这是 Igor Shvartser 的客座文章,他是一位我正在指导的聪明年轻学生。
这篇文章是关于建模著名的 Pima 印第安人糖尿病数据集的 3 部分系列中的第 1 部分,将介绍问题和数据。第 2 部分将探讨特征选择和算法抽查,第 3 部分将探讨分类准确率的改进和最终结果的呈现。
通过我新书《Weka 机器学习精通》,开启你的项目,书中包含所有示例的分步教程和清晰的截图。
预测糖尿病发病
数据挖掘和机器学习通过弥合海量数据集和人类知识之间的差距,正在帮助医疗专业人员简化诊断。我们可以开始将机器学习技术应用于分类,以处理一个描述了患糖尿病高风险人群的数据集。
糖尿病影响着全球 3.82 亿人,并且 2 型糖尿病患者的数量在每个国家都在增加。如果不加治疗,糖尿病会导致许多并发症。
糖尿病检测
照片由Victor拍摄,部分权利保留。
本研究的调查对象是亚利桑那州凤凰城附近的 Pima 印第安人。由于糖尿病发病率高,该人群自 1965 年以来一直受到美国国家糖尿病与消化与肾脏疾病研究所的持续研究。
在本数据集的分析中,糖尿病的诊断依据是世界卫生组织的标准,该标准规定,如果在任何一次普查检查中,2 小时口服葡萄糖耐量试验的血糖浓度至少为 200 mg/dl,或者为该社区服务的印度健康服务医院在常规医疗过程中测得的血糖浓度至少为 200 mg/dl。
鉴于我们可以收集到的关于人们的医疗数据,我们应该能够更准确地预测一个人患上糖尿病的可能性,并采取适当的行动来提供帮助。我们可以开始分析数据并试验有助于我们研究 Pima 印第安人糖尿病发病率的算法。
在Weka机器学习方面需要更多帮助吗?
参加我为期14天的免费电子邮件课程,逐步探索如何使用该平台。
点击注册,同时获得该课程的免费PDF电子书版本。
相关研究
我们的研究始于深入了解研究人员如何使用相同的数据集来处理相同的问题。这帮助我理解了数据,并为我的研究铺平了道路,特别是作者建议了值得研究的替代方法。
1988 年,Smith、Everhart、Dickson、Knowler 和 Johannes 评估了使用一种早期神经网络模型 ADAP 来预测高风险 Pima 印第安人群体中糖尿病发病的状况。他们认为,当“样本量小,潜在函数关系未知,并且潜在函数关系涉及多个变量之间复杂的交互作用和相关性”时,神经网络方法将提供强大的结果,请参阅《使用 ADAP 学习算法预测糖尿病发病率》。
他们将 ADAP 描述为“一种自适应学习程序,它生成并执行类似感知器的设备的数字模拟”,请参阅《控制和模式识别系统中的学习》。该算法将根据输入变量的函数进行预测,并在预测不正确时进行内部调整。网络分为 3 个主要层
- 输入,划分为“传感器”:代表一个离散值。这些值被组织成分区,并由输入“激活”。
- 关联单元:使用阈值函数激活特定的响应值。连接到基于所述函数变化的调整权重。
- 响应器:响应值被求和并构成特定预测。
该网络定义了一个“固定矩阵”,其中包含每个属性的分区、可能的取值范围以及通过“可变数组”识别数据连接的能力。矩阵中的行对应于传感器,而列对应于关联单元。可变数组提供了一种轻松识别传感器和关联单元之间连接的方法。
768 名 Pima 印第安女性
我们可以从 UCI 机器学习存储库 (UCI Machine Learning Repository) 获取数据,该存储库包含 21 岁以上 Pima 印第安血统女性患者的数据(更新:可在此处下载)。
