在分类问题中,不直接预测类别值,而是预测观察值属于每个可能类别的概率会更方便。
预测概率可以提供一定的灵活性,包括决定如何解释概率、呈现具有不确定性的预测,以及提供更细致的方式来评估模型的技能。
与每个类别的预期概率分布相匹配的预测概率被称为校准的。问题是,并非所有机器学习模型都能预测校准的概率。
有一些方法可以诊断预测概率的校准程度,并可以通过每个类别的观察分布来更好地校准预测概率。通常,这可以提高预测质量,具体取决于评估模型技能的方式。
在本教程中,您将了解校准预测概率的重要性,以及如何诊断和改进用于概率分类的模型校准。
完成本教程后,您将了解:
- 非线性机器学习算法通常会预测未经校准的类别概率。
- 可靠性图可用于诊断模型的校准情况,并且可以使用方法来更好地校准问题的预测。
- 如何在 Python 中使用 scikit-learn 开发可靠性图和校准分类模型。
通过我的新书开始您的项目 机器学习概率,其中包括分步教程和所有示例的Python 源代码文件。
让我们开始吧。

如何使用 scikit-learn 中的校准分类模型
照片由 Nigel Howe 拍摄,保留部分权利。
教程概述
本教程分为四个部分;它们是
- 预测概率
- 预测校准
- 如何在 Python 中校准概率
- 校准 SVM 概率的实际示例
预测概率
分类预测建模问题要求为给定的观察值预测或预测标签。
作为直接预测标签的替代方法,模型可以预测观察值属于每个可能的类别标签的概率。
这在预测的解释和呈现方式(阈值选择和预测不确定性)以及模型评估方式上都提供了一定的灵活性。
尽管模型可以预测概率,但概率的分布和行为可能与训练数据中观察到的概率的预期分布不符。
这对于不直接进行概率预测而使用近似值的复杂非线性机器学习算法尤其常见。
概率的分布可以进行调整,以更好地匹配数据中观察到的预期分布。这种调整称为校准,即模型校准或类别概率分布校准。
[…] 我们希望估计的类别概率能够反映样本的真实底层概率。也就是说,预测的类别概率(或类概率值)需要校准良好。要校准良好,概率必须有效地反映感兴趣事件的真实可能性。
— 第 249 页,《应用预测建模》,2013。
预测校准
校准概率有两个问题;它们是诊断预测概率的校准以及校准过程本身。
可靠性图(校准曲线)
可靠性图是观察到的相对频率(y 轴)与预测概率频率(x 轴)之间的线图。
可靠性图是说明概率预测系统属性的常用辅助工具。它们包含了一个绘制的观测相对频率与预测概率,为调整概率预测系统提供了快速的视觉比较,并记录了最终产品的性能。
— 提高可靠性图的可靠性,2007。
具体来说,预测概率沿 x 轴被分成固定数量的存储桶。然后计算每个存储桶中的事件(类别=1)数量(例如,相对观测频率)。最后,对计数进行归一化。然后将结果绘制成线图。
在预测文献中,这些图通常被称为“可靠性”图,尽管它们也可能被称为“校准”图或曲线,因为它们总结了预测概率的校准程度。
预测的概率越校准良好或越可靠,点在从左下角到右上角的主对角线上的显示就越接近。
点或曲线相对于对角线的位置有助于解释概率;例如
- 低于对角线:模型预测过度;概率太大了。
- 高于对角线:模型预测不足;概率太小了。
根据定义,概率是连续的,因此我们期望与直线有一定程度的分离,通常显示为 S 形曲线,表明悲观倾向,低概率预测过度,高概率预测不足。
可靠性图提供了诊断,用于检查预测值 Xi 是否可靠。粗略地说,如果事件实际发生的观测相对频率与预测值一致,则概率预测是可靠的。
— 提高可靠性图的可靠性,2007。
可靠性图有助于理解不同预测模型的预测的相对校准程度。
想学习机器学习概率吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
概率校准
预测模型的预测可以进行校准。
校准的预测可能(或可能不)在可靠性图上实现更好的校准。
有些算法的拟合方式使得其预测概率已经校准良好。不详细解释原因,逻辑回归就是一个例子。
其他算法不直接产生概率预测,而是必须近似预测概率。一些例子包括神经网络、支持向量机和决策树。
这些方法的预测概率可能是未经校准的,并且可能受益于通过校准进行修改。
预测概率的校准是在预测模型做出预测后应用的一种重新缩放操作。
有两种流行的概率校准方法;它们是 Platt 缩放和等渗回归。
Platt 缩放更简单,适用于 S 形的可靠性图。等渗回归更复杂,需要更多数据(否则可能过拟合),但可以支持不同形状的可靠性图(非参数)。
当预测概率的失真呈 sigmoid 形状时,Platt 缩放最有效。等渗回归是一种更强大的校准方法,可以纠正任何单调失真。不幸的是,这种额外的功能是有代价的。学习曲线分析表明,当数据稀缺时,等渗回归更容易过拟合,因此其性能不如 Platt 缩放。
— 使用监督学习预测良好概率,2005。
请注意,这一点非常重要:校准良好的概率可能导致更好的基于类或基于概率的预测,也可能不会。这实际上取决于用于评估预测的具体指标。
