Caret R 包允许您轻松构建许多不同的模型类型并调整其参数。
在创建和调整了许多模型类型之后,您可能想知道并选择最佳模型,以便您可以使用它来做出预测,尤其是在操作环境中。
在本帖中,您将了解如何使用 caret R 包比较多个模型的结果。
通过我的新书《R 机器学习精通》开始您的项目,其中包括分步教程以及所有示例的R 源代码文件。
让我们开始吧。
比较机器学习模型
在处理某个问题时,您会选择一个或少数几个表现良好的模型。在调整了每个模型的参数后,您将希望比较这些模型,找出哪些表现最好,哪些表现最差。
了解模型的分布很有用,也许其中一个可以改进,或者您可以停止研究一个明显比其他模型表现差的模型。
在下面的示例中,我们比较了 Pima Indians 糖尿病数据集中的三个复杂的机器学习模型。此数据集是医学报告集合的摘要,表明了患者在五年内患糖尿病的迹象。
你可以在此处了解更多关于此数据集的信息:
构建和调整的三个模型是学习向量量化 (LVQ)、随机梯度提升(也称为梯度提升机或 GBM)和支持向量机 (SVM)。每个模型都经过自动调整,并使用 3 次重复的 10 折交叉验证进行评估。
在训练每个算法之前设置随机数种子,以确保每个算法获得相同的数据分区和重复。这使我们能够进行公平的比较。或者,我们可以忽略此问题,将重复次数增加到 30 或 100 次,利用随机性来控制数据分区的变化。
需要更多关于R机器学习的帮助吗?
参加我为期14天的免费电子邮件课程,了解如何在您的项目中使用R(附带示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
一旦模型训练完成并为每个模型找到最佳参数配置,就会收集每个最佳模型的准确性结果。每个“获胜”模型都有 30 个结果(3 次重复的 10 折交叉验证)。比较结果的目标是比较模型之间的准确性分布(30 个值)。
这有三种方式。分布以百分位数的概念进行总结。分布以箱形图的形式进行总结,最后分布以点图的形式进行总结。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 加载库 library(mlbench) library(caret) # 加载数据集 data(PimaIndiansDiabetes) # 准备训练方案 control <- trainControl(method="repeatedcv", number=10, repeats=3) # 训练 LVQ 模型 set.seed(7) modelLvq <- train(diabetes~., data=PimaIndiansDiabetes, method="lvq", trControl=control) # 训练 GBM 模型 set.seed(7) modelGbm <- train(diabetes~., data=PimaIndiansDiabetes, method="gbm", trControl=control, verbose=FALSE) # 训练 SVM 模型 set.seed(7) modelSvm <- train(diabetes~., data=PimaIndiansDiabetes, method="svmRadial", trControl=control) # 收集重采样结果 results <- resamples(list(LVQ=modelLvq, GBM=modelGbm, SVM=modelSvm)) # 总结分布 summary(results) # 结果的箱形图 bwplot(results) # 结果的点图 dotplot(results) |
下面是总结每个模型分布结果的表格。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
