重采样方法旨在从训练数据集中添加或删除样本,以改变类别分布。
一旦类别分布更加平衡,就可以在转换后的数据集上成功拟合一套标准的机器学习分类算法。
过采样方法在少数类中复制或创建新的合成样本,而欠采样方法在多数类中删除或合并样本。两种重采样方法单独使用时都可以很有效,但当两种方法结合使用时效果可能更好。
在本教程中,您将学习如何组合过采样和欠采样技术来实现不平衡分类。
完成本教程后,您将了解:
- 如何定义一系列用于应用于训练数据集或评估分类器模型时的过采样和欠采样方法。
- 如何手动组合过采样和欠采样方法以实现不平衡分类。
- 如何使用预定义且性能良好的重采样方法组合来实现不平衡分类。
立即开始您的项目,阅读我的新书《Python 不平衡分类》,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。
- 2021 年 1 月更新:更新了 API 文档链接。

组合过采样和欠采样以实现不平衡分类
照片由 Radek Kucharski 拍摄,部分权利保留。
教程概述
本教程分为四个部分;它们是
- 二元测试问题和决策树模型
- Imbalanced-Learn 库
- 手动组合过采样和欠采样方法
- 手动组合随机过采样和欠采样
- 手动组合 SMOTE 和随机欠采样
- 使用预定义的重采样方法组合
- SMOTE 和 Tomek Links 欠采样组合
- SMOTE 和编辑最近邻欠采样组合
二元测试问题和决策树模型
在深入研究过采样和欠采样方法的组合之前,让我们定义一个合成数据集和模型。
我们可以使用 scikit-learn 库中的 make_classification() 函数定义一个合成二元分类数据集。
例如,我们可以创建 10,000 个具有两个输入变量和 1:100 类别分布的样本,如下所示:
|
1 2 3 4 |
... # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) |
然后,我们可以使用 Matplotlib 的 scatter() 函数创建数据集的散点图,以了解样本在每个类别中的空间关系及其不平衡性。
|
1 2 3 4 5 6 7 |
... # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
总而言之,创建不平衡分类数据集并绘制样本的完整示例列于下方。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 生成并绘制一个合成的不平衡分类数据集 from collections import Counter from sklearn.datasets import make_classification from matplotlib import pyplot from numpy import where # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # 总结类别分布 counter = Counter(y) print(counter) # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
运行该示例首先会总结类别分布,显示大约 1:100 的类别分布,其中类别 0 约有 10,000 个样本,类别 1 约有 100 个样本。
|
1 |
Counter({0: 9900, 1: 100}) |
接下来,创建了一个散点图,显示数据集中的所有样本。我们可以看到类别 0(蓝色)的大量样本以及类别 1(橙色)的少量样本。
我们还可以看到类别之间存在重叠,类别 1 的一些样本明显位于属于类别 0 的特征空间部分内。
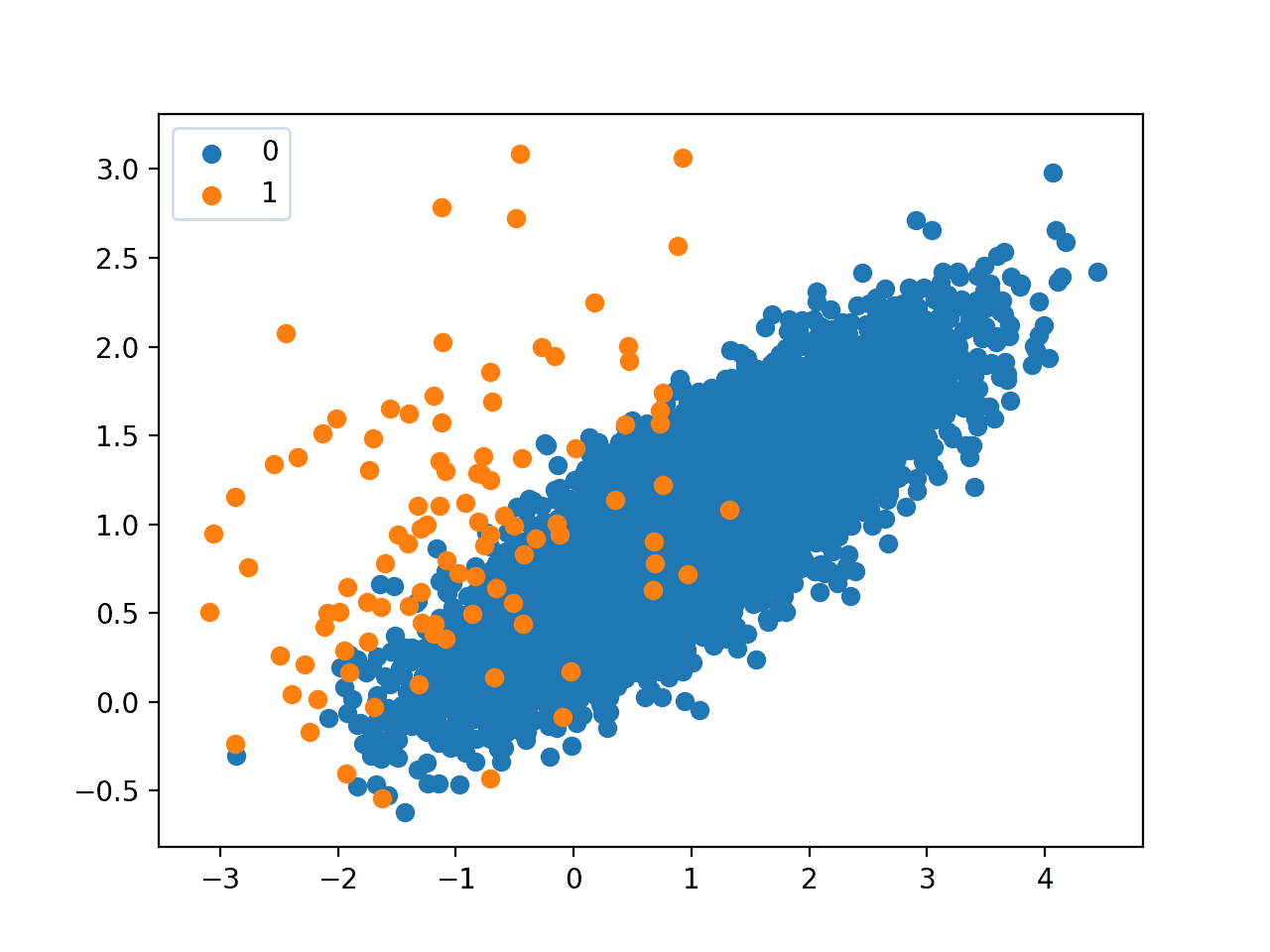
不平衡分类数据集的散点图
我们可以在此数据集上拟合一个 DecisionTreeClassifier 模型。这是一个很好的测试模型,因为它对训练数据中的类别分布敏感。
|
1 2 3 |
... # 定义模型 model = DecisionTreeClassifier() |
我们可以使用重复分层 k 折交叉验证,进行三次重复和 10 折来评估模型。
可以使用ROC 曲线下面积 (AUC) 指标来估计模型的性能。对于严重不平衡的数据集,它可能会过高估计,但它确实能正确显示模型性能的相对改进。
|
1 2 3 4 5 6 7 |
... # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(model, X, y, scoring='roc_auc', cv=cv, n_jobs=-1) # 总结性能 print('Mean ROC AUC: %.3f' % mean(scores)) |