我们有 768 个实例和以下 8 个属性
- 怀孕次数 (preg)
- 口服葡萄糖耐量试验 2 小时后的血浆葡萄糖浓度 (plas)
- 舒张压(毫米汞柱)(pres)
- 肱三头肌皮褶厚度(毫米)(skin)
- 2 小时血清胰岛素(毫单位/毫升)(insu)
- 身体质量指数,衡量体重(公斤)/(身高(米))^2 (mass)
- 糖尿病谱系函数 (pedi)
- 年龄(岁)(age)
研究中一个特别有趣的属性是糖尿病谱系函数 pedi。它提供了一些关于直系亲属的糖尿病史以及这些亲属与患者的遗传关系的数据。这种遗传影响的衡量标准让我们对一个人患糖尿病的可能性有一定的了解。根据上一节的观察,尚不清楚此函数在预测糖尿病发病率方面的效果如何。
数据观察
起初,我检查了每个属性,并回顾了 Weka Explorer 准备的分布参数。我观察到
- preg 和 age 属性是整数。
- 该人群普遍年轻,年龄小于 50 岁。
- 某些属性中存在零值似乎是数据中的错误(例如 plas, pres, skin, insu, 和 mass)。
在检查类值分布时,我注意到有 500 个阴性实例(65.1%)和 258 个阳性实例(34.9%)。
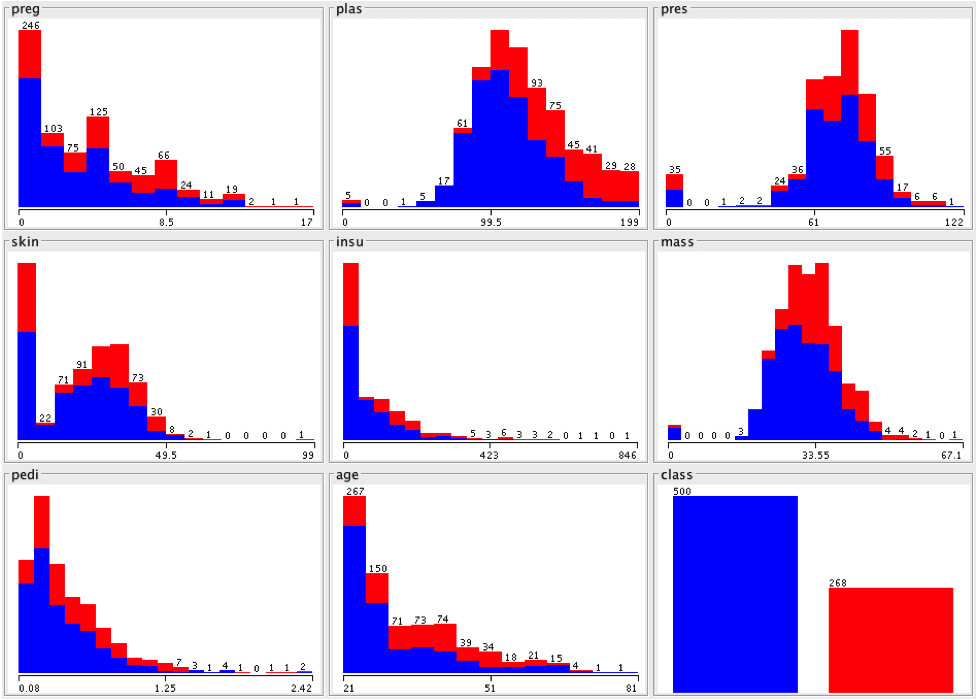
显示类别分布的属性直方图,截图来自 Weka
查看数据集中所有属性的直方图表明
- 一些属性看起来呈正态分布(plas, pres, skin, 和 mass)。
- 一些属性看起来可能呈指数分布(preg, insu, pedi, age)。
- 年龄可能应该呈正态分布,数据收集的限制可能导致了分布的偏差。
- 检验正态性(正态性图)可能很有趣。我们可以尝试将数据拟合到正态分布。
查看数据集中所有属性的散点图表明
- 年龄与糖尿病发病率之间没有明显的关联。
- pedi 函数与糖尿病发病率之间没有明显的关联。
- 这可能表明糖尿病不是遗传性的,或者糖尿病谱系函数需要改进。
- 较大的 plas 值与较大的 age, pedi, mass, insu, skin, pres, 和 preg 值结合,往往显示出更高的糖尿病阳性检测可能性。
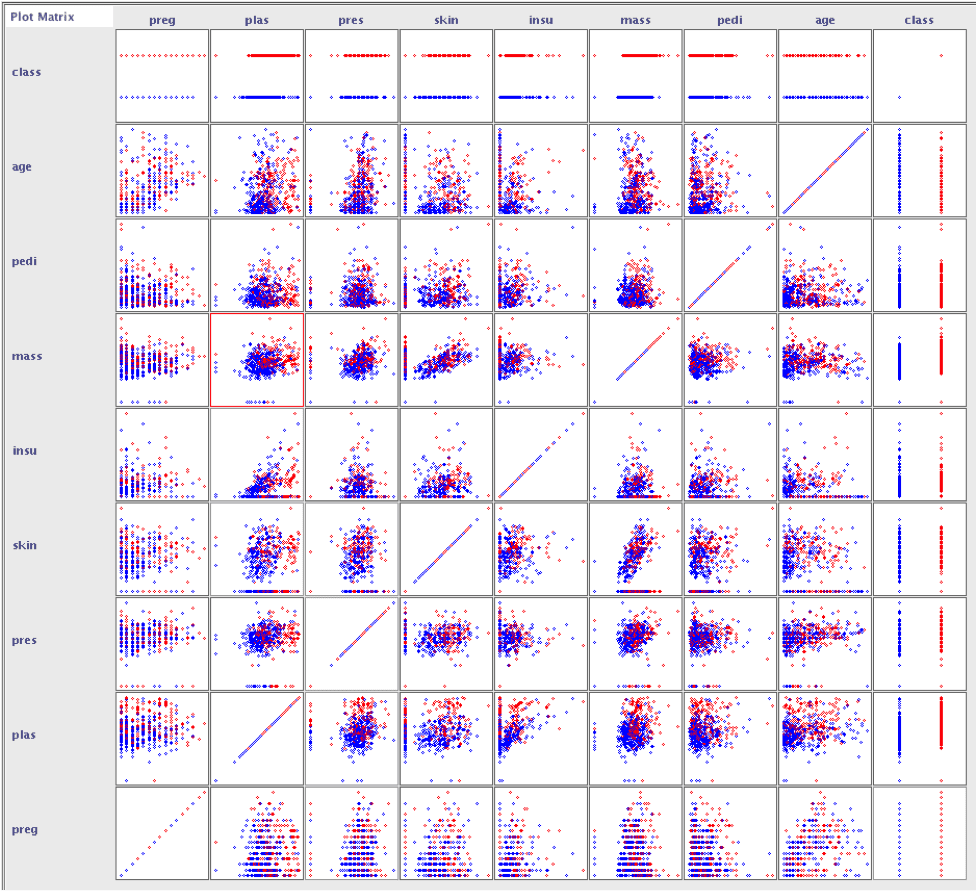
糖尿病数据散点图,截图来自 Weka
考虑数据的所有可能限制很重要,这些限制可能包括以下几点
- 结果可能仅限于 Pima 印第安人,但为我们如何开始诊断其他人群的糖尿病提供了一个良好的开端。
- 结果可能仅限于数据收集的时期(1960 年代至 1980 年代)。当今诊断糖尿病的医疗程序包括尿液检查和糖化血红蛋白 A1c 检测,后者显示了过去 3 个月内平均血糖水平。
- 数据集相当小,这可能会限制某些算法的性能。

Igor Shvartser
关于 Igor Shvartser
你好!我叫 Igor Shvartser,正在加州大学圣克鲁兹分校学习数学和计算机科学。我对机器学习非常感兴趣,在完成学校的机器学习与数据挖掘课程后,最近受到启发去深入学习。
我发现了 Machine Learning Mastery 网站,发现它非常有帮助,尤其是在补充我的课程材料方面。不久之后,我很高兴 Jason 通过电子邮件联系了我,并给了我一个为他的网站做贡献的机会。我们合作设计了一个机器学习项目,我将在接下来的几周内使用 Weka(一套在怀卡托大学编写的机器学习软件)来完成。我希望了解更多关于机器学习算法、应用和数据分析的知识,并在遇到困难时获得 Jason 的指导。
