聚类或聚类分析是一种无监督学习问题。
它通常用作数据分析技术,用于发现数据中有趣的模式,例如根据客户行为对客户进行分组。
有许多聚类算法可供选择,但没有一种聚类算法适用于所有情况。相反,最好探索一系列聚类算法和每种算法的不同配置。
在本教程中,您将了解如何在 Python 中拟合和使用顶级的聚类算法。
完成本教程后,您将了解:
- 聚类是在特征空间中寻找自然群组的无监督问题。
- 有许多不同的聚类算法,没有一种方法适用于所有数据集。
- 如何使用 scikit-learn 机器学习库在 Python 中实现、拟合和使用顶级的聚类算法。
通过我的新书 Machine Learning Mastery With Python 开启您的项目,其中包含分步教程和所有示例的Python 源代码文件。
让我们开始吧。

Python 聚类算法
照片由 Lars Plougmann 拍摄,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- 聚类
- 聚类算法
- 聚类算法示例
- 库安装
- 聚类数据集
- 亲和力传播
- 凝聚聚类
- BIRCH
- DBSCAN
- K-Means
- Mini-Batch K-Means
- Mean Shift
- OPTICS
- 谱聚类
- 高斯混合模型
聚类
聚类分析或聚类是一种无监督机器学习任务。
它涉及自动发现数据中的自然分组。与监督学习(如预测建模)不同,聚类算法仅解释输入数据并在特征空间中找到自然群组或簇。
当没有类别需要预测,而是实例要被划分为自然组时,就会应用聚类技术。
— 第 141 页,Data Mining: Practical Machine Learning Tools and Techniques, 2016。
簇通常是特征空间中的一个密度区域,其中来自该领域的示例(观测值或数据行)比其他簇更接近该簇。簇可能有一个中心(质心),该中心是特征空间中的一个样本或点,并且可能有一个边界或范围。
这些簇可能反映了从中提取实例的领域中起作用的某些机制,一种使某些实例比其他实例更相似的机制。
— 第 141-142 页,Data Mining: Practical Machine Learning Tools and Techniques, 2016。
聚类可以作为数据分析活动,以了解有关问题域的更多信息,即所谓的模式发现或知识发现。
例如
- 可以认为系统发育树是手动聚类分析的结果。
- 将正常数据与异常值或异常分开可以视为聚类问题。
- 基于自然行为分离簇是一个聚类问题,称为市场细分。
聚类还可以用作一种特征工程,其中可以将现有和新示例映射并标记为属于数据中已识别的簇之一。
已识别簇的评估是主观的,可能需要领域专家,尽管存在许多特定于聚类的定量度量。通常,聚类算法在具有预定义簇的合成数据集上进行学术比较,算法应能发现这些簇。
聚类是一种无监督学习技术,因此很难评估任何给定方法的输出质量。
— 第 534 页,Machine Learning: A Probabilistic Perspective, 2012。
聚类算法
有许多类型的聚类算法。
许多算法使用特征空间中示例之间的相似性或距离度量来发现观测值的密集区域。因此,在使用聚类算法之前对数据进行缩放通常是最佳实践。
聚类分析所有目标的核心是正在聚类的各个对象之间的相似性(或不相似性)程度的概念。聚类方法尝试根据提供给它的相似性定义来对对象进行分组。
— 第 502 页,The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2016。
一些聚类算法要求您指定或猜测数据中要发现的簇的数量,而另一些算法则要求指定示例之间某个最小距离,在其中示例可以被认为是“接近”或“连接”。
因此,聚类分析是一个迭代过程,其中对已识别的簇进行主观评估,并将该评估反馈到算法配置的更改中,直到达到期望或适当的结果。
scikit-learn 库提供了多种不同的聚类算法供您选择。
以下是 10 种更受欢迎的算法的列表
- 亲和力传播
- 凝聚聚类
- BIRCH
- DBSCAN
- K-Means
- Mini-Batch K-Means
- Mean Shift
- OPTICS
- 谱聚类
- 高斯混合模型
每种算法都为发现数据中的自然群组这一挑战提供了不同的方法。
没有最好的聚类算法,也没有不经过受控实验就能找到适合您数据的最佳算法的简单方法。
在本教程中,我们将回顾如何在 scikit-learn 库中使用这 10 种流行的聚类算法。
这些示例将为您提供复制粘贴示例并将方法应用于您自己的数据的基础。
我们不会深入探讨算法工作原理背后的理论,也不会直接比较它们。有关此主题的良好起点,请参阅
让我们开始吧。
聚类算法示例
