CNN 长短期记忆循环神经网络的温和介绍
附带 Python 示例代码。
具有空间结构(如图像)的输入无法通过标准 Vanilla LSTM 轻松建模。
CNN 长短期记忆网络或简称 CNN LSTM 是一种专门为具有空间输入(如图像或视频)的序列预测问题设计的 LSTM 架构。
在这篇文章中,您将发现用于序列预测的 CNN LSTM 架构。
完成这篇文章后,您将了解:
- 关于用于序列预测的 CNN LSTM 模型架构的开发。
- CNN LSTM 模型适用问题的类型示例。
- 如何在 Python 中使用 Keras 实现 CNN LSTM 架构。
通过我的新书《使用 Python 的长短期记忆网络》启动您的项目,包括分步教程和所有示例的Python 源代码文件。
让我们开始吧。

卷积神经网络长短期记忆网络
图片由 Yair Aronshtam 拍摄,保留部分权利。
CNN LSTM 架构
CNN LSTM 架构包括使用卷积神经网络 (CNN) 层对输入数据进行特征提取,并结合 LSTM 以支持序列预测。
CNN LSTM 专为视觉时间序列预测问题以及从图像序列(例如视频)生成文本描述的应用而开发。具体来说,以下问题:
- 活动识别:生成图像序列中所示活动的文本描述。
- 图像描述:生成单个图像的文本描述。
- 视频描述:生成图像序列的文本描述。
[CNN LSTM 是] 一类在空间和时间上都具有深度,并且灵活地适用于涉及顺序输入和输出的各种视觉任务的模型。
—— 用于视觉识别和描述的长期循环卷积网络,2015 年。
这种架构最初被称为长期循环卷积网络或 LRCN 模型,尽管在本课程中我们将使用更通用的名称“CNN LSTM”来指代将 CNN 作为前端的 LSTM。
该架构用于生成图像文本描述的任务。关键是使用在具有挑战性的图像分类任务上预训练的 CNN,并将其重新用作字幕生成问题的特征提取器。
……很自然地,通过首先对其进行图像分类任务的预训练,并使用最后一个隐藏层作为生成句子的 RNN 解码器的输入,将 CNN 用作图像“编码器”。
—— 展示和讲述:一种神经图像字幕生成器,2015 年。
这种架构也已用于语音识别和自然语言处理问题,其中 CNN 用作 LSTM 在音频和文本输入数据上的特征提取器。
这种架构适用于以下问题:
- 输入中具有空间结构,例如图像中的 2D 结构或像素,或句子、段落或文档中的单词的 1D 结构。
- 输入中具有时间结构,例如视频中图像的顺序或文本中的单词,或者需要生成具有时间结构的输出,例如文本描述中的单词。
卷积神经网络长短期记忆网络架构
需要 LSTM 帮助进行序列预测吗?
参加我的免费7天电子邮件课程,了解6种不同的LSTM架构(附代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
在 Keras 中实现 CNN LSTM
我们可以在 Keras 中定义一个 CNN LSTM 模型进行联合训练。
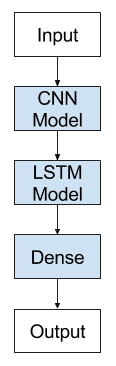
CNN LSTM 可以通过在前端添加 CNN 层,然后是 LSTM 层,并在输出层上添加一个 Dense 层来定义。
将此架构视为定义了两个子模型会很有帮助:用于特征提取的 CNN 模型和用于在时间步长上解释特征的 LSTM 模型。
让我们在 2D 输入序列(我们假设是图像)的上下文中查看这两个子模型。
CNN 模型
作为回顾,我们可以将 2D 卷积网络定义为由 Conv2D 和 MaxPooling2D 层组成,这些层按照所需的深度堆叠在一起。
Conv2D 将解释图像的快照(例如小方块),而池化层将整合或抽象解释。
例如,以下代码片段预计读取 10×10 像素的单通道图像(例如黑白)。Conv2D 将以 2×2 的快照读取图像,并输出一个新的 10×10 图像解释。MaxPooling2D 将解释池化为 2×2 块,将输出减少为 5×5 的整合。Flatten 层将单个 5×5 映射转换为 25 元素的向量,以便其他层处理,例如用于输出预测的 Dense 层。
|
1 2 3 4 |
cnn = Sequential() cnn.add(Conv2D(1, (2,2), activation='relu', padding='same', input_shape=(10,10,1))) cnn.add(MaxPooling2D(pool_size=(2, 2))) cnn.add(Flatten()) |
这对于图像分类和其他计算机视觉任务来说是有意义的。
LSTM 模型
上述 CNN 模型只能处理单个图像,将其从输入像素转换为内部矩阵或向量表示。
我们需要对多个图像重复此操作,并允许 LSTM 建立内部状态并使用 BPTT 通过输入图像的内部向量表示序列更新权重。
在将现有预训练模型(如 VGG)用于图像特征提取的情况下,CNN 可以是固定的。CNN 可能未经训练,我们可能希望通过从 LSTM 将误差反向传播到 CNN 模型,并通过多个输入图像对其进行训练。
在这两种情况下,概念上都有一个 CNN 模型和一个 LSTM 模型序列,每个时间步一个。我们希望将 CNN 模型应用于每个输入图像,并将每个输入图像的输出作为单个时间步传递给 LSTM。
我们可以通过将整个 CNN 输入模型(一层或多层)包装在 TimeDistributed 层中来实现这一点。此层实现了多次应用相同层或层的预期结果。在这种情况下,将其多次应用于多个输入时间步,并反过来向 LSTM 模型提供一系列“图像解释”或“图像特征”以供处理。
|
1 2 3 |
model.add(TimeDistributed(...)) model.add(LSTM(...)) model.add(Dense(...)) |
现在我们有了模型的两个元素;让我们把它们放在一起。
CNN LSTM 模型
我们可以在 Keras 中通过首先定义 CNN 层或层,将它们包装在 TimeDistributed 层中,然后定义 LSTM 和输出层来定义 CNN LSTM 模型。
我们有两种等效且仅在品味上不同的方法来定义模型。
您可以先定义 CNN 模型,然后通过将整个 CNN 层序列包装在 TimeDistributed 层中将其添加到 LSTM 模型,如下所示
|
1 2 3 4 5 6 7 8 9 10 |
# 定义 CNN 模型 cnn = Sequential() cnn.add(Conv2D(...)) cnn.add(MaxPooling2D(...)) cnn.add(Flatten()) # 定义 LSTM 模型 model = Sequential() model.add(TimeDistributed(cnn, ...)) model.add(LSTM(..)) model.add(Dense(...)) |
另一种可能更容易阅读的方法是在将 CNN 模型中的每一层添加到主模型时将其包装在 TimeDistributed 层中。
|
1 2 3 4 5 6 7 8 |
model = Sequential() # 定义 CNN 模型 model.add(TimeDistributed(Conv2D(...)) model.add(TimeDistributed(MaxPooling2D(...))) model.add(TimeDistributed(Flatten())) # 定义 LSTM 模型 model.add(LSTM(...)) model.add(Dense(...)) |
第二种方法的优点是所有层都出现在模型摘要中,因此目前更受青睐。
您可以选择您喜欢的方法。
进一步阅读
如果您想深入了解此主题,本节提供了更多资源。
CNN LSTM 论文
- 用于视觉识别和描述的长期循环卷积网络, 2015.
- 展示与讲述:一个神经图像字幕生成器, 2015.
- 卷积、长短期记忆、全连接深度神经网络, 2015.
- 字符感知神经语言模型, 2015.
- 卷积 LSTM 网络:一种用于降水临近预报的机器学习方法, 2015.
Keras API
文章
总结
在这篇文章中,您发现了 CNN LSTN 模型架构。
具体来说,你学到了:
- 关于用于序列预测的 CNN LSTM 模型架构的开发。
- CNN LSTM 模型适用问题的类型示例。
- 如何在 Python 中使用 Keras 实现 CNN LSTM 架构。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发用于序列预测的 LSTM!

在几分钟内开发您自己的 LSTM 模型。
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 构建长短期记忆网络
它提供关于以下主题的自学教程:
CNN LSTM、编码器-解码器 LSTM、生成模型、数据准备、进行预测等等...
最终将 LSTM 循环神经网络引入。
您的序列预测项目。
跳过学术理论。只看结果。






这种架构,经过一些调整,是否也适用于语音识别、说话人分离、语言检测和其他自然语言处理任务?
也许可以。
我看到它主要用于 NLP 中的文档分类/情感分析。
你好 Jason,你能提供一些关于这种 CNN + LSTM 架构在文本领域(文档分类、情感分析等)中的应用的参考文献吗?
也许在 scholar.google.com 上搜索一下。
你好 Jason,我非常苦恼,我想问你一个问题。例如,0-500 的数据,数据量相差很大。当我使用 LSTM 模型进行预测时,准确率太低。即使数据归一化也没有帮助,我想问你,数据应该如何处理?非常感谢!
也许先对数据进行归一化?
cnn + lstm 架构用于语音识别
– https://arxiv.org/pdf/1610.03022.pdf
感谢分享 Dan。
你好 Jason。如果时间序列数据很大,并且转换为 28*28 的 2D 图像作为输入。那么上述模型如何改变以进行功率预测?
本文中 CNN-LSTM 和 Conv2DLSTM 的示例可以根据您的问题进行调整
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
我想用 Conv1D 处理时间序列数据,然后将其输入 LSTM。你能推荐一些学习代码练习吗?
你好 J
1 我有和上面“liming”一样的问题
2 为什么你所有的 CNN 时间序列示例都使用 CNN-1D,而突然对于 CNN-LSTM,第一个 CNN 变成了 Conv2D?
例如
– https://machinelearning.org.cn/how-to-develop-convolutional-neural-network-models-for-time-series-forecasting/
或者
– https://machinelearning.org.cn/how-to-develop-convolutional-neural-networks-for-multi-step-time-series-forecasting/
我不明白?
如果您有一个 1D 单变量或多变量时间序列,那么您将使用 Conv1D,例如
https://machinelearning.org.cn/how-to-develop-convolutional-neural-network-models-for-time-series-forecasting/
如果您的输入是图像的时间序列,如本文所示,您将使用 Conv2D。
ConvLSTM2D 层有什么区别?
https://github.com/fchollet/keras/blob/master/examples/conv_lstm.py
据我所知,该层尚未得到支持。我一直避免使用它,直到所有错误都解决。
ConvLSTM 是 LSTM 的变体,它使用卷积代替 LSTM 单元中的内积
而 CNN LSTM 只是层的堆叠;CNN 后面跟着 LSTM。
Dan,你在项目中使用过它吗?
还没有,我只是在等待下一个 TensorFlow 版本,因为它似乎 ConvLSTM 将作为 tf.contrib.rnn.ConvLSTMCell 提供,相反,我已经在简单的语音识别实验中使用了 CNN + LSTM,它比 LSTM 堆叠效果更好。它确实有效!