Models: LVQ, GBM, SVM Number of resamples: 30 准确度 Min. 1st Qu. Median Mean 3rd Qu. Max. NA's LVQ 0.5921 0.6623 0.6928 0.6935 0.7273 0.7922 0 GBM 0.7013 0.7403 0.7662 0.7665 0.7890 0.8442 0 SVM 0.6711 0.7403 0.7582 0.7651 0.7890 0.8961 0 Kappa Min. 1st Qu. Median Mean 3rd Qu. Max. NA's LVQ 0.03125 0.1607 0.2819 0.2650 0.3845 0.5103 0 GBM 0.32690 0.3981 0.4638 0.4663 0.5213 0.6426 0 SVM 0.21870 0.3889 0.4167 0.4520 0.5003 0.7638 0 |
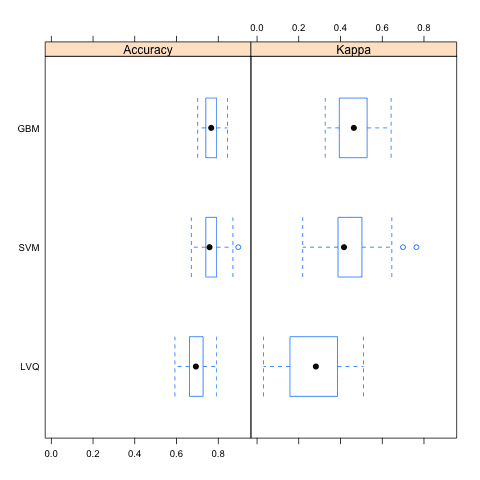
使用 Caret R 包比较模型结果的箱形图
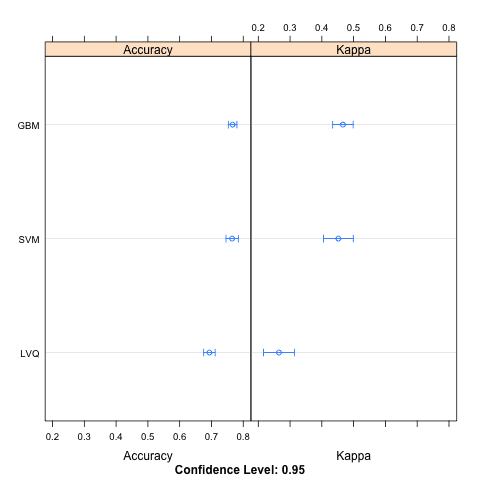
使用 Caret R 包比较模型结果的点图
如果您需要就哪个算法更好做出有力的声明,您还可以使用统计假设检验来统计地证明结果的差异是显著的。
如果结果呈正态分布,则使用学生 t 检验;如果分布未知,则使用秩和检验。
总结
在本帖中,您了解了如何使用 caret R 包来比较多个不同模型的结果,即使在优化了它们的参数之后。您看到了三种比较结果的方式:表格、箱形图和点图。
本帖中的示例是独立的,您可以轻松地将它们复制并粘贴到您自己的项目中,并针对您的问题进行改编。
在R中发现更快的机器学习!

在几分钟内开发您自己的模型
...只需几行R代码
在我的新电子书中探索如何实现
精通 R 语言机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、构建模型、调优等等...
最终将机器学习应用到您自己的项目中
跳过学术理论。只看结果。




做得很好
谢谢!
Jason,做得很好,
非常感谢。
很棒的参考。谢谢🙂
如果您有 50 个模型,每个模型都有特定的调优网格需要训练、预测和比较,您能否建议一个 R 代码?
我有一个,但太慢了。
这对非参数模型是否可接受?如果不是,您能否建议任何方法来选择最佳模型?
你好,请问如何解读模型比较的最终结果(即箱形图和点图)?最佳模型是箱形图中准确率最高的模型,还是箱形区域较小的模型(偏差较小)?
非常感谢!
Qiaojing,好问题,这确实取决于您的问题。
也许您更关注平均性能,或者更关注性能的不确定性。
谢谢,很棒的帖子。非常有帮助!
很高兴您觉得它有帮助 Aldo。
说真的,这是一篇很棒的帖子,对大家都有帮助!!
谢谢。
好帖子!为了讨论,您会建议在一种情况下,您已经穷尽了特征选择,而前两个模型的性能图大致相同,并且 t 检验给出了一个大的 p 值。在这种情况下,什么都无法得出结论,而且我找不到改进它们的方法。您会查看其中每个模型在统计学上相关的变量吗?抛硬币?您会考虑复杂性吗?谢谢!我真的很喜欢您在帖子中包含代码。
有关改进性能的一般建议,请参阅此帖
https://machinelearning.org.cn/machine-learning-performance-improvement-cheat-sheet/
您也可以尝试性能良好但无关联的模型集成,以及随机子空间变量的集成,看看是否能得到一些有趣的结果。
干得好!很有用😀
谢谢 pablo。
好文章!
谢谢,很高兴听到您喜欢它 Calu。
我学会了从这个例子的摘要对象中检索特定数据,如下所示
test=summary(results)
print(test)
myMean=test$statistics$Accuracy[,4]
myModelName=names(myMean[1])
myModleVal=myMean[[myModelName]]
myIndex=length(myMean)
for(i in 1:myIndex){
myModelName=names(myMean[i])
myModelVal=myMean[[myModelName]]
print(myModelName)
print(myModelVal)
}
如何从摘要对象生成或检索 RMSE/MSE 值?
我遇到了以下错误,尝试将我自己的源数据实现到此示例中
> modelLvq <- train(n2~., data=series, method="lvq", trControl=control)
错误:回归模型类型错误
哪里出错了?
也许检查一下您的数据?
是否有办法检查特定模型需要哪些数据?
