字幕生成是一个具有挑战性的人工智能问题,它同时涉及计算机视觉和自然语言处理。
编码器-解码器循环神经网络架构已被证明在此问题上非常有效。该架构的实现可以归结为基于注入和合并的模型,这两种模型对循环神经网络在解决问题中的作用做出了不同的假设。
在本博文中,您将发现用于字幕生成的编码器-解码器循环神经网络模型的注入和合并架构。
阅读本文后,你将了解:
- 字幕生成的挑战以及编码器-解码器架构的使用。
- 注入模型,它将编码后的图像与每个单词结合起来,以生成字幕中的下一个单词。
- 合并模型,它分别编码图像和描述,然后对其进行解码以生成字幕中的下一个单词。
开始您的项目,阅读我的新书《深度学习自然语言处理》,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。

使用编码器-解码器模型的注入和合并架构进行字幕生成
照片来自 Bernard Spragg. NZ,部分权利保留。
图像字幕生成
图像字幕生成问题涉及输出对照片内容的清晰简洁的描述。
这是一个具有挑战性的人工智能问题,因为它需要计算机视觉技术来解释照片的内容,还需要自然语言处理技术来生成文本描述。
最近,深度学习方法在该挑战性问题上取得了最先进的结果。结果如此令人印象深刻,以至于这个问题已成为深度学习能力的标准演示问题。
需要深度学习处理文本数据的帮助吗?
立即参加我的免费7天电子邮件速成课程(附代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
编码器-解码器架构
标准的编码器-解码器循环神经网络架构用于解决图像字幕生成问题。
这包括两个要素:
- 编码器:一个读取照片输入并使用内部表示将其内容编码为固定长度向量的网络模型。
- 解码器:一个读取编码照片并生成文本描述输出的网络模型。
有关编码器-解码器循环神经网络架构的更多信息,请参阅博文:
通常,卷积神经网络用于编码图像,而循环神经网络(如长短期记忆网络)用于编码迄今为止生成的文本序列,或用于生成序列中的下一个单词,或两者兼有。
有许多方法可以实现用于字幕生成问题的此架构。
通常使用在具有挑战性的照片分类问题上训练过的预训练卷积神经网络模型来编码照片。可以加载预训练模型,移除模型的输出,然后使用照片的内部表示作为输入图像的编码或内部表示。
此外,通常将该问题建模为给定照片和迄今为止生成的描述作为输入,模型生成输出文本描述的一个单词。在这种建模方式下,模型被递归调用,直到生成整个输出序列。
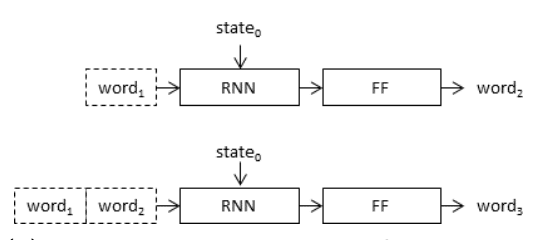
字幕生成模型的递归建模
摘自《图像字幕生成器中图像的位置》。
这种建模可以通过两种架构之一来实现,由 Marc Tanti 等人称为注入模型和合并模型。
注入模型
注入模型将图像的编码形式与迄今为止生成的文本描述的每个单词相结合。
该方法使用循环神经网络作为文本生成模型,该模型使用图像和单词信息序列作为输入,以生成序列中的下一个单词。
在这些“注入”架构中,图像向量(通常来自卷积神经网络的隐藏层的激活值)被注入到 RNN 中,例如,将图像向量视为与“单词”相当,并将其包含在字幕前缀中。
— 图像字幕生成器中图像的位置, 2017。
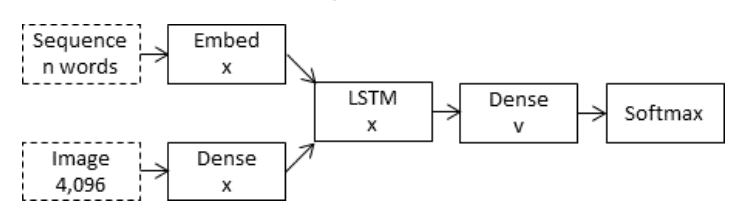
编码器-解码器模型的注入架构
摘自《循环神经网络(RNN)在图像字幕生成器中的作用?》。
该模型将图像的问题与每个输入单词结合起来,要求编码器开发一个包含视觉和语言信息在一起的编码。
在注入模型中,RNN 被训练成根据由语言和感知特征组成的历史来预测序列。因此,在该模型中,RNN 主要负责图像条件下的语言生成。
— 循环神经网络(RNN)在图像字幕生成器中的作用?, 2017。
合并模型
合并模型将图像输入的编码形式与迄今为止生成的文本描述的编码形式结合起来。
然后,将这两个编码输入的组合用于一个非常简单的解码器模型来生成序列中的下一个单词。
该方法仅使用循环神经网络来编码迄今为止生成的文本。
在“合并”架构的情况下,图像被排除在 RNN 子网络之外,因此 RNN 只处理字幕前缀,即只处理纯粹的语言信息。在字幕前缀被向量化后,图像向量会与前缀向量合并到一个单独的“多模态层”中,该层位于 RNN 子网络之后。
— 图像字幕生成器中图像的位置, 2017。
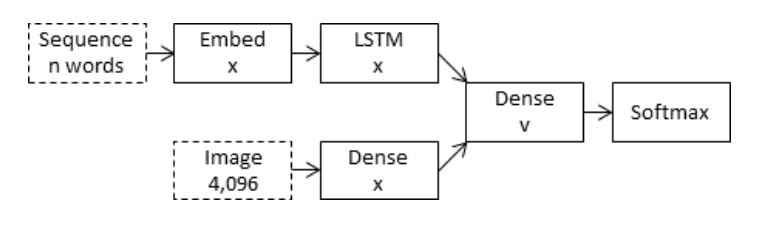
编码器-解码器模型的合并架构
摘自《循环神经网络(RNN)在图像字幕生成器中的作用?》。
这分离了对图像输入、文本输入以及编码输入的组合和解释的建模。
如前所述,通常使用预训练模型来编码图像,但同样,此架构也允许使用预训练的语言模型来编码字幕文本输入。
…在合并架构中,RNN 实质上编码语言表示,这些表示本身构成了稍后在多模态层之后出现的预测阶段的输入。只有在这个后期阶段,图像特征才用于条件化预测。
— 循环神经网络(RNN)在图像字幕生成器中的作用?, 2017。
有两种组合两个编码输入的方法,例如串联、乘法和加法,尽管 Marc Tanti 等人的实验表明加法效果更好。
总的来说,Marc Tanti 等人发现合并架构比注入方法更有效。
总的来说,证据表明将图像特征与语言编码的合并推迟到架构的后期阶段可能是有益的……结果表明,合并架构比注入架构具有更高的容量,并且可以使用更小的层生成更高质量的字幕。
— 循环神经网络(RNN)在图像字幕生成器中的作用?, 2017。
更多关于合并模型
合并模型在编码器-解码器架构中的成功表明,循环神经网络的作用是编码输入而不是生成输出。
这与普遍的理解不同,后者认为循环神经网络的贡献是作为生成模型。
如果 RNN 的主要作用是生成字幕,那么它需要能够访问图像才能知道要生成什么。情况似乎并非如此,因为将图像包含在 RNN 中通常不会对其作为字幕生成器的性能产生好处。
— 循环神经网络(RNN)在图像字幕生成器中的作用?, 2017。
对注入和合并模型的显式比较,以及合并模型在字幕生成方面优于注入模型,这引发了一个问题:这种方法是否适用于相关的序列到序列生成问题。
可以使用预训练语言模型来编码源文本,而不是使用预训练模型来编码图像,用于文本摘要、问答和机器翻译等问题。
我们希望研究类似的架构更改是否适用于机器翻译等序列到序列任务,其中我们将目标语言模型以源语言句子为条件,而不是以图像为条件。
— 循环神经网络(RNN)在图像字幕生成器中的作用?, 2017。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
总结
在本博文中,您发现了用于字幕生成的编码器-解码器循环神经网络模型的注入和合并架构。
具体来说,你学到了:
- 字幕生成的挑战以及编码器-解码器架构的使用。
- 注入模型,它将编码后的图像与每个单词结合起来,以生成字幕中的下一个单词。
- 合并模型,它分别编码图像和描述,然后对其进行解码以生成字幕中的下一个单词。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发文本数据的深度学习模型!

