一致地比较多个不同机器学习算法的性能非常重要。
在这篇文章中,您将了解如何使用 scikit-learn 在 Python 中创建测试平台来比较多个不同的机器学习算法。
您可以将此测试平台用作您自己的机器学习问题的模板,并添加更多不同的算法进行比较。
通过我的新书 《Python 机器学习精通》 开启您的项目,其中包含分步教程以及所有示例的Python 源代码文件。
让我们开始吧。
- **2018 年 3 月更新**:添加了下载数据集的备用链接,因为原始链接似乎已被删除。

如何在 Python 中使用 scikit-learn 比较机器学习算法
照片由 Michael Knight 拍摄,保留部分权利。
选择最佳机器学习模型
如何为你的问题选择最佳模型?
当你从事机器学习项目时,你通常会得到多个不错的模型可供选择。每个模型都有不同的性能特征。
通过使用交叉验证等重采样方法,你可以估计每个模型在未见过的数据上的准确性。你需要能够使用这些估计来从你创建的模型库中选择一到两个最佳模型。
仔细比较机器学习模型
当你有一个新数据集时,最好使用不同的技术来可视化数据,以便从不同角度观察数据。
模型选择也同样适用。你应该使用多种方法来查看你机器学习算法的估计准确性,以便选择一到两个最终模型。
一种方法是使用不同的可视化方法来显示平均准确性、方差以及模型准确性分布的其他属性。
在下一节中,您将确切地了解如何在 Python 中使用 scikit-learn 来实现这一点。
需要 Python 机器学习方面的帮助吗?
参加我为期 2 周的免费电子邮件课程,探索数据准备、算法等等(附带代码)。
立即点击注册,还将免费获得本课程的 PDF 电子书版本。
一致地比较机器学习算法
公平比较机器学习算法的关键是确保每个算法都在相同的数据上以相同的方式进行评估。
您可以通过强制每个算法在一个一致的测试平台上进行评估来实现这一点。
在下面的示例中,比较了 6 种不同的算法。
- 逻辑回归
- 线性判别分析
- K-最近邻
- 分类与回归树
- 朴素贝叶斯
- 支持向量机
问题是一个标准的二元分类数据集,称为 Pima 印第安人糖尿病发病问题。该问题有两类和八个不同尺度的数值输入变量。
你可以在此处了解更多关于此数据集的信息:
使用 10 折交叉验证程序来评估每种算法,重要的是配置相同的随机种子,以确保执行对训练数据的相同分割,并且每种算法都以完全相同的方式进行评估。
每种算法都有一个简短的名称,便于之后总结结果。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
# 比较算法 import pandas import matplotlib.pyplot as plt from sklearn import model_selection from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.discriminant_analysis import LinearDiscriminantAnalysis from sklearn.naive_bayes import GaussianNB from sklearn.svm import SVC # 加载数据集 url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = pandas.read_csv(url, names=names) array = dataframe.values X = array[:,0:8] Y = array[:,8] # 准备交叉验证测试平台的配置 seed = 7 # 准备模型 models = [] models.append(('LR', LogisticRegression())) models.append(('LDA', LinearDiscriminantAnalysis())) models.append(('KNN', KNeighborsClassifier())) models.append(('CART', DecisionTreeClassifier())) models.append(('NB', GaussianNB())) models.append(('SVM', SVC())) # 依次评估每个模型 results = [] names = [] scoring = 'accuracy' for name, model in models: kfold = model_selection.KFold(n_splits=10, random_state=seed) cv_results = model_selection.cross_val_score(model, X, Y, cv=kfold, scoring=scoring) results.append(cv_results) names.append(name) msg = "%s: %f (%f)" % (name, cv_results.mean(), cv_results.std()) print(msg) # 绘制算法比较箱线图 fig = plt.figure() fig.suptitle('算法比较') ax = fig.add_subplot(111) plt.boxplot(results) 轴.设置X轴标签(名称) plt.show() |
注意:由于算法或评估程序的随机性,或者数值精度差异,您的结果可能会有所不同。请考虑运行示例几次并比较平均结果。
运行该示例将提供每种算法的简称、平均准确性和标准差准确性列表。
|
1 2 3 4 5 6 |
LR: 0.769515 (0.048411) LDA: 0.773462 (0.051592) KNN: 0.726555 (0.061821) CART: 0.695232 (0.062517) NB: 0.755178 (0.042766) SVM: 0.651025 (0.072141) |
该示例还提供了一个箱线图,显示了每种算法在每个交叉验证折叠上的准确性得分的分布。
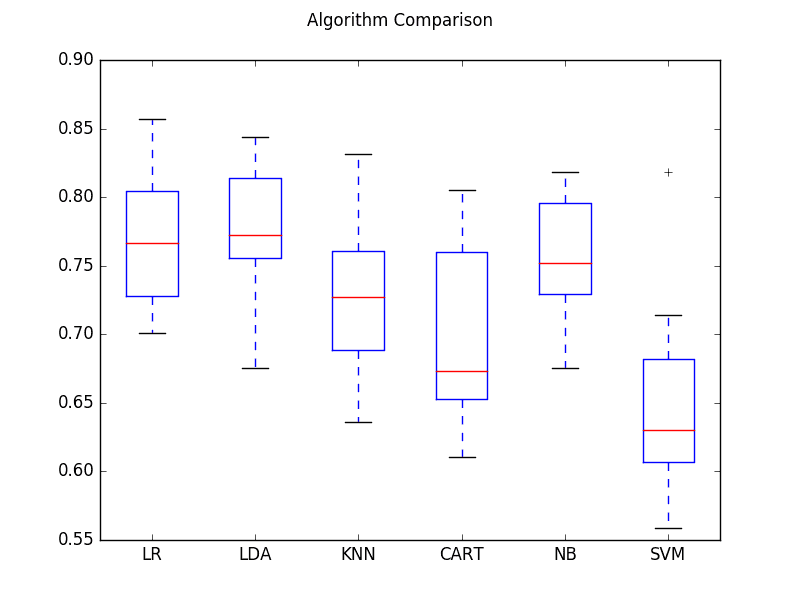
比较机器学习算法
从这些结果来看,这表明逻辑回归和线性判别分析在这类问题上可能都值得进一步研究。
总结
在这篇文章中,您学习了如何使用 scikit-learn 在 Python 中在一个数据集上评估多个不同的机器学习算法。
您学会了如何使用相同的测试平台来评估算法,以及如何以数值方式和使用箱线图来总结结果。
您可以将此方法作为模板,用于在您自己的问题上评估多个算法。
您对在 Python 中评估机器学习算法或本文有任何疑问吗?请在下面的评论区提问,我将尽力回答。
发现 Python 中的快速机器学习!