在本节中,我们将回顾如何在 scikit-learn 中使用 10 种流行的聚类算法。
这包括拟合模型的示例和可视化结果的示例。
这些示例旨在让您复制粘贴到您自己的项目中并将其方法应用于您自己的数据。
库安装
首先,让我们安装库。
不要跳过此步骤,您需要确保安装了最新版本。
您可以使用 pip Python 安装程序安装 scikit-learn 库,如下所示:
|
1 |
sudo pip install scikit-learn |
有关特定于您平台的其他安装说明,请参阅:
接下来,让我们确认已安装该库并正在使用现代版本。
运行以下脚本打印库版本号。
|
1 2 3 |
# 检查 scikit-learn 版本 import sklearn print(sklearn.__version__) |
运行该示例,您应该会看到以下版本号或更高版本。
|
1 |
0.22.1 |
聚类数据集
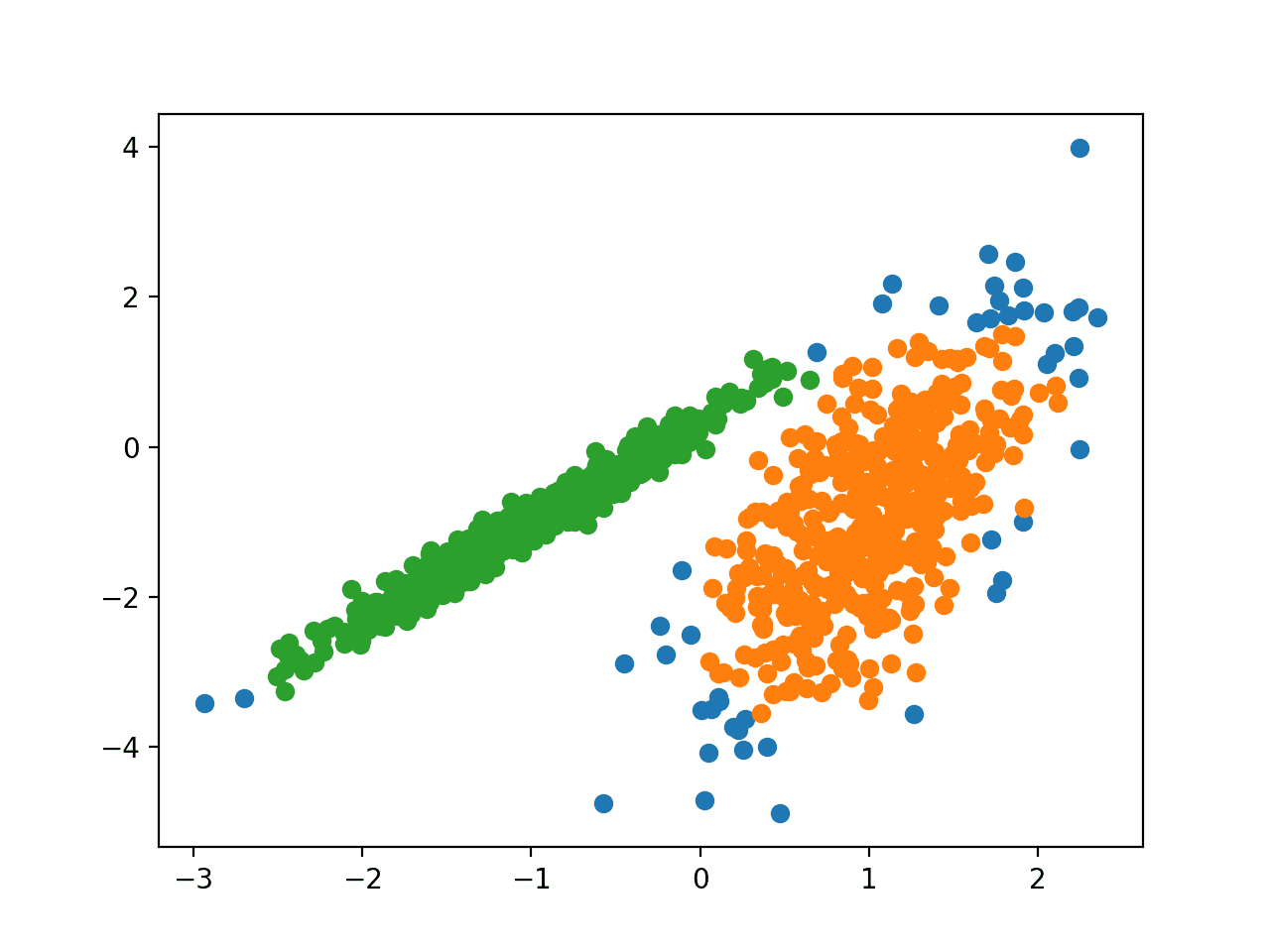
我们将使用 make_classification() 函数来创建测试二分类数据集。
数据集将包含 1,000 个示例,其中包含两个输入特征和一个类簇。簇在二维空间中非常明显,因此我们可以使用散点图绘制数据,并按分配的簇对图中的点进行着色。这将有助于(至少在测试问题上)了解簇的识别“效果”如何。
此测试问题中的簇基于多元高斯分布,并非所有聚类算法都能有效识别这些类型的簇。因此,本教程中的结果不应作为普遍比较方法的依据。
下面列出了创建和汇总合成聚类数据集的示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 合成分类数据集 from numpy import where from sklearn.datasets import make_classification from matplotlib import pyplot # 定义数据集 X, y = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 为每个类别的样本创建散点图 for class_value in range(2): # 获取具有此类别的样本的行索引 row_ix = where(y == class_value) # 创建这些样本的散点图 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 显示绘图 pyplot.show() |
运行示例创建合成聚类数据集,然后创建输入数据的散点图,其中点按类别标签(理想化的簇)着色。
我们可以清楚地看到二维空间中有两个不同的数据组,希望自动聚类算法能够检测到这些分组。
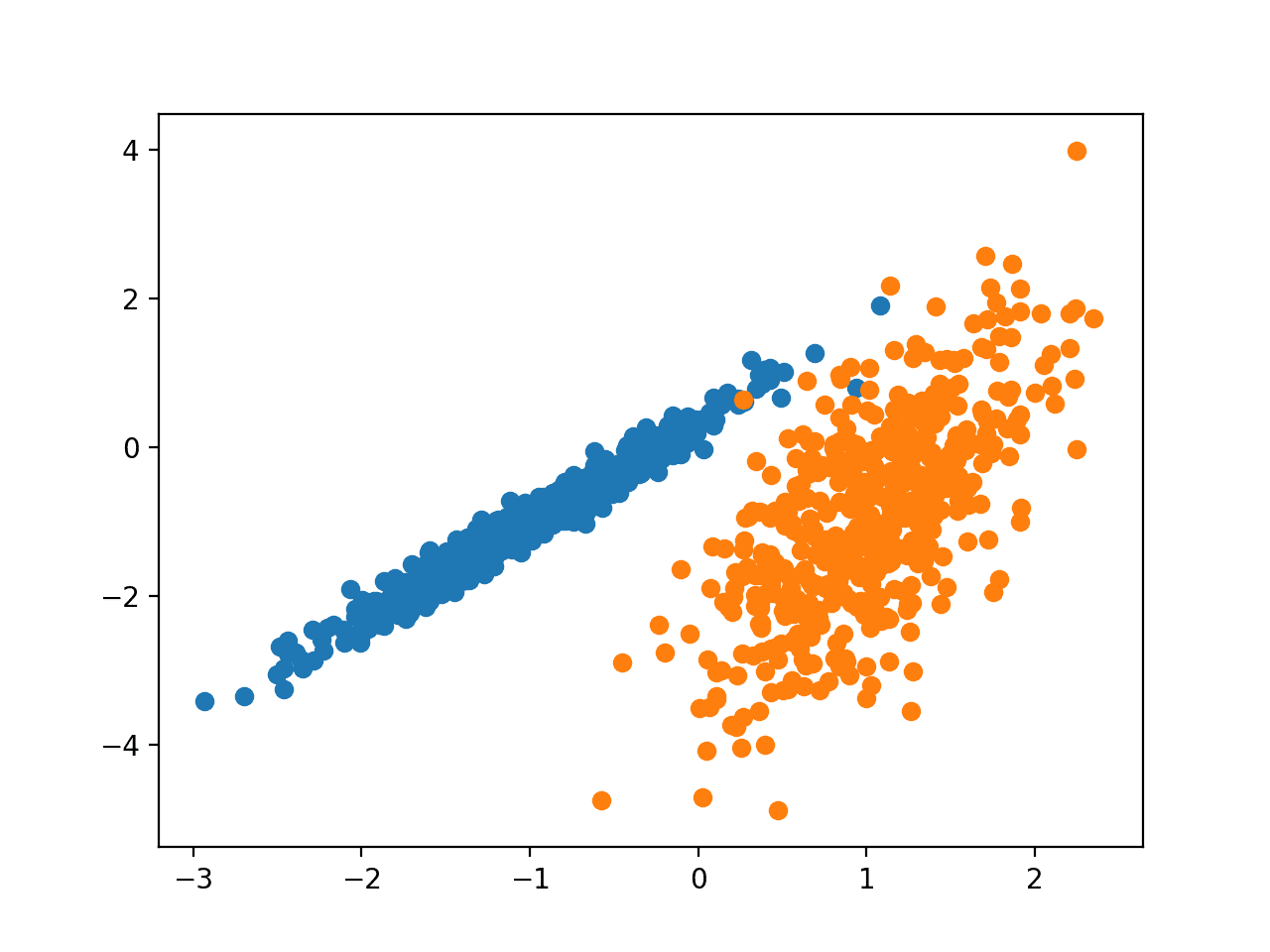
按已知簇着色的合成聚类数据集散点图
接下来,我们可以开始查看将聚类算法应用于此数据集的示例。
我对每种方法都进行了一些最小的调整。
你能为其中一种算法获得更好的结果吗?
在下面的评论中告诉我。
亲和力传播
亲和力传播涉及寻找一组最能概括数据的样本。
我们提出了一种称为“亲和力传播”的方法,该方法以数据点之间的相似性度量作为输入。数据点之间会交换实值消息,直到逐渐出现一组高质量的样本和相应的簇。
— Clustering by Passing Messages Between Data Points, 2007。
该技术在论文中有所描述
它通过 AffinityPropagation 类实现,需要调整的主要配置是“damping”(阻尼)设置在 0.5 到 1 之间,以及可能的“preference”(偏好)。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 亲和力传播聚类 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import AffinityPropagation from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = AffinityPropagation(damping=0.9) # 拟合模型 model.fit(X) # 为每个示例分配一个簇 yhat = model.predict(X) # 检索唯一簇 clusters = unique(yhat) # 为每个簇的样本创建散点图 for cluster in clusters: # 获取此簇的样本行索引 row_ix = where(yhat == cluster) # 创建这些样本的散点图 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 显示绘图 pyplot.show() |