事实上,一些经验结果表明,那些能从校准预测概率中获益更多的算法包括 SVM、bagged decision trees 和 random forests。
[…] 校准后,最佳方法是提升树、随机森林和 SVM。
— 使用监督学习预测良好概率,2005。
如何在 Python 中校准概率
scikit-learn 机器学习库允许您诊断分类器的概率校准,并校准可以预测概率的分类器。
诊断校准
您可以通过在测试集上创建实际概率与预测概率的可靠性图来诊断分类器的校准情况。
在 scikit-learn 中,这被称为校准曲线。
这可以通过首先计算 calibration_curve() 函数来实现。此函数接受数据集的真实类别值和主类别(类别=1)的预测概率。该函数返回每个存储桶的真实概率和每个存储桶的预测概率。存储桶的数量可以通过 *n_bins* 参数指定,默认为 5。
例如,下面是一个显示 API 用法的代码片段
|
1 2 3 4 5 6 7 8 9 10 |
... # 预测概率 probs = model.predict_proba(testX)[:,1] # 可靠性图 fop, mpv = calibration_curve(testy, probs, n_bins=10) # 绘制完美校准 pyplot.plot([0, 1], [0, 1], linestyle='--') # 绘制模型可靠性 pyplot.plot(mpv, fop, marker='.') pyplot.show() |
校准分类器
在 scikit-learn 中,可以使用 CalibratedClassifierCV 类来校准分类器。
使用此类有两种方法:预训练和交叉验证。
您可以在训练数据集上拟合模型,并使用保留的验证数据集来校准此预训练模型。
例如,下面是一个显示 API 用法的代码片段
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
... # 准备数据 trainX, trainy = ... valX, valy = ... testX, testy = ... # 在训练数据集上拟合基础模型 model = ... model.fit(trainX, trainy) # 在验证数据上校准模型 calibrator = CalibratedClassifierCV(model, cv='prefit') calibrator.fit(valX, valy) # 评估模型 yhat = calibrator.predict(testX) |
或者,CalibratedClassifierCV 可以使用 k 折交叉验证来拟合模型的多个副本,并使用保留集来校准这些模型预测的概率。预测是使用每个训练模型进行的。
例如,下面是一个显示 API 用法的代码片段
|
1 2 3 4 5 6 7 8 9 10 11 |
... # 准备数据 trainX, trainy = ... testX, testy = ... # 定义基本模型 model = ... # 在训练数据上拟合和校准模型 calibrator = CalibratedClassifierCV(model, cv=3) calibrator.fit(trainX, trainy) # 评估模型 yhat = calibrator.predict(testX) |
CalibratedClassifierCV 类支持两种类型的概率校准;具体来说,是参数化的“sigmoid”方法(Platt 方法)和非参数化的“isotonic”方法,可以通过“method”参数指定。
校准 SVM 概率的实际示例
我们可以通过一些实际示例来具体讨论校准。
在这些示例中,我们将拟合一个支持向量机(SVM)到一个有噪声的二元分类问题,并使用该模型来预测概率,然后使用可靠性图审查校准,并校准分类器审查结果。
SVM 是一个适合校准的候选模型,因为它不原生预测概率,这意味着概率通常是未经校准的。
关于 SVM 的说明:可以通过调用拟合模型的 *decision_function()* 函数而不是通常的 *predict_proba()* 函数来预测概率。概率没有归一化,但可以通过设置“normalize”参数为“True”来在调用 *calibration_curve()* 函数时进行归一化。
下面的示例在测试问题上拟合了一个 SVM 模型,预测了概率,并绘制了概率校准作为可靠性图,