在几分钟内开发您自己的模型
...只需几行 scikit-learn 代码
在我的新电子书中学习如何操作
精通 Python 机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、建模、调优等等...
最终将机器学习带入
您自己的项目
跳过学术理论。只看结果。




")

很棒的文章!只是一个快速的问题,您认为哪种方法最好?先优化超参数,然后再比较算法,还是反之?谢谢。
我建议先进行初步检查算法并进行比较,然后再进行调整。
感谢您的建议……
您不应仅依赖于此。准确性只是模型准确性的一部分。根据所需的调查,您应该查看精确率和召回率,因为准确性可能只是一小部分。另外,为什么您没有采用方差分析或 Wilcoxon 检验的方法,这些都是数据科学领域内的主要且被广泛接受的检验?此外,应该进行 5x2 交叉验证,而不是 10 折(这是被广泛接受的)。最后,我发现这里完全缺失的是您没有讨论如何做出统计上显著的决策。这不是一个好的代表。
Eric,没有人关心你的博士学位,无论你是在哪个领域获得的。另外,不要在你只是做回归的时候称之为方差分析,这并不能让你更聪明。最后,没有人关心你的博士学位和学术研究,这是一篇面向数据科学家的机器学习文章。
总有改进的空间,而且我们必须从一个入门性的文章开始/停止。
没错
接下来我们如何比较预测值与实际值?
尊敬的布朗利博士,
非常喜欢您的教程。我有一个关于先比较后调优方法的问题。当我们将其绘制在箱线图上并选择最佳模型时,这都是基于默认模型设置的,对吗?但是一旦我们调整了给定模型中的不同设置,预测性能是否会有所不同?
那么,如果正确训练了这些模型,一些不太好的模型甚至可能优于第一眼看到的箱线图中显示的最佳模型。那么,从这个意义上说,单独训练每个模块,然后连接所有模块并绘制它们的 ROC 曲线以查看哪个表现最佳,是否会更好呢?
当然,如果您有资源的话。
尊敬的 Bronwlee 博士,
感谢所有有用的教程。如果方便的话,我有两个问题。
1- 最好先对数据进行归一化,因为有些算法对其敏感?例如 KNN 和神经网络。
2- 我在比较另一个数据集的某些算法后获得了以下排名:
在调整超参数之前:随机森林、决策树、逻辑回归、SVM
在调整超参数之后:随机森林、逻辑回归、SVM、决策树
因此,您认为我们应该先调整超参数,然后再比较机器学习算法吗?
提前感谢您的回答。
是的,先缩放是一个好主意,但要进行测试以确认它能提升模型技能。
谢谢您的回答。
请,我还有一个最后的问题。
由于结果也取决于随机状态,我们是否应该使用不同的值并为每种机器学习算法保留平均准确性?
提前感谢。
是的。我在这里对此有更详细的解释。
https://machinelearning.org.cn/randomness-in-machine-learning/
还有这里
https://machinelearning.org.cn/evaluate-skill-deep-learning-models/
准确性很容易理解,但在我看来,它应该被 AUC 取代:AUC 比准确性“一致”且“更具辨别力”(Ling 等人,2003 年)。
AUC 可以在 ROC 曲线或精确率-召回率曲线中进行检查。应该基于混淆矩阵中的误分类进行权重调整。在这种情况下,您可以调整模型以避免某些误分类,因为避免某些误分类可能更有价值。如果您根本不关心发生哪种误分类,ROC 是如何调整参数的一个不错的指标。ROC 应该用于超参数决策。
那就自己写一篇文章吧。
哈哈哈,这个人似乎讨厌 Eric……而且既然是匿名的,这可能就是作者。
在代码中,“seed = 7”是硬编码的。每个折叠应该有不同的种子吗?
回答我自己的问题,似乎每个模型在移到下一个模型之前都会被训练和测试所有折叠。种子适用于初始状态,因此对于上述情况,10 个折叠将彼此不同,但相同的 数据分割将呈现给每个算法。
是的,Tom,种子确保我们拥有相同的随机数序列。随机数确保我们将数据随机分割成 k 个折叠。
谢谢分享。
我不得不稍微调整代码,使其能够与 scikit-learn 0.18 一起工作。
cross_validation 模块已弃用。它被 model_selection 取代了。
KFold 参数也发生了变化。
0.17: cross_validation.KFold(n, n_folds=3, shuffle=False, random_state=None)
0.18: model_selection.KFold(n_splits=3, shuffle=False, random_state=None)
我有一个问题:在将分类器添加到列表之前对其进行训练是否可以?例如
lr = LogisticRegression()
lr.fit(X_train, y_train)
models.append((‘LR’,lr))
谢谢 Guillaume,我会看看更新示例。我最近更新了我所有的书籍以支持新的 sklearn。
不可以,示例的结构是合适的,并且会逐个评估每个模型。您的示例基本上展开了 for 循环。
多么棒的文章!我从您的写作中学到了很多东西。
我还阅读了您关于比较 R 中不同算法的文章,我注意到您在那篇文章中使用了更多的技术。
• 表格摘要
• 箱线图
• 密度图
• 点图
• 平行图
• 散点图矩阵
• 成对 xy 图
• 统计显著性检验
我想知道为什么您没有在这篇 Python 文章中提供相同的技术?是因为这些功能在 R 中更易于获得吗?
