决策树是预测建模机器学习中一种重要的算法。
经典的决策树算法已经存在了几十年,像随机森林这样的现代变种是现有的最强大的技术之一。
在这篇文章中,您将发现这种简单的决策树算法,它以更现代的名称 CART 而闻名,CART 代表分类与回归树。阅读本文后,您将了解
- 用于描述机器学习中 CART 算法的许多名称。
- 学习到的 CART 模型使用的表示,它实际上存储在磁盘上。
- 如何从训练数据中学习 CART 模型。
- 如何使用学习到的 CART 模型对未见过的数据进行预测。
- 可用于进一步了解 CART 和相关算法的其他资源。
如果您上过算法和数据结构课程,您可能很难克制自己不去实现这个简单而强大的算法。从那里,您离自己实现随机森林只差一小步。
通过我的新书《掌握机器学习算法》启动您的项目,包括所有示例的分步教程和Excel 电子表格文件。
让我们开始吧。
- 2017 年 8 月更新:修复了一个排版错误,该错误指出基尼系数是类实例的数量,应该是实例的比例。还更新了内容,以展示用于评估分割的基尼加权以及计算子节点的纯度。

用于机器学习的分类和回归树
照片由 Wonderlane 提供,保留部分权利。
决策树
分类与回归树,简称 CART,是由 Leo Breiman 引入的术语,用于指代可用于分类或回归预测建模问题的 决策树 算法。
传统上,这种算法被称为“决策树”,但在某些平台(如 R)上,它们被称作更现代的术语 CART。
CART 算法为袋装决策树、随机森林和梯度提升决策树等重要算法提供了基础。
获取您的免费算法思维导图
方便的机器学习算法思维导图样本。
我创建了一份方便的思维导图,其中包含60多种按类型组织的算法。
下载、打印并使用它。
还可以独家访问机器学习算法电子邮件迷你课程。
CART 模型表示
CART 模型的表示是一个二叉树。
这是您在算法和数据结构中遇到的二叉树,没什么特别的。每个根节点代表一个输入变量 (x) 和该变量上的一个分割点(假设变量是数值型的)。
树的叶节点包含一个用于进行预测的输出变量 (y)。
给定一个包含两个输入(x),身高(厘米)和体重(公斤),输出性别(男或女)的数据集,下面是一个二叉决策树的粗略示例(纯属虚构,仅用于演示目的)。
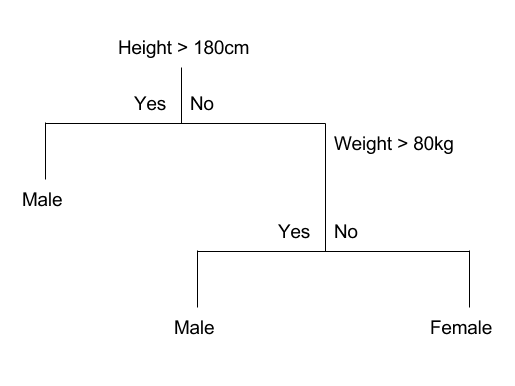
决策树示例
该树可以作为图形或一组规则存储到文件中。例如,下面是上述决策树的一组规则。
|
1 2 3 4 |
如果身高 > 180 厘米,则为男性 如果身高 <= 180 厘米 且 体重 > 80 公斤,则为男性 如果身高 <= 180 厘米 且 体重 <= 80 公斤,则为女性 使用 CART 模型进行预测 |
通过上述 CART 模型的二叉树表示,进行预测相对简单。
给定一个新的输入,通过评估从树的根节点开始的特定输入来遍历树。
一个学习到的二叉树实际上是对输入空间的划分。您可以将每个输入变量视为 p 维空间中的一个维度。决策树将其划分为矩形(当 p=2 个输入变量时)或具有更多输入的一些超矩形。
新数据通过树进行过滤并落在其中一个矩形中,该矩形的输出值就是模型做出的预测。这让您对 CART 模型能够做出的决策类型有所了解,例如箱形决策边界。
例如,给定输入 [身高 = 160 厘米,体重 = 65 公斤],我们将按如下方式遍历上述树:
|
1 2 3 |
身高 > 180 厘米:否 体重 > 80 公斤:否 因此:女性 |
从数据中学习 CART 模型
创建 CART 模型涉及选择输入变量和这些变量上的分割点,直到构建出合适的树。
使用贪婪算法选择要使用的输入变量和特定的分割点,以最小化成本函数。树的构建使用预定义的停止准则结束,例如分配给树的每个叶节点的训练实例的最小数量。
贪婪分割
创建二叉决策树实际上是一个划分输入空间的过程。采用一种称为 递归二叉分割 的贪婪方法来划分空间。
