这是伊戈尔·什瓦尔策(Igor Shvartser)的客座博文,他是一位我一直在指导的聪明的年轻学生。
这篇博文是关于对著名的皮马印第安人糖尿病数据集进行建模的系列文章中的第2部分(更新:可从此处下载)。 在第1部分中,我们定义了问题并研究了数据集,描述了我们在数据中注意到的模式的观察结果。
在本部分中,我们将介绍方法论,进行算法的抽样检查,并回顾初步结果。
通过我的新书 《Weka 机器学习精通》来启动您的项目,书中包含分步教程和所有示例的清晰屏幕截图。
方法论
本研究中的分析和数据处理是使用Weka 机器学习软件完成的。实验使用了十折交叉验证。其工作原理如下:
- 从给定数据中生成 10 个大小相等的子集。
- 将每个子集分为两组:90% 用于训练,10% 用于测试。
- 使用 90% 标记数据中的算法生成一个分类器,并将其应用于第一个子集的 10% 测试数据。
- 对子集 2 到 10 重复此操作。
- 对由 10 个大小相等(训练和测试)的子集生成的 10 个分类器的性能取平均值。
在Weka机器学习方面需要更多帮助吗?
参加我为期14天的免费电子邮件课程,逐步探索如何使用该平台。
点击注册,同时获得该课程的免费PDF电子书版本。
算法
在本研究中,我们将考察 4 种算法的性能。
- 逻辑回归(Cessie & Houwelingen, 1990)
- 朴素贝叶斯(John & Langley, 1995)
- 随机森林(Breiman, 2001)
- C4.5(Quinlan, 1993)
这些算法之所以重要,是因为它们可以对数据集进行分类,能够妥善处理缺失或错误的数据,并且在专注于医学诊断的科学文章中具有一定的意义,请参阅论文《机器学习在医学诊断中的应用:历史、现状与展望》和《人工神经网络在医学诊断中的应用》。
逻辑回归是一种概率统计分类器,用于根据一个或多个预测变量预测分类因变量的结果。该算法衡量因变量与一个或多个自变量之间的关系。
朴素贝叶斯是一种基于贝叶斯定理的简单概率分类器,它做出了强烈的独立性假设。贝叶斯定理如下:

贝叶斯定理
通常,我们可以通过观察某些证据或事件的概率来预测某个事件的结果。我们拥有的支持事件发生的证据越多,我们对其预测的支持就越好。有时,我们拥有的证据可能依赖于其他事件,这会使我们的预测更加复杂。为了创建一个简化的(或“朴素的”)模型,我们假设特定事件的所有证据都与其他事件相互独立。
根据 Breiman 的说法,随机森林创建了投票决定特定结果的树的组合。森林选择获得最多选票的分类。该算法之所以令人兴奋,是因为它是一种装袋算法,并且它有可能通过在不同的训练数据子集上训练算法来提高我们的结果。随机森林学习器的生长方式如下:
- 从训练集中进行有放回抽样,形成输入数据。训练集的三分之一未包含在内,被称为“袋外”(out-of-bag)。
- 为每棵树选择随机数量的属性,这些属性形成节点和叶子。
- 每棵树都生长到尽可能大,而不进行修剪(移除对分类贡献很少的树部分)。
- 然后使用袋外数据来评估每棵树和整个森林的准确性。
C4.5(在 Weka 中也称为“J48”)是一种用于生成分类决策树的算法。C4.5 中的决策树生长方式如下:
- 在每个节点上,选择最能将样本有效分割成一个类别富集于某个类别而另一个类别贫乏的子集的数据。
- 设置具有最高信息增益比的属性。
- 使用此属性创建决策节点并进行预测。
在这种情况下,信息增益比是衡量两个属性的两个概率分布之间差异的度量。该算法对我们有用的原因在于,它解决了 Quinlan 早期算法 ID3 可能遗漏的几个问题。根据 Quinlan 的说法,这些问题包括但不限于:
- 避免对数据过拟合(确定决策树的生长深度)。
- 减误剪枝。
- 规则后剪枝。
- 处理连续属性(例如,温度)。
- 选择合适的属性选择度量。
- 处理具有缺失属性值的训练数据。
- 处理具有不同成本的属性。
- 提高计算效率。
评估 (Evaluation)
在对数据集执行交叉验证后,我将重点通过三个指标来分析这些算法:准确率、ROC 面积和 F1 分数。
根据测试,准确率将确定算法正确分类的实例的百分比。这是我们分析的重要起点,因为它将为我们提供每种算法性能的基准。
ROC 曲线是通过绘制真阳性率与假阳性率绘制而成的。最优分类器的 ROC 面积值接近 1.0,而 0.5 则相当于随机猜测。我相信在这个尺度上看到我们的算法如何进行预测会非常有趣。
最后,F1 分数将是对分类的重要统计分析,因为它将衡量测试准确率。F1 分数使用精确率(真阳性数除以真阳性数和假阳性数之和)和召回率(真阳性数除以真阳性数和假阴性数之和)来输出一个介于 0 和 1 之间的值,值越高表示性能越好。
我强烈认为所有算法的性能会相当相似,因为我们处理的是一个用于分类的小型数据集。然而,这 4 种算法的性能都应该优于类基线预测,后者的准确率约为 65%。
结果
为了对各种算法进行严谨的分析,我使用Weka Experimenter 在所有创建的数据集上评估了性能。结果如下所示。

算法分类准确率在糖尿病数据集上的平均值以及逻辑回归在各种数据集上的性能散点图。
这里的数据表明,逻辑回归在标准、未更改的数据集上表现最好,而随机森林表现最差。然而,任何算法之间都没有明显的赢家。
平均而言,标准化和归一化数据集也似乎能提供更强的准确率,而离散数据集的准确率则最弱。这可能是因为名义值不允许我考虑的算法进行准确预测。
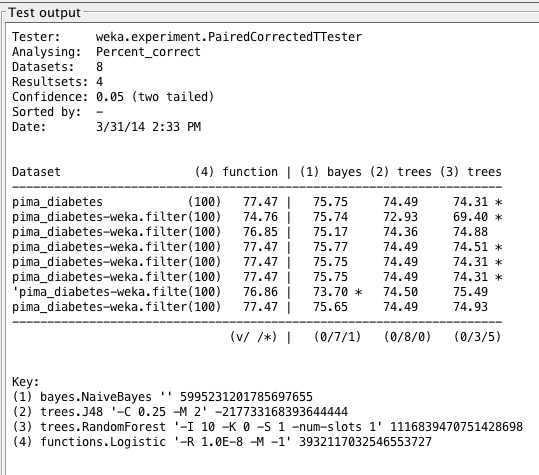
Weka Experimenter 输出比较了逻辑回归与其他算法的性能。
对归一化数据集进行尺度调整可能略微改善了结果。然而,对数据进行转换和重新缩放并未显著改善结果,因此可能并未揭示数据中的任何结构。
我们还可以看到值旁边有星号(*),这些值与第一列(逻辑回归的准确率)中的值在统计学上存在显著差异。Weka 通过配对比较方案来确定统计上的不显著性,这些方案使用标准 T 检验或校正重采样 T 检验,请参阅论文《泛化误差的推断》。
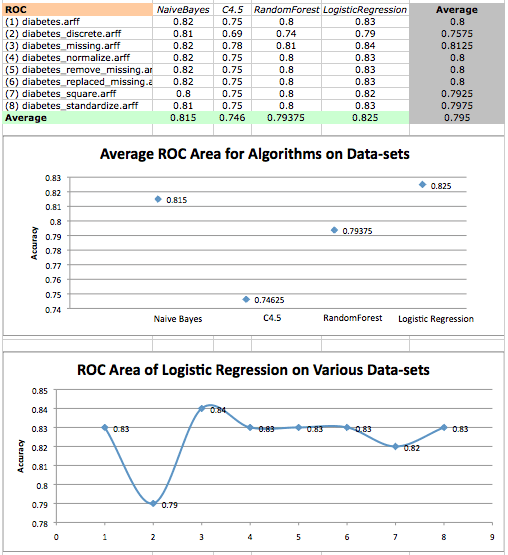
算法 ROC 面积在糖尿病数据集上的平均值以及逻辑回归在各种数据集上的性能散点图。
结果再次表明,逻辑回归表现最好,而 C4.5 表现最差。平均而言,纠正了缺失值的数据集表现最好,而离散数据集表现最差。
