当您构建分类问题的模型时,您几乎总是希望查看该模型的准确性,即所有预测中的正确预测数量。
这就是分类准确率。
在之前的帖子中,我们研究了如何使用交叉验证和多次交叉验证来评估模型的健壮性,以预测未见过的数据,在此过程中我们使用了分类准确率和平均分类准确率。
一旦您有了一个您认为能够进行稳健预测的模型,您就需要决定它是否是足够好的模型来解决您的问题。分类准确率本身通常不足以做出此决定。

分类准确率
摄影:Nina Matthews Photography,部分权利保留
在本帖中,我们将探讨您可以在二元分类问题中用于评估模型的精确率和召回率性能指标。
乳腺癌复发
乳腺癌数据集是一个标准的机器学习数据集。它包含9个属性,描述了286名患有乳腺癌并康复的女性,以及乳腺癌在5年内是否复发。
这是一个二元分类问题。在这286名女性中,201名未发生乳腺癌复发,其余85名发生了复发。
我认为对于这个问题,假阴性(False Negatives)可能比假阳性(False Positives)更糟糕。你同意吗?更详细的筛查可以清除假阳性,但假阴性却被送回家,得不到后续评估。
分类准确率
分类准确率是我们起点。它是正确预测次数除以总预测次数,再乘以100得到百分比。
全部未复发
一个只预测未发生乳腺癌复发的模型,准确率将是(201/286)*100或70.28%。我们称之为“全部未复发”模型。这是一个高准确率,但却是一个糟糕的模型。如果它单独用于决策支持来告知医生(不可能,但请配合),它会错误地认为85名女性的乳腺癌不会复发(假阴性很高),并将她们送回家。
全部复发
一个只预测乳腺癌复发的模型,准确率将是(85/286)*100或29.72%。我们称之为“全部复发”模型。这个模型准确率很差,并且会错误地认为201名女性患有乳腺癌复发,但实际上没有(假阳性很高),并将她们送回家。
CART
CART 或 分类与回归树(Classification And Regression Trees)是一种强大而简单的决策树算法。在此问题上,CART 可以达到69.23%的准确率。这低于我们的“全部未复发”模型,但这个模型更有价值吗?
我们可以看到,仅凭分类准确率不足以选择该问题模型。
混淆矩阵
呈现分类器预测结果的清晰、无歧义的方法是使用混淆矩阵(confusion matrix)(也称为列联表(contingency table))。
对于二元分类问题,该表有2行2列。顶部是观测到的类别标签,侧面是预测的类别标签。每个单元格包含分类器在该单元格中进行的预测数量。

真值表混淆矩阵
在这种情况下,一个完美的分类器将正确预测201个未复发和85个复发,这将被输入到左上角的未复发/未复发(真阴性)和右下角的复发/复发(真阳性)单元格中。
错误预测会清楚地分为另外两个单元格。假阴性是分类器标记为未复发的复发。我们没有这样的病例。假阳性是分类器标记为复发的未复发。
这是一个有用的表格,它展示了数据中的类别分布以及分类器的预测类别分布,并对错误类型进行了细分。
全部未复发混淆矩阵
混淆矩阵突出了大量(85个)假阴性。
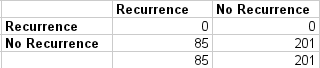
全部未复发混淆矩阵
全部复发混淆矩阵
混淆矩阵突出了大量(201个)假阳性。

全部复发混淆矩阵
CART 混淆矩阵
这看起来是一个更有价值的分类器,因为它正确预测了10个复发事件和188个未复发事件。该模型还显示适量的假阴性(75个)和假阳性(13个)。

CART 混淆矩阵
准确率悖论
正如我们在这个例子中看到的,准确率可能会产生误导。有时选择一个准确率较低但对问题具有更高预测能力的模型是可取的。
例如,在类别不平衡较大的问题中,模型可以预测所有预测的大多数类别值,并获得很高的分类准确率,但问题是这个模型在问题领域中没有用。正如我们在乳腺癌示例中所看到的。
这就是所谓的准确率悖论(Accuracy Paradox)。对于此类问题,需要额外的度量来评估分类器。
精确率
精确率(Precision)是真阳性数量除以(真阳性数量和假阳性数量)的总和。换句话说,它是正预测数量除以预测为正类的总数量。它也称为阳性预测值(Positive Predictive Value, PPV)。
精确率可以被认为是衡量分类器精确度的一个指标。低精确率也可能表示存在大量的假阳性。