谢谢丹。
我希望很快能为博客尝试一些例子。
@Dan Lim 您能分享您的语音识别脚本吗?谢谢。
你好,Jason。
您认为 CNNLSTM 可以解决回归问题吗?其输入是一些时间序列数据和一些属性/外生数据(空间),而不是图像数据?如果可以,如何在 CNN 中处理属性/外生数据(2D)。谢谢。
我也有同样的问题
也许吧,我还没有尝试将 CNN LSTM 用于时间序列。
也许每个序列都可以由一个 1D-CNN 处理。
考虑到 LSTM 已经解释了数据中的长期关系,这可能没有意义。
如果 CNN 可以找出与 LSTM 不同/新的结构,那可能会很有趣。也许您可以对序列进行 CNN 和 LSTM 解释,并使用另一个模型来集成和解释结果。
我尝试使用 CNN + LSTM 进行时间序列预测,希望 CNN 能够发现输入信号中的某些结构。到目前为止,即使在调整超参数之后,它的性能似乎也比两层 LSTM 模型差。我以为我会买你的书来查看详细信息,但听起来这本书没有涵盖?你之前关于 LSTM 模型的帖子非常有帮助。谢谢!
一般来说,我尝试过的所有时间序列问题(20+)中,LSTM 的表现都更差。
你可以在这里了解原因
https://machinelearning.org.cn/suitability-long-short-term-memory-networks-time-series-forecasting/
我建议首先穷尽经典时间序列方法,然后尝试 sklearn 模型,然后也许尝试神经网络。
@Jen Liu,希望看到您设法为您的实现发现一些隐藏信号。您能否分享一些关于您的 CNN + LSTM 时间序列预测的见解?谢谢。
我最近一直在使用这种方法,取得了巨大成功。
我已安排好关于这个主题的帖子。
你好,Miles。
我也有同样的问题。您在使用 CNN LSTM 进行时间序列研究方面有什么进展吗?
你好,你有 github 实现吗?
我的 LSTM 书中有一个完整的代码示例。
您好,先生,请提供您的书名和书的链接
https://machinelearning.org.cn/lstms-with-python/
嗨,Jason,
感谢您的出色工作和帖子。
我正在开始深度学习、python 和 keras 的学习。
我想知道如何在 Python 中使用 Keras 实现 CNN 与 ELM(极限学习机)架构进行分类任务。您有 github 实现吗?
抱歉,我没有。
感谢您的精彩示例……
我可以问您上面解释的 CNN LSTM 的完整代码吗?
因为,我遇到了 CNN 和 LSTM 维度相关的错误。
我遵循了您之前的示例,并尝试构建与 LSTM 堆叠的 VGG-16Net。
我的数据库只有 10 种不同的人体动作(10 个类别),例如走路和跑步等……
我的代码如下
# 图像的尺寸。
img_width, img_height = 224, 224
train_data_dir = 'db/train'
validation_data_dir = 'db/test'
nb_train_samples = 400
nb_validation_samples = 200
num_timesteps = 10 # 序列长度
num_class = 10
epochs = 10
batch_size = 8
lstm_input_len = 224 * 224
input_shape=(224,224,3)
num_chan = 3
# VGG16 作为 CNN
cnn = Sequential()
cnn.add(ZeroPadding2D((1,1),input_shape=input_shape))
cnn.add(Conv2D(64, 3, 3, activation='relu'))
cnn.add(ZeroPadding2D((1,1)))
cnn.add(Conv2D(64, 3, 3, activation='relu'))
cnn.add(MaxPooling2D((2,2), strides=(2,2),dim_ordering="th"))
cnn.add(ZeroPadding2D((1,1)))
cnn.add(Conv2D(128, 3, 3, activation='relu'))
cnn.add(ZeroPadding2D((1,1)))
cnn.add(Conv2D(128, 3, 3, activation='relu'))
cnn.add(MaxPooling2D((2,2), strides=(2,2),dim_ordering="th"))
cnn.add(ZeroPadding2D((1,1)))
cnn.add(Conv2D(256, 3, 3, activation='relu'))
cnn.add(ZeroPadding2D((1,1)))
cnn.add(Conv2D(256, 3, 3, activation='relu'))
cnn.add(ZeroPadding2D((1,1)))
cnn.add(Conv2D(256, 3, 3, activation='relu'))
cnn.add(MaxPooling2D((2,2), strides=(2,2),dim_ordering="th"))
cnn.add(ZeroPadding2D((1,1)))
cnn.add(Conv2D(512, 3, 3, activation='relu'))
cnn.add(ZeroPadding2D((1,1)))
cnn.add(Conv2D(512, 3, 3, activation='relu'))
cnn.add(ZeroPadding2D((1,1)))
cnn.add(Conv2D(512, 3, 3, activation='relu'))
cnn.add(MaxPooling2D((2,2), strides=(2,2),dim_ordering="th"))
cnn.add(ZeroPadding2D((1,1)))
cnn.add(Conv2D(512, 3, 3, activation='relu'))
cnn.add(ZeroPadding2D((1,1)))
cnn.add(Conv2D(512, 3, 3, activation='relu'))
cnn.add(ZeroPadding2D((1,1)))
cnn.add(Conv2D(512, 3, 3, activation='relu'))
cnn.add(MaxPooling2D((2,2), strides=(2,2),dim_ordering="th"))
cnn.add(Flatten())
cnn.add(Dense(4096, activation='relu'))
cnn.add(Dropout(0.5))
cnn.add(Dense(4096, activation='relu'))
#LSTM
model = Sequential()
model.add(TimeDistributed(cnn, input_shape=(num_timesteps, 224, 224,num_chan)))
model.add(LSTM(num_timesteps))
model.add(Dropout(.2)) # 添加
model.add(Dense(num_class, activation='softmax'))
model.compile(loss=’binary_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
# 这是我们用于训练的增强配置
train_datagen = ImageDataGenerator(rescale=1. / 255)
# 这是我们用于测试的增强配置
# 只进行缩放
test_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(224, 224),
batch_size=batch_size,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_data_dir,
target_size=(224, 224),
batch_size=batch_size,
class_mode='binary')
model.fit_generator(
train_generator,
steps_per_epoch=nb_train_samples // batch_size,
epochs=epochs,
validation_data=validation_generator,
validation_steps=nb_validation_samples // batch_size)
我忘了把错误写出来,那就是
ValueError:检查输入时出错:预期的 time_distributed_9_input 具有 5 个维度,但得到的数组形状为 (8, 224, 224, 3)
我想你还需要在该层的输入维度中指定一个批量大小,以获得第五个维度。尝试使用:
model.add(TimeDistributed(cnn, input_shape=(None, num_timesteps, 224, 224,num_chan)))。None将允许可变批量大小。是的,这对我有效。谢谢
请发送给我代码,对我不起作用
对我不起作用。有人解决过同样的问题吗?
你到底遇到了什么问题?
我也遇到了这个维度错误,你解决了吗?
请分享您的 Github 代码,我也遇到了相同的维度错误
我收到了同样的错误,您解决了吗?我可以请教您解决的方法吗?
抱歉,我无法调试您的代码。我在这里列出了一些获取代码帮助的地方
https://machinelearning.org.cn/get-help-with-keras/
你好。您如何向网络提供输入?如何确保它们是按顺序提供的?
嗨,Jason,
假设有一个数据集包含许多网格位置的时间序列数据(例如温度、降雨量)和地理数据(例如海拔、坡度),我需要使用该数据集来预测(回归)未来的天气。
我想到一种结合 LSTM(用于时间序列数据)+ 辅助(地理数据)的方法作为解决方案。但预测结果不太好。您有其他更好的方法吗?或者您有相关的课程吗?
非常感谢。
也许是一个带有时滞观测窗口的深度 MLP。
嗨,Jason,
您能详细解释一下吗?非常感谢。
此函数将帮助您重塑时间序列数据以使其成为监督学习问题
https://machinelearning.org.cn/convert-time-series-supervised-learning-problem-python/
然后您可以使用神经网络模型。
你好 Jason,非常感谢。我正在尝试使用函数式 API 实现 TimeDistributed CNN 与 LSTM 的相同架构,但遇到了问题。当我将 TimeDistributed 层传递给 maxpooling 步骤时,它会抛出错误,提示输入不是张量。您能提供几行代码,说明如何使用函数式 API 将 Timedistributed CNN 的输出输入到 LSTM 吗?
也许可以尝试将您的代码发布到 stackoverflow?
遇到同样的问题,希望能得到帮助!
也许可以尝试使用 Sequential API 代替?
也许可以尝试发布到这些位置之一
https://machinelearning.org.cn/get-help-with-keras/
嗨,Jason,
我将如何实现具有可变输入长度的 CNN-LSTM 分类问题?
使用填充或截断使输入长度相同
https://machinelearning.org.cn/handle-long-sequences-long-short-term-memory-recurrent-neural-networks/
使用填充方法,我担心 LSTM 可能会学习序列长度和分类之间的依赖关系。
我的数据结构是这样的:具有更多输入的序列比具有更少输入的序列更有可能属于某个类别。但是,我不希望我的模型学习这种依赖关系。
我的直觉正确吗?我记得在您之前的文章中读到 LSTM 会学习忽略填充序列,但我不太确定到什么程度。
您可以使用 Mask 来忽略填充值。
如何将卷积操作应用于序列本身而不是特征(时间样本数据)?
你具体指的是什么?
不错的介绍,但是很不完整。读完之后我知道如何构建 CNN LSTM,但我仍然不了解它的输入是什么样的,因此我不知道如何训练它。网络的输入到底是什么样的?我如何调和批量大小的概念与我的输入是一个序列的概念?对于从未用过 RNN 的人来说,这根本不清楚。
这确实取决于应用,例如,您希望将此方法应用于的问题的具体细节。
在视频和图像描述的情况下,使用您在此处显示的 LSTM 与使用编码器解码器 LSTM 模型有什么区别?
架构上的差异。
它可以用作视频摘要吗?您有代码吗?
也许吧。我没有视频摘要的示例。
您说:“在这两种情况下,概念上都有一个 CNN 模型和一个 LSTM 模型序列,每个时间步一个”
您能给我解释一下反向传播是如何在这里工作的吗?假设我的序列长度是 T,我有以下困惑
第一种解释:如果我以每个 LSTM 单元都有对应的 CNN 单元的方式解释。那么如果输入序列长度为 T,我将有 T 个 LSTM 和对应的 T 个 CNN。那么如果我假设我通过反向传播学习权重,那么所有 CNN 的权重难道不应该不同吗?所有 CNN 如何在时间上共享权重?
第二种解释:只有一个 CNN 和 T 个 LSTM。使用相同的 CNN 提取 T 帧的特征,并将其传递给具有不同权重的 T 个 LSTM。但是,这种网络如何学习 CNN 的权重呢?