这是一个数值过程,其中所有值都被排列起来,并使用成本函数尝试和测试不同的分割点。选择成本最低的分割点(因为我们最小化成本)。
所有输入变量和所有可能的分割点都以贪婪的方式进行评估和选择(例如,每次都选择最佳分割点)。
对于回归预测建模问题,用于选择分割点并最小化的成本函数是所有落入矩形内的训练样本的平方误差和
和(y - 预测)^2
其中 y 是训练样本的输出,prediction 是矩形的预测输出。
对于分类,使用基尼指数函数,该函数提供了叶节点“纯度”的指示(分配给每个节点的训练数据的混合程度)。
G = sum(pk * (1 – pk))
其中 G 是所有类的基尼指数,pk 是感兴趣矩形中具有类 k 的训练实例的比例。一个所有类都属于同一类型(完美类纯度)的节点将具有 G=0,而对于二元分类问题,具有 50-50 类分割(最差纯度)的节点将具有 G=0.5。
对于二元分类问题,可以将其改写为
G = 2 * p1 * p2
或者
G = 1 – (p1^2 + p2^2)
每个节点的基尼指数计算按父节点中的总实例数加权。因此,二元分类问题中选定分割点的基尼分数计算如下:
G = ((1 – (g1_1^2 + g1_2^2)) * (ng1/n)) + ((1 – (g2_1^2 + g2_2^2)) * (ng2/n))
其中 G 是分割点的基尼指数,g1_1 是组 1 中类别 1 的实例比例,g1_2 是类别 2 的实例比例,g2_1 是组 2 中类别 1 的实例比例,g2_2 是组 2 中类别 2 的实例比例,ng1 和 ng2 是组 1 和组 2 中的实例总数,n 是我们试图从父节点中分组的实例总数。
停止准则
上述递归二叉分割过程需要知道何时停止分割,因为它使用训练数据向下遍历树。
最常见的停止过程是使用分配给每个叶节点的训练实例数量的最小计数。如果计数小于某个最小值,则不接受分割,并将该节点视为最终叶节点。
训练成员的数量根据数据集进行调整,例如 5 或 10。它定义了树对训练数据的特异性。如果过于具体(例如计数为 1),树将过度拟合训练数据,并且在测试集上可能表现不佳。
修剪树
停止准则很重要,因为它强烈影响树的性能。您可以在学习树后使用 修剪 来进一步提升性能。
决策树的复杂性定义为树中分割的数量。更简单的树是首选。它们易于理解(您可以打印出来并展示给领域专家),并且不太可能过度拟合您的数据。
最快和最简单的修剪方法是遍历树中的每个叶节点,并使用保留测试集评估移除它的效果。仅当移除叶节点导致整个测试集上的总成本函数下降时才移除叶节点。当无法进一步改进时,停止移除节点。
可以使用更复杂的修剪方法,例如成本复杂性修剪(也称为最弱链接修剪),其中使用学习参数(alpha)来权衡是否可以根据子树的大小移除节点。

决策树的递归二叉分割
照片由 Paul L Dineen 拍摄,保留部分权利。
CART 的数据准备
CART 不需要任何特殊的数据准备,只需对问题进行良好表示即可。
进一步阅读
本节列出了一些资源,如果您想深入了解 CART,可以参考这些资源。
以下是一些从机器学习角度描述 CART 算法的优秀机器学习书籍。
- 统计学习导论:附带 R 应用程序,第八章
- 应用预测建模,第八章和第十四章
- 数据挖掘:实用机器学习工具和技术,第六章。
总结
在这篇文章中,您发现了机器学习中的分类与回归树 (CART)。您了解了
- 该算法的经典名称“决策树”和更现代的名称“CART”。
- CART 使用的表示是二叉树。
- 通过给定新的输入记录遍历二叉树,CART 可以进行预测。
- 树是使用训练数据上的贪婪算法学习的,以选择树中的分割点。
- 停止准则定义了树学习的程度,并且可以使用修剪来改进学习到的树。
您对 CART 或本文有任何疑问吗?