- “全部未复发”模型的精确率为 0/(0+0) 或 NaN,即 0。
- “全部复发”模型的精确率为 85/(85+201) 或 0.30。
- CART 模型的精确率为 10/(10+13) 或 0.43。
精确率表明 CART 是一个更好的模型,并且“全部复发”模型比“全部未复发”模型更有用,尽管它的准确率较低。“全部复发”模型和 CART 模型之间的精确率差异可以用“全部复发”模型预测的大量假阳性来解释。
回顾
召回率(Recall)是真阳性数量除以(真阳性数量和假阴性数量)的总和。换句话说,它是正预测数量除以测试数据中正类值的总数量。它也称为敏感性(Sensitivity)或真阳性率(True Positive Rate)。
召回率可以被认为是衡量分类器完整性的一种方法。低召回率表明存在许多假阴性。
- “全部未复发”模型的召回率为 0/(0+85) 或 0。
- “全部复发”模型的召回率为 85/(85+0) 或 1。
- CART 的召回率为 10/(10+75) 或 0.12。
正如你所料,“全部复发”模型具有完美的召回率,因为它为所有实例都预测了“复发”。CART 的召回率低于“全部复发”模型。这可以用 CART 模型预测的大量假阴性(75个)来解释。
F1 分数
F1 分数是 2*((精确率*召回率)/(精确率+召回率))。它也称为 F 分数或 F 度量。换句话说,F1 分数传达了精确率和召回率之间的平衡。
- “全部未复发”模型的 F1 分数为 2*((0*0)/0+0) 或 0。
- “全部复发”模型的 F1 分数为 2*((0.3*1)/0.3+1) 或 0.46。
- CART 模型的 F1 分数为 2*((0.43*0.12)/0.43+0.12) 或 0.19。
如果我们要根据精确率和召回率之间的平衡来选择模型,F1 度量表明“全部复发”模型是最好的,而 CART 模型尚未达到足够的竞争力。
总结
在本帖中,您了解了准确率悖论以及类别不平衡问题,在这些问题中,仅凭分类准确率不足以选择性能良好的模型。
通过示例,您了解了混淆矩阵作为描述未见数据集预测错误细分的有用方法。您还了解了总结模型精确度(准确性)和召回率(完整性)的度量,以及 F1 分数中对两者之间平衡的描述。

")
")



嗨,Jason,
在“混淆矩阵”部分的第一个段落中有一个拼写错误,您写的是“呈现分类器预测结果的清晰、无歧义的方式是使用使用一个混淆矩阵(也称为列联表)。”。
您看到了两个“使用一个”。🙂
谢谢你。
您也因为重复“使用一个”而犯了拼写错误。
谢谢,已修正。
在你最后一点上,
如果我们要根据精确率和召回率之间的平衡来选择模型,F1 度量表明“全部复发”模型是最好的,而 CART 模型尚未达到足够的竞争力。
那么我们在这里为什么选择“全部复发”模型,因为它提供了更好的精确率和召回率平衡?或者我们是否应该尝试选择一个比 CART 模型表现更好的模型?
F1 度量不适合结合精确率和召回率,如果存在类别不平衡,就像这里一样。更合适的方法是使用 Matthews 相关系数(Matthews Correlation Coefficient)。根据我的计算,结果是
全部未复发 = 0
全部复发 = 0
CART = 0.089
这意味着“全部未复发”和“全部复发”模型与随机猜测没有区别,“全部未复发”模型只比随机猜测好一点点。不幸的是,本文没有提出任何有用的模型,但使用 MCC 可以发现这一点。以下是解释 MCC 的方法
http://stats.stackexchange.com/questions/118219/how-to-interpret-matthews-correlation-coefficient-mcc
嗨 Asim,
先生——在上面,我们希望给假阴性比假阳性更大的权重。然而,F1 分数对两者给予了相同的权重(简单调和平均数)。我们如何调整权重?
或者我们应该选择你上面提到的 Matthews 相关系数
谢谢
Panchajanya
我们知道在模型选择时,0 是 F1 分数最差的值,1 是最好的值。F1 分数是否有任何标准值(例如 p 值),高于该值我们就接受模型,低于该值我们就拒绝模型?
计算癌症数据决策树准确率的 R 代码是什么?
