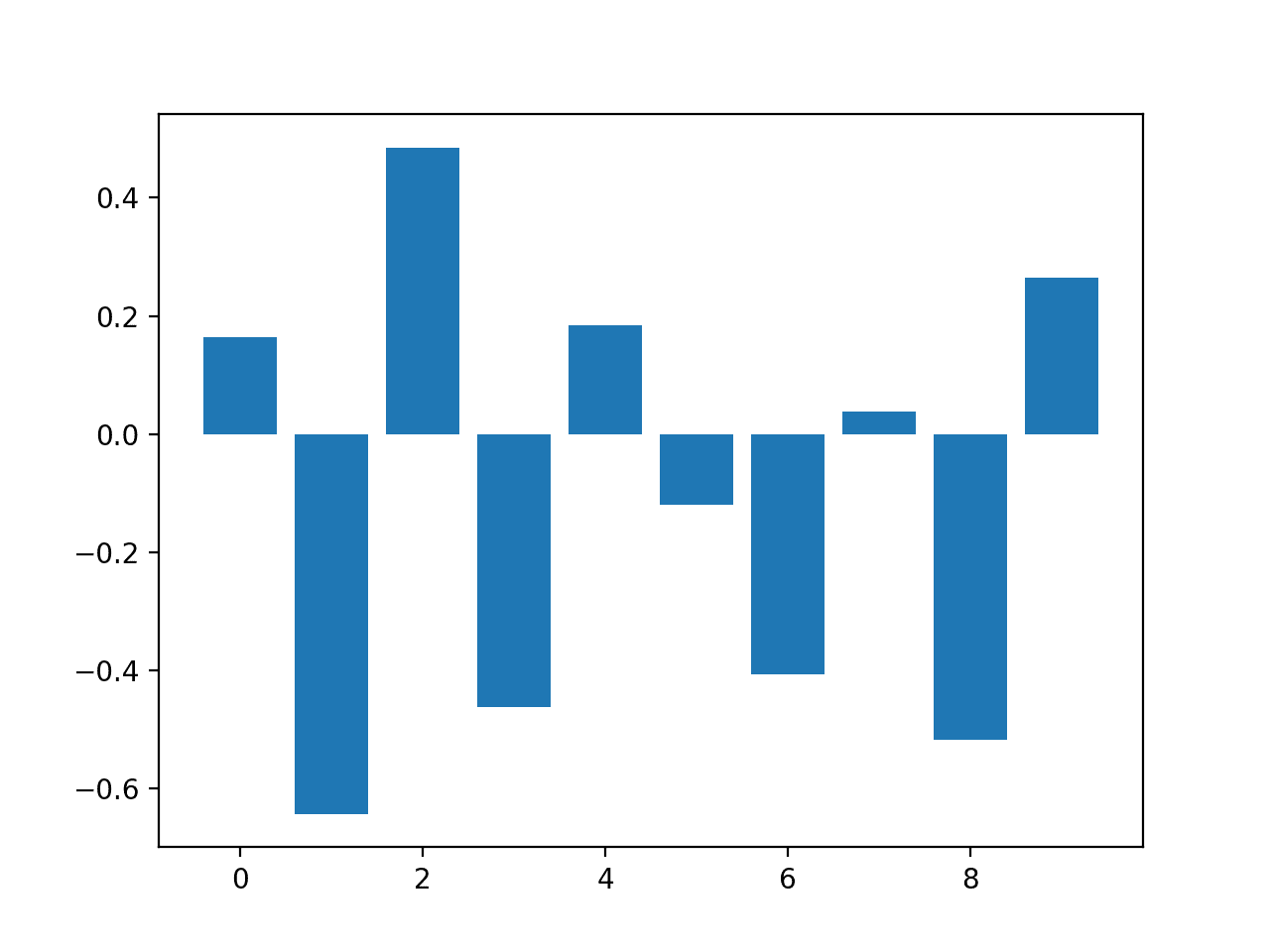
逻辑回归系数作为特征重要性分数的条形图
在看到了系数作为重要性分数的使用之后,让我们来看看更常见的基于决策树的重要性分数。
决策树特征重要性
像 分类和回归树(CART)这样的决策树算法提供了基于用于选择分割点(如 Gini 或熵)的标准的减少量的重要性分数。
同样的方法也可以用于决策树的集成,例如随机森林和随机梯度提升算法。
让我们分别来看一个实际例子。
CART 特征重要性
我们可以使用 scikit-learn 中实现的用于特征重要性的 CART 算法,即 _DecisionTreeRegressor_ 和 _DecisionTreeClassifier_ 类。
拟合后,模型提供了一个 _feature_importances_ 属性,可以访问该属性以检索每个输入特征的相对重要性分数。
让我们看一个回归和分类的例子。
CART 回归特征重要性
下面列出了拟合 DecisionTreeRegressor 并汇总计算出的特征重要性分数的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 用于回归问题的决策树特征重要性 from sklearn.datasets import make_regression 来自 sklearn.tree 导入 DecisionTreeRegressor from matplotlib import pyplot # 定义数据集 X, y = make_regression(n_samples=1000, n_features=10, n_informative=5, random_state=1) # 定义模型 模型 = DecisionTreeRegressor() # 拟合模型 model.fit(X, y) # 获取重要性 importance = model.feature_importances_ # 总结特征重要性 for i,v in enumerate(importance): print('Feature: %0d, Score: %.5f' % (i,v)) # 绘制特征重要性 pyplot.bar([x for x in range(len(importance))], importance) pyplot.show() |
运行该示例会拟合模型,然后报告每个特征的系数。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行示例几次并比较平均结果。
结果表明,10 个特征中的大约 3 个对预测很重要。
|
1 2 3 4 5 6 7 8 9 10 |
Feature: 0, Score: 0.00294 Feature: 1, Score: 0.00502 Feature: 2, Score: 0.00318 Feature: 3, Score: 0.00151 Feature: 4, Score: 0.51648 Feature: 5, Score: 0.43814 Feature: 6, Score: 0.02723 Feature: 7, Score: 0.00200 Feature: 8, Score: 0.00244 Feature: 9, Score: 0.00106 |
然后为特征重要性分数创建条形图。
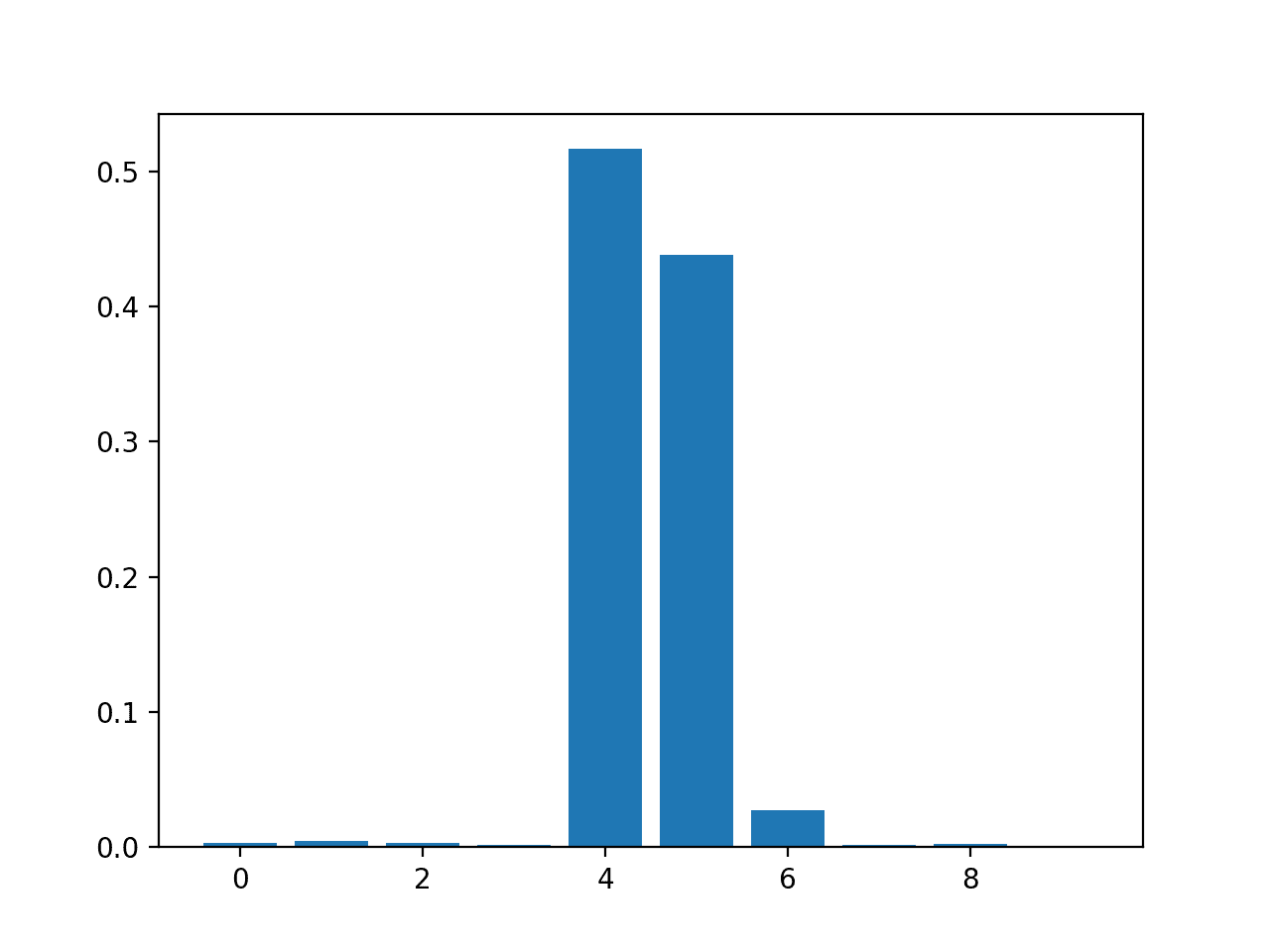
DecisionTreeRegressor 特征重要性分数条形图
CART 分类特征重要性
下面列出了拟合 DecisionTreeClassifier 并汇总计算出的特征重要性分数的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 用于分类问题的决策树特征重要性 from sklearn.datasets import make_classification from sklearn.tree import DecisionTreeClassifier from matplotlib import pyplot # 定义数据集 X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, n_redundant=5, random_state=1) # 定义模型 model = DecisionTreeClassifier() # 拟合模型 model.fit(X, y) # 获取重要性 importance = model.feature_importances_ # 总结特征重要性 for i,v in enumerate(importance): print('Feature: %0d, Score: %.5f' % (i,v)) # 绘制特征重要性 pyplot.bar([x for x in range(len(importance))], importance) pyplot.show() |
运行该示例会拟合模型,然后报告每个特征的系数。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行示例几次并比较平均结果。
结果表明,10 个特征中的大约 4 个对预测很重要。
|
1 2 3 4 5 6 7 8 9 10 |
Feature: 0, Score: 0.01486 Feature: 1, Score: 0.01029 Feature: 2, Score: 0.18347 Feature: 3, Score: 0.30295 Feature: 4, Score: 0.08124 Feature: 5, Score: 0.00600 Feature: 6, Score: 0.19646 Feature: 7, Score: 0.02908 Feature: 8, Score: 0.12820 Feature: 9, Score: 0.04745 |
然后为特征重要性分数创建条形图。
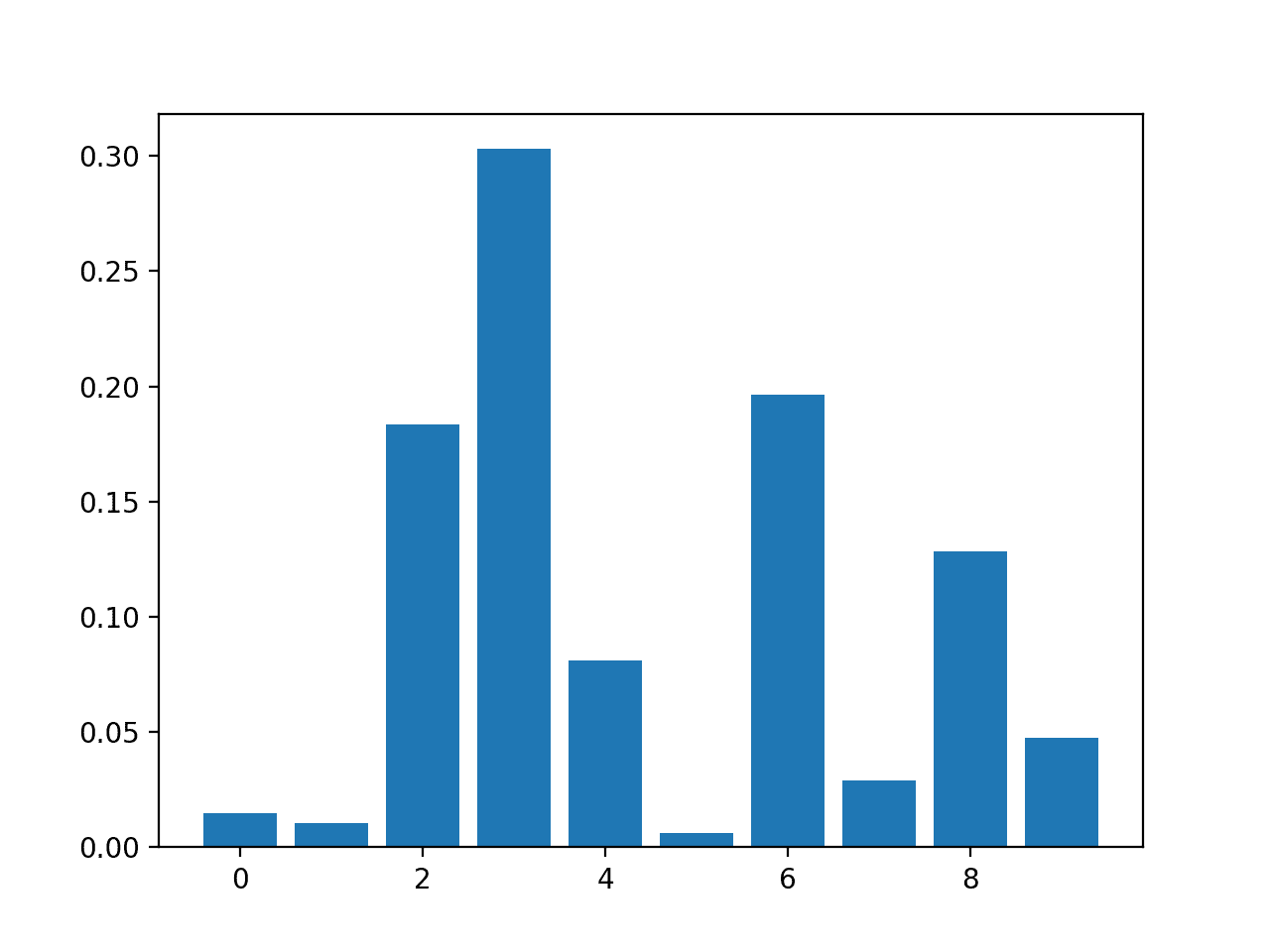
DecisionTreeClassifier 特征重要性分数条形图
随机森林特征重要性
我们可以使用 scikit-learn 中实现的用于特征重要性的 随机森林 算法,即 _RandomForestRegressor_ 和 _RandomForestClassifier_ 类。
拟合后,模型提供了一个 _feature_importances_ 属性,可以访问该属性以检索每个输入特征的相对重要性分数。
这种方法也可以与 bagging 和 extra trees 算法一起使用。
让我们看一个回归和分类的例子。
随机森林回归特征重要性
下面列出了拟合 RandomForestRegressor 并汇总计算出的特征重要性分数的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 用于回归问题的随机森林特征重要性 from sklearn.datasets import make_regression from sklearn.ensemble import RandomForestRegressor from matplotlib import pyplot # 定义数据集 X, y = make_regression(n_samples=1000, n_features=10, n_informative=5, random_state=1) # 定义模型 model = RandomForestRegressor() # 拟合模型 model.fit(X, y) # 获取重要性 importance = model.feature_importances_ # 总结特征重要性 for i,v in enumerate(importance): print('Feature: %0d, Score: %.5f' % (i,v)) # 绘制特征重要性 pyplot.bar([x for x in range(len(importance))], importance) pyplot.show() |