我不确定您的意思。您的工作是为模型定义数据,包括特征工程
https://machinelearning.org.cn/discover-feature-engineering-how-to-engineer-features-and-how-to-get-good-at-it/
我们无法知道什么会起作用最好,我们必须通过经验发现最能捕捉行为的特征。
我还收到
Error in terms.formula(formula, data = data)
公式中的“.”并且没有“data”参数
有什么提示吗?是因为我不再有 #library(mlbench) 了吗?
mlbench 中还有什么?
我尝试将我自己的源数据实现到此示例中。
它有一个包含日期的列和一个包含 1 到 30 的数字的列。
我设法用 read_csv() 替换了 data(PimaIndiansDiabetes)。
在 train 部分,我说例如
modelLvq <- train(n2~., data=series, method="lvq", trControl=control)
...其中 n2 是我的列标题。
为什么我会收到这么多错误?
警告消息
1: In .local(x, …) : Variable(s) `' constant. Cannot scale data.
2: In nominalTrainWorkflow(x = x, y = y, wts = weights, info = trainInfo,
重采样性能度量中存在缺失值。
这个例子中关键的数据结构依赖部分是什么?
我再也看不到了?mlbench 库的闭源中是否有任何内容?
mlbench 是一个 R 包
https://cran.r-project.cn/web/packages/mlbench/index.html
r1 = resamples( list (gbm_bc=gbm_bc , ada_yj= ada_y j) )
## 此处,gbm:梯度提升,ada:adaboost
summary(r1)
返回-
调用
summary.resamples(object = results_bestmodel)
Models: logistic_yj, rf_nor, ada_yj, gbm_bc, svm_yj, knn_nor, neural_nor
Number of resamples: 0
准确度
Min. 1st Qu. Median Mean 3rd Qu. Max. NA’s
logistic_yj NA NA NA NaN NA NA 0
rf_nor NA NA NA NaN NA NA 0
ada_yj NA NA NA NaN NA NA 0
gbm_bc NA NA NA NaN NA NA 0
svm_yj NA NA NA NaN NA NA 0
knn_nor NA NA NA NaN NA NA 0
neural_nor NA NA NA NaN NA NA 0
这可能是什么原因?我比较 3 个 AdaBoost 模型之间没有问题。
也许您的输入数据中存在一些 NaN 值?
不,我用 is.nan() 检查过,甚至 is.infinite()。此外,比较 3 个 AdaBoost 模型之间没有问题。不过,我会继续关注。谢谢。
据我所知,train() 的第一个参数意思是…
使用 ‘diabetes’ 作为结果 Y,并使用所有其他变量来预测 Y。
A) 如果我们想预测 Y 与 Y?
modelLvq “<"- train(diabetes~., data=PimaIndiansDiabetes, method="lvq", trControl=control)
我尝试了:train(y=dataset$n2, x=dataset[, -which(colnames(dataset) == "n2")],
…但这会导致消息
出了些问题;所有的 RMSE 度量值都丢失了。
B) 我也想将一个外部 R 变量传递给该参数。
这可能吗?我尝试了 paste() 和 sprintf()。但它们不起作用。
到目前为止,我只能说它是硬编码的
train(n2~.,[…]
有什么建议吗?
更新:通过进一步研究解决了 B)
f <- n2~.
http://www.learnbymarketing.com/741/using-the-caret-package-in-r/
我建议在深入研究 caret 之前先学习一些基本的 R 语法。
也许从这里开始
https://machinelearning.org.cn/r-crash-course-for-developers/
谢谢 Jason,这篇文章太棒了,而且非常容易理解。
现在我拥有了一个完整的管道,包括…
– 一个交互式命令行提示,用于在 Python 或 R 中选择具有不同参数的测试
– 一个数据库,其中填充了测试结果
– 一个 Excel 仪表板来分析和可视化我的结果。
目前有十个不同的、正在运行的实验,使用了我自己的数据。
除了特定的‘算法问题’之外,我唯一不理解的普遍问题是上面的 A) 问题。
我搜索了很多。有些人说有一天会有统一的 caret 的 train() 函数的 x 和 y 参数的语法。
Jason,您对此问题有什么额外的见解吗?
感谢您到目前为止的帮助。
我已经使用您的代码进行了梯度提升。对于其他机器学习技术,我可以将数据分为训练集和测试集,然后使用 predict 函数和 confusionMatrix 函数来获取准确率。我如何知道梯度提升的准确率???如果我使用 predict 和 confusionMatrix,我会收到一个错误。准确率显示为 AUC,而不是数值吗?