嗨,Jason,
[报告文章错误]
如果我们查看 F1 分数计算的示例,我们可以看到分母中缺少括号。仅供报告,您可能希望根据您之前陈述的正确公式更新它!🙂
https://en.wikipedia.org/wiki/F1_score
祝好,
Hichame
我发现 R 中的 caret 包提供的精确率和召回率值与它们在 https://en.wikipedia.org/wiki/Precision_and_recall 上的实际定义不同。您能告诉我为什么吗?事实上,我找到了一个在线混淆矩阵,其中显示了两个结果。http://www.marcovanetti.com/pages/cfmatrix/ 我不明白我应该使用哪个。
对于多类别不平衡数据集的分类任务,可以使用平衡准确率(Balanced Accuracy)作为比准确率更好的指标。您是否尝试过对此进行回顾以确认是否正确?如果是,您能否在博客上发布您的实现?
知道 F1/F 分数是通过精确率和召回率来衡量模型准确性的指标,其公式为:
F1_Score = 2 * ((Precision * Recall) / (Precision + Recall))
精确率通常称为阳性预测值。值得注意的是,PPV 也可以使用贝叶斯定理推导出来。
Precision = True Positives / (True Positives + False Positives)
召回率也称为真阳性率,定义如下:
Recall = True Positives / (True Positives + False Negatives)
感谢分享。
AUC 更好吗?
AUC 也是一个非常有用的指标。
对一个非常常见的分析场景的绝佳解释!
谢谢 Ankur。
如果您能看看 F-beta(特别是 F2)度量在您的情况下的表现,尤其是当我们试图最小化假阴性时……以及它与 AUC 的比较,那将很有帮助。
很好的建议,谢谢。
你好,我是一名 ML 初学者。最近,我正在做一个特征选择的项目。我已经完成了大部分工作。并且在 MATLAB 工具箱的帮助下编写代码是可以的。现在我了解到我们可以使用 MATLAB 的 classregtree 类构建决策树。并且我们可以使用 test 方法来获得误分类成本(Cost of Misclassification)。但接下来我应该怎么做才能获得分类准确率?有什么方法可以获得分类准确率吗?或者我们可以通过误分类成本来计算它?非常感谢您提供的任何帮助。
您可以在未见数据(未用于拟合模型的数据)上进行预测。这将为您提供模型在预测新数据时的技能估计。
非常感谢
本文应介绍平衡准确率 = (召回率 + 特异度)/2,该指标可以解决数据集不平衡问题。使用上述3个模型:
“全部未复发”模型的平衡准确率为 ((0/85)+(201/201))/2 或 0.5。
“全部复发”模型的平衡准确率为 ((85/85)+(0/201))/2 或 0.5。
CART 模型的精确率为 ((10/85)+(188/201))/2 或 0.53
如果不对假阳性或假阴性率进行偏好,那么 CART 是最佳选择。
感谢 Kaleb 的分享。
您好,我是一名 ML 的初学者,尤其是在衡量其性能方面。我最近尝试衡量深度学习架构在执行分类任务时的性能。使用的该任务的数据集高度不平衡。按比例,第一个类只占整个数据的 33%。我尝试使用 Accuracy、F1 和 Area Under ROC Curve。我还为交叉验证算法使用了 StratifiedKFold。但是,F1 值比准确率高 3-5%。Area Under ROC Curve 值仍然低于准确率。我和我的研究导师从未见过这样的情况。但是,我个人认为这是可能的。我的一个假设是,这是因为不平衡的数据集在准确率计算中产生了较小的真阴性值。这有可能吗?有什么解释吗?
如果 F 度量值低于准确率,而数据是不平衡的(分为2个类别,第一个类别占33%,第二个类别占67%),这是可能的吗?我认为这是因为真阴性值较低,对吗?
你好,
我认为在您的电子书《使用 R 进行机器学习精通》中包含这些信息会很好
我担心关于这个主题还有很多遗漏,
谢谢,
谢谢 Eduardo 的建议。
我很想看到多类别问题也有同样的解释。二元类别的混淆矩阵已经过时了。
感谢您的建议。
在训练分类器(例如基于 DNN 的分类器)时,如果具有连续输出 p,是否可以专门优化例如高召回率?我不是指仅仅在某个点上对 p 进行截断以获得高召回率,而是例如设定一个高召回率目标,例如 95%,并在此召回率目标下最小化可获得的假阳性率。
实值输出使您的预测问题成为回归问题,而不是分类问题。
回归问题无法测量召回率和精确率。
您提供的混淆矩阵将预测作为行,将观测类别作为列。这不是反过来了吗?
与什么相比,Richard?