总而言之,下面的示例在不平衡分类数据集上评估了一个决策树模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 在不平衡数据集上评估决策树模型 from numpy import mean from sklearn.datasets import make_classification from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold # 生成 2 类数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # 定义模型 model = DecisionTreeClassifier() # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(model, X, y, scoring='roc_auc', cv=cv, n_jobs=-1) # 总结性能 print('Mean ROC AUC: %.3f' % mean(scores)) |
运行该示例会报告决策树在数据集上的平均 ROC AUC,经过三次重复的 10 折交叉验证(即平均 30 次不同的模型评估)。
注意:由于算法或评估程序的随机性质,或者数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
在此示例中,可以看到该模型实现了约 0.76 的 ROC AUC。这为我们提供了在此数据集上的基线,我们可以用它来比较在训练数据集上应用不同过采样和欠采样方法组合的性能。
|
1 |
平均 ROC AUC:0.762 |
现在我们有了测试问题、模型和测试框架,让我们来看看重采样方法的组合。
想要开始学习不平衡分类吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
Imbalanced-Learn 库
在这些示例中,我们将使用 imbalanced-learn Python 库提供的实现,该库可以通过 pip 安装,如下所示:
|
1 |
sudo pip install imbalanced-learn |
您可以通过打印已安装库的版本来确认安装成功。
|
1 2 3 |
# 检查版本号 import imblearn print(imblearn.__version__) |
运行示例将打印已安装库的版本号;例如
|
1 |
0.5.0 |
手动组合过采样和欠采样方法
imbalanced-learn Python 库提供了多种重采样技术,以及一个 Pipeline 类,可用于创建一系列重采样方法的组合以应用于数据集。
我们可以使用 Pipeline 来构建一系列过采样和欠采样技术以应用于数据集。例如:
|
1 2 3 4 5 |
# 定义重采样 over = ... under = ... # 定义流水线 pipeline = Pipeline(steps=[('o', over), ('u', under)]) |
此 Pipeline 首先将过采样技术应用于数据集,然后将欠采样应用于过采样转换的输出,最后返回最终结果。它允许按顺序堆叠或应用转换到数据集。
然后,可以使用 Pipeline 来转换数据集;例如:
|
1 2 |
# 拟合并应用 pipeline X_resampled, y_resampled = pipeline.fit_resample(X, y) |
或者,可以将模型添加为 Pipeline 的最后一步。
这样,Pipeline 就可以被当作一个模型来处理。当它在训练数据集上拟合时,转换首先应用于训练数据集,然后将转换后的数据集提供给模型,以便其能够开发拟合。
|
1 2 3 4 5 6 7 8 |
... # 定义模型 model = ... # 定义重采样 over = ... under = ... # 定义流水线 pipeline = Pipeline(steps=[('o', over), ('u', under), ('m', model)]) |
请记住,重采样仅应用于训练数据集,而不应用于测试数据集。
当在k 折交叉验证中使用时,整个转换和拟合序列会应用于由交叉验证折组成的每个训练数据集。这一点很重要,因为转换和拟合都是在不知道保留集的情况下执行的,这可以避免数据泄露。例如:
|
1 2 3 4 5 |
... # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(pipeline, X, y, scoring='roc_auc', cv=cv, n_jobs=-1) |
现在我们知道了如何手动组合重采样方法,让我们来看看两个示例。
手动组合随机过采样和欠采样
组合重采样技术的良好起点是使用随机或朴素方法。
尽管它们很简单,并且单独使用时通常无效,但它们可以组合使用。
随机过采样涉及随机复制少数类中的样本,而随机欠采样涉及随机删除多数类中的样本。
由于这两种转换是针对不同的类别执行的,因此它们在训练数据集上的应用顺序无关紧要。
下面的示例定义了一个 Pipeline,该 Pipeline 首先将少数类过采样到多数类的 10%,然后将多数类欠采样到多数类的 50% 以上(相对于少数类),最后拟合一个决策树模型。
|
1 2 3 4 5 6 7 8 |
... # 定义模型 model = DecisionTreeClassifier() # 定义重采样 over = RandomOverSampler(sampling_strategy=0.1) under = RandomUnderSampler(sampling_strategy=0.5) # 定义流水线 pipeline = Pipeline(steps=[('o', over), ('u', under), ('m', model)]) |