非常感谢!
很好的问题。
这些功能在 Python 中都可用,但分布在 scipy 和 statsmodels 库中,而不是直接在 sklearn 中可用。
R 是一个更技术性的平台,面向更技术型的人,我倾向于在那些示例中提供更多细节。
Angela,您想看到更多这方面的内容吗?
嗨 Jason。感谢您提供这些精彩的文章。我还阅读了您的这篇文章(https://goo.gl/v71GPT)。我好奇的是正确的验证方法。我们应该进行 k-fold 还是重复的 n*k-fold 交叉验证?我最近读了一篇期刊文章,研究人员在 5x2 折的设置下比较了大约 50 种模型,认为它更稳健。我们应该如何进行模型比较?
嗨 Suleyman,
使用 k-fold 交叉验证是黄金标准。具体的配置是针对特定问题的,但常见的配置 3、5、10 在许多数据集上效果都很好。
对于非常大的数据集,训练-测试分割可能就足够了。对于复杂或小型数据集,如果您有资源,则首选重复的 k-fold 交叉验证。通常,我们希望使用重复的 k-fold 交叉验证,但计算成本太高。
没有“最佳”,只有很多选项可以根据您遇到的问题进行调整。
如何选择?
平衡您的约束(数据量、资源、时间等)和您的要求(结果的稳健性)。
谢谢 Jason。我一直在这样做。
坚持使用 5x2。嵌套交叉验证是公认的,而且远远优于常规的 k-fold。
嗨,Jason,
非常感谢这篇好文章。
您能对标准差值进行一些解释吗?
特别是关于过拟合。
我曾认为,如果 cv 结果的标准差较小,我们会遇到更多过拟合,但我不确定。
谢谢
嗨 Othmane,好问题。
因此,标准差总结了分布的散布情况,假设它是高斯分布。
紧密的散布可能表明过拟合,也可能不表明,但只有通过在保留集上评估模型才能确定。
标准差的一个用途是为结果指定置信区间。例如,模型在未见过的数据上的性能是 x%,在性能范围是该分数 2 个标准差(95% 百分位数)内。
这个可能会有帮助
https://en.wikipedia.org/wiki/68%E2%80%9395%E2%80%9399.7_rule
感谢您的提示,对结果的解释这个主题的讨论还不够充分。我计划写更多关于它的内容。
遵循 Othmane 的问题,我们是否应该使用平均值的标准误差而不是标准差?基本上是将标准差除以 sqrt(10)。这是因为“统计量(最常见的是平均值)的标准误差是其抽样分布的标准差”。https://en.wikipedia.org/wiki/Standard_error
可以,我有一个关于计算标准误差的示例,在此处:
https://machinelearning.org.cn/estimate-number-experiment-repeats-stochastic-machine-learning-algorithms/
我在这里有计算置信区间的示例:
https://machinelearning.org.cn/report-classifier-performance-confidence-intervals/
和这里
https://machinelearning.org.cn/calculate-bootstrap-confidence-intervals-machine-learning-results-python/
你好,从箱线图来看,LR 和 LDA 的准确性更高,所以我们选择它们作为我们的模型。
那么现在,我可以对测试数据应用 train_test_split 来检查这两种模型的 RMSE 和准确性吗?哪个提供最佳结果,我将选择它作为我的最终模型?
嗨 Dhrubajit,
有许多选择最终模型的方法。通常我们更喜欢平均性能更好的模型,而不是绝对性能更好的模型,这是因为模型在未见过的数据上的性能估计存在自然差异。
一旦您选择了最终模型,就在所有可用数据上进行训练,然后就可以开始使用它来做出预测了。
很棒的文章!请您解释一下为什么当Y是浮点数时,这个程序就无法正常工作?
您好 Peter,
分类问题假设结果是一个标签。
很棒的帖子!感谢分享
谢谢 Edmond。
嗨,Jason,
我已开始学习和实现机器学习算法。
一个问题——上面的博客会告诉我们选择哪个机器学习算法。然而,如果我们使用回归,我们是否应该通过检查来了解回归与数据的拟合程度
自相关、多重共线性与正态性。
我从阅读博客和文章中学到的是,我们都使用交叉验证方法来计算分数,然后找出最适合的模型。我还没有看到有人遵循传统方法,例如检查自相关、多重共线性与正态性。我可能错了。请对此说明一下。
谢谢 Nitesh
是的,在时间序列上,理解自相关几乎是必须的。
在使用线性方法时,了解多重共线性会有帮助。
我建议在研究模型之前进行此类分析,以便更好地了解您问题的结构。
您好 Jason!首先,感谢您所有的博文,它们对我更好地理解如何处理数据集和机器学习算法非常有帮助。
我有一个关于评分方法的问题。在发现您在这里使用的方法之前,我曾这样使用 .score() 方法(假设我已经将数据集分割为80/20,并转换了数据)
from sklearn.svm import LinearSVC
lin_svc = LinearSVC()
lin_svc.fit(train_set_scaled, train_set_labels)
lin_svc.score(test_set_scaled, test_set_labels)
得到的评分与本文介绍的方法相似但不同。使用 score() 和使用 cross_val_score() 有什么区别?
