激活函数是神经网络设计中至关重要的组成部分。
隐藏层中激活函数的选择将决定网络模型学习训练数据的效果。输出层中激活函数的选择将定义模型可以进行的预测的类型。
因此,对于每个深度学习神经网络项目,都必须仔细选择激活函数。
在本教程中,您将学习如何为神经网络模型选择激活函数。
完成本教程后,您将了解:
- 激活函数是神经网络设计的重要组成部分。
- 隐藏层的现代默认激活函数是ReLU函数。
- 输出层的激活函数取决于预测问题的类型。
让我们开始吧。

如何为深度学习选择激活函数
照片作者:Peter Dowley,部分权利保留。
教程概述
本教程分为三个部分;它们是:
- 激活函数
- 隐藏层的激活
- 输出层的激活
激活函数
神经网络中的激活函数定义了输入的加权和如何转换为网络层中节点或节点的输出。
有时激活函数被称为“传递函数”。如果激活函数的输出范围受限,则可能被称为“压缩函数”。许多激活函数是非线性的,可能被称为层或网络设计中的“非线性”。
激活函数的选择对神经网络的能力和性能有很大影响,并且模型的不同部分可以使用不同的激活函数。
从技术上讲,激活函数在网络中每个节点的内部处理过程中或之后使用,尽管网络被设计为在层中的所有节点使用相同的激活函数。
网络可以有三种类型的层:输入层,用于接收来自域的原始输入;隐藏层,用于接收来自另一层的输入并传递输出到另一层;以及输出层,用于进行预测。
所有隐藏层通常使用相同的激活函数。输出层通常使用与隐藏层不同的激活函数,具体取决于模型所需的预测类型。
激活函数通常也是可微的,这意味着可以计算给定输入值的导数。这是必需的,因为神经网络通常使用误差反向传播算法进行训练,该算法需要预测误差的导数才能更新模型权重。
神经网络中有许多不同类型的激活函数,尽管在实践中用于隐藏层和输出层的函数可能只有少数几种。
让我们依次看看用于每种类型层的激活函数。
隐藏层的激活
神经网络中的隐藏层是接收来自另一层(例如另一隐藏层或输入层)的输入并向另一层(例如另一隐藏层或输出层)提供输出的层。
隐藏层不直接接触输入数据,也不直接产生模型的输出,至少在一般情况下是这样。
神经网络可以有零个或多个隐藏层。
通常,神经网络的隐藏层使用可微的非线性激活函数。这使得模型能够学习比使用线性激活函数训练的网络更复杂的函数。
为了获得对更丰富的假设空间(将受益于深度表示)的访问,您需要一个非线性函数,即激活函数。
—— 第72页,《深度学习与 Python》,2017。
您可能需要考虑用于隐藏层的激活函数有大约三种;它们是:
- 修正线性激活(ReLU)
- Logistic(Sigmoid)
- 双曲正切(Tanh)
这不是隐藏层激活函数的详尽列表,但它们是最常用的。
让我们依次仔细看看每一个。