在不平衡二元分类问题上评估此组合的完整示例列于下方。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 随机过采样和欠采样组合用于不平衡分类 from numpy import mean from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.tree import DecisionTreeClassifier from imblearn.pipeline import Pipeline from imblearn.over_sampling import RandomOverSampler from imblearn.under_sampling import RandomUnderSampler # 生成数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # 定义模型 model = DecisionTreeClassifier() # 定义重采样 over = RandomOverSampler(sampling_strategy=0.1) under = RandomUnderSampler(sampling_strategy=0.5) # 定义流水线 pipeline = Pipeline(steps=[('o', over), ('u', under), ('m', model)]) # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(pipeline, X, y, scoring='roc_auc', cv=cv, n_jobs=-1) # 总结性能 print('Mean ROC AUC: %.3f' % mean(scores)) |
运行该示例会评估转换系统和模型,并以平均 ROC AUC 总结性能。
注意:由于算法或评估程序的随机性质,或者数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
在这种情况下,我们可以看到 ROC AUC 性能从没有转换时的约 0.76 提升到使用随机过采样和欠采样时的约 0.81。
|
1 |
平均 ROC AUC:0.814 |
手动组合 SMOTE 和随机欠采样
我们不限于使用随机重采样方法。
也许最流行的过采样方法是合成少数类过采样技术(Synthetic Minority Oversampling Technique),简称 SMOTE。
SMOTE 通过选择在特征空间中接近的样本,在线条上绘制新样本。
该技术的作者建议在少数类上使用 SMOTE,然后对多数类使用欠采样技术。
SMOTE 和欠采样组合的性能优于单纯的欠采样。
— SMOTE: 合成少数类过采样技术, 2011。
我们可以将 SMOTE 与 RandomUnderSampler 结合使用。同样,这些过程的应用顺序无关紧要,因为它们是在训练数据集的不同子集上执行的。
下面的 Pipeline 实现此组合,首先应用 SMOTE 将少数类分布提高到多数类的 10%,然后使用 *RandomUnderSampler* 将多数类降低到比少数类多 50% 的水平,最后拟合一个 DecisionTreeClassifier。
|
1 2 3 4 5 6 7 |
... # 定义模型 model = DecisionTreeClassifier() # 定义流水线 over = SMOTE(sampling_strategy=0.1) under = RandomUnderSampler(sampling_strategy=0.5) steps = [('o', over), ('u', under), ('m', model)] |
下面的示例在我们不平衡的二元分类问题上评估此组合。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# SMOTE 和随机欠采样组合用于不平衡分类 from numpy import mean from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.tree import DecisionTreeClassifier from imblearn.pipeline import Pipeline from imblearn.over_sampling import SMOTE from imblearn.under_sampling import RandomUnderSampler # 生成数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # 定义模型 model = DecisionTreeClassifier() # 定义流水线 over = SMOTE(sampling_strategy=0.1) under = RandomUnderSampler(sampling_strategy=0.5) steps = [('o', over), ('u', under), ('m', model)] pipeline = Pipeline(steps=steps) # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(pipeline, X, y, scoring='roc_auc', cv=cv, n_jobs=-1) # 总结性能 print('Mean ROC AUC: %.3f' % mean(scores)) |