谢谢!
好问题。
cross_val_score() 函数使用更鲁棒的交叉验证方法来评估模型技能
https://scikit-learn.cn/stable/modules/generated/sklearn.model_selection.cross_val_score.html#sklearn.model_selection.cross_val_score
模型上的 score() 函数评估模型在提供的数据集上的技能。
https://scikit-learn.cn/stable/modules/generated/sklearn.svm.LinearSVC.html#sklearn.svm.LinearSVC.score
这有帮助吗?
在使用上面提到的相同代码比较算法时,我遇到了一个错误“无法将字符串转换为浮点数”。
您能告诉我如何解决这个问题吗?
确认您已准确复制代码,并且您正在使用相同的数据文件。另外,请确认您的所有 Python 库都是最新的。
谢谢 Jason。
实际上我正在使用不同的数据集。我的数据集与股票有关。那么在比较算法时,我该怎么办?
你好,
非常感谢这个教程。它确实帮助我更好地使用 sklearn 中的机器学习。
一个问题:我正尝试使用我的数据集来使用此代码,但我有一些特征是字符串而不是数字,就像在您的数据集中一样。
我该如何修改代码才能使其正常工作?(我收到一个错误消息“无法将字符串转换为浮点数”)
如果它们是标签,您可以使用标签编码器。
如果您正在处理字符串输入,请参阅 NLP
https://machinelearning.org.cn/start-here/#nlp
Jason 博士您好!非常感谢您提供的这篇精彩文章。我有一个问题想请教您。我注意到您在 Python 迷你课程中没有提到特征选择和特征工程。那么,如果我们要在当前这个阶段进行特征选择和特征工程,它们的顺序应该是什么?是应该在比较机器学习算法之后,先选定一到两个表现最佳的模型,然后进行特征选择和特征工程,还是应该先进行特征选择和特征工程,然后再进行模型选择和比较?
提前感谢。
通常在进行抽样检查之前。
感谢您的回答!但是,“通常”这个词帮助不大。您能否解释一下在哪些情况下建议这样做,在哪些情况下不建议这样做?我认为这对我来说非常重要。
不,这取决于数据和项目。我必须笼统地回答,因为我没有能力深入到每个人的项目中。抱歉。
哦,好的。希望随着我做更多项目能学会。谢谢!
感谢您提供的精彩教程!如果我们已经将数据分割为训练集和测试集,并想知道训练模型在保留的测试数据上的准确性,我们可以这样做吗?
cv_results = model_selection.cross_val_score(model, X_test, Y_test, cv=kfold, scoring=scoring)
或者在测试测试数据之前,我们需要先在训练数据上使用 .fit() 吗?希望这个问题有意义!谢谢。
通常,我们会用整个训练集来训练模型,对测试集进行预测,然后评估预测在测试集上的表现。
啊,好的,所以上述方法只是用于比较模型吗?然后我们使用例如 0.2 的分割来进行训练/测试?您会真正使用交叉验证来训练您的模型吗?非常感谢。
不,您会在所有数据上训练模型,然后再进行预测。请参阅此帖子
https://machinelearning.org.cn/train-final-machine-learning-model/
感谢您提供的精彩教程!我能理解逻辑,但 UCI 似乎已下架 Pima Indians 数据集。
谢谢,我已经更新了数据集的链接。
感谢您发布的 Jason。然而,我很好奇,在比较具有略微不同特征的 ML 模型时,通常会报告哪些分数。例如,有一组特征是模型 A 和 B 共有的,A 还有一个唯一的特征,B 也有一个,但 A 没有训练过。在评估这些模型以进行比较时,我们应该在测试集上报告和比较分数,还是使用 cross_val_score 并使用所有数据?
有意思。
也许您可以选择一个与通用领域相关的度量,它可以是一些通用的度量,例如模型准确性或预测误差。
感谢您的回复,我正在考虑使用 MAE 或 MSE,因为我的问题是回归问题,看看哪个模型能获得最低分数。
但是,我不知道,一般实践是什么,我们应该像这样比较两个模型吗?
A:使用 cross_val_score 报告回归器的 MSE 和 X、y,其中 X 和 y 是整个数据(无训练/测试分割)
或者
B:进行训练/测试分割,使用训练数据拟合模型,然后使用测试数据进行预测,并比较模型的 MSE 分数
测试工具的选择和配置是应用机器学习挑战的重要组成部分。
它必须针对您的具体问题进行定制。
嗨,Jason博士,
感谢您提供的这篇精彩的帖子。我有一个关于复杂性的问题。我们通常使用准确率来评估学习算法的性能。是否有任何措施来衡量算法完成给定任务所需的时间(即速度)?我在您帖子中使用的一个代码中添加了一个 timeit 函数,如下所示:
%timeit results = cross_val_score(bcancermodelb, X, Y, cv=kfold,scoring=scoring)
print(“Accuracy: %.3f%% (%.3f%%)” % (results.mean()*100.0, results.std()*100.0))
然后我得到了以下结果:
19.2 毫秒 ± 1.08 毫秒/循环 (7 次运行的平均值 ± 标准偏差, 10 次循环/运行)
准确率:93.420% (3.623%)。
这是否可以作为衡量特定模型所需时间的良好指标?
通常不。如果这是您模型中的一个重要考虑因素,那么您可以将其纳入考量。
嗨,Jason,
我对得到的箱线图感到有些困惑。我在我的数据集上比较了 9 种算法的准确率,这些数据集具有 90 多个特征。结果有点令人困惑,因为只有 LDA 的准确率超过 90%,而其他模型的准确率在 20% 到 40% 之间。这个图是有效的,我可以认为 LDA 是最好的模型吗?
也许可以检查原始数据以确认发现。
您好,我遇到了这个错误,为什么会这样?