ReLU隐藏层激活函数
修正线性激活函数,或称ReLU激活函数,可能是隐藏层中最常用的函数。
它之所以常用,是因为它既易于实现,又能有效克服Sigmoid和Tanh等先前流行激活函数的局限性。具体来说,它不太容易出现梯度消失,这会阻碍深度模型的训练,尽管它可能面临饱和或“死亡”单元等其他问题。
ReLU函数计算如下:
- max(0.0, x)
这意味着如果输入值(x)为负,则返回0.0,否则返回x值。
您可以在此教程中了解有关ReLU激活函数的更多详细信息。
我们可以通过下面的示例来直观地了解此函数的形状。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# rectfied linear activation function 的示例图 from matplotlib import pyplot # 修正线性函数 def rectified(x): return max(0.0, x) # 定义输入数据 inputs = [x for x in range(-10, 10)] # 计算输出 outputs = [rectified(x) for x in inputs] # 绘制输入与输出 pyplot.plot(inputs, outputs) pyplot.show() |
运行示例将计算一系列值的输出,并绘制输入与输出的图。
我们可以看到ReLU激活函数熟悉的折线形状。
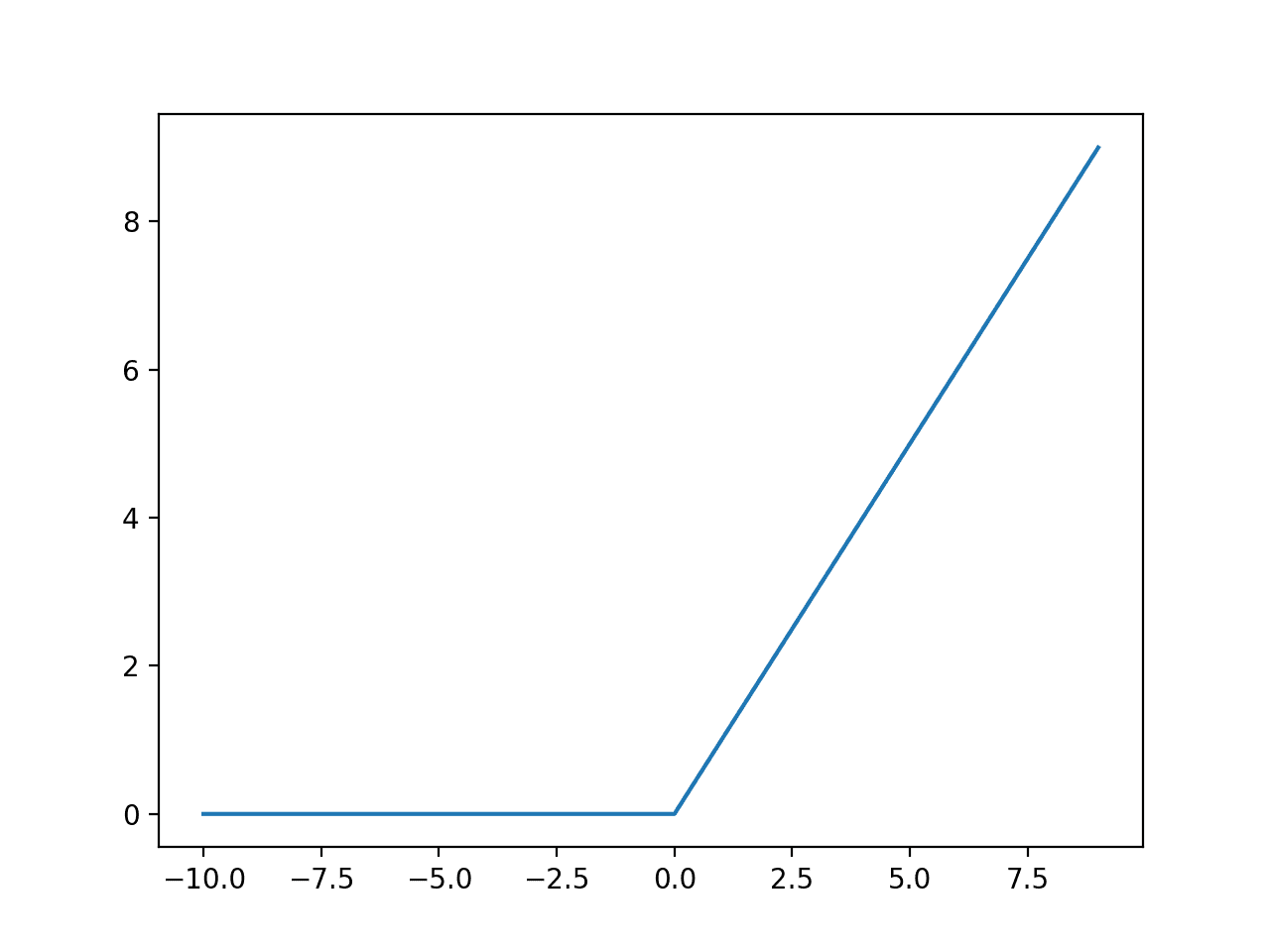
ReLU激活函数的输入与输出图。
在使用ReLU函数作为隐藏层时,建议使用“He Normal”或“He Uniform”权重初始化,并在训练前将输入数据缩放到0-1范围(标准化)。
Sigmoid隐藏层激活函数
Sigmoid激活函数也称为logistic函数。
它与logistic回归分类算法中使用的函数相同。
该函数接受任何实数值作为输入,并输出0到1范围内的值。输入越大(越正),输出值越接近1.0;输入越小(越负),输出值越接近0.0。
Sigmoid激活函数计算如下:
- 1.0 / (1.0 + e^-x)
其中 e是数学常数,即自然对数的底数。
我们可以通过下面的示例来直观地了解此函数的形状。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# sigmoid 激活函数的示例图 from math import exp from matplotlib import pyplot # sigmoid 激活函数 def sigmoid(x): return 1.0 / (1.0 + exp(-x)) # 定义输入数据 inputs = [x for x in range(-10, 10)] # 计算输出 outputs = [sigmoid(x) for x in inputs] # 绘制输入与输出 pyplot.plot(inputs, outputs) pyplot.show() |