运行该示例会评估转换系统和模型,并以平均 ROC AUC 总结性能。
注意:由于算法或评估程序的随机性质,或者数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
在这种情况下,我们可以看到 ROC AUC 性能从约 0.81 进一步提高到约 0.83。
|
1 |
平均 ROC AUC:0.833 |
使用预定义的重采样方法组合
存在一些过采样和欠采样方法组合已被证明是有效的,并且它们共同构成了重采样技术。
两个例子是 SMOTE 与 Tomek Links 欠采样组合以及 SMOTE 与 Edited Nearest Neighbors 欠采样组合。
imbalanced-learn Python 库直接提供了这两种组合的实现。让我们逐一详细介绍。
SMOTE 和 Tomek Links 欠采样组合
SMOTE 是一种过采样方法,它在少数类中合成新的可行样本。
Tomek Links 是一种识别数据集中具有不同类别的最近邻对的方法。移除这些对中的一个或两个样本(例如,多数类中的样本)可以使训练数据中的决策边界不那么嘈杂或模糊。
Gustavo Batista 等人在他们 2003 年的论文《平衡训练数据以自动标注关键词:案例研究》中测试了组合这些方法。
具体来说,首先应用 SMOTE 方法将少数类过采样以达到平衡分布,然后识别并移除多数类中的 Tomek Links 样本。
在我们的工作中,我们只移除了构成 Tomek links 的多数类样本,因为少数类样本被认为过于稀少而无法丢弃。... 在我们的工作中,由于少数类样本是人工创建的,并且数据集目前是平衡的,因此会移除构成 Tomek link 的多数类和少数类样本。
— 平衡训练数据以自动标注关键词:案例研究, 2003。
该组合在二元分类任务中被证明可以减少假阴性,但会增加假阳性。
我们可以使用 SMOTETomek 类来实现此组合。
|
1 2 3 |
... # 定义重采样 resample = SMOTETomek() |
SMOTE 的配置可以通过“smote”参数设置,它接受一个配置好的 SMOTE 实例。Tomek Links 的配置可以通过“tomek”参数设置,它接受一个配置好的 TomekLinks 对象。
默认情况下,SMOTE 会平衡数据集,然后移除所有类别的 Tomek links。这是另一篇探讨此组合的论文所使用的方法,题为“研究几种平衡机器学习训练数据的方法的行为”。
… 我们建议将 Tomek links 应用于过采样后的训练集作为数据清理方法。因此,我们移除构成 Tomek links 的两个类别的样本。
— 研究几种平衡机器学习训练数据的方法的行为, 2004。
或者,我们可以将组合配置为仅移除多数类中的链接,如 2003 年的论文所述,通过将“tomek”参数设置为带有“sampling_strategy”参数的 *TomekLinks* 实例来仅对‘majority’类进行欠采样;例如:
|
1 2 3 |
... # 定义重采样 resample = SMOTETomek(tomek=TomekLinks(sampling_strategy='majority')) |
我们可以使用决策树分类器在我们的不平衡分类问题上评估此组合重采样策略。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# SMOTE 和 Tomek Links 重采样组合用于不平衡分类 from numpy import mean from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from imblearn.pipeline import Pipeline from sklearn.tree import DecisionTreeClassifier from imblearn.combine import SMOTETomek from imblearn.under_sampling import TomekLinks # 生成数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # 定义模型 model = DecisionTreeClassifier() # 定义重采样 resample = SMOTETomek(tomek=TomekLinks(sampling_strategy='majority')) # 定义流水线 pipeline = Pipeline(steps=[('r', resample), ('m', model)]) # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(pipeline, X, y, scoring='roc_auc', cv=cv, n_jobs=-1) # 总结性能 print('Mean ROC AUC: %.3f' % mean(scores)) |
