梯度提升算法是强大的预测工具,而 CatBoost 因其对类别数据的有效处理而广受欢迎。这对于包含大量类别特征(如邻里、房屋风格和销售条件)的 Ames 住房数据集尤其有价值。
CatBoost 通过其创新的“有序目标统计”方法在类别特征方面表现出色。与需要大量预处理(如独热编码)的传统方法不同,CatBoost 可以直接处理类别变量。它会计算每个类别的目标变量的统计数据,并考虑示例的顺序以防止过拟合。
在本文中,我们将探讨 CatBoost 的独特功能,例如对称树和有序提升,并比较不同的配置。您将学习如何为回归任务实现 CatBoost,如何有效准备数据,以及如何分析特征重要性。无论您是数据科学家还是房地产分析师,本文都将帮助您理解和应用 CatBoost 来改进您的预测模型。
通过我的书《进阶数据科学》启动您的项目。它提供了带有可运行代码的自学教程。
让我们开始吧。

CatBoost 要点:构建稳健的房价预测系统
照片来源:Kote Puerto。部分权利保留。
概述
本文分为五个部分,它们是:
- 安装 CatBoost
- CatBoost 的关键区别
- 与其他提升算法的重叠特征
- 为房价预测实现 CatBoost
- CatBoost 特征重要性分析
安装 CatBoost
CatBoost(Categorical Boosting 的缩写)是一种使用决策树梯度提升的机器学习算法。它由俄罗斯科技公司 Yandex 开发,在处理具有类别特征的数据集方面特别有效。 您可以使用以下命令安装 CatBoost:
|
1 |
pip install catboost |
此命令将下载并安装 CatBoost 包及其必要的依赖项。
想开始学习进阶数据科学吗?
立即参加我的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
CatBoost 的关键区别
CatBoost 在几个方面脱颖而出,不同于 Gradient Boosting Regressor、XGBoost 和 LightGBM 等其他梯度提升框架:
- 对称树:CatBoost 构建对称树,这有助于减少过拟合和提高泛化能力。
- 有序提升:CatBoost 中的一个可选参数,它使用一种驱动排列的替代方法来代替标准的梯度提升方案。
让我们深入探讨这些使 CatBoost 脱颖而出的两个独特功能。
对称树:平衡性能与泛化
对称树的使用是 CatBoost 的一个关键区别。
- 树结构:与其他算法中可能出现的深度不平衡的树不同,CatBoost 增长的树更加平衡和对称。
- 工作原理:
- 强制在每个节点上更均匀地划分数据。
- 限制树的深度,同时保持其预测能力。
- 优点:
- 减少过拟合:平衡的结构可防止创建过于具体的分支。
- 提高泛化能力:对称树在未见过的数据上往往表现更好。
- 增强可解释性:更平衡的树通常更容易理解和解释。
- 比较:虽然 Gradient Boosting Regressor、XGBoost 和 LightGBM 等其他算法通常使用深度优先或叶子优先的增长策略,可能导致非对称树,但 CatBoost 在坚持对称树结构方面是独一无二的。
有序提升:梯度提升的可选方法
有序提升是 CatBoost 中的一个可选参数,旨在解决目标泄露问题。
- 问题:在传统的梯度提升中,模型同时为所有实例计算梯度,这可能导致细微的过拟合。
- CatBoost 的解决方案:
- 创建数据集的多个随机排列。
- 对于每个实例,它仅使用排列中的前一个实例来计算梯度。
- 构建多个模型,每个模型对应一个排列,然后将它们组合起来。
- 潜在好处:
- 减少过拟合:通过使用不同的排列,模型不太可能记住特定模式。
- 更稳定的预测:对训练数据的特定顺序不太敏感。
值得注意的是,虽然有序提升是 CatBoost 的一项独特功能,但它是一个可选参数,而不是默认设置。
与其他提升算法的重叠特征
虽然有序提升和对称树是 CatBoost 所独有的,但它与其他梯度提升框架共享一些高级功能。
自动处理类别特征
- CatBoost 和 LightGBM 可以直接处理类别特征,而无需进行独热编码等预处理步骤。
- XGBoost 最近增加了对类别特征的实验性支持。
- GBR(Gradient Boosting Regressor)通常需要手动编码类别变量。
此功能对我们的房价预测任务特别有益,因为房地产数据通常包含大量类别变量。
GPU 加速
- CatBoost、XGBoost 和 LightGBM 都提供本地 GPU 支持,可加快大型数据集上的训练速度。
- scikit-learn 中的标准 GBR 实现不提供 GPU 加速。
GPU 加速可以显著加快训练过程,尤其是在处理大型住房数据集或进行广泛的超参数调整时。
为房价预测实现 CatBoost