ValueError: Input contains NaN, infinity or a value too large for dtype(‘float64’).
也许可以检查您的输入数据是否已正确加载?
cv_results = model_selection.cross_val_score(model, X, Y, cv=kfold,scoring=scoring)
这行可能出错了
请确保您准确复制了代码,保留了空格。
您好,您是怎么解决您的问题的?
如果我使用上面的代码,我会收到以下错误消息。(Python 3.6 – Spyder)
for name, model in models
文件“”,第 1 行
for name, model in models
^
SyntaxError: 解析时遇到意外的 EOF
看起来您添加了一个“,”。
请确保准确复制代码。
我找到了错误。
很高兴听到这个消息。
请解释一下:“preg’、‘plas’、‘pres’、‘skin’、‘test’、‘mass’、‘pedi’、‘age’、‘class’”
它们在这里有解释
https://github.com/jbrownlee/Datasets/blob/master/pima-indians-diabetes.names
嗨 Jason
从您的例子中,我如何获得每个算法的混淆矩阵?还有 TP FP TN 和 FN 来计算每个算法的预测和召回率?谢谢!
这篇帖子解释了混淆矩阵,并展示了如何计算它
https://machinelearning.org.cn/confusion-matrix-machine-learning/
谢谢 Jason。
您好,问题是我知道实际值(Y),但在本例中找不到如何获取/打印每个算法的预测值?
这篇帖子解释了如何使用 sklearn 进行预测
https://machinelearning.org.cn/make-predictions-scikit-learn/
非常感谢您提供的所有帖子。它们非常有帮助。
我很高兴它们有帮助!
你好先生,
我的问题的准确率很低,您能否建议我改进一下?
LDA:0.581771 (0.052691)
KNN:0.523047 (0.054386)
CART:0.606641 (0.044246)
NB:0.562109 (0.089570)
SVM:0.554167 (0.099744)
是的,我在这里有一些建议
https://machinelearning.org.cn/machine-learning-performance-improvement-cheat-sheet/
我的代码有问题。
在这一行 kfold = model_selection.KFold(n_splits=6, random_state=seed)
我的数据集包含 4 个数值输入和两个类别。
我需要知道 seeds 和 n-splits 的含义或它们指的是什么?
请尽快回复。
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/what-value-should-i-set-for-the-random-number-seed
你好,先生,
我正在尝试构建一个 Web 工具作为我项目的一部分。它允许用户上传数据集并根据此代码绘制不同算法的准确率。我尝试使用此代码处理了许多数据集,发现此代码不适用于太大的数据集,例如包含 2*10^6 行和 30 列的数据集。您能告诉我数据集的最大大小,以便能够正常运行吗?
我相信它会随着可用 RAM 的量而扩展。
对于更大的数据集,最好使用渐进式加载或大数据框架。
感谢您,Brownlee 博士,提供的这个教程。
您提到结果表明,逻辑回归和线性判别分析都值得在此问题上进一步研究。
我们如何比较两个箱线图(例如,逻辑回归和线性判别分析)来确定哪个更好?
也许可以多次评估每个模型,并比较它们的均值(平均值的平均值及其分布)。
感谢您提供的这篇精彩帖子。我正在处理客户流失问题,已经应用了 LR、RF、SVM、KNN,当我将您的代码应用于 x_test 和 y_test 而不是 X、Y 时,我得到了以下输出。我这样做是否正确,比如应该将什么数据传递给 X 和 Y?训练集还是测试集??请尽快回复。
谢谢你
LR:0.762319 (0.024232)
SVM:0.666667 (0.033747)
KNN:0.598551 (0.030891)
RF:0.779710 (0.027430)
抱歉,我不明白您的问题,也许您可以换一种说法或详细说明?
Jason 您好,感谢您提供的这篇帖子。我如何使用您的模板为每个模型进行超参数调优?例如,假设我想调整 KNN 的“邻居数量”,决策树的“树的深度”等等。我正在考虑在主循环中再加一个循环来进行超参数调优。对我来说棘手的部分是如何将参数值传递给模型?
我推荐这篇帖子来结合抽样检查和一些调优
https://machinelearning.org.cn/spot-check-machine-learning-algorithms-in-python/
您好,Jason,我想您能否帮我一个忙。
(1)我的本科论文是关于设计一个算法或几个代码块,基于神经网络,特别是深度神经网络。
(2)但我还需要比较深度学习和浅层学习的性能,例如准确率和其他指标。
因此,基于这两项任务,我是否有高效的实现方法?能否像您一样导入 sklearn 中的一些现有内容?但我不太确定我能用 sklearn 做什么。我曾将我的论文视为一项从头开始重构蒸馏器的任务。这似乎不值得我付出努力,但我不确定。您怎么看?
我建议您与您的研究导师讨论您的顾虑。
嗨,Jason,
感谢您在Python中比较不同预测模型的文章。我目前正在尝试使用均方根百分比误差(RMSPE)来比较回归问题中的不同预测模型。我使用了您如下的交叉验证代码:
我得到了以下结果:
LM: -8679071434605513.000000 (7381730822398656.000000)
Ridge: -9344356403286348.000000 (5680597868319848.000000)
Lasso: -8214240415834513.000000 (6885019346742973.000000)
RandomForest: -6671926010255401.000000 (5635345468122856.000000)
gbm: -5373061987919916.000000 (5191299686435015.000000)
请问如何将这些结果转换为RMSPE,并在箱线图中显示?我已经将数据集分割成了训练集和测试集。谢谢!
这些分数太大了!
您可能想在建模之前对数据进行缩放?