运行该示例会拟合模型,然后报告每个特征的系数。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行示例几次并比较平均结果。
结果表明,10 个特征中的大约 2 或 3 个对预测很重要。
|
1 2 3 4 5 6 7 8 9 10 |
Feature: 0, Score: 0.00280 Feature: 1, Score: 0.00545 Feature: 2, Score: 0.00294 Feature: 3, Score: 0.00289 Feature: 4, Score: 0.52992 Feature: 5, Score: 0.42046 Feature: 6, Score: 0.02663 Feature: 7, Score: 0.00304 Feature: 8, Score: 0.00304 Feature: 9, Score: 0.00283 |
然后为特征重要性分数创建条形图。
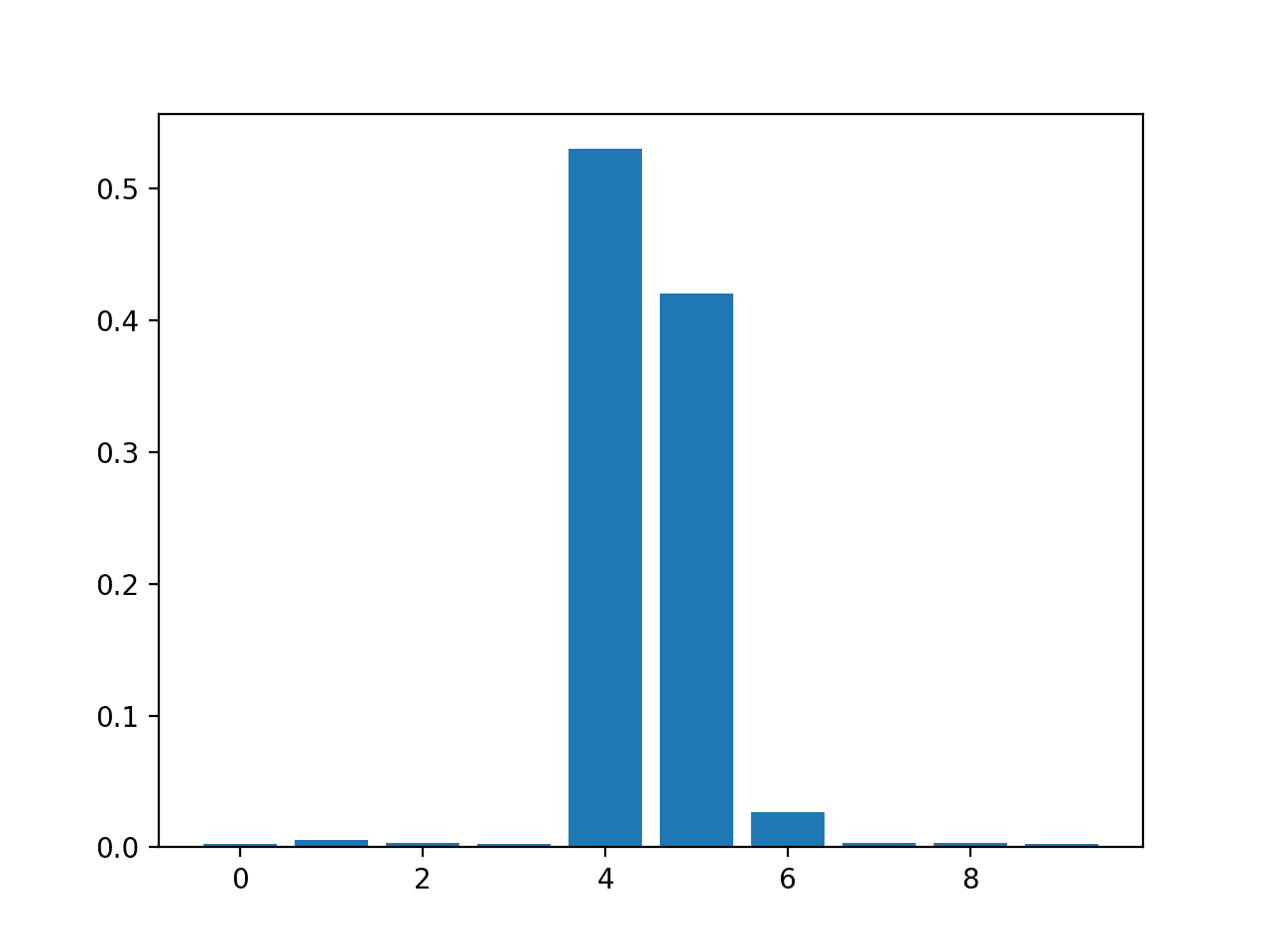
RandomForestRegressor 特征重要性分数条形图
随机森林分类特征重要性
下面列出了拟合 RandomForestClassifier 并汇总计算出的特征重要性分数的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 用于分类问题的随机森林特征重要性 from sklearn.datasets import make_classification from sklearn.ensemble import RandomForestClassifier from matplotlib import pyplot # 定义数据集 X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, n_redundant=5, random_state=1) # 定义模型 model = RandomForestClassifier() # 拟合模型 model.fit(X, y) # 获取重要性 importance = model.feature_importances_ # 总结特征重要性 for i,v in enumerate(importance): print('Feature: %0d, Score: %.5f' % (i,v)) # 绘制特征重要性 pyplot.bar([x for x in range(len(importance))], importance) pyplot.show() |
运行该示例会拟合模型,然后报告每个特征的系数。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行示例几次并比较平均结果。
结果表明,10 个特征中的大约 2 或 3 个对预测很重要。
|
1 2 3 4 5 6 7 8 9 10 |
Feature: 0, Score: 0.06523 Feature: 1, Score: 0.10737 Feature: 2, Score: 0.15779 Feature: 3, Score: 0.20422 Feature: 4, Score: 0.08709 Feature: 5, Score: 0.09948 Feature: 6, Score: 0.10009 Feature: 7, Score: 0.04551 Feature: 8, Score: 0.08830 Feature: 9, Score: 0.04493 |
然后为特征重要性分数创建条形图。
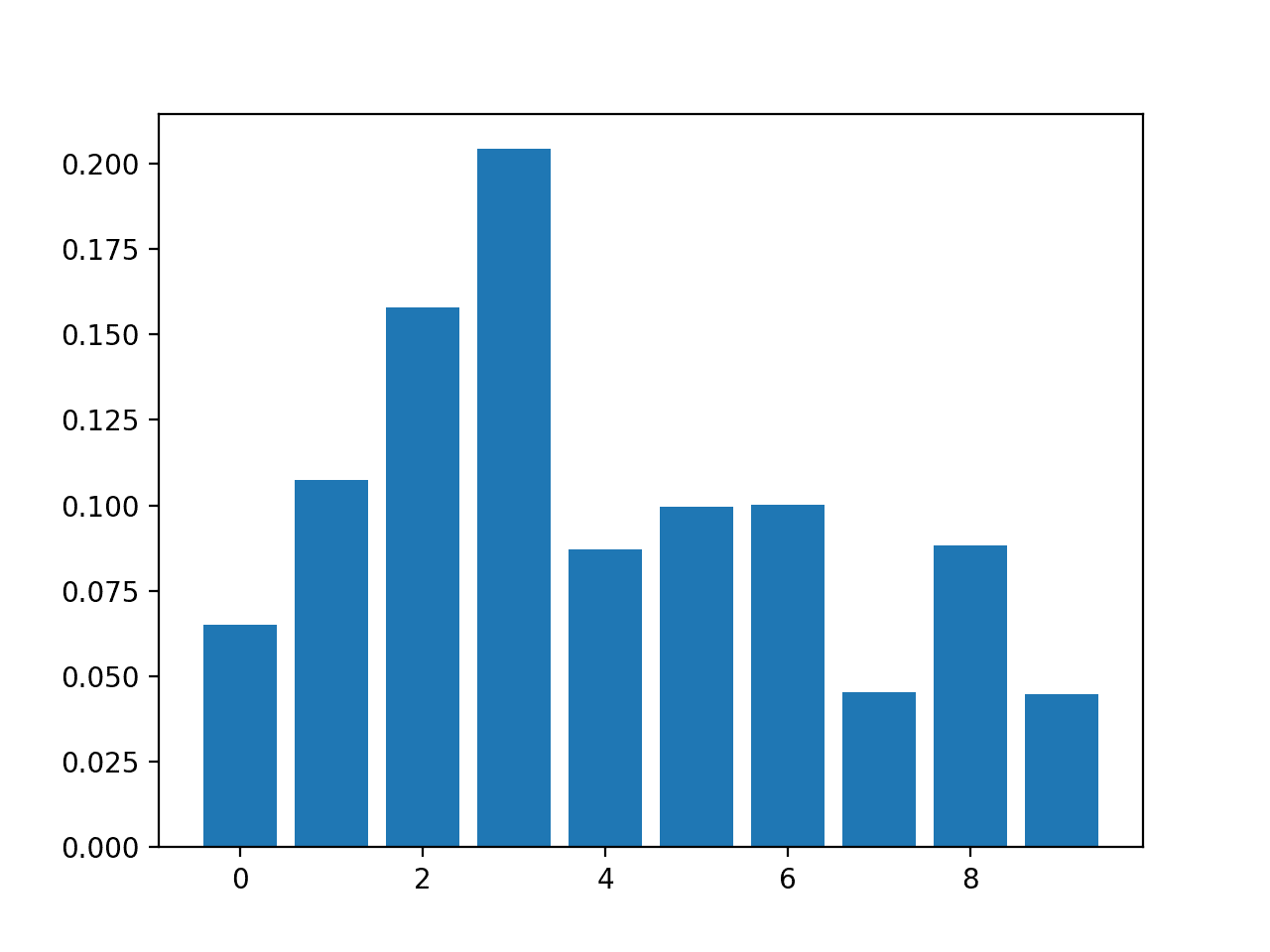
RandomForestClassifier 特征重要性分数条形图
XGBoost 特征重要性
XGBoost 是一个提供随机梯度提升算法的高效实现库。
该算法可以通过 _XGBRegressor_ 和 _XGBClassifier_ 类与 scikit-learn 一起使用。
拟合后,模型提供了一个 _feature_importances_ 属性,可以访问该属性以检索每个输入特征的相对重要性分数。
该算法也通过 _GradientBoostingClassifier_ 和 _GradientBoostingRegressor_ 类通过 scikit-learn 提供,并且可以使用相同的特征选择方法。
首先,安装 XGBoost 库,例如使用 pip:
|
1 |
sudo pip install xgboost |
然后,通过检查版本号来确认库是否已正确安装并正常工作。
|
1 2 3 |
# 检查 xgboost 版本 import xgboost print(xgboost.__version__) |
运行该示例,您应该会看到以下版本号或更高版本。
|
1 |
0.90 |
有关 XGBoost 库的更多信息,请从此处开始:
让我们来看一个在回归和分类问题上使用 XGBoost 进行特征重要性的示例。
XGBoost 回归特征重要性
下面列出了拟合 XGBRegressor 并汇总计算出的特征重要性分数的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 用于回归问题的 XGBoost 特征重要性 from sklearn.datasets import make_regression from xgboost import XGBRegressor from matplotlib import pyplot # 定义数据集 X, y = make_regression(n_samples=1000, n_features=10, n_informative=5, random_state=1) # 定义模型 model = XGBRegressor() # 拟合模型 model.fit(X, y) # 获取重要性 importance = model.feature_importances_ # 总结特征重要性 for i,v in enumerate(importance): print('Feature: %0d, Score: %.5f' % (i,v)) # 绘制特征重要性 pyplot.bar([x for x in range(len(importance))], importance) pyplot.show() |
运行该示例会拟合模型,然后报告每个特征的系数。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行示例几次并比较平均结果。
结果表明,10 个特征中的大约 2 或 3 个对预测很重要。
|
1 2 3 4 5 6 7 8 9 10 |
Feature: 0, Score: 0.00060 Feature: 1, Score: 0.01917 Feature: 2, Score: 0.00091 Feature: 3, Score: 0.00118 Feature: 4, Score: 0.49380 Feature: 5, Score: 0.42342 Feature: 6, Score: 0.05057 Feature: 7, Score: 0.00419 Feature: 8, Score: 0.00124 Feature: 9, Score: 0.00491 |
然后为特征重要性分数创建条形图。
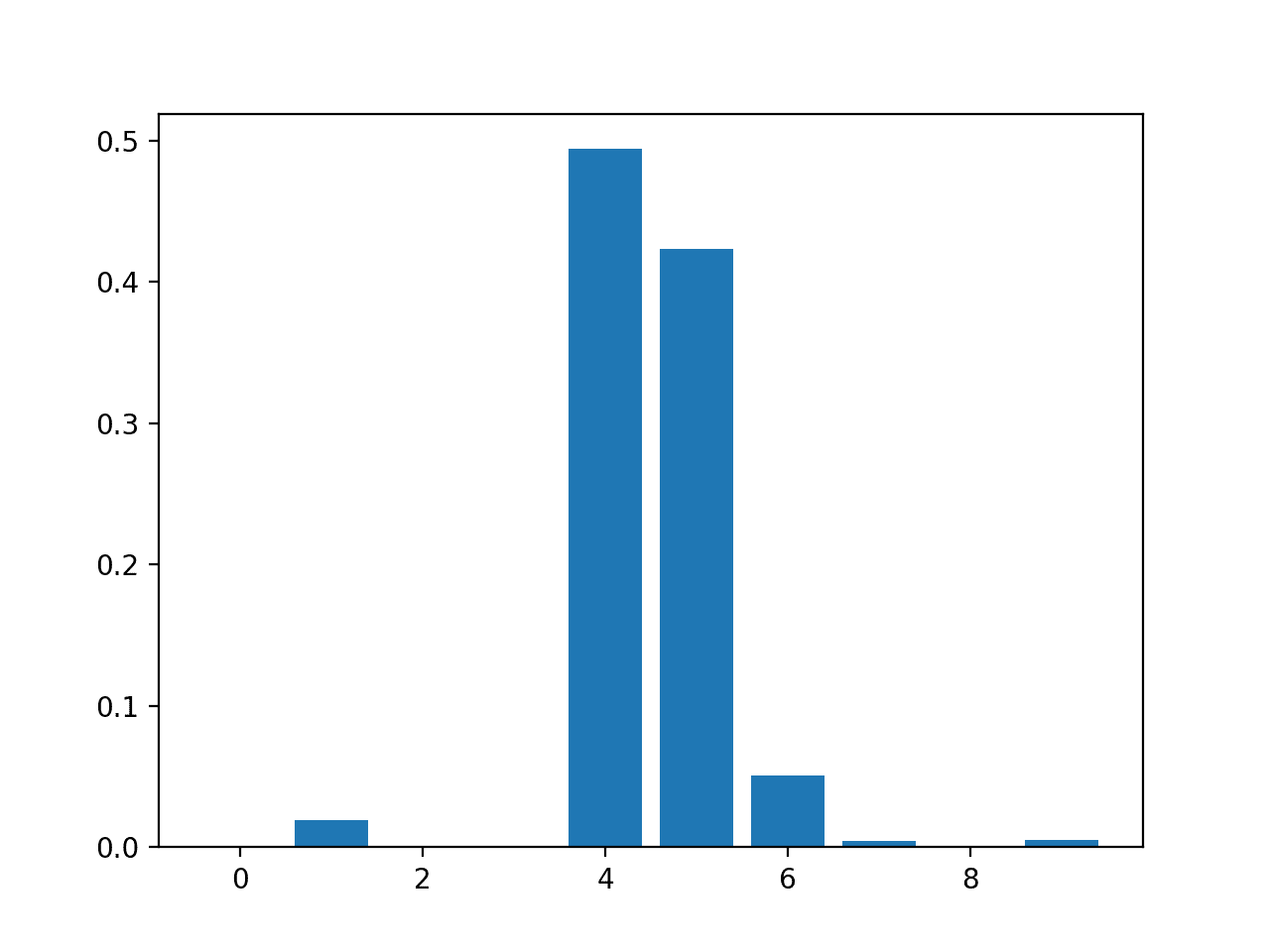
XGBRegressor 特征重要性分数条形图
XGBoost 分类特征重要性