我真的花了很多时间去理解,但我仍然很困惑。如果您能回答,那将非常有帮助 🙂
这篇帖子将帮助您理解 BPTT
https://machinelearning.org.cn/gentle-introduction-backpropagation-time/
LSTM 正在从 CNN 中获取输入的解释(例如 CNN 的输出),这在图像和有时文本数据的情况下提供了对输入的更多感知。
感谢分享 BPTT 链接。我了解了 LSTM 权重将如何更新。但是 CNN 权重呢?我附上了简单网络的图像。
https://drive.google.com/file/d/1J6-iLpEbNFL32Du-3il_ztw8jrMIZVSD/view?usp=sharing
如果反向传播是这样工作的,那么在端到端训练之后,所有 CNN 权重难道不会不同吗?如果是这样,那么它们怎么还是同一个 CNN 呢?
我相信错误会针对每个时间步反向传播。
输入的形状应该是什么样的?
例如,对于 45*45 图像
x_train.shape = (num_images, 45,45,num_channels)
y_train.shape =???
这是代码,图像实际上是 56*56*1
print "正在构建模型..."
model = Sequential()
# 定义 CNN 模型
model.add(TimeDistributed(Conv2D(32, (3, 3), activation = 'relu'),input_shape = (None, 56, 56, 1)))
model.add(TimeDistributed(MaxPooling2D(pool_size=(2, 2))))
model.add(TimeDistributed(Flatten()))
# 定义 LSTM 模型
model.add(LSTM(256,activation='tanh', return_sequences=True))
model.add(Dropout(0.1))
model.add(LSTM(256,activation='tanh', return_sequences=True))
model.add(Dropout(0.1))
model.add(Dense(2))
model.add(Activation('softmax'))
model.compile(loss=’binary_crossentropy’,
optimizer='adam',
class_mode='binary', metrics=['accuracy'])
print model.summary()
batch_size=1
nb_epoch=100
print len(final_input)
print len(final_input1)
X_train = numpy.array(final_input)
X_test = numpy.array(final_input1)
#y_train = numpy.array(y_train)
#y_test = numpy.array(y_test)
#y_train = y_train.reshape((10000,1))
#y_test = y_test.reshape((1000,1))
print "正在打印最终形状..."
print "X_train: ", X_train.shape
print "y_train: ", y_train.shape
print "X_test: ", X_test.shape
print "y_test: ", y_test.shape
print
print('训练...')
model.fit(X_train, y_train, batch_size=batch_size, nb_epoch=nb_epoch,
validation_data=(X_test, y_test))
print('评估...')
score, acc = model.evaluate(X_test, y_test, batch_size=batch_size,
show_accuracy=True)
print('测试分数:', score)
print('测试准确率:', acc)
形状 = num_images, k
其中 k 是类别的数量,或二元分类为 1。
你好,我正在研究一个 CNN LSTM 网络。当我编译以下代码时,我收到以下错误。我有 input_shape,但当我编译代码时仍然收到错误。你能帮我吗。
谢谢你。
代码
# 导入 Keras 库和包
来自 keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Flatten
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Dropout
from keras.layers import TimeDistributed
# 初始化 CNN
classifier = Sequential()
# 步骤 1 – 卷积分类器 = Sequential()
classifier.add(TimeDistributed(Conv2D(32, (3, 3), input_shape = (64, 64, 3), activation = 'relu')))
错误
ValueError: Sequential 模型中的第一层必须有
input_shape或batch_input_shape参数。这很奇怪,我不确定发生了什么。
您对此情况有什么建议吗?
是的,我建议仔细调试您的代码。
你好 Fathy,你解决你的问题了吗?我正遇到同样的麻烦。如果你得到解决方案,请告诉我
您需要指定时间维度:input_shape = (每个样本的时间步数,64, 64, 3)
嗨,Jason,
谢谢您的分享!
ConvLSTM 是否适用于解决海面温度预测问题?我的意思是我们将输入一系列网格图并得到下一个温度网格图?
也许吧。试试看。
好的。谢谢!您对如何修改此模型以解决此问题有什么建议吗?
你好,你解决你的问题了吗?我对于如何将这些图像作为 convLSTM 的输入感到困惑?你能给我一些例子或一些我可以参考的资料吗?非常感谢!
嘿,
感谢您的信息丰富的帖子……这很有用!
我想做一些类似的任务,但更复杂一点。假设我们希望将网络泛化以能够用于不同的尺寸。因此,我们需要以补丁尺度查看帧,然后图像补丁的效果导致图像效果,然后是视频的图像结果。(请注意,我的情况下无法调整大小!)
换句话说,假设我们想在网络中使用视频,其中每个视频具有不同数量的帧,并且不同视频的帧可能具有不同数量的补丁,考虑到不同视频的不同帧大小。因此,输入维度应该为例如 [None(用于批量),None(用于帧), None(用于补丁),100,100,3]
实际上我无法用 Keras 或 TensorFlow 编程!您能帮我吗?
对于帧数不同的视频,您可以
– 归一化以具有相同数量的帧
– 填充视频以具有相同数量的帧,并可能使用遮罩层
– 使用对序列长度不敏感的网络
– ……更多想法
对于不同的补丁大小,我想您是指不同的滤波器大小。如果是这样,您可以使用此处描述的多输入模型
https://machinelearning.org.cn/keras-functional-api-deep-learning/
这有帮助吗?
就使用掩码层而言。您能否描述在这种情况下应该如何使用掩码层。我的意思是,当我尝试在 CNN 之前使用掩码层(其中填充的帧确实具有零值)时,它会告诉我 CNN 不支持掩码。如果掩码层在 CNN 之后使用,我们确定填充的帧将具有特定值并且这将是什么?为了保持零,是不是不需要使用偏差?作为替代,不使用偏差会是一个好主意吗?
非常感谢!
您好 Theogani……以下内容应该会更清晰
https://github.com/jzbontar/pixelcnn-pytorch/blob/14c9414602e0694692c77a5e0d87188adcded118/main.py#L17
嗨,Jason,
感谢您的博客!我对如何将这个集成模型应用于我的数据有一些疑问。现在,我有多波段时间序列图像用于作物产量回归,我如何将这些数据作为输入导入到这个模型中?您能给我一些示例或一些我可以参考的资料吗?非常感谢!
你到底遇到了什么问题?
您可以使用 Python 工具(例如 PIL)加载图像。
http://www.pythonware.com/products/pil/
我在书中提供了一个带有虚构图像的完整示例
https://machinelearning.org.cn/lstms-with-python/
当我运行以下模型代码时,我收到错误“ValueError: Sequential 模型中的第一层必须有
input_shape或batch_input_shape参数。”model=Sequential()
K.set_image_dim_ordering('th')
model.add(TimeDistributed(Convolution2D(64, (2,2), border_mode= 'valid' , input_shape=(1, 2, 2), activation= 'relu')))
model.add(TimeDistributed(Convolution2D(64, (1,1), border_mode= 'valid', activation= 'relu')))
model.add(TimeDistributed(MaxPooling2D(pool_size=(1,1))))
model.add(TimeDistributed(Convolution2D(64, (1,1), activation= 'relu' )))
model.add(TimeDistributed(MaxPooling2D(pool_size=(1,1))))
model.add(TimeDistributed(Dropout(0.0)))
model.add(TimeDistributed(Flatten()))
model.add(TimeDistributed(Dense(16, activation= 'relu' )))
model.add(TimeDistributed(Dense(16, activation= 'relu' )))
#lstm
m=Sequential()
m.add(LSTM(units = 1, activation='sigmoid'))
我很乐意帮忙,但我无法为您调试代码。
也许可以发布到 stackoverflow?
嘿 Jason,这个例子很有启发性!
我目前正在尝试对一些射电天文数据进行异常检测,这些数据由 .tiff 图像文件组成,其中水平轴是时间戳,垂直轴是频率。在这种情况下,使用频率轴作为空间(因为信号以不同的频率出现),您认为应用 1D 卷积层比仅使用普通 LSTM 层来编码图像更好吗?我知道我的数据存在空间依赖性,但它只有 1 维。我想知道您对此的看法。
顺便说一句,我购买了您的机器学习/深度学习/LSTM 捆绑包,您在过去的几个月里一直是我的导师!
是的,尝试使用 1D CNN。
例如,1D CNN 对于作为输入的单词序列很有用,我认为这与您所描述的有一些相似之处。
嘿 Jason,您的帖子真棒!我正在阅读您的书,并尝试将示例应用于时间序列分类问题,使用时间序列图像序列,就像这个人在这篇帖子中做的那样:http://amunategui.github.io/unconventional-convolutional-networks/index.html
我的图像是 20000 张(每帧增加接下来 30 分钟的价格),“50×50” 1 通道,
问题是,我使用了所有能用的正则化,几乎所有的架构准确率都在 0.51 左右,这是我最后一次做的
model = Sequential()
model.add(TimeDistributed(Conv2D(5, (3,3), kernel_initializer="he_normal", activation= 'relu',kernel_regularizer=l2(0.0001)),
input_shape=(None,img_rows,img_cols,1)))
model.add(TimeDistributed(MaxPooling2D((2, 2), strides=(1,1))))
model.add(TimeDistributed(Dropout(0.75)))
model.add(TimeDistributed(BatchNormalization()))
model.add(TimeDistributed(Conv2D(3, (2,2), kernel_initializer="he_normal", activation= 'relu',kernel_regularizer=l2(0.0001))))
model.add(TimeDistributed(MaxPooling2D((2, 2), strides=(1, 1))))
model.add(TimeDistributed(Dropout(0.75)))
model.add(TimeDistributed(Flatten()))
model.add(Bidirectional(LSTM(50)))
model.add(Dropout(0.7))
model.add(Dense(num_classes, activation='softmax'))
model.summary()
model.compile(loss='binary_crossentropy', optimizer=keras.optimizers.Adam(lr=1e-6),metrics=['accuracy'])
所以我想问你,在这种架构中如何避免过拟合,以及帧的高度和长度是否会影响模型识别所有模式的方式,就像我的问题一样,我不知道是否因为图像之间非常微小的细节差异(因为它们非常相似)会对准确性和过拟合产生影响。
如果您能帮助我,那就太好了!
谢谢,您的书很棒!🙂
有趣的方法,我更喜欢直接建模数据而不是图像。也许使用 1D CNN。
避免神经网络过拟合的好方法是使用验证数据集进行早期停止。
Keras 在这里支持这一点
https://keras.org.cn/callbacks/#earlystopping
你好 Jason,
您帮了我很多。
我这里有一个问题。我有一个项目使用 CNN-LSTM 模型。但是,当我使用 1D cnn 时,用于滤波器数量的 Maxpooling 层的性能优于用于数据大小的 Maxpooling 层。所以我必须通过 Pernute 层调整 cnn 层之后的数据大小。您对此有何看法?
如果它能带来良好的性能,那就使用它。
另外,我想知道您是否可以探索 CNN 层中的替代滤波器大小来改变输出大小?
感谢您的回答。
实际上,我已经多次更改了过滤器大小。我知道通常Maxpooling层用于减少数据大小,而不是过滤器数量。即使Keras只在CNN2D中支持对数据宽度或高度进行Maxpooling,所以我对此有点担心。
Jason博士您好
感谢您的教程。我有一些问题。
根据您的教程 https://machinelearning.org.cn/multivariate-time-series-forecasting-lstms-keras/
我想知道我是否可以使用该教程实现您的CNN LSTM想法?如果可以,我应该更改代码中的哪些部分?我正在尝试实现它,但不知何故我被困住了。
此外,使用此模型进行分类工作是否有意义?