运行示例将计算一系列值的输出,并绘制输入与输出的图。
我们可以看到sigmoid激活函数熟悉的S形。
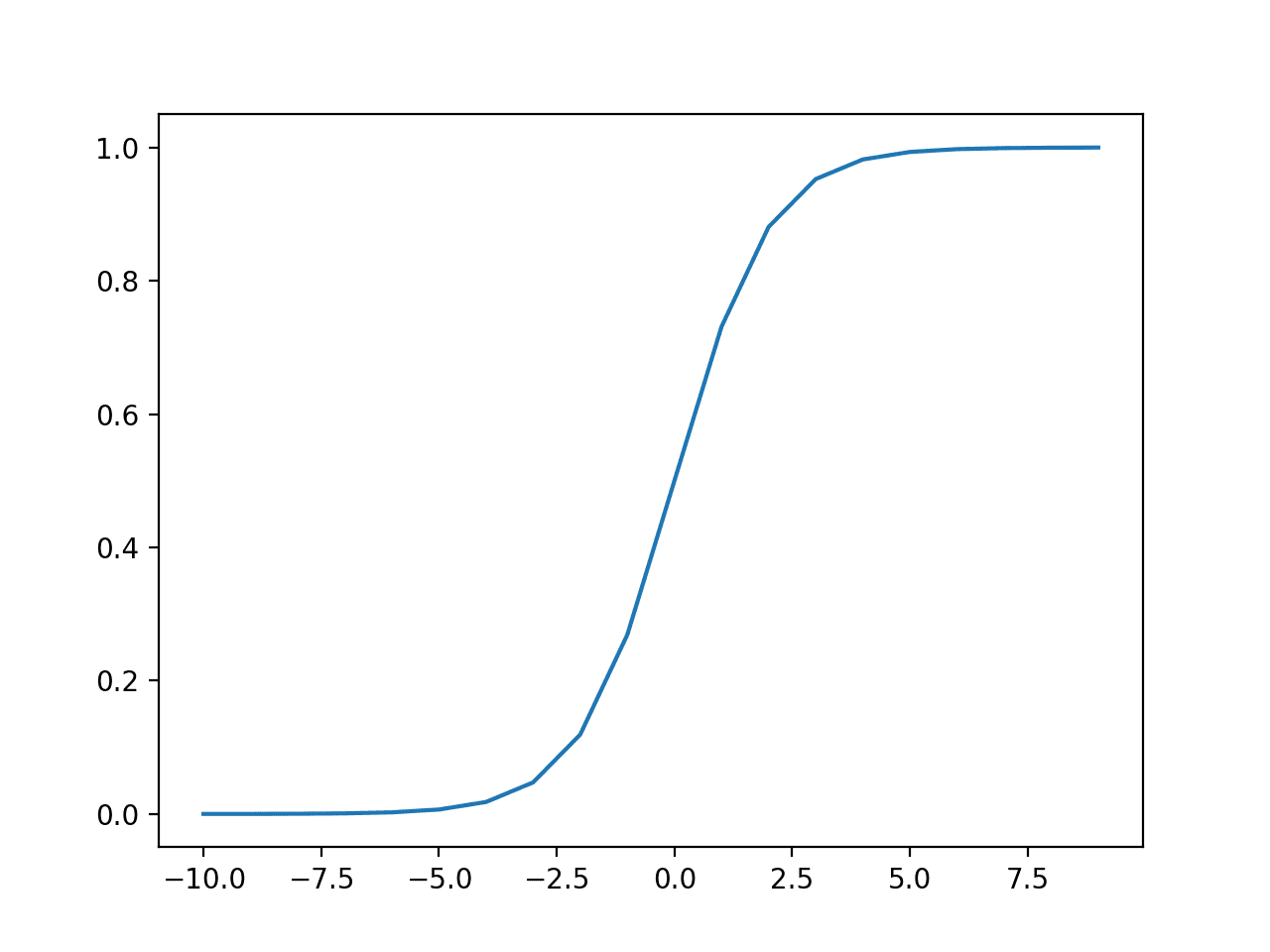
Sigmoid激活函数的输入与输出图。
当使用Sigmoid函数作为隐藏层时,建议使用“Xavier Normal”或“Xavier Uniform”权重初始化(也称为Glorot初始化,以Xavier Glorot命名),并在训练前将输入数据缩放到0-1范围(例如,激活函数的范围)。
Tanh隐藏层激活函数
双曲正切激活函数也简称为Tanh(也称为“tanh”和“TanH”)函数。
它与sigmoid激活函数非常相似,甚至具有相同的S形。
该函数接受任何实数值作为输入,并输出-1到1范围内的值。输入越大(越正),输出值越接近1.0;输入越小(越负),输出值越接近-1.0。
Tanh激活函数计算如下:
- (e^x – e^-x) / (e^x + e^-x)
其中 e是数学常数,即自然对数的底数。
我们可以通过下面的示例来直观地了解此函数的形状。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# tanh 激活函数的示例图 from math import exp from matplotlib import pyplot # tanh 激活函数 def tanh(x): return (exp(x) - exp(-x)) / (exp(x) + exp(-x)) # 定义输入数据 inputs = [x for x in range(-10, 10)] # 计算输出 outputs = [tanh(x) for x in inputs] # 绘制输入与输出 pyplot.plot(inputs, outputs) pyplot.show() |
运行示例将计算一系列值的输出,并绘制输入与输出的图。
我们可以看到Tanh激活函数熟悉的S形。
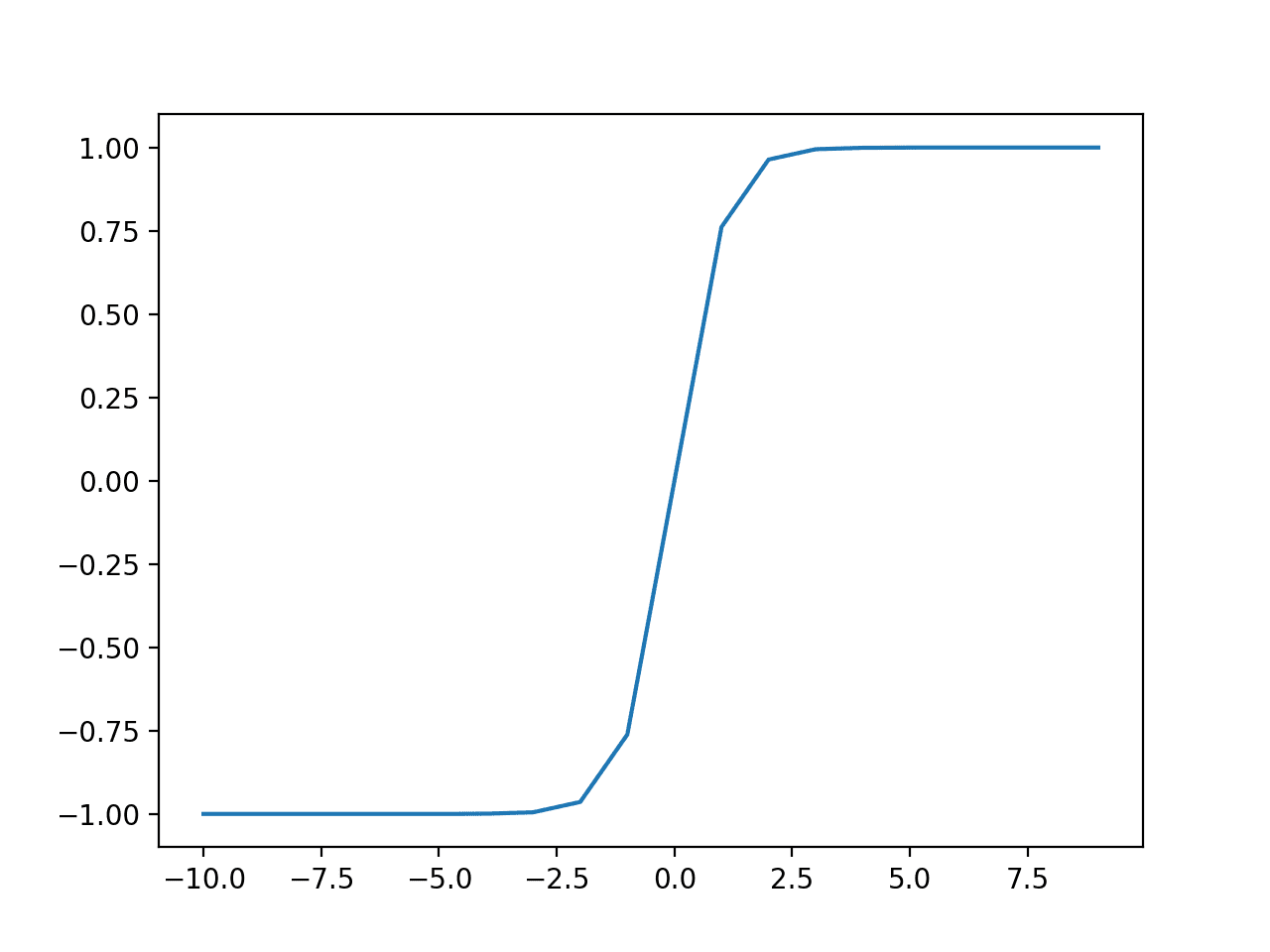
Tanh激活函数的输入与输出图。
当使用TanH函数作为隐藏层时,建议使用“Xavier Normal”或“Xavier Uniform”权重初始化(也称为Glorot初始化,以Xavier Glorot命名),并在训练前将输入数据缩放到-1到1范围(例如,激活函数的范围)。