当我们检查分类器的性能时,我们是否关心真阴性?另外,如何将这些度量应用于多类别问题?对我来说,感觉阳性和阴性是两个类别。但如果我们将其扩展到例如3个类别的问题。我们是否需要将精确率和召回率的概念扩展到所有三个类别才能找到最佳分类器?
这实际上取决于您的具体问题以及您最关心的预测领域。
Jason,好文章!
我不知道准确率和 F1 分数之间的区别。在这里,它清晰地展示了准确率的悖论,明确了模型验证的重要性。
我很高兴这篇文章能帮到你。
您好,Jason Brownlee
解释得很棒!!
请您能否指导我如何计算多类别响应变量的模型分类和预测能力?请帮助我提供有关此主题的相关信息。
谢谢你
也许可以从混淆矩阵开始,以帮助理解模型输出。
https://machinelearning.org.cn/confusion-matrix-machine-learning/
Jason,感谢这篇文章。我可以问您是否能就我在这个问题中提出的关于 MCC 的问题发表评论吗?
https://stats.stackexchange.com/questions/299333/question-about-imbalanced-training-and-test-sets
另外,您对使用 G-mean 作为不平衡数据集的性能指标有何看法?
感谢您提供的所有帮助!
在这种情况下,什么才是决定我们模型预测良好的良好精确度和召回率值?
谢谢。
很好的问题。
您希望结果相对于基线模型(例如零规则算法)更好。
“混淆矩阵”在检测时间序列数据中的错误值方面有用吗?如果有用,如何将神经网络的输出归类为真阳性、真阴性等。
例如,当我将值“x”输入神经网络时,它会显示“y”,但在我的测试数据中,该值为“z”(假设“z”是错误值,“y”是正确值)。我是否应该将其视为真阳性(假设错误值由“阳性”表示)。
不,它适用于分类问题,而时间序列通常是回归问题。
谢谢 Jason,
很棒的文章。
是否可以根据7种不同的性能指标(召回率、特异度、平衡准确率、精确率、F分数、MCC和AUC)来比较不同的二元分类模型(使用不平衡数据集),以及我们如何决定哪个模型是最好的?
谢谢
是的。模型选择将取决于您的项目目标。
嗨,Jason,
我有一个关于决策的问题。
当不同度量之间存在冲突时,我们如何解释以下结果,我们能做出什么决定?
例如,在平衡准确率方面,Kernel-SVM是最佳模型,为98.09%,其次是RBF-NN(97.74%)和CART DT(95.26%)。在F分数、MCC和AUC度量方面,RBF-NN模型取得了最高的结果(分别为99.21%、92.82和0.98),其次是CART DT(分别为98.43%、85.34%和0.91),以及Kernel-SVM模型(分别为98.05%、81.32%和0.97)。
谢谢
这归结于最能反映您目标并且在该度量上最熟练的度量。
谢谢 Jason,
是否可以根据不同性能指标的总体平均值来比较不同的分类模型?
当然,您可以根据您的具体要求以任何您希望的方式比较算法。
Jason,谢谢。
我看到了一系列有用的评估指标。以分类为例,我们看到准确率、F度量、ROC曲线下面积等。
一个愚蠢的问题:是否有结合了其中许多(全部?)指标并给我们一个通用分数的实用分数指标?可能没有,为什么呢?
例如,F度量结合了精确率和召回率。
附注。当我回答我的问题或评论时,我如何收到电子邮件通知。
模型技能实际上是权衡取舍。您必须找到适合您特定问题的权衡(例如,与利益相关者交谈)。
抱歉,我还没有通知,希望将来会添加。感谢您的提示!
你好,Jason先生。我做了一个多类分类,并找到了它的混淆矩阵。然后我计算了每个类的精确率和灵敏度,现在我想计算F分数。那么我该怎么做呢?我应该为每个类计算F分数然后取平均吗?还是计算平均精确率和灵敏度然后计算F分数?或者其他方法?
本文可能有助于您手动计算 F 分数
https://en.wikipedia.org/wiki/F1_score
感谢这篇文章!我刚开始接触机器学习时犯的一个最大也是最早的错误就是认为准确率说明了一切。事实上,我发现 AUC、F1 以及精确率和召回率等更复杂的指标比准确率更常用。特别是 Kaggle 在分类竞赛中倾向于偏爱 AUC 而非准确率或 F1。
是的,还有日志损失。
嗨 Jason!感谢您的这些信息。您的书里有这些内容吗?
我的一些书中确实涵盖了这些指标,但细节不多。
您具体需要什么帮助?