下面列出了拟合 XGBClassifier 并汇总计算出的特征重要性分数的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 用于分类问题的 XGBoost 特征重要性 from sklearn.datasets import make_classification from xgboost import XGBClassifier from matplotlib import pyplot # 定义数据集 X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, n_redundant=5, random_state=1) # 定义模型 model = XGBClassifier() # 拟合模型 model.fit(X, y) # 获取重要性 importance = model.feature_importances_ # 总结特征重要性 for i,v in enumerate(importance): print('Feature: %0d, Score: %.5f' % (i,v)) # 绘制特征重要性 pyplot.bar([x for x in range(len(importance))], importance) pyplot.show() |
运行该示例会拟合模型,然后报告每个特征的系数。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行示例几次并比较平均结果。
结果表明,10 个特征中的大约 7 个对预测很重要。
|
1 2 3 4 5 6 7 8 9 10 |
Feature: 0, Score: 0.02464 Feature: 1, Score: 0.08153 Feature: 2, Score: 0.12516 Feature: 3, Score: 0.28400 Feature: 4, Score: 0.12694 Feature: 5, Score: 0.10752 Feature: 6, Score: 0.08624 Feature: 7, Score: 0.04820 Feature: 8, Score: 0.09357 Feature: 9, Score: 0.02220 |
然后为特征重要性分数创建条形图。
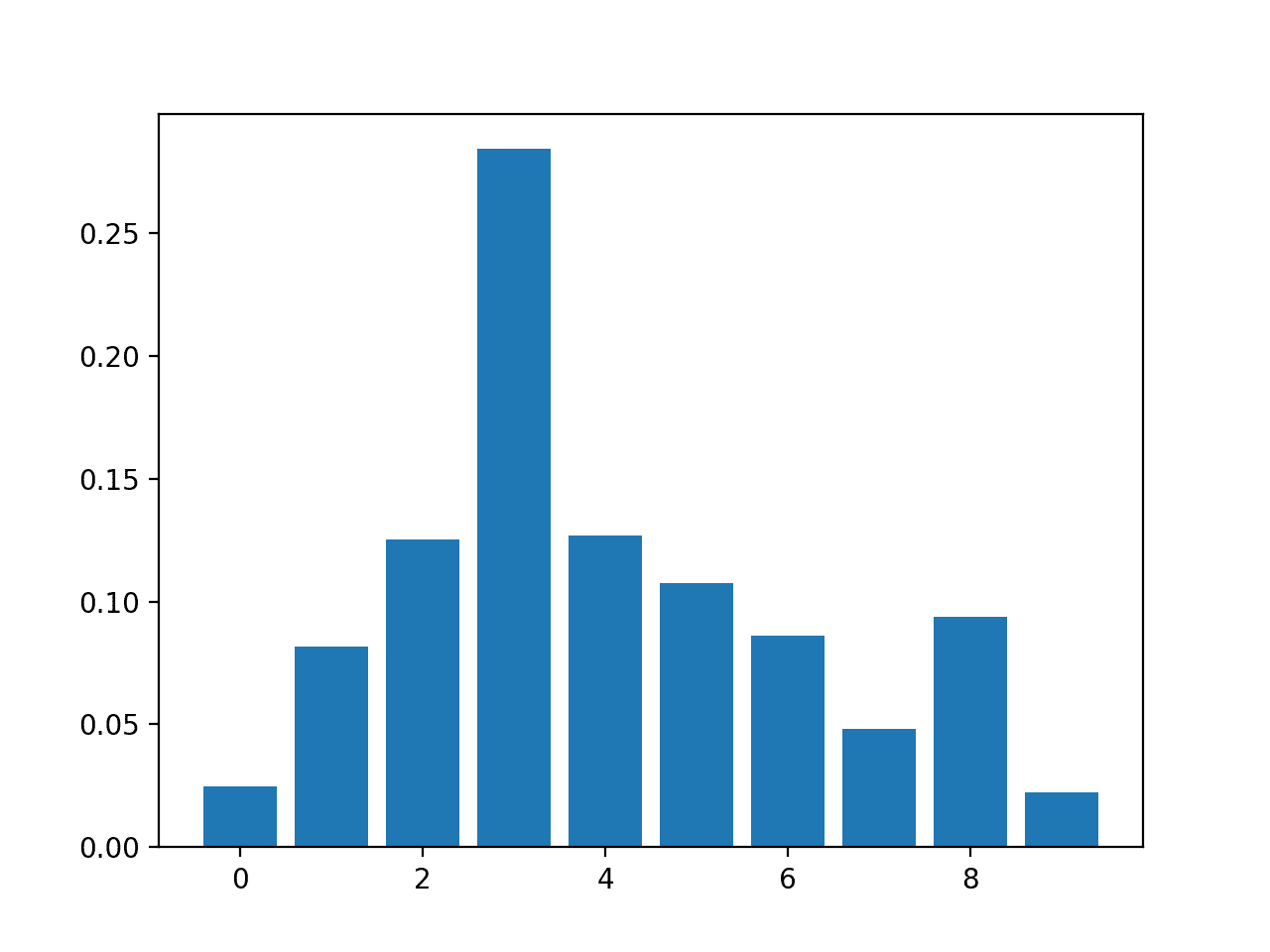
XGBClassifier 特征重要性分数条形图
置换特征重要性
置换特征重要性 是一种计算模型无关的相对重要性分数的技
首先,在数据集上拟合模型,例如不支持原生特征重要性分数的模型。然后,模型用于在数据集上进行预测,尽管数据集中的某个特征(列)的值被打乱了。这会为数据集中的每个特征重复一次。然后,整个过程重复 3、5、10 次或更多次。结果是每个输入特征的平均重要性分数(以及给定重复次数的分数分布)。
这种方法可用于回归或分类,并且需要选择一个性能指标作为重要性分数的基础,例如回归的均方误差和分类的准确率。
置换特征选择可以通过 permutation_importance() 函数 来使用,该函数接受一个拟合的模型、一个数据集(训练集或测试集均可)以及一个评分函数。
让我们用一个原生不支持特征选择的算法来研究这种特征选择方法,特别是 k-近邻。
置换特征重要性用于回归
下面列出了拟合 KNeighborsRegressor 并汇总计算出的置换特征重要性分数的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 使用 KNN 进行回归的置换特征重要性 from sklearn.datasets import make_regression from sklearn.neighbors import KNeighborsRegressor from sklearn.inspection import permutation_importance from matplotlib import pyplot # 定义数据集 X, y = make_regression(n_samples=1000, n_features=10, n_informative=5, random_state=1) # 定义模型 model = KNeighborsRegressor() # 拟合模型 model.fit(X, y) # 执行置换重要性 results = permutation_importance(model, X, y, scoring='neg_mean_squared_error') # 获取重要性 importance = results.importances_mean # 总结特征重要性 for i,v in enumerate(importance): print('Feature: %0d, Score: %.5f' % (i,v)) # 绘制特征重要性 pyplot.bar([x for x in range(len(importance))], importance) pyplot.show() |
运行该示例会拟合模型,然后报告每个特征的系数。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行示例几次并比较平均结果。
结果表明,10 个特征中的大约 2 或 3 个对预测很重要。
|
1 2 3 4 5 6 7 8 9 10 |
Feature: 0, Score: 175.52007 Feature: 1, Score: 345.80170 Feature: 2, Score: 126.60578 Feature: 3, Score: 95.90081 Feature: 4, Score: 9666.16446 Feature: 5, Score: 8036.79033 Feature: 6, Score: 929.58517 Feature: 7, Score: 139.67416 Feature: 8, Score: 132.06246 Feature: 9, Score: 84.94768 |
然后为特征重要性分数创建条形图。
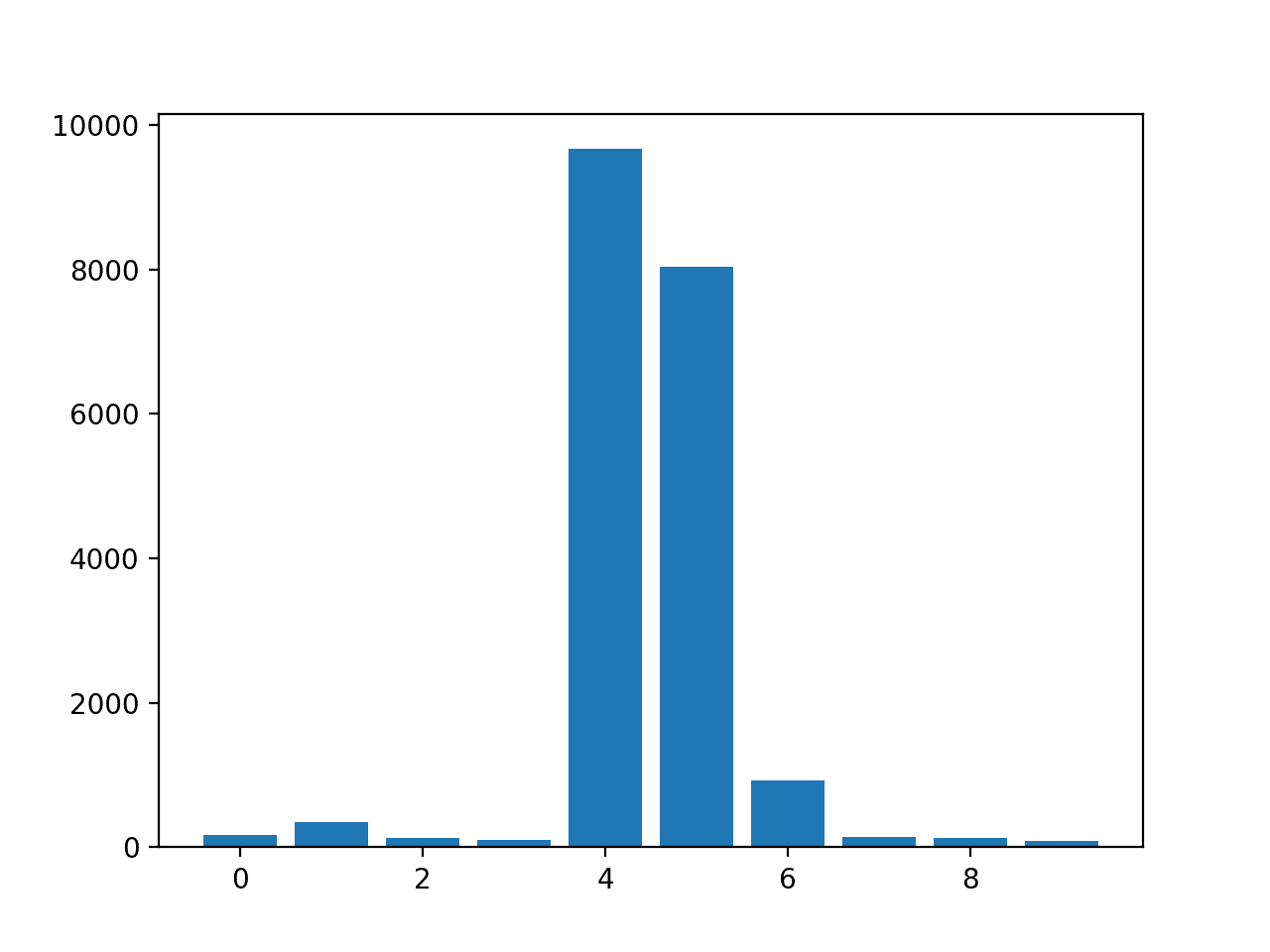
带有置换特征重要性分数的 KNeighborsRegressor 条形图
置换特征重要性用于分类
下面列出了拟合 KNeighborsClassifier 并汇总计算出的置换特征重要性分数的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 使用 KNN 进行分类的置换特征重要性 from sklearn.datasets import make_classification from sklearn.neighbors import KNeighborsClassifier from sklearn.inspection import permutation_importance from matplotlib import pyplot # 定义数据集 X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, n_redundant=5, random_state=1) # 定义模型 model = KNeighborsClassifier() # 拟合模型 model.fit(X, y) # 执行置换重要性 results = permutation_importance(model, X, y, scoring='accuracy') # 获取重要性 importance = results.importances_mean # 总结特征重要性 for i,v in enumerate(importance): print('Feature: %0d, Score: %.5f' % (i,v)) # 绘制特征重要性 pyplot.bar([x for x in range(len(importance))], importance) pyplot.show() |