在几分钟内开发您自己的文本模型
...只需几行python代码
在我的新电子书中探索如何实现
用于自然语言处理的深度学习
它提供关于以下主题的自学教程:
词袋模型、词嵌入、语言模型、标题生成、文本翻译等等...
最终将深度学习应用于您的自然语言处理项目
跳过学术理论。只看结果。






你好!感谢您对社区的无限支持。我有一个问题,我需要一个充满爱心的回答,尽您所能!我正在做一个深度学习项目,用于计算车辆内的人数。根据我在谷歌上的搜索,最好的方法是 SSD 对象检测器:因为它比 YOLO 或 R CNN 等简单。
1. 您何时会有这方面的博文?
2. 我还能使用哪些其他对象检测器或深度学习方法来解决这个问题:是否有比 SSD 更好的方法来解决这个问题?
3. 如果您没有这方面的博文,您是否有专注于 SSD 或 YOLO 的资源(书籍或带示例代码的教程),以便我可以买给您?
感谢您的时间!!!
我没有关于这些主题的博文,感谢您的建议。我希望将来能涵盖它们。
嗨,Jason,
那么在进行推理而不将描述文本作为输入时,您实际上是如何生成文本输出的?我似乎从这段文字中错过了这一点。
此致,
Aleksandar
合并模型将一次生成一个单词,并使用迄今为止生成的单词序列作为输入。
这有帮助吗?
我在这方面也很困惑。请对此详细说明。我还不明白您是如何实际生成文本输出的。请详细解释。
当然,本教程实际向您展示了如何操作:
https://machinelearning.org.cn/develop-a-deep-learning-caption-generation-model-in-python/