在这两种情况下,我们发现树形算法在此数据集上的表现不佳。事实上,C4.5 给出的所有结果(以及随机森林中的一个结果)与逻辑回归给出的结果在统计学上存在显著差异。
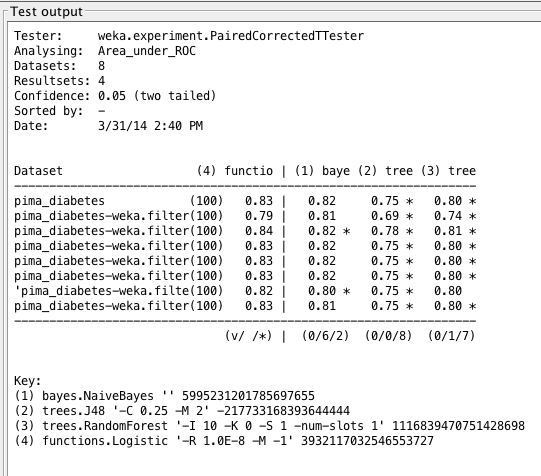
Weka Experimenter 输出比较了逻辑回归的 ROC 曲线面积与其他算法的 ROC 曲线面积。
这种较差的表现可能是由于树形算法的复杂性。衡量因变量和自变量之间的关系在此可能具有优势。此外,C4.5 可能没有选择正确的属性进行分析,从而导致基于最高信息增益的预测变差。
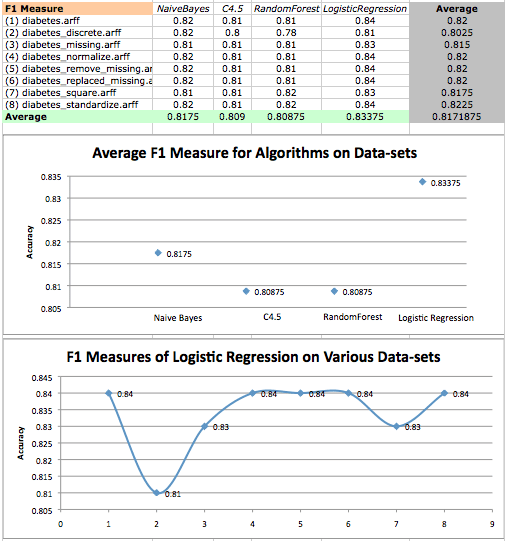
F1 分数在糖尿病数据集上的值以及逻辑回归 F1 分数在各种数据集上的散点图。
在前两次分析中,我们发现朴素贝叶斯的性能紧随逻辑回归的性能之后。现在我们发现,除了一个结果之外,朴素贝叶斯的所有结果与逻辑回归给出的结果在统计学上都存在显著差异。
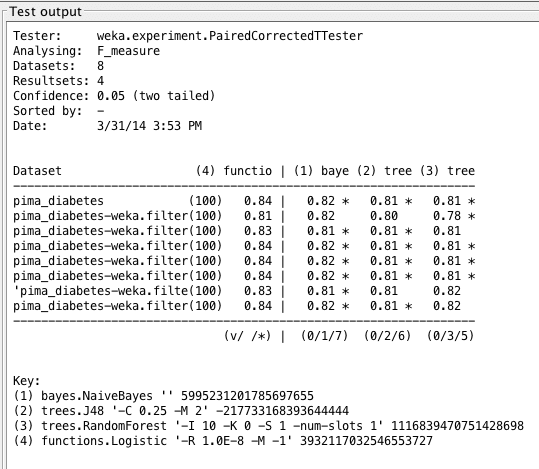
Weka Experimenter 输出比较了逻辑回归的 F1 分数与其他算法的 F1 分数。
结果表明,逻辑回归表现最好,但差距不大。这意味着逻辑回归在这种情况下具有最准确的测试,并且在此数据集上学习得很好。为了回顾 F1 分数背后的计算,我们知道:
- 召回率: R = TP / (TP + FN),
- 精确率: P = TP / (TP + FP),以及
- F1 分数: F1 = 2[ (R * P) / (R + P) ],
其中 TP = 真阳性,FP = 假阳性,FN = 假阴性。
我们的结果表明,逻辑回归最大化了真阳性率,并最小化了假阴性和假阳性率。至于糟糕的表现,我认为朴素贝叶斯进行的预测过于“朴素”,因此该算法过度使用了独立性假设。
我们可能需要更多数据来为某个事件的发生提供更多证据,这应该能更好地支持其预测。在这种情况下,树形算法可能会因其复杂性而受损,或者仅仅是因为选择了错误的属性进行分析。随着数据集的增大,这可能不再是问题。
有趣的是,我们还发现表现最好的算法逻辑回归在diabetes_discrete.arff 数据集上表现最差。可以安全地假设,对于逻辑回归而言,除了diabetes_discrete.arff 之外,所有数据转换似乎都能产生更好且非常相似的结果,这一点可以通过每个散点图中相似的趋势清楚地看出!
接下来,在第 3 部分中,我们将研究如何提高分类准确率并最终展示结果。
探索无需代码的机器学习!

在几分钟内开发您自己的模型
...只需几次点击
在我的新电子书中探索如何实现
使用 Weka 精通机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、构建模型、调优等等...
最终将机器学习应用到你自己的项目中
跳过学术理论。只看结果。
")
")

")


您好,感谢您的分析,能否请您解释一下 Weka 是如何实现不同的数据集转换的?也就是说,标准化数据集和归一化数据集有什么区别?缺失值被什么值替换了?