运行该示例会拟合模型,然后报告每个特征的系数。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行示例几次并比较平均结果。
结果表明,10 个特征中的大约 2 或 3 个对预测很重要。
|
1 2 3 4 5 6 7 8 9 10 |
Feature: 0, Score: 0.04760 Feature: 1, Score: 0.06680 Feature: 2, Score: 0.05240 Feature: 3, Score: 0.09300 Feature: 4, Score: 0.05140 Feature: 5, Score: 0.05520 Feature: 6, Score: 0.07920 Feature: 7, Score: 0.05560 Feature: 8, Score: 0.05620 Feature: 9, Score: 0.03080 |
然后为特征重要性分数创建条形图。
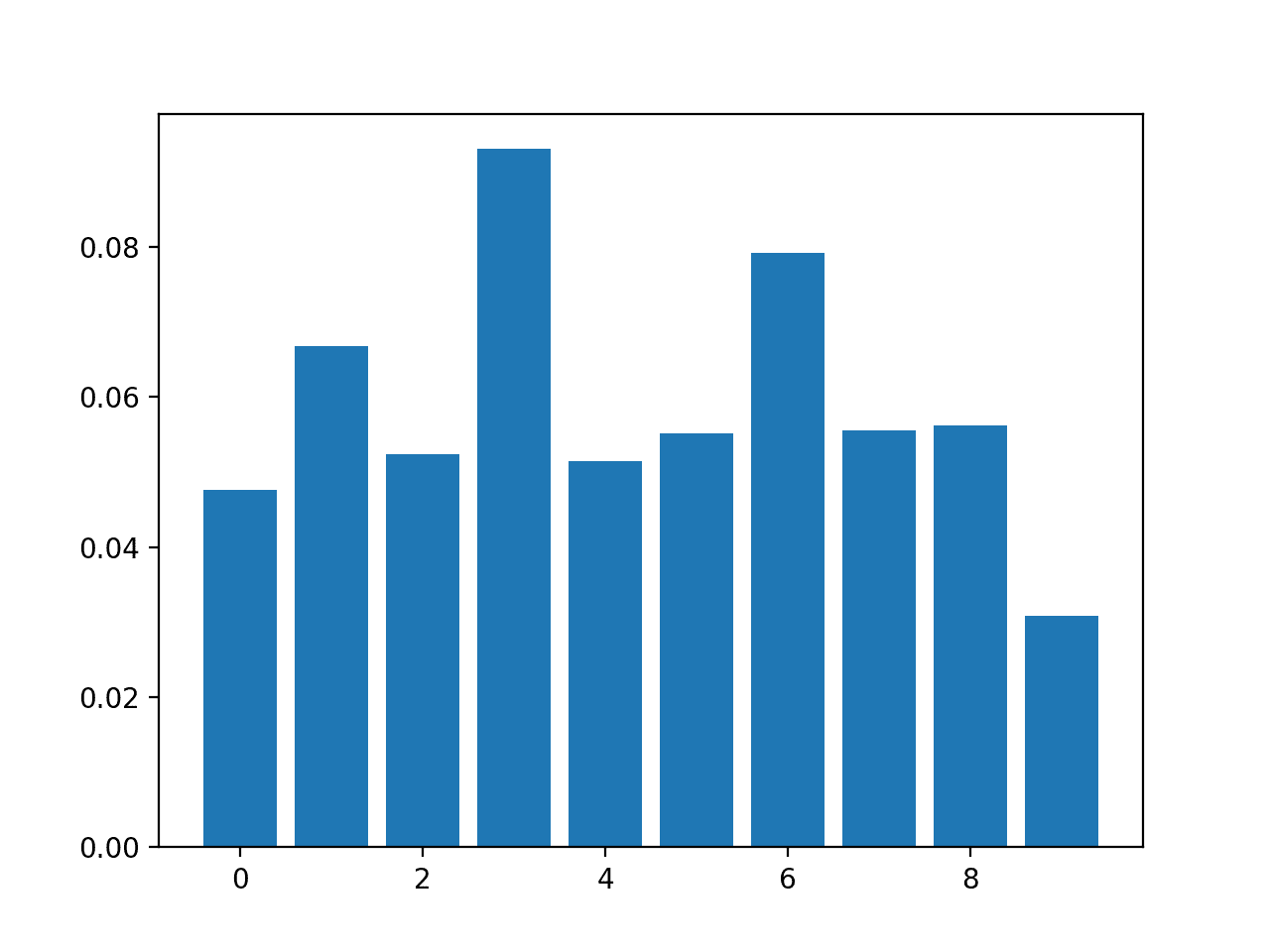
带有置换特征重要性分数的 KNeighborsClassifier 条形图
使用重要性进行特征选择
特征重要性分数可用于帮助解释数据,但也可以直接用于帮助对预测模型最有用的特征进行排名和选择。
我们可以用一个小的例子来演示这一点。
回想一下,我们的合成数据集有 1,000 个样本,每个样本有 10 个输入变量,其中五个是冗余的,五个对结果很重要。我们可以使用特征重要性分数来帮助选择五个相关的变量,并将它们作为输入到预测模型中。
首先,我们可以将训练数据集分割为训练集和测试集,并在训练数据集上训练模型,在测试集上进行预测,并使用分类准确率来评估结果。我们将使用逻辑回归模型作为预测模型。
这为我们删除特征时进行比较提供了基线。
下面列出了使用数据集中的所有特征评估逻辑回归模型的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 使用所有特征的模型的评估 from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score # 定义数据集 X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, n_redundant=5, random_state=1) # 拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # 拟合模型 model = LogisticRegression(solver='liblinear') model.fit(X_train, y_train) # 评估模型 yhat = model.predict(X_test) # 评估预测 accuracy = accuracy_score(y_test, yhat) print('Accuracy: %.2f' % (accuracy*100)) |
运行该示例首先在训练数据集上拟合逻辑回归模型并对其进行评估。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行示例几次并比较平均结果。
在这种情况下,我们可以看到模型使用数据集中的所有特征达到了大约 84.55% 的分类准确率。
|
1 |
Accuracy: 84.55 |
考虑到我们创建了数据集,我们期望使用一半数量的输入变量能获得更好的或相同的结果。
我们可以使用上面探索过的任何特征重要性分数,但在这种情况下,我们将使用随机森林提供的特征重要性分数。
我们可以使用 SelectFromModel 类来定义我们希望计算重要性分数的模型,在本例中是 RandomForestClassifier,以及要选择的特征数量,本例中为 5。
|
1 2 3 |
... # 配置以选择特征子集 fs = SelectFromModel(RandomForestClassifier(n_estimators=200), max_features=5) |
我们可以将特征选择方法拟合到训练数据集上。
这将计算可用于对所有输入特征进行排名的重要性分数。然后,我们可以将该方法作为转换应用,从数据集中选择 5 个最重要的特征子集。此转换将应用于训练数据集和测试集。
|
1 2 3 4 5 6 7 |
... # 从训练数据中学习关系 fs.fit(X_train, y_train) # 转换训练输入数据 X_train_fs = fs.transform(X_train) # 转换测试输入数据 X_test_fs = fs.transform(X_test) |
将所有内容联系起来,下面列出了使用随机森林特征重要性进行特征选择的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
# 使用随机森林重要性选择的 5 个特征的模型评估 from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.feature_selection import SelectFromModel from sklearn.ensemble import RandomForestClassifier from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score # 特征选择 def select_features(X_train, y_train, X_test): # 配置以选择特征子集 fs = SelectFromModel(RandomForestClassifier(n_estimators=1000), max_features=5) # 从训练数据中学习关系 fs.fit(X_train, y_train) # 转换训练输入数据 X_train_fs = fs.transform(X_train) # 转换测试输入数据 X_test_fs = fs.transform(X_test) return X_train_fs, X_test_fs, fs # 定义数据集 X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, n_redundant=5, random_state=1) # 拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # 特征选择 X_train_fs, X_test_fs, fs = select_features(X_train, y_train, X_test) # 拟合模型 model = LogisticRegression(solver='liblinear') model.fit(X_train_fs, y_train) # 评估模型 yhat = model.predict(X_test_fs) # 评估预测 accuracy = accuracy_score(y_test, yhat) print('Accuracy: %.2f' % (accuracy*100)) |
运行该示例首先对数据集执行特征选择,然后像之前一样拟合和评估逻辑回归模型。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行示例几次并比较平均结果。
在这种情况下,我们可以看到模型在使用一半的输入特征的情况下,在数据集上实现了相同的性能。正如预期的那样,随机森林计算出的特征重要性分数使我们能够准确地对输入特征进行排名,并删除与目标变量无关的特征。
|
1 |
Accuracy: 84.55 |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
相关教程
书籍
- 应用预测建模, 2013.