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# SVM 可靠性图 from sklearn.datasets import make_classification from sklearn.svm import SVC from sklearn.model_selection import train_test_split from sklearn.calibration import calibration_curve from matplotlib import pyplot # 生成 2 类数据集 X, y = make_classification(n_samples=1000, n_classes=2, weights=[1,1], random_state=1) # 划分为训练/测试集 trainX, testX, trainy, testy = train_test_split(X, y, test_size=0.5, random_state=2) # 拟合模型 model = SVC() model.fit(trainX, trainy) # 预测概率 probs = model.decision_function(testX) # 可靠性图 fop, mpv = calibration_curve(testy, probs, n_bins=10, normalize=True) # 绘制完美校准 pyplot.plot([0, 1], [0, 1], linestyle='--') # 绘制模型可靠性 pyplot.plot(mpv, fop, marker='.') pyplot.show() |
运行该示例将创建一个可靠性图,显示 SVM 预测概率的校准(实线)与图中对角线上的完美校准模型(虚线)的比较。
我们可以看到保守预测预期的 S 形曲线。
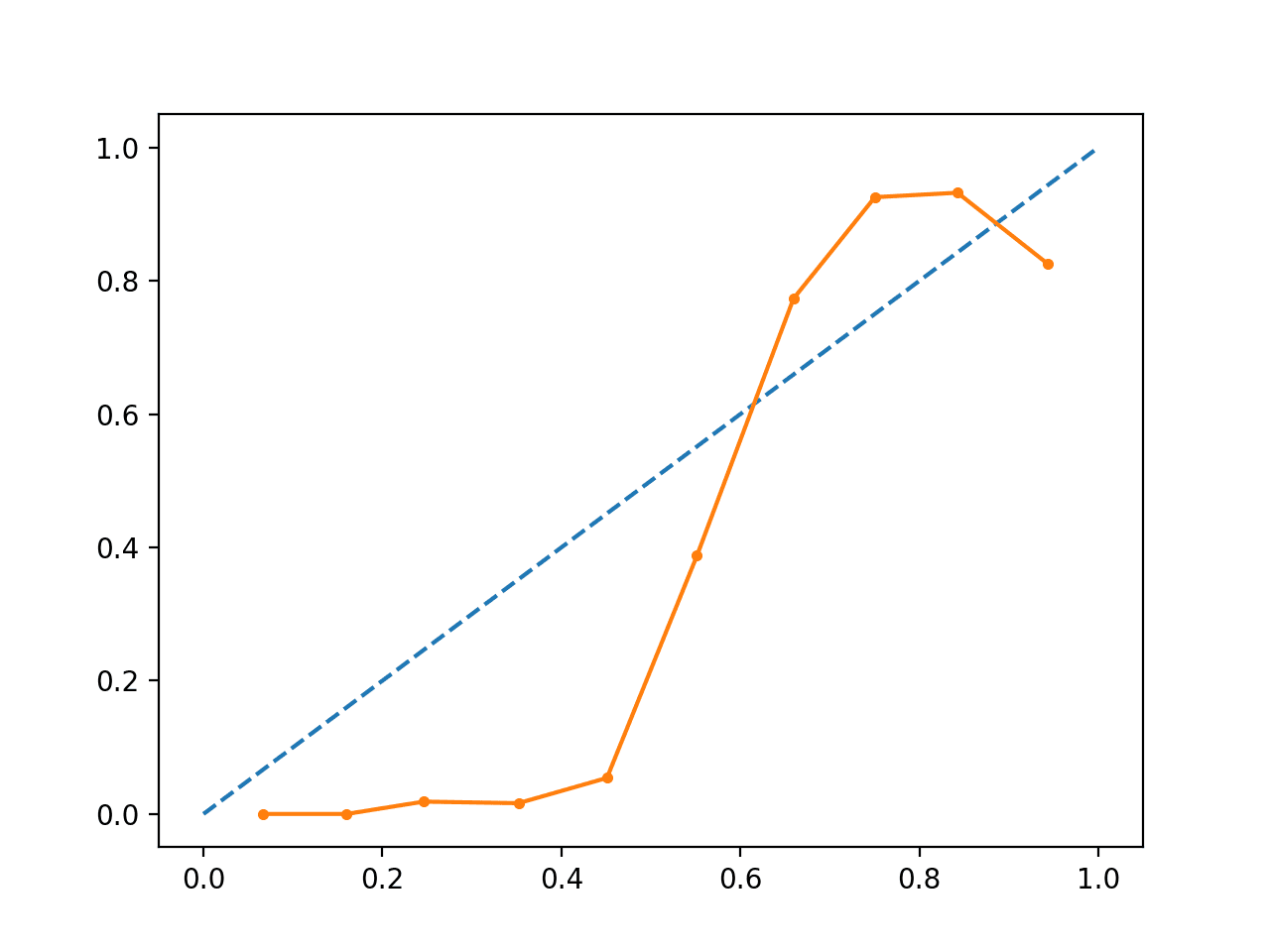
未经校准的 SVM 可靠性图
我们可以通过使用 5 折交叉验证,使用 CalibratedClassifierCV 类来拟合 SVM 来更新示例,并使用保留集来校准预测概率。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 带有校准的 SVM 可靠性图 from sklearn.datasets import make_classification from sklearn.svm import SVC from sklearn.calibration import CalibratedClassifierCV from sklearn.model_selection import train_test_split from sklearn.calibration import calibration_curve from matplotlib import pyplot # 生成 2 类数据集 X, y = make_classification(n_samples=1000, n_classes=2, weights=[1,1], random_state=1) # 划分为训练/测试集 trainX, testX, trainy, testy = train_test_split(X, y, test_size=0.5, random_state=2) # 拟合模型 model = SVC() calibrated = CalibratedClassifierCV(model, method='sigmoid', cv=5) calibrated.fit(trainX, trainy) # 预测概率 probs = calibrated.predict_proba(testX)[:, 1] # 可靠性图 fop, mpv = calibration_curve(testy, probs, n_bins=10, normalize=True) # 绘制完美校准 pyplot.plot([0, 1], [0, 1], linestyle='--') # 绘制校准的可靠性 pyplot.plot(mpv, fop, marker='.') pyplot.show() |
运行该示例将创建一个校准概率的可靠性图。
校准概率的形状不同,更紧密地贴合对角线,尽管在象限上方仍有预测不足的情况。
从视觉上看,该图表明模型校准得更好。
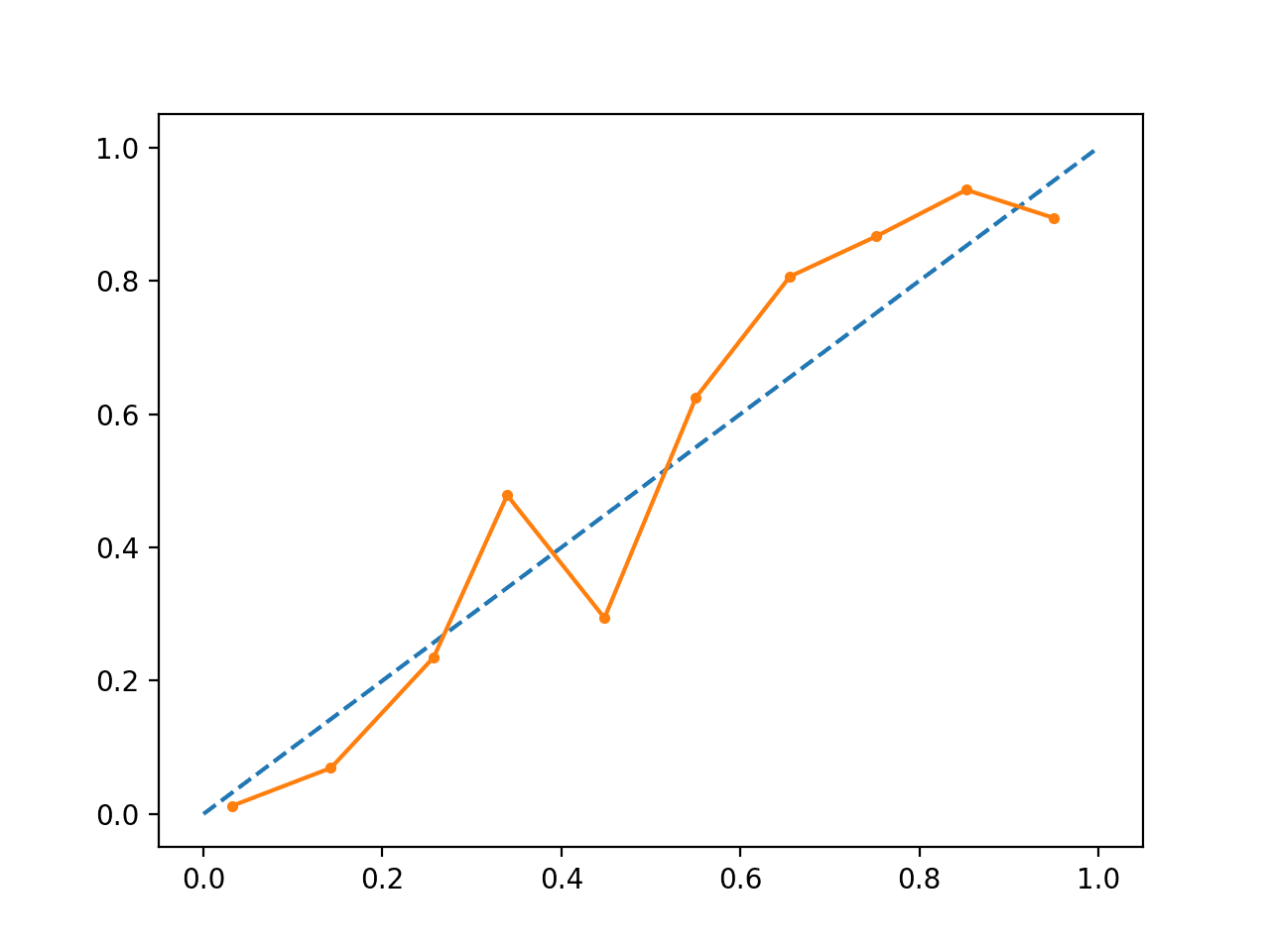
校准的 SVM 可靠性图
我们可以通过将两个可靠性图包含在同一张图中,来更清晰地对比这两个模型。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