运行示例会在训练数据集上拟合模型,并为数据集中的每个示例预测一个簇。然后创建一个散点图,其中点按其分配的簇着色。
在这种情况下,我未能获得良好结果。
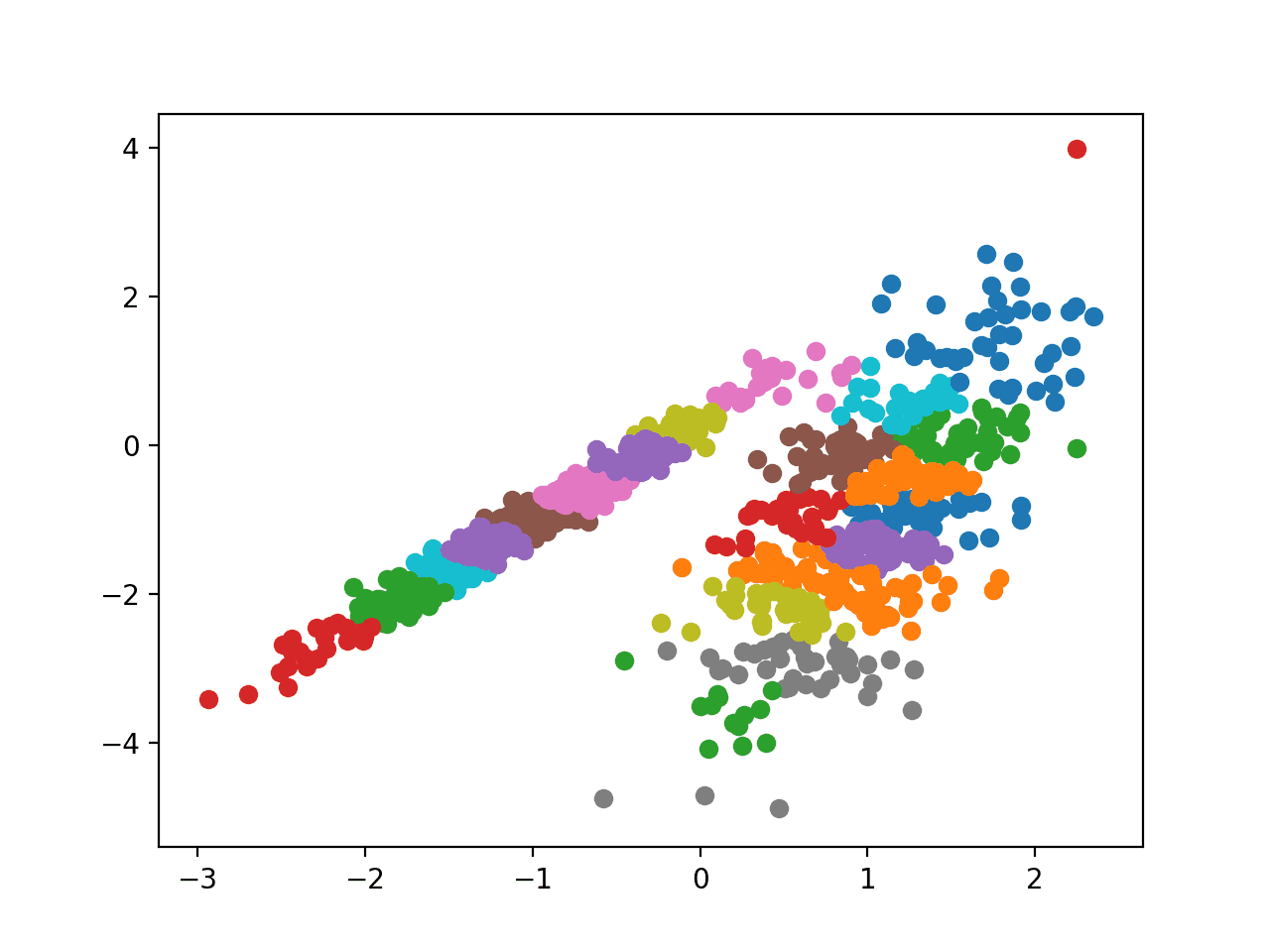
使用亲和力传播识别的簇的数据集散点图
凝聚聚类
凝聚聚类涉及合并示例,直到达到所需的簇数。
它是更广泛的层次聚类方法的一部分,您可以在此处了解更多信息
它通过 AgglomerativeClustering 类实现,需要调整的主要配置是“n_clusters”(簇数)设置,即数据中簇数量的估计值,例如 2。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 凝聚聚类 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import AgglomerativeClustering from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = AgglomerativeClustering(n_clusters=2) # 拟合模型并预测簇 yhat = model.fit_predict(X) # 检索唯一簇 clusters = unique(yhat) # 为每个簇的样本创建散点图 for cluster in clusters: # 获取此簇的样本行索引 row_ix = where(yhat == cluster) # 创建这些样本的散点图 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 显示绘图 pyplot.show() |
运行示例会在训练数据集上拟合模型,并为数据集中的每个示例预测一个簇。然后创建一个散点图,其中点按其分配的簇着色。
在这种情况下,可以找到合理的群组。
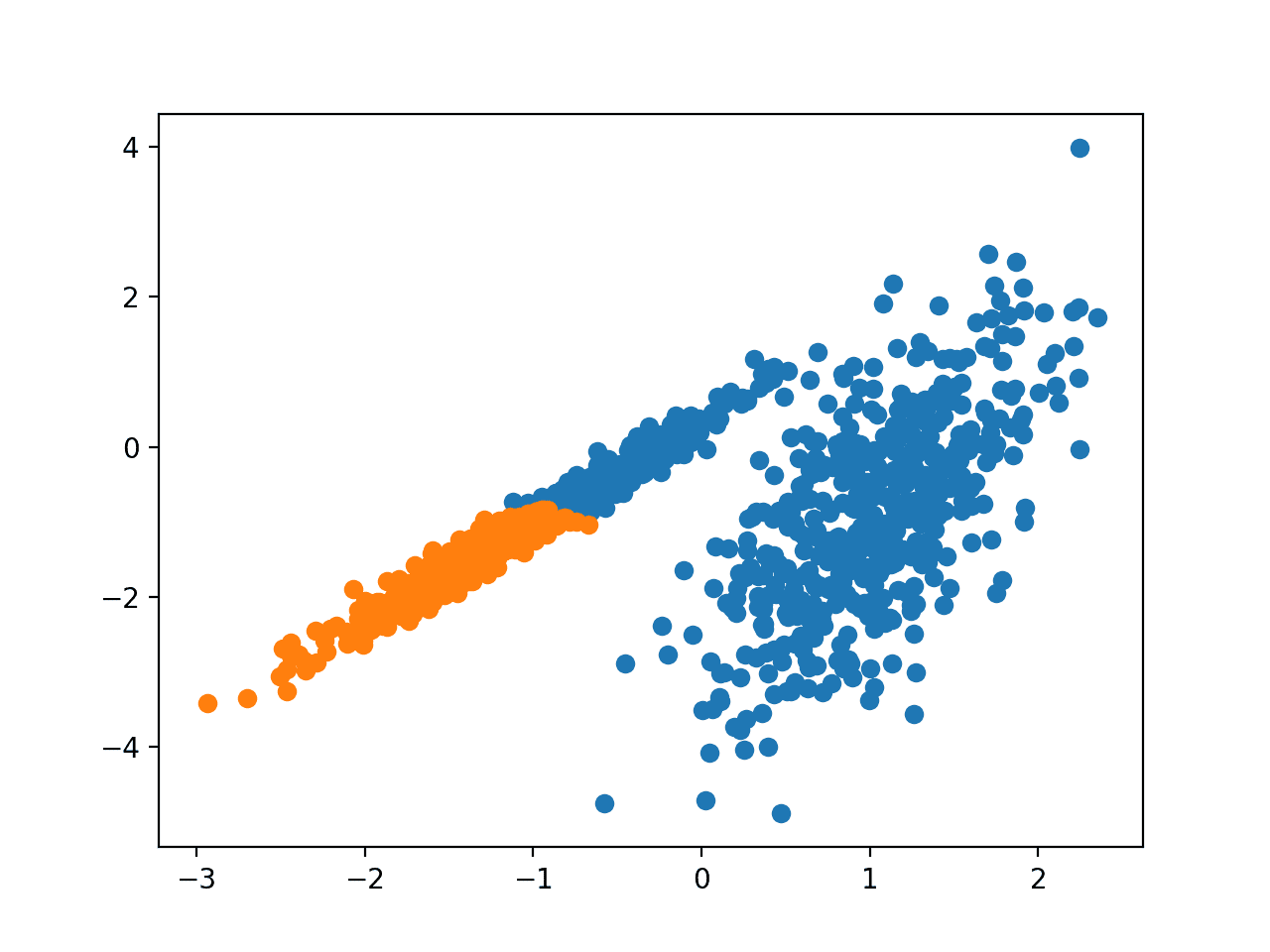
使用凝聚聚类识别的簇的数据集散点图
BIRCH
BIRCH 聚类(BIRCH 是 Balanced Iterative Reducing and Clustering using
Hierarchies 的缩写)涉及构建一个从中提取簇质心的树状结构。
BIRCH 以增量和动态方式对输入的多元度量数据点进行聚类,以尝试在可用资源(即可用内存和时间限制)下产生最佳质量的聚类。
— BIRCH: An efficient data clustering method for large databases, 1996。
该技术在论文中有所描述
- BIRCH: 一种用于大型数据库的高效数据聚类方法, 1996.
它通过 Birch 类实现,需要调整的主要配置是“threshold”(阈值)和“n_clusters”(簇数)超参数,后者提供了簇数量的估计。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# birch 聚类 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import Birch from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = Birch(threshold=0.01, n_clusters=2) # 拟合模型 model.fit(X) # 为每个示例分配一个簇 yhat = model.predict(X) # 检索唯一簇 clusters = unique(yhat) # 为每个簇的样本创建散点图 for cluster in clusters: # 获取此簇的样本行索引 row_ix = where(yhat == cluster) # 创建这些样本的散点图 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 显示绘图 pyplot.show() |
运行示例会在训练数据集上拟合模型,并为数据集中的每个示例预测一个簇。然后创建一个散点图,其中点按其分配的簇着色。
在这种情况下,找到了出色的群组。
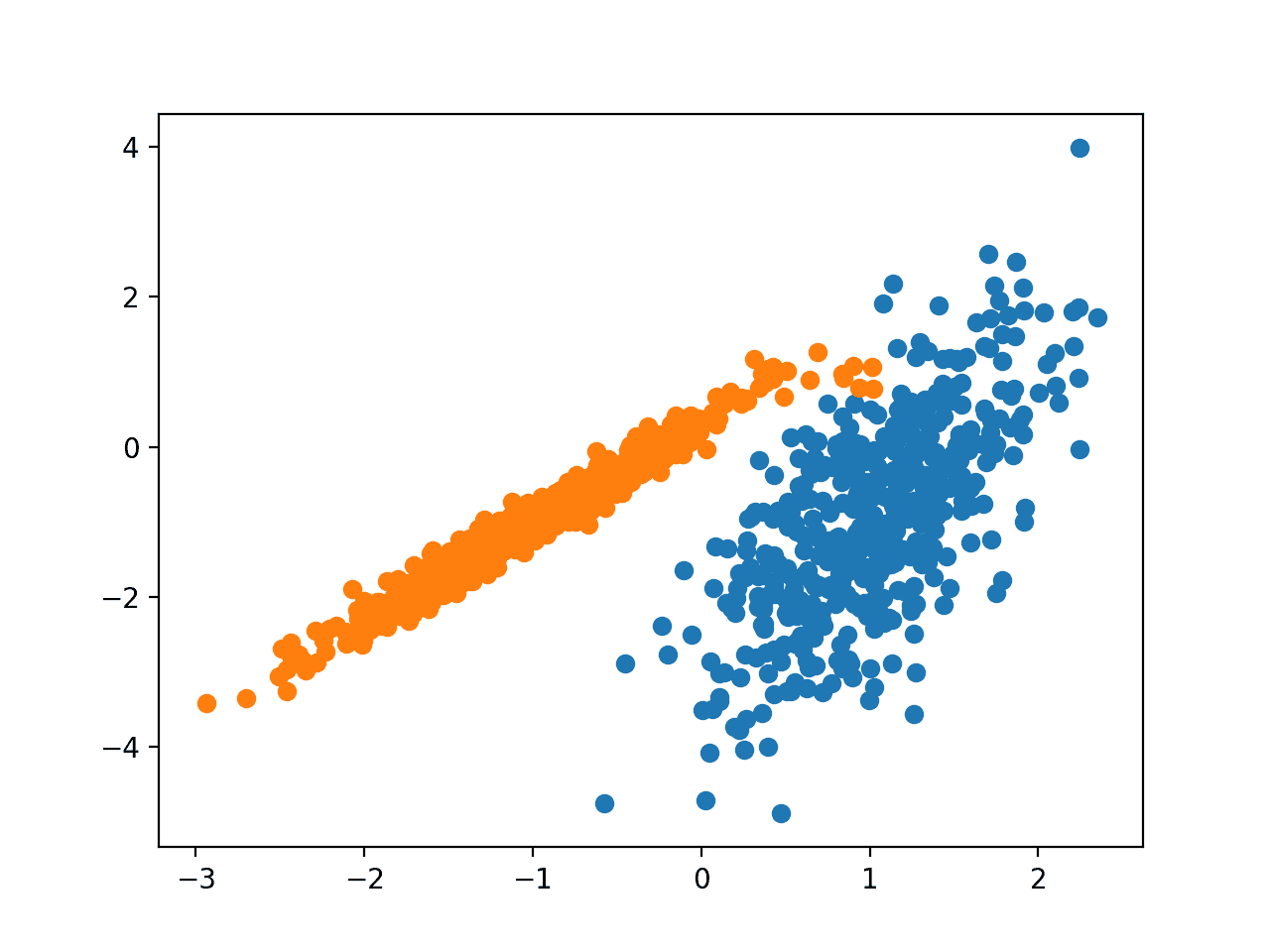
使用 BIRCH 聚类识别的簇的数据集散点图
DBSCAN
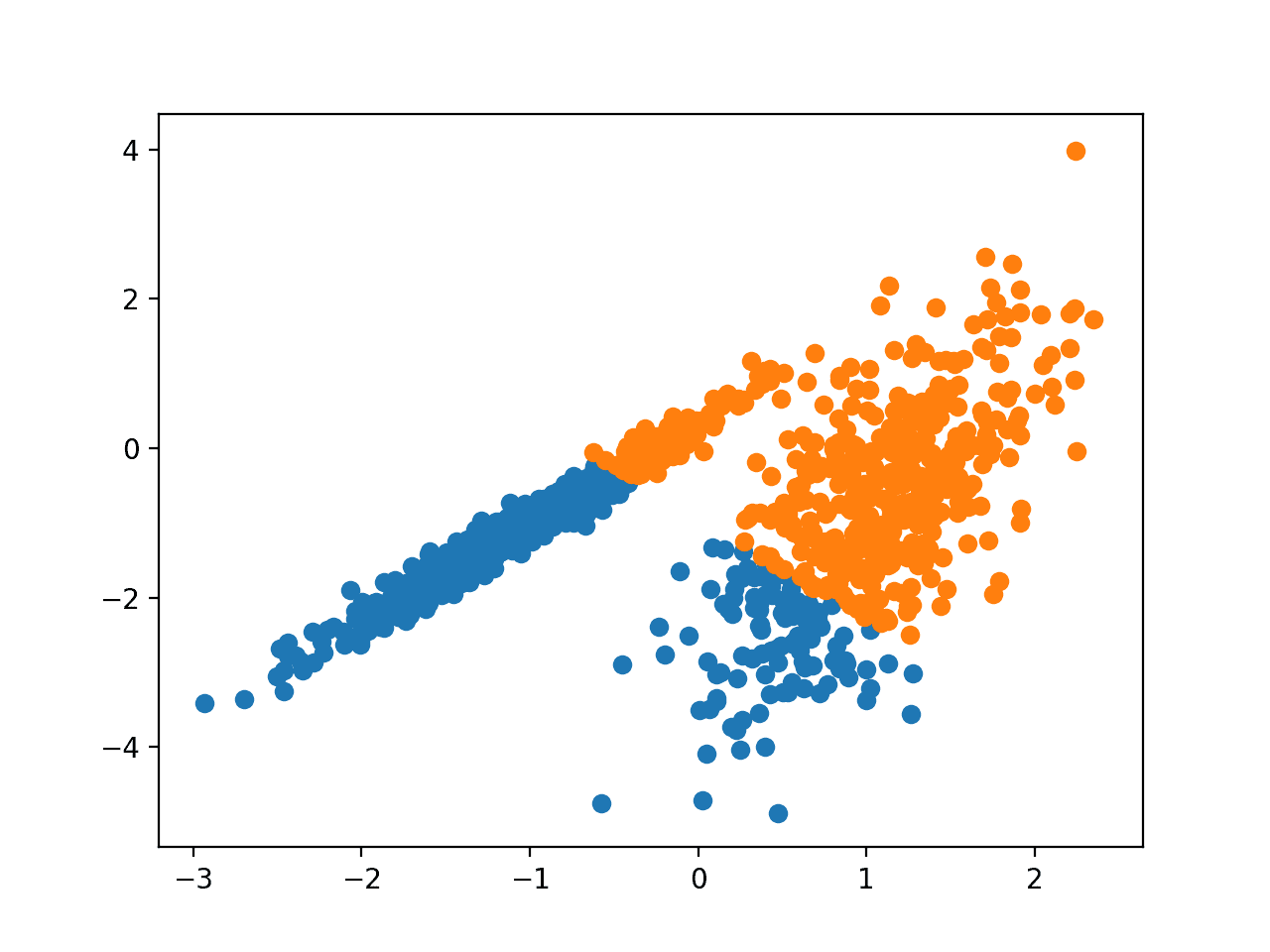
DBSCAN 聚类(DBSCAN 是 Density-Based Spatial Clustering of Applications with Noise 的缩写)涉及在领域中查找高密度区域,并围绕这些区域扩展特征空间作为簇。