在评论中提问,我将尽力回答。







C 4.5(在 weka 中称为 J48)和 C 5.0 怎么样,请老师制作一个教程,我需要它
我有一个句子,它的极性是负或正,我想用 CART 来提高准确性。但是我不知道该怎么做?
是否可以将 CART 融入 GA?
不知道,乔。
先生,我想比较 CART 和 GA。
嗨 Mynose,它们非常不同。CART 是一种函数逼近方法,而 GA 是一种函数优化方法。
我想你可以使用 GA 来优化一组规则或一棵树,然后将其与 CART 进行比较。听起来很有趣。
嗨,Jason!在使用 CART 模型时,我该如何避免过拟合问题?当我使用 CART 树对不同故障类型的数据进行分类时,cp 是获得最优 CART 模型的唯一参数。但是,根据我的领域知识,训练模型的树结构明显过拟合。那么我该如何避免过拟合呢?
嗨,Lee,好问题。
主要方法是限制树的深度。
您可以在构建树时执行此操作,但首选方法是在构建深树后进行修剪。
你好先生,
在实现贪婪算法时,输入变量的选择是如何完成的?为了计算最小成本函数,您需要预测值,但是算法如何为第一次分割选择输入变量?
此致,
Rohit
嗨 Rohit,我们计算分割时有预测值——它们都在训练数据中。
分割在训练后固定,然后我们只用它们对新数据进行预测。
先生,我有以下问题。如果您能为我解答,将对我非常有帮助。
1) CART 是数据科学领域决策树方法的现代名称吗?
2) CART 可以在哪些场景中使用?
3) 使用 CART 相对于其他预测技术有什么优势?
嗨 madhav,
1. 是的,CART 或分类与回归树是标准决策树的现代名称。
2. 广泛应用于分类和回归预测建模问题。试试看。
3. 训练速度快,结果易于理解,并且通常非常有效。
嗨 Jason
我很好奇,为什么我的 CART 在排除一个变量(例如 ID)后只生成一个节点?我尝试更改 cp,但结果仍然相同。您能帮我解决这个问题吗?
CART 算法适用于决策制定项目吗?
这取决于决策是否可以框定为分类或回归类型问题。
嗨,Jason,
我是机器学习新手。实习要求是否有可能制作一个分类方法。输入变量是少量单词(1-6 个),输出变量是 0 或 1。是否可以将 CART 应用于此问题?我很难找到不同算法用于哪种问题,您有什么建议吗?
我建议你遵循这个过程
https://machinelearning.org.cn/start-here/#process
嗨,Jason,
我想知道在 CART、CHAID 和 QUEST 决策树算法中需要更改哪些参数才能进行有效建模。
抱歉,我没有这些信息。
嗨,Jason,
我不明白算法如何选择用于分割的输入变量。在你的例子中,
为什么身高在体重之前分割?谢谢。
这只是一个例子。
嗨,Jason,
我正在处理高度不平衡的数据,我有 4 个类别,其中 98.4% 的数据是类别 0。当我尝试使用 rpart 包修剪树时。使用 X-Var 相对误差来决定节点数量,结果恰好是一个节点。是否可以将 X-Var 相对误差更改为其他更考虑其他类别的误差(在此包中或在其他包中)?