如果您能回答,我将不胜感激,Jason博士。非常感谢。
是的,你可以。
我有一些关于此的教程已经安排了。
亲爱的Jason
再次感谢您的教程
抱歉,您没有包含同时实现CNN (conv2D) 和LSTM的数据集的教程
我相信LSTM书中有一个例子,而且我很快会在博客上安排一些例子。
嗨,Jason,
我正在使用GRU进行字幕问题中的序列学习。GRU训练中的训练损失是什么意思?我的损失从9.###下降到0.29##,但如果我继续训练,它又开始增加。有什么想法导致损失再次增加吗?
我的损失函数是
loss_function = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y_true,
logits=y_pred)
loss_mean = tf.reduce_mean(loss_function)
y_true 和 y_labels 是字幕的令牌序列
训练损失是衡量模型拟合训练数据程度的指标。
你可以在这里了解更多关于交叉熵的信息
https://en.wikipedia.org/wiki/Loss_functions_for_classification
布朗利先生您好
我在评论中看到您提到您可能会研究Keras中现在可用的ConvLSTM层。我首先要感谢您做出的巨大贡献,您的博客对我理解LSTM非常有帮助。在提供内容的同时处理所有这些评论一定花费了您大量时间。然而,我阅读了您的许多帖子,但我的知识却不够用!
我希望利用ConvLSTM2D解决视频分割问题。这与本博客上常见的序列预测应用非常不同。我有N个视频,每个视频有500帧,每个视频对应一个2D分割掩码。我认为这是一个多对一的问题
输入: (N, 500, cols, rows, 1)
输出: (N, 1, cols, rows, 1)
根据您关于如何处理长序列的帖子,我已将输入调整为包含序列“片段”,例如50个时间步,这样我现在有了
输入: (N, 10, 50, cols, rows, 1)
输出 (N, 1, 1, cols, rows, 1)
这不太奏效,因为Keras LSTM期望一个5D数组,而不是6D。我的理解是,我将能够一次将单个序列输入到有状态LSTM中(500张图像被切成50个片段),并且我可以通过这种方式记住500张图像的状态,以便在决定是否更新梯度之前做出最终预测。
我的实现方法在输入 (10, 50, cols, rows, 1) 的情况下不起作用,因为这里的“10”被认为是样本数量,因此相应的输出需要是 (10, 1, cols, rows, 1),即每50帧一个分割掩码,这并非我所寻求的。
我可以将分割复制10次以产生所需的输出,但我不确定这是否是正确的方法。
或者我应该等待博客帖子?
我确实安排了一些使用conv2dlstm进行时间序列的帖子,但不是视频。
不过,我鼓励您首先通过任何方式使模型工作起来,然后使其运行良好。
将所有500帧视频都作为时间步长,或者只取前200帧。这样,每个视频就是一个样本,然后您可以像处理任何图像一样处理行、列和通道。
一旦模型开始工作,检查是否需要所有帧,也许只使用每第5或第20帧之类的。评估其对模型技能的影响。
好的,谢谢。我看看会发生什么。
你好,你能给我发一个Conv2D LSTM时间序列的链接吗?我正在查看你的书并在谷歌上搜索博客文章,但我找不到它。我特别想找一个 Conv2D LSTM 作为编码器/解码器架构的编码器部分的例子。
另外,顺便问一下,这些架构类型可以是有状态的吗?
谢谢你,Jason。
我相信这篇文章中有一个例子。
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
我尝试将CNN+LSTM+CTC应用于扫描文本行识别。您能推荐一些更好的理解来源吗?
干得好!
也许可以尝试在 scholar.google.com 上搜索一下
一如既往的出色文章。我想澄清一个问题。卷积LSTM [https://github.com/keras-team/keras/blob/master/examples/conv_lstm.py] 是否与卷积神经网络后跟LSTM的意思相同。我理解您试图使用CNN在将特征传递给LSTM之前进行外推,所以从技术上讲,它们应该相同吗?
不,ConvLSTM与CNN-LSTM不同。
ConvLSTM将作为LSTM单元输入的一部分执行卷积。
CNN-LSTM 是一种模型架构,它有一个用于输入的 CNN 模型,以及一个用于处理 CNN 模型处理过的输入时间步的 LSTM 模型。
嗨,Jason,
感谢您的文章。
我希望能得到您对我正在尝试构建的模型的投入和建议。
该模型的目标是结合CNN和LSTM作为词性标注器。
CNN部分接收Glove嵌入的词向量表示作为输入,并希望能学习到关于词/序列的信息。
BiLSTM将处理CNN的输出。
在密集层添加了TimeDistributed层进行预测。
模型训练没有问题,但在性能方面,指标比纯LSTM模型差。
我构建模型的方式错了吗?
这很难说。开发并评估模型,然后以此作为模型构建是否良好的反馈。
感谢您的回复,Jason。
我有几个模型迭代,从1个CNN层+2个BLSTM层到3个CNN+2个BLSTM。
在所有情况下,纯粹的2个BLSTM模型都优于它们。
我有点卡壳,不确定是CNN还是LSTM的问题。
也许这会有帮助。
https://machinelearning.org.cn/improve-deep-learning-performance/
感谢您的回复,Jason,我会查看该帖子。
感谢教程,我想问一下您的Keras后端,是TensorFlow还是Theano?谢谢
我目前使用并推荐TensorFlow,但有时在某些平台上安装可能具有挑战性,在这种情况下我推荐Theano。
我们如何将视频帧作为输入馈入cnn+lstm模型?我目前正在研究这个问题,不清楚如何实现。您能指导我一下吗?基本上我想了解模型输入部分。
每张图像都是图像序列中的一个步骤(例如时间步长),每个样本是一个图像序列。
我读到你曾将LSTM用于不同的问题,但发现它们用处不大。你的文章是关于时间序列回归的,但我想听听你对时间序列分类的看法。在阅读文献时,我发现RNNs/LSTMs在不同领域略微提高了准确性,但我没有看到这些网络取得许多突破性的成果。你是否有任何经验表明,对于时间序列分类,使用MLP或CNN的窗口方法也比LSTM/RNN方法更有用?
是的,我这里有MLP、CNN和LSTM用于时间序列分类的例子
https://machinelearning.org.cn/start-here/#deep_learning_time_series
我发现CNN-LSTM混合模型非常有效。
先生,谢谢您提供这些精彩的教程,它们对我帮助很大……我尝试使用keras实现CNN-lstm,但准确率只有0.5。而且在几个epoch后准确率也没有提高……请指导我,先生。
from string import punctuation
from os import listdir
from numpy import array,shape
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
来自 keras.models import Sequential
from keras.layers import Dense,BatchNormalization
from keras.layers import Flatten
from keras.layers import Dropout, Activation
from keras.layers import LSTM
from keras.layers import Embedding
from keras.layers.convolutional import Conv1D
from keras.layers.convolutional import MaxPooling1D
from keras.callbacks import EarlyStopping
from History import LossHistory
# 加载文档到内存
def load_doc(filename)
# 以只读方式打开文件
file = open(filename, ‘r’)
# 读取所有文本
text = file.read()
# 关闭文件
file.close()
return text
# 将文档转换为干净的令牌
def clean_doc(doc, vocab)
# 按空格分割成令牌
tokens = doc.split()
# 从每个令牌中去除标点符号
table = str.maketrans(”, ”, punctuation)
tokens = [w.translate(table) for w in tokens]
# 过滤掉不在词汇表中的令牌
tokens = [w for w in tokens if w in vocab]
tokens = ‘ ‘.join(tokens)
return tokens
# 加载目录中的所有文档
def process_docs(directory, vocab, is_trian)
documents = list()
# 遍历文件夹中的所有文件
for filename in listdir(directory)
# 跳过测试集中的任何评论
if is_trian and filename.startswith(‘cv9’)
continue
if not is_trian and not filename.startswith(‘cv9’)
continue
# 创建要打开的文件的完整路径
path = directory + ‘/’ + filename
# 加载文档
doc = load_doc(path)
# 清理文档
tokens = clean_doc(doc, vocab)
# 添加到列表中
documents.append(tokens)
return documents
# 加载词汇表
vocab_filename = ‘vocab.txt’
vocab = load_doc(vocab_filename)
vocab = vocab.split()
vocab = set(vocab)
# 加载所有训练评论
positive_docs = process_docs(‘txt_sentoken/pos’, vocab, True)
negative_docs = process_docs(‘txt_sentoken/neg’, vocab, True)
train_docs = negative_docs + positive_docs
# 创建分词器
tokenizer = Tokenizer()
# 在文档上拟合分词器
tokenizer.fit_on_texts(train_docs)
# 序列编码
encoded_docs = tokenizer.texts_to_sequences(train_docs)
# 填充序列
max_length = max([len(s.split()) for s in train_docs])
Xtrain = pad_sequences(encoded_docs, maxlen=max_length, padding=’post’)
# 定义训练标签
ytrain = array([0 for _ in range(900)] + [1 for _ in range(900)])
# 加载所有测试评论
positive_docs = process_docs(‘txt_sentoken/pos’, vocab, False)
negative_docs = process_docs(‘txt_sentoken/neg’, vocab, False)
test_docs = negative_docs + positive_docs
# 序列编码
encoded_docs = tokenizer.texts_to_sequences(test_docs)
# 填充序列
Xtest = pad_sequences(encoded_docs, maxlen=max_length, padding=’post’)
with open(“sentiment.txt”, “w”) as text_file
for p in test_docs: text_file.write(“%s \n” % p)
# 定义测试标签
ytest = array([0 for _ in range(100)] + [1 for _ in range(100)])
# 定义词汇量大小(最大整数值)
vocab_size = len(tokenizer.word_index) + 1
print (Xtrain)
print(‘构建模型…’)
# print (max_length) # 1209
# print (vocab_size) #13045
# 定义模型
model = Sequential()
model.add(Embedding(vocab_size, 100, input_length=max_length))
model.add(Conv1D(filters=32, kernel_size=8, activation=’relu’))
model.add(MaxPooling1D(pool_size=2))
model.add(LSTM(100))
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation(‘sigmoid’))
model.compile(loss=’binary_crossentropy’,
optimizer='adam',
metrics=['accuracy'])
early_stop = EarlyStopping(monitor=’val_loss’, patience=10)
train_log = LossHistory()
model.fit(array(Xtrain), array(ytrain),
batch_size = 30,
epochs=10,
callbacks=[early_stop, train_log],
validation_data=(array(Xtest), array(ytest)))
score, acc = model.evaluate(array(Xtest), array(ytest), batch_size=30)
model.save(‘cnn-lstm_model.h5’)
# score, acc = model.evaluate(x_test, y_test, batch_size=batch_size)
print('测试分数:', score)
print('测试准确率:', acc)
我这里有一个关于诊断和改进深度学习模型性能的指南
https://machinelearning.org.cn/start-here/#better
谢谢先生,我会参考那个。
嗨,Jason,
您会为物理问题推荐哪种神经网络模型?例如:与流体力学相关的问题?就像下面视频中展示的液体围绕一个圆流动,过一会儿开始产生漩涡。哪种NN架构最适合这种问题,其中我们有50个时间步的数据,我们训练模型40个,然后想要预测接下来10个时间步的数据并与实际结果进行比较。数据将包括视频中所示域在x和y方向上的速度、涡度和其他物理参数。我尝试在Keras中使用ConvLSTM2D,但结果不佳。
我提到的流体流动问题的视频链接
https://www.youtube.com/watch?v=JgoHhKiQFKI
我建议测试一系列方法,以发现最适合您的特定数据集的方法。
嗨,Jason博士,
精彩的帖子,感谢分享。
我目前正在研究交通分类问题。这种方法似乎非常适合这种情况。
我需要您在以下几点上提供帮助。
1. 我已经使用普通CNN模型(使用ResNet50进行迁移学习)实现了交通分类。
2. 时间是重要因素,因为我不希望图像被分类为A B A B。(理想情况是A A A A …… B B B B B ……)
3. 我可以在这个模型的末尾添加LSTM模型吗?