… 我们提出了一种新的聚类算法 DBSCAN,它依赖于密度概念的聚类,该算法旨在发现任意形状的簇。DBSCAN 仅需要一个输入参数,并支持用户确定其适当的值。
— A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise, 1996。
该技术在论文中有所描述
它通过 DBSCAN 类实现,需要调整的主要配置是“eps”(epsilon)和“min_samples”(最小样本数)超参数。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# dbscan 聚类 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import DBSCAN from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = DBSCAN(eps=0.30, min_samples=9) # 拟合模型并预测簇 yhat = model.fit_predict(X) # 检索唯一簇 clusters = unique(yhat) # 为每个簇的样本创建散点图 for cluster in clusters: # 获取此簇的样本行索引 row_ix = where(yhat == cluster) # 创建这些样本的散点图 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 显示绘图 pyplot.show() |
运行示例会在训练数据集上拟合模型,并为数据集中的每个示例预测一个簇。然后创建一个散点图,其中点按其分配的簇着色。
在这种情况下,可以找到合理的群组,尽管需要更多的调整。
使用 DBSCAN 聚类识别的簇的数据集散点图
K-Means
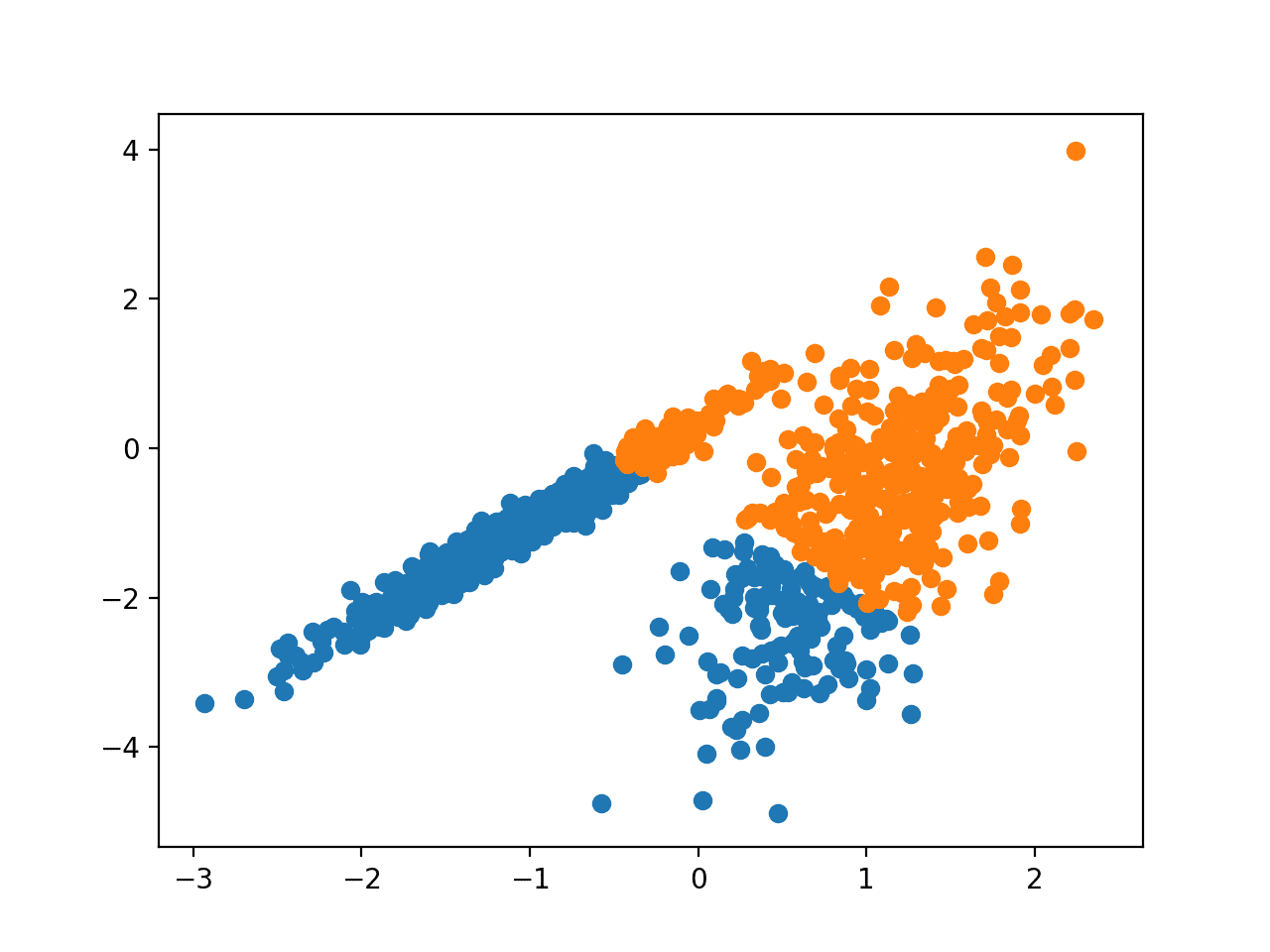
K-Means 聚类可能是最广为人知的聚类算法,它涉及将示例分配给簇,以最小化每个簇内的方差。
本文的主要目的是描述一种根据样本将 N 维总体划分为 k 个集合的过程。该过程称为“k-means”,在类内方差方面似乎能得到合理有效的划分。
— Some methods for classification and analysis of multivariate observations, 1967。
该技术在此处进行了描述
它通过 KMeans 类实现,需要调整的主要配置是“n_clusters”(簇数)超参数,设置为数据中簇数量的估计值。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# k-means 聚类 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import KMeans from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = KMeans(n_clusters=2) # 拟合模型 model.fit(X) # 为每个示例分配一个簇 yhat = model.predict(X) # 检索唯一簇 clusters = unique(yhat) # 为每个簇的样本创建散点图 for cluster in clusters: # 获取此簇的样本行索引 row_ix = where(yhat == cluster) # 创建这些样本的散点图 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 显示绘图 pyplot.show() |
运行示例会在训练数据集上拟合模型,并为数据集中的每个示例预测一个簇。然后创建一个散点图,其中点按其分配的簇着色。
在这种情况下,可以找到合理的群组,尽管每个维度中不相等的方差使得该方法不太适合此数据集。
使用 K-Means 聚类识别的簇的数据集散点图
Mini-Batch K-Means
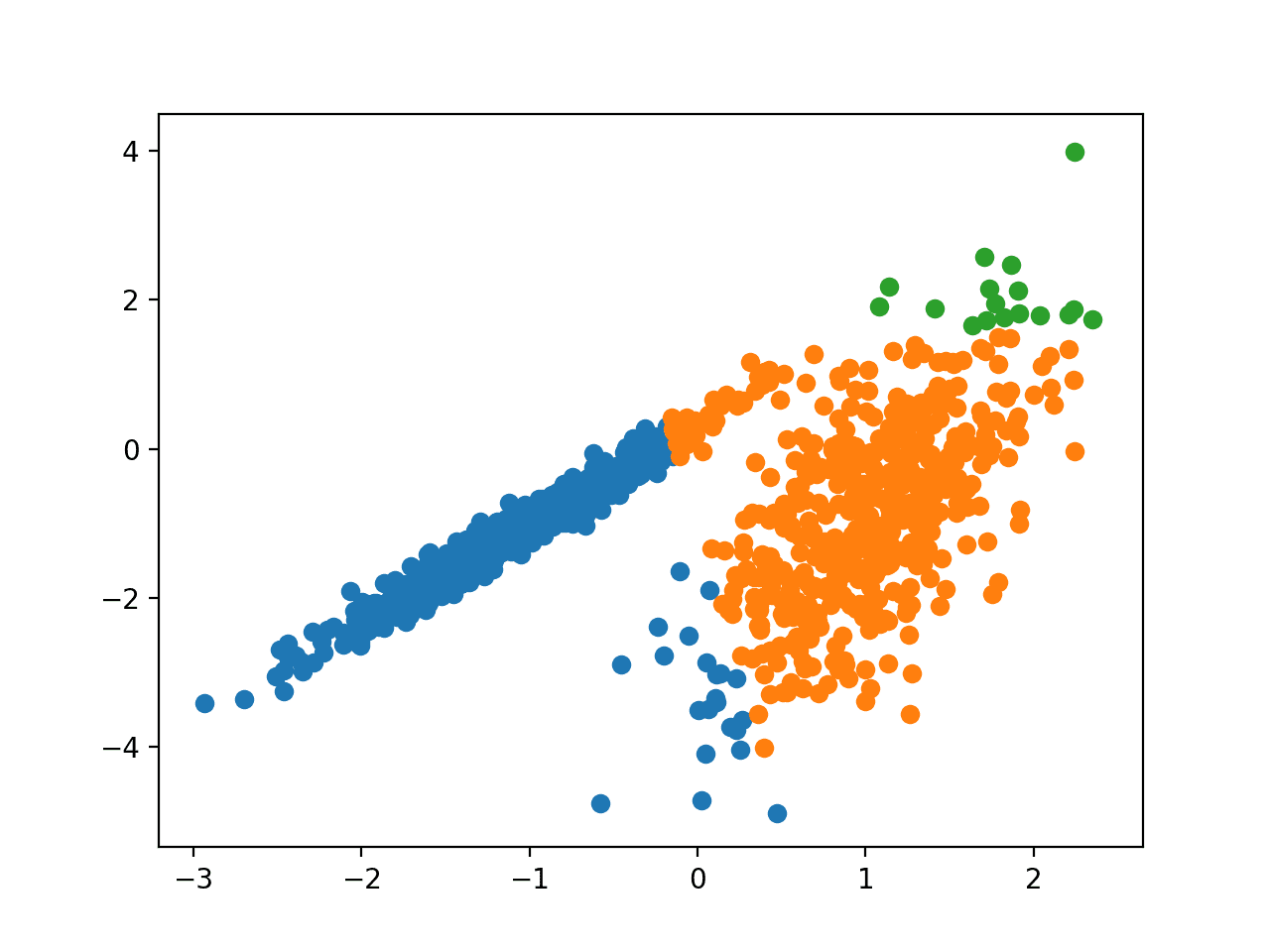
Mini-Batch K-Means 是 k-means 的一个修改版本,它使用样本的 mini-batch 而不是整个数据集来更新簇质心,这可以使其在大数据集上运行更快,并且可能对统计噪声更具鲁棒性。
… 我们提出了使用 mini-batch 优化进行 k-means 聚类。与经典的 batch 算法相比,这可以降低几个数量级的计算成本,同时产生比在线随机梯度下降明显更好的解决方案。
— Web-Scale K-Means Clustering, 2010。
该技术在论文中有所描述
- Web-Scale K-Means 聚类, 2010.