如何选择隐藏层激活函数
神经网络几乎总是在所有隐藏层中使用相同的激活函数。
在模型中改变激活函数非常罕见。
传统上,sigmoid激活函数是20世纪90年代的默认激活函数。大约在90年代中期到2010年代,Tanh函数是隐藏层的默认激活函数。
……双曲正切激活函数通常比logistic sigmoid表现更好。
—— 第195页,《深度学习》,2016。
Sigmoid和Tanh函数都可能导致模型在训练期间更容易出现问题,即所谓的梯度消失问题。
您可以在此教程中了解此问题的更多信息。
隐藏层使用的激活函数通常根据神经网络架构的类型来选择。
现代神经网络模型,如MLP和CNN,将使用ReLU激活函数或其扩展。
在现代神经网络中,默认建议使用修正线性单元或ReLU……
—— 第174页,《深度学习》,2016。
循环网络仍常用Tanh或sigmoid激活函数,甚至两者都用。例如,LSTM常用的Sigmoid激活用于循环连接,Tanh激活用于输出。
- 多层感知机(MLP):ReLU激活函数。
- 卷积神经网络(CNN):ReLU激活函数。
- 循环神经网络:Tanh和/或Sigmoid激活函数。
如果您不确定为网络选择哪种激活函数,请尝试几种并比较结果。
下图总结了如何为神经网络模型的隐藏层选择激活函数。
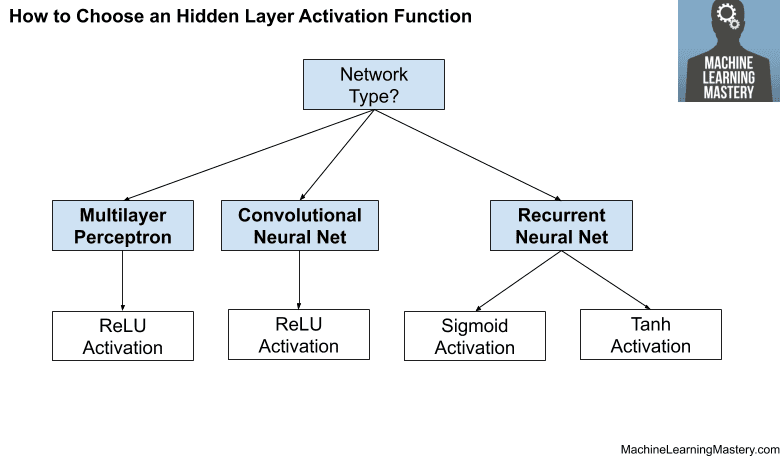
如何选择隐藏层激活函数
输出层的激活
输出层是神经网络模型中直接输出预测的层。
所有前馈神经网络模型都有一个输出层。
您可能需要考虑用于输出层的激活函数有大约三种;它们是:
- 线性
- Logistic(Sigmoid)
- Softmax
这不是输出层激活函数的详尽列表,但它们是最常用的。
让我们依次仔细看看每一个。
线性输出激活函数
线性激活函数也称为“恒等”(乘以1.0)或“无激活”。
这是因为线性激活函数不会以任何方式改变输入的加权和,而是直接返回该值。
我们可以通过下面的示例来直观地了解此函数的形状。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 线性激活函数的示例图 from matplotlib import pyplot # 线性激活函数 def linear(x): 返回 x # 定义输入数据 inputs = [x for x in range(-10, 10)] # 计算输出 outputs = [linear(x) for x in inputs] # 绘制输入与输出 pyplot.plot(inputs, outputs) pyplot.show() |
运行示例将计算一系列值的输出,并绘制输入与输出的图。