# 带有未经校准和已校准概率的 SVM 可靠性图 from sklearn.datasets import make_classification from sklearn.svm import SVC from sklearn.calibration import CalibratedClassifierCV from sklearn.model_selection import train_test_split from sklearn.calibration import calibration_curve from matplotlib import pyplot # 预测未经校准的概率 def uncalibrated(trainX, testX, trainy): # 拟合模型 model = SVC() model.fit(trainX, trainy) # 预测概率 return model.decision_function(testX) # 预测校准概率 def calibrated(trainX, testX, trainy): # 定义模型 model = SVC() # 定义并拟合校准模型 calibrated = CalibratedClassifierCV(model, method='sigmoid', cv=5) calibrated.fit(trainX, trainy) # 预测概率 return calibrated.predict_proba(testX)[:, 1] # 生成 2 类数据集 X, y = make_classification(n_samples=1000, n_classes=2, weights=[1,1], random_state=1) # 划分为训练/测试集 trainX, testX, trainy, testy = train_test_split(X, y, test_size=0.5, random_state=2) # 未经校准的预测 yhat_uncalibrated = uncalibrated(trainX, testX, trainy) # 已校准的预测 yhat_calibrated = calibrated(trainX, testX, trainy) # 可靠性图 fop_uncalibrated, mpv_uncalibrated = calibration_curve(testy, yhat_uncalibrated, n_bins=10, normalize=True) fop_calibrated, mpv_calibrated = calibration_curve(testy, yhat_calibrated, n_bins=10) # 绘制完美校准 pyplot.plot([0, 1], [0, 1], linestyle='--', color='black') # 绘制模型可靠性 pyplot.plot(mpv_uncalibrated, fop_uncalibrated, marker='.') pyplot.plot(mpv_calibrated, fop_calibrated, marker='.') pyplot.show() |
运行该示例将创建一个可靠性图,同时显示已校准(橙色)和未经校准(蓝色)的概率。
这并不是一个真正苹果对苹果的比较,因为已校准模型做出的预测实际上是五个子模型的组合。
尽管如此,我们确实看到了已校准概率可靠性方面的显着差异(很可能是由于校准过程造成的)。
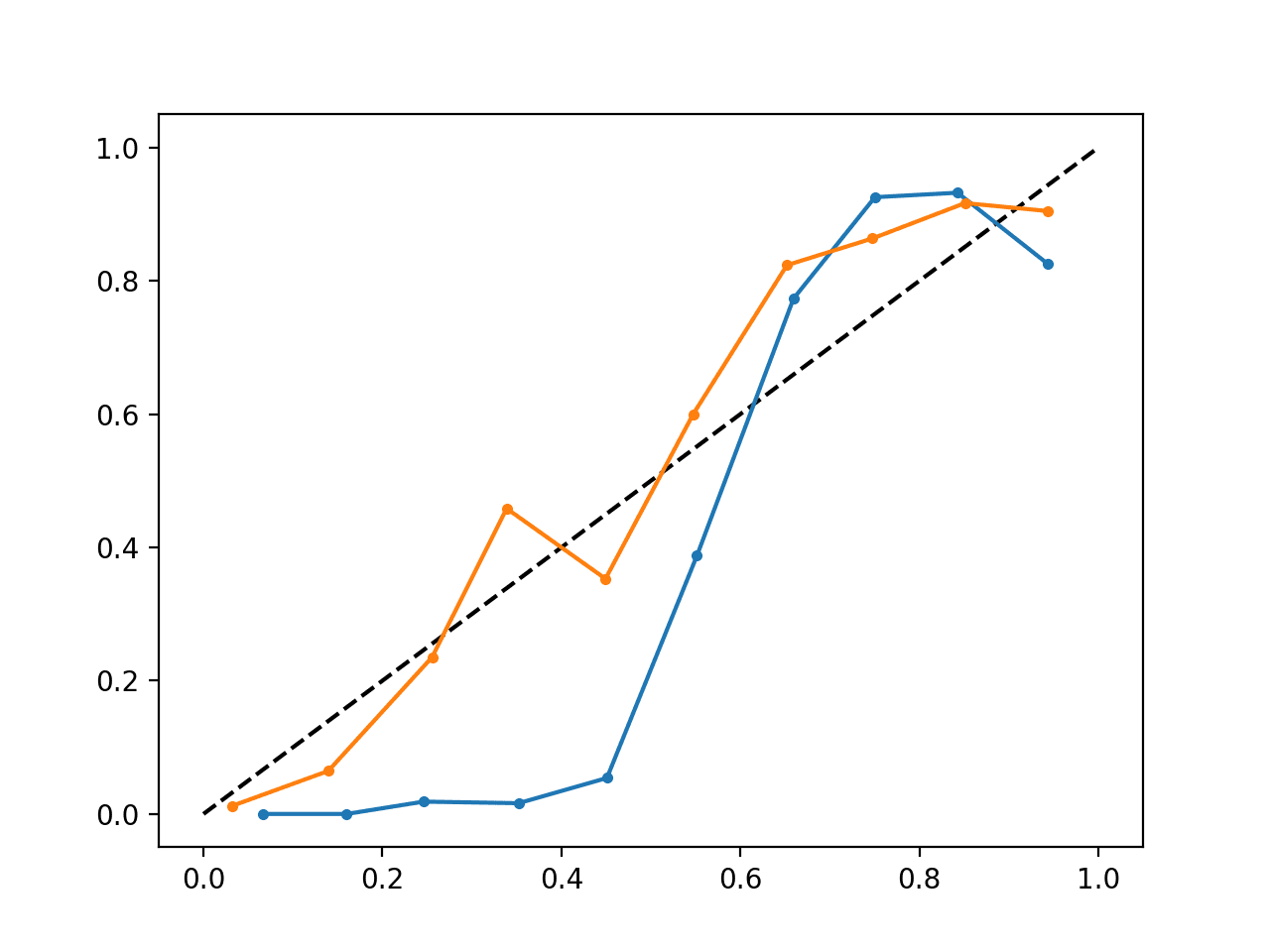
已校准和未经校准的 SVM 可靠性图
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍和论文
- 应用预测建模, 2013.
- 使用监督学习预测良好概率, 2005.
- 从决策树和朴素贝叶斯分类器中获得校准的概率估计, 2001.
- 提高可靠性图的可靠性, 2007.
API
- sklearn.calibration.CalibratedClassifierCV API
- sklearn.calibration.calibration_curve API
- 概率校准,scikit-learn 用户指南
- 概率校准曲线,scikit-learn
- 分类器校准比较,scikit-learn
文章
总结
在本教程中,您了解了校准预测概率的重要性,以及如何诊断和改进用于概率分类的模型校准。
具体来说,你学到了:
- 非线性机器学习算法通常会预测未经校准的类别概率。
- 可靠性图可用于诊断模型的校准情况,并且可以使用方法来更好地校准问题的预测。
- 如何在 Python 中使用 scikit-learn 开发可靠性图和校准分类模型。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







我希望您将最后两个教程包含在“Python 机器学习精通”中。
谢谢。它们可能对于那本入门书籍来说有点高级。
谢谢分享,非常有趣,但在我的梯度下降提升英国赛马评分中,它不幸未能提高性能。
谢谢,很棒的尝试!