它通过 MiniBatchKMeans 类实现,需要调整的主要配置是“n_clusters”(簇数)超参数,设置为数据中簇数量的估计值。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# mini-batch k-means 聚类 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import MiniBatchKMeans from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = MiniBatchKMeans(n_clusters=2) # 拟合模型 model.fit(X) # 为每个示例分配一个簇 yhat = model.predict(X) # 检索唯一簇 clusters = unique(yhat) # 为每个簇的样本创建散点图 for cluster in clusters: # 获取此簇的样本行索引 row_ix = where(yhat == cluster) # 创建这些样本的散点图 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 显示绘图 pyplot.show() |
运行示例会在训练数据集上拟合模型,并为数据集中的每个示例预测一个簇。然后创建一个散点图,其中点按其分配的簇着色。
在这种情况下,找到了与标准 k-means 算法等效的结果。
使用 Mini-Batch K-Means 聚类识别的簇的数据集散点图
Mean Shift
Mean shift 聚类涉及根据特征空间中的示例密度来查找和调整质心。
我们证明对于离散数据,递归均值漂移过程收敛到底层密度函数的最近固定点,从而证明了其在检测密度模式中的效用。
— Mean Shift: A robust approach toward feature space analysis, 2002。
该技术在论文中有所描述
- Mean Shift:一种强大的特征空间分析方法, 2002.
它通过 MeanShift 类实现,需要调整的主要配置是“bandwidth”(带宽)超参数。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# mean shift 聚类 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import MeanShift from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = MeanShift() # 拟合模型并预测簇 yhat = model.fit_predict(X) # 检索唯一簇 clusters = unique(yhat) # 为每个簇的样本创建散点图 for cluster in clusters: # 获取此簇的样本行索引 row_ix = where(yhat == cluster) # 创建这些样本的散点图 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 显示绘图 pyplot.show() |
运行示例会在训练数据集上拟合模型,并为数据集中的每个示例预测一个簇。然后创建一个散点图,其中点按其分配的簇着色。
在这种情况下,在数据中找到了合理的簇集。
使用 Mean Shift 聚类识别的簇的数据集散点图
OPTICS
OPTICS 聚类(OPTICS 是 Ordering Points To Identify the Clustering Structure 的缩写)是上述 DBSCAN 的修改版本。
我们引入了一种新的聚类分析算法,该算法不显式生成数据集的聚类;而是创建一个增强的数据库排序,代表其基于密度的聚类结构。这种簇排序包含与广泛参数设置相对应的基于密度的聚类等效的信息。
— OPTICS: ordering points to identify the clustering structure, 1999。
该技术在论文中有所描述
- OPTICS:对点进行排序以识别聚类结构, 1999.
它通过 OPTICS 类实现,需要调整的主要配置是“eps”(epsilon)和“min_samples”(最小样本数)超参数。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# optics 聚类 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import OPTICS from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = OPTICS(eps=0.8, min_samples=10) # 拟合模型并预测簇 yhat = model.fit_predict(X) # 检索唯一簇 clusters = unique(yhat) # 为每个簇的样本创建散点图 for cluster in clusters: # 获取此簇的样本行索引 row_ix = where(yhat == cluster) # 创建这些样本的散点图 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 显示绘图 pyplot.show() |
运行示例会在训练数据集上拟合模型,并为数据集中的每个示例预测一个簇。然后创建一个散点图,其中点按其分配的簇着色。
在这种情况下,我未能在此数据集上获得合理的结果。
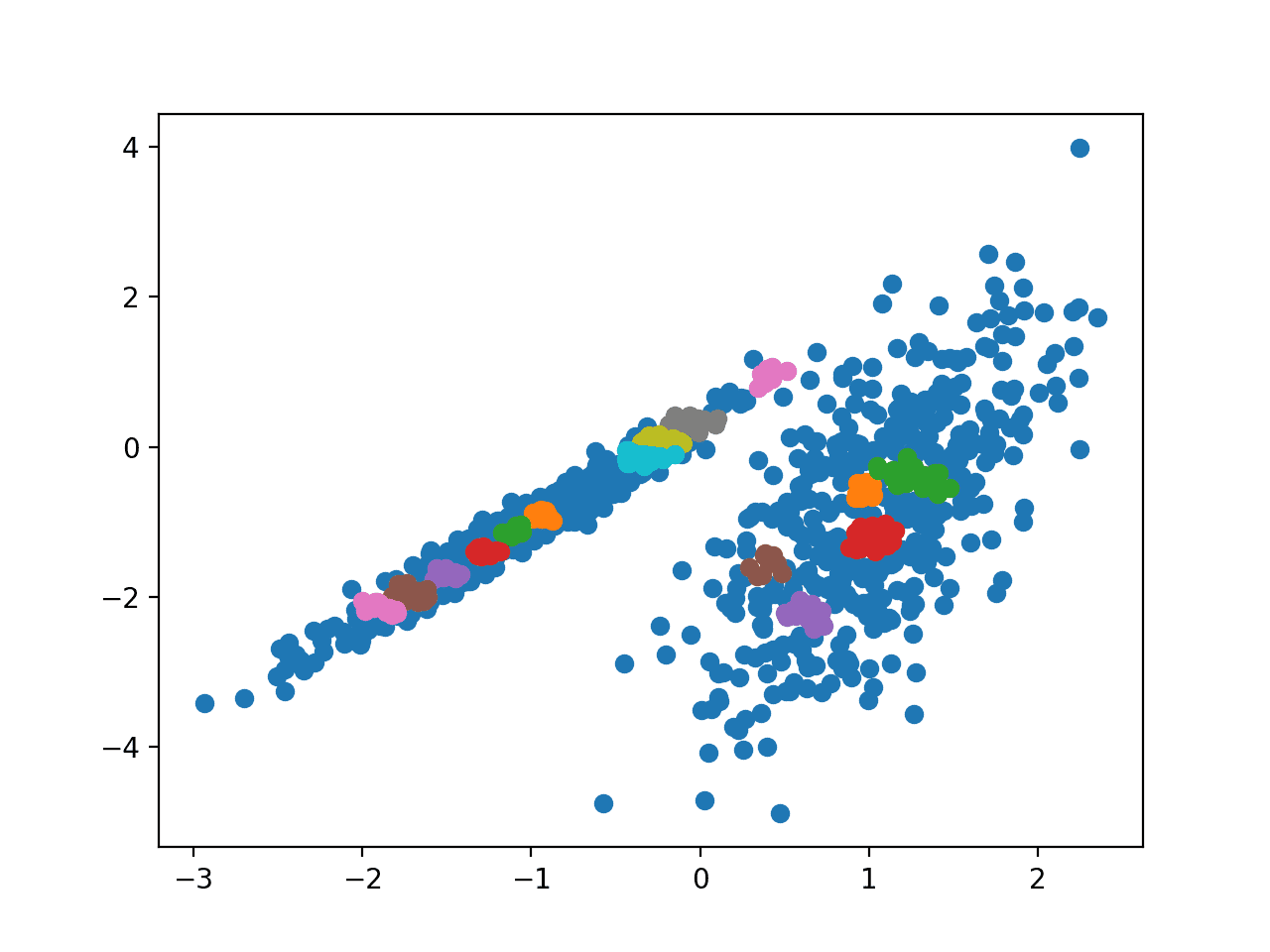
使用 OPTICS 聚类识别的簇的数据集散点图
谱聚类
谱聚类是一类通用的聚类方法,源自线性代数。
一个有前途的替代方法最近在许多领域出现,那就是使用谱方法进行聚类。在这里,人们使用从点之间距离派生的矩阵的顶部特征向量。
— On Spectral Clustering: Analysis and an algorithm, 2002。
该技术在论文中有所描述
- 关于谱聚类:分析与算法, 2002.