“results”变量是一个列表,可以直接绘制成箱线图,然后您可以有一个列表的列表用于一系列箱线图。
嗨,Jason,
谢谢您的回复。但是,我的特征包含类别和数值变量。在这种情况下,我该如何进行缩放?我通常没有缩放数据的习惯。谢谢!
只缩放数值特征。只有在使用整数编码时才缩放类别特征。
感谢您发表的精彩文章,也感谢您的慷慨和回复!我正在使用Pyspark平台构建模型,该平台能够从海量数据集中提供见解并预测风险。您能推荐我使用哪些参数来比较机器学习算法,以便在Pyspark上获得最佳的准确性和性能吗?
谢谢!
我建议测试一套算法配置,以发现最适合您特定数据集的方法。
我在这里解释了更多
https://machinelearning.org.cn/faq/single-faq/what-algorithm-config-should-i-use
Brownlee博士,这是一篇很棒的文章。
请问,我该如何使用大数据集来测试和比较不同的机器学习算法?
有什么参考资料吗?Kuggle算是一个大数据的好例子吗?
谢谢。
也许您可以使用大数据框架。抱歉,我没有这方面的教程。
好贴!!!
嗨 Jason,
我正在预测候选人的前3项技能。在比较实际值与预测值时,我遇到了问题,在比较实际值和预测值时,前3个类别是根据最高概率排序并映射到类别的,而在实际值中只有类别标签,当我们比较这些值时,它们会产生偏差。请您提供如何进行的建议。
此致,
Naveen
也许您的问题是多标签分类问题,而不是多类别分类问题?
如果是这样,这篇论文可能会给您一些关于如何评估技能的思路:
https://scholar.google.com/scholar?cluster=11211211207326445005&hl=en&as_sdt=0,5
嗨,Jason,
非常感谢您这篇精彩的文章。我遇到了一个问题,我的数据集中共有124414个观测值,因变量是二元的(0和1),但是数据集中有124388个零和只有106个一。您能告诉我如何处理这种情况吗?
也许可以尝试一套模型,看看问题是否可以学习?
我尝试了几个模型。训练集和测试集的准确率都很高。您认为这正常吗?
LogisticRegressionCV
0.999153
0.999138
KNeighborsClassifier
1
0.999028
DecisionTreeClassifier
1
0.998766
GaussianNB
0.997454
0.997272
LinearDiscriminantAnalysis
0.994809
0.994139
您的项目可能很容易解决,或者测试数据不能代表更广泛的问题。
嗨,Jason,
我想问您如何将我的结果与种子进行比较,以及与未指定种子的其他用户的不同种子的结果进行比较?
您可以多次运行,使用不同的种子,并比较所有运行的平均性能。
嗨,Jason,
我想请教您,已知一些测量点,如何用python拟合两个特征变量的曲线,并得到相应的表达式?您能否通过sklearn,通过scipy的curve_fit函数来实现?谢谢,期待您的回复!
我相信scipy有用于此的多项式模型,例如:
https://docs.scipy.org.cn/doc/numpy/reference/generated/numpy.polyfit.html
嗨,Jason,
感谢您关于比较Python中不同模型的文章。
在比较不同预测模型时,我使用了您的交叉验证代码如下:
results = []
names = []
scoring = ‘accuracy’
for name, model in models
kfold = model_selection.KFold(n_splits=10, random_state=seed)
cv_results = model_selection.cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
results.append(cv_results)
names.append(name)
msg = “%s: %f (%f)” % (name, cv_results.mean(), cv_results.std())
print(msg)
但是,我收到一个警告消息,如下:“gamma的默认值将从‘auto’更改为‘scale’,以便在0.22版本中更好地处理未缩放的特征。请将gamma显式设置为‘auto’或‘scale’以避免此警告”。
请问,我该如何处理?
是的,这篇文章展示了如何处理:
https://machinelearning.org.cn/how-to-fix-futurewarning-messages-in-scikit-learn/
感谢您的快速回复。此外,这篇文章确实非常有帮助。但是,在运行代码后,我只能获得支持向量机(Support Victor Machine)的简称以及相应的平均准确率和标准差,而不是提供所有算法的简称、平均准确率和标准差准确率的列表。
请问,需要添加什么来解决这个问题?
我对我的积极回应感到满意。
提前感谢。
抱歉,我没明白。您具体遇到了什么问题?
Brownlee博士您好,感谢您的文章!您能否帮助我解决一个问题?我需要比较两种不同的深度学习算法在解决相同分类任务上的性能,使用相同的数据集。首先,我定义了最大参数数量,并将其用于两种模型,因此,尽管模型完全不同,但它们在参数方面具有相同的复杂度。2)我还考虑了其他超参数,例如dropout率、epochs数量和batch size。最后,我获得了具有优化超参数的两种模型。现在,我将通过优化情况下的交叉验证结果(指标的均值和标准差)来比较它们的性能,然后检查它们在测试集上的性能。这种方法正确吗?
这听起来是个不错的方法。
可以确保两种方法在相同数量的折叠上进行测试,并且测试过程重复3-30次。
谢谢 🙂
不客气。
Jason 博士您好
为什么您不使用统计检验来比较算法?
您可以在大型项目上进行。
我尽量让每个教程都专注于一个问题。
您会推荐哪种测试来比较算法?
如果我有一个训练集和一个测试集。
您能告诉我哪种情况是正确的吗?
1-我使用EarlyStopping(早停法)来处理训练损失,同时在训练集上拟合模型。然后,我在测试集上测试模型。
2-我在某个epoch将模型拟合到训练集上,而不使用EarlyStopping。然后,我在测试集上测试模型。
谢谢你
您在训练集上训练,在验证集上使用早停法,并在测试集上评估模型。
更多信息在这里
https://machinelearning.org.cn/difference-test-validation-datasets/
还有这里
https://machinelearning.org.cn/early-stopping-to-avoid-overtraining-neural-network-models/
感谢Jason提供的这个有用的例子。我将其作为我的分析模板。
您是否有这样的例子,您使用交叉验证的留一法(leave-one-out)而不是K折交叉验证?