API
- 特征选择,scikit-learn API.
- 置换特征重要性,scikit-learn API.
- sklearn.datasets.make_classification API.
- sklearn.datasets.make_regression API.
- XGBoost Python API 参考.
- sklearn.inspection.permutation_importance API.
总结
在本教程中,您了解了 Python 中机器学习的特征重要性分数。
具体来说,你学到了:
- 特征重要性在预测建模问题中的作用。
- 如何从线性模型和决策树计算和审查特征重要性。
- 如何计算和审查置换特征重要性分数。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。




 from Scratch in Python")


本教程缺少最重要的一点——特征重要性与置换重要性之间的比较。选择哪种,为什么?
有兴趣的读者请看:https://explained.ai/rf-importance/
比较广义线性模型(线性回归、逻辑回归等)中特征重要性的最佳方法是将特征系数乘以变量的标准差。它会给你标准化后的 Beta 值,不受变量尺度度量的影响。因此,它们是可比较的。
缩放或标准化变量仅在您只有数值数据时有效,而在实际中……很少发生!
比较需要一个上下文,例如您有兴趣解决的特定数据集和模型套件。
嘿,Jason
如果我有一个数值数据集,大约有 40 个自变量和一个名为 quality 的因变量。我想找到导致 quality 下降的特征,或者哪些特征对因变量影响最大。
但是,自变量中存在多重共线性,因此我需要先根据内部共线性对所有自变量进行分组,然后找到对 quality 影响最大的特征。
特征重要性将提供每个变量对因变量影响的逐变量的观点,同时考虑模型支持的交互作用。
你好,你能帮我解答我的问题吗?在执行 RFE 后,假设我得到了一个 10 个特征的模型子集。如果我查看这些特征的排名,很明显每个特征都排名为“1”。但是,我需要知道所选子集中特征的重要性。用于可视化/比较每个特征的标准是什么?
谢谢你
通常,一个子集作为一个整体会提供一些信息给目标变量。单个特征可能不像与另一个特征互补时那么强大。话虽如此,量化重要性的一种方法是使用相关系数。越接近零,特征越弱。
嗨 Martin,
如果你已经用 StandardScaler 缩放了你的数值数据集,你是否还需要通过将系数乘以 std 来对特征进行排名,或者因为它已经被缩放了,所以系数排名足够了?
谢谢
Luigi
嗨 Martin,
你能详细说明一下吗?哪个方法中的系数?假设有一个用于分类的神经网络,特征数量很大,我认为任何权重本身都没有意义。
嗨,Jason!
感谢您提供的精美代码示例和解释。不过,关于随机森林特征重要性的一点评论:使用
importance = model.feature_importances_
的特征重要性是否可能因连续特征和高基数分类特征而产生偏差?
最好的祝福
奥利弗
可能是的,你为什么这么说?
几年前,我偶然发现了这篇发布时的帖子,其中讨论了如何谨慎解释随机森林的特征重要性。我曾使用 scikit-learn 和 R 中的其他一些包来举例说明。
https://explained.ai/rf-importance/index.html
这与 Martin 上面提到的相同。
最好的祝福
奥利弗
感谢分享。
谢谢 Jason,这非常有信息量。
作为数据科学新手,我有一个问题:
特征重要性的概念是否适用于所有方法?深度学习方法(CNN、LSTM)呢?BERT呢?我直觉上认为,无论使用何种方法,都应该有类似的功能,但在线搜索时发现答案并不明确。我想我缺乏一些基本的、关键的知识。
是的,但使用的方法不同。
这里,我们专注于表格数据。
嗨 Jason,感谢您的帖子!
LSTM 有哪些其他不同的方法?
这里的不同方法意味着我们可能看不到特征那么容易。以图像数据为例,众所周知,处理图像并找到边缘(例如,将彩色照片转换为铅笔画)会有所帮助。
你好 Adrian,
我不明白你的意思。你能具体说明一下吗?我应该如何获得 LSTM 模型的置换特征重要性?我在网上找不到太多关于这方面的信息。
这取决于问题的性质和数据集。LSTM 是一个模型,但在这里不重要。你应该看看数据集,找出你可以提供哪些特征。
你好,我是一名新生,我想知道随着深度学习自动查找特征的发展,手动和有效地构建特征的特征工程是否会过时?如果不是,在哪里可以使用特征工程比深度学习更好?
它会执行特征提取。
即便如此,这些模型也可能不比其他方法表现更好。
谢谢你。
不客气。
你好,我也是新手。我想问一下,是否有办法使用 Keras 实现“分类的置换特征重要性”?
我不知道为什么不行。将 Keras 包装类用于您的模型。
你好。只是对你的评论做一点补充。请注意 RF 中使用标准特征重要性度量的特征重要性。参见:https://explained.ai/rf-importance/
请继续保持出色的工作!
感谢分享。
嗨,Jason,
请问您是否计划发布一些关于知识图谱(嵌入)的实用内容?
谢谢,Bill
谢谢你的建议 Bill!
您的教程非常有趣。
谢谢。
嗨,Jason,
非常感谢您的帖子。一如既往地非常有趣!
我可以得出结论,每种方法(线性、逻辑、随机森林、XGBoost 等)都可以提供其计算特征重要性的方式吗?
谢谢你。
谢谢。
是的,我们可以从许多不同的角度来了解什么重要。
嗨 Jason!!
此方法适用于包含分类和连续特征的数据吗?或者我必须将这些特征分开然后计算特征重要性,但我认为这不是一个好的做法!
另外,一个无关紧要的问题是,我能否对分类特征应用 P.C.A?如果不能,是否有等效的分类特征方法?
我相信是的。
不。PCA 是用于数值数据的。
L.D.A 是用于分类值的吗?
LDA – 线性判别分析 – 不,它也是用于数值值的。
你好 Jason,我从你的网站上学到了很多关于机器学习的知识。顺便问一下,你对如何了解使用 Keras 模型进行特征重要性有什么想法吗?
谢谢。
试试:置换特征重要性
嗨,Jason,
我是一名来自科罗拉多州的数据分析研究生,您的网站一直是我的学习宝库!
关于在机器学习过程中进行特征选择的顺序,我有一个问题。我的数据集存在严重的类别不平衡(95%/5%)且有许多 NaN 需要填充。一位教授还建议将 PCA 与特征选择一起进行。您建议将特征选择放在哪个位置?我的初步计划是:填充 -> 特征选择 -> SMOTE -> 缩放 -> PCA。
为了提供更多背景信息,数据有 180 万行,65 列。目标变量是二元的,列大部分是数值型的,其中一些分类特征经过了独热编码。
非常感谢您的指导!
谢谢,很高兴听到这个。
进行实验以发现最有效的方法。
我会选择 PCA 或特征选择,而不是两者都选。我可能会先缩放,然后抽样,再选择。但也可以尝试先缩放,再选择,然后抽样。
嗨,Jason
感谢您的帖子!
关于类别不平衡数据集的特征重要性分数,我有一个问题。类别不平衡是否会影响特征重要性的解释?换句话说,如果一个二元分类器(例如随机森林)在一个高度偏斜的数据集上拟合,那么从模型中获得的特征重要性分数是否仍然可信?谢谢~
这可能会,具体取决于使用的方法。非常有可能。
也许可以测试一系列方法,并比较在选定特征上拟合的模型的结果。
感谢 Jason 提供此信息。
不客气!
嗨,Jason,
我正在运行决策树回归器来识别最重要的预测变量。我得到的结果格式与您提供的格式相同。但是,我无法理解“Feature 1”的含义以及数字的意义。
我也运行了随机森林回归器,但由于缺少标签,无法比较结果。请提供 Python 代码来映射适当的字段和绘制。
谢谢
如果您有一系列字符串名称作为每个列的名称,那么特征索引将与列名称索引相同。
这有帮助吗?
你好 Jason 🙂 感谢这个非常有用的例子!
我有一个非常相似的问题:我没有字符串名称列表,而是通过管道模型使用缩放器和独热编码器。您是否有任何提示,如何在使用独热编码和模型中同时包含数值变量后,找出哪个特征编号对应哪个特征名称? :-/
提前非常感谢!
不,您可以通过手动进行编码来将二进制变量映射到分类标签。
你好 Jason 🙂
感谢您的回复!以防对其他人有用
我发现了一个访问 Column_Transformer 中列名的好方法
(参见此处用于访问转换数据后的名称的 def
https://johaupt.github.io/scikit-learn/tutorial/python/data%20processing/ml%20pipeline/model%20interpretation/columnTransformer_feature_names.html)
(希望在这里发布此链接没问题?)事实证明,这正是我的问题所在 >.<
非常感谢您的内容,它非常有帮助!
很高兴听到您解决了问题。
先生,
使用 SelectKbest 从 sklearn 识别最佳特征怎么样??
它在计算上与上述方法有何不同?
提前致谢
是的,它允许您使用特征重要性作为特征选择方法。
嗨,Jason,
很棒的帖子和精美的代码示例。我刚接触机器学习领域。我尝试了我自己的数据集并拟合了一个简单的决策树(分类器 0,1)。模型准确率为 0.65。当我查看特征重要性时,我感到非常惊讶。它们全部为 0.0(7 个特征,其中 6 个是数值型的)。这怎么可能?
祝好
Alex
谢谢。
65% 较低,接近随机。也许特征重要性无法提供对您数据集的洞察。它不是绝对重要性,更像是一种建议。
好的,谢谢,是的,这确实几乎是随机的。但即便如此,我也期望看到一些非常小的数字,比如 0.01 左右,因为所有特征都完全是 0.0……总之,我会查看并使用您精彩的博客和评论进行进一步学习。谢谢。
我看到许多读者链接了文章“Beware Default Random Forest Importances”,该文章比较了 sklearn 中默认的 RF Gini 重要性与置换重要性方法。我相信提到另一种趋势方法,称为 SHAP,是值得的。
https://www.kaggle.com/wrosinski/shap-feature-importance-with-feature-engineering
https://towardsdatascience.com/explain-your-model-with-the-shap-values-bc36aac4de3d
最近我将其用作特征选择的几种并行方法之一。由于它使用独立的方法来计算重要性(与 Gini 或置换方法相比),它似乎值得我们关注。它也有助于可视化变量如何影响模型输出。您对此有任何经验或评论吗?
此致!
感谢分享。
嗨,Jason,
非常感谢您提供这些有用的帖子和书籍!
您能否分享一下您对通过检索系数或直接使用内置绘图函数来获取 XGBoost 模型特征重要性的区别的看法?
我认为两者提供的的重要性分数相同。您具体是指什么?
我目前正在使用特征重要性分数来对我的数据集的输入进行排名。我发现,通过 model.feature_importances_ 检索系数或通过内置绘图函数 plot_importance(model) 获得的分数不同(重要性顺序也不同)。使用的具体模型是 XGBRegressor(learning_rate=0.01,n_estimators=100, subsample=0.5, max_depth=7 )
因此,我想知道它们是否使用不同的策略来解释特征在模型上的相对重要性……以及哪种方法最适合决定何时以及选择哪种。
再次感谢 Jason,感谢您所有的辛勤工作。
可能使用了不同的度量标准来生成绘图。
我认为我以前见过这种情况,看看用于生成绘图的函数的参数。
嗨 Jason,谢谢,这很有用。
我在回归的置换特征重要性方面遇到一些困难。我对
评分“MSE”。“MSE”越接近 0,模型的性能越好。当
根据“置换重要性算法大纲”,重要性是原始“MSE”与新“MSE”之间的差值。也就是说,差值越大,原始特征越不重要。但文章的意思是,差值越大,特征越重要。
这可能有助于解决实施细节
https://scikit-learn.cn/stable/modules/generated/sklearn.inspection.permutation_importance.html
大家好,
除了模型性能指标(MSE、分类错误等)之外,还有其他方法可以可视化这些算法排名的变量的重要性吗?
例如,当将重要特征绘制与索引(趋势图)或二维散点图数组绘制时,您是否会看到数据中的分离(如果存在)?
排名前列的变量是否总是显示最大的分离(如果数据中存在)?还是通常需要搜索列表才能在深入研究时看到内容?如果必须搜索,那么当深入研究列表不一致时,排名又有什么意义?
如果一个“重要”变量在趋势图或二维散点图中看不到任何东西怎么办?如果看不到任何东西,就无法采取措施解决问题,那么它们真的“重要”吗?
如果在高维空间中一个变量很重要,并且有助于提高准确性,它是否总是在趋势图或二维图中显示出一些东西?如果不是,如何让任何人相信它很重要?
我认为变量重要性非常难以解释,尤其是当您拟合高维模型时。
我希望听到一些有趣的见解。
非常感谢!
Alex
SeasonWarez
是的,本教程中使用的条形图是可视化特征重要性的一种方式。
也许我不理解你的问题?
条形图不是实际数据本身。对于这些具有重要性的高维模型,您是否期望在趋势图或 F1vsF2 等的二维图中看到任何内容?