谢谢!!
哎呀
抱歉,我不熟悉那个包。
嗨,Jason,
我很少看到用于回归的决策树示例,只看到用于分类的。您知道有什么喜欢的例子吗,或者您会为此发一篇帖子吗?讨论 OLS 和其他线性回归方法之间的区别会很有趣,我认为。
谢谢!
这里有一些例子
https://machinelearning.org.cn/non-linear-regression-in-r-with-decision-trees/
使用博客上的搜索功能。
你好,
关于基尼函数的一点说明——我认为有一个错字
G = sum(pk * (1 – pk))
-> G = sum( pk/p * (1 – pk/p) ),其中 p 是矩形中的实例总数。
因为我们似乎在查看每个类的实例的相对比例。
谢谢 Pia,我会调查的。
是的,这是一个错字。已修复。谢谢!
嗨!Jason Brownlee
你能帮我回答这个问题吗,我是机器学习新手。谢谢
您是渣打银行企业和投资银行部的初级数据科学家,任务是向投资银行家解释数据科学算法的工作原理以及它们如何帮助他们开展日常活动。
投资银行家每天从内部和外部来源(如期刊、新闻源、宏观经济数据、公司财务等)收到大量信息。他们利用这些信息评估下一个大宗交易可能来自何处,并优先考虑他们认为最有可能实现的那些机会。他们还考虑以下因素:
I. 交易价值
II. 潜在佣金
III. 渣打银行在该交易发生国家的业务存在情况
IV. 交易类型(并购、收购、股权交易等)
V. 参与交易的公司的信用评级
VI. 地理区域
VII. 工业部门(例如农业、旅游、金融服务等)
请注意,交易发生频率较低。
然后,您决定向他们展示决策树的强大功能,以及如何使用它们来评估所有潜在交易。使用以上信息
1. 解释构建决策树的步骤以及它们如何应用于这一业务挑战。
这看起来像是家庭作业,我建议您向老师寻求帮助。
#rm(list=ls(all=TRUE))
setwd(“C:\\Users\\hp\\Desktop\\R”)
版本
#从 CSV 文件读取
univ=read.table('dataDemographics.csv',
header=T,sep=',',
col.names=c("ID", "年龄", "经验", "收入",
"邮编", "家庭",
"教育", "抵押贷款"))
dim(univ)
head(univ)
str(univ)
names(univ)
sum(is.na(univ))
sum(is.na(univ[[2]])) #查看第 2 列中的缺失值
sapply(univ, function(x) sum(is.na(x)))
row.names.data.frame(is.na(univ))
# 读取第二个表
loanCalls <- read.table("dataLoanCalls.csv", header=T, sep=",",
col.names=c("ID", "信息请求", "贷款"),
dec=".", na.strings="NA")
head(loanCalls)
dim(loanCalls)
sum(is.na(loanCalls))
sapply(loanCalls, function(x) sum(is.na(x)))
# 读取第三个表
cc <- read.table("dataCC.csv", header=T, sep=",",
col.names=c("ID", "月份", "月度"),
dec=".", na.strings="NA")
head(cc)
dim(cc)
sum(is.na(cc))
sapply(cc, function(x)sum(is.na(x)))
#我们有 12 个月的月度信用卡支出。
#我们需要计算月度支出
tapply
head(cc)
summary(cc)
str(cc)
cc$ID <- as.factor(cc$ID)
cc$Month <- as.factor(cc$Month)
sapply(cc,function(x) length(unique(x)))
summary(cc)
# 计算均值的函数
meanNA <- function(x){
a <-mean(x, na.rm=TRUE)
return(a)
}
ccAvg <- data.frame(seq(1,5000),
tapply(cc$Monthly, cc$ID, meanNA))
ccAvg
head(ccAvg)
dim(ccAvg)
names(ccAvg)
colnames(ccAvg) <- c("ID", "ccavg")
str(ccAvg)
ccAvg$ID <- as.factor(ccAvg$ID)
summary(ccAvg)
str(ccAvg)
rm(cc)
# 读取第四个表
otherAccts <- read.table("dataOtherAccts.csv", header=T, sep=",",
col.names=c("ID", "变量", "值"),
dec=".", na.strings="NA")
dim(otherAccts)
head(otherAccts)
summary(otherAccts)
otherAccts$ID <- as.factor(otherAccts$ID)
otherAccts$Val <- as.factor(otherAccts$Val)