我们可以看到一条对角线形状,其中输入与相同的输出绘制在一起。
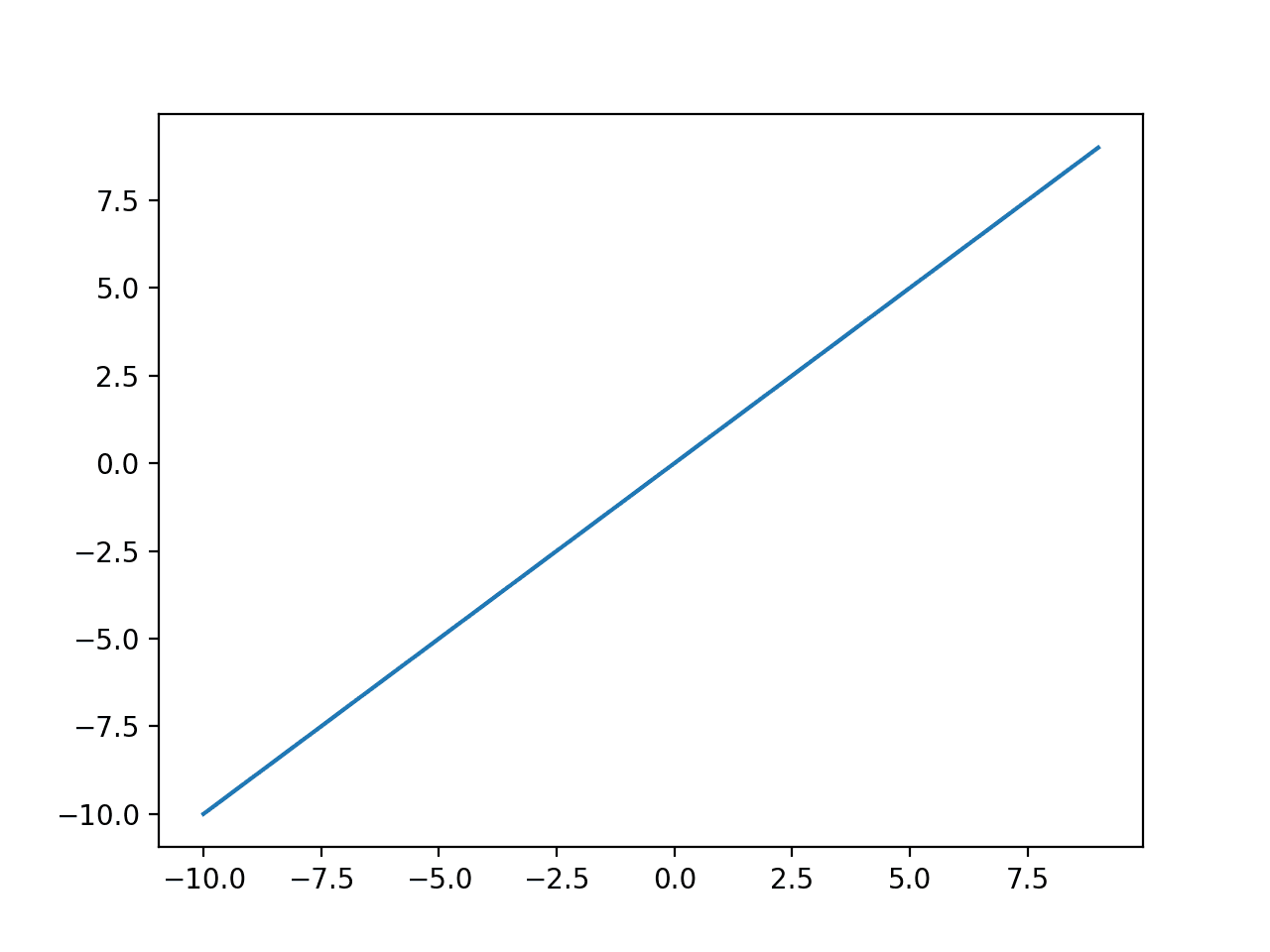
线性激活函数的输入与输出图。
用于使用输出层中的线性激活函数训练模型的目标值通常在建模之前使用标准化或归一化转换进行缩放。
Sigmoid输出激活函数
Sigmoid或logistic激活函数已在上一节中介绍。
尽管如此,为了增加一些对称性,我们可以通过下面的示例回顾此函数的形状。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# sigmoid 激活函数的示例图 from math import exp from matplotlib import pyplot # sigmoid 激活函数 def sigmoid(x): return 1.0 / (1.0 + exp(-x)) # 定义输入数据 inputs = [x for x in range(-10, 10)] # 计算输出 outputs = [sigmoid(x) for x in inputs] # 绘制输入与输出 pyplot.plot(inputs, outputs) pyplot.show() |
运行示例将计算一系列值的输出,并绘制输入与输出的图。
我们可以看到sigmoid激活函数熟悉的S形。
Sigmoid激活函数的输入与输出图。
用于使用输出层中的sigmoid激活函数训练模型的目标标签将具有0或1的值。
Softmax输出激活函数
softmax函数输出一个总和为1.0的值向量,该向量可以解释为类别成员的概率。
它与argmax函数相关,argmax函数为所有选项输出0,为选定选项输出1。Softmax是argmax的“更柔和”版本,它允许类似概率的赢者通吃函数输出。
因此,函数的输入是一个实值向量,输出是相同长度的向量,其值像概率一样总和为1.0。
softmax函数计算如下:
- e^x / sum(e^x)
其中*x*是输出向量,e是数学常数,即自然对数的底数。
您可以在此教程中了解有关Softmax函数更多详细信息。
我们无法绘制softmax函数,但我们可以举例说明如何在Python中计算它。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
from numpy import exp # softmax 激活函数 def softmax(x): return exp(x) / exp(x).sum() # 定义输入数据 inputs = [1.0, 3.0, 2.0] # 计算输出 outputs = softmax(inputs) # 报告概率 print(outputs) # 报告概率总和 print(outputs.sum()) |