它通过 SpectralClustering 类实现,主要的谱聚类是一类通用的聚类方法,源自线性代数。需要调整的是“n_clusters”(簇数)超参数,用于指定数据中估计的簇数量。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 谱聚类 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import SpectralClustering from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = SpectralClustering(n_clusters=2) # 拟合模型并预测簇 yhat = model.fit_predict(X) # 检索唯一簇 clusters = unique(yhat) # 为每个簇的样本创建散点图 for cluster in clusters: # 获取此簇的样本行索引 row_ix = where(yhat == cluster) # 创建这些样本的散点图 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 显示绘图 pyplot.show() |
运行示例会在训练数据集上拟合模型,并为数据集中的每个示例预测一个簇。然后创建一个散点图,其中点按其分配的簇着色。
在这种情况下,找到了合理的簇。
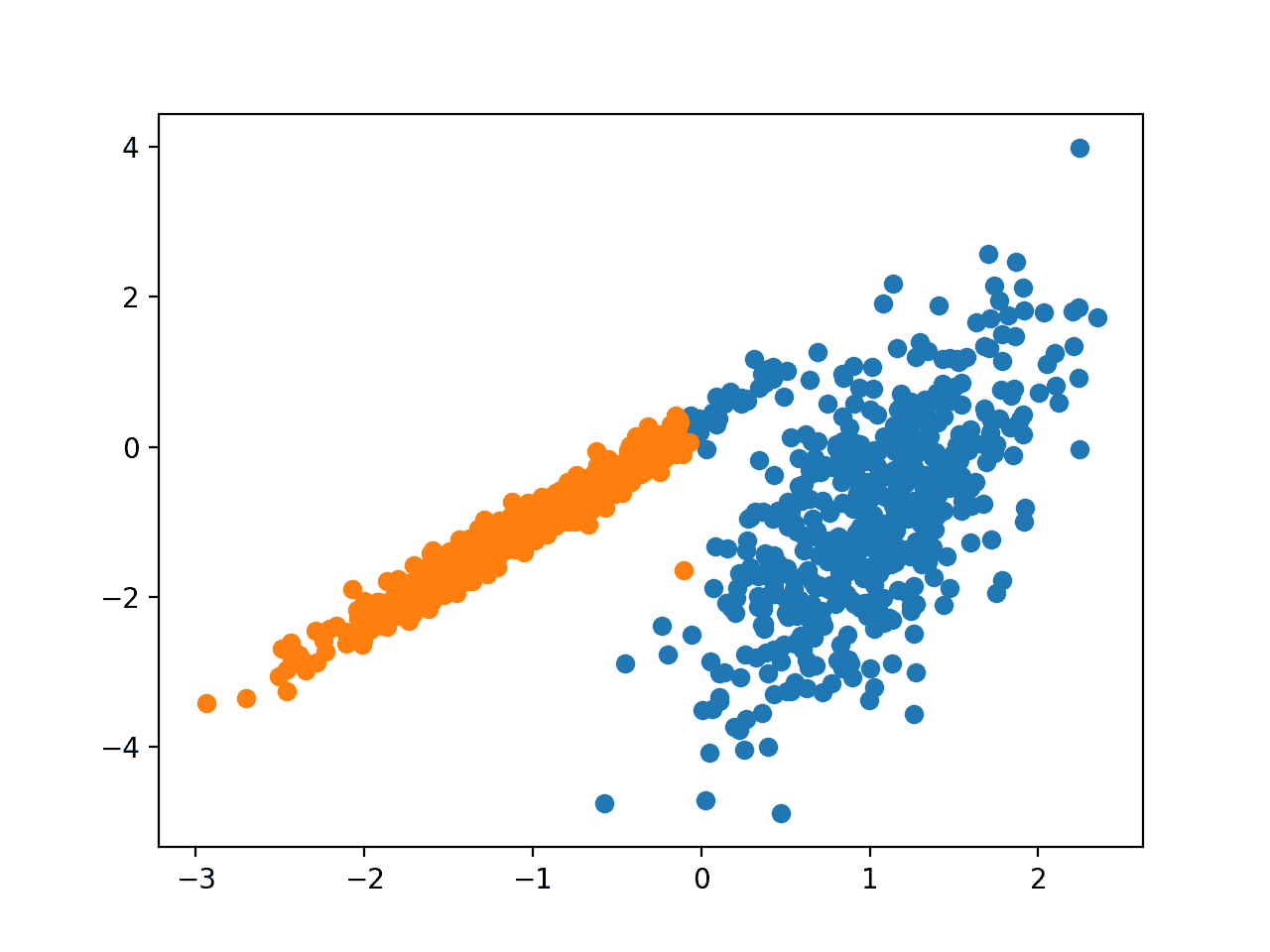
使用 Spectra Clustering 聚类识别的簇的数据集散点图
高斯混合模型
正如其名称所示,高斯混合模型用高斯概率分布的混合来总结多元概率密度函数。
有关该模型的更多信息,请参阅
它通过 GaussianMixture 类实现,需要调整的主要配置是“n_components”(分量数)超参数,用于指定数据中估计的簇数量。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 高斯混合聚类 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.mixture import GaussianMixture from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = GaussianMixture(n_components=2) # 拟合模型 model.fit(X) # 为每个示例分配一个簇 yhat = model.predict(X) # 检索唯一簇 clusters = unique(yhat) # 为每个簇的样本创建散点图 for cluster in clusters: # 获取此簇的样本行索引 row_ix = where(yhat == cluster) # 创建这些样本的散点图 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 显示绘图 pyplot.show() |
运行示例会在训练数据集上拟合模型,并为数据集中的每个示例预测一个簇。然后创建一个散点图,其中点按其分配的簇着色。
在这种情况下,我们可以看到簇被完美地识别出来。这并不奇怪,因为数据集是通过高斯混合生成的。
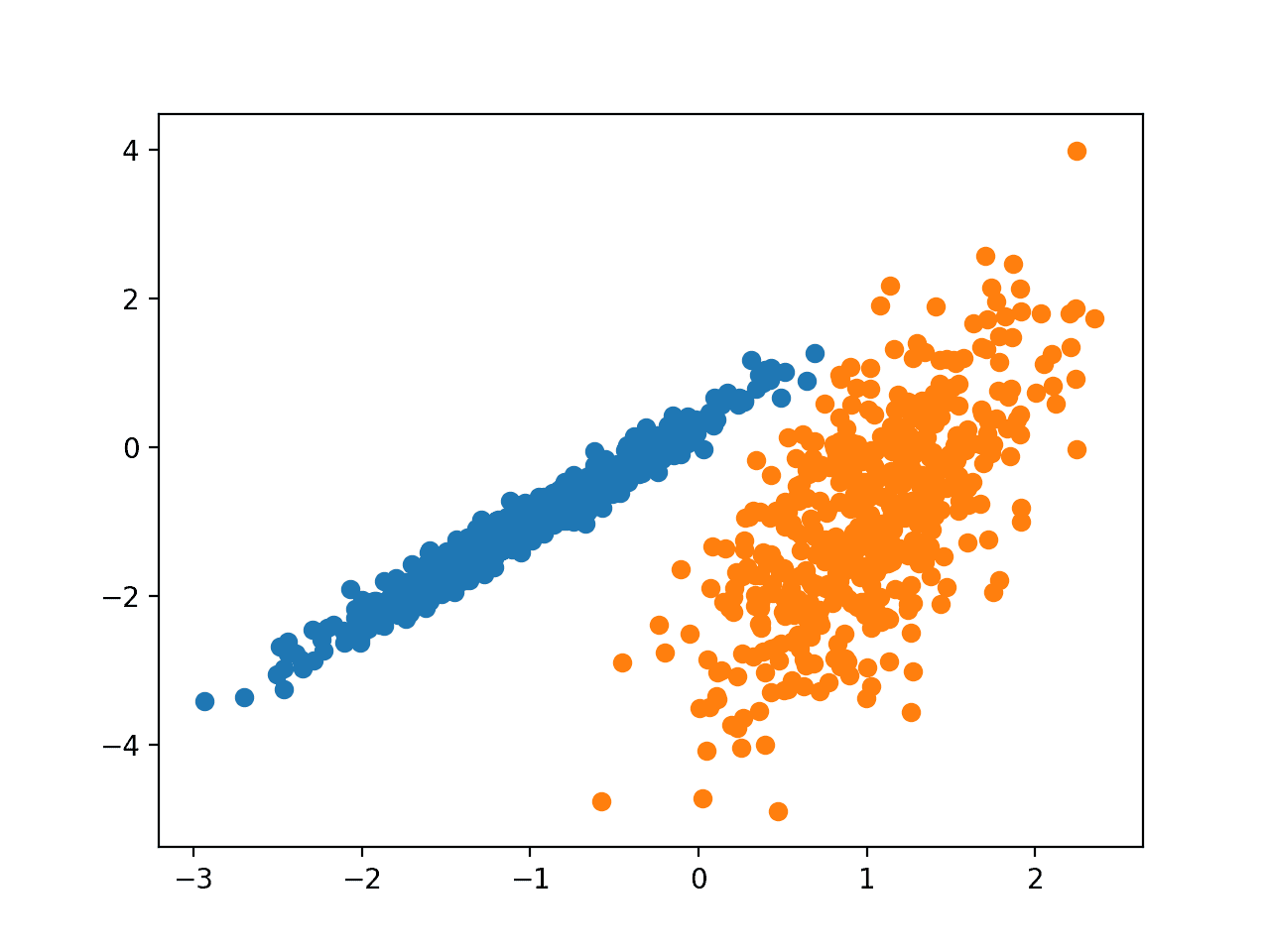
使用高斯混合聚类识别的簇的数据集散点图
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- Clustering by Passing Messages Between Data Points, 2007.
- BIRCH: 一种用于大型数据库的高效数据聚类方法, 1996.
- 一种用于在大型空间数据库中发现具有噪声的簇的基于密度的算法, 1996.
- 一些多元观测值的分类和分析方法, 1967.
- Web-Scale K-Means 聚类, 2010.
- Mean Shift:一种强大的特征空间分析方法, 2002.
- 关于谱聚类:分析与算法, 2002.
书籍
- 《数据挖掘:实用机器学习工具与技术》(Data Mining: Practical Machine Learning Tools and Techniques), 2016.
- 《统计学习要素:数据挖掘、推理和预测》, 2016.
- 机器学习:概率视角, 2012.
API
文章
总结
在本教程中,您学习了如何在 Python 中拟合和使用顶级的聚类算法。
具体来说,你学到了:
- 聚类是在特征空间中寻找自然群组的无监督问题。
- 有许多不同的聚类算法,没有一种方法适用于所有数据集。
- 如何使用 scikit-learn 机器学习库在 Python 中实现、拟合和使用顶级的聚类算法。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
发现 Python 中的快速机器学习!

在几分钟内开发您自己的模型
...只需几行 scikit-learn 代码
在我的新电子书中学习如何操作
精通 Python 机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、建模、调优等等...
最终将机器学习带入
您自己的项目
跳过学术理论。只看结果。
")





一如既往,非常感谢!
不客气,Richard!
对于 K 均值,颜色是如何排序的?例如,如果 K = 1 则是蓝色,如果 K = 2 则是橙色,如果 K = 3 则是绿色,那么 K = 4 和 K = 5 的颜色是什么?(我做了 k 均值,k = 5)。非常感谢!
你好 DK…你可能会发现以下资源很有启发性
https://towardsdatascience.com/understanding-k-means-clustering-in-machine-learning-6a6e67336aa1
感谢您这篇极具启发性的博文 Jason。
不客气,Paul!
好博文
谢谢!
优秀的教程。感谢辛勤工作。
谢谢。
亲爱的 Jason,
感谢您对聚类的快速而清晰的介绍。
我想知道是否有方法选择一个聚类算法而不是另一个算法来处理聚类问题。
我想说这取决于问题。也许数据集可视化有助于决定选择哪种算法。但是,我想知道在选择算法时是否有任何建议需要牢记。
此外
1- 如何可视化高维数据以理解其后台结构?(我正在考虑使用 PCA 将维度降低到 2D/3D,然后在此新表示中绘制原始轴,但这仍然非常困难)。
2- 如何选择不同数据集大小(从小到大)的算法?
此致,
Marco
不客气。
通常使用对您的项目有意义的性能指标并进行优化。
https://scikit-learn.cn/stable/modules/classes.html#clustering-metrics
1- 如何可视化高维数据以理解其后台结构?(我正在考虑使用 PCA 将维度降低到 2D/3D,然后在此新表示中绘制原始轴,但这仍然非常困难)。
答:请尝试使用seaborn Python包来可视化高维数据(最多7维)。这个包非常高效。当然,您也可以先降低维度,然后与seaborn一起使用。
2- 如何选择不同数据集大小(从小到大)的算法?