打字错误:CART F分数计算中的召回率指标缺少小数点,即读作12而不是0.12
“CART模型的F1为2*((0.43*12)/0.43+12)或0.19。”
很棒的博客 Jason!
谢谢,已修复!
我正在对图像进行二元分类,并对 imagenet 数据集预训练的 resnet50 进行微调,对所有层进行微调,但我只能达到 91% 的验证准确率。如何达到更高的准确率?
我在这里有一些通用想法
https://machinelearning.org.cn/improve-deep-learning-performance/
这是我使用的全部代码。
import os
import glob
import numpy as np
import json
import pickle
import cv2
import ntpath
import random
import pdb
import datetime
from sklearn.preprocessing import LabelEncoder
import numpy as np
import h5py
import datetime
import time
# keras imports
#from keras.applications.mobilenet import MobileNet, preprocess_input
from keras.applications.resnet50 import ResNet50, preprocess_input
from keras.preprocessing import image
from keras.models import Model , load_model
from keras.models import model_from_json
from keras.layers import Input , Dense , Dropout , GlobalAveragePooling2D
from tensorflow.python.keras._impl.keras.layers import Conv2D , Reshape
from keras.preprocessing.image import ImageDataGenerator
from keras.optimizers import SGD,Adam
from keras import models
from keras import layers
from keras.callbacks import ReduceLROnPlateau , ModelCheckpoint , Callback
from keras import regularizers
#print (“[STATUS] start time – {}”.format(datetime.datetime.now().strftime(“%Y-%m-%d %H:%M”)))
#start = time.time()
image_size = 224
#prepare the data
train_datagen = ImageDataGenerator(
rescale=1./255,
vertical_flip=True,
horizontal_flip=True,
rotation_range=20)
validation_datagen = ImageDataGenerator(rescale=1./255)
# Change the batchsize according to your system RAM
train_batchsize = 16
val_batchsize = 16
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(224, 224),
batch_size=train_batchsize,
class_mode='categorical')
validation_generator = validation_datagen.flow_from_directory(
validation_dir,
target_size=(224, 224),
batch_size=val_batchsize,
class_mode=’categorical’,
shuffle=False)
#Model
resnet50 = ResNet50()
resnet50.layers.pop()
#x = mobilenet.layers[-6].output
#x = Dense(512 , activation = “relu”)(x)
#x = Dropout(0.2)(x)
#predictions = Dense(2 , activation = “softmax”)(x)
#model = Model(inputs = mobilenet.inputs , outputs = predictions)
#print(model.summary())
x = resnet50.layers[-1].output
x = Dropout(0.5)(x)
predictions = Dense(2 , activation = “softmax”)(x)
model = Model(inputs = resnet50.inputs , outputs = predictions)
for layer in resnet50.layers
layer.trainable = True
filepath=”weights-improvement-{epoch:02d}-{val_acc:.2f}.hdf5″
#Compile the model
model.compile(optimizer=Adam(lr=0.000001), loss=’categorical_crossentropy’, metrics=[‘accuracy’])
#Callbacks
checkpointer = ModelCheckpoint(filepath, monitor=’val_loss’ , verbose=1, save_best_only=True , mode = ‘min’)
history = model.fit_generator(
train_generator,
steps_per_epoch=train_generator.samples/train_generator.batch_size ,
epochs=200,
validation_data=validation_generator,
validation_steps=validation_generator.samples/validation_generator.batch_size,
verbose=1,
callbacks=[checkpointer]
)
您能根据这些分享一些想法吗?
我很乐意提供帮助,但我没有能力调试您的代码。
抱歉。我没有让您调试。我只是想让您看看参数和增强技术,并提出一些想法。
我的训练数据有 6000 张图像,验证数据有 1600 张图像。
亲爱的 Jason,
这是一篇非常有信息量的文章,但我有一个疑问:如果精确率和召回率的值相同(即相同),这说明了什么?感谢您的宝贵时间。
我不确定您在说什么?
亲爱的 Jason,
以下是精确率和召回率值相同的示例。
精确率 召回率
0.82 0.85
0.85 0.81
平均值 0.83 0.83
我想知道精确率和召回率值为何会相同。
为什么?
亲爱的 Jason,感谢您清晰的帖子。我是机器学习的新手,我对此主题有一个问题。对于分类,我将数据集分为训练集和测试集。我想知道迭代分类预测(及相关的混淆矩阵)多次以评估模型的稳健性是否恰当,即查看当用于在训练数据上构建模型的参数发生变化时会发生什么。我希望我已经表达清楚了,感谢您的帮助。
是的,拟合和评估给定配置多次并计算平均性能是一个好主意。
这是为了抵消算法的随机性。我在这里解释得更详细
https://machinelearning.org.cn/evaluate-skill-deep-learning-models/
对您而言,模型准确率还是模型性能更重要?