如果您在实际数据中看不到任何内容,如何做出决定或对这些重要变量采取行动?
例如,如果您按分类中的 Good/Bad Group1/Group2 对数据进行着色。或者如果您在回归中计算 X 和 Y 之间的相关性。
如果您使用这些高维模型,那么在数据钻取中看不到任何内容的可能性是否会增加?如果您在数据钻取中看不到任何内容,如何采取行动?真的有什么有意义的东西在高维空间中吗?
这就是我遇到的与使用模型的自动排名方法相关的问题。
它们可能有用,例如,在每个视角或每个特征子集上拟合一个模型,比较结果,然后选择导致最佳主模型性能的特征。这比穷举搜索子集更快,尤其是在特征数量非常大的情况下。
每个算法对于重要性的看法都不同。我个人将任何特征重要性的结果都视为建议,可能是在建模过程中,也可能是在问题总结过程中。
我觉得我没表达清楚,哈哈。
你关注的是在准确率(MSE等)方面获得最佳模型。是的,特征选择对于该任务肯定很有用,遗传算法也是一种可能派上用场的方法。
然而,在用模型解释异常值或数据中的故障时。或者在进行分类(如随机森林)以确定 GroupA/GroupB 之间的差异时。以及对变量进行排名。
在解释输入变量数据(我称之为“钻取”)时,我会将 Feature1 与 Index(或时间)绘制成所谓的“单变量趋势”。或者将 Feature1 与 Feature2 绘制成散点图。
现在,如果你有一个具有许多输入的“高维度”模型,你将获得一个排名。但即使你查看了单个输入趋势,或单个相关性,或 F2vsF2 散点图,你仍然可能一无所获。好/坏数据在低维度下不会在视觉上或统计上突出显示。
相关性会很低,而坏数据在重要变量中也不会显眼。
随着维度的不断提高,模型输入的数量也越来越多,这个问题会变得更加严重。
那么我的问题是,如果你有一个准确率很高但输入非常多的模型,当你看到数据中的异常值或偏移时,如何在低维度图表中看不到任何东西的情况下可视化它?如果问题确实是 4 维或更高维的问题,你如何可视化并对其采取行动?
非常感谢
感谢 Alex 的详细说明。
一种方法是使用流形学习,并将特征空间投影到低维空间,该空间保留了重要的属性/结构。
或许可以从 t-SNE 开始。
https://scikit-learn.cn/stable/modules/manifold.html
尊敬的Jason博士,
感谢您的本教程。
这是我对这行的理解——以鸢尾花数据集为例。
首先我们看内部函数
本质上,我们生成了一个决策树分类器的“骨架”。有 10 棵决策树。请注意,这是一个骨架。
对于下一个示例,我将使用来自
model =
我们可以拟合一个模型到决策树分类器。
你可能会问,为什么要把模型拟合到一堆决策树上?
在上面的例子中,我们用所有特征拟合了一个模型。
然后你可能会问,那这个呢:将 RandomForestClassifier 放入 SelectFromModel 中
在这种情况下,我们从 SelectFromModel 中获取了我们的模型“model”。在鸢尾花数据集中,有五个特征。这里,上面的函数 SelectFromModel 选择最多 3 个特征的“最佳”模型。
我们从 SelectFromModel 中获得了一个模型,而不是 RandomForestClassifier。所以我们不是在 RandomForestClassifier 上拟合模型,而是 RandomForestClassifier 提供决策树分类器的“骨架”。然后通过基于最佳三个特征选择模型来确定模型。
谢谢你
悉尼的Anthony
“SelectFromModel”不是一个模型,你不能用它来进行预测。
它是一个转换器,将使用其他模型(如 RF)作为指导来选择特征。
尊敬的Jason博士,
谢谢你
悉尼的Anthony
不客气。
尊敬的Jason博士,
需要在这里澄清一下“SelectFromModel”。
指本博客最后的代码行 12-14。
当“fs”被拟合在
时,我们该怎么做?
谢谢你,
悉尼的Anthony
它正在拟合转换器。
这里有一个使用鸢尾花数据集的例子。
鸢尾花数据集有四个特征,一个输出是分类的 0,1,2。
总而言之,model.fit 和 fs.fit 之间存在区别。
问题是 fs.fit 是什么?
谢谢你,
悉尼的Anthony
它拟合了转换器。
https://scikit-learn.cn/stable/modules/generated/sklearn.feature_selection.SelectFromModel.html#sklearn.feature_selection.SelectFromModel.fit
尊敬的Jason博士,
我查看了 fit 的定义,如
这个含义并没有让我更清楚。
为什么开发人员不能说 fit(X) 方法获取 X 的最佳拟合列呢?
这是因为当你打印模型时,你会得到 X 的特征子集。
对我来说,“transform”这个词意味着进行某种数学运算。
但在这种情况下,“transform”意味着获取最能解释 y 的预测的特征。
谢谢你,
悉尼的Anthony
尊敬的Jason博士,
为了总结,我们想知道由 SelectFromModel 确定的特征的名称。
希望这有帮助,
悉尼的Anthony
尊敬的Jason博士,
再次为“替代”方法获取名称表示歉意。请忽略最后一条,因为结果不正确。
抱歉
悉尼的Anthony
而是替代方法是
这是使用“zip”函数的正确替代方法。
再次抱歉。
悉尼的Anthony
这是数学上的。
在这种情况下,transform 指的是 Xprime = f(X),其中 Xprime 是 X 的列的子集。
谢谢你,
悉尼的Anthony
不客气。
尊敬的Jason博士,
再次感谢您的教程。
我曾尝试过 RFE 和 GradientBoosterClassifier 等方法,并确定了一组要使用的特征。我从尝试鸢尾花数据中发现,GradientBoosterClassifier 会“确定”2 个特征能最好地解释模型以预测物种,而 RFE 则“确定”3 个特征能最好地解释模型以预测物种。
问题
尝试 GradientBoostClassifier 确定了 2 个特征,而 RFE 确定了 3 个特征。
特征选择的结果必须相同吗?
换句话说,是否需要调整 GradientBoostClassifier 和 RFE 的参数以获得相同的结果。
谢谢你,
悉尼的Anthony
很好的问题。
不,每种方法对哪些特征重要都会有不同的看法。
谢谢你,
悉尼的Anthony
不客气。
感谢 Jason 分享有价值的内容。
您能否澄清一下,如果其中一个输入特征与类别属性相同,分类准确率会受到什么影响?
不客气!
如果类标签被用作模型的输入,那么模型应该达到完美的技能。事实上,模型是不需要的。
你好!感谢这篇精彩的文章!!
我刚接触机器学习,有两个关于特征重要性计算的问题。
首先,出于某种原因,在使用 coef_ 时,在拟合了线性回归模型之后,我得到了一些特征的负值,这正常吗?如果正常,那对这些特征意味着什么?或许(因为我们谈论的是线性回归)第一个特征的值越小,第二个特征(或目标值,取决于我们比较的是哪些变量)的值就越大。对于逻辑回归,特征与一个类或另一个类相关是很直接的,但在线性回归中,负值非常令人困惑,您能否分享一下您的看法?
其次,也许不是完全关于这个主题,但我认为仍然值得一提。场景如下。当尝试像上面示例那样使用 DecisionTreeRegressor 的 feature_importance_ 时,唯一的区别是我使用了我自己的一个数据集。当我多次尝试相同的脚本配置时,如果数据集是使用 train_test_split 分割的,并且 random_state 参数等于一个特定的整数,每次运行脚本时我都会得到不同的结果。唯一获得相同结果的方法是设置 random_state 等于 false(甚至不是 None,这是默认值)。从 sklearn 的文档中,我理解使用一个 int random_state 会导致“跨多个函数调用的可重复输出”,而且这确实每次都会产生相同的分割;但是,当涉及到获取 DecisionTreeRegressor 模型的 feature_importance_ 时,结果每次都会不同?这如何以及为何可能?
不客气。
是的,这是可以预料的。如果用作重要性分数,请先将所有值设为正数。
您可能还需要设置模型的种子。
感谢快速回复!
对于第一个问题,我已确保所有特征值均为正数,方法是使用 MinMaxScaler 进行标准化时设置 feature_range=(0,1) 参数,但遗憾的是我仍然得到负系数。
对于第二个问题,您完全正确,一旦我为 DecisionTreeRegressor 包含了特定的 random_state,我就会在重复后获得相同的结果。
抱歉,我的意思是您可以在将系数解释为重要性分数之前,先将它们本身设为正数。
Jason 医生您好。这些方法中有哪些适用于时间序列?如果我将我的时间序列转换为监督学习问题,就像您在之前的教程中所做的那样,我仍然可以使用随机森林进行特征重要性吗?我不知道 X 和 y 是什么。
不,我认为您需要使用专为时间序列设计的方法。
我希望将来能写关于它们的内容。
对于滞后观测的重要性,也许 ACF/PACF 是一个不错的开始。
https://machinelearning.org.cn/gentle-introduction-autocorrelation-partial-autocorrelation/
嗨,Jason Brownlee,
感谢这篇帖子。
您如何说在某些情况下重要特征。
1) 随机森林用于分类问题的特征重要性(两个或三个,而条形图与其他特征非常接近)
2) xgboost 用于分类问题的特征重要性(10 个特征中的 7 个被认为是重要的预测因子。) 0.5 和 1.0 之间有阈值吗?
3) 使用 KNN 进行分类的置换特征重要性(两个或三个,而条形图与其他特征非常接近)
谢谢,
Arul
抱歉,我不明白您的问题,也许您可以重述或重新表述一下?
尊敬的Jason博士,
感谢您的教程。
我正在使用特征重要性分数来对数据集的变量进行排名。
我通过随机森林和决策树获得了特征重要性分数。
我按照您关于分类模型的逐步教程进行了操作
使用模型特征重要性。
本教程显示了 1 次运行的重要性分数。但我想要 100 次运行中的特征重要性分数。
在 DF 和 RF 和 svm 模型的 100 次运行中,出现次数最多的变量必须排在第一位???
谢谢您。
您为什么要 100 次运行的分数?
我有 200 条记录和 18 个属性。
我的目标是对特征进行排名。
为了验证排名模型,我需要 100 次运行的平均值。
您有其他方法吗?
请在这方面帮助我。
您能否也教我们 Python 中的部分依赖图?
谢谢你
我不明白。如何精确评估排名特征?
感谢您的建议。
上面的教程中的特征重要性分数不能用来对变量进行排名吗?
如果是这样,这足够了吗??!!
单次运行将产生一个排名。多次运行将产生混乱。
Jason 您好,感谢精彩的教程。我有一个关于使用 Keras 包装器进行 CNN 模型的问题。CNN 需要 3 维输入,但 Scikit-learn 的 fit 函数只接受 2 维输入。我该如何满足 Keras 和 Scikit-learn 的 2D 和 3D 维度要求?我的部分代码如下,谢谢!
from keras.wrappers.scikit_learn import KerasRegressor
from sklearn.inspection import permutation_importance
from matplotlib import pyplot
# 我的输入 X 的形状为 (10000*380*1),有 380 个输入特征
# 定义模型
from tensorflow.keras.models import Sequential
from tensorflow.keras import layers
def base_model()
model = Sequential()
model.add(layers.Conv1D(40,7, activation=’relu’, input_shape=(input_dim,1))) #CONV1D 需要 3D 输入
model.add(layers.MaxPooling1D(4))
model.add(layers.Conv1D(60,11, activation=’relu’))
model.add(layers.MaxPooling1D(8))
model.add(layers.Dense(80, activation=’relu’))
model.add(layers.Flatten())
model.add(layers.Dense(2, activation=’linear’))
model.compile(loss=’mse’,
optimizer='adam',
metrics=[‘mae’])
打印(model.summary())
return model
wrapper_model = KerasRegressor(build_fn=base_model)
# 拟合模型
wrapper_model.fit(X, Y) #scikit learn 在此处只接受 2D 输入
# 执行置换重要性
results = permutation_importance(wrapper_model, X, Y, scoring=’neg_mean_squared_error’)
# 获取重要性
importance = results.importances_mean
CNN 不适合回归问题。
这会有帮助
https://machinelearning.org.cn/when-to-use-mlp-cnn-and-rnn-neural-networks/
在将 1D CNN 用于时间序列预测或序列预测时,我建议直接使用 Keras API。
嗨,Jason,
感谢这篇文章 🙂
如果模型是 sklearn 管道的一部分,我该如何获得特征重要性?
谢谢
您可以使用特征重要性模型独立地计算重要性以供您审查。
这篇文章信息量很大,我们能否用真实世界的例子而不是 n_samples=1000, n_features=10?
谢谢。
我故意使用了合成数据集,以便您可以专注于学习方法,然后轻松地替换为您自己的数据集。
你好,
我想这些发现特征重要性的方法在目标变量是二元变量时是有效的。
我们能否将建议的方法用于多类分类任务?
谢谢你
Alex
是的。
在二元任务中(例如基于线性 SVM 系数),具有正系数和负系数的特征分别与分类为某个类别的概率具有正相关和负相关。
多类分类任务呢?我们如何解释线性 SVM 系数?
谢谢你,
SVM 不支持多类。问题必须被转化为多个二元问题。
谢谢你的回复。
在多类 SVM 的情况下(例如,对于 3 类任务),我们能否合并来自不同“二元学习器”的 SVM 系数来确定特征重要性?