答:越大越好🙂 然而,您可能需要一位领域专家来评估结果。因为,尽管您可以认为某个结果在视觉上是完美的(如上所述),但它不一定是最好的。以OPTICS的视觉结果为例(见上文)。也许一些癌组织隐藏在一个大的部分中?
是的,请看流形学习方法
https://scikit-learn.cn/stable/modules/manifold.html
通常算法的复杂度会起作用,例如,为大型数据集选择更快的算法,或者使用数据样本而不是全部数据。
非常感谢两位慷慨的回答。我非常感激。
关于回答
1- 我尝试过用不同的方式使用seaborn来可视化高维数据。我发现pair plot对于理解每个特征的分布以及每对特征的分布都很有用。您有其他建议吗?
流形方法是我还没有使用的,因为我对它背后的理论不太了解(也许是下一篇文章的建议;))。不过,我将尝试使用t-SNE和相当新的UMAP。
2- 谢谢您的提示。我正在处理的数据集是完全无监督的。想法是基于聚类结果进行一些评估。这意味着任何聚类算法都可以用于第一次聚类。与我一起工作的专家未能提供更多关于数据结构的信息(尽管最终决定将是二元的,但我们正在分析的项可以具有不同的特征结构——这就是我使用大于2个簇进行聚类的原因)。最后,我决定应用GMM,为每个簇选择一组项,并要求对这些项进行评估。一旦有了这些评估,我将尝试基于这些有限的标签来评估簇,并优化算法和超参数。
真的非常感谢您的支持
我喜欢pca、sammons mapping、som、tsne以及其他一些方法。
祝你好运!
刚看到这篇博文,想起了你之前的一个回复
https://machinelearning.org.cn/supervised-and-unsupervised-machine-learning-algorithms/#comment-409461
一如既往地感谢您。
太棒了!
如何将代码应用于我的数据而不是make_classification数据集。我需要做哪些更改来定义我的x、y,以及for循环中的哪些更改?我有三列(前两列中有两个变量x、y,第三列中有一个变量(Z),我想用Z值来着色x、y值)
从CSV文件中加载数据
https://machinelearning.org.cn/load-machine-learning-data-python/
非常感谢。
我已应用于我的数据
https://www.kaggle.com/abdulmeral/10-models-for-clustering
干得好!
内容丰富且信息量大的帖子
谢谢!
演示得很好。谢谢
谢谢!
Jason,这是一篇关于聚类算法的图文并茂的好文章。
我想知道您是否可以揭示这些算法背后的数学原理。了解它们的内部机制会很棒。
谢谢。
是的,请参阅每种方法的引用论文。
您是否考虑过潜在类别分析 (LCA)。我知道它存在已久,但不那么流行。谢谢!
没有,那是什么?
我看到它在营销分析的客户细分方面被引用为最先进的技术(mike grigsby),但没有scitkit的实现
感谢分享。
潜在类别分析(LCA)是一种用于聚类分类数据的模型。
数据。
谢谢你告诉我 Jose,我不太熟悉它。
谢谢。
不客气。
再次感谢 Jason 的精彩帖子。
只是一个快速的问题。如果我们想找到具有相似行为的消费品,例如,在护肤品领域。有超过200个SKU,我们想根据销售额、支出的折扣、渠道、地区等来找到产品,我们该如何应用这些聚类算法?它们可以应用吗?因为可视化聚类会很困难,而且,如何设置具有多个属性的任务,其中一些是分类的?
评估聚类非常困难——这让我不喜欢整个主题,因为它变得主观。
您可以使用指标
https://scikit-learn.cn/stable/modules/classes.html#clustering-metrics
或使用主题专家来审查聚类结果。
您应该看看HDBScan:https://hdbscan.readthedocs.io/en/latest/how_hdbscan_works.html
感谢分享!
你好,Jason。
我有一个包含50000个向量,每个向量有512个维度的数据集。哪种方法是最佳且最快的聚类方法?
感谢您提供有趣的帖子。
每种方法都有不同的权衡。或许可以直接比较几种方法。
谢谢您如此详细的介绍,我计划仔细研究!不过目前,我正在寻找关于如何处理拥有约2000个观测值和30个二元(0/1)特征的数据集的最佳方法的说明,并且想要确定最佳的聚类数量。如果您有什么建议,我将不胜感激!
也许可以尝试一套方法,看看哪种方法产生的聚类结果符合您的预期。
大多数聚类算法都需要指定“n_clusters”参数或类似的阈值。在处理2D/3D数据时,可以通过视觉来监督这个参数,但在更高维度上可能会有问题。您知道如何处理我们不知道预期有多少个簇的情况吗?
此致!
不知道,抱歉。方法的主观性让我非常不喜欢在实践中使用聚类。
您好,先生,
我正在尝试找到具有不同时间尺度的hmm的序列聚类。
我正在尝试实现这篇论文——https://papers.nips.cc/paper/1217-clustering-sequences-with-hidden-markov-models.pdf
我在2.1节有疑问,请帮我该如何进行??
抱歉,我帮不了你。也许可以尝试在cross-validated上发帖。
感谢如此清晰的文章,介绍了聚类算法…
不客气!
您讨论了少量的无监督方法,例如聚类。
不,我倾向于关注监督学习。
您能帮我处理基于顶点(基于Jaccard相似性)的聚类吗?
感谢您的建议,也许我将来会写有关它的文章。
嗨,
我需要关于在kmeans.fit()中使用哪个X作为输入的帮助。我想生成K-Means聚类的3D图,使用前三个主成分,因为原始特征空间是高维的(n个特征=34!)。这是我的图
https://github.com/tuttoaposto/OpenSource/blob/master/Derm_Clustering/Derm_3D_KMeans.png
下面的代码显示了我如何规范化X并将其映射到PC。我应该使用哪个聚类结果,y_kmeans还是y_kmeans_pca?X_pca不是0-1边界。或者我应该先规范化X_pca并使用kmeans.fit_predict(X_pca_normlized)?
代码
X_normalized = MinMaxScaler().fit_transform(X)
pca = PCA(n_components=3).fit(X_normalized)
X_pca = pca.transform(X_normalized)
kmeans = KMeans(n_clusters=6, random_state=0)
# 为每个示例分配一个簇
y_kmeans_pca= kmeans.fit_predict(X_pca)
# 为每个示例分配一个簇
y_kmeans= kmeans.predict(X_normalized)
谢谢!
抱歉,我无法帮助您创建3D图,我没有关于此主题的教程。
我的问题不是关于创建3D图。我的问题是,如果我想可视化高维数据的聚类,应该将哪个X输入应用于kmeans.fit():1) 规范化X值,主成分,还是规范化主成分,因为一些PC的范围是-1到1,有些范围是-2到2。谢谢!
无论您的数据有多少维度,您通常会以相同的方式使用k-means,例如调用model.fit()并将所有输入数据传递给它。
是的,首先对输入数据进行缩放是个好主意,例如规范化或标准化输入。
你好先生,
我想为聚类创建一个新算法,以克服所有算法的缺点,您能指导我吗?
我想创建一个新的算法来实现高效鲁棒的聚类。
这听起来像一个研究项目,我建议您与您的研究导师讨论此事。
非常感谢Jason,很高兴能读到您的文章。对于DBSCAN,它也存在于异常值和异常的识别中,另一方面,它的复杂度随着数据库的增大而增加。您怎么看?
听起来合理。
您能否也分享一些模糊 C 均值聚类的实现?
感谢您的建议。
似乎以下文章的作者试图利用本篇文章的示例代码,但在此过程中添加了一些错误
https://www.freecodecamp.org/news/8-clustering-algorithms-in-machine-learning-that-all-data-scientists-should-know/
很多人抄袭我的帖子。这很糟糕!
谷歌知道这一点,并在搜索结果中严厉惩罚抄袭行为。
感谢这篇评论。非常有用和方便。
不客气。
嗨,Jason,
我需要根据23个不连续的特征对文章进行分组。我该如何显示属于每个簇的文章?
提前感谢。
也许可以对数据进行聚类,然后编写一个for循环和一个if语句来按分配的簇对所有文档进行排序。
你好,
总结得很好🙂 看起来OPTICS的eps值设置得有点低。
谢谢 Erik。
嗨 Jason,好文章。我有一个问题。是否存在一个聚类算法,它根据超参数“每个簇中的点数”来聚类数据?例如,如果我有200个数据点并设置每个簇中的点数为10,模型将给出20个簇,每个簇有10个数据点。如果您能帮我解决这个问题,我将不胜感激。
谢谢。
可能存在,但我现在不确定。也许您可以将上述方法之一配置为这种方式。
嗨 Pouyan,您是否找到了用于此目的的聚类算法?我也在寻找一种好的聚类方法来均匀地聚类我的2D坐标数据。谢谢。
非常感谢 Jason,它非常实用和有用,我已经保存了链接,我相信我还会再次回顾这篇文章。
不客气。
感谢这篇帖子。数据集中点的特征数量很多。每个点都是一个向量,可能包含多达五十个元素。哪种聚类算法最适合这个问题?
不客气。
我们无法知道。我建议测试一套算法,并使用某个指标来评估它们,选择在您的数据集上得分最高的算法。
嗨,Jason,
用于kmeans聚类的数据是否应该进行标准化?或者如果数据集中存在异常值是否可以?你能解释一下为什么标准化重要/不重要吗?或者如果你有教程,你能告诉我吗?谢谢
尝试使用和不使用标准化进行测试,并比较结果,使用最适合您的结果。
尝试在您的数据集上进行异常值移除和不移除的测试,并比较结果,使用最适合您的结果。
关于标准化 (minmaxscaler) 的更多信息
https://machinelearning.org.cn/standardscaler-and-minmaxscaler-transforms-in-python/
嗨,Jason,
非常感谢您为知识传播所做的工作。
我在模式识别方面有问题。我的问题是使用聚类方法来识别引力波时间序列数据的时频表示(声谱图)的模式。模式识别是通过曲线拟合完成的,但我希望通过聚类方法来识别声谱图的趋势或模式。
请解释一下哪种聚类方法最适合?
谢谢。
谢谢你。
抱歉,我没有关于时间序列聚类的教程,但我希望将来能写有关该主题的文章。
我正在考虑为我的项目做kmodes算法。您是否有关于如何使用pickle进行操作和保存的想法?
这可能会帮助您保存模型
https://machinelearning.org.cn/save-load-machine-learning-models-python-scikit-learn/
你好 Jason,
首先感谢您将机器学习普及得如此之好。很高兴能避免从头开始学习数学和理论的负担。
我阅读了很多关于聚类的内容,也利用了不同的方法进行实验。聚类算法是有用且高效的,但问题在于理解定义的聚类特征。我过去常常在雷达图或箱线图上绘制特征来尝试理解,但当遇到大量数据集的特征数量时,这会变得难以理解。
有没有可视化聚类特征重要性的工具?