运行示例将计算输入向量的softmax输出。
然后我们确认softmax输出的总和确实等于1.0。
|
1 2 |
[0.09003057 0.66524096 0.24472847] 1.0 |
用于使用输出层中的softmax激活函数训练模型的标签将是目标类别为1,所有其他类别为0的向量。
如何选择输出激活函数
您必须根据要解决的预测问题的类型来选择输出层的激活函数。
具体来说,就是要预测的变量的类型。
例如,您可以将预测问题分为两大类:预测分类变量(分类)和预测数值变量(回归)。
如果您的问题是回归问题,则应使用线性激活函数。
- 回归:一个节点,线性激活。
如果您的问题是分类问题,那么有三种主要的分类问题类型,每种可能使用不同的激活函数。
预测概率不是回归问题;它是分类。在所有分类情况下,您的模型将预测类别成员的概率(例如,示例属于每个类别的概率),您可以通过四舍五入(对于sigmoid)或argmax(对于softmax)将其转换为清晰的类别标签。
如果存在两个互斥的类别(二元分类),则输出层将有一个节点,应使用sigmoid激活函数。如果存在两个以上互斥的类别(多类分类),则输出层将有每个类一个节点,并应使用softmax激活。如果存在两个或多个互不包含的类别(多标签分类),则输出层将有每个类别一个节点,并使用sigmoid激活函数。
- 二元分类:一个节点,sigmoid激活。
- 多类分类:每个类别一个节点,softmax激活。
- 多标签分类:每个类别一个节点,sigmoid激活。
下图总结了如何为神经网络模型的输出层选择激活函数。
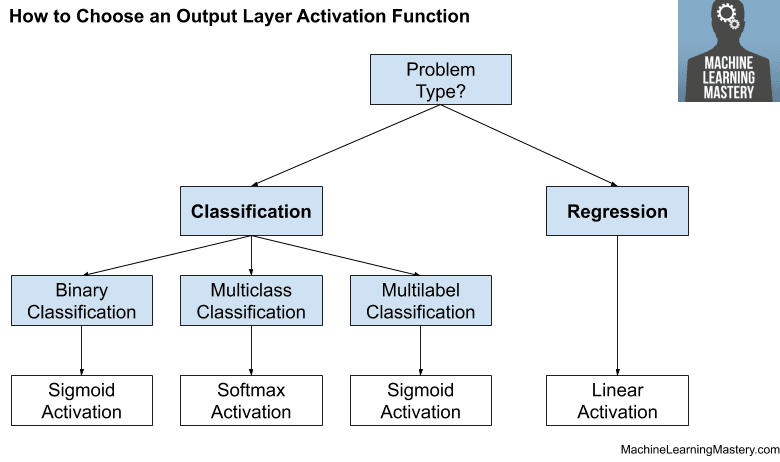
如何选择输出层激活函数
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
书籍
- 深度学习, 2016.
- 《神经网络精工:前馈人工神经网络中的监督学习》, 1999.
- 《用于模式识别的神经网络》, 1996.
- 使用 Python 进行深度学习, 2017.
文章
总结
在本教程中,您了解了如何为神经网络模型选择激活函数。
具体来说,你学到了:
- 激活函数是神经网络设计的重要组成部分。
- 隐藏层的现代默认激活函数是ReLU函数。
- 输出层的激活函数取决于预测问题的类型。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。






您在machinelearningmastery.com上的材料非常棒。
谢谢!