提前感谢
– 重现了案例研究,并明确说明了使用的过滤器。
Github:https://github.com/dr-riz/diabetes
干得好!
很棒的博客!我刚完成了关于同一数据库的研究,我的想法在某种程度上受到了您的工作的启发,但有更多实现细节。我在研究中使用了 scikit-learn python 库。
我的工作可以在这里找到:
https://www.wenhaoz.net/blog/?p=22
谢谢 Daniel。
我正在用 Python 重现这个案例研究。虽然我不担心平均准确率的差异,但我注意到平台报告的统计显着性有所不同。有什么突出的吗?
Github:https://github.com/dr-riz/diabetes/blob/master/diabetes.py
在 Weka 中,我没有看到考虑的算法之间有任何统计差异。
数据集(1)函数 | (2)贝叶斯 (3)树 (4)树 (5)树
------------------------------------------------------------------
pima_diabetes (100) 77.10 | 75.75 74.49 76.10 74.56
normalized.arff (100) 77.10 | 75.77 74.49 76.03 74.56
standardized.arff (100) 77.10 | 75.65 74.49 76.05 74.51
------------------------------------------------------------------
(v/ /*) | (0/3/0) (0/3/0) (0/3/0) (0/3/0)
键
(1) functions.SimpleLogistic ‘-I 0 -M 500 -H 50 -W 0.0’ 7397710626304705059
(2) bayes.NaiveBayes (NB) ” 5995231201785697655
(3) trees.J48 ‘-C 0.25 -M 2’ -217733168393644444
(4) trees.RandomForest ‘-P 100 -I 100 -num-slots 1 -K 0 -M 1.0 -V 0.001 -S 1’ 1116839470751428698
(5) trees.SimpleCart ‘-M 2.0 -N 5 -C 1.0 -S 1’ 4154189200352566053
在 Python 的 scipy.stats.ttest_rel 中。
= diabetes_attr =
算法,平均值,标准差,显着性,p 值
LR: 0.769515 (0.048411) 否 nan
NB: 0.755178 (0.042766) 是 0.153974 <= 统计差异
RF: 0.752495 (0.075017) 是 0.219830 <= 统计差异
DT: 0.695181 (0.062523) 否 0.000738 <= 平均准确率约为 .70,但与 LR 没有差异……令人费解。
= normalized_attr =
算法,平均值,标准差,显着性,p 值
LR: 0.761740 (0.052185) 否 nan
NB: 0.755178 (0.042766) 是 0.481693 <= 统计差异
RF: 0.756494 (0.049717) 是 0.439988 <= 统计差异
DT: 0.693934 (0.052831) 否 0.000706
= standardized_attr =
算法,平均值,标准差,显着性,p 值
LR: 0.779956 (0.050088) 否 nan
NB: 0.755178 (0.042766) 否 0.003418
RF: 0.747317 (0.068342) 否 0.012759
DT: 0.700359 (0.076543) 否 0.000716
我的错,p 值,小于 0.05,则显著。大于 0.05,则不显著。[1,2]
为了交叉检查 p 值,我将“结果”输入 Excel 生成了 p 值 [3]。
[1] http://blog.minitab.com/blog/understanding-statistics/what-can-you-say-when-your-p-value-is-greater-than-005
[2] https://www.statsdirect.com/help/basics/p_values.htm
[3] https://www.youtube.com/watch?v=RHBIQ2reACM
修订的显着性评估。
评估指标:准确率
= diabetes_attr =
算法,平均值,标准差,显着性,p 值
LR: 0.769515 (0.048411) 否 nan
NB: 0.755178 (0.042766) 否 0.153974
RF: 0.756459 (0.046061) 否 0.277776
DT: 0.693934 (0.065643) 是 0.000325
== 5.4 选择最佳模型,比较算法 ==
= normalized_attr =
算法,平均值,标准差,显着性,p 值
LR: 0.761740 (0.052185) 否 nan
NB: 0.755178 (0.042766) 否 0.481693
RF: 0.755263 (0.051668) 否 0.615343
DT: 0.697847 (0.062331) 是 0.000174
== 5.4 选择最佳模型,比较算法 ==
= standardized_attr =
算法,平均值,标准差,显着性,p 值
LR: 0.779956 (0.050088) 否 nan
NB: 0.755178 (0.042766) 是 0.003418
RF: 0.752597 (0.070907) 是 0.010882
DT: 0.703042 (0.062132) 是 0.000062
您需要增加重复次数才能获得更好的人群结果进行比较。
您是指增加交叉验证的折数,从 10 增加到其他数字吗?增加多少?
不,是实验的重复次数。
在这里了解更多
https://machinelearning.org.cn/evaluate-skill-deep-learning-models/