summary(otherAccts)
str(otherAccts)
# 转置
library(reshape)
otherAcctsT=data.frame(cast(otherAccts,
ID~Var,value="Val"))
head(otherAcctsT)
dim(otherAcctsT)
#合并表格
univComp <- merge(univ,ccAvg,
by.x="ID",by.y="ID",
all=TRUE) #外连接
univComp <- merge(univComp, otherAcctsT,
by.x="ID", by.y="ID",
all=TRUE)
univComp <- merge(univComp, loanCalls,
by.x="ID", by.y="ID",
all=TRUE)
dim(univComp)
head(univComp)
str(univComp)
summary(univComp)
names(univComp)
sum(is.na(univComp))
#处理缺失值
#install.packages("VIM")
library(VIM)
matrixplot(univComp)
#使用KNNimputation填充缺失值
library(DMwR)
univ2 <- knnImputation(univComp,
k = 10, meth = "median")
sum(is.na(univ2))
summary(univ2)
head(univ2,10)
univ2$family <- ceiling(univ2$family)
univ2$edu <- ceiling(univ2$edu)
head(univ2,15)
str(univ2)
names(univ2)
# 将ID、Family、Edu、loan转换为因子
attach(univ2)
univ2$ID <- as.factor(ID)
univ2$family <- as.factor(family)
univ2$edu <- as.factor(edu)
univ2$loan <- as.factor(loan)
str(univ2)
summary(univ2)
sapply(univ2, function(x) length(unique(x)))
# 移除id、Zip和experience,因为experience
# 与年龄相关
names(univ2)
univ2Num <- subset(univ2, select=c(2,3,4,8,9))
head(univ2Num)
cor(univ2Num)
names(univ2)
univ2 <- univ2[,-c(1,3,5)]
str(univ2)
summary(univ2)
# 将分类变量转换为因子
# 将年龄和收入离散化为分类变量
library(infotheo)
#离散化变量'age'
age <- discretize(univ2$age, disc="equalfreq",
nbins=10)
class(age)
head(age)
age=as.factor(age$X)
#离散化变量'inc'
inc=discretize(univ2$inc, disc="equalfreq",
nbins=10)
head(inc)
inc=as.factor(inc$X)
#离散化变量'age'
ccavg=discretize(univ2$ccavg, disc="equalwidth",
nbins=10)
ccavg=as.factor(ccavg$X)
#离散化变量'age'
mortgage=discretize(univ2$mortgage, disc="equalwidth",
nbins=5)
mortgage=as.factor(mortgage$X)
# *** 从原始数据中移除数值变量
# *** 并添加它们的分类形式
head(univ2)
univ2 <- subset(univ2, select= -c(age,inc,ccavg,mortgage))
head(univ2)
univ2 <- cbind(age,inc,ccavg,mortgage,univ2)
head(univ2,20)
dim(univ2)
str(univ2)
summary(univ2)
# 让我们将数据分为训练、测试
# 和评估数据集
rows=seq(1,5000,1)
set.seed(123)
trainRows=sample(rows,3000)
set.seed(123)
remainingRows=rows[-(trainRows)]
testRows=sample(remainingRows, 1000)
evalRows=rows[-c(trainRows,testRows)]
train = univ2[trainRows,]
test=univ2[testRows,]
eval=univ2[evalRows,]
dim(train); dim(test); dim(eval)
rm(age,ccavg, mortgage, inc, univ)
#### 构建模型
#使用C50的决策树
names(train)
#install.packages("C50")
library(C50)