谢谢
Amora
干得好!
是的,从这里开始
https://machinelearning.org.cn/k-fold-cross-validation/
Jason,如果我将K设置为N(我的数据集中的总样本数),这是否就像LOO(留一法)一样工作?换句话说,如果我运行上面的代码并将k从10更改为N(我的数据集中有395个样本),这是否就像LOO算法一样工作?
for name, model in models
kfold = model_selection.KFold(n_splits=395 random_state=None)
cv_results = model_selection.cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
results.append(cv_results)
names.append(name)
msg = “%s: %f (%f)” % (name, cv_results.mean(), cv_results.std())
print(msg)
是的,或者您也可以直接使用LOOCV。
https://scikit-learn.cn/stable/modules/generated/sklearn.model_selection.LeaveOneOut.html
两者都做同样的事情。
嗨,Jason博士
我有点困惑,我们应该如何进行,在选择了最佳模型(并且进行了超参数调整)之后?通常,在没有交叉验证的情况下,我们会比较训练分数和测试分数,以查看模型是否过拟合。但是,使用交叉验证时,我最初将数据集分割为训练集和测试集,并使用训练集进行交叉验证。之后,我应该如何处理测试集?我应该用训练集拟合模型,然后将测试分数与从交叉验证中获得的分数进行比较吗?
谢谢!
一种方法是,如果数据集很小,则使用所有数据进行交叉验证并比较分数。
如果您有很多数据,请使用训练数据上的交叉验证来选择模型,并在验证数据上进行调优。
博士您好,
我有一个疑问。根据您的例子,在选择模型的评估阶段,我们通常选择准确率最高的模型(使用交叉验证)。但是,如果我们获得评估准确率和训练准确率(我的意思是不仅打印评估准确率,还打印训练准确率),有时通过这两个值之间的差异,我们可以推断出具有最高评估准确率的模型正在过拟合。在这种情况下,我们是否应该选择一个不同的算法,尽管它的准确率较低,但我们知道它没有过拟合问题?
谢谢你的帮助!
理想情况下,您应该将模型训练到过拟合之前,或者使用可防止过拟合的测试框架。
博士您好,
我遵循了您的文章(这是一篇非常好的文章,我必须说),并获得了以下图表:
https://ibb.co/9WcQWFy
我一直试图获得训练准确率,以发现潜在的过拟合迹象。
我的疑问是,我选择了RFC算法。但是,训练准确率为100%。由于这是训练准确率,这个值正常吗?您有什么建议?我是否应该选择另一个在训练集上不给出100%准确率的算法,因为RFC过拟合了?
谢谢!
我建议查看留出测试集的准确率,而不是训练集的准确率。
感谢您的回复!留出测试集的准确率为82%。我认为我的疑问是,我应该将什么与留出测试集进行比较,以识别潜在的过拟合。我应该将此值与RFC测试获得的94%进行比较吗?
将一个模型的留出性能与一个朴素模型的留出性能进行比较。
https://machinelearning.org.cn/faq/single-faq/how-to-know-if-a-model-has-good-performance
如何使用scikit-learn在Python中比较机器学习算法,如果问题数据集是回归而不是二元分类,也就是说,当目标是“连续”时?
使用回归算法和不同的误差指标,如平均绝对误差。
嗨,Jason,
感谢您的文章。
我想知道,比较同一问题的不同深度学习模型的最佳方法是什么?
谢谢
使用一致的测试框架,例如训练/测试分割或k折交叉验证,理想情况下重复评估以克服学习算法的随机性。
请看这个教程
https://machinelearning.org.cn/evaluate-skill-deep-learning-models/
好文章。
我在我的数据集上训练了一个Tiny yolov3模型,并得到了一个model.h5。
我修改了这个模型并得到了它的三个不同版本,也训练了它们并得到了每个版本的model.h5。我该如何比较它们,就像您做的那样?
在相同的留出测试集上评估每个模型,并比较选定的性能指标。
嗨,Jason,
感谢您的教程。它们极大地帮助了我理解机器学习。
我有一个类似的问题,可能对您来说很幼稚,但我认为您是我的逻辑途径。
我有一个二元分类数据集,我使用了十几种机器学习算法来训练、测试、分类并比较了我的准确率。我观察到算法及其模型在相同和不同数据集上的表现各不相同,给出了不同的特征重要性来预测标签。
因此,我想得到一些想法来处理为什么一个机器学习算法比另一个表现更好,以及如何获得统一的结果。
任何意见都值得赞赏。
感谢您的时间。
不客气。
一些算法比其他算法表现更好是理所当然的,因为它们使用不同的表示和优化算法。
我们作为从业者的工作是发现对给定数据集最有效的方法。
我在那里找到了一个类似的例子。
https://towardsdatascience.com/quickly-test-multiple-models-a98477476f0
感谢分享。
Jason您好,如果我使用相同的算法(逻辑回归、随机森林等)和一个神经网络。我该如何比较或将神经网络添加到与其他算法的比较中?
非常感谢。
祝您有美好的一天!
Diana
您可以使用您的测试框架来估算每种方法的性能,并直接比较每种方法的平均性能。
先生,我可以使用此代码运行我的数据集吗?