运行该示例会评估转换系统和模型,并以平均 ROC AUC 总结性能。
注意:由于算法或评估程序的随机性质,或者数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
在这种情况下,似乎这种组合重采样策略并未为该模型在该数据集上提供任何优势。
|
1 |
平均 ROC AUC:0.815 |
SMOTE 和编辑最近邻欠采样组合
SMOTE 可能是最流行的过采样技术,并且可以与许多不同的欠采样技术结合。
另一种非常流行的欠采样方法是编辑最近邻(Edited Nearest Neighbors,简称 ENN)规则。该规则涉及使用 k=3 个最近邻来定位数据集中被错误分类并随后被删除的样本。它可以应用于所有类别,或者仅应用于多数类中的样本。
Gustavo Batista 等人在他们 2004 年的论文《研究几种平衡机器学习训练数据的方法的行为》中,比较了多种过采样和欠采样方法的组合与单独使用这些方法的效果。
这包括以下组合:
- 压缩最近邻 + Tomek Links
- SMOTE + Tomek Links
- SMOTE + Edited NearestNeighbors
关于最后一种组合,作者评论说 ENN 比 Tomek Links 更倾向于降低多数类的样本数量,提供了更深入的清理。他们应用该方法,从多数类和少数类两个类别中删除样本。
... ENN 用于从两个类别中删除样本。因此,任何被其三个最近邻错误分类的样本都将从训练集中删除。
— 研究几种平衡机器学习训练数据的方法的行为, 2004。
这可以通过 imbalanced-learn 库中的 SMOTEENN 类来实现。
|
1 2 3 |
... # 定义重采样 resample = SMOTEENN() |
SMOTE 配置可以通过“smote”参数设置为 SMOTE 对象,ENN 配置可以通过“enn”参数设置为 EditedNearestNeighbours 对象。SMOTE 默认会平衡分布,然后 ENN 默认会移除所有类别中被错误分类的样本。
我们可以通过将“enn”参数设置为一个具有 *sampling_strategy* 参数为‘majority’的 *EditedNearestNeighbours* 实例来更改 ENN 以仅移除多数类中的样本。
|
1 2 3 |
... # 定义重采样 resample = SMOTEENN(enn=EditedNearestNeighbours(sampling_strategy='majority')) |
我们可以使用决策树分类器在我们不平衡的数据集上评估默认策略(编辑所有类别的样本)。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# SMOTE 和编辑最近邻重采样组合用于不平衡分类 from numpy import mean from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from imblearn.pipeline import Pipeline from sklearn.tree import DecisionTreeClassifier from imblearn.combine import SMOTEENN # 生成数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # 定义模型 model = DecisionTreeClassifier() # 定义重采样 resample = SMOTEENN() # 定义流水线 pipeline = Pipeline(steps=[('r', resample), ('m', model)]) # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(pipeline, X, y, scoring='roc_auc', cv=cv, n_jobs=-1) # 总结性能 print('Mean ROC AUC: %.3f' % mean(scores)) |
运行该示例会评估转换系统和模型,并以平均 ROC AUC 总结性能。
注意:由于算法或评估程序的随机性质,或者数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
在这种情况下,我们看到性能比使用随机欠采样方法的 SMOTE 进一步提高,从约 0.81 提高到约 0.85。
|
1 |
平均 ROC AUC:0.856 |
这个结果凸显了编辑过采样后的少数类也可能是一个重要的考虑因素,很容易被忽略。
这与 2004 年的论文中的发现相同,该论文发现 SMOTE 与 Tomek Links 以及 SMOTE 与 ENN 在一系列数据集上表现良好。
我们的结果表明,过采样方法总体上,特别是对于具有少量正例(少数类)的数据集,Smote + Tomek 和 Smote + ENN(本工作中提出的两种方法)在实践中提供了非常好的结果。
— 研究几种平衡机器学习训练数据的方法的行为, 2004。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- SMOTE:合成少数过采样技术, 2011.