感谢您的帮助。
有没有工具可以
不客气。
也许您可以使用成对散点图并将点按分配的簇着色?
尊敬的先生/女士:
我正在使用Python语言,并希望在医学数据上应用深度学习算法。然而,我对Python是新手,不知道哪种算法适用于数据聚类。我正在寻找一种不需要输入参数就可以进行聚类数据的算法。如果您能指导我并推荐任何适合此类聚类的算法,我将非常感激。期待尽快收到您的回复。
谢谢,
Hassan
我不确定深度学习是否是聚类的最佳工具。
也许可以尝试几种算法和每种算法的几种配置,看看哪种最适合您的数据集。
你好,先生,
我有两个问题
第一个,我在哪里可以获得不同领域的的数据集?
第二个,我应该计算哪些参数来衡量聚类算法的性能。
我打算在 Python 中实现所有聚类算法,因此我需要大量的数据集,并且我应该计算哪些参数作为每个算法的结果,以便我可以与所有算法的性能进行比较。
抱歉,我不明白你的第一个问题,你能重新表述一下或详细说明一下吗?
这可以帮助您评估聚类算法
https://machinelearning.org.cn/faq/single-faq/how-do-i-evaluate-a-clustering-algorithm
尊敬的先生,
如何衡量聚类算法的性能?应该考虑哪些参数?
好问题,我在这里回答
https://machinelearning.org.cn/faq/single-faq/how-do-i-evaluate-a-clustering-algorithm
model.fit(X)
无法为形状为 (442458, 442458) 且数据类型为 float64 的数组分配 1.42 TiB 内存
请帮忙 🙂
也许少用点数据?
也许在内存更大的机器上运行?
我的电脑有 16 GB 内存,少用数据对我来说不是一个选项。我尝试使用 Dask 库,但没有成功。我会寻找其他方法或升级内存到 64 GB。
顺便说一句,感谢这篇文章。
渐进式加载数据到内存可能是前进的方向。
谢谢建议。我也会试试的。
不客气。
我是 Python 新手。如何将我自己的数据集插入到示例中?
这将帮助您加载数据集
https://machinelearning.org.cn/load-machine-learning-data-python/
感谢您花时间撰写一篇很棒的文章(以及许多其他非常有帮助的文章)。
我有两个问题
-有没有办法对具有约束条件进行聚类?例如,如果我们正在对一起订购的产品进行聚类,是否有办法不允许某些产品属性出现在同一集群中?
-是否可以基于数值字段设置集群最大值(即,集群不能超过 X 金额的销售单位总和(所有产品))?
不客气。
我怀疑两者都可以通过自定义代码实现。我对聚类方面的内容不多,抱歉。
谢谢 Jason
我先试试。
谢谢你的这篇博文?
在获得良好的聚类后,我们如何解释结果?如果只有 2 个维度,那很容易。但是,一旦有 2 个以上,我们如何找出各个集群的特征差异?
例如,
集群 1 – 中位年龄 30,体重 50 公斤,就业,健康
集群 2 – 中位年龄 30,体重 50 公斤,失业,不健康
集群 3 – 中位年龄 55,体重 65 公斤,就业,不健康
聚类后如何梳理这些信息?
我想在降维后解释聚类会更困难,但你是否有任何建议可以帮助解释结果?
谢谢!
这是聚类中的大问题。我觉得这一切都太主观了!
也许这会有帮助。
https://machinelearning.org.cn/faq/single-faq/how-do-i-evaluate-a-clustering-algorithm
令人印象深刻的 Python 聚类算法指南,对于那些想在聚类算法方面获得一些知识的人来说,这是必读的博客
谢谢。
感谢 Jason 先生的这个精彩教程!
不客气。
嗨,Jason,
非常棒的聚类指南。您知道有什么方法可以提取某种特征重要性分数吗?例如,输出哪些特征对于聚类数据很重要?
谢谢!
没有,抱歉。
嗨,Jason!
你的网站救了我(和我的时间)!恭喜!!!
我有一些问题
1) 我只在这里的页面上找到了关于聚类算法的教程。是否有关于无监督学习的教程(+代码)?
2) 如果没有其他教程,我想请你推荐一本关于这方面的书。有关于聚类的吗?如果没有,你能推荐其他类似这个代码片段的书或网站吗?
我将不胜感激!
提前感谢!
索菲亚
这里有一个关于聚类的教程:https://machinelearning.org.cn/clustering-algorithms-with-python/
聚类是进行无监督学习的一种方式。你还对无监督学习的哪些具体主题感兴趣?
如何对图像进行聚类?
这取决于你想做什么,你需要将图像转换成向量,然后根据向量进行聚类。我可以给你一些关于如何做的想法:使用自动编码器来生成这些向量,计算像素的颜色,因此一个 256 灰度图像将产生一个 256 维向量,应用一些图像处理技术,如边缘检测,并将边缘表示为长度和斜率等。
你好,
能否将分类教程中使用的代码(如标准化、PCA 分析等)纳入上述代码?
谢谢你!
为什么不呢?事实上,在应用聚类之前应用 PCA 来转换/降维是相当常见的。
Jason,你好,我有一个问题……
我编写了这些
# Dependencies
import pandas as pd
from numpy import where
from matplotlib import pyplot
# Load Data
names = [“Frequency”,”Comments Count”,”Likes Count”,”Text nwords”]
dataset = pd.read_csv(“Posts.csv”, encoding=”utf-8″, sep=”;”, delimiter=None,
names=names, delim_whitespace=False,
header=0, engine=”python”)
X = dataset.values[:,0:2]
y = dataset.values[:,3]
# Explore Data
print(dataset.shape)
print(dataset.head(10))
print(dataset.describe())
print(dataset.dtypes)
X,y = dataset(n_samples=100, n_features=4, n_informative=4, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 为每个类别的样本创建散点图
for class_value in range(3)
# get row indexes for samples with this class
row_ix = where(y == class_value)
# create scatter of these samples
pyplot.scatter(X[row_ix, 0], X[row_ix, 3])
# 显示绘图
pyplot.show()
我收到此错误
回溯(最近一次调用)
File “C:/Users/USER/pythonProject/main.py”, line 44, in
X,y = dataset(n_samples=100, n_features=4, n_informative=4, n_redundant=0, n_clusters_per_class=1, random_state=4)
TypeError: ‘DataFrame’ object is not callable
有什么想法吗?我该怎么办?
我认为问题出在 #load data.. 如何插入我的数据集?
也许我混淆了 Dataset(作为一个变量)和 Dataset(作为一个函数)。
提前感谢!
索菲亚
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
你哪本书是关于聚类的?
目前还没有,也许将来会有。
谢谢 Jason,感谢您提供的教程。
sklearn 的高斯混合模型每个由距离度量引起的整个集群空间只有一个一维方差变量。但是,如果一个集群的方差跨越多个维度,例如一个集群是水平椭圆,另一个集群是垂直椭圆。那么 sklearn 的实现就无法很好地捕捉这些概念。
您知道任何考虑了集群每个维度方差的标准库吗?
它不应该这样。请参阅 sklearn 的二维案例示例,您可以看到椭圆:https://scikit-learn.cn/stable/auto_examples/mixture/plot_gmm_pdf.html
你好,我是 Raju,我想要一个部分相关的多任务聚类 Python 项目,我有一些关于该项目使用的工具、项目目的和项目职责的疑问。
使用模糊 C 均值聚类算法解决以下聚类问题。在必要时写下适当的假设。(给定:对象数:5,簇数:2,以及下表中每个对象的 x,y 数据点)。详细写出算法的所有步骤,直到您为至少两个迭代进行求解。
A – 10, 15
B – 15, 15
C – 25, 25
D – 50, 60
E – 65, 65
有人能帮我解决上面的问题吗?
你好!
如何将我的数据集(csv)插入到示例中?
在此教程中,您使用了 make_classification() 函数来创建测试二分类数据集,而不是 CSV 文件。
这个:https://machinelearning.org.cn/load-machine-learning-data-python/ 对我帮助不大……有什么想法吗?
提前感谢
make classification 是用于生成数据的,而如果你有 CSV 数据,你只需要读取它。最简单的方法是使用 pandas 的 read_csv() 函数。这里有一个例子:https://machinelearning.org.cn/quick-and-dirty-data-analysis-with-pandas/
Jason 你好!!!!
我正在寻找动态贝叶斯网络(DBN)的 Python 实现。
我需要在 ICP - 颅内压监测 - 中使用它们来处理一些时间序列
信号并识别集群。
您是否知道任何可用的 Python 实现?
提前感谢。
Alejandro.
你好 Alejandro……请看下面的
https://machinelearning.org.cn/introduction-to-bayesian-networks-with-jhonatan-de-souza-oliveira/
https://machinelearning.org.cn/introduction-to-bayesian-belief-networks/
https://machinelearning.org.cn/what-is-bayesian-optimization/
感谢有价值的信息
不客气 Gowripriya!
你好。有没有办法根据相似性对向量(数字)进行聚类?
你好 Storm,
请详细说明你正在做什么?
此致,
你好,我正在寻找一种方法来聚类大量关于 covid-19 病例的数据,以识别热点区域,并将它们归类为三个不同的级别;即轻度 covid-19 级别、中度 covid-19 级别和重度 covid-19 级别。
我在学习数据聚类算法的道路上是正确的吗?第二个问题是,我认为谱聚类和 K-均值算法是适合我的算法。你怎么看?
你好 John N……我认为你的目标和方法没有问题。
希望尽快得到答复。非常感谢。
谢谢 John N!
你好 James,我感谢你的回复!
你认为哪种算法最适合我的目标,为什么?非常感谢。
不客气 John!请更详细地说明一些目标,我们可以提供一些建议来帮助您朝着正确的方向前进。
这是我之前回复的参考,
“你好,我正在寻找一种方法来聚类大量关于 covid-19 病例的数据,以识别热点区域,并将它们归类为三个不同的级别;即轻度 covid-19 级别、中度 covid-19 级别和重度 covid-19 级别。”
我的问题是哪种算法最适合我的目标,为什么?我在这件事上仍然卡住了。非常感谢。
感谢清晰的聚类教程!
不客气!我们感谢您的反馈和支持!
非常感谢您提供的清晰教程,我想知道您是否有关于集成聚类的教程
你好 Malek……你可能会对以下内容感兴趣
https://machinelearning.org.cn/ensemble-learning-books/
聚类前的数据标准化有帮助吗?
它肯定有帮助。以下资源提供了通过数据准备来提高性能的更多建议
https://machinelearning.org.cn/data-preparation-for-machine-learning-7-day-mini-course/