4. 这种方法会使我的模型在实际应用中更好吗?
谢谢你,
KK
是的,我建议对模型进行原型设计并评估其性能。
如何将其转化为一个分层模型?在空间(cnn)和时间(lstm)上都分层?这样,更大区域的特征可以与更小的特征相关联,更长时间的模式可以与这些小特征和大特征空间中的较短时间模式相关联。
是否一定是这样的结构?
cnn -> lstm ->
cnn -> lstm -> cnn -> lstm ->
cnn -> lstm -> cnn -> lstm -> cnn -> lstm
cnn -> lstm -> cnn -> lstm -> ^
cnn -> lstm -> ^ ||
|| ||
|| ||
|| ||
总结时间序列数据 ||
||
||
||
总结总结时间序列数据
一开始进行大量小特征检测,然后馈送到一组在更大空间和时间维度上进行卷积的层,依此类推?
Conv-LSTM 混合模型足够了,ConvLSTM 模型也可以。
两者都将处理空间数据的时间步。
然后,您可以为每个详细级别使用一个模型,并使用一个模型来组合它们的解释。
Jason 您好,我使用了与您类似的模型。我为每个cnn-lstm使用了10帧。我的形状是 (Sample,10,90,90,1) —> (样本,时间,图像形状,图像形状,通道)
问题是每次预测我都会得到10个结果,我不知道为什么。而且这10个结果都不同。您有什么想法吗?
谢谢
Emre
除非您使用编码器-解码器,否则每个输入时间步您将得到一个输出。
我只对类别使用了one-hot编码(我有5个不同的类别)。实际上,我每个时间步有50个结果(而不是10个)。我是否也应该为模型使用编码器-解码器?或者我该如何解决这个问题?
此致,
Emre
也许可以尝试一下并比较结果?
你解决这个问题了吗?我也遇到了同样的错误。
什么错误?
先生,您好,
感谢这篇精彩的教程。
我正在研究一个图像分类问题,我认为CNN+LSTM将非常有用,因为我正在输入从视频中获取的图像帧。
在这种情况下,我需要如何排列我的图像帧?
如果是一般的图像分类,我将为每个类别创建一个文件夹。但在这个例子中,假设我取了3个属于同一类别的视频序列。我必须如何排列训练和测试中的图像帧?
谢谢你,
KK
图像必须按时间顺序排列并组织成序列。
您可能需要编写一个自定义数据生成器来生成每个序列或图像序列批次。
嘿,Jason,我们如何对图像进行ImageDataGenerator?由于图像的形状,我遇到了错误。
ValueError: Input to
.fit()should have rank 4. Got array with shape: (11194, 10, 90, 90, 1)谢谢,
Emre
也许这篇文章会有所帮助
https://machinelearning.org.cn/how-to-configure-image-data-augmentation-when-training-deep-learning-neural-networks/
我正尝试构建这篇论文中描述的用于视频目标检测的模型的简单版本:https://arxiv.org/abs/1903.10172。其架构是一个ConvNet特征提取器,将其输出馈送给ConvLSTM,ConvLSTM再将其输出馈送给SSD检测层。但第一步是先在图像分类上端到端预训练ConvNet+ConvLSTM。
您在此处描述的模型似乎是结合ConvNet和ConvLSTM的正确方法,但我对输入形状感到困惑。TimeDistributed层需要3D输入,其中一个维度是时间。我理解在训练时如何做到这一点,但在推理时我不想将3D张量馈送给模型。我只想让它一次处理一张图像。我感觉我遗漏了一个小细节,希望您能帮助我。谢谢!
附注:上述论文的作者在tensorflow/models/research/lstm_object_detection repo中有代码,但似乎他们这项工作的版本(约一周前更新)不完整,对我来说非常令人困惑。
嗯,我不熟悉这个模型。
通常,这有助于理解输入形状
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
此外,本帖子中的CNN-lstms和convlstms可能具有启发性
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
通常,CNN-LSTM 期望一个特征是一张图像,一个样本是一个图像序列,例如 [?, 时间步, 行, 列, 通道]。
这有帮助吗?
感谢您的快速回复。我可能不应该提到那个特定的模型,因为它对问题并不是至关重要的。我只是想提供一些背景信息。
阅读您分享的第一个链接后,看来我想要做的是只输入一个时间步,但通过stateful = true参数在多个时间步上保持内部状态。但在这种情况下,似乎不需要TimeDistributed层,除了可能一开始就使用LSTM期望的输入形状。否则,我可以直接将ConvNet输出重塑为具有时间维度,然后再馈送到ConvLSTM。您觉得这样对吗?
再次感谢!希望我今天能构建我的模型。
也许可以。
解决一个给定问题有许多方法。我鼓励你集思广益,提出几种方法,然后逐一测试。这将有助于你更多地了解数据和模型,并找到适合你特定数据集的方法。
布朗利先生您好
我想用CNN LSTM进行图像分类。
我使用了您上面的CNN LSTM代码,但遇到了
“ValueError: Sequential模型中的第一层必须有
input_shape或batch_input_shape参数。”的错误,错误发生在“model.add(TimeDistributed(cnn,…)”这一行。我怎么知道这一层的输入形状是什么?是我的输入图像形状还是从CNN获得的特征向量?
您能指导我如何填写LSTM模型代码的括号吗?例如,如何选择“model.add(LSTM(…))”的元素?
非常感谢
也许这会有帮助。
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
布朗利先生您好
感谢您的指导。我阅读了链接,但我的cnnLSTM仍然无法工作。并且timeDistributed代码出现了错误。
我搜索了很多来解决这个问题,最终我找到了一个建议,“使用r1.4.0,一个TensorFlow的API文档”。
我的TensorFlow版本是1.4.0。现在我的问题是如何使用这个API,我的意思是,我应该安装它来代替我的TensorFlow,还是应该把它复制到某个地方,或者其他什么。
我把我的代码发给你(输入图像是28*28)
请再次帮助我,布朗利先生。
谢谢你
import numpy
来自 keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers import LSTM
from keras.layers import TimeDistributed
from keras.utils import np_utils
from keras import backend as K
K.set_image_dim_ordering('th')
# 设置随机种子以保证结果可复现
seed = 7
numpy.random.seed(seed)
# 重塑为 [样本][像素][宽度][高度]
X_train = X_train.reshape(X_train.shape[0], 1, 28, 28).astype(‘float32’)
X_test = X_test.reshape(X_test.shape[0], 1, 28, 28).astype(‘float32′)
# 将输入从0-255归一化到0-1
X_train = X_train / 255
X_test = X_test / 255
# one hot 编码输出
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
num_classes = y_test.shape[1]
num_timesteps = 10 # 序列长度
# 定义 CNN 模型
model = Sequential()
model.add(TimeDistributed(Conv2D(32, (3, 3), input_shape=(1, 28,28), activation=’relu’)))
model.add(TimeDistributed(MaxPooling2D(pool_size=(2, 2))))
model.add(TimeDistributed(Flatten()))
# 定义 LSTM 模型
model.add(LSTM(num_timesteps))
model.add(Dense(num_classes, activation='softmax'))
# 编译模型
model.compile(loss=’categorical_crossentropy’,optimizer=’adam’,metrics=[‘accuracy’])
#return model
# 拟合模型
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=200, verbose=2)
# 模型的最终评估
scores = model.evaluate(X_test, y_test, verbose=0)
print(“CNN Error: %.2f%%” % (100-scores[1]*100))
———————————————-
ValueError: Sequential 模型中的第一层必须有
input_shape或batch_input_shape参数。或许尝试更新到最新版本的TensorFlow,例如1.13。
再次感谢
但我在Anaconda提示符中输入了以下代码;然后我遇到了一个异常。
哪里出了问题?
我如何更新我的TensorFlow?
(C:\Users\ASUS\Anaconda3) C:\Users\ASUS>python
Python 3.6.3 |Anaconda custom (64-bit)| (default, Oct 15 2017, 03:27:45) [MSC v.1900 64 bit (AMD64)] on win32
键入 "help"、"copyright"、"credits" 或 "license" 获取更多信息。
(C:\Users\ASUS\Anaconda3) C:\Users\ASUS>pip install
您必须至少提供一个要安装的要求(请参阅“pip help install”)
您正在使用pip版本9.0.1,但版本19.1.1可用。
您应该考虑通过“python -m pip install –upgrade pip”命令进行升级。
(C:\Users\ASUS\Anaconda3) C:\Users\ASUS>pip install -U –no-deps keras tensorflow theano scikit-learn
异常
回溯(最近一次调用)
文件“C:\Users\ASUS\Anaconda3\lib\site-packages\pip\basecommand.py”,第215行,在main中
status = self.run(options, args)
文件“C:\Users\ASUS\Anaconda3\lib\site-packages\pip\commands\install.py”,第335行,在run中
wb.build(autobuilding=True)
文件“C:\Users\ASUS\Anaconda3\lib\site-packages\pip\wheel.py”,第749行,在build中
self.requirement_set.prepare_files(self.finder)
文件“C:\Users\ASUS\Anaconda3\lib\site-packages\pip\req\req_set.py”,第380行,在prepare_files中
ignore_dependencies=self.ignore_dependencies))
文件“C:\Users\ASUS\Anaconda3\lib\site-packages\pip\req\req_set.py”,第487行,在_prepare_file中
req_to_install, finder)
文件“C:\Users\ASUS\Anaconda3\lib\site-packages\pip\req\req_set.py”,第428行,在_check_skip_installed中
req_to_install, upgrade_allowed)
文件“C:\Users\ASUS\Anaconda3\lib\site-packages\pip\index.py”,第465行,在find_requirement中
all_candidates = self.find_all_candidates(req.name)
文件“C:\Users\ASUS\Anaconda3\lib\site-packages\pip\index.py”,第423行,在find_all_candidates中
for page in self._get_pages(url_locations, project_name)
文件“C:\Users\ASUS\Anaconda3\lib\site-packages\pip\index.py”,第568行,在_get_pages中
page = self._get_page(location)
文件“C:\Users\ASUS\Anaconda3\lib\site-packages\pip\index.py”,第683行,在_get_page中
return HTMLPage.get_page(link, session=self.session)
文件“C:\Users\ASUS\Anaconda3\lib\site-packages\pip\index.py”,第811行,在get_page中
inst = cls(resp.content, resp.url, resp.headers)
文件“C:\Users\ASUS\Anaconda3\lib\site-packages\pip\index.py”,第731行,在__init__中
namespaceHTMLElements=False,
TypeError: parse() got an unexpected keyword argument ‘transport_encoding’
您正在使用pip版本9.0.1,但版本19.1.1可用。
您应该考虑通过“python -m pip install –upgrade pip”命令进行升级。
我不知道,也许尝试一次安装一个库来缩小范围。
也许也可以尝试这个教程
https://machinelearning.org.cn/setup-python-environment-machine-learning-deep-learning-anaconda/
我成功更新了我的TensorFlow。
现在在我的Anaconda /lib/site-package中,我有两个TensorFlow文件夹
TensorFlow 1.4.0 和 TensorFlow 1.10.0
我应该删除TensorFlow 1.4.0 吗?