- 平衡训练数据以自动标注关键词:案例研究, 2003.
- 几种平衡机器学习训练数据方法的行为研究 (A Study of the Behavior of Several Methods for Balancing Machine Learning Training Data), 2004.
书籍
- 从不平衡数据集中学习 (Learning from Imbalanced Data Sets), 2018.
- 不平衡学习:基础、算法与应用 (Imbalanced Learning: Foundations, Algorithms, and Applications), 2013.
API
- Imbalanced-learn, GitHub.
- 过采样和欠采样组合, Imbalanced Learn 用户指南.
- imblearn.over_sampling.RandomOverSampler API.
- imblearn.pipeline.Pipeline API.
- imblearn.under_sampling.RandomUnderSampler API.
- imblearn.over_sampling.SMOTE API.
- imblearn.combine.SMOTETomek API.
- imblearn.combine.SMOTEENN API.
文章
总结
在本教程中,您学习了如何组合过采样和欠采样技术来实现不平衡分类。
具体来说,你学到了:
- 如何定义一系列用于应用于训练数据集或评估分类器模型时的过采样和欠采样方法。
- 如何手动组合过采样和欠采样方法以实现不平衡分类。
- 如何使用预定义且性能良好的重采样方法组合来实现不平衡分类。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
掌控不平衡分类!

在几分钟内开发不平衡学习模型
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 处理不平衡分类问题
它提供了关于以下内容的自学教程和端到端项目:
性能指标、欠采样方法、SMOTE、阈值移动、概率校准、成本敏感算法
以及更多...






对重采样技术的绝佳概述。谢谢!
我也只尝试了 plain under = RandomUnderSampler(sampling_strategy=0.5)
并且我获得了最佳分数
平均 ROC AUC: 0.864
所以看起来您总是需要尝试多种方法才能知道什么最适合您的数据集。
您对为什么随机欠采样在此数据集上效果最好有什么评论吗?
此致
干得好!
不,数据集仅用于演示目的——例如,展示如何使用该方法,我们并不试图获得最佳结果。
感谢您的回答,我现在明白了,这只是一个没有特定模式可供学习的随机合成数据集,因此随机采样是最佳保留分布的方法。如果数据集具有非随机模式并添加了一些噪声,那么一些重采样技术可能有助于锐化类别边界并帮助分类器学习模式。
嗨,Jason,
您提到欠采样和过采样仅适用于训练数据集,而不适用于验证集和测试集。在交叉验证管道中,Python 包会忽略验证集中的采样过程吗?请看下面
##############################################
# 随机过采样和欠采样组合用于不平衡分类
from numpy import mean
从 sklearn.datasets 导入 make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.tree import DecisionTreeClassifier
from imblearn.pipeline import Pipeline
from imblearn.over_sampling import RandomOverSampler
from imblearn.under_sampling import RandomUnderSampler
# 生成数据集
X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0,
n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1)
# 定义模型
model = DecisionTreeClassifier()
# 定义重采样
over = RandomOverSampler(sampling_strategy=0.1)
under = RandomUnderSampler(sampling_strategy=0.5)
# 定义流水线
pipeline = Pipeline(steps=[(‘o’, over), (‘u’, under), (‘m’, model)])
# 定义评估过程
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# 评估模型
scores = cross_val_score(pipeline, X, y, scoring=’roc_auc’, cv=cv, n_jobs=-1)
# 总结性能
print(‘平均 ROC AUC:%.3f’ % scores 的平均值)
是的。
干得好!
鉴于 SMOTE 在不平衡数据集的情况下很有用……
如果我们拥有均衡的数据,例如,每个类有 10 个样本,并且我们希望将它们人为地增加到每个类 20 个样本。
机器学习中是否有任何方法可以用于过采样平衡数据集?