当我不在学习机器学习时,我不是在骑山地自行车,就是在与团队合作开发一款开源软件,该软件将使科学家能够分析和收集分子聚合物图像的数据。在此之前,我曾在一个位于圣克鲁兹的小型初创公司工作,帮助改变了公司管理和理解其可持续性数据的方式。
第 2 部分
请继续关注关于特征选择和算法抽查的第 2 部分。
探索无需代码的机器学习!

在几分钟内开发您自己的模型
...只需几次点击
在我的新电子书中探索如何实现
使用 Weka 精通机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、构建模型、调优等等...
最终将机器学习应用到你自己的项目中
跳过学术理论。只看结果。
")
")

")


你的网站又一篇好文章,继续保持好工作!
你好 Igor 和 Jason,
感谢你们的努力。:) 这是我的一点贡献。
– 重现了案例研究并明确说明了所使用的过滤器
– 通过以下方式扩展了案例研究:
* 通过对少数类和多数类进行过采样和欠采样来平衡类别,
* 用概率注释预测,
* 控制概率阈值以牺牲假阳性为代价来减少假阴性。
Github:https://github.com/dr-riz/diabetes
干得好!
在 Weka 中重现并扩展了案例研究后,我决定在 Python 中重现它们。原因:
我对这个问题有了理解。
Weka 案例将作为比较基线。
我想了解两个平台在解决同一问题时提供的努力程度和灵活性。
作为热身,我完成了 Dr. Brownlee 的“Python 中你的第一个机器学习项目,一步一步来”。我写了带有标题的代码,以便输出的跟随者能了解情况。
除了我扩展的 Weka 案例研究外,Python 部分通过以下方式进一步扩展了案例研究:
– 增加了用于抽查的算法。
– 使用 LR 参数平衡类别标签。
– 对超参数进行网格搜索。
– 搜索灵敏度和特异性之间的交叉点。
– 绘制 ROC 曲线。
– 灵敏度和特异性交叉。
– (不太令人兴奋)将模型保存和加载到磁盘。
Github:https://github.com/dr-riz/diabetes
我喜欢你通过许多可视化和数值检查来探索 Pima 印第安数据集的方式!非常感谢。
除了你设置不同模型以优雅地比较它们的性能的方式(对于 GridSearch、Spot check、benchmarking 等非常有用)……
我再次认为 Bronwlee 博士的教程给我们带来了很多启发,不仅是主要的机器学习概念,还包括所有必要的辅助工具,如 Python、Keras、Sklearn、Matplot……非常感谢 Jason!
JG
谢谢!
JG。很高兴你觉得我关于 Pima 数据集的工作很有用。:)
干得好!
很好的倡议。为你们俩喝彩!
你好,有谁知道糖尿病谱系函数是如何计算的吗?
在https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2245318/pdf/procascamc00018-0276.pdf中找到了。
太棒了!
这个可能会有帮助
https://github.com/jbrownlee/Datasets/blob/master/pima-indians-diabetes.names