更正一下,实际上我从另一个例子中获取了创建校准图的代码,并且我将 normalize 设置为 True。对于赛马来说,你真的想按原样接受概率,当我这样做时,概率是相当校准良好的,无需调整。
是否有 Python Sklearn 函数可以衡量校准曲线的拟合程度,即一种类似 MSE 的计算?
预测概率的对数损失可以实现这一点。
https://machinelearning.org.cn/how-to-score-probability-predictions-in-python/
谢谢,非常有用的。
很高兴听到这个消息。
在可靠性图中,如何绘制 y 轴存储桶中的观测值?例如,0.2 存储桶在 y 轴上可能的值是多少?也许对可靠性图进行详细说明会有帮助。谢谢。
好问题,我期望计算出的存储桶可以通过某种方式访问,但我没有示例。
这是一篇很棒的文章——您能否更详细地解释一下如何使用过采样数据集进行校准(这将产生不正确的概率)?您应该在校准之前或之后自行调整概率以考虑过采样,还是应该只使用 fit() 函数中的 weights 参数?有什么想法吗?
您可以使用过采样数据集进行拟合,但使用未处理的验证数据集进行校准。
一如既往,您对 ML 社区的又一很酷贡献!
您能否指出如何将此方法与随机森林作为分类器一起使用 — 因为 RF 不像 SVC 那样输出决策函数。
非常感谢。
您可以直接使用校准方法。
也许我不明白你遇到的问题?
你好,又来了。
请忽略我之前的问题 — 似乎在 uncalibrated 函数(使用随机森林时)中返回 predict_proba(testX)[:, 1] 解决了我的问题。
谢谢,
M。
不客气。
嗨,Jason,
是否可以CalibratedClassifierCV来校准一个非scikit-learn的模型?例如,如何校准一个用TensorFlow编写的分类器?
谢谢,
Jen
也许可以,但您可能需要将模型包装成看起来像sklearn分类器的样子(就像我们可以在Keras中做的那样)。
Jason您好,感谢您如此详细的解释!我一直在阅读这些问题,因为我试图寻找比较不同分类器性能的最佳方法,而ROC曲线和AUC的使用非常普遍。但是,正如您在这里所说的,“并非所有机器学习模型都能预测校准后的概率”,所以我想这只对某些分类器才有意义讨论概率和阈值。但是sklearn中的大多数模型要么有.predict_prob()方法,要么有.decision_function()方法,所以我想知道我们在这里讨论的是哪些具体的模型。我不明白对没有返回决策函数的模型(例如决策树)选择阈值是什么意思,但它确实有一个predict_prob()方法。
简单来说,我可以使用ROC和校准概率来比较哪些分类器?
简单的模型是基于概率模型的,例如逻辑回归,而许多非线性方法则不是这样运作的。
一种方法是将模型分开处理,有校准的和无校准的,将它们全部混合在一起,看看在我的比较中哪种表现最好。校准不会损害逻辑回归这样的概率模型,反而会帮助非概率模型。
您能否更详细地说明如何将其扩展到多类别问题?
您在哪个特定方面遇到困难?
嗨 Jason,当我尝试在多类别上运行时,calibration_curve 抛出了“bad input shape”错误。
“fop_uncalibrated, mpv_uncalibrated = calibration_curve(testy, yhat_uncalibrated, n_bins=10, normalize=True)”
testy 的大小是 [59, 8],np_utils 类别数据。
yhat_uncalibrated 的大小是 [59, 8],这是“model.decision_function(testX)”的输出。
是的,据我回忆,该实现仅用于二分类。
好的,谢谢你的信息。如果我想为多类别实现它,我该怎么做?你能建议一个方法吗?
抱歉,我没有例子。我无法立即给出建议。
嗨!
非常感谢您的这篇帖子,它非常有帮助!
我一直在运行随机森林并进行校准,正如您在此建议的那样,但现在数据集的大小正在增加,我可能需要迁移到Spark。您知道是否有办法在Spark上进行校准吗?
谢谢!
抱歉,我不知道Spark。
谢谢!=)
不客气。
你好。
校准可以改变某些对象的预测相对位置吗?我的意思是,如果校准前对象1的预测概率大于对象2,但校准后反之亦然。
如果不可以,那是否意味着校准不影响ROC-AUC得分?
谢谢!
它通常不会,但可能会,例如,对于接近阈值的概率。
我期望校准后ROC会发生变化!
嗨,我该如何与CalibratedClassifierCV一起进行网格搜索来调整我的参数?
我不确定,也许可以尝试使用不带CV的CalibrateClassifier作为网格搜索内的管道?
Jason您好,我想知道您是否进一步考虑了与执行GridSearch进行参数调整然后进行校准相关的问题。这是一个有趣的问题,我还没有遇到多少相关的讨论。
理想情况下,校准应成为建模管道的一部分,并在测试框架内进行评估。
太棒了🙂
谢谢!
解释得很好!谢谢!
谢谢!
在SVC中使用CalibratedClassifierCV真的有必要吗?
我认为您可以使用sv = SVC(probabilities=True)进行5折交叉验证校准。对吧?
它将使用CV来估计校正后的概率,而不是评估模型。
谢谢!
那么您是建议使用CalibratedClassifierCV,还是取决于用例?
我在实践中通常会使用它。
嗨,Jason,
您能否解释一下如何生成多类别分类器概率的calibration_curve?
抱歉,我没有例子。这可能没有意义,我只见过用于二分类(我想)。
您需要做的是使用“一对多”的方法将多类别问题转换为多个二元问题(每个类别一个)。之后,您就可以为每个类别单独创建校准曲线。我所做的是使用CalibratedClassifierCV来校准我的分类器。下一步,您可以使用先前校准过的分类器创建一个OneVsRestClassifier。拟合OneVsRestClassifier后,它会提供一个名为base_estimators的字段,使用其中的每一个,您可以创建校准曲线,因为它们都代表一个二元分类器(分别代表每个类别)。请参阅 https://scikit-learn.cn/stable/modules/calibration.html#multiclass-support 中的解释,尤其是 https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.13.7457&rep=rep1&type=pdf
希望这有帮助
感谢分享。这似乎是合理的。
Jason您好,感谢您的所有帮助!我正在做一个个人项目,我一直在按XGBoost生成的概率递减顺序对正类实例进行排名。从您的文章中,我可以看到校准基本上是重新缩放。这也是我的理解。然而,我发现一旦我选择基于校准后的类别概率进行排序,候选者的顺序也会发生变化。例如:校准后0.94变为0.91,0.85变为0.95。这改变了实例的顺序(排名)。在某些情况下,概率下降了0.2,这是一个很大的幅度。
如果校准的根本机制是逻辑回归,根据模型预测的实际结果,为什么它不进行缩放并导致顺序发生变化?如果我做了错误的假设,请纠正我。谢谢!