也许吧。另外,或许尝试更新到 TensorFlow 1.13,最新版本。
谢谢你
布朗利先生
非常抱歉,问了很多问题,
这是我唯一能信任的参考资料。
更新后,我的Anaconda提示符无法工作。
我的意思是它不会停留在桌面上。
这四行出现后它就会关闭
C:\Users\ASUS>python C:\Users\ASUS\Anaconda3\etc\keras\load_config.py 1>temp.txt
C:\Users\ASUS>set /p KERAS_BACKEND= 0del temp.txt
C:\Users\ASUS>python -c “import keras” 1>nul 2>&1
或许尝试不重定向输出,直接运行代码?
您好,Brownlee先生
我彻底卸载了系统中的Anaconda,然后重新安装了Anaconda,所有库都是更高版本,例如TensorFlow是1.13.0等等。
现在的问题是,当我运行之前的代码时,我遇到了以下错误
import numpy as np
import scipy
import scipy.misc
n_images =16416 #示例值
image_names = [“traincharactor2/image_{0}.bmp”.format(k) for k in range(n_images)]
training_set = []
for img in image_names
training_set += [scipy.misc.imread(name=img)]
X_train = np.array(training_set).reshape(16416, 28,28);
C:\Users\ASUS\Anaconda3\lib\site-packages\ipykernel_launcher.py:10: DeprecationWarning:
imread已弃用!imread在 SciPy 1.0.0 中已弃用,并将在 1.2.0 中移除。请改用
imageio.imread。# 当我们加载内容时,从sys.path中移除CWD。
我添加了 ” import imageio”
但出现了以下错误
import numpy as np
import scipy
import scipy.misc
import imageio
n_images =16416 #示例值
image_names = [“traincharactor2/image_{0}.bmp”.format(k) for k in range(n_images)]
training_set = []
for img in image_names
training_set += [imageio.imread(‘name=img’)]
X_train = np.array(training_set).reshape(16416, 28,28);
FileNotFoundError: 没有这样的文件: ‘C:\Users\ASUS\name=img’
我尝试了许多语法用于 ” training_set += [imageio.imread(‘name=img’)]”
但都没有用
我想你需要更改你正在加载的文件的名称。
您好,Brownlee先生
我解决了读取图片的问题。
我开始运行LSTM_CNN进行图像分类。
和以前一样,我遇到了这个错误
ValueError: Dimension must be 5 but is 4 for ‘time_distributed_4/conv2d_5/transpose’ (op: ‘Transpose’) with input shapes: [?,10,28,28,1], [4].
这是我的代码(图片大小为28*28)
import numpy
#from keras.datasets import mnist
来自 keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers import LSTM
from keras.layers import TimeDistributed
from keras.utils import np_utils
from keras import backend as K
K.set_image_dim_ordering('th')
# 设置随机种子以保证结果可复现
seed = 7
numpy.random.seed(seed)
# 重塑为 [样本][像素][宽度][高度]
X_train = X_train.reshape(X_train.shape[0], 1, 28, 28).astype(‘float32’)
X_test = X_test.reshape(X_test.shape[0], 1, 28, 28).astype(‘float32′)
# 将输入从0-255归一化到0-1
X_train = X_train / 255
X_test = X_test / 255
# one hot 编码输出
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
num_classes = y_test.shape[1]
num_timesteps = 10 # 序列长度
# 定义 CNN 模型
cnn = Sequential()
cnn.add(Conv2D(32, (5, 5), input_shape=(1, 28,28), activation=’relu’))
cnn.add(MaxPooling2D(pool_size=(2, 2)))
cnn.add(Flatten())
# 定义 LSTM 模型
model = Sequential()
model.add(TimeDistributed(cnn, input_shape=(None, num_timesteps, 28, 28,1)))
model.add(LSTM(num_timesteps))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=’categorical_crossentropy’,optimizer=’adam’,metrics=[‘accuracy’])
# 拟合模型
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=200, verbose=2)
# 模型的最终评估
scores = model.evaluate(X_test, y_test, verbose=0)
print(“CNN Error: %.2f%%” % (100-scores[1]*100))
我尝试了许多改变input_shape的方法,但都没有奏效。
您能帮我指出代码中哪里出了问题吗?!
我的研究真的需要这段代码
非常感谢
抱歉,我无法为您调试代码,也许可以尝试发布到StackOverflow?
也许这会有帮助。
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
此外,也许这里有cnn-lstm代码示例
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
布朗利先生您好
我的问题还没有解决。
现在我想将CNN提取的特征保存为向量。
我该怎么做呢?
我想先保存CNN特征,然后将其馈送给LSTM。
———
另一个问题是关于我的数据库,
为了实现CNN_LSTM,我的训练数据集是一个文件夹,其中所有类别的图像都按顺序排列。测试文件夹也像训练文件夹一样。
这对您上面建议的代码合适吗?
我这里有一个从CNN提取向量的例子
https://machinelearning.org.cn/how-to-use-transfer-learning-when-developing-convolutional-neural-network-models/
数据集布局听起来不错。
我用timedistributed()包装了一切
仍然出现错误
“输入张量必须是4维”
我该怎么办?
也许可以从一个可用的示例开始,然后根据你的问题进行调整。
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
我们可以用CNN或RNN对IRIS数据集进行分类吗?
不,鸢尾花数据不是序列。
请看这篇文章
https://machinelearning.org.cn/when-to-use-mlp-cnn-and-rnn-neural-networks/
你好 Jason,
我正在开始学习LSTM,在尝试拟合模型时遇到了一个奇怪的情况。您能检查一下我对任务的描述,如果发现任何问题请纠正我吗?(我正在使用R,但代码几乎相同 🙂 )
# 问题背景/使用的数据生成器
给您一些背景,我有一个单通道2D数组数据集。这些2D数组的序列足以创建一个分类器。其中一个数组的形状是(180,360,1),每天我有24个这样的数组。
在这种情况下,据我所知,我正在尝试构建一个多对一的LSTM模型。
我创建了一个数据生成器,它返回一个维度为 (batch_size, time_steps, 180, 360, 1) 的数组。
# 测试模型的结果
(1)
如果我使用一个“简单”的模型,没有使用LSTM模型,但“将所有时间步一起考虑”
batch_size <- 1 # 一个批次就是一天
time_steps <- 24 # 发送当天所有2D数组
model %
layer_flatten(input_shape = c(time_steps, 180, 360, 1)) %>%
layer_dense(units = 32, activation = “relu”) %>%
layer_dense(units = 16, activation = “relu”) %>%
layer_dense(units = 1, activation = “sigmoid”)
model %>% compile(
optimizer = “rmsprop”,
loss = “binary_crossentropy”,
metrics = c(“accuracy”)
)
我得到 val_acc 约为 0.76,val_loss 约为 0.56
(2)
如果使用CNN + LSTM,每批次3天,每天发送48个时间步(回溯2天)
batch_size <- 3 # 批次为三天
time_steps <- 48 # 一天和前一天所有的数组
model %
time_distributed(
layer_conv_2d(filters = 32, kernel_size = c(5,5), activation = “relu”,
kernel_initializer = ‘he_uniform’),
input_shape = list(24*lookback_d, 180, 360,1)
) %>%
time_distributed(
layer_max_pooling_2d(pool_size = c(3,3))
) %>%
time_distributed(
layer_conv_2d(filters = 32, kernel_size = c(5,5), activation = “relu”,
kernel_initializer = ‘he_uniform’)
) %>%
time_distributed(
layer_flatten()
) %>%
layer_gru(units = 32, dropout = 0.1, recurrent_dropout = 0.5) %>%
layer_dense(units = 16, activation = “relu”) %>%
layer_dense(units = 1, activation = “sigmoid”)
model %>% compile(
optimizer = “rmsprop”,
loss = “binary_crossentropy”,
metrics = c(“accuracy”)
)
我得到相同的 val_acc 约为 0.75,val_loss 约为 0.55
# 问题
这些结果几乎相同,是因为CNN+LSTM模型需要进一步调优吗?或者是因为创建的“基本模型”很难改进?
由于增加每个批次发送的天数,或增加每天发送的时间步数,都会导致ResourceExhaustedError(在第一个conv_2d层分配张量时OOM),您认为我应该修改数据生成器发送给模型的数据形状吗?
感谢您的帮助!
抱歉,我没有能力调试您的代码/问题。
也许可以尝试发布到 stackoverflow?
我们可以将CNN与LSTM用于信号数据预测吗?
当然,我在这里提供了一个例子
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
可以将其应用于卫星图像时间序列的时间分割吗?
抱歉,我不知道那个问题具体是什么?
杰森,帖子写得太棒了。我们能否使用ConvLSTM从一系列包含人脸的帧中提取人类情感,而不是从单帧中提取?我正在做一个练习项目,从我的孩子们的视频中提取人类情感,普通的CNN会在每一帧中吐出人类情感,但我观察到情感在系列帧的最后一帧达到高峰。
或许可以试试看?
感谢Jason的回复。我是机器学习编程的初学者,花了很多精力才发现CNN无法帮助我实现目标。一个如何实现它的通用算法将对我在项目中解决最小可行产品(MVP)非常有帮助。
我可以用2D-CNN进行时间序列预测吗?您的回复对我研究很有价值。
是的,CNN可以用于时间序列,这里有很多例子
https://machinelearning.org.cn/how-to-develop-convolutional-neural-network-models-for-time-series-forecasting/
2D CNN只对时空数据有意义,例如随时间变化的图像。
感谢这篇很棒的教程。
请告诉我如何使用2D CNN进行时空时间序列预测。有没有相关的教程?