SMOTE 有用,但并非总是如此,有时其他方法效果更好。这取决于数据集。
是的,您可以强制过采样方法创建更多合成样本。请参阅 API 文档。
抱歉 Jason,如果我错了,请纠正我。
我在各种论文中读到 SMOTE 只能在不平衡数据集的情况下使用?
使用 SMOTE 处理小规模平衡数据是否公平?
并非如此。也许可以尝试一下,看看它是否能提高您数据集的性能。
感谢您的工作,这很棒!
不过,我有几个问题,
在使用这些技术之前,是否最好对数据进行缩放?
它们在多大程度上会产生噪声?
在此先感谢,
Marine
在采样之前对数据进行缩放是个好主意,因为通常会使用 kNN 模型作为采样过程的一部分。
我有几个问题
1. 我们如何校准这些采样组合的概率?这里提到了两种单独欠采样和过采样的方法:http://www.data-mining-blog.com/tips-and-tutorials/overrepresentation-oversampling/ 和 https://www3.nd.edu/~dial/publications/dalpozzolo2015calibrating.pdf
2. 我们是否以不同的阈值来识别类别?
校准是通过没有数据采样的验证集进行的。
阈值设定在校准之后进行。
谢谢!我假设相同的校准方法(等渗/sigmoid)可以处理采样引起的偏差?
数据中的偏差已通过采样数据在拟合模型之前得到纠正。
如何在没有验证数据的情况下将 Smote 与 calibratedclassifiercv 一起使用……?
您可以使用训练集的一部分作为验证集。
你好 Jason,
为了适应数据集中的多个类别,我应该怎么做?
在计算指标或采样数据时,将正类和负类分组在一起。您需要告知算法什么是“正”案例。
非常感谢!
假设我有 3 个类别。我将有 3 种组合(即),类别 1 作为正例,类别 2、3 作为负例,以此类推。
我的理解正确吗?
不完全是,它会是这样的
正类:0、1
负类:2
对于一个模型/评估指标。
嗨 Jason
感谢您的精彩工作
我有一个不平衡的医学数据集,有 245 个少数类,760 个多数类,并且数据是分类类型的。这导致了糟糕的分类性能。我想提高分类性能并使用特征选择。
所以我使用了 chi2,然后应用了 EditedNearestNeighbours,获得了很好的改进。
现在,我想知道,在我进行特征选择之前使用 EditedNearestNeighbours 是否正确?
特征选择可能最好作为第一步。
我建议测试一套方法,以发现哪种方法效果最好,请参阅此内容
https://machinelearning.org.cn/framework-for-imbalanced-classification-projects/
您的最后一个示例使用管道来实现 SMOTEEN(),但当我运行代码时,它会显示 TypeError:所有中间步骤都应该是转换器并实现 fit 和 transform 或字符串“passthrough”'SMOTEENN()'(类型 )不是
我找到了我的错误。我使用了 sklearn 的管道。还有一个问题,我可以在重采样后标准化数据吗?
很高兴听到这个。
是的,尝试一下,看看它在采样之前或之后是否会产生差异。
请确保您使用的是 imbalanced-learn 项目中的 Pipeline 类,例如,确保您复制了完整代码列表中的所有代码。
……然后使用 RandomUnderSampler 将少数类减少到比少数类多 50% 的数量,然后拟合 DecisionTreeClassifier。
我认为您的意思是,
……然后使用 RandomUnderSampler 将多数类减少到比少数类多 50% 的数量,然后拟合 DecisionTreeClassifier。
谢谢!已修复。
您好。
我写了以下代码,但最后所有的二元值都变成了连续值。
谢谢你的帮助……
from imblearn.pipeline import Pipeline
pipeline1 = Pipeline([(‘impute’, SimpleImputer()),(‘scaler’,MinMaxScaler()), (‘balance’, SMOTE())])
SMOTE 假设输入是连续的,对于分类输入或混合输入,您必须使用 SMOTENC
https://imbalanced-learn.readthedocs.io/en/stable/generated/imblearn.over_sampling.SMOTENC.html
Jason,
您对 TF-IDF Vectorizer 有何看法?
是否应该先对整个语料库使用 TF_IDF,然后进行训练、测试拆分,或者
先进行训练测试拆分,然后执行 tf_vectorizer.fit_transform(train) 和 tf_vectorizer.transform(test)。
因此,问题是:先在整个数据上进行 TF-IDF,然后进行训练测试拆分,还是先进行训练测试拆分,然后进行 TF_IDF?