在探索了 CatBoost 的独特功能之后,让我们通过使用 Ames 住房数据集将它们付诸实践。我们将实现默认的 CatBoost 模型和带有有序提升的模型,以比较它们的性能。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# 导入运行 CatBoost Regressor 的库 import pandas as pd from catboost import CatBoostRegressor from sklearn.model_selection import cross_val_score # 加载数据集 data = pd.read_csv('Ames.csv') X = data.drop(['SalePrice'], axis=1) y = data['SalePrice'] # 识别并填充类别列中的 NaN 值 cat_features = [col for col in X.columns if X[col].dtype == 'object'] X['Electrical'] = X['Electrical'].fillna(X['Electrical'].mode()[0]) X[cat_features] = X[cat_features].fillna('Missing') # 识别类别列 cat_features = X.select_dtypes(include=['object']).columns.tolist() # 定义并训练默认的 CatBoost 模型 default_model = CatBoostRegressor(cat_features=cat_features, random_state=42, verbose=0) default_scores = cross_val_score(default_model, X, y, cv=5, scoring='r2') print(f"默认 CatBoost 的平均 R² 分数:{default_scores.mean():.4f}") # 定义并训练带有有序提升的 CatBoost 模型 ordered_model = CatBoostRegressor(cat_features=cat_features, random_state=42, boosting_type='Ordered', verbose=0) ordered_scores = cross_val_score(ordered_model, X, y, cv=5, scoring='r2') print(f"CatBoost 与有序提升的平均 R² 分数:{ordered_scores.mean():.4f}") |
让我们分解一下此实现的要点:
- 数据准备:我们加载 Ames 住房数据集,并将特征 (X) 与目标变量 (y) 分开。我们识别类别列并填充任何缺失值。对于“Electrical”列,我们使用众数(最常见的值)。对于所有其他类别列,我们将缺失值填充为字符串“Missing”。此步骤是必需的,因为 CatBoost 在类别特征中不能很好地处理
np.nan值。如我们在此所做的,对缺失值进行显式处理可确保所有类别值均为有效字符串。值得注意的是,CatBoost 可以处理数值特征中的缺失值 (np.nan) 而无需此类修订,这表明了对类别和数值缺失数据的不同行为。 - 指定类别特征:我们使用
cat_features参数明确告知 CatBoost 哪些列是类别。这是一个重要步骤,因为它允许 CatBoost 应用其对类别变量的特殊处理。 - 模型训练和评估:我们创建了两个 CatBoost 模型——一个具有默认设置,另一个具有有序提升。两个模型都使用 5 折交叉验证进行评估。
运行此代码的结果是:
|
1 2 |
默认 CatBoost 的平均 R² 分数:0.9310 CatBoost 与有序提升的平均 R² 分数:0.9182 |
默认的 CatBoost 模型在本次数据集上的表现优于有序提升变体。默认模型达到了令人印象深刻的 R² 分数 0.9310,解释了房屋价格方差的约 93.1%。虽然有序提升模型表现仍然良好,R² 分数为 0.9182,但未能达到默认模型的性能。
这一结果强调了一个要点:尽管有序提升是一项旨在减少目标泄露的创新功能,但它不一定总是能带来更好的性能。有序提升的有效性可能取决于数据集的特定特征以及预测任务的性质。
在我们的例子中,默认的 CatBoost 设置似乎非常适合 Ames 住房数据集。这突显了尝试不同模型配置的重要性,并且不要假设更复杂或创新的方法总是能产生更好的结果。
CatBoost 特征重要性分析
在本节中,我们将仔细研究默认的 CatBoost 模型,以了解哪些特征对预测房价最重要。通过采用稳健的交叉验证方法,我们可以可靠地识别顶级预测变量,同时减轻过拟合到任何特定数据分割的风险。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
# 构建上面的代码块以提取特征重要性 import numpy as np import seaborn as sns import matplotlib.pyplot as plt from catboost import CatBoostRegressor from sklearn.model_selection import KFold # 设置 K 折交叉验证 kf = KFold(n_splits=5) feature_importances = [] # 遍历每个分割 for train_index, test_index in kf.split(X): X_train, X_test = X.iloc[train_index], X.iloc[test_index] y_train, y_test = y.iloc[train_index], y.iloc[test_index] # 