我建议进行预测并计算准确率。Caret 可以为您完成。
在这种情况下,resamples() 函数的作用是什么?
尝试:?resamples 了解更多信息。
或者这里
https://topepo.github.io/caret/model-training-and-tuning.html
嗯……文档说
这些函数提供了从共同数据集收集、分析和可视化一组重采样结果的方法。
稍后在您提到的网站上
给定这些模型,我们能否对它们的性能差异做出统计声明?要做到这一点,我们首先使用 resamples 收集重采样结果。
所以我想说 'resamples()' 函数是一种比较模型性能的工具,这些模型在 caret 中进行了训练。
你好,
帖子很好,但当我运行模型训练的代码时,我收到了以下错误,不确定为什么会收到相同的错误。您能否帮助一下。
modelLvq # 训练 GBM 模型
> set.seed(7)
> modelGbm <- train(diabetes~., data=PimaIndiansDiabetes, method="gbm", trControl=control, verbose=FALSE)
Error in train(diabetes ~ ., data = PimaIndiansDiabetes, method = "gbm",
unused arguments (data = PimaIndiansDiabetes, method = "gbm", trControl = control, verbose = FALSE)
API 可能已更改。
嗨,Jason,
您的帖子非常有帮助。做得很好🙂
非常感谢。
但是,您是否知道恢复 caret 拟合的模型的系数的最佳方法?因为我未能做到。例如,model$FinalModel$coefficients 返回 NULL。
提前感谢,
祝您有美好的一天
Célia
Jason,这是一项多么伟大的工作!谢谢。
我想确认一下。这是否让我们无需将数据分成训练/测试集并预测测试数据来验证模型?即,‘resampled’的准确率是否反映了样本内误差,还是也涵盖了样本外误差?我们是否需要对测试数据进行任何进一步的验证?
感谢您的帮助。
它们是对样本外误差的估计。
我正在尝试将此用于非分类(即回归)问题。对于回归,是否有等效于LVQ的模型?
我相信有。抱歉,我手头没有示例。
好文章,
是否有显示哪种模型在特定数据集上表现最佳的备忘单,例如分类可分与不可分数据?
线性回归怎么样?
这是不可知的,您必须尝试一系列方法并找出最适合您问题的方法。更多内容请参见此处
https://machinelearning.org.cn/faq/single-faq/what-algorithm-config-should-i-use
如果您没有指定 svmRadial 的最佳 sigma 和 cost 参数,train 如何选择它们?
它不选择,它使用默认值。您必须使用网格搜索来查找数据集的最佳超参数值。
亲爱的 Jason,
希望您一切顺利,
请问您有回归模型性能的比较吗?
我将非常感谢您的帮助,
KJ
是的,有很多。或许从这里开始
https://machinelearning.org.cn/spot-check-machine-learning-algorithms-in-r/
运行时出现以下错误
> results <- resamples(list(decision_tree=fitdt, logistic_regresion=lm.fitlog,random_forest=lm.fitrandom))
警告信息
在 resamples.default(list(decision_tree = fitdt, logistic_regresion = lm.fitlog,
某些性能指标未为每个模型计算:Accuracy, Kappa, MAE, RMSE, Rsquared
这绝对是最好的机器学习网站!我总能找到有用且简单的信息!来自巴西的感谢!
谢谢。
谢谢!
不客气。
嗨,Jason,
精彩的帖子!我有时会遇到点图和箱线图显示不同的模型性能排名,我认为是因为点图基于准确率均值和 95% CI,而箱线图基于中位数,对吗?如果是这样,如果我们真的想选择最好的一个,我们应该主要依靠哪一个?或者您认为报告哪个图都可以吗?谢谢!
谢谢!
我不记得了,抱歉,您可能需要查看文档。
Jason,谢谢您提供的材料。非常有价值。
我检查了几种算法,并根据它们的平均准确率选择了前两种。但是,我在测试数据上运行它们,得分最高的模型在未见过的数据上表现不佳,而排名第 3、4、5 的模型在未见过的数据上表现更好。哪种结果更相关,是来自 train-cv 的结果还是来自查看测试数据的结果?
祝好。
不客气。
也许您使用的保留测试集很小/不具代表性?
也许可以专注于重复 k-fold 交叉验证模型选择的结果,然后在所有数据上拟合最终模型,并开始预测新数据?