dtC50 <- C5.0(loan ~ ., data = train, rules=TRUE)
summary(dtC50)
predict(dtC50, newdata=train, type="class")
a=table(train$loan, predict(dtC50,
newdata=train, type="class"))
rcTrain=(a[2,2])/(a[2,1]+a[2,2])*100
rcTrain
# 在测试数据上进行预测
predict(dtC50, newdata=test, type="class")
a=table(test$loan, predict(dtC50,
newdata=test, type="class"))
rcTest=(a[2,2])/(a[2,1]+a[2,2])*100
rcTest
# 在评估数据上进行预测
predict(dtC50, newdata=eval, type="class")
a=table(eval$loan, predict(dtC50,
newdata=eval, type="class"))
rcEval=(a[2,2])/(a[2,1]+a[2,2])*100
rcEval
cat("训练召回率", rcTrain, '\n',
"测试召回率", rcTest, '\n',
"评估召回率", rcEval)
#通过将inc和ccavg中的bin数量增加到10进行测试
#通过将inc和ccavg中的bin更改为equalwidth进行测试
library(ggplot2)
#使用qplot
qplot(edu, inc, data=univ2, color=loan,
size=as.numeric(ccavg))+
theme_bw()+scale_size_area(max_size=9)+
xlab("教育程度") +
ylab("收入") +
theme(axis.text.x=element_text(size=18),
axis.title.x = element_text(size =18,
colour = 'black'))+
theme(axis.text.y=element_text(size=18),
axis.title.y = element_text(size = 18,
colour = 'black',
angle = 90))
#使用ggplot
ggplot(data=univ2,
aes(x=edu, y=inc, color=loan,
size=as.numeric(ccavg)))+
geom_point()+
scale_size_area(max_size=9)+
xlab("教育程度") +
ylab("收入") +
theme_bw()+
theme(axis.text.x=element_text(size=18),
axis.title.x = element_text(size =18,
colour = 'black'))+
theme(axis.text.y=element_text(size=18),
axis.title.y = element_text(size = 18,
colour = 'black',
angle = 90))
rm(a,rcEval,rcTest,rcTrain)
#—————————————————
#使用CART的决策树
#加载rpart包
library(rpart)
#使用rpart函数构建分类树模型
dtCart <- rpart(loan ~ ., data=train, method="class", cp = .001)
#输入churn.rp以检索分类树的节点详细信息
# classification tree
dtCart
#使用printcp函数检查复杂度参数
printcp(dtCart)
#使用plotcp函数绘制成本复杂度参数
plotcp(dtCart)
#plot函数和text函数绘制分类树
plot(dtCart,main="贷款类别分类树",
margin=.1, uniform=TRUE)
text(dtCart, use.n=T)
## 验证分类树预测性能的步骤
————————————————————————
predict(dtCart, newdata=train, type="class")
a <- table(train$loan, predict(dtCart,
newdata=train, type="class"))
dtrain <- (a[2,2])/(a[2,1]+a[2,2])*100
a <-table(test$loan, predict(dtCart,
newdata=test, type="class"))
dtest <- (a[2,2])/(a[2,1]+a[2,2])*100
a <- table(eval$loan, predict(dtCart,
newdata=eval, type="class"))
deval <- (a[2,2])/(a[2,1]+a[2,2])*100
cat("训练召回率", dtrain, '\n',
"测试召回率", dtest, '\n',
"评估召回率", deval)
#### 修剪树
——————–
#查找分类树模型的最小交叉验证错误