也许可以。
使用 RFE 可能会更容易。
https://machinelearning.org.cn/rfe-feature-selection-in-python/
亲爱的 Jason,
感谢您提供有用的文章。
我想知道使用深度神经网络实现回归问题,然后使用随机森林特征重要性获取预测变量的重要性分数是否合理?
提前感谢,
马苏德
不。我认为重要性分数和神经网络模型之间没有任何有用的关系。
亲爱的 Jason,
感谢您的回复。所以我想,检索 DNN 或 Deep CNN 模型(用于回归问题)中参数特征重要性的最佳方法是置换特征重要性。我说得对吗?
提前感谢,
马苏德
我建议您查阅文献。
你好,Jason。
我正在使用 AdaBoost Classifier 来获取特征重要性。我有 17 个变量,但结果只显示 16 个。我哪里做错了?谢谢
也许你有 16 个输入和 1 个输出,总共 17 个。
抱歉,如果我的问题听起来很愚蠢,但为什么回归和分类的特征重要性结果会有如此大的差异,即使使用相同的模型(如 RandomForest)?我明白目标特征是不同的,因为在使用回归方法时它是数值,而在使用分类方法时它是类别值(或类别)。但是输入特征,它们不是一样的吗?如果不是,使用相同的输入特征数据集进行回归和分类会很有趣,这样我们就可以看到相似之处和差异。谢谢。
好问题,每种算法对重要特征的看法都不同。
更多信息在这里
https://machinelearning.org.cn/faq/single-faq/what-feature-importance-method-should-i-use
本教程中的回归和分类使用了不同的数据集,对吧?
是的。
Jason 您好,感谢您的精彩文章。
是否有办法设置一个最小阈值,以便我们可以说从那里开始,它对于特征选择很重要,例如系数的平均值,分位数 1...?
提前感谢你
此致
Saber
不客气。
不完全是,模型技能是关注的焦点,应该选择能够带来最佳模型性能的特征。
教程很棒。谢谢!
我看到有许多用于减少特征维度或评估重要性或从给定数据集中选择特征的技术……其中大多数与“sklearn”库有关。我通过您关于此主题的众多教程中的几篇学习了它们……提供了丰富的用于探索特征相关性的方法……有时,由于要测试和评估的工具数量众多,会有点混乱……
我只有一个问题。对于图像领域(计算机视觉),我们有类似(或等效)的东西吗?或者它们是否都专门与表格数据集相关?
提前感谢你
不客气。
是的,像素缩放和数据增强是图像的主要数据预处理方法。
Jason,感谢您提供此信息丰富的教程。
我有 2 个问题
1- 您提到“正分数表示预测类别 1 的特征,而负分数表示预测类别 0 的特征。”,这意味着与正分数相关的特征在预测类别 0 时不会被使用吗?
2- 由于同一数据集上的各种技术可能产生不同的重要特征子集,我们是否应该使用每个子集来训练模型,然后保留使模型表现最佳的子集?我们可以合并来自不同技术的重要特征吗?
不,线性模型是所有输入的加权和。
是的,这里有一个例子
https://machinelearning.org.cn/feature-selection-subspace-ensemble-in-python/
Jason 您好,感谢您的有用教程。
我想知道我们是否可以使用 Lasso()
model = BaggingRegressor(Lasso()) 其中您使用
# 拟合模型
model = LogisticRegression(solver=’liblinear’)
因为 Lasso() 本身就会进行特征选择?
提前感谢
或许可以尝试一下。我不确定在 bagging 模型中使用 lasso 是否明智。
由于 Lasso() 具有特征选择功能,我是否可以在上面的代码中使用它代替“LogisticRegression(solver=’liblinear’)”?
model = LogisticRegression(solver=’liblinear’)
model = Lasso()
您能否告诉我为什么使用
model = BaggingRegressor(Lasso()) 不明智?
当我改编您的代码使用 model = BaggingRegressor(Lasso()) 时,与其他模型相比,我获得了最好的结果。
提前感谢
LASSO 具有特征选择功能,但没有特征重要性。
Bagging 适用于高方差模型,LASSO 不是高方差模型。
做得好。使用在您的项目中效果最好的模型。
非常感谢您提供有趣的教程。
你能帮帮我吗?
我想对我的输入特征进行排名。使用相同的输入特征,我运行了不同的模型并获得了特征系数的结果。但是,每个特征系数的排名在各种模型(例如 RF 和 Logistic Regression)之间都不同。如果我不关心模型的结果,而是关心系数的排名。哪个模型最好?我们如何评估特征系数排名的置信度?
提前非常感谢。
此致,
Alex。
不客气。
是的,每个模型对哪些特征重要都会有不同的“看法”,您可以在这里了解更多信息
https://machinelearning.org.cn/faq/single-faq/what-feature-importance-method-should-i-use
亲爱的 Jason,
我有 40 个特征,使用 SelectFromModel 后,我发现我的模型在使用特征 [6, 9, 20, 25] 时效果更好。
1-我能否只使用这些特征而忽略其他特征然后进行预测?我这样做了,结果非常糟糕。
2-我能否使用 SelectFromModel 来保存我的模型?您能否提供信息,帮助我创建一个管道来加载新数据和使用 SelectFromModel 保存的模型,并进行最终预测?
如果结果很糟糕,那就不要只使用那些特征。
您可以直接保存模型,请参阅此示例
https://machinelearning.org.cn/save-load-machine-learning-models-python-scikit-learn/
我的另一个问题是,我是否可以在 SelectFromModel 之前使用 PCA 和 StandardScaler()?
# 拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
#### 这里首先对 X_train, X_test, y_train, y_test 进行 StandardScaler
#### 然后对 X_train, X_test, y_train, y_test 进行 PCA
# 特征选择
X_train_fs, X_test_fs, fs = select_features(X_trainSCPCA, y_trainSCPCA, X_testSCPCA)
提前感谢
我建议使用 Pipeline 来执行一系列数据转换。
https://scikit-learn.cn/stable/modules/generated/sklearn.pipeline.Pipeline.html
谢谢,我将使用管道,但我们仍然需要在管道中有一个正确的顺序,是吗?这就是我问这个顺序的原因。
1 – # 分割为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
2 – #### 这里首先对 X_train, X_test, y_train, y_test 进行 StandardScaler
3 – #### 然后对 X_train, X_test, y_train, y_test 进行 PCA
4 – # 特征选择
X_train_fs, X_test_fs, fs = select_features(X_trainSCPCA, y_trainSCPCA, X_testSCPCA)
提前感谢
是的,顺序很重要。
在 PCA 之前进行标准化是正确的顺序。
嗨,Jason,
感谢这篇很棒的文章。
我有一个关于置换重要性的问题。
由于它涉及到每个预测变量的置换,它是否可以应用于时间数据(我的特征是每日金融指数)?
我不确定在这种情况下是否可以,因为您有一定的时序顺序和序列相关性。
您对此有何看法?
非常感谢
Luigi
也许可以。我不确定,但凭经验我认为用于表格数据的特征选择方法通常不适用于时间序列数据。
嗨,Jason,
很棒的教程。谢谢。
我看到了一些对本教程评论的批评。
所以首先,我喜欢并支持您的教学方法,它更侧重于您通过代码片段使用的工具,而不是宏大的想法/概念。我的意思是,我宁愿拥有一个“刀”并尝试如何使用它,而不是让大人物们解释如何切割的宏大想法……但却没有给我工具。
所以我在这里分享我的实验
1º) 我尝试了 Sklearn 的“permutation_importance”方法,这似乎是最客观的,我也将其应用于我自己的回归数据集问题)。我还对我的数据集应用了缩放(MinMaxScaler())。
所以我决定稍微放弃其他等效方法,例如:(RFE、KBest 和某些 sklearn 模型的 .coef_、.features_ mean、importances.mean 的自定义方法)。
2º) 我将“permutation_importance”应用于多个模型(某种比较方法的网格),包括 LinearRegressor()、SVR()、RandomForestRegressor()、ExtraTreesRegressor()、KNeighborsRegressor()、XGBRegressor()……我还添加了一个简单的 ANN MLP 模型(未包含
在 Sklearn 中)……
3º) 我决定训练所有这些模型,并决定选择最佳的 permutation_importance,以便将全部特征减少到 K 个特征,但应用于我获得最佳指标(例如 RMSE)性能的模型。您同意我的标准吗?
4º) 最后,我根据这些最佳模型(ANN、XGR、ETR、RFR)的特征重要性值来减少数据集,并检查应用于减少数据集特征的新训练的最终性能……而且我获得了比使用完整数据集特征更好的性能……
所以我得出结论,特征重要性选择是有效的……
我甚至感到惊讶,因为我选择了一个方法来选择特征,但我在一个接近的方法中获得了最佳的特征减少训练性能,而不是最好的。
我的问题是
5º) 您能否写下(或链接到您的某个教程)如何使用 Sklearn 方法保存 Sklearn 训练模型(权重)(我听说可以使用 pickle,但我具体不知道如何)……
以及如何加载 Sklearn 保存的模型权重……
在 Keras 中,等效的方法是:model.save('filename.h5') 和,
load_model('filename.h5')
此致,
JG
谢谢。
同意,我也是。
很棒的实验!
这展示了如何保存 sklearn 模型。
https://machinelearning.org.cn/save-load-machine-learning-models-python-scikit-learn/
还有这个。
https://machinelearning.org.cn/how-to-save-and-load-models-and-data-preparation-in-scikit-learn-for-later-use/
我相信如果您将 keras 模型包装在 sklearn 包装器类中,它将无法(轻松)保存。
谢谢你,Jason。
您确实提供了极大的 ML 价值!
谢谢!
Jason,非常感谢您的所有帮助!这个网站是一个绝佳的资源!您发布的任何内容都非常宝贵!!
谢谢!
亲爱的 Jason,
首先,您所做的工作很棒,非常感谢。如果我想对这个模型进行交叉验证,
将 RandomForest 与 StandardScaler() 和线性模型(如 SVC())一起插入管道并对其进行交叉验证是否正确?
代码如下
from sklearn.model_selection import cross_val_score
fs = SelectFromModel(RandomForestClassifier(n_estimators=1000), max_features=30)
model=SVC()
model_=make_pipeline(StandardScaler(),fs,model)
scores = cross_val_score(model_, X, y, cv=20)
np.round(np.mean(scores),2)
您可以在管道中使用特征重要性作为一个步骤。
亲爱的 Jason,
非常感谢您的快速回复——我不明白,我不是指特征重要性,而是如果我将 SelectFromModel RandomForest 插入管道,交叉验证是否合法……但我猜是可以的(?)
是的,您可以使用这种方法。
Jason 您好。本教程正是我的需要,我正在使用随机森林来查找特征重要性。我的目标是不进行任何预测,只是查看哪些变量对于解释我的因变量很重要。因此,考虑到这个目标,我应该将数据分割为训练集和测试集,还是在这种情况下不需要分割?这是一个紧急问题,如果您能快速回复,我将非常感激。
也许只使用所有数据来估计特征重要性。例如,这听起来更像是一个分析任务而不是预测任务。
兄弟,如何通过应用 RFRegressor 选择 PermutationImportance 特征
你到底遇到了什么问题?
嗨 Jason
在您上面的文章中,Logistic Regression 的特征重要性给出了正负系数。我个人不喜欢使用 sklearn,更喜欢使用 statsmodels 进行回归和 LR,因为我能够获得有意义的信息(如 t 统计量和 p 值)。当使用 statsmodels 进行回归时,我得到了与您相同的系数。但有趣的是,statsmodels 警告说:
ConvergenceWarning: Maximum Likelihood optimization failed to converge.
即使选择其他优化方法,结果也是相同的(无法收敛),所有 t 统计量和 p 值都为 NaN。
有趣,感谢分享!
亲爱的 Jason:
如何在 SelectFromModel 中查看选定特征的排名?
我仍然对特征重要性感到困惑,先生。你能帮帮我吗?如果我使用 DecisionTreeClassifier() 然后使用 importance = model.feature_importances。那么,我能否说 importance 变量的输出是基尼指数值?另一种情况是如何找出基尼指数分数作为模型的特征选择?
您不会在树中使用重要性,您可以使用它用于其他目的,例如向项目利益相关者解释每个输入对预测模型的重要性。
嗨,Jason,
我有一些生理数据,每秒记录 120 个数据点。我使用了特征重要性分数,发现时间戳比其他特征具有更高的重要性分数,即使时间戳与其他特征没有相关性。为什么时间戳比其他特征更重要?有什么想法吗?
谢谢
这可能表明自相关,例如,尝试对正在预测的变量进行 ACF/PACF 图。
感谢您的快速回复。我会看一下 ACF/PACF,但测试数据的预测分数约为 90%。
我还看了相关矩阵,其中其他特征彼此相关,但时间戳与其他特征的相关性很差。但相同的数据集为时间戳提供了更重要的分数。因此,我感到困惑,我是否做错了什么。我如何验证时间戳和其他特征的重要分数是否正确?
分数只是一个指南,它既不是正确也不是不正确。
相反,评估一个有和没有特定特征的模型,看看它是否有助于进行预测。
谢谢,杰森。
我尝试了使用和不使用时间戳特征,其中不使用时间戳的预测分数仅为 66%,而使用时间戳的预测分数为 90%。所以,我认为它对预测很重要。
然而,时间戳与其他特征的相关性很差,但时间戳的重要性分数是 0.35,而其他特征的分数在 0.05 到 0.16 之间。您对此有何看法?