感谢您的建议,我希望将来能涵盖它。
我正在设计一个时空多变量2D CNN LSTM
13974个序列,100个时间戳,6个位置,5个变量(特征)
训练输入形状: (13974, 100, 6, 5)
训练输出形状: (13974, 1, 6, 5)
测试输入形状: (3494, 100, 6, 5)
测试输出形状: (3494, 1, 6, 5)
model = Sequential()
model.add(TimeDistributed(Conv2D(32, (3, 3),
padding=’same’),
input_shape=(100, 6, 5,1)))
model.add(TimeDistributed(Activation(‘relu’)))
model.add(TimeDistributed(Conv2D(32, (3, 3))))
model.add(TimeDistributed(Activation(‘relu’)))
model.add(TimeDistributed(MaxPooling2D(pool_size=(2, 2))))
model.add(TimeDistributed(Dropout(0.25)))
model.add(TimeDistributed(Flatten()))
model.add(TimeDistributed(Dense(512)))
model.add(TimeDistributed(Dense(35, name=”first_dense_flow” )))
model.add(LSTM(20, return_sequences=True, name=”lstm_layer_flow”));
model.add(TimeDistributed(Dense(101), name=” time_distr_dense_one_ flow “))
model.add(GlobalAveragePooling1D(name=”global_avg_flow”))
model.compile(loss=’mae’, optimizer=’adam’, metrics=[‘accuracy’]) model.fit(train_input,train_output,epochs=50,batch_size=60)
我的模型能够预测输出 (13974, 1, 6, 5) 吗?
请纠正我的错误。
抱歉,我没有能力审查和调试您的代码,这里有一些建议
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
你好,
我按照您的帖子,构建了CNN+LSTM模型,它编译正常。
但在训练时,fit_generator存在问题。
错误是
输入需要5维,但只得到了4维
我通过Image datagenerator提供了图像,其输入维度为64x64x3,批处理大小为4。
因此,fit_generator接收的输入是: (4,64,64,3)
这表明数据和模型之间存在不匹配。您可以更改其中一个。
嗨 Jason:我是您的忠实粉丝。问题是:您在这里展示了一个可用于分析视频数据的CNN-LSTM架构。但是我们如何预处理视频数据以输入到这个架构中呢?我有多个2秒人类运动的视频片段,标签为0或1,我已经提取了一些帧,但不知道如何将它们输入到这个NN架构中……
从上面评论来看,似乎有相当多的人对CNN-LSTM用于视频数据感兴趣!但它仍然不清楚如何工作……特别是如何构建项目,以及如何预处理原始数据以进行输入……也许这可以成为未来的教程?谢谢Jason 🙂
我在LSTM书中给出了一个模拟视频的例子。
它是一个图像数组,每张图像都是一个时间步。
谢谢你,乔治。
好问题。抱歉,我没有一个完整的工作示例。将帧裁剪到最小集合(每秒几帧?),然后或许对图像数据进行像素缩放,就像图像分类一样?
嗨,Jason,
感谢这篇精彩的文章。文章中没有提到数据是如何读入模型的。由于这是一个CNN + LSTM模型,典型的ImageDataGenerator将不起作用,因为我们正在读取一个图像序列。
典型的ImageDataGenerator会生成 (N, W, H, C) 格式的数据,其中 N 是批次大小,W 和 H 是宽度和高度,C 是通道数(RGB图像为3,灰度图像为1)。
但我们需要发送一个序列,我们需要发送多个帧。所需的形状是 (N, F, W, H, C) — 其中 F 是我们序列的帧数。
那么我们如何才能继续阅读每一个图像序列呢?
抱歉,我不确定我理解你的问题。
LSTM 书中有关于图像的示例
https://machinelearning.org.cn/lstms-with-python/
这里有一个时间序列的示例
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
你好 Jason,
我想问一下,我是否可以在CSV文件中的数据上实现CNN,用于交通流量预测!!!
有没有什么资源可以帮助我使用keras或pytorch库在python中实现?
数据有日期、时间和每小时车辆流量两个特征。
谢谢你。
这或许能帮助你入门
https://machinelearning.org.cn/how-to-develop-convolutional-neural-network-models-for-time-series-forecasting/
你好,Jason
我可以在 CNN+LSTM 上应用无标签数据集吗?这可能吗?
如果可以,算法是如何工作的?
也许,如果你将问题重新定义为自监督学习。
谢谢你,先生,
您有任何参考资料和代码吗?
是的,我在书中给出了一个二维示例。
我的博客上有很多一维示例,你可以使用博客搜索。
嗨,Jason,
我正在尝试将视频片段分类为动作。
我已拥有通过CNN层提取的I3D特征。
尝试将它们拟合到LSTM模型中进行训练,但是val_acc始终保持在45%。
我怀疑它没有学习序列,因为我没有使用有状态的LSTM。但是当我阅读您上面的文章时,没有处理来确保序列也得到学习,或者我没有理解它是如何处理的?您能帮我理解您的模型如何确保序列被学习吗?
更多信息
1. 由于有些片段过长/过短,我使用pad_sequence进行了截断/填充。对于截断,我从片段的中点获取帧,因为我读到这通常能更好地反映动作。
我读到您的另一篇文章提到了有状态的LSTM,这应该是一个LSTM的正确使用方式。我认为LSTM有助于学习视频片段之间的序列,从而有助于改善对片段依赖关系的预测。我尝试调整批次大小,使一个视频作为一个批次,以便它学习序列。但这没有帮助。
恭喜您取得进展。
有状态可能有用也可能没用。
我认为这里的教程将帮助您诊断问题并提升模型的技能
https://machinelearning.org.cn/start-here/#better
先生,您能告诉我如何使用LSTMs进行静态数据的特征选择吗?
我还没有见过LSTMs用于特征选择。
你好Jason……我有个疑问……将lstm与cnn模型结合,是否总是比单独使用cnn模型(特别是vgg16模型)在图像分割方面获得更好的结果(准确率)……
不,这确实取决于预测任务的具体情况。
是因为图像分割,所以会有这样的差异吗?视频分类会带来更好的结果吗?另外,有没有办法仅根据模型摘要比较两个模型的性能?
CNN-LSTM 适用于图像序列,例如视频。并非专门用于分割。
您好 Jason,我们可以将卷积 LSTM 用于多元时间序列预测吗?基本上我们有一个数据集,其中包含降雨量、温度、压力、太阳辐照度和太阳能输出等因素,我们需要预测太阳能输出。那么可以使用这种方法吗?
是的。请看这里
https://machinelearning.org.cn/how-to-develop-convolutional-neural-network-models-for-time-series-forecasting/
您好,Jason,我主要想将卷积 LSTM 应用于多元时间序列数据,而不仅仅是 CNN。那么这是否可能呢?
当然,请看这里的示例
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
你好,Jason!
感谢这篇精彩的文章,我喜欢您的作品!
但我有一个问题:在文章中,您将通过CNN处理的图像输出用作LSTM的单个时间步,但我希望将通过CNN处理的图像输出用作多个时间步。例如,如果我的CNN输出是32×80,我希望将此输出用作LSTM的32个时间步,每个时间步80个特征。该如何实现呢?
谢谢!
谢谢!
这似乎不太合理——例如,将图像特征向量划分为LSTM的“时间步”。您能帮我理解一下吗?
我的用例是图像中的文本识别。如果我们有一个单词的图像,将图像视为一系列垂直特征块可能很有用,如果我从网上阅读到的内容理解正确的话。我相信这是因为一个单词是一系列字符。
我认为它的工作方式是这样的:通过CNN获取带有单词的图像将提取相关特征。通过使用池化层,我们可以使输出体积变为 W' x 1 x F(池化宽度,池化高度等于1,F 个过滤器/核输出),而输入图像是 W x H x 1(灰度)。然后,输出可以被视为每个 W' **时间步**的提炼信息,因为初始图像和 CNN 的输出都可以被视为一系列“垂直”观测。
如果有什么地方不合理,请纠正我,因为我根本不是专家。我在这篇文章中读到过这种网络类型:https://towardsdatascience.com/build-a-handwritten-text-recognition-system-using-tensorflow-2326a3487cd5,所以我可能理解错了。
我相信一个好的方法是首先定位文本,然后进行分割,最后进行OCR。
我没有这方面的教程,我建议查阅相关文献,了解最新的技术进展。
你好,Jason,我一直感激您的出色教程。我正在尝试使用LSTM预测一个非常复杂的时间序列函数,但到目前为止,我在训练LSTM方面遇到了困难。我正在考虑将LSTM与1d CNN结合起来。我有以下问题
如果我先使用 `return_sequences=True` 的 LSTM,然后对其输出应用 1d CNN,与我先使用 1d CNN 然后使用 LSTM(如您此处所述)有什么区别?我将其概念化为 LSTM 提取时间特征,然后 1d CNN 提取一些更复杂的特征,因为这是一个非常复杂的函数。这有意义吗?老实说,我已经应用了这种方法,并且与仅使用 LSTM 的模型相比,取得了更好的结果。如果我的概念化是正确的,是否有可能可视化 LSTM 学习了哪些特征以及 CNN 学习了哪些特征?非常感谢您的提前指导。
LSTM 可以从原始数据中提取对 CNN 有用的特征。
在这个例子中听起来像是 CNN-LSTM
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
或许可以试试看?
感谢您的工作,Jason。您的文章给了我很多启发。
我有一个问题:为什么在Conv之后使用Flatten?不同激活的特征图并没有真正的时序依赖性,对吧?为什么不直接将数据传递给lstm(不进行Flatten),其中一个激活的特征图将代表lstm的一组特征?(即如果conv有64个核,lstm将有64个“序列”)
如果flattening确实有意义,我将非常感谢您的评论,因为我没有找到任何可以证实这种方法的论文。
谢谢你。
谢谢。
好问题,卷积层的输出是多个二维特征图,而全连接层或LSTM期望向量输入,因此我们需要扁平化。
论文很少讨论底层实现细节,尝试查看给定论文提供的代码。
我想知道 CNN LSTM 是否适合签名验证系统?
您能给我一些建议吗?
谢谢你
也许可以尝试一下。
嗨 Jason,我想知道您能否指导我。我对应用 CNN + LSTM 结构感到非常困惑。在我的结构中,样本数和序列数据数分别为 6000 和 20。此外,输入的尺寸是 2000*10*1。根据我的理解,我应该将输入定义为 5d。但我真的不知道输出的尺寸应该是多少。如果我将输出尺寸定义为 6000x1,我收到错误,它应该是 3d。在这种情况下,如果我将其定义为 6000x20x1,我认为在这种情况下我会犯错。因为,对于每个段,我将有一个输出。那么,数据的序列就没有被考虑。如果您能指导我,我将不胜感激。
也许本教程中的 CNN-LSTM 示例将对您有所帮助
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
嗨 Jason,请问如何创建时空时间序列预测模型?
需要添加哪些具体步骤来处理空间依赖性?
CNN-LSTM 将是一个很好的入门模型。
你好,Jason。
我可以使用 CNN + LSTM 进行音频分类吗?
也许可以尝试一下。
你好 Jason,
非常感谢您的这篇宝贵文章。我有一个案例问题,让我很困惑。
我有一个混合静态和动态特征的时空数据集。
我的问题是,我们是否可以将CNN-LSTM用于这个数据集?
此外,在数据集准备和动态特征方面,我有序列的可用数据;但是,对于使用基于此数据集构建的任何模型进行预测,我只能访问动态特征的初始步骤和静态特征。
您有什么建议吗?