训练默认 CatBoost 模型 model = CatBoostRegressor(cat_features=cat_features, random_state=42, verbose=0) model.fit(X_train, y_train) feature_importances.append(model.get_feature_importance()) # 计算所有折叠的平均特征重要性 avg_importance = np.mean(feature_importances, axis=0) # 转换为 DataFrame feat_imp_df = pd.DataFrame({'Feature': X.columns, 'Importance': avg_importance}) # 对前 20 个特征进行排序 top_features = feat_imp_df.sort_values(by='Importance', ascending=False).head(20) # 设置样式和调色板 sns.set_style("whitegrid") palette = sns.color_palette("rocket", len(top_features)) # 创建绘图 plt.figure(figsize=(12, 10)) ax = sns.barplot(x='Importance', y='Feature', data=top_features, palette=palette) # 自定义绘图 plt.title('Top 20 Most Important Features - CatBoost Model', fontsize=20, fontweight='bold') plt.xlabel('Importance Score', fontsize=15) plt.ylabel('Features', fontsize=15) # 为每个条形图的末尾添加数值标签 for i, v in enumerate(top_features['Importance']): ax.text(v + 0.01, i, f'{v:.2f}', va='center', fontsize=13) # 将 x 轴延长 10%,并调整特征名称字体大小 plt.xlim(0, max(top_features['Importance']) * 1.1) plt.yticks(fontsize=13) # 调整布局并显示 plt.tight_layout() plt.show() |
我们的分析使用了 5 折交叉验证来确保特征重要性排名的稳定性和可靠性。
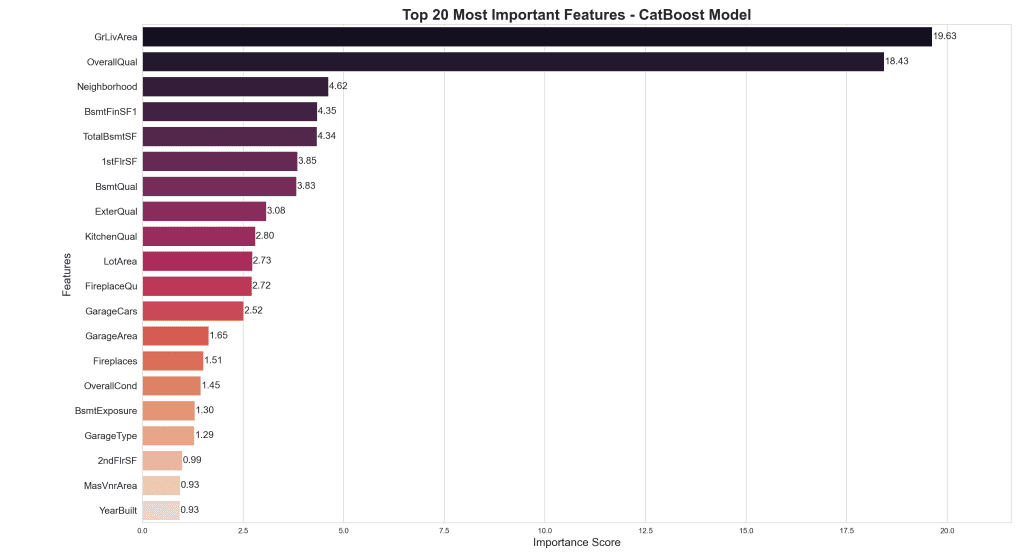 从可视化来看,我们可以得出几个重要见解:
从可视化来看,我们可以得出几个重要见解:
- 顶级预测变量:‘GrLivArea’(地面居住面积)和‘OverallQual’(整体质量)这两个特征的权重大得多。这表明居住面积的大小和房屋的整体质量是房价的最强预测指标。
- 社区很重要:“Neighborhood”位列第三重要的特征,突出了位置对房价的重大影响。
- 尺寸和质量占主导地位:许多最重要的特征与房屋不同方面的尺寸(例如,“TotalBsmtSF”、“1stFlrSF”)或质量(例如,“ExterQual”、“KitchenQual”)有关。
- 地下室特征:几个与地下室相关的特征(“BsmtFinSF1”、“TotalBsmtSF”、“BsmtQual”)出现在前 10 名中,表明地下室特征在确定房屋价值方面的重要性。
- 外部因素:诸如“ExterQual”(外部质量)和“LotArea”之类的特征也起着重要作用,这表明房屋外部的质量和地块的大小都会影响价格。
- 年龄很重要,但没那么重要:“YearBuilt”出现在前 20 名中,但其相对较低的重要性表明,其他因素在决定房屋价格时通常会压倒房屋的年龄。
通过利用这些见解,房地产市场利益相关者可以在物业估值、房屋翻新和投资策略方面做出更明智的决策。
进一步阅读
教程
Ames 住房数据集和数据字典
总结
在这篇博文中,我们探讨了强大的梯度提升库 CatBoost,并将其应用于使用 Ames 住房数据集的房价预测任务。我们强调了 CatBoost 的独特功能,包括对称树和有序提升。通过实际应用,我们演示了如何将 CatBoost 用于回归任务,并分析了特征重要性,以深入了解对房价影响最大的因素。
具体来说,你学到了:
- CatBoost 中的默认与高级配置:虽然 CatBoost 提供了有序提升等高级功能,但我们的结果表明,更简单的配置(如默认设置)有时可以优于更复杂的配置。这突显了实验的重要性,并且不要假设更高级的技术总是能带来更好的结果。
- CatBoost 的数据准备:我们讨论了为 CatBoost 进行适当数据准备的重要性,包括处理类别特征和缺失值。CatBoost 在类别列中不能很好地处理
np.nan值,因此需要字符串转换或显式缺失值处理。 - 稳健的特征重要性分析:我们采用了 5 折交叉验证方法来计算特征重要性,从而确保了影响特征的稳定可靠的排名。与单个训练测试分割相比,此方法提供了更稳健的特征重要性估计,考虑了不同数据子集之间的变异性。
您有任何问题吗?请在下面的评论中提出您的问题,我将尽力回答。






暂无评论。