请看这个教程
https://machinelearning.org.cn/prepare-text-data-machine-learning-scikit-learn/
这并没有回答我问的问题。我们应该在进行训练测试拆分之前还是之后进行 TF-IDF?
如果是在之后,它是否应该只在训练数据上进行?
TFIDF 和其他转换器一样,应该在训练数据上进行拟合,然后应用于训练集和测试集。
您可以在此处了解将数据准备方法应用于数据以避免数据泄露的正确程序/顺序
https://machinelearning.org.cn/data-preparation-without-data-leakage/
你好,Jason!
精彩的文章!
只有一个问题
PCA 应该在重采样技术(smote、random undersampling、random oversampling……)之前还是之后应用?
提前感谢您!
谢谢。
好问题,也许可以尝试这两种方法,看看哪种方法最适合您的数据和模型。
我读过的最好的教程之一。谢谢!
谢谢!
你好,先生,
您在这里使用了
model = DecisionTreeClassifier()
# 定义流水线
over = SMOTE(sampling_strategy=0.1)
under = RandomUnderSampler(sampling_strategy=0.5)
steps = [(‘o’, over), (‘u’, under), (‘m’, model)]
管道 = Pipeline(steps=steps)
# 定义评估过程
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) 然后
scores = cross_val_score(pipeline, X, y, scoring=’roc_auc’, cv=cv, n_jobs=-1)
但是,如果我想在训练数据集上应用 RandomUnderSampler、RepeatedStratifiedFold 和决策树模型,该如何应用?
上面的例子正是这样做的。
也许我不明白你遇到的问题?
是的,谢谢,在交叉验证中我们做同样的事情。
Jason,
这里的东西很好。如果您想在用 GridsearchCV 拟合的管道中使用这些过采样/欠采样技术,关于如何防止过采样/欠采样技术在测试性能时应用到测试/泛化数据集的想法?考虑到 GridsearchCV 将拟合一个估计器/管道到整个训练数据集,然后在我们应用 predict 或 score 将该估计器/管道应用于保留的测试集时,它将在管道中应用相同的转换到测试集。
谢谢
杰夫
是的,管道将确保方法仅在内部训练集上进行拟合,并在内部测试集上应用。
这就是使用管道的主要好处。
但我认为您不想对保留/测试集进行过采样/欠采样,对吗?我从您的博客中了解到,您想在过采样/欠采样训练集上训练模型,但在测试时针对具有正常类别分布的数据集进行测试。因为模型在实际操作中将处理的就是这种情况。
谢谢
杰夫
是的,过采样/欠采样不适用于测试/保留数据。管道可以识别这一点。
如果您手动拟合/应用管道,您必须考虑到这一点。
在其中一行写着——“SMOTE 是一种过采样方法,它在多数类中合成新的合理示例。”
如果我错了,请纠正我,它不应该是少数类吗?
根据微软的文档
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/smote#:~:text=SMOTE%20stands%20for%20Synthetic%20Minority,dataset%20in%20a%20balanced%20way.&text=SMOTE%20takes%20the%20entire%20dataset,of%20only%20the%20minority%20cases.
它被列为——
“该模块通过生成输入中提供的现有少数类的新实例来工作。此 SMOTE 实现不会更改多数类的数量。”
是的,少数类,是拼写错误。已修正。
在此处了解更多关于 smote 的信息
https://machinelearning.org.cn/smote-oversampling-for-imbalanced-classification/
嗨,Jason!
非常有趣的论文。是否可以在 R 中进行组合过采样和欠采样(例如:SMOTE+ Random Undersampling)?如果可以,您能否制作一篇关于如何在 R 中进行混合采样的文章。非常感谢。
谢谢你。
你好……感谢您的推荐!它将为未来的内容提供考虑。
嗨,我对此声明有些困惑。
“请记住,重采样仅应用于训练数据集,而不应用于测试数据集。”
为什么我们不对测试数据进行平衡,而只对训练数据进行平衡?
如果我们对训练数据进行了平衡,但没有对测试数据进行平衡,那么我们需要评估模型是否使用了为不平衡数据集设计的指标(例如 G-mean、ROAUC 等),因为我们的测试数据仍然不平衡,并且测试数据中少数类的实例很少。
嗨 Zaa……以下资源可能对您有兴趣
https://towardsdatascience.com/the-complete-guide-to-resampling-methods-and-regularization-in-python-5037f4f8ae23