谢谢你
是的,您可以有一个具有多个输入的模型,例如一个用于时空元素(cnn-lstm)和一个用于静态元素(密集)。
您可以使用函数式 API 实现这一点。
这将帮助您入门
https://machinelearning.org.cn/keras-functional-api-deep-learning/
非常感谢您的回复。
函数式API似乎能完美解决我数据集中静态和动态特征的问题。然而,一旦模型构建完成,它需要一系列不同时间步的动态特征来输入模型,但我只能访问初始时间步的动态特征来输入已构建的模型。
有没有办法使用这些模型来做到这一点?谢谢
是的,接受静态特征的子模型不需要知道“时间步”。
谢谢Jason的回复。我的问题出在动态数据上。在我的数据集中,我有一个包含动态(在不同时间步)和静态特征的数据集。但我的问题是,一旦在数据集上构建了任何模型,我只能提供初始时间步的动态数据加上静态数据。我没有一系列该动态特征来输入模型。
谢谢
您可以使用多输入模型,其中动态数据使用 CNN/LSTM,静态数据使用密集输入。
这可以通过函数式 API 实现
https://machinelearning.org.cn/keras-functional-api-deep-learning/
亲爱的Jason Brownlee,
恭喜您的精彩教程!真的很有帮助!顺便问一下,有没有可能有一个教程实际实现CNN+LSTM的这两个选项,并使用一些真实的图像数据(仅仅是为了实际演示)?
谢谢 🙂
谢谢!
是的,我有一些。也许可以从这里的示例开始
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
嗨,Jason,
我知道CNNLSTM可以用于从图像序列生成文本描述的应用。我的问题是从输入图像序列中预测活动曲线。
如果我有一系列动态3D医学图像(3D空间+1D时间=整体4D)以及不同部分随时间的活动(一系列1d标量向量),CNNLSTM或任何其他架构是否可以用于预测活动曲线?如果可以,CNN部分在这里会有何不同,因为我的任务不再是分类。
谢谢。
也许可以尝试一下,看看它在您的数据上是否有效。
CNN将从图像中提取特征,LSTM将对提取的特征序列进行操作。如果您处理的是日常事物的照片,我建议从预训练的CNN模型开始。
您好 Jason,感谢您的宝贵文章,
我有一个数据集,包括静态输入参数,以及一个依赖于时间的输出(并且我有这个输出在多个时间步的数据)。我已经为我的输出的每个时间步训练了 1D-CNN 模型(在我的例子中是用于回归)。所以,假设我有 10 个时间步的输出数据,并且我训练了 10 个不同的 1D-CNN 模型。
有没有办法在我的数据集(它不是图像或文本,它只是一个普通的表格数据集)上使用 CNN-LSTM 来训练它,使其能够学习我的输出的时间依赖性?
您可以有一个多输入模型,一个输入用于时间序列数据,另一个用于静态数据。
这将帮助您定义模型
https://machinelearning.org.cn/keras-functional-api-deep-learning/
我遇到的问题是,只有我的输出是随时间变化的。例如,我有30个静态参数,从31到40是我在不同时间步的输出参数。
我可以建立一个模型,将所有30个参数与第一个时间步的输出(第31列)或第二个时间步的输出(第32列)分别关联起来。
如果我使用API将它们分开,静态模型和时间序列模型的输入将是什么?
静态数据将作为输入提供给模型的静态部分,时间序列将提供给模型中期望序列数据的部分。
你好 Jason,
我有点困惑。如果我想构建一个一对多的CNN-LSTM模型,CNN和LSTM的输入形状会是怎样的。您在文章中提到它应该像这样
model = Sequential()
model.add(TimeDistributed(Conv2D(…))
model.add(TimeDistributed(MaxPooling2D(…)))
model.add(TimeDistributed(Flatten()))
model.add(LSTM(…))
model.add(Dense(…))
例如,如果我使用100张形状为(20,20,1)的照片来训练我的模型,其滤波器大小为64,核大小为(3*3),这些行会是什么样子?我们应该在哪里定义输出生成的时间步数?
谢谢你
好问题,您可以在本教程中看到一个工作示例
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
我的数据集包含 10 列和一个目标变量。目标变量有 4 个类别标签。
所以当我进行测试时,它应该预测类别标签。我可以使用 CNN-LSTM 来实现吗?
CNN-LSTM 仅适用于您的数据是时间序列或观测序列的情况。
在这种情况下,这里的示例将帮助您入门——并且您可以将其调整用于分类
https://machinelearning.org.cn/how-to-develop-convolutional-neural-network-models-for-time-series-forecasting/
嗨,感谢您的教程,
我想这样构建一个问题:
1. 想开发一个LSTM-CNN模型
2. 首先,我想在LSTM中应用目标变量的历史时间序列,用于提取时间信息。
3. 然后,我想将LSTM的输出和除目标变量之外的另一组输入变量作为输入应用到CNN模型中。
这可能吗?我该怎么做?
# 定义 LSTM 模型
model = Sequential()
model.add(LSTM(..))
model.add(Dense(…))
cnn=Sequential()
cnn.add(TimeDistributed(model,…))
cnn.add(Conv2D(…))
cnn.add(MaxPooling2D(…))
cnn.add(Flatten())
cnn.add(Dense())
我们可以对不同的输入集分别拟合LSTM和CNN吗?
有什么想法吗?
不客气。
这很奇怪。也许可以尝试一下,并将结果与更简单的模型进行比较,看看它表现更好还是更差。
AttributeError: ‘KerasTensor’ object has no attribute ‘add’
先生,我收到了这个错误
很抱歉听到这个消息,也许这个会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
您说要使用“一系列LSTM模型,每个时间步一个”,这相当令人困惑。
不应该只有一个LSTM模型,并且它被用于输入序列的所有时间步吗?使用多个LSTM模型是没有意义的。
我明白你为什么会那样想。但实际上,“序列”发生在 LSTM 模型产生状态 c 和 h 并将其传递到下一个时间步(就像编程中的递归)时。
我正在从事推荐系统的工作。我的数据是一个矩阵,行代表用户,列代表位置。如果我使用用户共享的照片作为序列,并使用位置照片作为序列。我可以使用CNN_LSTM将照片作为序列进行处理以进行预测吗?
嗨 Thaair…请重新表述或澄清您的问题,以便我们更好地协助您。
感谢您的精彩帖子。我有一系列图像时间序列,用于提取土壤湿度。除了这些图像,还需要将一些辅助数据集(如温度)作为输入特征参与到过程中。我考虑使用CNN-LSTM。现在我想知道这种方法是否对这个问题有用。如果您能分享您的意见,我将不胜感激。
提前感谢。
嗨 Mina…是的,CNN-LSTM模型和集成多样性可能会有益。
https://machinelearning.org.cn/ensemble-diversity-for-machine-learning/
非常感谢您的时间和快速回复。
亲爱的詹姆斯·卡迈克尔,
我有一个带有空白的图像时间序列。我想使用CNN-LSTM算法和辅助数据集来填充这些空白。实际上,我将带有空白的图像视为输出,并使用辅助数据集作为输入。我打算通过引入一个二元滤波器来指示算法何时有数据以及何时有空白。但我不知道如何在实践中实现这一部分。如果您能在这个问题上帮助我,我将不胜感激。
提前感谢您的帮助!
祝好,
米娜·拉赫马尼
我可以在LSTM层之前使用全连接层吗?我的问题似乎使用那种架构表现更好,但我不确定它是否正确。
嗨 Prerna…当然可以!那是一个混合模型的例子,当然是一个可选项。
我的皮肤癌二分类问题遇到了困难,我使用了许多模型,如VVG16... 我们设计了一个融合 CNN 和 LSTM 的混合模型,并获得了最佳结果,准确率为 90%。我的导师问我为什么 CNN 和 LSTM 能给我们带来测试结果,我该如何在学术上回答这个问题!?
感谢您的努力
数据集
健康 = 420
不健康 = 510
我们将数据集分为三部分:训练、验证和测试。
总参数
•模型总共有 2,432,231 个参数。
我的皮肤癌二分类问题遇到了困难,我使用了许多模型,如VVG16... 我们设计了一个融合 CNN 和 LSTM 的混合模型,并获得了最佳结果,准确率为 90%。我的导师问我为什么 CNN 和 LSTM 能给我们带来测试结果,我该如何在学术上回答这个问题!?
感谢您的努力
数据集
健康 = 420
不健康 = 510
我们将数据集分为三部分:训练、验证和测试。
你好 Jason,
我们有一个皮肤癌图像分类模型,我们从医院数据集自行收集数据,其中健康图像402张,不健康图像510张。我们训练了许多模型,大多数模型的准确率在60%到87%之间。我们设计了一个结合CNN和LSTM的模型,并获得了94%的准确率。我的导师问我为什么CNN和LSTM结合会得到最好的结果,请问我该如何学术地回答这个问题?
此致
嗨 Yasir…在与您的主管讨论 CNN-LSTM 模型的结果时,您可以组织您的解释,以清晰地传达方法和发现。以下是一些您可能需要考虑在讨论中包含的关键点:
1. **数据集描述**:首先详细说明从医院收集的数据集,具体说明健康皮肤癌图像(402张)和不健康皮肤癌图像(510张)的数量。解释用于准备数据进行训练的任何预处理或数据增强技术。
2. **模型比较**:简要概述最初尝试的各种模型的性能,提及它们的准确率范围(60% 到 87%)。这为理解 CNN-LSTM 模型带来的改进设定了基线。
3. **模型架构**:描述您设计的 CNN-LSTM 模型的架构。解释您选择将卷积神经网络 (CNN) 与长短期记忆网络 (LSTM) 结合的原因。通常,CNN 擅长处理空间数据(如图像),而 LSTM 擅长识别序列数据中的模式。将它们结合可以利用空间和序列线索,这在图像或其特征具有时间依赖性或您正在使用序列帧或补丁时可能特别有用。
4. **训练过程**:分享有关训练过程的详细信息,例如训练轮数、批次大小、学习率以及使用的任何特殊技术(如用于正则化的 dropout 或特定的优化器如 Adam)。
5. **结果**:突出显示实现的准确率(94%)并讨论其重要性。将其与之前测试过的模型的准确率进行比较,以强调改进。如果可用,您还可以提及其他性能指标(如敏感性、特异性、F1 分数)。
6. **解释和假设**:提出一个关于为什么 CNN 和 LSTM 的组合导致卓越性能的假设。这可能涉及讨论 LSTM 层如何捕获 CNN 层单独可能遗漏的额外上下文或纹理信息。
7. **进一步步骤**:建议进一步调查以验证模型,例如交叉验证、使用不同数据集进行外部验证,或在临床环境中部署模型以监控其在实际条件下的性能。
8. **可视化和演示**:如果可能,准备视觉辅助工具,如图表、损失曲线、随训练轮数变化的准确率趋势或混淆矩阵。这些可以帮助直观地展示模型的性能和稳健性。
这种结构化的方法不仅清晰地传达了您的发现和实验设置背后的原理,而且还展示了对当前任务的深思熟虑的分析和理解。