注意:我使用的校准方法是sigmoid。
是的,可以将其视为从未校准的概率到校准后的概率的非线性映射。
例如,一个概率分布函数到另一个。
嘿,兄弟,同样的疑问。
看看这里
https://scikit-learn.cn/stable/modules/calibration.html#calibration
”
CalibratedClassifierCV使用交叉验证方法来拟合分类器和回归器。对于每个(训练集,测试集)对,一个分类器在训练集上进行训练,并在测试集上的预测用于拟合一个回归器。我们最终得到k个(分类器,回归器)对,其中每个回归器将对应分类器的输出映射到[0, 1]。每个对都暴露在calibrated_classifiers_属性中,其中每个条目都是一个校准后的分类器,其predict_proba方法输出校准后的概率。
->>>主CalibratedClassifierCV实例的predict_proba的输出对应于calibrated_classifiers_列表中的k个估计器的预测概率的平均值。
predict的输出是具有最高概率的类。
“
感谢分享。
mmmm,这不应该发生,因为您正在对单调函数取平均值。这可能是因为一些观测值,它们很接近(例如0.0021和0.002),被“挤压”在一起,然后被舍入。排名、AUC应该几乎相同。
嗨,Jason!
我有点困惑,也许你能帮我。
当我使用不同的校准策略时,模型的预测会发生变化。我曾尝试过不同的方法(platt、isotonic、prefit、cv),只是为了了解发生了什么。但我发现我的预测每次都不同。我正在处理文本数据,对25个类别进行分类。
祝好,
Vera
是的。也许选择一个指标,并通过CV或留出验证集来优化它。
你好,我想知道是否有可能进行多于两个类别的校准?如果可以,如何做?
谢谢
这可能是可能的。我没有关于这个主题的教程,抱歉。
我们如何最终确定模型?通常,当我们对模型满意后,我们会将其拟合到所有数据上。校准也是如此吗?谢谢!
是的,但您需要一个验证集或CV程序来最终确定校准。
那么,如果我理解正确,使用下面的示例,模型在步骤3中最终确定,然后可以用于预测新数据(步骤4)?
1) model=RandomForestClassifier()
2) calibrated=CalibratedClassifierCV(model, method=’sigmoid’, cv=5)
3) calibrated.fit(X_train,y_train)
4)calibrated_probs = calibrated.predict_proba(X)[:,1]
是的。
我对这里选择的数据集划分感到困惑。为什么你在训练数据上进行校准?也就是说,与分类器训练的相同数据?这不会导致偏差吗?
假设我们使用 xgboost。我们可以这样做:
1. 找到最佳参数(训练)在训练数据上训练分类器
2. 使用测试数据测量我们模型的性能
3. 在测试数据上训练校准器
4. 使用训练数据测量我们校准器的性能
5. 在train+test数据上重新训练分类器
或者可能
1. 找到最佳参数(训练)在训练数据上训练分类器
2. 使用测试数据测量我们模型的性能
3. 在train+test数据上重新训练分类器
4. 在单独的校准数据上训练校准器
5. 使用train+test数据测量我们校准器的性能
Maciej 您好……以下资源提供了训练/测试分割的最佳实践。
https://machinelearning.org.cn/training-validation-test-split-and-cross-validation-done-right/
保存/加载 CalibratedClassifierCV 是否与其他模型相同?我曾尝试保存和加载校准后的模型并进行预测,但它们的结果与模型最初创建时相比大相径庭,谢谢!
是的,我相信是这样。
很遗憾听到您遇到了麻烦。也许可以尝试将您的代码和错误发布到Stack Overflow?
这对于阅读来说很棒,对于分类器的预测也很有用。我相信我现在将永远想要做这项练习,以查看我的预测与校准后的预测相比如何。非常感谢您,先生。
谢谢!
抱歉,我不明白您说的“对角线下:模型过度预测;概率太大了。”
对角线上方:模型预测不足;概率太小。当然,如果曲线在直线下方,我们就是在预测不足?例如,给定概率为0.5,一个完美的分类器将预测50%的人口为阳性。然而,如果我们的模型说给定概率为0.5,实际比例为0.4,那么我们就是在低估阳性?
抱歉,也许我解释得不好。
也许这里“可靠性图”部分会对此有所帮助
https://www.cawcr.gov.au/projects/verification/
嗨 Jason,如果您能阐明我遇到的问题,我将非常感激:https://datascience.stackexchange.com/questions/77445/why-does-my-calibration-curve-for-platts-and-isotonic-have-less-points-than-my-u,这种情况会发生吗?我是否正确使用它?
也许您可以将您的问题概括为一两句话?
好的,假设我使用我的训练数据(例如来自网格搜索的xgboost)来拟合一个分类器。然后我运行校准,调用‘prefit’变量,并用训练数据拟合这个校准后的分类器——为什么我不能这样做?——据称您不能。
为什么您不能这样做?我没有尝试过,我很好奇。
也许只需用选定的超参数和校准再次拟合模型?
因为根据文档,用于拟合分类器的数据必须与用于拟合回归器的数据分开。
是的,也许准备一个留出数据集,或者手动从训练集中分割一部分数据。
亲爱的 Jason,
感谢您提供的有用教程。
我想知道“置信度校准”和“联合校准”有什么区别?
您是否介意编辑此教程以添加这些定义?
提前感谢您考虑我们的要求。
祝好
Maryam
感谢您的建议。
您在哪里听到这些术语的?
亲爱的 Jason,
我很感激您的快速回复。
我想搜索贝叶斯深度学习和不确定性,在这些论文中我遇到了一些关于校准的定义,我无法理解
1- Pitfalls of In-Domain Uncertainty Estimation and Ensembling in Deep Learning
2-On Calibration of Modern Neural Networks
您是否介意详细解释如何应用校准?
提前感谢你
Maryam
感谢您的建议,也许将来会考虑。
您好,我想就我在“Cross Validated”网站上提出的关于校准的全局度量的问题/想法征求您的意见。链接在这里:https://stats.stackexchange.com/questions/487179/calibration-measure-for-classification-with-linear-slope。
如果您已经有相关论文,我很乐意帮助。
感谢您的辛勤工作和建议!