是的,加载您的数据集并比较评估结果。
先生您好,解释得很棒。我是这个领域的新手,您能告诉我该写什么来获得这些算法的f1分数吗?谢谢。
这将帮助您计算f1。
https://machinelearning.org.cn/fbeta-measure-for-machine-learning/
嗨,谢谢您的教程。
不过我有一个问题,我正在做一个“有毒评论检测”的项目,我有4个类别 [仇恨言论, 噪音, 中性, 支持],我的模型输出的是每个类别的概率,我想将我的模型与一个现有的API进行比较,这个API只返回评论的类别(不返回概率),目前我使用的是准确率,但我认为这并不是最好的衡量标准,有没有一个更好的、更公平的衡量标准来比较两者?当我使用ROC得分时,我认为这对于API来说不公平,因为当它出错时,它会犯下最大的错误(预测1而实际是0比预测0.8而实际是0更糟)。
不客气。
ROC得分不适用,因为你有多个类别。
也许这会有帮助。
https://machinelearning.org.cn/tour-of-evaluation-metrics-for-imbalanced-classification/
执行此代码时出现错误,你能帮我吗?
通常我不会帮助调试,但请发布错误信息。我会快速看一下。
你好!我该如何比较模型,如果我使用了这个代码3次,第一次是原始的6个模型,第二次是对6个模型进行过采样,第三次是对6个模型进行欠采样,我保存了不同的分数和结果(results、results1和results2),但我找不到一种方法来比较这18个模型。
谢谢!
如果你得到了分数,为什么不能进行比较?
Brownlee 博士,
非常感谢这个精彩的教程。我将其应用于回归问题。它适用于LR、SVR、DT和RF。
我尝试添加深度学习。结果不确定。请看下面。
# 模型准备
models = []
models.append((‘LR’, LinearRegression()))
models.append((‘SVR’, SVR()))
models.append((‘DT’, DecisionTreeRegressor()))
models.append((‘RF’, RandomForestRegressor()))
models.append((‘DL’, KerasRegressor()))
#models.append((‘DL’, Sequential()))
当我添加KerasRegressor()时,我收到了错误消息:AttributeError: ‘KerasRegressor’ object has no attribute ‘__call__’
当我用Sequential()替换KerasRegressor()时,我收到了这个错误消息
TypeError: Cannot clone object ” (type ): it does not seem to be a scikit-learn estimator as it does not implement a ‘get_params’ method。
也许我这样做是错的。非常感谢任何帮助。
你好Kim-Ndor… 感谢提问。
我很想帮忙,但我实在没有能力为您调试代码。
我很乐意提出一些建议
考虑将代码积极削减到最低要求。这将帮助您隔离问题并专注于它。
考虑将问题简化为一个或几个简单的例子。
考虑寻找其他可行的类似代码示例,并慢慢修改它们以满足您的需求。这可能会暴露您的失误。
考虑在 StackOverflow 上发布您的问题和代码。
亲爱的布朗利博士,
根据我之前的帖子,我想补充以下内容:
models.append((‘DL’, Sequential())) 在模型准备时不会抛出错误消息。
但是,在运行模型评估时,我得到了前四个算法的结果
LR: -0.169154 (0.072120)
SVR: -0.101527 (0.040932)
DT: -0.200274 (0.057728)
RF: -0.117059 (0.034939)
加上
.
.
TypeError: Cannot clone object ” (type ): it does not seem to be a scikit-learn estimator as it does not implement a ‘get_params’ method。
models.append((‘DL’, KerasRegressor())) 在运行模型准备时会给出AttributeError: ‘KerasRegressor’ object has no attribute ‘__call__’
在运行模型准备时
以下是我的所有模型
# 模型准备
models = []
models.append((‘LR’, LinearRegression()))
models.append((‘SVR’, SVR()))
models.append((‘DT’, DecisionTreeRegressor()))
models.append((‘RF’, RandomForestRegressor()))
#models.append((‘DL’, KerasRegressor()))
models.append((‘DL’, Sequential()))
我先是使用了KerasRegressor(),然后改用了Sequential()来看看是否有效。
此致,
Kim
I
感谢Kim的反馈!
亲爱的Carmichael,
抱歉,我的第一条消息没有显示出来。我需要帮助将深度学习添加到前四个算法中。我正在运行回归问题。
在这种情况下,是否不能追加KerasRegressor()?我在我之前的帖子中粘贴了错误消息。欢迎任何帮助。
下面是模型准备。
# 模型准备
models = []
models.append((‘LR’, LinearRegression()))
models.append((‘SVR’, SVR()))
models.append((‘DT’, DecisionTreeRegressor()))
models.append((‘RF’, RandomForestRegressor()))
#models.append((‘DL’, KerasRegressor()))
models.append((‘DL’, Sequential()))
请问我有一个问题,我构建了一个姿态估计项目,但还没有在其中添加机器学习算法。
我正在犹豫使用哪一个,我的问题是帮助人们通过计算输入视频中的关键点之间的角度来更好地进行物理治疗练习。
你好Esraa…你能详细说明一下你所说的“已经构建了项目”是什么意思吗?这是否意味着你已经收集了输入数据并对其进行了预处理?
我想一起计算准确率、精确率、召回率、F1分数,使用此代码一次性运行,我应该怎么做?
你好Bhuvaneshwari…以下资源可能对你有帮助。
https://machinelearning.org.cn/how-to-calculate-precision-recall-f1-and-more-for-deep-learning-models/
你好
我有以下数据框,我想为每个模型的每个指标绘制箱线图。也就是说,我需要为准确率绘制3个箱线图,其他指标也一样。
模型 准确率 灵敏度 特异度 MCC
0 ACPred-BMF 80.81 88.37 73.26 62
1 ACP-MHCN 73.00 78.50 67.40 46
2 提议模型 95.33 91.65 97.08 88
请提供Python代码
谢谢 & 顺祝商祺
你好Shahid…以下资源是一个很好的起点,关于使用Matplotlib创建箱线图
https://www.geeksforgeeks.org/box-plot-in-python-using-matplotlib/