这太棒了!
谢谢!
非常感谢!
不客气!
对于softmax示例,我认为您忘记包含这一行
from numpy import exp
谢谢!已修复。
math.exp显示以下错误:
TypeError: must be real number, not list
已修正,谢谢。
谢谢。很有帮助。
问题:我能构建一个同时包含回归和分类目标的单个神经网络吗?
不客气。
是的,您可以使用多个输出层/模型,为每个输出模型设置一个损失函数,并相应地准备您的训练集。
Keras 函数式 API 会有帮助。
https://machinelearning.org.cn/keras-functional-api-deep-learning/
谢谢 Jason Brown,我想问一下,对于那些想从零开始培养构建神经网络技能的人,您推荐哪些教科书?
好问题,这些书
https://machinelearning.org.cn/books-for-deep-learning-practitioners/
你好,杰森,
我正在使用降水数据集测试一个LSTM grid_search(),模型配置如下:
# 定义模型
model = Sequential()
model.add(LSTM(n_nodes, activation=’relu’, input_shape=(n_input, n_features)))
model.add(Dense(n_nodes, activation=’relu’))
model.add(Dense(1, activation=’sigmoid’))
model.compile(loss=’mse’, optimizer=’adam’)
# 拟合模型
model.fit(train_x, train_y, epochs=n_epochs, batch_size=n_batch, verbose=0)
return model
输出的“model.add(Dense(1, activation=’sigmoid’))”行是否正确?
关于我的例子。LSTM是RNN,不应该在隐藏层激活中使用Tanh或Sigmoid吗?
一如既往的精彩文章!!!
不行。
输出层表明这是一个二元分类任务。
损失函数表明这是一个回归任务。
好的。我删除了输出层,因为结果都一样。
那么,对于lstm模型,我必须使用relu激活函数吗?
输出层的激活函数必须与您正在解决的问题类型相匹配,请参阅上面的教程,了解如何选择激活函数。
好文章,先生。
谢谢!
非常感谢。我深受启发!
不客气。
嵌入层可以作为输入层到模型的归一化或标准化数据的某种方法吗?
不完全是。嵌入用于将分类变量编码为分布式表示。
一旦您有了每个类别的这种数据表示,在传递给后续层之前是否仍然需要进行转换?
不行。
谢谢你,Jason!
不客气。
多项式/非线性回归的输出激活应该是什么?
那么,如果输出是多标签非线性回归呢?
两种情况下的线性激活。
Jason,你对“swish”或“mish”等最新函数有什么看法?
我不太了解它们。我希望能进一步研究它们。ReLU效果非常好。
嗨,Jason,
激活函数的极好总结!
概念划分得相当好
谢谢
谢谢!
你好,先生
非常感谢您把数据科学做得如此简单。
我有一个问题,多标签和多类别之间有什么区别,因为您将其定义为每个类只有一个节点?
不客气!
好问题,这里是每种分类类型的定义
https://machinelearning.org.cn/types-of-classification-in-machine-learning/
对于总和为1的比率回归,或者需要总和为1的多个比率,该怎么办?
sigmoid 用于 0-1,softmax 用于输出总和为 1 的多个输出。
这在上面的教程中已经涵盖了,也许可以重读一下?
谢谢!
不客气。
谢谢!如果您不介意,我可以在我的博客文章中使用您的图表图片“如何选择……”。我也会写上来源链接。
可以,只要您链接到这篇博文并清楚注明来源。
谢谢! 🙂
嗨,Jason,
我正在尝试通过子类化来更改 keras 的 SimpleRNN 层中的激活方程。
所以,
1. 我按以下方式覆盖了 SimpleRNNCell 类中的 call 方法
class NotSoSimpleRNNCell(SimpleRNNCell)
def call(self, inputs, states, **kawrgs)
output, new_state = super(NotSoSimpleRNNCell, self).call(inputs, states, **kwargs)
output = output – self.activation(self.bias)
new_state = [output] if nest.is_nested(states) else output
return output, new_state
2. 然后,我按以下方式覆盖了 SimpleRNN 类中的 init 方法
class NotSoSimpleRNN(SimpleRNN)
def __init__(self,
units,
activation=’tanh’,
use_bias=True,
kernel_initializer=’glorot_uniform’,
recurrent_initializer=’orthogonal’,
bias_initializer=’zeros’,
kernel_regularizer=None,
recurrent_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
recurrent_constraint=None,
bias_constraint=None,
dropout=0.,
recurrent_dropout=0.,
return_sequences=False,
return_state=False,
go_backwards=False,
stateful=False,
unroll=False,
**kwargs)
if ‘implementation’ in kwargs
kwargs.pop(‘implementation’)
logging.warning(‘The
implementationargument ‘‘in
SimpleRNNhas been deprecated. ‘‘Please remove it from your layer call.’)