这是我在这里经常回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/can-you-comment-on-my-stackoverflow-question
也许您可以为我总结一下您的问题。
感谢教程,非常有帮助!一个问题:假设我首先将数据分为测试集和训练集。然后我使用k折交叉验证进行随机搜索来查找最佳超参数或算法,然后用整个训练集拟合最佳模型。最后,我想校准我的模型(即使用prefit方法)。为此,我需要另一个完全独立于其他数据的留出集,对吗(您上面称之为valX, valY,即用于训练分类器的训练集,用于校准的验证集,以及用于最终测试的测试集)?还是有其他数据量需求较低的方法?例如,使用用于训练分类器的数据集进行校准,方法是通过对校准器应用k折交叉验证?
是的,您可以使用CV来确定模型的校准,同时使用整个数据集。这是sklearn中的默认方法。
谢谢Jason,我猜是这样。让我没有信心的句子是sklearn用户指南中的这句话:
“用户需要确保用于拟合分类器的数据与用于拟合回归器的数据是分开的。” (scikit-learn.org/stable/modules/calibration.html)
这似乎表明了相反的情况。您知道为什么吗?
也许为了说清楚我的意思:我的观点是,如果我想*预先拟合*我的分类器,然后只将CalibratedClassifierCV应用于拟合回归器,那么我需要将分类器训练中的训练/测试分割(或分割)存储起来,并将它们传递给CalibratedClassifierCV的cv参数。因为否则分割将不同,回归器将拟合分类器已经拟合过的数据。(这与使用kfold,k>1或仅k=1无关)。
我得出这个结论是因为我理解了 sklearn 的文档,如下所示:
CalibratedClassifier(my_clf, cv = 5) –> 对于每一次训练/测试分割,my_clf 在训练集上进行拟合,然后基于 my_clf.predict_proba(test_set) 来拟合回归器。关键在于,在每个折叠中,训练数据与测试数据是独立的。
CalibratedClassifier(my_clf, cv = ‘prefit’) –> 不执行交叉验证。只是根据传入的任何数据来拟合回归器。
更简洁地说:我不能使用所有数据来拟合一个分类器(my_clf),然后使用 CalibratedClassifierCV(my_clf, cv = ‘prefit),仅仅因为没有剩余数据可以让 my_clf 没有见过。
换句话说,CalibratedClassifierCV 之所以能够以其方式使用 k 折交叉验证,仅仅是因为它之后输出了它拟合的 k 个模型的预测的平均值,但绝不是一个一次性用所有数据拟合的模型输出。
是的。
没错。Prefit 意味着没有交叉验证,您将使用训练期间未见过的数据进行校准(理想情况下)。
嗯,现在想不起来。
如果您有足够的数据,在单独的数据集上进行校准会更好/更明智。我们很少这样做。
嗨,Jason,
虽然有点晚了,但我只想感谢您回复我详尽的帖子!
所以,谢谢!🙂
不客气。
我正在教授一门硕士级别的机器学习课程,并想快速地在 Python 的 Scikit-learn 模块中为线性回归和逻辑回归实现 AIC/BIC。我偶然发现了您的页面。问题是:线性回归的 AIC/BIC 公式中是否存在错误?均方误差(除以 sigma^2)已经是似然度了。为什么还要再次取其对数?另外,第二项必须乘以估计的 sigma。我会这样重写函数:
def calculate_aic(n, mse, num_params, sigma)
aic = n * mse + 2 * num_params * sigma
return aic
BIC 也是如此。
也许这会有帮助。
https://machinelearning.org.cn/probabilistic-model-selection-measures/
感谢您的帖子!也许这个问题已经有人回答过了,但更简单地说
您可以使用与用于超参数调优相同的验证集来进行校准吗(假设您将其分为训练/验证/测试)?
是的,但理想情况下,使用单独的数据集会更好——如果您能腾出数据的话。
你好。我有一个问题:如何使用 Trust Region Reflective 算法在 MATLAB 或 Scilab 中校准和预测分数流行病学模型?如果可能,我能有一个例子吗?谢谢。
抱歉,我没有您描述的技术的示例,也没有 MATLAB 的示例。
感谢这篇非常有用的教程,我有一个问题,根据以下论文,我假设校准模型可能是一种后处理,在未校准模型的结果上拟合一个新模型。我的问题是如何校准 BERT,例如(实际上,我有点困惑校准过程是如何进行的)
是的,校准可以是对预测概率的后续处理。
抱歉,我没有校准 BERT 概率的经验,我不想给出误导性的临时建议。
抱歉,我忘了发布论文
https://arxiv.org/pdf/1706.04599.pdf
嗨,Jason,
我现在正在努力校准我的 XGB 分类器的概率。由于我使用的是 xgb API,我必须使用 xgb.DMatrix 对象。所以,我不知道如何使用 CalibratedClassifier 模型。您有什么想法或建议吗?XGB.Classifier 的结果更差……M
听到这个消息我很难过。
我期望 XGBClassifier 的结果与直接使用 XGB API 的结果相同。
如果不是这样,也许是库的最新版本存在错误,或者您配置两种实现的方式存在差异?
这就是奇怪之处。我使用的是完全相同的参数,甚至是相同的随机种子。这个问题在 stackoverflow 上也讨论过,但没有结果,所以我想问您。谢谢!
嘿,杰森!
首先,感谢您的教程。😉
我能否将此方法用于多类别分类?让我简要解释一下我的问题。
我有一个分类管道,其输出是该输入属于 a、b、c… 类的概率。
尽管我有超过 100 个类别,但我只返回每个输入概率最高的 3 个类别,并基于此选择获胜者。
我想校准这些概率,以便为每个输入提供最现实的值。
那么,基于您的示例,我如何将其适应我的问题?
再次感谢您的帮助!
好问题,我不太确定,我没试过。
也许可以试验一下,看看它是否直接适用?
嗯,我明白了。我重新阅读了 scikit-learn 的文档,在概率校准解释的末尾,我发现了关于多类别使用 CalibratedClassifierCV 为每个类别单独校准(在 OneVsRestClassifier 中)的内容。我会尝试一下,如果成功了就告诉您😉
祝你好运!
Jason 您好,非常感谢您写了这么棒的文章。我正在对随机森林应用校准,但校准后的结果比未校准的结果差。我也在计算 log_loss 分数,这也表明分数随着校准而下降。这正常吗?
不客气。
这可能会发生,也许可以尝试另一种校准方法/配置,或者不进行校准。
Jason 您好,我非常感谢您所做的出色工作……但我有一个关于校准的问题……我使用了以下步骤,但我的校准概率比未校准的要差
1. 我将数据分为训练集和测试集
2. 我进一步将步骤 1 中的训练数据分为训练集和验证集
3. 我对步骤 2 中的训练数据进行了降采样
4. 我使用步骤 3 中的降采样训练数据拟合了我的模型
5. 我使用步骤 2 中未修改的验证数据校准了我的模型。
您是否知道问题所在,或者我在上述步骤中是否犯了错误?