准确率是一种性能度量。
也许我没明白您的问题?您是指性能如计算复杂度吗?
我认为所有复发准确率应该是(85/286),而不是(75/286)
谢谢,已修正。
感谢您的这篇博文,这是一个有用的示例,可以让我更容易地将这些东西传达给老板。
问题
为什么“无复发”的预测不应计入“无复发”结果的“真阳性”?这仅仅是因为这是一个二元示例吗?以及二元问题与分类两个相互排斥的类别(例如苹果和香蕉)有什么区别……?
也许这会让事情更清楚,Tyler
https://en.wikipedia.org/wiki/Precision_and_recall
我认为即使是像 (TPR + TNR)/2 这样简单的指标也对评估准确率很有用。是什么让 F1 更好?
没有“更好”,只有不同的尝试方法,一种可能适合您的问题。
很棒的文章!我在统计疾病诊断模型时经常参考 F1 分数。除了平衡精确率和召回率外,它还对应于最低的假阳性率(FDR),这是我们在现实世界中需要注意的。AUROC 和 F1 类似地描述了性能,但有时高 AUROC 也可能伴随高 FDR(F1 通常不会)。但正如您所说,没有更好的,这取决于具体问题以及哪种类型的错误更容易接受。一切都是为了权衡:)
当然。您需要了解在您的项目上衡量模型性能方面什么最重要,并像激光一样专注于此。
您好,谁能帮我解释一下“CART 混淆矩阵”的值是如何计算/显示的,请帮帮我,我已经尽力了但还是不明白。请详细解释。
这篇文章会有帮助:
https://machinelearning.org.cn/confusion-matrix-machine-learning/
先生,我仍然不清楚 CART 混淆矩阵中的“复发 10”和“无复发 188”是如何计算的。
先生,链接中有一个男人和女人的例子,但这里只有一个女人的例子。
我认为这个例子是人为设计的。
嗨,Jason,
我有一个疑问。假设我们有 1 个数据集,用它构建了 2 个模型,还有 2 个性能指标,并且每个模型在不同的指标上都给出更好的值,那么我们如何决定为这两个模型以及要在同一数据集上测试的更多模型选择哪个指标?
也许选择最能捕捉模型对您和项目利益相关者重要性的指标?
混淆矩阵的列和行分别是“实际”和“预测”吗?一些标记会使信息更清晰。
谢谢。
分类准确率是我们的起点。它是正确预测的数量除以预测的总数。
“正确预测”不应该有两个参数吗?
预测某人患有癌症/复发的准确率。
预测某人没有癌症/没有复发的准确率。
正确预测仅仅意味着模型预测了实际发生的情况,例如,癌症/无癌症。
然后,您可以根据类别结果进一步细分预测类型,例如,真阳性、假阳性等。
我的意思是,对于(1)所有复发模型(2)所有无复发模型(3)CART模型,应该有两种准确率,如上所述。
正确预测的准确率
(a)女士患有恶性癌症(b)女士没有恶性癌症
(1)对于所有无复发(2)对于所有复发(3)对于 CART(4)对于理想模型
然后
正确预测的准确率
(a1)0/85(a2)85/85(a3)10/85(a4)85/85
(b1)201/201(b2)0/201(b3)188/201(b4)201/201。
让我解释一下,以提供背景
假设我们给机器学习算法两组细胞进行比较。一组是已知的癌细胞。一组是已知的健康细胞。
因此,算法应该将患者的细胞与上述两组进行比较,并生成两个相关性。
患者细胞与
健康细胞:80%-100%:已知癌细胞:0%-30%:女士患癌症的可能性很小。
健康细胞:0%-30%:已知癌细胞:70%-99%:女士患癌症的可能性很高。
健康细胞:40%-70%:已知癌细胞:30%-70%:女士患癌症的可能性很高。
健康细胞:0%-30%:已知癌细胞:10%-40%:机器学习工程师,我们有一些东西需要学习。女士,您处于临界状态。
健康细胞:50%-70%:已知癌细胞:40%-60%:机器学习工程师,我们有一些东西需要学习。女士,您处于临界状态。
我相信您指的是 TP/FP/FN/TN,您可以在此处了解更多信息
https://en.wikipedia.org/wiki/Precision_and_recall#Definition_(classification_context)
写得很好。切中要点,解释最简单。谢谢!