#classification tree model
min(dtCart$cptable[,"xerror"])
#定位具有最小交叉验证错误的记录
which.min(dtCart$cptable[,"xerror"])
#获取具有最小交叉验证错误的记录的成本复杂度参数
# the minimum cross-validation errors
dtCart.cp <- dtCart$cptable[5,"CP"]
dtCart.cp
#通过将cp参数设置为具有最小交叉验证错误的记录的CP值来修剪树
# of the record with minimum cross-validation errors
prune.tree <- prune(dtCart, cp= dtCart.cp)
prune.tree
#使用plot和text函数可视化分类树
#text function
plot(prune.tree, margin= 0.01)
text(prune.tree, all=FALSE , use.n=TRUE)
## 验证分类树预测性能的步骤
————————————————————————
a <- table(train$loan, predict(prune.tree,
newdata=train, type="class"))
dtrain <- (a[2,2])/(a[2,1]+a[2,2])*100
a <-table(test$loan, predict(prune.tree,
newdata=test, type="class"))
dtest <- (a[2,2])/(a[2,1]+a[2,2])*100
a <- table(eval$loan, predict(prune.tree,
newdata=eval, type="class"))
deval <- (a[2,2])/(a[2,1]+a[2,2])*100
cat("训练召回率", dtrain, '\n',
"测试召回率", dtest, '\n',
"评估召回率", deval)
#———————————————————
# 使用条件推断的决策树
library(party)
ctree.model= ctree(loan ~ ., data = train)
plot(ctree.model)
a=table(train$loan, predict(ctree.model, newdata=train))
djtrain <- (a[2,2])/(a[2,1]+a[2,2])*100
a=table(test$loan, predict(ctree.model, newdata=test))
djtest <- (a[2,2])/(a[2,1]+a[2,2])*100
a=table(eval$loan, predict(ctree.model, newdata=eval))
djeval <- (a[2,2])/(a[2,1]+a[2,2])*100
cat("训练召回率", djtrain, '\n',
"测试召回率", djtest, '\n',
"评估召回率", djeval)
我无法调试你的代码。
嘿,杰森!
“免费获取你的算法思维导图”:页面顶部的免费下载链接指向的页面不存在。
请帮忙。
链接对我来说是有效的。
你可以在这里注册获取思维导图
https://machinelearningmastery.leadpages.co/machine-learning-algorithms-mini-course/
在这个链接(www.saedsayad.com/decision_tree.htm)中,Saed在页面底部写了一些关于决策树的问题。所以我的问题是,
1. 如果我们在将模型拟合到数据集之前处理了数据集中的缺失值,决策树将如何工作,正如Saed提到的,决策树只处理缺失值?
2. 什么是连续属性,正如Saed暗示的,决策树算法处理连续属性(分箱)?
请帮助解决这些问题……..
确实,缺失值可以被视为另一个分割值。
连续意味着实数值。
如果你有关于Saed的问题,也许直接问他?
CART可以在超市中使用吗??
超市是什么?
你好 Jason,
我想知道贪婪算法和基尼指数到底指的是什么??它们有什么用?
我在这篇文章中展示了如何实现基尼分数
https://machinelearning.org.cn/implement-decision-tree-algorithm-scratch-python/
先生早上好,我想问您关于CART算法预测连续数的问题……我查阅了其他资料,它说要预测连续数,我们应该用标准差减小来代替基尼指数。这是真的吗??
谢谢,先生
基尼指数适用于分类的CART,你需要为回归使用不同的度量。抱歉,我没有这方面的例子。
谢谢您的回复,先生。据此,我想请教您关于标准差减小可用于回归树的看法。如果您不介意,我希望您能向我解释,先生。谢谢您,先生。
抱歉,我不明白你的问题。也许你可以提供更多的背景信息?
什么是“标准差减小”,它与回归树有什么关系?
我读过这篇文章 http://www.saedsayad.com/decision_tree_reg.htm
他用标准差减小来代替信息增益。所以,我仍然困惑于如何用这样的公式来构建树。也许,您可以帮助我,先生.. 🙂
先谢谢了
抱歉,我不了解那种方法,也许可以联系作者?