谢谢!
这些步骤看起来不错。
也许可以尝试使用 k 折交叉验证重复此过程并将结果平均。
先生您好,感谢您的精彩讲解。我想问一下,从 SVC(使用校准分类器)中获取的概率与 SVC(将 probability 设置为 true)的概率有什么区别?它们实际上是使用了相同的过程吗?我使用这两种方式得到了不同的结果。
好问题,我建议您查阅 API 文档。
Jason 您好,如果您使用的是预拟合模型,对于验证集的大小(或者训练、验证、测试分割的比例),您有什么指导意见吗?
没有太多,除了“代表性足够”。
Jason 您好,感谢您提供的这篇信息量很大的文章。请问我应该在已经完成了分类器超参数调优之后,才对模型进行校准(使用交叉验证),对吗?还是应该在包装了 CalibratedClassifierCV() 的情况下,调整模型的超参数(例如 SVM)?非常感谢
交叉验证是为了给模型打分,所以我们可以使用该分数作为指标来比较不同的模型。因此,您应该固定超参数,然后运行 CV。
谢谢您的回复。
我仍然对如何组织我的数据来进行超参数调优和概率校准感到相当困惑。
1) 目前,我的数据被分为训练集和预留的测试集(完全不使用)。
2) 使用训练数据,我通过随机森林和随机搜索进行了超参数调优,cv=5。
3) 完成此操作后,我是否可以使用相同的数据集,固定我的超参数,然后校准模型,例如使用 cv=3?这将意味着用于超参数调优的数据也将被使用。
4) 现在,如果我想比较校准与未校准模型的性能,我该如何进行?再次使用训练数据并设置新的 cv(也许 cv=5)来拟合和测试这两个模型?
5) 然后最终的模型将是例如在所有训练数据上(不进行 CV)训练的校准模型,然后用于对预留的测试集进行预测。
非常感谢!
在步骤 2 之后,您就知道了您想要使用的超参数。然后您可以丢弃之前的 CV 数据。现在您可以 (a) 训练您的模型,或者 (b) 训练然后校准您的模型。您是在比较 (a) 和 (b)。您可以使用相同的旧训练数据对方法 (a) 和 (b) 运行 k 折交叉验证来进行比较。您可以尝试使用 scikit-learn 的 k 折交叉验证函数,但对于 (b),内部还有另一个 CV 来进行校准,因此实际用于训练的数据甚至更少。
仅在完成超参数调整后进行校准。
我明白这一点,但我一直在想,我是否可以使用我的所有训练数据并进行交叉验证来校准模型?还是用于调整模型的数据不能用于校准模型?
Jason 您好。感谢您的教程。我对我何时将此校准应用于预训练的分类器感到困惑。以下是我在自己的项目中进行的操作。
1) 我使用十折交叉验证(通过 sklearn kFold)来评估 RF、SVM 和 XGB 在固定、预调参数下的模型性能。在每次 k 折中的子测试数据上的性能指标最终被平均,以给出最终的评估和比较。
2) 在十折交叉验证之后。我使用整个训练数据拟合每个模型,并使用这些模型进行预测。特别是 SVM,将概率 < 0.5 的实例预测为正类。
我的问题是,我应该何时应用此校准步骤以提供具有校准概率的预测结果?我应该在十折交叉验证之后简单地校准它们吗?我应该使用哪种方法,prefit 还是 CV?顺便说一句,目前我只有一个训练数据集,也就是用于十折交叉验证的数据集,还有一个仅用于预测的数据集。没有独立的数据集。我现在真的很困惑,想知道是否需要将校准步骤整合到现有的十折交叉验证步骤中。如果需要,该如何进行?提前感谢您的帮助。
这应该在步骤 2 之后进行,因为在那里您已经训练好了分类器。
感谢您的回复。我阅读了代码和说明,有一个担忧。如果我没有一个独立的预留验证集来使用“prefit”方法进行校准,该怎么办?如前所述,我在步骤 2 中使用所有训练数据拟合了模型。提前感谢您的建议。
抱歉添加更多信息。我想我可以在十折交叉验证和评估方面坚持步骤 1。但是,为了校准模型以进行预测,我可以使用未训练的模型和固定参数,并使用 cv = 10,然后拟合我获得的所有训练数据。在这种情况下,它满足了训练和校准的两个目的。我在帖子中的评分最高的答案(https://stats.stackexchange.com/questions/263393/scikit-correct-way-to-calibrate-classifiers-with-calibratedclassifiercv)中读到了这个。希望这会奏效。
这是正确的。感谢您提供 StackExchange 问题的链接。
嘿,如果我理解正确的话;我们不拟合模型,而使用 cv = 5 的原因是 calibratorCV 对任何训练折叠进行模型训练,然后对校准折叠进行校准。但当 cv = prefit 时,它不进行训练,它将训练好的模型作为输入,并使用我们选择的验证集来校准该模型。您认为这就是内部机制吗?因为我很难理解哪一行代码做了什么,我就是这样理解的。如果您能批准或否定我,我将不胜感激,感谢您的工作。
嗨 Dave……您可能会发现这个资源很有益
https://machinelearning.org.cn/implement-resampling-methods-scratch-python/
嗨,Jason,
校准会提高模型的准确性吗?例如从 0.68 提高到 0.75?正如我所读到的,它只帮助维护值。
嗨 Vinay……以下内容可能对您感兴趣
https://towardsdatascience.com/classifier-calibration-7d0be1e05452
嗨 Jason,感谢您的文章!
我仍在努力理解校准的目的。您有没有什么情况是您特别想找到校准的?它就像一个评分函数吗?
此外,与预期概率相比,我们是指数据集对吗?还是领域知识
谢谢帮助。
嗨 Andrew……以下内容可能对您感兴趣
https://towardsdatascience.com/classifier-calibration-7d0be1e05452
您能否为时间序列分类建议一种校准模型的方法?
我相信 scikit learn 的校准方法,因为它依赖于标准的交叉验证,可能不合适。
提前感谢,
您能否为时间序列分类建议一种校准模型的方法?
我相信 scikit learn 的校准方法,因为它依赖于标准的交叉验证,可能不合适。
我可以通过将 TimeSeriesSplit 实例作为 cv 方法来使其工作吗?
提前感谢,
嗨 Andrea……您可能会发现以下内容很有趣
https://towardsdatascience.com/classifier-calibration-7d0be1e05452