谢谢,很高兴它帮到了你!
您好,感谢您的文章!
是否可以使用模型性能与最佳性能之间的距离?
例如,假设我们有一个二分类数据集,比如一个不平衡的数据集。我们有五个指标
全局准确率、主要类别的检测率(也称为特异度)、主要类别的精确率、少数类别的检测率(灵敏度)和少数类别的精确率。
因此,完美模型的度量向量将是:(1, 1, 1, 1, 1)。
所以距离将等于
sqrt( (global_accuracy – 1)^2 + (sensitivity – 1)^2 + … )
选择最小化该度量的模型(或阈值、参数集……)是否有意义?
如果是这样,您是否有关于它的论文(上网还没找到……)?
再次感谢您的出色工作!
也许,这实际上是一个项目特定的问题——例如,模型对项目利益相关者来说最重要的方面是什么。
感谢您这篇非常实用的精彩文章,Jason 先生。
但是,我有一些问题,您认为多类不平衡问题最好的指标是什么?
这实际上取决于您的项目以及对您的项目利益相关者而言什么最重要。
流行的选项包括 F1、精确率、召回率以及像日志损失这样的概率度量。
我的项目是关于故障分类的,所以我想在我的情况下,召回率或 fbeta 会更合适。但我对是使用 micro、macro 还是 weighted averaging 对指标进行平均存在疑问。您认为哪种方法更适合不平衡分类?
我正在做一个预测违约概率的模型,并且我对模型的准确性感兴趣。
在选择模型时,我知道 0 是最差的值,1 是最好的值。是否存在任何标准值,高于该值即可接受模型?
我的准确率为 80.17%,但我找不到像 p 值那样有最低标准的值,例如
是的,您可以使用朴素模型来计算准确率,特别是多数类模型。
任何准确率高于该模型的模型都具有技能,任何准确率低于该模型的模型都不具有技能。
在这里了解更多
https://machinelearning.org.cn/faq/single-faq/how-to-know-if-a-model-has-good-performance
还有这里
https://machinelearning.org.cn/how-to-develop-and-evaluate-naive-classifier-strategies-using-probability/
你好 Gianinna,
您能分享一下您在 PD 模型方面的工作经验吗?我现在处于同样的情况。
此致
你好,
一个新手(稳步进步),我遇到了这种情况:三个不同的分类模型,NB、LR 和 SVM,在精确率、召回率等方面在记分牌上显示相同的数字。我意识到我的数据集是不平衡的,即一列包含 2,320 行摘要,另一列包含“Go”/“No go”限定词。2K+ 的摘要显示“No go”,而少于 100 显示“Go”。限定词指示是否继续处理摘要内容。
我读到我可以将模型中的权重从 None 改为 balanced,但我不知道在哪里添加此信息……;o/
我得到的 traceback 说
UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use
zero_divisionparameter to control this behavior._warn_prf(average, modifier, msg_start, len(result))
我无法移除这个错误(顺便说一下,我从谷歌搜索中了解到这本身并不是一个错误),但这并没有改变我选择的所有分类模型在其精确率和召回率度量上都有零的事实。
我尝试将 train/test 分割从 .3 改为 .5,然后改为 .1。错误与上述相同。
您有什么关于如何添加权重(如果这是问题所在??)或如何处理该问题的想法吗?
此致
Jens
您可以在定义模型时将 `class_weights` 设置为 `'balanced'`。
这是一个警告,它表明无法计算 F1 分数所需的精确率或召回率。您很可能预测的是所有值为 1 的情况(少数类)。
或许可以探索其他模型和替代模型配置。
更正
应该是这样说
我没有遇到移除该错误的问题(顺便说一句,我通过谷歌搜索了解到这本身并不是一个真正的错误),但这并没有改变我选择的所有分类模型在其精确率和召回率指标上都为零的状况。
没错。
感谢您这篇信息丰富的文章。不过,我有一个问题。
我们可以计算多类问题的灵敏度和特异性吗?如果可以,那么这些值的意义是什么?
我相信可以。您需要指定哪些是正类和负类。
很棒的文章。我想知道哪种指标适用于 NLP 预测模型。在文献中,人们更倾向于使用召回率、精确率和 F1 分数,而不是准确率,有什么特别的原因吗?
谢谢!
这取决于具体的任务。也许可以查阅您任务相关的文献,看看他们使用了哪些指标?