if ‘enable_caching_device’ in kwargs
cell_kwargs = {‘enable_caching_device’
kwargs.pop(‘enable_caching_device’)}
else
cell_kwargs = {}
cell = NotSoSimpleRNNCell(
units,
activation=activation,
use_bias=use_bias,
kernel_initializer=kernel_initializer,
recurrent_initializer=recurrent_initializer,
bias_initializer=bias_initializer,
kernel_regularizer=kernel_regularizer,
recurrent_regularizer=recurrent_regularizer,
bias_regularizer=bias_regularizer,
kernel_constraint=kernel_constraint,
recurrent_constraint=recurrent_constraint,
bias_constraint=bias_constraint,
dropout=dropout,
recurrent_dropout=recurrent_dropout,
dtype=kwargs.get(‘dtype’),
trainable=kwargs.get(‘trainable’, True),
**cell_kwargs)
super(NotSoSimpleRNN, self).__init__(
cell,
return_sequences=return_sequences,
return_state=return_state,
go_backwards=go_backwards,
stateful=stateful,
unroll=unroll,
**kwargs)
3. 然后,我像这样创建了一个 NotSoSimpleRNN 对象
U= Input(shape=(T,1), batch_size=1)
H1= NotSoSimpleRNN(3, activation=’tanh’, return_sequences=True, stateful=True)(U)
但我得到了这个错误:
/usr/local/lib/python3.7/dist-packages/tensorflow/python/keras/layers/recurrent.py in __call__(self, inputs, initial_state, constants, **kwargs)
654 inputs, initial_state, constants = _standardize_args(inputs,
655 initial_state,
–> 656 constants,
657 self._num_constants)
658
TypeError: _standardize_args() missing 1 required positional argument: ‘num_constants’
这是基本 RNN 类的一部分。
————————
问:这是达到我目标 的正确方法吗?为什么在调用基类 RNN 的 call 方法时没有初始化这个参数?
提前感谢您的时间。
也许可以试试在 stackoverflow.com 上发布你的代码和错误信息。
我可以用 softmax 激活函数来分类二元问题吗?
可以,但不常见。你应该使用 sigmoid。
解释得太棒了!非常感谢。
不客气。
精彩的文章。我喜欢将摘要作为图表的想法。
干得好。
谢谢!
你好!阅读得真好!我有一个关于回归部分的问题。你提到“回归,一个单元,线性激活函数”。我不能有多个回归输出单元吗?我以为那是可能的……
是的,你当然可以,这里有一个例子
https://machinelearning.org.cn/deep-learning-models-for-multi-output-regression/
啊哈,太好了!谢谢。还有最后一件事:如果我,只是为了好玩,选择在隐藏层中使用线性激活函数,如果我理解正确的话,那就是根本没有激活函数?
在反向传播中我该如何处理?假设我有一个具有 sigmoid 函数的另一个神经网络。我在前向传播时将 g(z)=sigmoid(z) 送入下一层。在反向传播中,我取 g(z) 的导数,即 g'(z)。对于隐藏层的线性激活函数,那会是向前发送 z,向后发送 z’ 吗?
再次感谢!
正确。
反向传播会很好地处理这种情况,不需要求导函数,只有原始误差。
你好,感谢这篇非常好的文章。我有一个长久以来的疑问,并决定寻求帮助。为什么我们要将数据缩放到激活输出的范围内?例如,你说要标准化 tanh,因为输出范围是 -1 到 1。我也有一个关于 relu 的问题……标准化(min max)数据,部分原因我理解,因为所有负输入都会变成零。但所有正输入都会产生相同的结果,所以 relu 就变成了一个线性函数,对吗?如果你能分享一些参考文献那就太好了。谢谢!
你可以使用 sklearn 的 minmaxscaler 对象,或者手动编写代码来缩放。
这篇文章太棒了,我是神经网络的新手,这对初学者来说是一个非常清晰的教程!
我想知道,如果我的最终输出应该在正实数范围内,那么我似乎应该使用 ReLU 激活函数。但你在本教程中建议不要在输出层使用 ReLU。你是否认为这种情况可能是一个例外,应该尝试 ReLU?如果不是,你会推荐什么激活函数?
感谢您的帮助!
在你的特定情况下,这可能会起作用。确实取决于问题,有时我们可以在最后一层使用线性激活(即无激活)。
感谢您的确认 adrian!
非常有帮助。
如果您为每个部分添加一些图形表示,那将帮助我们更容易地理解。
维基百科的表格里都有: https://en.wikipedia.org/wiki/Activation_function
我喜欢这个 machinelearningastery.cm 网站
如果您添加更多具体的课程和示例,那将是最好的。
感谢您的反馈 Alemu!
我正在学习机器学习,这个网站对我来说很棒。
我印象深刻的是,模型背后的总体思想以及如何在实践中使用它们都得到了如此清晰的解释。
非常感谢!
感谢 Guillaume 的精彩反馈!
你太棒了,先生。每当我遇到任何疑问时,我都会先访问 machinelearningmastery.com 来查找文章。
感谢 Sachin 的反馈和支持!
非常有帮助,非常感谢。
感谢 Jannadi 的反馈和支持!我们非常感谢!
我正在进行关于人工智能和版权法的博士研究,我经常使用您的网站,并且学到了很多!它是我的首选网站之一,用于检查任何与人工智能相关的内容。
我可以问一个非常简单的问题吗?我猜激活函数也在训练好的模型中使用,而不仅仅是在训练阶段?
你好 Ben……你的理解是正确的。以下资源也可能有益
https://machinelearning.org.cn/using-activation-functions-in-neural-networks/
谢谢!
Benjamin,不客气!