你好!先生
我想知道,CART可以用于我的系统,包括三个类别标签吗?
CART可以支持2个或更多类别标签。
cart和id3有什么区别?
我记得ID3先出现,CART是它的改进。
我手头不记得具体的区别,也许这会有帮助
https://en.wikipedia.org/wiki/ID3_algorithm
CART中的预测变量是相关的还是不相关的。
通常不相关会更好,但对于CART来说,这不像其他算法那样重要。
尝试使用和不使用相关输入,并比较性能。
谢谢教授,文章写得很好,通俗易懂……
您可以发布关于模糊CART的文章吗?
我现在决定将此方法用于我的案例研究……
万分感谢
感谢您的建议。
您好,先生,我想问一些我不明白的问题。如果我的数据集有三个类别标签,我可以使用CART吗?
当然可以。
在回归中,我们最终可以得到像y=0.91+1.44X1+1.07X2这样的方程,其中我们可以用任意数量的值替换x1和x2,使用CART是否可以在最后得到一个类似的公式?
不,相反,你将从树中提取一组针对特定输入的规则。
有人有R中的贝叶斯加性回归树(BART)代码吗??我需要它
手头没有,抱歉。
???? 您好,Jason先生,
如何将树以一组规则的形式存储到Python文件中?请问
你可以枚举从根到叶子的所有树路径作为规则列表,然后将它们保存到文件中。
不过,我没有这方面的例子,抱歉。
CART是否可以在不使用“一对多”方法的情况下进行多类别分类?支持多类别分类的决策树算法有哪些?我知道CHIAD树的每个节点可以有超过2个分割。这是否意味着它可以处理多类别分类?
好问题,我相信CART支持多类别分类。
我建议查阅一本好的教科书,例如“统计学习的要素”。
你好,我是机器学习新手,但我想使用CART增强类别性能评估,这可能吗?
例如,输入变量会是什么?
这里有一个Python中CART的清晰示例
https://machinelearning.org.cn/implement-decision-tree-algorithm-scratch-python/
我的问题是:当我有一个数据集,想计算它的基尼指数或CART时。那么我的理解是单独计算每个属性实例的基尼指数。之后计算所有指数的加权和。其中将进一步决定根节点……
请帮忙。
你可以在这里看到Python中的计算示例
https://machinelearning.org.cn/implement-decision-tree-algorithm-scratch-python/
先生,
如果我想从这段代码中计算ROC值,这可能吗?
你能给一些提示怎么做吗?
请看这个教程
https://machinelearning.org.cn/roc-curves-and-precision-recall-curves-for-classification-in-python/
嗨,Jason,
我无法下载算法思维导图;我按照步骤操作,输入了正确的邮箱地址,但什么也没有。
提前感谢。
直接联系我,我会通过电子邮件发送给你
https://machinelearning.org.cn/contact/
邮件已发送。非常感谢。
已收到并回复。不客气。
那么在CART中,每个特征都会被多次选择,而不像ID3中每个特征只被考虑一次,对吗?
是的,据我所知,CART对变量在树中出现的次数没有限制。
你好,我是机器学习新手,但想使用CART来提高类别性能评估,这可能吗?
例如,输入变量会是什么?
也许这会对你有帮助
https://machinelearning.org.cn/how-to-define-your-machine-learning-problem/
CART树总是对称的吗?它对CART会有优势还是劣势?
不,树可能是不对称的。
这对CART有好处吗?
取决于数据。
好信息,先生,谢谢。
谢谢。
我是机器学习新手。我想确认我的理解。对于每个节点,所有特征都将与所有可能的分割点进行测试,以最小化成本函数吗?我的意思是,在为任何节点分配具有分割点的特定特征之前。每个特征都将与所有可能的分割点进行测试,并选择产生最小成本函数的那个吗?
请回复。
是的,但仅限于收集/分配到该点的数据中。