我认为时间序列数据的特征重要性与表格数据非常不同,相反,您应该使用 pacf/acf 图。
我认为时间序列模型和数据预处理必须使用前向验证来评估,以避免数据泄漏。
我认为您应该使用在稳健的测试平台上效果最好的方法。
那么我如何知道模型中的基尼指数呢?我需要您的建议。
抱歉,我没有计算该指标的模型示例。
如上所述,有多种分类器用于计算特征重要性,那么如何选择哪种方法最好,例如随机森林、逻辑回归还是其他?
好问题,我在这里回答这个问题
https://machinelearning.org.cn/faq/single-faq/what-feature-importance-method-should-i-use
我应该先找到最佳超参数(min_depth、min_samples_leaf 等),然后再找到特征重要性吗?
另外,您建议何时使用其重要性值删除特征?
好问题。我通常会避免在计算特征重要性之前调整模型。
删除特征是建模之前的一个步骤,例如数据准备。
你好,
有没有关于如何获取图数据库(neo4j)的节点重要性的例子?
谢谢
没有,抱歉。
嗨,Jason,
您能否澄清一下 permutacion_importance() 函数(或其他函数)获得的值与特征系数有关,是绝对意义还是归一化意义?我没看到……或者相反,是否应该仅解释为相对或排名(系数)值?
致敬
JG
我认为分数是相对的,不是绝对的。
例如,相对于特定运行、数据集和模型的其他分数。
嗨,Jason,
确定特征重要性的不同算法是什么,例如随机森林回归器?
我的意思是 KNN 能否确定特征重要性?
我不认为 knn 可以确定特征重要性。
谢谢
不客气。
嗨,Jason,
我已经在我的数据上使用了随机森林,得到了 4 个最重要的特征。当我使用全部数据时,我得到了 99% 的准确率。当我使用那 4 个最重要的特征时,我仍然得到几乎相同的准确率(这似乎是合乎逻辑的)。但问题是,当我使用其他特征(删除那 4 个特征)时,我得到了大约 95% 的准确率,这较低,但仍然不错。这是否合乎逻辑,还是我的模型可能出了问题?我使用随机森林作为比较准确率的模型。
是的,这意味着其他特征正在添加统计噪声或为模型增加一些价值。
你好 jason,
我喜欢您的作品。我有一个关于 scikit learn Permutation Importance 的问题。我正在使用 Keras 二进制分类模型,它返回概率作为预测,而不是类值。所以我希望是否有办法不使用 Keras Wrapper 类,而是修改评分器函数来获取特征重要性。您能告诉我这是否真的可行吗?
谢谢
也许可以尝试一下。
嗨,Jason,
我是这个领域的新手。我一直在尝试构建一个倾向得分,拥有近 200,000 个观测值和 203 个变量。您认为我上面给出的方法是否能让我很好地理解我应该为 XGboost 选择的变量?或者我应该进一步缩小我的变量范围??
您的博客非常有帮助,我是否有可能通过 Google Meet 与您联系,以便我能清除我的疑虑?
谢谢你
快速计算一下,200,000 除以 203 大约是 1000。每个变量应该有足够的变异性,以便模型可以从数据中学习规则。所以您很有可能使其奏效。
我可以在 spark mllib 模型上使用置换重要性函数吗?
为什么您认为您不能?
大家好,
感谢您的评论。我的疑问是关于最后一个,即“带重要性的特征选择”。
在上面的示例中,他们已经知道要选择的特征数量(max_features = 5),因为他们创建了自己的数据集。但是,您如何知道哪个值适合该参数?您如何为给定的数据集设置阈值?
我想知道是否有必要用不同数量的特征(max_features 的不同值)来训练模型,然后进行比较。
希望有人能帮忙!
谢谢你。
您不这样做!或者您已经知道需要多少 max_features,因为您的计算机内存有限等。所以您说得对,我们尝试不同的 max_features 值来看哪个权衡是合理的。
嗨,Jason,
感谢您的教程!对于某些或所有变量,置换重要性是否可能高于 1?我使用 R2 作为评分,对于 Ridge 和 Huber 等模型,我得到了高于 1 的数字。对于每个模型,我都有这样的内容:
model.fit(X_train, y_train)
result = permutation_importance(model, X_test, y_test, scoring=’r2′)
importance_score = result.importances_mean
您认为我做错了什么吗?
R2 不应高于 1——数学上不可能。有什么不对吗?
感谢您的回复。这就是我感到困惑的原因。我只是使用了上面的代码来计算置换重要性。但是,一些模型会产生高于 1 的置换重要性。我想知道是什么原因导致了这个问题。
不知道。如果您使用 R^2,这听起来是不可能的。
嗨,Jason,
感谢您的教程。feature_importances_ 属性和 Permutation Feature Importance 的结果相同还是不同?
你好 Ali……它们不会完全一样,但它们在总体上应该能得出关于相对“特征重要性”的相似结论。我强烈建议在根据低分数做出删除特征的最终决定之前,同时使用这两种方法。
嗨,Jason,
感谢您的教程。我正在尝试通过优化相似度距离来优化类比工作量估算(类似于 KNN Regressor)中的特征权重。目标函数是最小化准确性度量。
我想问一下如何使用交叉验证来验证我的最终模型?
你好,我们可以缩短这个介绍,使用
model=[LinearRegression(), LogisticRegression().
然后生成数据
并使用
model.fit
model.predict
对于所有模型……
谢谢你的反馈 Michael!
大家好,
我有一个关于统计指标的快速问题,想问问更有经验的人。
假设我有一个 SVM 分类器的 alpha 和保留的观测值(即支持向量)的结果。
那么,如果我将每个支持向量乘以其 alpha 值,然后使用原始的 y_true 进行拟合来运行逻辑回归,其产生的权重是否对应于某种“特征重要性”,因为它们描绘了该特定训练集的“线性相关强度”?(我忽略了偏差问题)。感谢您提前告知我是否在胡说八道。
你好 Mat……以下内容可能有所帮助
https://machinelearning.org.cn/feature-selection-with-real-and-categorical-data/
为什么结果是有意义的?
如果 make_classification 首先创建有意义的特征,那么重要性分数不应该发现它们是最重要的吗?
这是否意味着分类器没有选择它?
好的,由于 make_calssification 的 shuffle 参数为 True,顺序不像我想象的那样 🙂
我的错。
感谢您的反馈!继续努力 Idan!
如果已经被问过(我肯定错过了),请原谅我。对于特征重要性,是否可以在输出中包含特征名称——而不是“Feature: 0”、“Feature: 1”等等?
你好 Tim……这是可能的。以下讨论可能会有所帮助
https://stackoverflow.com/questions/61508922/keeping-track-of-feature-names-when-doing-feature-selection
如何处理我的数据集是分类和数值数据组合的情况?如何进行特征重要性?谢谢。
顶一下,因为我有和 Rodney 一样的问题。如何确定混合分类和数值特征的特征重要性?将分类变量编码为数值变量然后确定特征重要性是否有意义?如果是这样,它是否会为特征重要性引入大量多余的特征?不清楚如何处理这种情况。
你好Jason
在上面的帖子中,在解释逻辑回归的系数时,我们如何说正分数表示预测类别 1 的特征,而负分数表示预测类别 0 的特征?谢谢。
置换重要性似乎对 GradientBoostingClassifier 的 n_estimators 很敏感。对于我的数据,默认设置 100 都很好,但下降到 40 时,所有结果都返回零。
可以使用 AdaBoost Regressor 进行特征重要性吗?
你好 Valentin……您可能会发现以下资源很有趣
https://stackoverflow.com/questions/36665511/scikit-adaboost-feature-importance
你好,
您能告诉我如何为聚类模型(如 kmeans)进行特征重要性分析吗?
谢谢
你好 Akshay……您可能会发现以下资源很有趣
https://towardsdatascience.com/interpretable-k-means-clusters-feature-importances-7e516eeb8d3c
嗨,Jason,
感谢您的文章。我总是从您的博客中学到很多东西。
只有一个快速问题,随机森林分类器计算出的特征重要性分数如何反映在决策树中?我已经提取了最重要的 10 个特征,并构建了一个决策树,其中一个顶级决策节点(根节点)不是最重要的第 1 个特征。您能解释一下它们之间是如何关联的吗?RFC 和决策树的特征重要性计算?
谢谢!
你好 Katie……以下资源可能有助于澄清
https://towardsdatascience.com/the-mathematics-of-decision-trees-random-forest-and-feature-importance-in-scikit-learn-and-spark-f2861df67e3
你好 Jason 和大家,
感谢所有教程,它们非常有帮助。
我有一个快速问题。我想在大型数据集上运行 RF,并且需要查看特征重要性。同时,我想使用嵌套 CV 获得最佳模型。那么,我的问题是,在嵌套 CV 的哪个阶段检查特征重要性?我应该在外层循环内进行检查并获得平均值,还是应该对最终模型(在整个数据集上拟合)运行置换方法?
非常感谢任何建议
谢谢
Nico
你好 Nico……以下内容可能对您有益
https://machinelearning.org.cn/feature-importance-and-feature-selection-with-xgboost-in-python/
我认为您的帖子大多数在技术覆盖方面都很有价值,但您坚持使用人工数据集而不是公共数据集,这是一个主要的缺点,并且使您的帖子价值和趣味性大大降低。
大多数工作在于处理真实特征(有意义的特征)以及特征选择方面的努力。
当您的帖子说特征 08 很重要时,这价值不大,因为在现实世界中,发现已知特征中隐藏的关系是游戏的重要组成部分,这是故事讲述中的巨大亮点。
感谢您的反馈 Paulo!我们很感激。
太棒了!!!!!!谢谢您。
不客气 Getnet!
嗨,很棒的帖子。我想知道在使用堆叠模型(即我有多个堆叠模型)时是否可以计算特征重要性分数。我想知道您的意见,该如何做到?
你好 Anjali……以下资源可能对您感兴趣
https://machinelearning.org.cn/stacking-ensemble-machine-learning-with-python/
https://www.analyticsvidhya.com/blog/2021/08/ensemble-stacking-for-machine-learning-and-deep-learning/
亲爱的布朗利博士,
有没有什么阈值来确定哪个特征是好的解释变量?有学术文章可供参考吗?
你好 Nguyen……可以在这里找到数学基础
https://towardsdatascience.com/the-mathematics-of-decision-trees-random-forest-and-feature-importance-in-scikit-learn-and-spark-f2861df67e3
嗨!
感谢您的论文!
它帮助我在 Kaggle 的泰坦尼克号灾难竞赛中稍微提高了一些分数。
我有一个问题:如果我们能简单地执行移除特征分析,为什么还需要进行置换特征重要性分析?
我的意思是移除特征并多次训练我们的模型,然后取目标指标的平均值,并查看基础模型和没有特定特征的模型所获得的目标指标之间的差异?
你好 Artem……以下资源可能对您有益
https://machinelearning.org.cn/feature-selection-with-real-and-categorical-data/
嗨,感谢您的文章。我只是想知道如何从特征重要性分数中获取特征名称。我对分类特征进行了一些独热编码,并使用 BalancedRandomForestClassifier 进行了交叉验证。但是,我想找出哪些特征及其分数对结果做出了贡献。我该如何做到?
要从像
BalancedRandomForestClassifier这样的模型中获取特征名称及其重要性分数,尤其是在对分类特征进行独热编码后,您可以遵循以下步骤:1. **拟合模型**:首先,确保您的
BalancedRandomForestClassifier已使用您的数据集正确训练。2. **检索特征重要性**:训练后,您可以通过分类器的
feature_importances_属性访问特征重要性分数。3. **将编码后的特征与原始特征匹配**:当使用独热编码的特征时,这会变得有点棘手。您需要将这些编码后的特征名称映射回您的原始特征名称。
4. **对特征重要性进行排序和显示**:为了更好地理解,您可能希望根据重要性分数对这些特征进行排序。
以下是如何在 Python 中执行此操作的示例:
pythonimport pandas as pd
from sklearn.ensemble import BalancedRandomForestClassifier
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
# 示例数据集
# df = pd.read_csv('your_dataset.csv')
# 分离特征和目标
X = df.drop('target_column', axis=1)
y = df['target_column']
# 独热编码
encoder = OneHotEncoder(sparse=False)
X_encoded = encoder.fit_transform(X)
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X_encoded, y, test_size=0.2, random_state=42)
# 训练模型
model = BalancedRandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
# 获取特征重要性
importances = model.feature_importances_
# 将编码后的特征名称与原始特征名称匹配
encoded_feature_names = encoder.get_feature_names_out(input_features=X.columns)
feature_importances = pd.DataFrame({'feature': encoded_feature_names, 'importance': importances})
# 按重要性排序
feature_importances = feature_importances.sort_values('importance', ascending=False)
# 显示
print(feature_importances)
此代码将为您提供一个包含每个独热编码特征及其相应重要性分数的 DataFrame。请记住,在独热编码中,分类特征的每个唯一值都会成为一个新特征。因此,重要性列表中的特征名称将对应于这些新特征。您可以根据
OneHotEncoder使用的命名约定将其追溯到原始分类变量。