我能知道评估多类分类模型的最佳技术是什么吗?
好问题,请看这个
https://machinelearning.org.cn/tour-of-evaluation-metrics-for-imbalanced-classification/
你好,
一如既往,您的文章都非常精彩。
我有一个问题,我有一个不平衡且质量差的训练集,我进行了上采样,但神经网络遇到了问题。它无法对上采样后的类别进行分类。
为了说清楚
精确率 召回率 f1分数 支持数
1 0.56 1.00 0.72 1013
2 0.00 0.00 0.00 797
准确率 0.56 1810
宏平均 0.28 0.50 0.36 1810
加权平均 0.31 0.56 0.40 1810
这是我从神经网络中得到的结果,但令人费解的是,对于 SVC,在进行上采样后,我总是得到这样的结果
精确率 召回率 f1分数 支持数
1 0.84 0.96 0.90 1013
2 0.94 0.78 0.85 797
准确率 0.88 1810
宏平均 0.89 0.87 0.88 1810
加权平均 0.89 0.88 0.88 1810
这就像神经网络对我的训练集来说太复杂了(我尝试修改架构、层等等)。
这可能吗?
非常感谢
这可能是。使用性能最好的模型。
您好,
如果我们有一个多类分类但数据集是平衡的,准确率足够吗?
可以的!
要使这些数字正确,加法应该加上括号
“全部未复发”模型的 F1 分数为 2*((0*0)/0+0) 或 0。
“全部复发”模型的 F1 分数为 2*((0.3*1)/0.3+1) 或 0.46。
CART 模型的 F1 分数为 2*((0.43*0.12)/0.43+0.12) 或 0.19。
像这样
“全部无复发”模型的 F1 分数为 2*(0*0)/(0+0) 或 0。
“全部复发”模型的 F1 分数为 2*(0.3*1)/(0.3+1) 或 0.46。
CART 模型的 F1 分数为 2*(0.43*0.12)/(0.43+0.12) 或 0.19。
很棒的文章,谢谢!
谢谢,这可能更好
https://machinelearning.org.cn/feature-selection-with-real-and-categorical-data/
这个例子非常令人困惑。您应该举一个“是/否”类型的例子。
感谢您的建议。
先生,我想问一个问题:RIFO(排序改进 F 分数排序)和 F 分数差异,我对它们感到困惑,请先生帮助我,哪个更好更先进。
抱歉,我不知道“RIFO”。
嗨,Jason,
我正在尝试构建一个客户流失分类模型。但是,无论我尝试哪种模型,我都无法使任何评估指标超过 0.66。这是否意味着我需要更好的特征?
另外,在这种情况下,最佳行动方案是什么?
这也许能帮助您选择一个指标。
https://machinelearning.org.cn/tour-of-evaluation-metrics-for-imbalanced-classification/
你好 Jason,
您是如何得出 CART 混淆矩阵中的数字的?
那是 TP、FP、FN、TN 的数字。我无法理解这一部分。
请分享相关细节。
只需计数。您计算预测了多少个正样本,以及数据集中有多少个正样本。然后您可以将每个样本归类为 TP、FP、TN、FN。
在什么情况下,F 分数会有如此大的差异,即使只有 1%?
抱歉,我看不出您指的是什么。您说的是什么差异?
我的意思是,如果我有一个数据集中有 100 个正样本和 1000 个负样本。当我们计算这个数据的 F1 分数时,在这种情况下,这种差异是否显著。
如果我在这组数据上应用随机森林,假设我得到 98% 的 F1 分数,而另一个人做同样的工作,他得到 98.5% 的 F1 分数。那么,在这种情况下,F1 分数提高 0.5% 会有什么不同?
我不确定您在问什么。但对于负样本为 10% 的情况,F1 分数提高 0.5% 似乎对我来说已经很多了。您是在问一个 0.5% 的改进是否显著的用例吗?这可能是一个答案:https://qr.ae/pGxHUL
那么,在我们关注假阳性和假阴性的时候,我们计算 F 分数。在这种情况下,我认为提高 0.5% 似乎很多?我说得对吗?
我认为是的。但如果您不确定,可以尝试考虑 MCC,它同时考虑了正负样本:https://en.wikipedia.org/wiki/Matthews_correlation_coefficient
首先,我想感谢您的课程,它们非常非常有用。
文档分类的最佳指标是什么,为什么?
嗨 marwa... 不客气!以下资源希望对您有所帮助
https://iq.opengenus.org/performance-metrics-in-classification-regression/